一、引言
1.1 现有的数据存储方式有哪些?
- Java程序存储数据(变量、对象、数组、集合),数据保存在内存中,属于瞬时状态存储。
- 文件(File)存储数据,保存在硬盘上,属于持久状态存储。
1.2 以上存储方式存在哪些缺点?
- 没有数据类型的区分。
- 存储数据量级较小。
- 没有访问安全限制。
- 没有备份、恢复机制。
二、数据库基本知识
2.1 为什么需要数据库?
数据库的出现,很好的解决了数据的存储效率和读取效率。
存储成一个文件,不大方便操作,也不大方便共享。
2.2 概念
数据库是“按照数据结构来组织、存储和管理数据的仓库。是一个长期存储在计算机内的、有组织的、有共享的、统一管理的数据集合。
2.2.1什么是数据库
数据库就是存储数据的仓库。为了方便数据的存储和管理,将数据按照特定的规则存储在磁盘上。通过数据管理系统,有效的组织和管理存储在数据库中的数据。
数据库(DATABASE)是按照数据结构来组织、存储和管理数据的仓库(通常是一个文件或一组文件)。
理解数据库的一种简单方法就是将其想象成一个文件柜,此文件柜是一个存储存放数据的位置。
注意:有些人通常使用数据库这个术语来代表他们使用的数据库软件,这是不正确的。确切的说,数据库软件对应DBMS(数据库管理系统)。数据库是通过DBMS操纵的容器。我们不直接访问数据库,我们使用的是DBMS,它替我们访问数据库。
2.2.2什么是数据库系统
数据库系统和数据库不是一个概念,数据库系统DBS比数据库大很多,由数据库,数据库管理系统,应用开发工具构成。
数据库,数据表,表的结构。。
DB:是指datebase(数据库)
数据库是存储数据的一个集合,数据库中通常使用数据表等组成,而数据表是由数据的字段和数据的值等信息组成。
DBMS:是指datebase mangement systerm(数据库管理系统)
它是操作数据库和管理数据库的一个系统,比如mysql、sqlserver等都是属于数据库管理软件,人们通过这些系统或者工具来管理数据库内的数据。
DBS:是指datebase systerm (数据库系统)
数据库系统由数据库和数据库管理软件等组成,数据库是一个逻辑上的存储数据的概念,而对应的是实体是数据库管理软件存储在硬盘上的数据库,所以数据库系统包含数据库和数据库管理软件。
比较一下DB,DBMS,DBS
2.3 数据库的分类
- 网状结构数据库:美国通用电气公司IDS(Integrated Data Store),以节点形式存储和访问。
- 层次结构数据库:IBM公司IMS(Information Management System)定向有序的树状结构实现存储和访问。
- 关系结构数据库:Oracle、DB2、MySQL、SQL Server,以表格(Table)存储,多表间建立关联关系,通过分类、合并、连接、选取等运算实现访问。
- 非关系型数据库:ElastecSearch、MongoDB、Redis,多数使用哈希表,表中以键值(key-value)的方式实现特定的键和一个指针指向的特定数据。
2.4关系型数据库的介绍
关系型数据库模型是吧复杂的数据结构归结为简单的二元关系(即二维表格形式)
在关系型数据库中,对数据的操作几乎全部建立在一个或多个关系的表格上,通过对这些关联的表格分裂、合并、连接或选取等运算来实现数据库的管理。
Oracle在数据库领域上升到了霸主地位
MySQL数据库在中小企业和免费市场具有绝对地位
关系型数据库的几个概念:
表:
表(table)是数据库存储数据的基本单位。
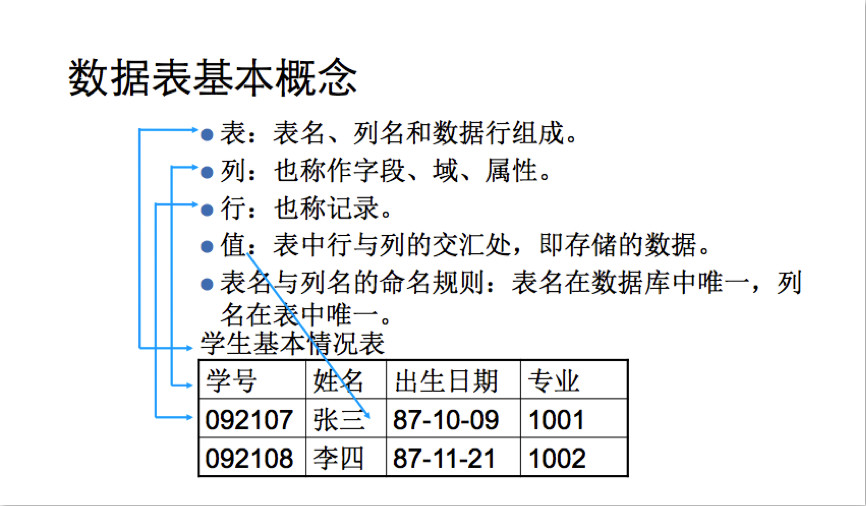
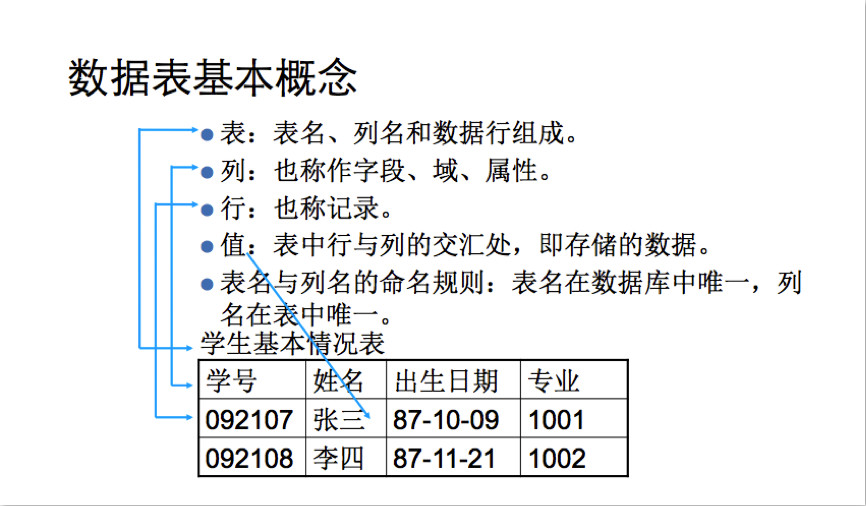
列:
列(column)表中的一个字段。所有的表都是由一个或多个列组成
数据类型:
数据类型(datatype)每个列都有相应的数据类型,用来限制该列存储的数据。
行:
行(row)表中的一个(行)记录
表中的数据是按行存储的,所保存的每个记录存储在自己的行内,如果将表想象成网格,网格中垂直的列为表列,水平行为表行
主键:
主键(primary key)一列或一组列,其值能够唯一区分表中的每一行。
表中每一行都应该可以唯一标识自己的一列。一个顾客表可以使用顾客编号,而订单表可以使用订单ID。一个表中没有主键的话,更新或删除特定行的话很困难,因为没有相关的方法保证只涉及相关的行。
主键的规则 表中的任何列都可以作为主键,只要它满足以下条件:
- 任何两行都不具有相同的主键值(每一行的主键值唯一)
- 每个行都必须具有主键值(主键值不允许null)
主键的好习惯除了强制的规则外,应该坚持的几个普遍认可的好习惯:
- 不更新主键列中的值
- 不重用主键列的值
- 不在主键列中使用可能更改的值
三、MySQL
3.1 简介
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS(Relational Database Management System,关系数据库管理系统) 应用软件之一。
下载mysql
使用百度云下载
下面是百度云的链接,下载好mysql-installer-community-5.7.21.0.msi
链接:https://pan.baidu.com/s/17h_K4xP-vecDonpSZFLanw
提取码:alpa
官方下载
官方网站:https://www.mysql.com/ 下载地址:https://dev.mysql.com/downloads/mysql/

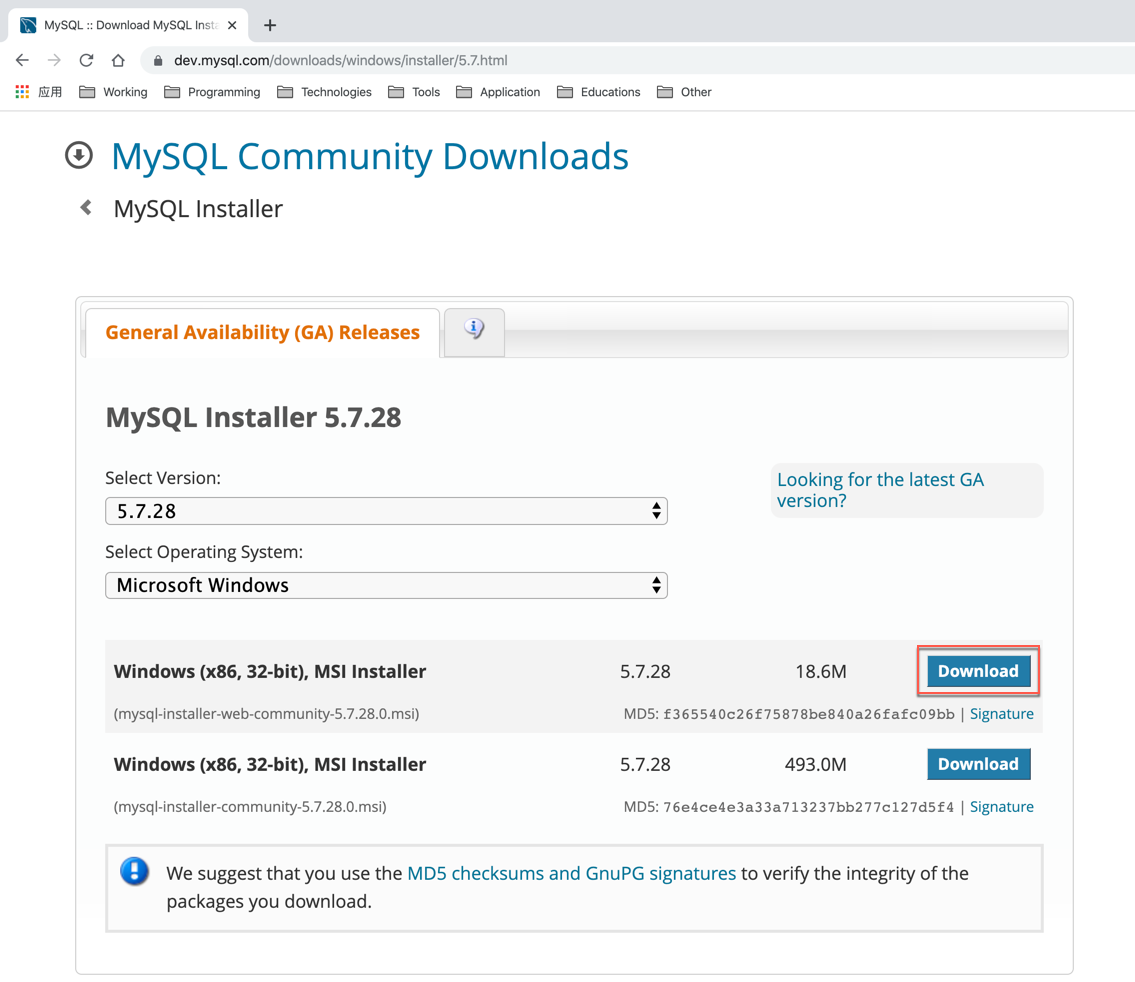
3.2 Mysql的安装 (网上很多就不提供了)
3.3 登录
方式一:DOS窗口:输入以下命令:
C:\Users\ruby>mysql -u root -p回车后输入密码即可
使用百度云下载 Navicat Premium 12
下面是百度云的链接,下载好Navicat Premium 12
链接:https://pan.baidu.com/s/17h_K4xP-vecDonpSZFLanw
提取码:alpa

1、安装navicat120_premium_cs_x64.exe (使用默认路径,便于后面破解)
2、打开注册机Navicat_Keygen_Patch_v3.4_By_DFoX_URET.exe

3、按文档Navicat Premium 12激活步骤.txt 破解
正常使用的界面如下
3.4 创建数据库:
1.创建数据库:
//create database [if not exists]数据库名 [default charset utf8 collate utf8_general_ci];
create database cundao character set utf8;
Query OK, 1 row affected (0.00 sec)
1.数据库名不要使用中文,
由于数据库将来存储一些非ascii码的字符,所以务必指定字符编码,一般都是指定utf-8编码
charset指定utf8
COLLATE 指定utf8_general_ci
mysql中文字符集是utf8,不是utf-8
2.显示有哪些数据库:
show databases;
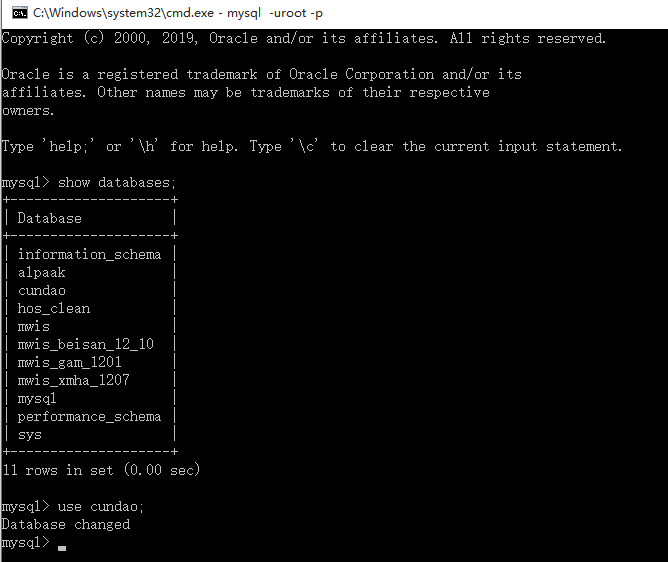
3.切换到数据库:以后的操作都是针对该数据库的,比如建表。。
use cundao;
4 显示所有表
mysql> show tables;

5.删除数据库: (线上的数据库别这样玩)
drop database if exists cundao;
3.5 数据类型
MySQL支持多种类型,大致可以分为三类
- 数值:常用的是int(整数)和decimal(浮点数)
- 日期/时间:最常用的是datetime
- 字符串(字符):最常用的是char,varchar和text
char(10)—>定长的字符串,查找速度更快一些
“hello “
“abc “
varchar(10)—>变长,节省空间
“hello”
“abc”
总结常用的类型:
int :整型; double:浮点型,例如double(5,2)表示最多5位,其中必须有2位小数,即最大值:999.99 decimal:浮点型,不会出现精度缺失问题,比如金钱 char:固定长度字符串类型,最大长度:char(255) varchar:可变长度字符串类型,最大长度:varchar(65535) text(clob):字符串类型,存储超大文本 blob:字节类型,最大4G date:日期类型;格式:yyyy-MM-dd time:时间类型;格式:hh:mm:ss timestamp:时间戳 datetime:
3.6 数据表的操作
1.创建数据库:
create database if not exists cundao default charset utf8 collate utf8_general_ci;
2.创建数据表:
创建表语法:
CREATE TABLE [IF NOT EXISTS]表名(
列名 列类型(长度) 约束 默认值,
列名 列类型(长度) 约束 默认值,
...
);
注意:
- 字段使用NOT NULL,是因为我们不希望这个字段的值为NULL。因此,如果用户尝试创建具有NULL值的记录,那么MYSQL会产生错误
- 字段的AUTO_INCREMENT属性告诉MySQL自动增加id字段下一个可以用的编号。
- DEFAULT 设置默认值
- 关键字primary key 用于定义此列作为主键。
3.查看表结构:desc—>describecreate table users( id int(4) primary key auto_increment, username varchar(20) , pwd varchar(30) );desc users;
4.显示检表语句:show create table users;总结:
1.先创建数据库
mysql:
database1—>oa
database2—>bluebird
。。。。2.切换数据库,
use 数据库名3.创建数据表
CREATE TABLE `student` ( `no` int(11) NOT NULL, `name` varchar(32) DEFAULT NULL, `age` int(11) DEFAULT NULL, `sex` char(0) DEFAULT NULL, `birthday` datetime DEFAULT NULL, PRIMARY KEY (`no`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;4.插入多条数据:
insert into users(id,username,pwd) values(1,'admin','123456'); INSERT INTO `cundao`.`student`(`no`, `name`, `age`, `sex`, `birthday`) VALUES (1001, '王二狗', 18, '女', '2007-10-10 00:00:00'); INSERT INTO `cundao`.`student`(`no`, `name`, `age`, `sex`, `birthday`) VALUES (1002, 'rose', 19, '女', '2007-10-10 00:00:00'); INSERT INTO `cundao`.`student`(`no`, `name`, `age`, `sex`, `birthday`) VALUES (1003, 'jack', 20, '男', '2007-10-10 00:00:00'); INSERT INTO `cundao`.`student`(`no`, `name`, `age`, `sex`, `birthday`) VALUES (1004, '张三', 18, '男', '2007-10-10 00:00:00'); INSERT INTO `cundao`.`student`(`no`, `name`, `age`, `sex`, `birthday`) VALUES (1005, '李四', 20, '男', '2007-10-10 00:00:00'); INSERT INTO `cundao`.`student`(`no`, `name`, `age`, `sex`, `birthday`) VALUES (1006, '麻雷子', 21, '男', '2007-10-10 00:00:00');5.查询数据:
select * from users;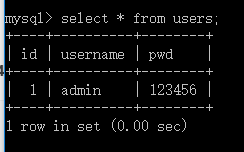
3.7 修改表结构
alter table 表名 xxx。。。1 添加字段:add
alter table users add( age int(4), birthday date );
2 修改已有字段的数据类型:modify
alter table users modify age float(4,1);
注意点:并不能随意的更改已有列的数据类型。尤其是表中已经有数据了
A:兼容类型:长度可以从小到大,不能已有的数据越界。
B:不兼容类型:varchar—>int,更改失败。
以下报错
alter tables users modify name int;
3.删除某列:drop
alter table users drop birthday;

4.删除表:drop table
drop table users;
3.8 插入数据
1.插入数据:
insert into 表名(列1,列2,列3.。。) values(值1,值2,值3.。。)
全列插入:如果有所有列都要插入数据,那么可以省略列的名字
对自动增长的数据,在全列插入的时候需要占位处理,一般使用0来占位,但是最终的值以实际为准;
缺省插入:如果有某一个或一些字段没有数值,那么就要写清楚列名和值。
插入的时候,not null和primary key的列必须赋值,其他的列根据情况来赋值,如果没有赋值则会使用默认值
同时插入多行:
insert into 表名(列1,列2,列3.。。) values(值1,值2,值3.。。),(值1,值2,值3.。。),....;
3.9 修改数据
语法结构:
update 表名 set 列1=值1,列2=值2...[where 条件];
1、条件必须是boolean类型的值或表达式;
表达示如下
运算符:
=,数值相等
!=,<>,数值不等
between ... and,区间
>
<
>=
<=
or
and
in(值1,值2,值3.。)
is null
is not null
2、 is null不是=null,=null永远是false
SELECT * from users WHERE age=null;
1.修改学号为1006的同学姓名为张雷子
mysql> update student set name='麻雷子' where no=1006;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from student;
+------+--------+------+------+------------+
| no | name | age | sex | birthday |
+------+--------+------+------+------------+
| 1001 | 王二狗 | 18 | 男 | 2007-10-10 |
| 1002 | rose | 19 | 女 | 2006-09-09 |
| 1003 | jack | 20 | 男 | 2005-08-06 |
| 1004 | 张三 | 18 | 女 | 1990-12-12 |
| 1005 | 李四 | 21 | 男 | 1991-06-08 |
| 1006 | 麻雷子 | 22 | 男 | 1992-10-10 |
+------+--------+------+------+------------+
6 rows in set (0.00 sec)
2.年龄小于19岁的同学,性别改为女
mysql> update student set sex='女' where age < 19;
Query OK, 1 row affected (0.01 sec)
Rows matched: 2 Changed: 1 Warnings: 0
mysql> select * from student;
+------+--------+------+------+------------+
| no | name | age | sex | birthday |
+------+--------+------+------+------------+
| 1001 | 王二狗 | 18 | 女 | 2007-10-10 |
| 1002 | rose | 19 | 女 | 2006-09-09 |
| 1003 | jack | 20 | 男 | 2005-08-06 |
| 1004 | 张三 | 18 | 女 | 1990-12-12 |
| 1005 | 李四 | 21 | 男 | 1991-06-08 |
| 1006 | 麻雷子 | 22 | 男 | 1992-10-10 |
+------+--------+------+------+------------+
6 rows in set (0.01 sec)
3.年龄大于等于18岁,并且小于等于19岁的同学姓名改为马冬梅
mysql> update student set name='马冬梅' where age >= 18 and age <= 19;
Query OK, 3 rows affected (0.01 sec)
Rows matched: 3 Changed: 3 Warnings: 0
mysql> select *from student;
+------+--------+------+------+------------+
| no | name | age | sex | birthday |
+------+--------+------+------+------------+
| 1001 | 马冬梅 | 18 | 女 | 2007-10-10 |
| 1002 | 马冬梅 | 19 | 女 | 2006-09-09 |
| 1003 | jack | 20 | 男 | 2005-08-06 |
| 1004 | 马冬梅 | 18 | 女 | 1990-12-12 |
| 1005 | 李四 | 21 | 男 | 1991-06-08 |
| 1006 | 麻雷子 | 22 | 男 | 1992-10-10 |
+------+--------+------+------+------------+
6 rows in set (0.00 sec)
4.修改年龄19到20岁之间的同学姓名为马春梅:
mysql> update student set name=’马春梅’ where age between 19 and 20;
2
Query OK, 2 rows affected (0.01 sec)
3
Rows matched: 2 Changed: 2 Warnings: 0
4
5
mysql> select * from student;
6
+———+————+———+———+——————+
7
| no | name | age | sex | birthday |
8
+———+————+———+———+——————+
9
| 1001 | 马冬梅 | 18 | 女 | 2007-10-10 |
10
| 1002 | 马春梅 | 19 | 女 | 2006-09-09 |
11
| 1003 | 马春梅 | 20 | 男 | 2005-08-06 |
12
| 1004 | 马冬梅 | 18 | 女 | 1990-12-12 |
13
| 1005 | 李四 | 21 | 男 | 1991-06-08 |
14
| 1006 | 麻雷子 | 22 | 男 | 1992-10-10 |
15
+———+————+———+———+——————+
16
6 rows in set (0.00 sec)
3.10删除数据
语法结构:
SQL
复制代码
1
delete from 表名[where 条件]
SQL
复制代码
1
mysql> delete from student2 where no=1001 or no=1002;
2
Query OK, 2 rows affected (0.14 sec)
四、SQL
什么是SQL
结构化查询语言(Structured Query Language)简称SQL(发音:/ˈes kjuː ˈel/ “S-Q-L”),是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;同时也是数据库脚本文件的扩展名
操作数据库需要使用SQL语句,而并非Java
SQL标准:SQL99即99年制定的标准
(1)操作所有关系型数据库的规则; (2)是第4代语言 (3)是一种结构化的查询语言 (4)只需发出合理合法的语句,就有结果显示
注意:不同的DBMS(mysql,oracle)不会只支持SQL99,还会有自己的一些独有的语法,比如limit只在mysql中可以使用。
SQL语法
1,SQL语句可以在单行或多行书写,以分号结尾,
有些时候可以不用分号结尾,比如在代码中。
2,可以使用空格或缩进来增强语句的可读性
3,SQL不区分大小写,建议大写。
结构化查询语言(Structured Query Language)。操作数据库的。
SQL99标准的四大分类
DDL语言:数据定义语言(用于定义数据的表结构)Data Definition Language
创建数据表:create table 表名
修改数据表:alter table 表名
删除数据表:drop table 表名
DML语言:数据操纵语言(用于操作数据表中的数据)DML - Data Mainpulation Language
添加数据:insert
修改数据:update
删除数据:delete
DQL语言:数据查询语言(专门用于数据的查询)DQL - Data Query Language
查询数据:select
DCL语言:数据控制语言(Data Control Language)
grant 权限 to scott, remove 权限 from scott
五、约束
约束:用于限制数据表中某列的数据的存储内容。
默认值:default
非空约束:not null
唯一约束:unique
主键约束:primary key
外键约束:foreign key
主键约束:非空+唯一
用作这个表中,主键所在的字段是该表的唯一标识。一个表中最多只能有一个主键约束。
语法:
create table stu(
sid int primary key auto_increment,#定义sid作为stu表的主键
sname vachar(20),
age int,
gender varchar(10)
);
或者
create table stu(
sid int auto_increment,
sname varchar(20),
age int,
gender varchar(10),
[constraint [sid_pk]] primary key (sid) #指明sid作为stu的主键
)
删除主键
alter table stu drop primary key;
添加主键
alter table stu add primary key(sid);
主键自增:auto_increment
要求该字段数值不允许为空,而且数值唯一。所以我们通常会指定主键类型为整型,然后设置其自动增长,这样可以保证在插入数据的时候主键列的唯一和非空特性。
外键约束:保证数据的完整性和有效性。
两张表:
父表:主表
主键
子表:从表
外键
演示外键约束
子表中设置外键的列,是父表中主键。那么子表中外键的列,的数值,就会受到父表中主键的数值的约束。
外键设置语法:
references 父表(主表)
constraint classno_FK foreign key (classno) references class(classno)
或者:
alter table student add constraint stu_classno foreign key (classno) references class(classno);
创建父表:
mysql> create table class(
-> classno int(4) primary key,
-> classname varchar(20));
insert into class(classno,classname) values (1,'java'),(2,'python'),(3,'html5');
创建子表:
mysql> create table student(
-> sid int(4) primary key auto_increment,
-> sname varchar(30),
-> age int(3),
-> sex varchar(3),
-> classno int(4),
-> constraint fk_stu foreign key (classno) references class(classno));
insert into student(sid,sname,age,classno) values (1,'张三',20,1),(2,'李四',34,2),(3,'张五',32,3);
添加数据:
父表:1,2,3
子表:classno:受到父表的限制
六、查询
用户对于数据表或视图最常用的操作就是查询,也叫检索。通过select 语句来实现。
语法:
select {columns}
from {table|view|other select}
[where 条件]
[group by 分组条件]
[having 分组后再限定]
[order by 排序]
准备环境:下载sql后执行
简单查询
1.查询指定的列:
select 列1,列2,列3.。。 from 表名
select empno,ename,hiredate from emp;
2.起别名:as 可以省略不写
select 列1 as 别名 from 表名
select empno as 员工编号,ename '员工 姓名' from emp;
3.字符串类型可以做连续运算
concat(“我的名字是”,name,’我今年。。。’);
select concat('我的名字是',ename,',喔喔') from emp;
4.去重:distinct
select distinct job from emp;
select distinct job,deptno from emp;
distinct 列名1,列名2,一行数据都相同,才会被认为是重复的数据,去除。
条件查询
在检索数据库中的数据时候,需要满足某些条件,才能被检索到,使用where关键字,来限制检索的条件。
比较运算符:=,!=,<>,>,<,>=,<=
逻辑运算符:and ,or, not
范围:between and,in,not in
null:is null,is not null
练习1:查询1981年以后入职的员工信息
select * from emp where hiredate>='1981-1-1';
练习2:查询部门编号为30或者工资大于2000的员工信息。
select ename,sal,deptno from emp where sal>2000 or deptno=30;
练习3:在emp表中,使用in关键字查询职务为”president”,”manager”和”analyst”中任意一种的员工信息。
SELECT * FROM emp WHERE job IN('president','manager','analyst');
模糊查询:like
%:匹配0-多个任意的字符
_:匹配1个任意字符
//名字的第三个字母为a的员工信息
mysql> select * from emp where ename like '__a%';
like ‘_a’;只有两个字符
like ‘%a%’;包含a
like ‘a%’;以a 字母开头的
select * from emp where ename like 'A%';
排序:orderby
asc:升序,默认
desc:降序
select查询完后,排序要写在整个sql语句的最后。
select * from emp order by sal;
select * from emp order by sal desc;
统计函数
也叫聚合函数,通常用于求整个表中某列的数据的:总和,平均值,最大值,最小值。通常不搭配表中的字段一起查询。
sum(),
avg(),
max()
min(),
count(*/主键)
练习1:求部门编号20中员工的平均工资,工资总和,工资最大值,最小值,人数。
SELECT
ename,
sum( sal ),
avg( sal ),
max( sal ),
min( sal ),
count( empno ),
count( comm )
FROM
emp
WHERE
deptno = 20;
分组
group by 列名,按照指定的列进行分组,值相同的会分在一组。
语法:
select 列名 from 表名 group by 列名
或者
select 列名1,列名2 from 表名 group by 列名1,列名2
说明:
- select 后面跟的列名和group by 后的列名一致
- 当group by 单独使用的时候,只显示每组的第一条记录。所以group by单独使用的意义不大,大多要配合聚合函数。
- group by 后面也可以跟多个列进行分组,表示这些列都相同的时候在一组。
按照某列分组,该列有几种取值,就分为几组。
分组后使用聚合函数
select sex,count(*) from stu group by sex;
注意:
- 如果没有分组,那么聚合函数(sum,count,max,min)作用在整张表上
- 如果有分组,组函数作用在分组后的数据上
- 在写select子句中列,如果没有在组函数里,那么一定要group by 后边。
select a,b,sum(c),count(d) from 表 group by a,b
分组后限定查询:having
二次筛选:就是分组后再对数据进行筛选,需要having子句来完成。
select 列名 from 表名 group by 列名 having 条件
having子句和where 子句:都是用于限定条件
对比:
- where 和having后面都是跟条件
- where是对表中数据进行原始筛选
- having是对group by 的结果的二次筛选
- having必须配合group by使用,一般也会跟着聚合函数一起使用
- 可以先有where,后面跟着group by和having
区别和结论:
- 语法上:在having中使用组函数(max,min,avg,count…),而where后不能用组函数。
- 执行上:where是先过滤再分组。having是先分组再过滤。
练习1:按照部门来分组,查询每个部门的最高工资,最低工资,平均工资。
select deptno, max(sal),min(sal),avg(sal) from emp group by deptno;
练习2:求每种工作的最高薪资,最低薪资,以及人数。
select job,max(sal),min(sal),count(empno)
from emp group by job;
练习3:查询部门人数超过5人的部门。
select deptno,count(*) from emp group by deptno having count(*) >5;
分页
limit是mysql特有的。方言。
limit用于限定查询结果的起始行,以及总行数。
select * from 表名 limit start,count;
例如:查询起始行为第5行,一共查询3行
select * from stu limit 4,3;
其中4表示从第5行开始,其中3表示是查询3行。即5,6,7行
select * from emp limit 2,3;
七、多表联查
笛卡尔积
两张表在连接查询的时候,如果没有连接条件,那么会产生笛卡尔积(冗余数据)
select emp.*,dept.* from emp,dept
3.1 内连接
查询出来的数据一定满足链接的规则。
语法:
方言:select * from 表1 别名1,表2 别名2 where 别名1.xx=别名2.xx
标准:select * from 表1 别名1 inner join 表2 别名2 on 别名1.xx=别名2.xx
select e.*,d.* from emp e inner join dept d on e.deptno=d.deptno;
3.2 左外链接
因为内连接的查询结果,并不是所有的数据,而是满足规则的数据。
左外链接,右外连接是为了补充内连接的查询结果的。
左表记录无论是否满足条件都会查询出来,而右表只有满足条件才能查询出来。左表中不满足条件的记录,右表部分都为NULL
语法:
select * from 表1 别名1 left [outer] join 表2 别名2 on 别名1.xx=别名2.xx
select * from emp e left outer join dept d on e.deptno=d.deptno;
select e.ename,e.deptno,d.dname from emp e left outer join dept d on e.deptno=d.deptno;
3.3 右外连接
右表记录无论是否满足条件都会查询出来,而左表只有满足条件才能查询出来。右表中不满足条件的记录,左表部分都为NULL
语法:
select * from 表1 别名1 right [outer] join 表2 别名2 on 别名1.xx=别名2.xx
select * from emp e right outer join dept d on e.deptno=d.deptno;
练习1:查询所有的部门,以及对应的员工信息。
SELECT
e.*, d.*
FROM
emp e
RIGHT JOIN dept d ON e.DEPTNO = d.DEPTNO;
select d.DNAME,d.DEPTNO,e.DEPTNO,e.EMPNO,e.ENAME from dept d left join emp e on d.DEPTNO = e.DEPTNO;
练习2:查询每个员工的员工信息,工资等级。emp,salgrade
SELECT
e.*,s.*
FROM emp e
LEFT JOIN salgrade s
on e.SAL BETWEEN s.LOSAL and s.HISAL
练习3:查询每个员工的员工信息,部门名称,部门位置,工资等级
SELECT
e.*,d.DNAME,d.LOC,s.GRADE
FROM emp e
LEFT JOIN dept d
ON e.DEPTNO = d.DEPTNO
LEFT JOIN salgrade s
on e.SAL BETWEEN s.LOSAL and s.HISAL;
练习4:查询在部门在纽约的员工信息,部门名称,工资等级。
select
e.*,d.dname,d.LOC,s.grade
FROM emp e
left join dept d
on e.deptno = d.deptno
LEFT JOIN salgrade s
on e.sal BETWEEN s.LOSAL and s.hisal
where d.LOC = 'NEW YORK';
练习5:查询每个部门的人数,部门名称,部门编号。
SELECT e.DEPTNO,d.DNAME,count(*) from emp e
LEFT JOIN dept d ON e.DEPTNO = d.DEPTNO
group by e.DEPTNO,d.DNAME;
select t.*,d.DNAME
from (
SELECT e.DEPTNO,count(*) from emp e group by e.DEPTNO
) t
left join dept d
on t.DEPTNO = d.DEPTNO;
八、子查询
子查询:是指sql语句中包含另外一个select 语句。
子查询出现的位置:
from 后,作为表
where 后,作为条件
1,子查询必须在()里
2,在子查询中不能使用order by子句
3,子查询可以再嵌套子查询,最多不能超过255层
子查询:单行子查询,多行子查询
- 单行子查询
子查询的结果是单行数据
在where条件后,需要配合单行运算符:>,<,>=,<=,!=,= - 多行子查询
子查询的结果是多行数据
1.查询比allen工资高的员工信息。
select * from emp where sal > (select sal from emp where ename='allen');
练习1:查询工资不是最高的,也不是最低的员工信息。
select * from emp where sal !=(select max(sal) from emp ) and sal !=(select min(sal) from emp);
练习2:不是销售部的员工信息
dname—->deptno
思路一:
select deptno from dept where dname=’sales’
select * from emp where deptno != (select deptno from dept where dname='sales');
思路二:
select deptno from dept where dname !=’sales’;
select * from emp where deptno in(select deptno from dept where dname !='sales');
练习3:查询员工信息,要求工资高于部门编号为10的中的任意员工即可
思路一:
select min(sal) from emp where deptno=10; //
练习4:查询员工信息,工资大于30部门的所有人
思路一:
select * from emp where sal >(select max(sal) from emp where deptno=30);
练习5:查询本公司工资最高的员工详细信息
select max(sal) from emp;
select * from emp e,dept d
where sal=(select max(sal) from emp) and e.deptno=d.deptno;

若有收获,就点个赞吧
0 人点赞
