一种分层数据的抽象模型
满二叉树:
如果一棵深度为k的二叉树其节点数为2- 1那么这棵树便是满二叉树,也就是说除了叶节点以外,其他节点都有两个子节点。
完全二叉树:
满二叉树是一种特殊的完全二叉树,在满二叉树的基础上,除了倒数第二层不是两个子节点,其他节点均有两个字节点,且最下层的节点都集中在左边。
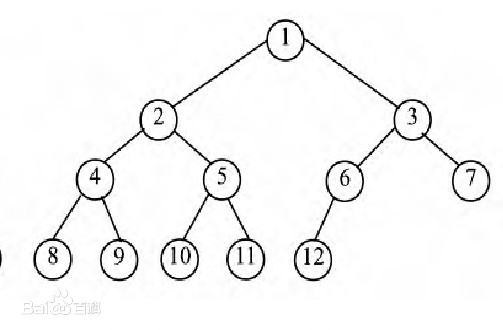
二叉树的结构:
- 使用js的Array与Object构建一棵树
```javascript
const tree = {
val: “a”,
children: [
] }{val: "b",children: [{val: "d",children: []},{val: "e",children: []}]},{val: "c",children: [{val: "f",children: []},{val: "g",children: []}]}
2. 二叉树(本质是对象的嵌套)
```javascript
const bt = {
val: 1,
left: {
val: 2,
left: {
val: 4,
left: null,
right: null
},
right: {
val: 5,
left: null,
right: null
}
},
right: {
val: 3,
left: {
val: 6,
left: null,
right: null
},
right: {
val: 7,
left: null,
right: null
}
}
}
二叉树的常用操作有:深度、广度优先遍历,先中后序遍历
深度优先遍历,其特点是尽可能深的访问二叉树的分支。
const dfs = (root) => { // 访问根节点 console.log(root.val); // 对根节点的children挨个进行深度优先遍历 root.children.forEach(node => dfs(node)); // root.children.forEach(dfs); } dfs(tree);广度优先遍历,其特点是优先访问离根节点近的节点,从左子树开始。
const bfs = (root) => { // 创建一个队列,将根节点入队 const queue = [root]; while (queue.length) { // 将队头出队并访问 let queueTop = queue.shift(); console.log(queueTop.val); // 将队头的children挨个入队 queueTop.children.forEach(node => { queue.push(node); }) } }先序遍历 ```javascript // 递归版,在做题时使用较多 const preorder = (root) => { if (!root) return; // 首先访问根节点 console.log(root.val); // 对根节点的左子树进行先序遍历 preorder(root.left); // 对根节点的右子树进行先序遍历 preorder(root.right); }
// 使用栈的非递归版 const preorder = (root) => { if (!root) return; const stack = [root]; while (stack.length) { const tmp = stack.pop(); console.log(tmp.val); if(tmp.right) stack.push(tmp.right); if(tmp.left) stack.push(tmp.left); } }
- 中序遍历
```javascript
// 递归版
const inorder = (root) => {
if (!root) return;
inorder(root.left);
console.log(root.val);
inorder(root.right);
}
// 非递归版
const inorder = (root) => {
if (!root) return;
const stack = [];
let p = root; // 使用一个指针
while (stack.length || p) {
while (p) {
stack.push(p);
p = p.left;
}
let temp = stack.pop();
console.log(temp.val);
p = temp.right;
}
}
- 后序遍历(使用较少) ```javascript // 递归版 const postorder = (root) => { if (!root) return; postorder(root.left); postorder(root.right); console.log(root.val); }
// 非递归版 const postorder = (root) => { if (!root) return; const stack = [root]; const outputStack = []; while (stack.length) { const tmp = stack.pop(); outputStack.push(tmp); if (tmp.left) stack.push(tmp.left); // 注意这里和先序遍历不同,是先放右节点 if (tmp.right) stack.push(tmp.right); } while (outputStack.length) { const tmp = outputStack.pop(); console.log(tmp.val); } }
<a name="0hGdO"></a>
#### 补充一下堆:
堆是一种特殊的**完全二叉树**,不一样的是堆的每一个节点都**大于**或者**小于**(也有可能等于)他的子节点,也就是说堆顶的节点值一定是最大的或者最小的。<br /> <br />在JS中常用**数组**来表示堆,所以我们节点的位置常常用数组的索引表示,我们要记得三个关键的位置:
- 左节点:**2*index+1**(index代表父节点索引)
- 右节点:**2*index+2**(index代表父节点索引)
- 父节点:**(index-1)/2**(index代表子节点索引)
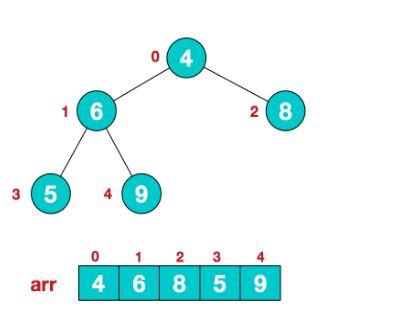<br />那么堆主要用来干嘛的呢?在算法题中主要用来查找数组中**第k大或第k小**的元素,过程是这样的:
- 将元素放入堆的底部
- 判断堆的大小是否超过k,如果超过删除堆顶的元素
- 结束后堆顶就是第k个最大或者最小的元素
我们来看一个用**ES6**实现最小堆的代码:
```javascript
class MinHeap {
constructor() {
this.heap = [];
}
swap(i1, i2) {
let tmp = this.heap[i1];
this.heap[i1] = this.heap[i2];
this.heap[i2] = tmp;
}
getParentIndex(n) {
return (n - 1) >> 1;
}
getLeftIndex(i) {
return (2 * i) + 1;
}
getRightIndex(i) {
return (2 * i) + 2;
}
shiftUp(index) {
if (index === 0) return;
// 首先我们需要获取当前节点的父节点的索引
const parentIndex = this.getParentIndex(index);
// 判断当前节点与父节点的大小
if (this.heap[parentIndex] &&
this.heap[parentIndex] > this.heap[index]) {
// 将当前节点与父节点进行交换
this.swap(parentIndex, index);
// 重复直到到达栈顶或者为最小父节点
this.shiftUp(parentIndex);
}
}
shiftDown(index) {
let leftIndex = this.getLeftIndex(index);
let rightIndex = this.getRightIndex(index);
if (this.heap[leftIndex] &&
this.heap[index] > this.heap[leftIndex]) {
this.swap(index, leftIndex);
this.shiftDown(leftIndex);
}
if (this.heap[rightIndex] &&
this.heap[index] > this.heap[rightIndex]) {
this.swap(index, rightIndex);
this.shiftDown(rightIndex);
}
}
insert(value) {
// 将值放入到最小堆中
this.heap.push(value);
// 传入其索引进行上移操作
this.shiftUp(this.heap.length - 1);
}
// 删除堆顶
pop() {
if(this.heap.length === 1) {
this.heap.shift();
return;
}
if(this.heap.length === 0) return;
this.heap[0] = this.heap.pop();
this.shiftDown(0);
}
peek() {
return this.heap[0];
}
size() {
return this.heap.length;
}
}
const h = new MinHeap();
h.insert(3);
h.insert(2);
h.insert(1);
h.pop();
重点要了解两个操作:
- 插入insert:将元素插入堆底,然后不断的往上移动,也就是比较当前元素与其父节点的大小,如果小于就与其父节点交换位置
- 删除堆顶pop:pop出堆的最后一个节点,覆盖掉堆的第一个节点,然后将顶部的节点不断的下移,下移的过程就是比较当前节点与左节点或者右节点的大小,如果大于就交换位置

若有收获,就点个赞吧
0 人点赞
