课后练习 9.1
测试对 CPU 的校验和准入行为
- 定义一个 Pod,并将该 Pod 中的 nodeName 属性直接写成集群中的节点名。
- 将 Pod 的 CPU 的资源设置为超出计算节点的 CPU 的值。
- 创建该 Pod。
- 观察行为并思考。
结果是OutOfcpu
制定了pod,应该会跳过schedule调度,直接到kubelet上(通过不超限的资源可以印证这一点,event中无调度这个过程)
在启动pod前会再次进行资源确认,因为超限了,所以OutOfcpu
9.3 kubernetes集群可能存在的问题
基础架构守护进程问题:ntp关闭等
硬件问题:CPU,内存、磁盘、网卡损坏
内核问题:内核死锁,文件系统损坏
容器运行时问题:运行时守护程序无响应
当k8s中节点发生上述问题,k8s 无法感知,会导致pod仍然调度到这些节点。
node-problem-detector
社区引入引入守护进程node-problem-detector
- runtime无响应
- linux kernel无响应
- 网络异常
- 文件描述符异常
硬件问题如CPU,内存或者磁盘故障
故障分类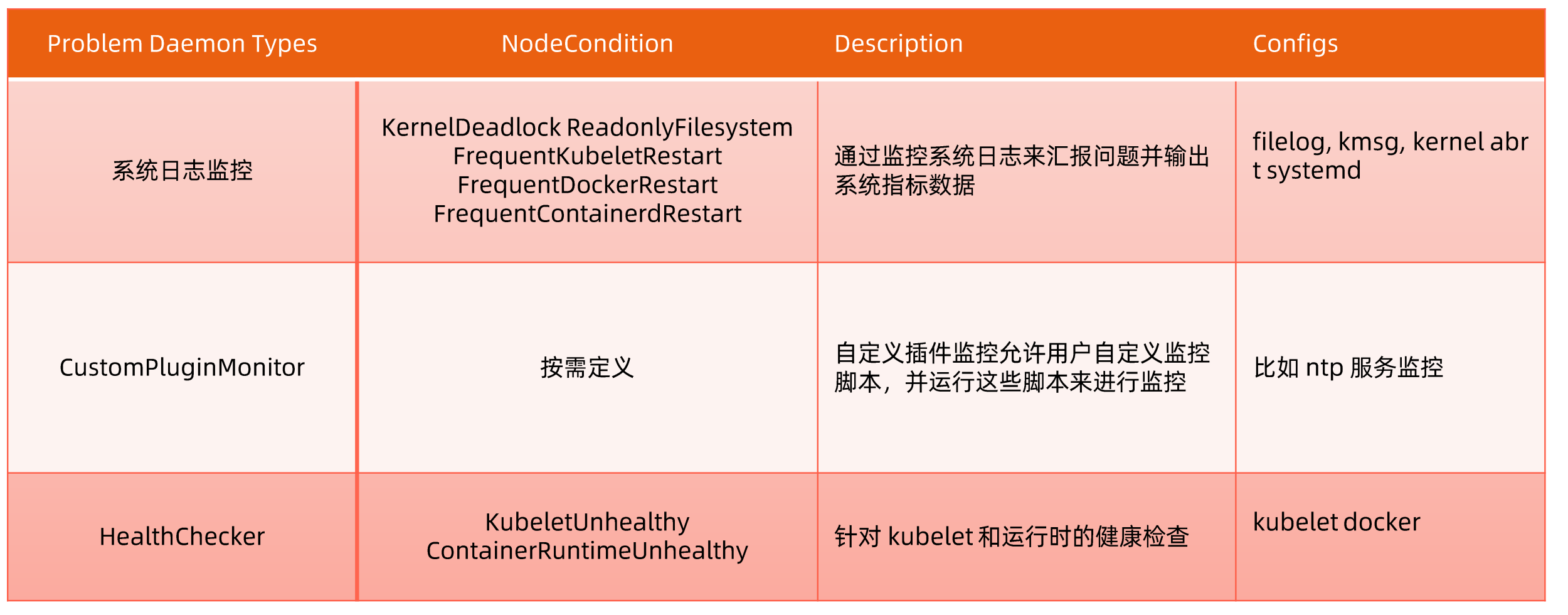
问题汇报手段
通过设置NdeCondition或者Event对象来汇报问题NodeCondition:针对永久性故障,会通过NodeCondition来改变节点状态
- Event:临时故障,通过Event来提醒相关对象,比兔通知当前节点运行的pod
https://github.com/kubernetes/node-problem-detector
helm repo add deliveryhero https://charts.deliveryhero.io/helm install deliveryhero/node-problem-detector
集群部署时在动加载
kubectl logs [-f] [-p] (POD | TYPE/NAME) [-c CONTAINER]’
clusterapi
https://cluster-api.sigs.k8s.io/user/quick-start.html
安装clusterctl
https://cluster-api.sigs.k8s.io/user/quick-start.html#install-clusterctl

若有收获,就点个赞吧
0 人点赞
