1.基本概念
1.1 定义
零个或者多个元素的有限排列
PS:元素之间有序,有限
2. 线性表的抽象数据结构
InitList(*L); // 初始化,建立一个空的线性表ListEmpty(L); // 若线性表为空,返回 true,否则返回 falseClearList(*L); // 清空线性表GetElem(L,i,*e); // 将线性表中的第 i 个位置的元素返回给 eLocateElem(L,e); // 在线性表中查找与 e 值相等的元素,并返回序号ListInsert(*L,i,e); // 在线性表中的第 i 个位置插入新元素 eListDelete(*L,i,*e); // 删除线性表中第 i 个位置的元素,并用 e 返回这个值ListLength(L); // 返回线性表的元素个数
note:
- 线性表是逻辑结构,而顺序表和链表是逻辑结构
- 插入默认是前插
- 有 * 表示,该对象发生了减少,增加,复制之类结构上的变化
- 在 C 语言中 . 用于左操作数为结构体,而 -> 用于左操作数为指向结构体的指针
3. 线性表的顺序存储结构
线性表的顺序结构就是用一段地址连续的存储单元一次存放线性表的数据元素

3.1 顺序存储方式
- 通过数组实现
- 顺序结构的三个属性
- 存储空间的起始位置:数组 data,它的存储位置就是存储空间的存储位置
- 最大存储容量:数据长度 MaxSize
- 线性表当前的长度:length
PS:线性表长度是指当前数组中元素的个数,随着元素的插入和删除发生变化(动态的),而数组的长度是一开始分配的数组最大长度,这里不考虑动态开辟数组空间的情况(静态的)
**
3.2 地址计算方法

其中 c 表示占用了 c 个存储单元
3.3 顺序表的优缺点
| 优点 | 缺点 |
|---|---|
| 快速存取任意位置的元素 | 插入和删除需要移动大量元素 |
| 容易造成空间碎片 |
3.4 顺序表的实现
链接
顺序表的静态实现
上面是静态的。
这是动态的:
note
- 顺序表插入和删除的时间复杂度都是 O(n)
- 单链表的逆置(转)
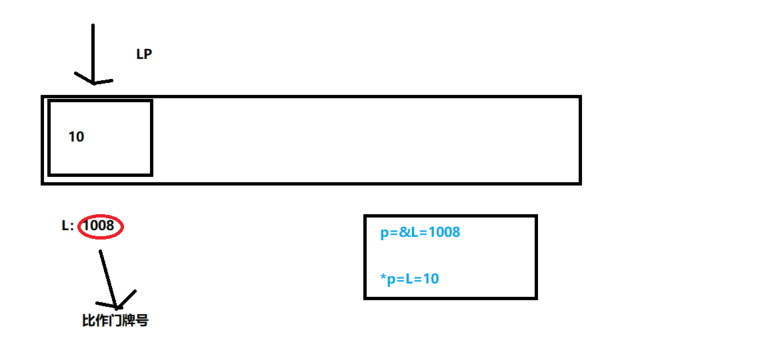
- 指针与地址
4. 线性表的链式存储结构
4.1 定义
不考虑物理上存储结构的相邻关系,只需要让逻辑上相邻。
4.2 存储结构
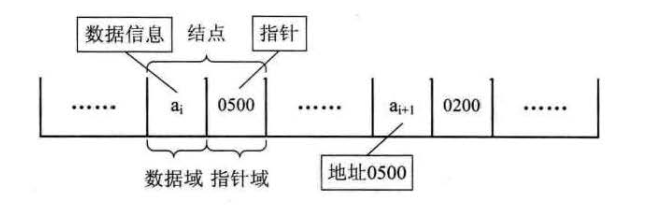
![D3UY4O1$O%K]]O9QZF)@N14.png](/uploads/projects/fromdark@yx0hps/c7d1bce96327d7efdeb2259d94583af8.png)
一个结点由数据域和指针域组成,数据域存放信息,指针域存放下一个结点的信息,尾结点的指针域尾 NULL。
链表第一个结点的存储位置叫做头指针,整个链表的存取也是从头指针开始的
为了方便起见,我们设置头结点,头指针指向头结点,头结点指向链表中第一个结点。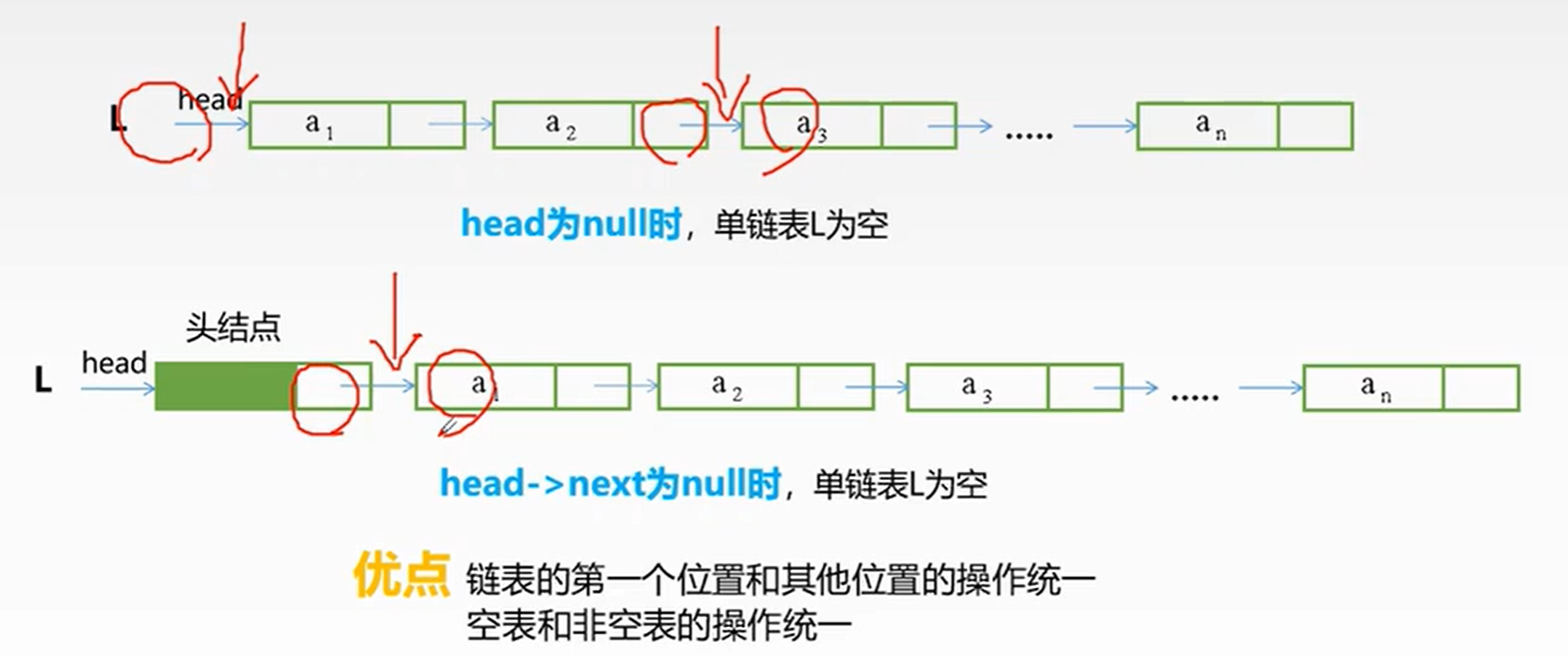
note
- 在没有头结点的时候,**
head(头指针)= NULL时为空(因为此时 head 指向第一个结点,即代表第一个结点;当有头结点的时候,head->next = NULL 表示空,此时 head 指向头结点,所以 head->next 才是指向第一个结点**。
4.3 头结点与头指针的异同
| 头指针 | 头结点 |
|---|---|
| 头指针指向链表的第一个结点,若链表由头结点,则是指向头结点的指针 | 头结点是为了操作方便设置的,不是必须的元素 |
| 头指针是链表的不要元素 |
4.4 单链表的基本操作
1. 单链表的数据结构
// typedef struct Node{...}Node;// 在学习 C 语言的时候,我们直到 struct 后面的 Node 是可以// 省略的,但是这里必须加上,因为在结构体内部定义了后驱尾// 该结构,这个时候,在运行代码的时候,最后的末尾的 Node 没有// 运行到,会报错typedef int ElemType;typedef struct Node{ElemType data;struct Node *next;}Node;// 定义一个结构体指针// 对于初学者来说,结构体指针的目的就是为了构造链表typedef struct Node *LinkList;


4.4.2. 单链表的创建
4.4.2.1. 尾插法建立单链表
- 创建单链表的过程就是一个动态生成链表的过程
- 算法的思路
- 初始化一个空链表 L:
*L = (LinkList)malloc(sizeof(Node)); - 让 L 指向 NULL:
(*L)->next = NULL; - 创建新结点 P:
LinkList p; - 循环
- 没创建一个新结点 P,就插入到头结点和就的 P 结点之间:
p->next = (*L)->next; (*L)->next =p;
- 没创建一个新结点 P,就插入到头结点和就的 P 结点之间:
- 初始化一个空链表 L:
// 以下两种插法都是带头结点的// 头插法// 头插法是每次把新加入的结点都相比于已经存在的结点// 往前插入,但是头结点本身始终位于链表最前面的结点// 这个方法相当于逆序插入void CreateListHead(LinkList *L,int n){// 创建一个新结点 pLinkList p;int i;// 初始化一个空链表// 创建一个新的结点,该节点是头结点*L = (LinkList)malloc(sizeof(Node));// L 的头结点指针指向 NULL,这是一个带头结点的单链表(*L)->next = NULL;for(i=0;i<n;i++){p = (LinkList)malloc(sizeof(Node));p->data = i;// 注意第一次时,新创建的结点指向头结点的下一个结点,此时是指向// 的 NULLp->next = (*L)->next;(*L)->next =p;}}// 尾插法void CreateListTail(LinkList *L,int n){LinkList p,r;int i;*L = (LinkList)malloc(sizeof(Node));// r 指向当前链表,注意这里的 L 和头插法中的 L// 有区别,这里的 L 是指的整个链表// r 是 rear(尾部)的缩写,此时 r 当作尾结点(因为// 当前还没有新插入的结点 p ,所以认为 r 是头结点也对)r = *L;for(i=0;i<n;i++){p=(LinkList)malloc(sizeof(Node));p->data = i;// 此时 r 为前一个结点,新创建的结点 p// 被放在 r 后面(尾插)r->next = p;// 然后让 r 变成 p,这样 r 又可以作为尾结点r = p;}// 循环结束,让尾结点指空r-next = NULL;}
这里另起一个关于头插入法的代码,目前这个是我完全掌握的。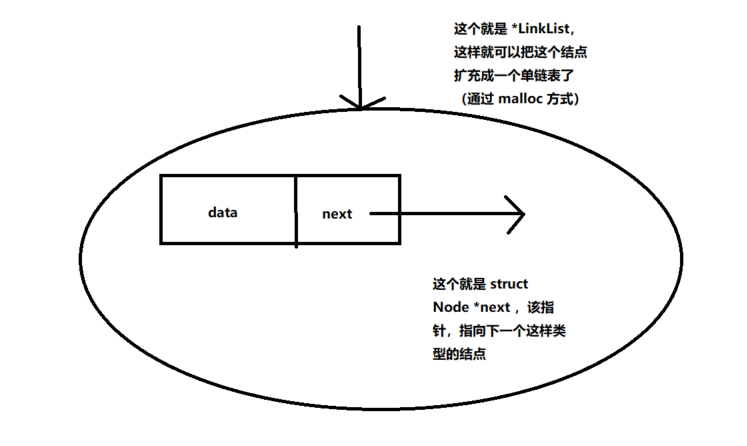
头插法(图片来源)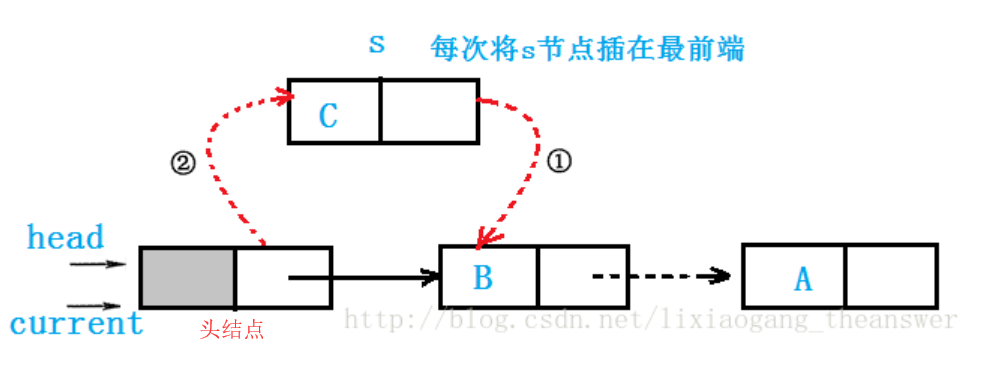
r->next = p; 的含义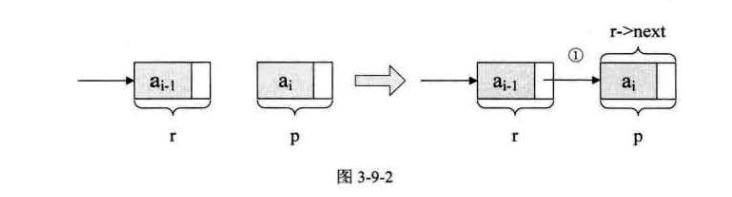
r = p; 的含义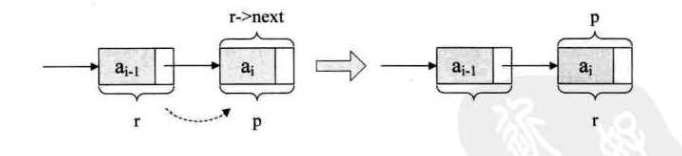
单链表的插入
3. 单链表的读取
// 单链表的读取// 依然是带有头结点的形式Status GetElem(LinkList L,ElemType *e){int j=1; // 为计数器LinkList p; // 声明一个额外的指针p = L->next; // 将 p 指向链表的第一个结点while(p && j<i) // 当 p 不为空,且当前查找到的下标小于要被查找的下标循环继续{p = p->next;++j;}if(!p||j>i)return 0;else{*e = p->data;printf("要查找的数值是:%d\n",e);}return 1;}
4. 单链表的插入与删除
插入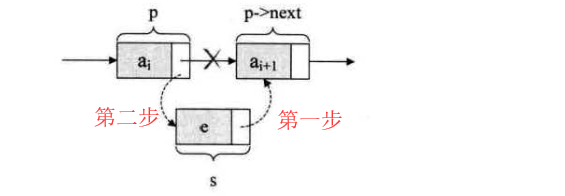
// 插入的核心代码s->next = p->next;p->next = s;
对于头尾特殊位置的插入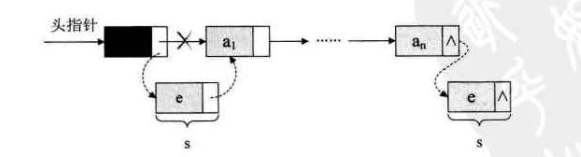
前插,且没有传入链表
删除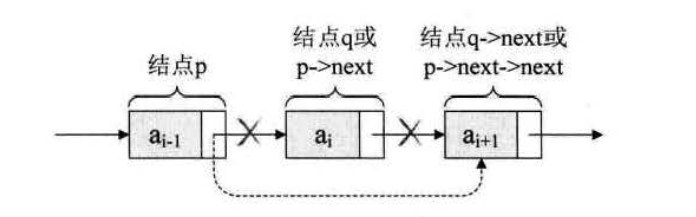
p->next = q->next
5. 单链表的整表删除
// 单链表的整表删除Status ClearList(LinkList *L){LinkList p,q;while(p){// 声明两个结点 p 和 q,分别赋值 p 为第一个结点// q 为第二个结点,当释放 p 所在的结点后,p 又指向// q。下一次循环时,q 有移动到当前 p 的下一个结点q = p->next;free(p);p=q;}// 最终将单链表完全释放掉(*L)->next = NULL;return 1;}
6. 单链表的基本操作合集
4.5 单链表的优势
单链表在插入和删除时的时间复杂度都是 O(n),所以对于插入和删除数据越频繁的操作,单链表的优势就越大。
4.6 单链表与顺序表的对比
| 存储分配方式 | 时间性能 | |
|---|---|---|
| 顺序表 | 一段连续的内存地址 | 查找:O(1) 插入和删除:O(n) |
| 单链表 | 逻辑上连续,物理上随机 | 查找:O(n) 插入和删除:O(1) |
5. 静态链表
所谓静态链表,就是用数组来代替指针描述链表的一种方式。
数组元素由两个数据域 data 与 cur 组成。其中 data 存放数据元素,cur(游标)起到指针的作用。
之所以这么做,是因为在早期的编程语言中还没有引入指针的概念。
5.1 静态链表的抽象结构
#define MAXSIZE 1000typedef int ElemType;typedef struct{ElemType data;int cur;}Component,StaticLinkList[MAXSIZE];
在已经划分的数组空间中,未被使用的数组元素称为备用链表。
其中,数组的第一个(下标为 0 )和最后一个元素另作他用,不存储数据。
下标为 0 的元素 cur 存放备用链表(未被使用的数组元素)的第一个结点的下标,最后一个元素 cur 存放已使用的第一个元素的下标(相当于头结点)。
PS:
- 初始化静态链表的时候,除了首尾两个元素,其他都是空的,即都是备用链表。
- 静态链表初始化时没有任何元素,则其 cur 为 0。
- 指针域指出下一个结点的位置
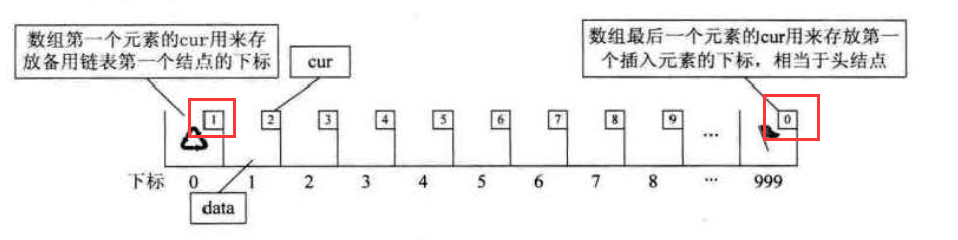
5.2 静态链表的初始化
// 初始化Status InitList(StaticLinkList space){int i;for(i=0;i<MAXSIZE-1;i++)space[i].cur = i+1;space[MAXSIZE-1].cur=0; // 当前初始化链表为空return 1;}
5.3 静态链表的插入
在单链表中我们使用 malloc 和 free 函数作为实现插入和删除的必备步骤。但是静态链表不具备这样的函数,所以需要我们手动实现。
思想
未使用(包括之前删除的)的每个数组空间构成备用链表(就是之前的讲的那个),当插入时从备用链表上取一个结点作为被插入的新结点。
// 自定义具有 malloc 功能的函数int mallocSll(StaticLinkList space){// 当前第一个备用链表的下标// 也就是上图中下标为 1 的元素空间// i 的值时这个下标为 1 的元素空间的下一个元素空间// 即下标为 2int i=space[0].cur;if(space[0].cur)space[0].cur = space[i].cur; // 将第二个备用链表升级成第一个// 返回空闲下标return i;}
插入
// 插入操作Status ListInsert(StaticLinkList L,int i,ElemType e){int j,k,l;k = MAXSIZE-1; // k 是最后一个元素的下标if(i<1 || i>ListLength(L)+1)return 0;j = mallocSll(L); // 获得空闲下标if(j){L[j].data = e; // 将数据赋给 datafor(l=1;l<=i-1;l++)k=L[k].cur;// 最后一个元素的 cur 是用来存放已使用的// 第一个元素的下标L[j].cur=L[k].cur;// 前一个元素的下标指向新元素的下标L[k].cur=j;return 1;}return 0;}
5.4 静态链表的删除
自定义的 free 函数
// 自定义 free 函数void FreeSll(StaticLinkList space,int k){// 把原来的一个备用链表的下标给现在被删除的空位的下标// 即后面如果还有数值插入,就优先插入现在被删除的位置space[k].cur = space[0].cur;// 更新第一个备用链表下标为 kspace[0].cur = k;}
删除
// 删除操作Status ListDelete(StaticLinkList L,int i){int j,k;if(i<1 || i>ListLength(L))return 0;k = MAXSIZE -1 ;for(j=1;j<=i-1;j++)k=L[k].cur;j=L[k].cur;L[k].cur=L[j].cur;FreeSll(L,j);return 1;}
5.5 静态链表的操作合集
6. 循环链表
- 将终端结点的指针由空指针(即指向 NULL)改为指向头结点,使链表形成了一个环,这就是循环链表。
- 循环链表解决了如何从任意一个结点出发就可以访问全部结点的问题。
- 和单链表不同的是,循环链表使用尾指针。其开始结点可以这样表示:
rear->next->next - 带头结点的循环单链表的尾指针指向头结点

7. 双向链表
7.1 双向链表的抽象结构
typedef struct DulNode{ElemType data;struct DuLNode *prior;struct DuLNode *next;} DulNode,*DuLinkList;
循环双向链表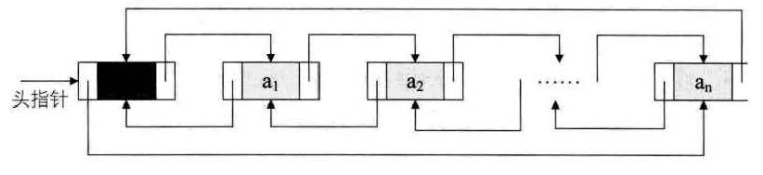
循环双向链表的前驱的后继和后继的前驱都是自己
p->next->prior = p = p->prior->next
7.2 插入和删除操作
插入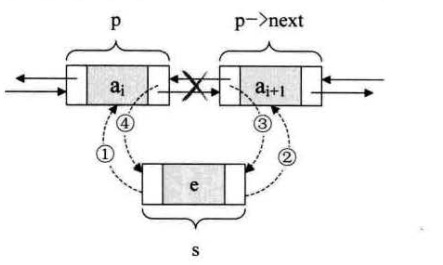
s->prior = p;
s->next = p->next;
p->next->prior = s;
p->next = s;
删除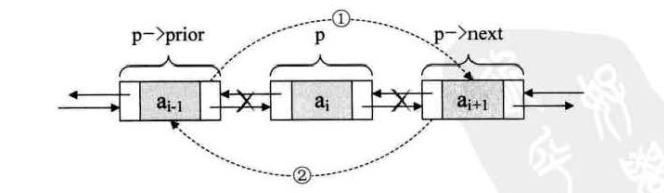
p->prior->next=p->next;
p->next->prior=p->prior;
free(p);
7 总结与回顾



若有收获,就点个赞吧
0 人点赞
