pod生命周期
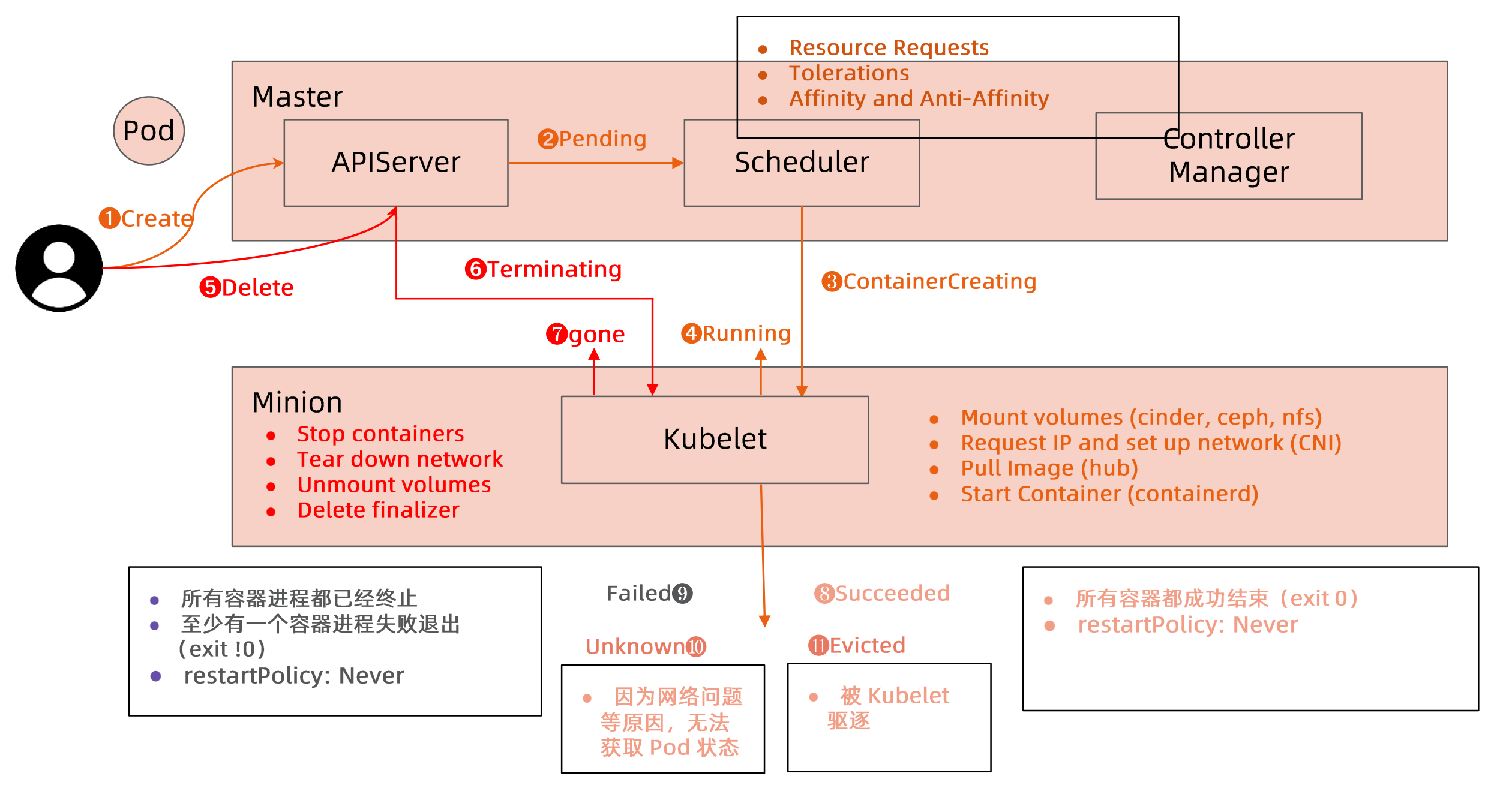
用户创建POD
APIserver将请求存入etcd,此时pod的node name是空的,pod处于pending状态
pending状态的pod会被调度器schedule发现,进行调度,调度完成更新node name,pod处于containerCreating状态
kubelet调用CRI/CNI创建pod,pod处于running状态
failed:
- pod内所有容器都终止
- restartpolicy为never, 不再执行重启
- 至少有1个进程失败退出
Unknown:网络问题,状态无法上报pod状态
Success:
- 所有进程都正常退出(退出状态码是0),
- restartpolicy为never,意味着不会被重新拉起
evicted:被kubelet驱逐
terminating状态:用户删除pod,这个过程中需要处理以下内容
- 应用进程要退出
- 存储数据导出
- 网络tear down
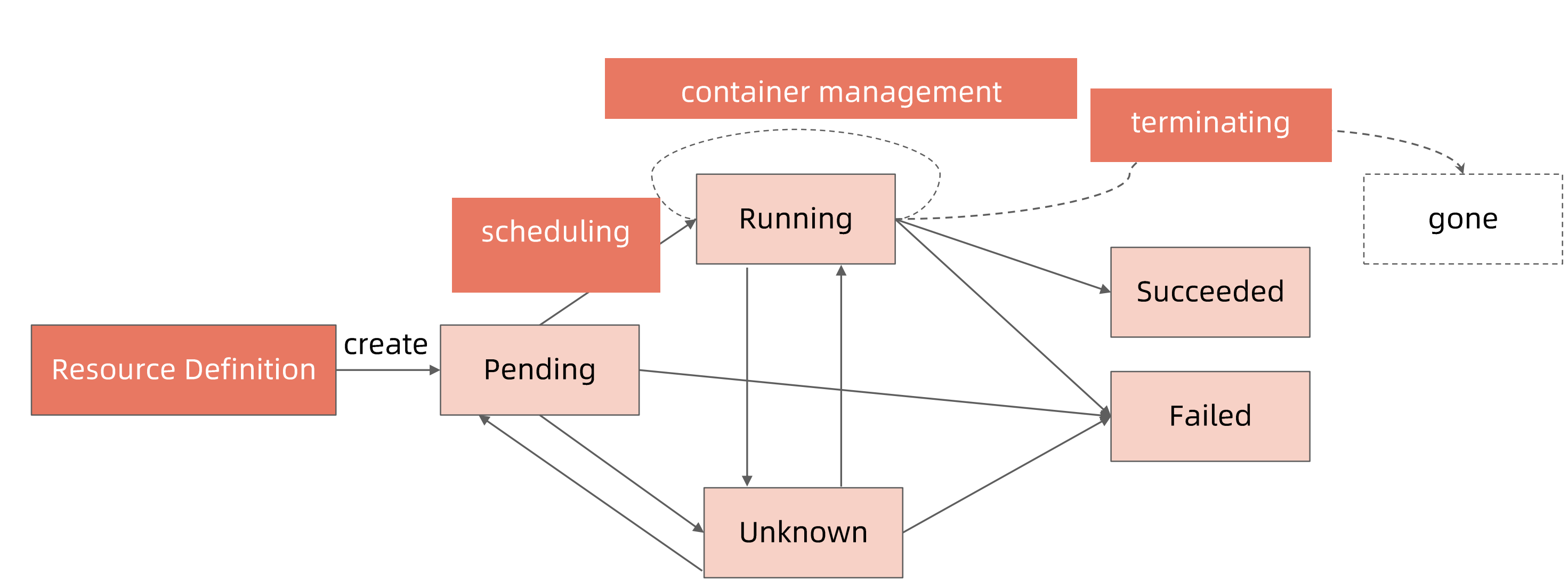
condition 什么时间更新
condition:更细节的状态
pod phase:全局状态
pending
running
succeeded
failed
unknown
get pod时显示的状态信息是由pod status的condition和phase计算出来的
查看pod的细节
kubectl get pod $podname -o yaml
查看pod相关事件
kubectl describe pod $podname
| get pod 状态 | pod phase | conditions |
|---|---|---|
| Completed | Succeeded | |
| ContainerCreating | Pending | |
| CreateContainerConfigErr | Pending | configmap “test” not found secret “my-secret” not found |
| ErrImagePull/ImagePullBackOff/Init:ImagePullBackOff/InvalidImageName | Pending | backoff pulling image |
| Init: 0/1 | Pending | Init containers donnot exit |
| Init: CrashLoopBackoff/Init:Error | Pending | Init container crashed(exit with not 1) |
| CrashLoopBackOff | Running | Container exits |
| OOMKiller | Running | Containers are OOMKilled |
| StartError | Running | COntainers cannot be started |
| Unknown | Running | Node NotReady |
| Error | Failed | restartPolicy: Never container exits with error(not 0) |
| OutOfCpu/OutOfMemory | Failed | Scheduled, but it cannot pass kubelet admit |
如何确保POD高可用
避免容器进程被终止,pod被驱逐
- 设置合理的resource.memory limits防止容器进程被OOMkill
- 设置合理的emptydir.sizeLimit并且确保数据写入不超过emptyDir的限制,防止pod驱逐
Pod的Qos分类
Guaranteed
- pod的每个容器都设置了资源CPU和内存需求
- Limit和requests的值完全一致
Burstable # 超售,提升资源利用率
- 至少一个容器指定了CPU或者内存 request
- pod的资源需求不符合Guaranteed QoS的条件,也就是requests小于limits
BestEffort
- Pod中的所有容器都未指定CPU或者内存资源需求requests
当计算节点检测到内存(不可压缩资源)压力时,kubernetes被按照 BestEffort、Burstabble、Curaranteed的书序依次驱逐pod
Burstable适用于大多数场景
- 超售,提升资源利用率
- requests锁定一定的资源
- 平衡资源利用率和应用性能
Node Lifecycle Controller驱逐过了tolerationSeconds的pod
健康检测探针
健康检测探针类型
- livenessProbe 应用进程探活,默认是活的
- 探活,检测失败意味着应用进程无法正常提供服务,kubelet会终止容器进程并按照restartPolicy决定是否重启
- readlineProbe 进程还未启动完成,不能接收traffic,默认是false
- 就绪检查,当检查失败时,意味着应用进程正在运行,但因为某些原因无法提供服务,Pod的状态会被标记为NotReady
- startupProbe
- 在初始化阶段(Ready之前)进行的健康检查,通常用来避免过于频繁的检测影响应用启动。
在pod启动过程中,先进行 startupProbe 检测,等待pod启动完成后在进行 livenessProbe、readlineProbe 检测
探活方法
- ExecAction:在容器内部运行指定指令,当返回码为0时,探测结果为成功
- TCPSocketAction:由kubelet发起,检测容器端口是否可达
- HTTPGetAction:由kubelet发起对pod ip和端口以及路径进行HTTPGet,当返回状态码为200~400时,探测结果为成功
探针属性
- InitialDelaySeconds:pod启动后延迟多久做第1次检测
- PeriodSeconds:
- timeoutSeconds:多久没有返回则失败
- SuccessThreshold:几次成功算成功
- failureThreshold:几次失败算失败
ReadnessGates
readiness 允许在kubernetes再带的pod condition之外引入自定义的就绪条件
Condition加上条件,需要为True状态,Pod才可以为就绪状态
改状态应该由某控制器修改
Post-start 和Pre-stop hook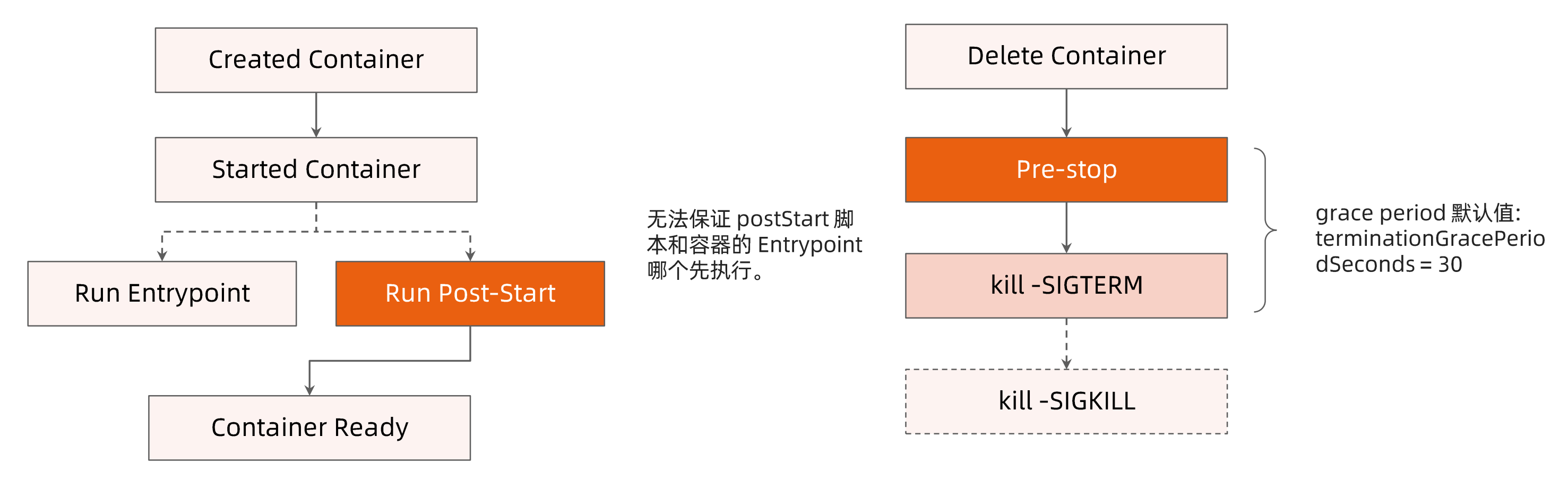
Post-start
- EntryPoint和Post-start并行执行,无先后顺序
- postStart结束之前,容器不会被标记为running
pre-stop
- 自定义定义优雅终止的行为
- kill -SIGTERM 通知进程终止
- kill -SIGKILL杀死进程
Pre-stop+SIGTERM需要等待(terminationGracePeriodSeconds=30),最后执行SIGKILL,防止进程突然被kill
terminationGracePeriodSeconds
sh没有处理SIGTERM的能力
服务发布
通过service提供pod的固定访问地址路径,pod重建等不影响这个路径
ClusterIP 集群内部访问
默认类型,APIserver启动时通过service-cluster-ip-range参数配置虚拟ip地址段
NodePort 集群外部可以访问
APIserver启动时通过node-port-range参数配置nodePort范围,默认是30000~32000
每个节点的kube-proxy会在服务分配的nodePort上建立侦听器接收请求,并转发给服务对应的pod实例
同时拥有ClusterIP和NodePort
127.0.0.1 和 localhost 访问NodePort不同
LoadBanlacer 结合外部控制器,配置负载均衡器
企业数据中心的负载均衡器,作为外网请求进入数据中心内部统一流量入口
针对不同基础架构云平台,k8s cloud manger 提供支持不同供应商API的service controllerr。
以下两种基于DNS
ExternalName 为外部域名定义一个域名,可以在内部访问,怎么实现
相当于cname
Headless service
显示将ClusterIP定义为Node,则不会分配统一入口
服务发布的挑战
kube-dns
- DNS TTL问题,因为TTL,客户端无法及时感知到域名后端服务的变化,导致请求可能会被发到故障节点
- 通常域名指向的地址是静态的不经常变换的
Service
由kube-proxy配置iptables和ipvs实现,4层负载均衡
- ClusterIP 只能对内
- iptables和ipvs规模限制,产生性能和生产化问题
- kube-proxy drift问题
- 频繁的pod变动会导致LB频繁变更
- 对外帆布包的Service需要与企业的ELB集成
- 默认不支持grpc
- 不支持自定义DNS和高级路由功能
Ingress
- Spec的成熟度?
跨地域部署
需要多少实例
如何控制失败域,不部署几个地区,AZ,集群
如何进行精细的流量控制
如何按低于顺序更新
如何回滚
微服务架构下的高可用挑战
服务发现
- 服务注册发现
- 服务提供方一般以集群方式提供服务,同时引入负载均衡和健康检查
集中式LB服务发现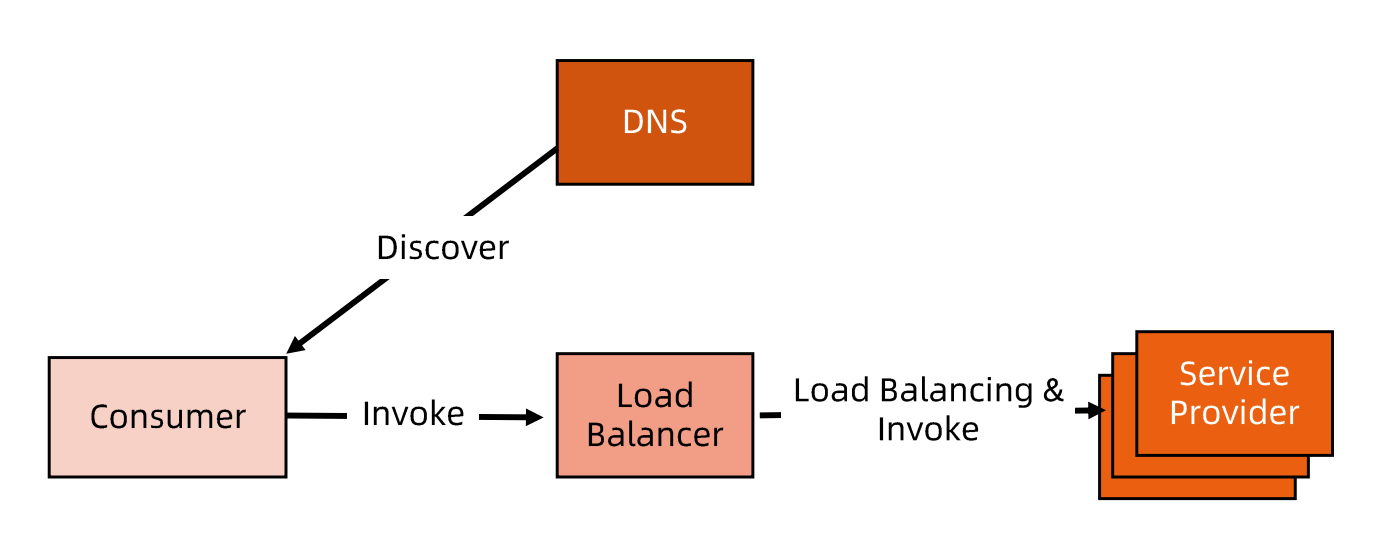
- 在服务消费者和服务发现者中间有一个独立的LB
- LB上有所有的地址转换映射表,通常由运维配置管理
- 服务消费方调用服务时,它向LB发起请求,由LB以某种策略负载均衡到转发请求到目标后端
- LB一般具有健康检查能力
- 服务消费方通过DNS发现LB,运维人员为服务配置DNS域名,指向这个LB
优缺点
- LB实现简单,在LB上比较容易做访问控制,这一方案还是业界主流
- LB存在单点问题和性能瓶颈
- 在服务消费方和提供方中间增加一跳,有性能开销
进程内LB服务发现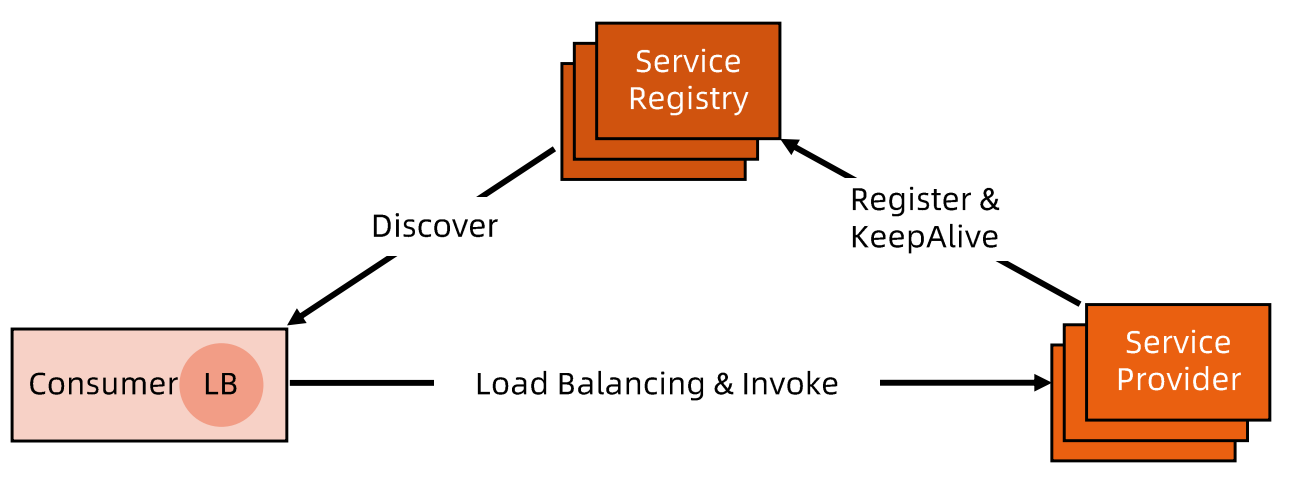
- 进程内LB将LB功能以库的形式集成到服务消费方的进程中,该方案也被称为客户端负载方案
- 服务注册表配合支持服务自注册和自发现(服务将地址注册到注册表中,同时定期上报心跳以表明存活状态)
- 对服务注册表的可用性要求很高,一般采用能满足高可用分布式组件(zk,consul,etcd)
优缺点
- 消费者从注册中心发现服务后,直接访问服务提供者,没有额外开销,性能较好。
- 需要维护多种语言的客户端,有一定研发和维护成本
- 一旦客户端发布到生产系统中后续如果要多客户端升级,势必要求业务方升级代码并重新发布,该方案升级推广有阻力
独立LB进程服务发现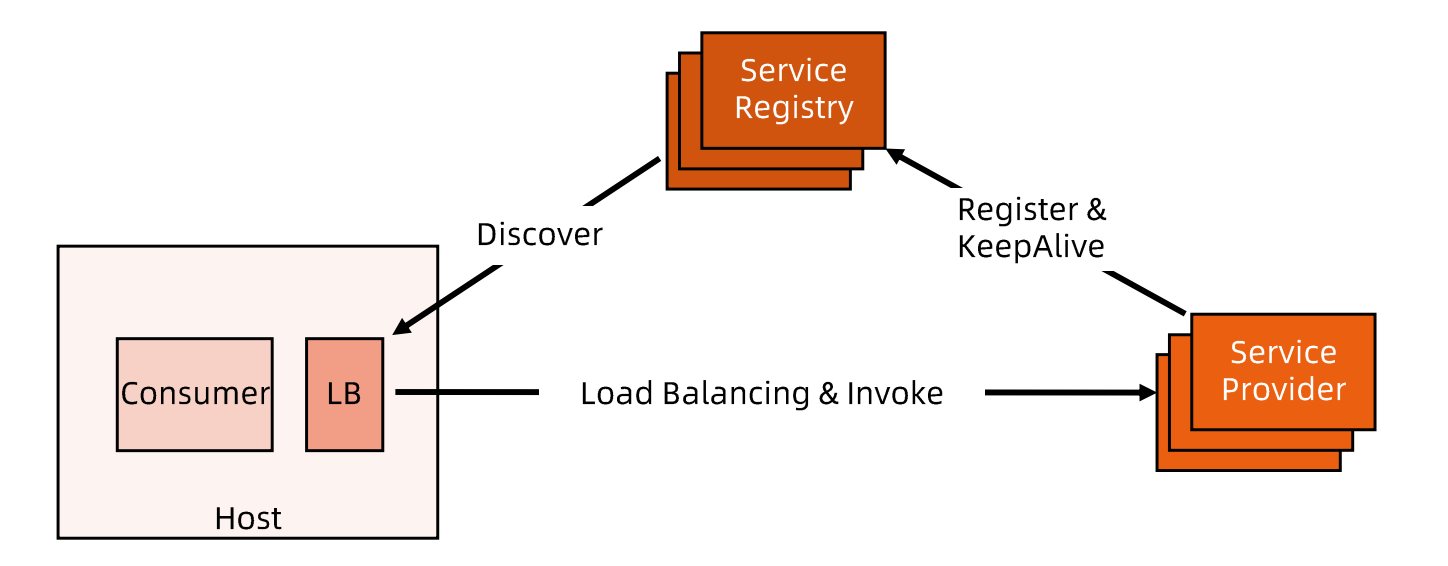
- 针对进程内LB模式不足而提出的一种这种方案
- 将LB和服务发现功能从进程内移出来,变成主机上独立的进程,主机上一个或者多个服务要访问目标服务时,他们通过同意主机上独立的LB进程做服务发现和负载均衡
- LB独立进程可以进一步与服务消费方进行解耦,以独立集群形式提供高可用的负载均衡服务
- 软负载
优缺点
- 独立LB进程也是一种方案,没有单点,一个LB进程挂了只影响该主机上的服务调用方
- 服务调用方和LB之间是进程间调用,性能好
- 简化了调用方,不需要为不同语言开发客户端库,LB升级不需要调用方改代码
- 部署较复杂,环节多,排查问题不方便
负载均衡
纵向(垂直)扩展和横向(水平)扩展
纵向扩展,从单机角度通过增加硬件处理能力
横向扩展,通过增加机器和负载均衡来提高对外能力
负载均衡解决的问题
- 解决并发压力,提高吞吐
- 提供故障转移,实现高可用
- 通过添加或减少服务器数量,提供网站的伸缩性,扩展性
- 安全防护,负载均衡设备上做过滤,黑白名单等
DNS负载均衡
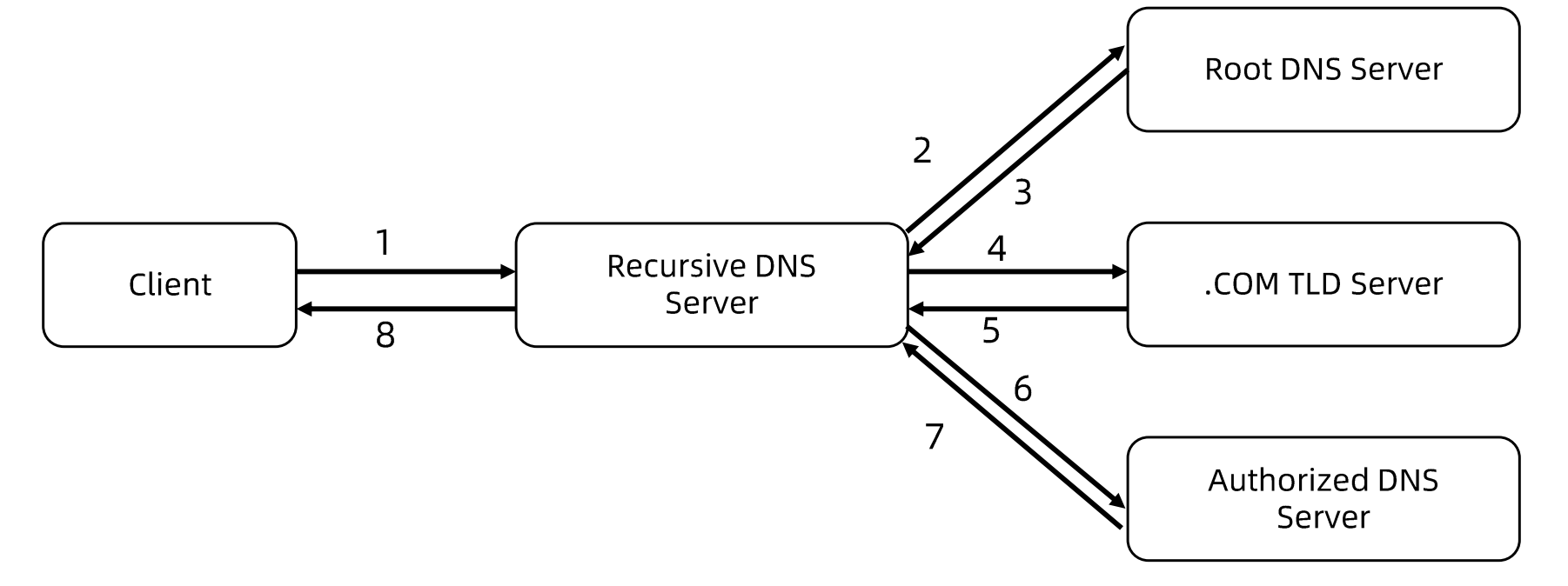
最早的负载均衡技术,利用域名解析实现负载均衡,在DNS服务器上,配置多个A记录,多个A记录对应多个后端服务
针对返回的多个IP,客户端可以采取失败更换IP重试,解决A记录失效但记录并未移除的问题
优点
使用简单,省掉了负载均衡服务器维护麻烦
挺高性能,可以提供基于地址的域名解析,解析成举例用户最近的服务器地址,改善访问速度。
缺点
可用性差,DNS解析是多级解析,新增修改DNS后,解析时间较长
扩展性低,DNS负载聚恒控制权在福明提供商,无法做更多的改善和扩展
维护性差,不能反应服务器当前的运行状态,支持的算法少,不能区分服务器的差异
负载均衡技术概览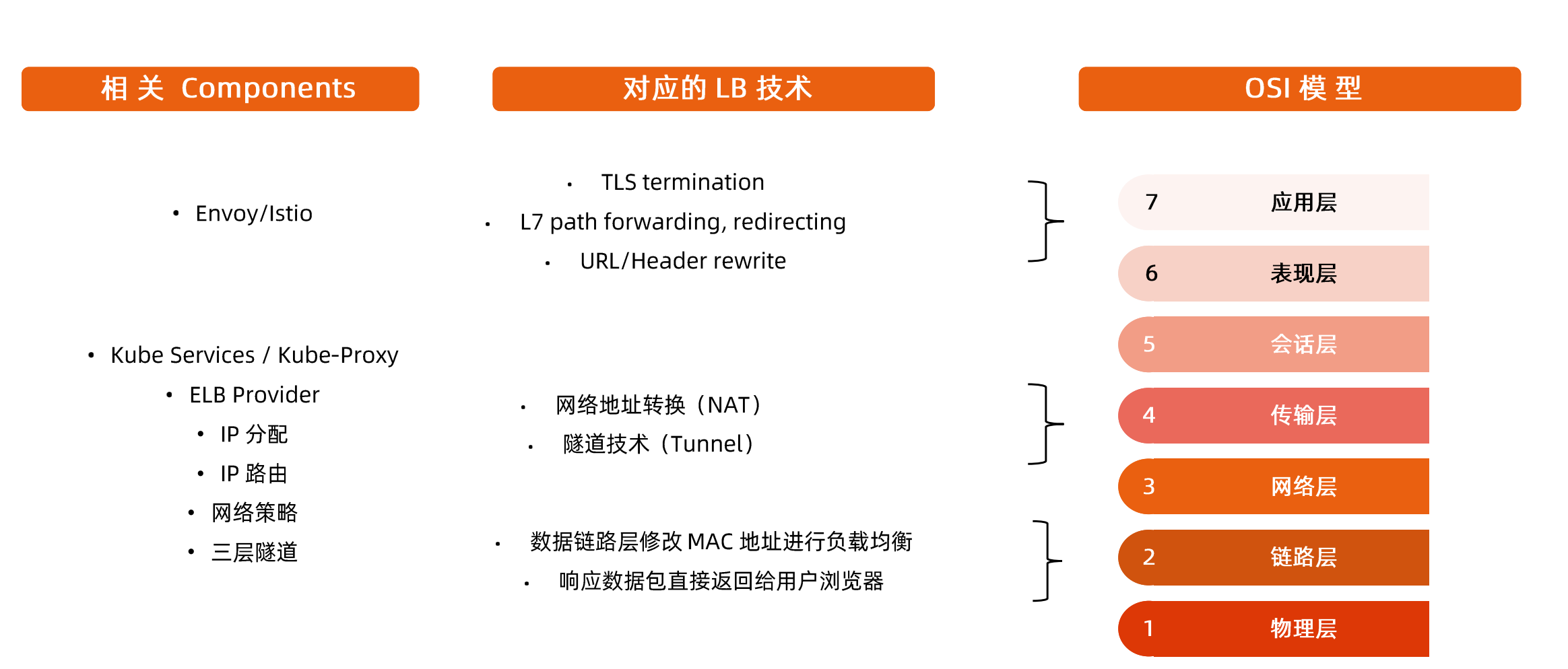
链路层,源、目标mac地址
网络层,源、目标ip地址
传输层,源、目标i端口
应用层,contextpath,uri,各种method,和header
执行目标的属性上做文章
各种技术补充
service
Service对象-example
apiVersion: v1kind: Servicemetadata:name: nginx-service-demospec:selector:app: nginxports:- name: httpprotocol: TCPport: 80targetPort: 80
- Service Selector
允许将pod对象标签通过label进行过滤,以便选择服务的上游应用
- Ports
定义协议(TCP、UDP),服务端口和目标端口
service工作在4层,protocol只有tcp或者udp
默认是clusterIP类型,通过service的clusterIP访问资源
为什么是4层
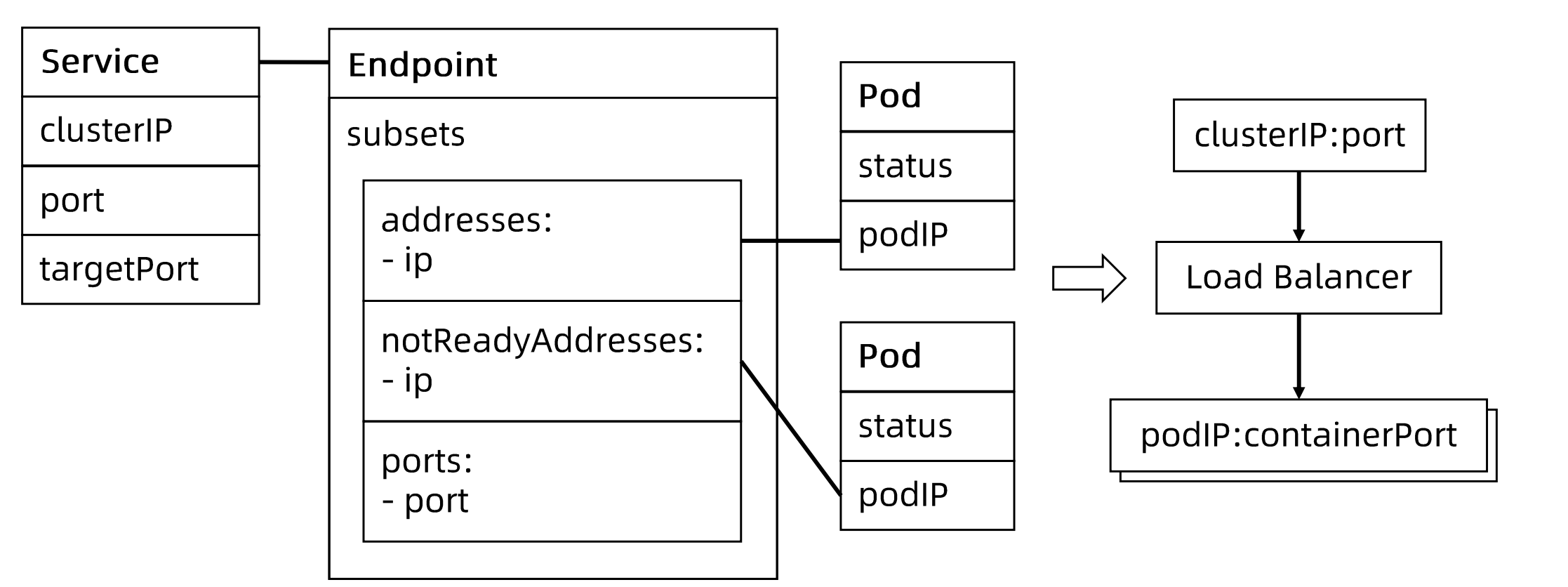
endpoint对象
apiVersion: v1kind: Endpointsmetadata:annotations:endpoints.kubernetes.io/last-change-trigger-time: "2022-06-19T09:25:29Z"creationTimestamp: "2022-06-19T09:25:29Z"name: nginx-demonamespace: defaultresourceVersion: "7133305"uid: 371c2eea-c68a-4d19-970b-46f745ff0c9asubsets:- addresses:- ip: 192.168.237.45nodeName: kubernetes-mastertargetRef:kind: Podname: nginx-deployment-85b98978db-zcnc5namespace: defaultresourceVersion: "7133072"uid: 6bec10fc-4284-4743-95f6-aad6c2fc7847ports:- name: httpport: 80protocol: TCP
endpoint controller 监听两类对象:
- pod
- service
endpoint controller发现service被创建,并且定义了selector;endpoint controller建立一个和service同名的endpoint对象,按照selector去选择target pod,如果pod是就绪的,subsets.addresses中就会有对应pod的地址;如果未就绪则在notReadyAddresses
notReadyPod不接流量
pod和service之间是多对多的关系,endpoint则是维护了这种中间多对多的关系
EndpointSlice
https://kubernetes.io/zh-cn/docs/concepts/services-networking/endpoint-slices/
- 当service对应的backend pod较多时,endpoint对象因为保存大量pod导致endpoint对象变得很大。
- pod状态变更会引起endpoint变更,endpoint变更会推送到所有节点,从而占用大量网络带宽
- EndpointSlice对象用于pod较多时对endpoint进行切片,切片大小可以自定义
不定义selector的service
用户创建了service但未定义selector,则不会创建endpoint
- endpoint controller 不会为该serive创建 endpoint
- 用户可以手动创建endpoint对象,并设置任意IP地址到address
- 访问该服务的请求会被发送到目标地址
用于访问集群外部的资源
DNS
不同类型的DNS记录
普通service
ClusterIP,NodePort,LoadBalancer类型的service都有APIserver分配的ClusterIP,CoreDNS会为这些service创建FQDN格式为 $svcname.$namespace.svc.$clusterdomain
headless service
显式声明ClusterIP为None,APIserver不会分配ClusterIP,CoreDNS会为此类Service创建多条A记录,并且目标为就绪的PodIP
每个pod会拥有一个FQDN格式为$podname.$svcname.$namespace.svc.$clusterdomain的A记录指向PodIP
External Service
用来引用已经存在的域名,CoreDNS会创建一个cname指向目标域名
当pod启动时,同一namespace的service都会以环境变量形式加载在pod中
enableServiceLinks 所有的service信息都会以环境形式存在pod中
自定义DNSpolicy
当service名字确定,加上namespace确定,可以通过DNS唯一确定一个FQDN来访问服务,比clusterip更加稳定(Service重建,ClusterIP会变)
error: error validating “headless-svc.yaml”: error validating data: ValidationError(Service.spec): unknown field “ClusterIP” in io.k8s.api.core.v1.ServiceSpec; if you choose to ignore these errors, turn validation off with —validate=false
Ingress
解决了什么问题
service工作在四层,实现了网络地址转换;ingress工作在七层,同一个域名下不同子系统转发。
| 基于L4的服务 | 基于L7的Ingress |
|---|---|
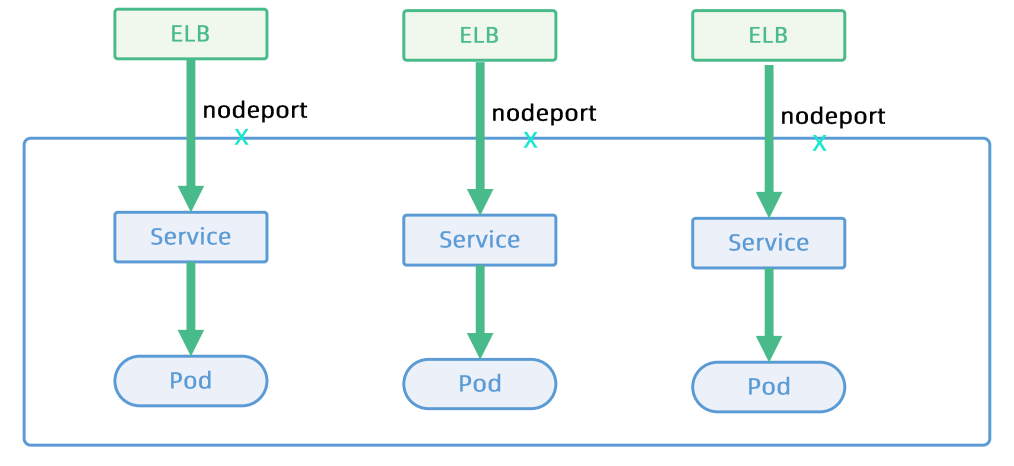
- 基于iptables/ipvs的四层负载均衡技术(基于数据包5元组) - 多种LB provider与企业现有的ELB整合 - kube-proxy基于iptables规则为k8s形成全局统一的分布式LB - kube-proxy是一种mesh,Internal Client,无论是通过podip,nodeport,还是LB vip都是经由kube-proxy跳转至pod |
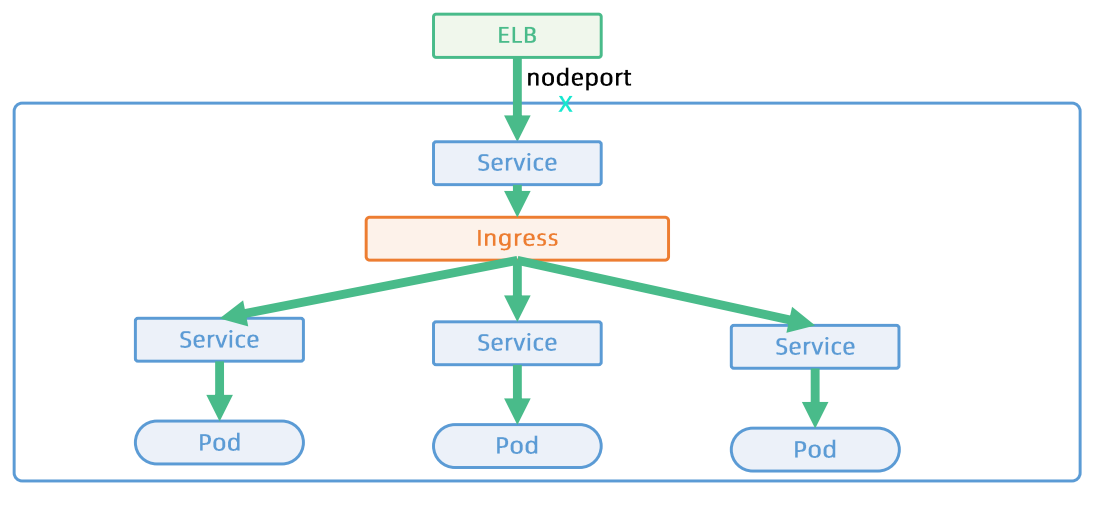
- 基于7层应用层,提供更多的功能 - TLS termination - L7 path 转发 - URL/http header rewrite |
- 每个应用独占ELB - 为每个服务动态创建DNS记录,频繁更新DNS - 支持TCP和UDP,业务部门需要启动https服务,自己管理证书 |
 |
|
- 多个应用共享ELB,节省资源
- 多个应用共享一个domain,可采用静态DNS配置
- TLS termination发生在Ingress层,可集中管理证书
- 更多的复杂性,更多网络hop
- 用户态进程
 |
|
安装ingress
https://kubernetes.github.io/ingress-nginx/deploy/#quick-start
root@kubernetes-master:/jfs/cncamp101/module8/ingress# kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.2.0/deploy/static/provider/cloud/deploy.yamlroot@kubernetes-master:/jfs/cncamp101/module8/ingress# kubectl get svc -n ingress-nginxNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEingress-nginx-controller LoadBalancer 10.108.3.54 <pending> 80:31823/TCP,443:31098/TCP 30mingress-nginx-controller-admission ClusterIP 10.111.165.87 <none> 443/TCP 30mroot@kubernetes-master:/jfs/cncamp101/module8/ingress# kubectl get pod -n ingress-nginxNAME READY STATUS RESTARTS AGEingress-nginx-admission-create-496d9 0/1 Completed 0 31mingress-nginx-admission-patch-gbdzs 0/1 Completed 0 31mingress-nginx-controller-7575567f98-jj5zl 1/1 Running 0 31m
创建ingress,请求先发到service的nodeport,由kube-proxy将请求转发到ingress-nginx-controller pod中,进入nginx处理部分
Ingress
- 是一层代理
- 负责根据hostname和path将流量转发到不同的服务上,使得一个负载均衡器用于多个后台应用
- k8s Ingress Spec 是转发规则的集合
Ingress Controller
- 确保实例状态(Actual)与期望状态(Desired)一致的Control Loop
- 负载均衡配置
- 边缘路由配置
- DNS配置
如何安装ingress
ingress-example
apiVersion: networking.k8s.io/v1kind: Ingressmetadata:name: gatewayannotations:kubernetes.io/ingress.class: "nginx"spec:tls:- hosts:- cncamp.comsecretName: cncamp-tlsrules:- host: cncamp.comhttp:paths:- path: "/"pathType: Prefixbackend:service:name: nginx-basicport:number: 80
traefik
https://www.qikqiak.com/tags/traefik/
rewrite
https://kubernetes.github.io/ingress-nginx/examples/rewrite/
国内源
https://xuxinkun.github.io/2019/06/11/cn-registry/
crictl 和docker对比
https://kubernetes.io/zh-cn/docs/reference/tools/map-crictl-dockercli/
update cert
https://github.com/yuyicai/update-kube-cert
LDAP 中 CN, OU, DC 的含义
https://www.cnblogs.com/qiuxiangmuyu/p/6438650.html

若有收获,就点个赞吧
0 人点赞
