Web Monetization
一个用来规范 Web 付费方式的标准草案,大概包含如下内容:
- 支持 ILP(Interledge Protocol 国际账本协议?)的电子钱包
- 付款方、收款方都需要对应的电子钱包账号
- 收款方在 html
<meta>标签里面配置收款信息(payment pointer)
由于暂时没有浏览器实现,付款方需要安装一个 Chrome 插件来完成付费流程,此外由于内容展示/隐藏的逻辑是在前端实现的,目前只能以捐赠形式为主。
参考链接:
- https://coil.com/
- https://www.quirksmode.org/blog/archives/2021/06/lets_talk_about.html
- https://webmonetization.org/docs/getting-started
WebMetal
WebMetal 是 kvark 在 2016 年开始的一次给 Web GPU 编程更新换代的尝试,初衷是立足于苹果的 GPU 编程模型 Metal API,底层采用 Vulkan 实现,通过给 Servo 开发一个 webmetal 组件来验证结果。
这次尝试的初衷是参考 Metal 或者 Vulkan API,在 Web 提供一层比较薄的封装,让 Web 开发者也能够使用相对比较裸的 GPU 编程模型。相比于现行标准 OpenGL、WebGL,Metal 或者 Vulkan 主要的差别在于编程模型更加适合并行任务,能够比较好地平衡 CPU 和 GPU 的负载。
kvark 先后尝试了 WebMetal(参考 Metal)、gfx-hal(参考 Vulkan)、以及 WebGPU(两者的混合),五年时间下来,虽然产出颇丰,但这几个项目的影响仍然有些不及他的预期,并在文章结尾写下:
My advice for the future self is to avoid blindly putting trust elsewhere, be it Khronos groups, or people who I work with. I want to believe that open standards are the best, and still do, but that wish impaired my judgement. Knowing when to trust yourself is a good skill.
参考链接:
npm-audit
npm install 的时候会自动分析依赖树中存在潜在问题的 npm 包,如果某些包有安全隐患,就会提示使用者执行 npm audit 检查相关 npm 包,或者执行 npm audit --fix 直接修复。
但有些时候,这些引发警告的 npm 包可能是某个开发依赖的间接依赖,例如比较常见的正则表达式 DDoS,其实在开发环境这种问题的影响范围是很有限的,因为用户输入是开发者直接控制,即便真的搞坏了,重新配置就行。
有一些建议的改善方案比如使用 npm audit --production 规避开发依赖相关问题引发的警告,再比如想 Vite 现在做的,把依赖全部打进安装包,这样除了下载速度更快、安装内容更加可控,也间接解决了 npm audit 引发无谓提示的问题。
为祖国健康工作五十年
好吧原标题其实还没有这么狠,原标题是《程序员如何工作到 60 岁》,很多建议非常中肯,特别赞同“把程序员当作资产而不是成本”:
我已经 61 岁了。我变老之后,无法和年轻人拼工作时长了。
- 我通常早晨 8 点至 12 点完成一天的编程工作,然后下午回复邮件,审核代码,学点新东西。
- 虽然我老了,但是经验也更丰富了,8-12 点四个小时的产出,其实是我年轻时 2 天的产出。
- 我没有精力和年轻人争辩了。如果他要做一个愚蠢的设计,就随他去吧,反正他有精力,半夜 2 点也可以起来修 bug。
- 对新事物保持开放的心态。我的一些观念和知识有可能是完全错误的。
- 我以前还尝试记快捷键和命令行,现在放弃了,干脆用鼠标了。
- 我有许多同龄人仍然还是程序员,也有不少已经不再是了。有些公司喜欢聘用年轻人,但其他的也会招聘年长的。喜欢招年轻人的公司要么有比较年轻的管理层,或者有一套固定的运作方式而不需要开辟新的领域,因此他们需要很多人力来填满职位,那些没有意识到自己在被占便宜的人力。
- 对自己能力有清醒的认识:我敲的代码并不是最好的,在编程领域要专注在自己的强项上就好了。
- 程序员的工资有天花板。最好的程序员的产出可能是别人的 8 倍,但是他们的工资最多是别人的 3 倍,所以老老实实存钱。交社保,买房子,投资。
- 和我年纪一样大,但是无法继续编程的人,大部分是身体出了问题,所以保持健康很重要。
- 尽量找一个好公司。好公司把程序员当作资产,而不是成本。
个人觉得第六点有些绝对,以语雀团队为例,我们团队的年龄跨度其实很大,而且有大量新的或者跟深层次的疆域想要去开辟,但我们确实相对来说更加需要有着新一代视角的同学加入。套用一位同事的话说,我们欢迎各种意义上(心态、世界观)的年轻人,年龄既不是充分因素,也不是必要条件。
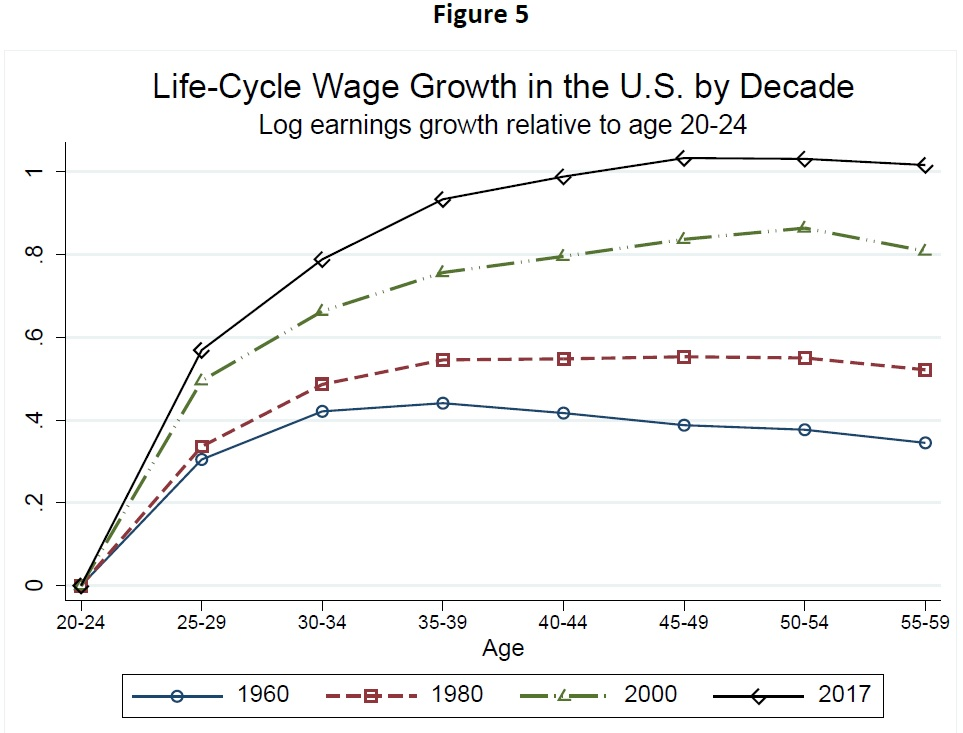
过去几个时期的生命周期薪资变化(除以 20-24 岁时的薪资,log10)
参考链接:
- https://ruby-china.org/topics/41422
- https://conversableeconomist.wpcomstaging.com/2021/07/01/how-wages-over-the-life-cycle-have-change/
进程和线程
Linus的这封邮件(Linux-Kernel Archive: Re: proc fs and shared pids)是我看到的对线程和进程的最好的解释。
On Mon, 5 Aug 1996, Peter P. Eiserloh wrote:
>
> We need to keep a clear the concept of threads. Too many people
> seem to confuse a thread with a process. The following discussion
> does not reflect the current state of linux, but rather is an
> attempt to stay at a high level discussion.NO!
There is NO reason to think that “threads” and “processes” are separate
entities. That’s how it’s traditionally done, but I personally think it’s a
major mistake to think that way. The only reason to think that way is
historical baggage.Both threads and processes are really just one thing: a “context of
execution”. Trying to artificially distinguish different cases is just
self-limiting.A “context of execution”, hereby called COE, is just the conglomerate of
all the state of that COE. That state includes things like CPU state
(registers etc), MMU state (page mappings), permission state (uid, gid)
and various “communication states” (open files, signal handlers etc).Traditionally, the difference between a “thread” and a “process” has been
mainly that a threads has CPU state (+ possibly some other minimal state),
while all the other context comes from the process. However, that’s just
one way of dividing up the total state of the COE, and there is nothing
that says that it’s the right way to do it. Limiting yourself to that kind of
image is just plain stupid.The way Linux thinks about this (and the way I want things to work) is that
there is no such thing as a “process” or a “thread”. There is only the
totality of the COE (called “task” by Linux). Different COE’s can share parts
of their context with each other, and one subset of that sharing is the
traditional “thread”/“process” setup, but that should really be seen as ONLY
a subset (it’s an important subset, but that importance comes not from
design, but from standards: we obviusly want to run standards-conforming
threads programs on top of Linux too).In short: do NOT design around the thread/process way of thinking. The
kernel should be designed around the COE way of thinking, and then the
pthreads library can export the limited pthreads interface to users who
want to use that way of looking at COE’s.Just as an example of what becomes possible when you think COE as opposed
to thread/process:
- You can do a external “cd” program, something that is traditionally
impossible in UNIX and/or process/thread (silly example, but the idea
is that you can have these kinds of “modules” that aren’t limited to
the traditional UNIX/threads setup). Do a:clone(CLONE_VM|CLONE_FS);
child: execve(“external-cd”);
/ the “execve()” will disassociate the VM, so the only reason we
used CLONE_VM was to make the act of cloning faster /
- You can do “vfork()” naturally (it meeds minimal kernel support, but
that support fits the CUA way of thinking perfectly):clone(CLONE_VM);
child: continue to run, eventually execve()
mother: wait for execve
- you can do external “IO deamons”:
clone(CLONE_FILES);
child: open file descriptors etc
mother: use the fd’s the child opened and vv.All of the above work because you aren’t tied to the thread/process way of
thinking. Think of a web server for example, where the CGI scripts are done
as “threads of execution”. You can’t do that with traditional threads,
because traditional threads always have to share the whole address space, so
you’d have to link in everything you ever wanted to do in the web server
itself (a “thread” can’t run another executable).Thinking of this as a “context of execution” problem instead, your tasks can
now chose to execute external programs (= separate the address space from the
parent) etc if they want to, or they can for example share everything with
the parent except for the file descriptors (so that the sub-“threads” can
open lots of files without the parent needing to worry about them: they close
automatically when the sub-“thread” exits, and it doesn’t use up fd’s in the
parent).Think of a threaded “inetd”, for example. You want low overhead fork+exec, so
with the Linux way you can instead of using a “fork()” you write a
multi-threaded inetd where each thread is created with just CLONE_VM (share
address space, but don’t share file descriptors etc). Then the child can
execve if it was a external service (rlogind, for example), or maybe it was
one of the internal inetd services (echo, timeofday) in which case it just
does it’s thing and exits.You can’t do that with “thread”/“process”.
Linus
核心思想是没理由将“线程”和“进程”区分成两个完全不同的实体。传统方式可能确实如此,但 Linus 个人认为这么想是一个误解。线程和进程其实都是同一个东西,“执行上下文(context of execution)”,文中简称 COE。
执行上下文其实是执行环境中的当前状态,这个状态可能包含 CPU 状态(寄存器等等)、MMU 状态(页面映射)、权限状态(uid、gid)、以及各种“通信状态”(打开的文件句柄、信号处理器等等)。
传统意义上,“线程”和“进程”的区别主要在于线程有 CPU 状态(或者还有一些其他的相对小一些的状态),其他的则多来自进程。但是,这只是区分 COE 执行状态的其中一种方式。

若有收获,就点个赞吧
0 人点赞
