etcd是CoreOS基于raft协议分布式kv存储,可用于服务发现、共享配置以及一致性保障(数据库选主,分布锁)。
在分布式系统中,如何管理节点间的状态一直是一个难题,etcd像是专门为集群环境的服务发现和注册而设计的。
- 键值对存储:将数据存储在分层的组织目录中,如同在标准的文件系统中
- 监测变更:监控特定的键或目录的变更
- 简单:curl可访问的API
- 安全:可选的SSL证书
- 快速:单实例每秒1000次读写,2000+读操作
- 可靠:使用raft算法保证一致性
如何支撑大规模集群
使用场景
键值对存储
etcd是一个键值存储的组件,其他应用都是基于器键值存储的功能展开
- 采用kv型数据存储,一般情况下比关系型数据库快
- 支持动态存储(内存)和静态存储(磁盘)
- 分布式存储,可成为多节点集群
- 存储方式,采用类似于目录结构(B+Tree)
- 只有叶子节点才能真正存存储数据,相当于文件
- 叶子节点的父节点一定是目录,且不能存储数据
服务注册与发现
强一致性、高可用的服务存储目录
注册服务和服务健康状况机制
用户可以在etcd中注册服务,并对注册的服务配置key TTL,定时保持服务的心跳以达到监控健康状态的效果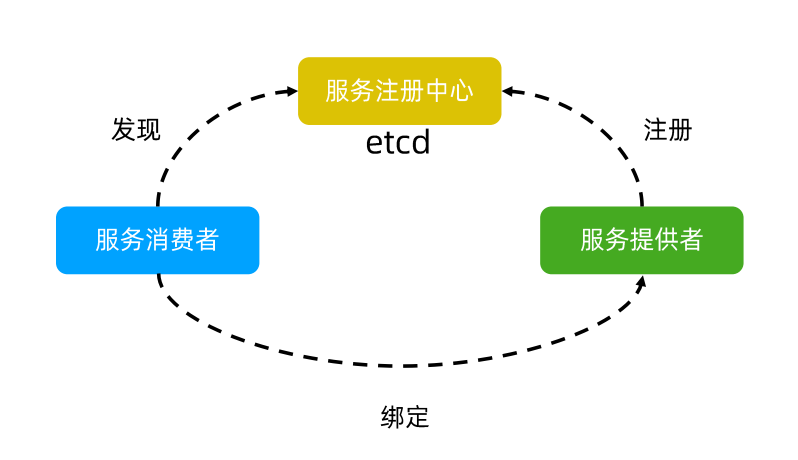
消息发布与订阅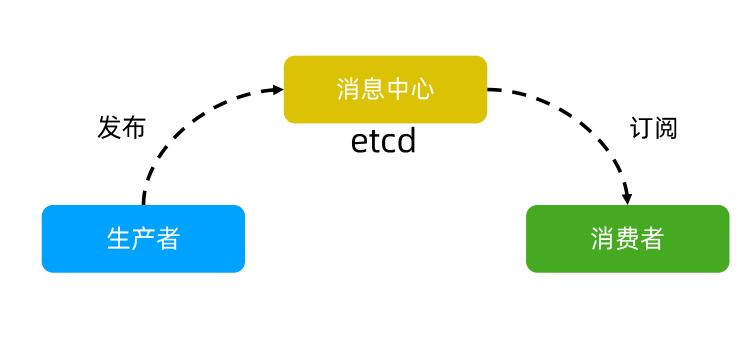
- 构建一个配置共享中心,数据提供者在配置中心发布消息,消息使用者订阅相关主题,一旦有消息发布,就会实时通知订阅者
- 通过这种方式可以做到分布式系统配置的集中管理和动态更新
- 应用中常用的信息放到etcd进行集中管理
- 应用在启动的时候主动从etcd获取一次配置信息,同事在etcd节点航注册一个watch并等待,以后每次配置更新的时候,etcd都会实时通知订阅者,以此达到获取最新配置信息的目的
TTL
Time to Live 指的是给一个key设置一个有效期,到期后这个key就会被自动删除,这在很多分布式锁的实现上都会用到,可以保证锁的实时有效
CAS
Atomic Compare and Swap 指的是在对key进行赋值时,客户端需要指定一些条件,当条件满足后才能赋值
- prevExist: key 当前赋值前是否存在
- prevValue: key 当前赋值前的值
- prevIndex: key当前赋值前的Index
key的设置是有前提的,需要知道这个key的具体情况才能对齐进行设置
安装
ETCD_VER=v3.5.4# choose either URLDOWNLOAD_URL=https://github.com/etcd-io/etcd/releases/downloadrm -f /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gzrm -rf /tmp/etcd-download-test && mkdir -p /tmp/etcd-download-testcurl -L ${DOWNLOAD_URL}/${ETCD_VER}/etcd-${ETCD_VER}-linux-amd64.tar.gz -o /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gztar xzvf /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz -C /tmp/etcd-download-test --strip-components=1rm -f /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz/tmp/etcd-download-test/etcd --version/tmp/etcd-download-test/etcdctl version/tmp/etcd-download-test/etcdutl version
启动
## 成员相关参数# member 指定名称--name default# 数据目录--data-dir /etcd-data# 集群节点之间通信监听的 URL--listen-peer-urls http://localhost:2380#以下两个参数需要一起使用# 监听客户端请求的 URL--listen-client-urls http://localhost:2379# 此成员的客户端URL的列表,以广播到集群的其余部分--advertise-client-urls http://localhost:2379## 集群相关参数--initial-cluster-state [new|existing]# 起始启动的集群配置--initial-cluster default=http://localhost:2380# 此成员的对等URL的列表,以通告到集群的其余部分。这些地址用于在集群周围传递etcd数据。所有集群成员必须至少有一个路由。这些URL可以包含域名。--initial-advertise-peer-urls http://localhost:2380# 集群初始化所使用的 Token 值,不同集群使用不同的值# 防止多个独立集群出现意外交互--initial-cluster-token "etcd-cluster"## 安全相关参数# 客户端服务器 TLS CA 文件路径--ca-file# 客户端服务器 TLS 密钥(key)文件路径--key-file# 客户端服务器 TLS 证书文件路径--cert-file# 客户端服务器 TLS 授信 CA 文件路径--trusted-ca-file# 服务器 TLS 证书文件路径--peer-cert-file# 服务器 TLS key 文件路径--peer-key-file# 客户端证书吊销列表文件的路径--client-crl-file
默认的端口是2379/2380
使用容器启动一个测试demo
参考
root@aliyun:/tmp/etcd-v3.5.4-linux-amd64/default.etcd# docker run -d --name Etcd-server \> --network app-tier \> --publish 2379:2379 \> --publish 2380:2380 \> --env ALLOW_NONE_AUTHENTICATION=yes \> --env ETCD_ADVERTISE_CLIENT_URLS=http://etcd-server:2379 \> bitnami/etcd:latest8a00906c8427599a38846b19b1e3fccf48ae2c4c0f775e2fb59b67a21088e7e7root@aliyun:/tmp/etcd-v3.5.4-linux-amd64/default.etcd# docker port Etcd-server2380/tcp -> 0.0.0.0:23802380/tcp -> :::23802379/tcp -> 0.0.0.0:23792379/tcp -> :::2379
命令行启动测试demo
./etcd
term 从2开始 每重新启动一次,term会加2 如果指定数据目录,建议目录权限为700
日志中有默认的启动参数
{"level":"info","ts":"2022-05-21T19:16:22.843+0800","caller":"embed/etcd.go:308","msg":"starting an etcd server","etcd-version":"3.5.4","git-sha":"08407ff76","go-version":"go1.16.15","go-os":"linux","go-arch":"amd64","max-cpu-set":2,"max-cpu-available":2,"member-initialized":false,"name":"default","data-dir":"a","wal-dir":"","wal-dir-dedicated":"","member-dir":"a/member","force-new-cluster":false,"heartbeat-interval":"100ms","election-timeout":"1s","initial-election-tick-advance":true,"snapshot-count":100000,"snapshot-catchup-entries":5000,"initial-advertise-peer-urls":["http://localhost:2380"],"listen-peer-urls":["http://localhost:2380"],"advertise-client-urls":["http://localhost:2379"],"listen-client-urls":["http://localhost:2379"],"listen-metrics-urls":[],"cors":["*"],"host-whitelist":["*"],"initial-cluster":"default=http://localhost:2380","initial-cluster-state":"new","initial-cluster-token":"etcd-cluster","quota-size-bytes":2147483648,"pre-vote":true,"initial-corrupt-check":false,"corrupt-check-time-interval":"0s","auto-compaction-mode":"periodic","auto-compaction-retention":"0s","auto-compaction-interval":"0s","discovery-url":"","discovery-proxy":"","downgrade-check-interval":"5s"}
etcdctl使用
# 获取成员信息root@kubernetes-master:~# etcdctl --endpoints=localhost:12379 --write-out=table member list+------------------+---------+---------+----------------------+----------------------+------------+| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |+------------------+---------+---------+----------------------+----------------------+------------+| eb06dc1bc141ff4f | started | default | http://0.0.0.0:12380 | http://0.0.0.0:12379 | false |+------------------+---------+---------+----------------------+----------------------+------------+# 写入读取数据root@kubernetes-master:~# etcdctl --endpoints=localhost:12379 put /key1 value1OKroot@kubernetes-master:~# etcdctl --endpoints=localhost:12379 put /key2 value2OKroot@kubernetes-master:~# etcdctl --endpoints=localhost:12379 get --prefix / [--keys-only]/key1value1/key2value2# 查看key/valueroot@aliyun:/tmp/etcd-v3.5.4-linux-amd64# etcdctl get a -wjson{"header":{"cluster_id":14841639068965178418,"member_id":10276657743932975437,"revision":1025,"raft_term":11},"kvs":[{"key":"YQ==","create_revision":2,"mod_revision":1025,"version":1011,"value":"MTAwMA=="}],"count":1}root@aliyun:/tmp/etcd-v3.5.4-linux-amd64# echo "YQ==" | base64 -daroot@aliyun:/tmp/etcd-v3.5.4-linux-amd64# echo "MTAwMA==" | base64 -d# 查看所有数据etcdctl get "" --prefix=true# watch数据root@kubernetes-master:~# etcdctl --endpoints=localhost:12379 watch --prefix / [--rev 0]PUT/key3value3
etcd基于raft的一致性
选举方法
初始启动时,节点处于follower状态并被设定election timeout,如果在这一事件周期内没有收到来自leader的heartbeat。此节点将发起选举,将自己切换为candidate,向集群中其他follower发送请求,询问是否选举自己为leader
当收到超过半数的节点的投票,此节点将成为leader。开始接收保存client的数据,并向其他follower节点同步日志。
如果没有达成一致,则candidate(candidate是否还保持状态,还是变为follower)随机选择一个等待间隔(150ms~300ms)再次发起投票,得到集群半数以上的投票的candidate将成为leader
candidate是否也能投票,应该是智能投自己,不能投其他人。
leader节点依靠定时向follower发送心跳来保持其地位。(心跳频率是多少)
任何时候,如果其他follower在election timeout期间没有收到来自leader的心跳,同样会将自己切换为candidate状态。每成功选举一次,新leader的任期Term都会比之前的leader的任期大1
日志复制
当leader接收到客户端的日志(事务请求)后会先把日志追加到本地log中,然后通过心跳把Entry同步给其他follower,follower接收到日志记录日志到本地log后向leader发送ACK
当leader收到大多数的ACK信息后,将该日志设置为已提交并追加到磁盘,并在下次心跳中通知follower将日志存储到本地磁盘
写请求可以发到follower,follower会在一致性模块中将写请求转发到leader
安全性
保证每个节点都执行相同序列的安全机制
当某个follower消息落后于leader 的committed log时,恰好leader故障了,稍后可能该follower会被选举为leader,这时新的leader会用新的log覆盖先前已经committed的log,这会导致节点执行不同序列,safety就是用于保证选举出来的leader一定包含先前已经committed的log
选举安全性(election safety):每个任期只能选出一个leader
leader完成性(leader compelteness)
指leader日志的完整性,当log在任期term1被commit后,那么后面的任期必须包含该log;raft在选举阶段使用term判断用于保证完整性:当请求投票的candidate term较大,或term相同index更大则投票,否则拒绝投票。
给比自己厉害的人投票
失效处理
leader失效
没有收到心跳的节点会发起选举,当leader恢复后由于term小于新leader会自动降级成为follower(日志也会被新的leader日志覆盖)
follower节点不可用
集群中的日志始终是从leader同步的,只要这一节点再次加入集群时重新从leader节点处复制日志即可
多个candiate
冲突后的candidate将随机选择等待时间后再次投票,得到半数以上投票的candidate成为leader
灾备
备份
etcdctl --endpoints https://127.0.0.1:3379 \--cert /tmp/etcd-certs/certs/127.0.0.1.pem \--key /tmp/etcd-certs/certs/127.0.0.1-key.pem \--cacert /tmp/etcd-certs/certs/ca.pem snapshot save snapshot.db
查看备份数据
etcdctl --write-out=table snapshot status snapshot.db
恢复
export ETCDCTL_API=3etcdctl snapshot restore snapshot.db \--name infra0 \--data-dir=/tmp/etcd/infra0 \--initial-cluster infra0=https://127.0.0.1:3380,infra1=https://127.0.0.1:4380,infra2=https://127.0.0.1:5380 \--initial-cluster-token etcd-cluster-1 \--initial-advertise-peer-urls https://127.0.0.1:3380etcdctl snapshot restore snapshot.db \--name infra1 \--data-dir=/tmp/etcd/infra1 \--initial-cluster infra0=https://127.0.0.1:3380,infra1=https://127.0.0.1:4380,infra2=https://127.0.0.1:5380 \--initial-cluster-token etcd-cluster-1 \--initial-advertise-peer-urls https://127.0.0.1:4380etcdctl snapshot restore snapshot.db \--name infra2 \--data-dir=/tmp/etcd/infra2 \--initial-cluster infra0=https://127.0.0.1:3380,infra1=https://127.0.0.1:4380,infra2=https://127.0.0.1:5380 \--initial-cluster-token etcd-cluster-1 \--initial-advertise-peer-urls https://127.0.0.1:5380
构建多副本集群
安装cfssl
apt install golang-cfssl
生成tls证书
git clone https://github.com/etcd-io/etcd.gitcd etcd/hack/tls-setup# 编辑hosts部分,加入主机节点cat config/req-csr.json{"CN": "etcd","hosts": ["localhost","127.0.0.1"],"key": {"algo": "rsa","size": 2048},"names": [{"O": "autogenerated","OU": "etcd cluster","L": "the internet"}]}export infra0=127.0.0.1export infra1=127.0.0.1export infra2=127.0.0.1make
启动服务
## each etcd instance name need to be unique# x380 is for peer communication# x379 is for client communication# dir-data cannot be shared#nohup etcd --name infra0 \--data-dir=/tmp/etcd/infra0 \--listen-peer-urls https://127.0.0.1:3380 \--initial-advertise-peer-urls https://127.0.0.1:3380 \--listen-client-urls https://127.0.0.1:3379 \--advertise-client-urls https://127.0.0.1:3379 \--initial-cluster-token etcd-cluster-1 \--initial-cluster infra0=https://127.0.0.1:3380,infra1=https://127.0.0.1:4380,infra2=https://127.0.0.1:5380 \--initial-cluster-state new \--client-cert-auth --trusted-ca-file=/tmp/etcd-certs/certs/ca.pem \--cert-file=/tmp/etcd-certs/certs/127.0.0.1.pem \--key-file=/tmp/etcd-certs/certs/127.0.0.1-key.pem \--peer-client-cert-auth --peer-trusted-ca-file=/tmp/etcd-certs/certs/ca.pem \--peer-cert-file=/tmp/etcd-certs/certs/127.0.0.1.pem \--peer-key-file=/tmp/etcd-certs/certs/127.0.0.1-key.pem 2>&1 > /var/log/infra0.log &nohup etcd --name infra1 \--data-dir=/tmp/etcd/infra1 \--listen-peer-urls https://127.0.0.1:4380 \--initial-advertise-peer-urls https://127.0.0.1:4380 \--listen-client-urls https://127.0.0.1:4379 \--advertise-client-urls https://127.0.0.1:4379 \--initial-cluster-token etcd-cluster-1 \--initial-cluster infra0=https://127.0.0.1:3380,infra1=https://127.0.0.1:4380,infra2=https://127.0.0.1:5380 \--initial-cluster-state new \--client-cert-auth --trusted-ca-file=/tmp/etcd-certs/certs/ca.pem \--cert-file=/tmp/etcd-certs/certs/127.0.0.1.pem \--key-file=/tmp/etcd-certs/certs/127.0.0.1-key.pem \--peer-client-cert-auth --peer-trusted-ca-file=/tmp/etcd-certs/certs/ca.pem \--peer-cert-file=/tmp/etcd-certs/certs/127.0.0.1.pem \--peer-key-file=/tmp/etcd-certs/certs/127.0.0.1-key.pem 2>&1 > /var/log/infra1.log &nohup etcd --name infra2 \--data-dir=/tmp/etcd/infra2 \--listen-peer-urls https://127.0.0.1:5380 \--initial-advertise-peer-urls https://127.0.0.1:5380 \--listen-client-urls https://127.0.0.1:5379 \--advertise-client-urls https://127.0.0.1:5379 \--initial-cluster-token etcd-cluster-1 \--initial-cluster infra0=https://127.0.0.1:3380,infra1=https://127.0.0.1:4380,infra2=https://127.0.0.1:5380 \--initial-cluster-state new \--client-cert-auth --trusted-ca-file=/tmp/etcd-certs/certs/ca.pem \--cert-file=/tmp/etcd-certs/certs/127.0.0.1.pem \--key-file=/tmp/etcd-certs/certs/127.0.0.1-key.pem \--peer-client-cert-auth --peer-trusted-ca-file=/tmp/etcd-certs/certs/ca.pem \--peer-cert-file=/tmp/etcd-certs/certs/127.0.0.1.pem \--peer-key-file=/tmp/etcd-certs/certs/127.0.0.1-key.pem 2>&1 > /var/log/infra2.log &
容量管理
- 单个对象不建议超过1.5M
--max-request-bytes - 默认容量2G,不建议超过8G
--quota-backend-bytes在 3.4 版本中,etcd 的存储容量得到了提高,你可以设置 100G 的存储空间,当然并不是越大越好,key 存储过多性能也会变差,根据集群规模适当调整。
设置 etcd 存储大小
限制16M
etcd --quota-backend-bytes=$((16*1024*1024))
写爆磁盘
while [ 1 ]; do dd if=/dev/urandom bs=1024 count=1024 | ETCDCTL_API=3 etcdctl put key || break; done
查看member状态
ETCDCTL_API=3 etcdctl --write-out=table endpoint status
查看alarm
ETCDCTL_API=3 etcdctl alarm list
清理碎片
ETCDCTL_API=3 etcdctl defrag
清理alarm
只有清理了alarm才能继续写入数据
ETCDCTL_API=3 etcdctl alarm disarm
压缩历史版本
自动压缩
# 不压缩,默认配置--auto-compaction-mode=0# 按时间段来(配置开启,periodic):# 每1/10个配置的时间段,执行一次压缩,压缩的数据是1/10个小时计算的。--auto-compaction-mode=periodic // 按时间段压缩--auto-compaction-retention=10h // 保留10小时前的历史数据# 按版本号(配置开启,reversion):# 每5分钟执行一次:扫描现有key的所有latestVersion。压缩掉 latestVersion-retention之前的所有--auto-compaction-mode=revision // 按时间段压缩--auto-compaction-retention=1000 //保留近1000个revision
主动压缩
# 在 5 之前的所有版本都会被压缩,不可访问etcdctl compact 5# 如果 etcdctl get --rev=4 demo,会报错Error: rpc error: code = 11 desc = etcdserver: mvcc: required revision has been c
碎片整理
# 碎片整理## defrag命令默认只对本机有效etcdctl defrag## 如果带参数--endpoints,可以指定集群中的其他节点也做整理etcdctl defrag --endpoints xxx## 如果etcd没有运行,可以直接整理目录中db的碎片etcdctl defrag --data-dir <path-to-etcd-data-dir>
碎片整理会阻塞对etcd的读写操作,因此偶尔一次大量数据的defrag最好逐台进行,以免影响集群稳定性。
用户权限
租约

若有收获,就点个赞吧
0 人点赞
