服务注册中心本质
本质上是为了解耦服务提供者和服务消费者。对于任何一个微服务,原则上都应存在或者支持多个提供者,这是由微服务的分布式属性决定的。更进一步,为了支持弹性扩缩容特性,一个微服务的提供者的数量和分布每每是动态变化的,也是没法预先肯定的。所以,本来在单体应用阶段经常使用的静态LB机制就再也不适用了,须要引入额外的组件来管理微服务提供者的注册与发现,而这个组件就是服务注册中心。
CAP, ACID
RDBMS (Mysql,Oracle,SQL server) ==》ACID
NoSQL (redis,mongdb) ===》CAP
ACID
是指数据库管理系统(DBMS)在写入或更新资料的过程中,为保证事务(transaction)是正确可靠的,所必须具备的四个特性:原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability)。
CAP
原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
CAP理论
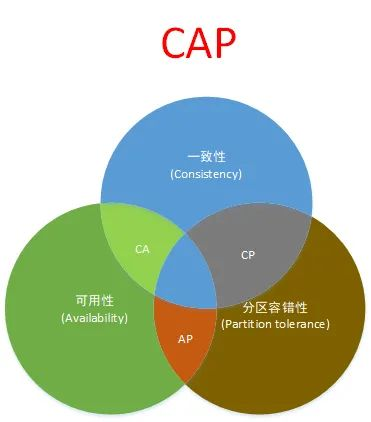
CAP理论是分布式架构中重要理论git
- 一致性(Consistency) (全部节点在同一时间具备相同的数据)
- 可用性(Availability) (保证每一个请求无论成功或者失败都有响应)
- 分隔容忍(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运做)
取舍策略
高可用、数据一致是很多系统设计的目标,但是分区又是不可避免的事情:
CAP三个特性只能满足其中两个,那么取舍的策略就共有三种:
CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但放弃P的同时也就意味着放弃了系统的扩展性,也就是分布式节点受限,没办法部署子节点,这是违背分布式系统设计的初衷的。
CP without A:如果不要求A(可用),相当于每个请求都需要在服务器之间保持强一致,而P(分区)会导致同步时间无限延长(也就是等待数据同步完才能正常访问服务),一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统。设计成CP的系统其实不少,最典型的就是分布式数据库,如Redis、HBase等。对于这些分布式数据库来说,数据的一致性是最基本的要求,因为如果连这个标准都达不到,那么直接采用关系型数据库就好,没必要再浪费资源来部署分布式数据库。
AP wihtout C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。典型的应用就如某米的抢购手机场景,可能前几秒你浏览商品的时候页面提示是有库存的,当你选择完商品准备下单的时候,系统提示你下单失败,商品已售完。这其实就是先在 A(可用性)方面保证系统可以正常的服务,然后在数据的一致性方面做了些牺牲,虽然多少会影响一些用户体验,但也不至于造成用户购物流程的严重阻塞。
[
](https://blog.csdn.net/yeyazhishang/article/details/80758354)
[
](https://blog.csdn.net/chen77716/article/details/30635543)
常用的注册
| Feature | Consul | Zookeeper | Etcd | Eureka | Nacos |
|---|---|---|---|---|---|
| 服务健康检查 | 服务状态,内存,硬盘等 | (弱)长连接,keepalive | 连接心跳 | 可配支持 | 传输层 (PING 或 TCP)和应用层 (如 HTTP、MySQL、用户自定义)的健康检查 |
| 多数据中心 | 支持 | — | — | — | 支持 |
| kv存储服务 | 支持 | 支持 | 支持 | — | 支持 |
| 一致性 | Raft | Paxos | Raft | — | Raft |
| CAP定理 | CP | CP | CP | AP | CP: 配置中心 AP: 注册中心 |
| 使用接口 (多语言能力) |
支持http和dns | 客户端 | http/grpc | http(sidecar) | Nacos 支持基于 DNS 和基于 RPC 的服务发现。服务提供者使用 原生SDK、OpenAPI、或一个独立的Agent |
| watch支持 | 全量/支持long polling | 支持 | 支持 long polling | 支持 long polling/大部分增量 | 支持 long polling/大部分增量 |
| 自身监控 | metrics | — | metrics | metrics | |
| 安全 | acl /https | acl | https支持(弱) | — | acl |
| Spring Cloud集成 | 已支持 | 已支持 | 已支持 | 已支持 | 已支持 |
| 备注 | 可以作为eureka的替代使用 | 2.0不在更新 | 1. 支持dubbo 2. spring-cloud-alibaba支持 |
springcloud中实现的注册中心
- 当项目数量少于1000时, 可以考虑 eureka 1.x ; 2.0版本官方不在维护
2. 使用最新的可以考虑使用 Consul, 使用Raft实现一致性的同时, 尽量保证可用, 支持 k8s
3. 使用dubbo, 可以使用 zookeeper、 nacos, 推荐使用 nacos
4. nacos是阿里来源的集配置中心和注册中心与一体的, 新版本 AP 支持性能良好, 天然支持 dubbo
在 spring-cloud-alibaba 项目中, 很好的实现配置中心和注册中心
支持 k8s、spring 系列、 docker 和 多注册中心的同步
2.0 规划 屏蔽 同步 k8s 和 spring 管理的差异、 支持 istio
5. 新项目可以使用 nacos
Apache Zookeeper -> CP
与 Eureka 有所不一样,Apache Zookeeper 在设计时就紧遵CP原则,即任什么时候候对 Zookeeper 的访问请求能获得一致的数据结果,同时系统对网络分割具有容错性,可是 Zookeeper 不能保证每次服务请求都是可达的。
从 Zookeeper 的实际应用状况来看,在使用 Zookeeper 获取服务列表时,若是此时的 Zookeeper 集群中的 Leader 宕机了,该集群就要进行 Leader 的选举,又或者 Zookeeper 集群中半数以上服务器节点不可用(例若有三个节点,若是节点一检测到节点三挂了 ,节点二也检测到节点三挂了,那这个节点才算是真的挂了),那么将没法处理该请求。因此说,Zookeeper 不能保证服务可用性。
固然,在大多数分布式环境中,尤为是涉及到数据存储的场景,数据一致性应该是首先被保证的,这也是 Zookeeper 设计紧遵CP原则的另外一个缘由。
可是对于服务发现来讲,状况就不太同样了,针对同一个服务,即便注册中心的不一样节点保存的服务提供者信息不尽相同,也并不会形成灾难性的后果。
由于对于服务消费者来讲,能消费才是最重要的,消费者虽然拿到可能不正确的服务实例信息后尝试消费一下,也要赛过由于没法获取实例信息而不去消费,致使系统异常要好(淘宝的双十一,京东的618就是紧遵AP的最好参照)。
当master节点由于网络故障与其余节点失去联系时,剩余节点会从新进行leader选举。问题在于,选举leader的时间太长,30~120s,并且选举期间整个zk集群都是不可用的,这就致使在选举期间注册服务瘫痪。
在云部署环境下, 由于网络问题使得zk集群失去master节点是大几率事件,虽然服务能最终恢复,可是漫长的选举事件致使注册长期不可用是不能容忍的。
Spring Cloud Eureka -> AP
Spring Cloud Netflix 在设计 Eureka 时就紧遵AP原则(尽管如今2.0发布了,可是因为其闭源的缘由 ,可是目前 Ereka 1.x 任然是比较活跃的)。
Eureka Server 也能够运行多个实例来构建集群,解决单点问题,但不一样于 ZooKeeper 的选举 leader 的过程,Eureka Server 采用的是Peer to Peer 对等通讯。这是一种去中心化的架构,无 master/slave 之分,每个 Peer 都是对等的。在这种架构风格中,节点经过彼此互相注册来提升可用性,每一个节点须要添加一个或多个有效的 serviceUrl 指向其余节点。每一个节点均可被视为其余节点的副本。
在集群环境中若是某台 Eureka Server 宕机,Eureka Client 的请求会自动切换到新的 Eureka Server 节点上,当宕机的服务器从新恢复后,Eureka 会再次将其归入到服务器集群管理之中。当节点开始接受客户端请求时,全部的操做都会在节点间进行复制(replicate To Peer)操做,将请求复制到该 Eureka Server 当前所知的其它全部节点中。
当一个新的 Eureka Server 节点启动后,会首先尝试从邻近节点获取全部注册列表信息,并完成初始化。Eureka Server 经过 getEurekaServiceUrls() 方法获取全部的节点,而且会经过心跳契约的方式按期更新。
默认状况下,若是 Eureka Server 在必定时间内没有接收到某个服务实例的心跳(默认周期为30秒),Eureka Server 将会注销该实例(默认为90秒, eureka.instance.lease-expiration-duration-in-seconds 进行自定义配置)。
当 Eureka Server 节点在短期内丢失过多的心跳时,那么这个节点就会进入自我保护模式。
Eureka的集群中,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。除此以外,Eureka还有一种自我保护机制,若是在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现如下几种状况:
- Eureka再也不从注册表中移除由于长时间没有收到心跳而过时的服务;
- Eureka仍然可以接受新服务注册和查询请求,可是不会被同步到其它节点上(即保证当前节点依然可用);
- 当网络稳定时,当前实例新注册的信息会被同步到其它节点中;
所以,Eureka能够很好的应对因网络故障致使部分节点失去联系的状况,而不会像zookeeper那样使得整个注册服务瘫痪。
Consul -> CP
Consul 是 HashiCorp 公司推出的开源工具,用于实现分布式系统的服务发现与配置。Consul 使用 Go 语言编写,所以具备自然可移植性(支持Linux、windows和Mac OS X)。
Consul 内置了服务注册与发现框架、分布一致性协议实现、健康检查、Key/Value 存储、多数据中心方案,再也不须要依赖其余工具(好比 ZooKeeper 等),使用起来也较为简单。
Consul 遵循CAP原理中的CP原则,保证了强一致性和分区容错性,且使用的是Raft算法,比zookeeper使用的Paxos算法更加简单。虽然保证了强一致性,可是可用性就相应降低了,例如服务注册的时间会稍长一些,由于 Consul 的 raft 协议要求必须过半数的节点都写入成功才认为注册成功 ;在leader挂掉了以后,从新选举出leader以前会致使Consul 服务不可用。
Consul本质上属于应用外的注册方式,但能够经过SDK简化注册流程。而服务发现刚好相反,默认依赖于SDK,但能够经过Consul Template(下文会提到)去除SDK依赖。Consul Template
Consul,默认服务调用者须要依赖Consul SDK来发现服务,这就没法保证对应用的零侵入性。
所幸经过Consul Template,能够定时从Consul集群获取最新的服务提供者列表并刷新LB配置(好比nginx的upstream),这样对于服务调用者而言,只须要配置一个统一的服务调用地址便可。
Consul强一致性(C)带来的是:
- 服务注册相比Eureka会稍慢一些。由于Consul的raft协议要求必须过半数的节点都写入成功才认为注册成功
- Leader挂掉时,从新选举期间整个consul不可用。保证了强一致性但牺牲了可用性。
Eureka保证高可用(A)和最终一致性:
- 服务注册相对要快,由于不须要等注册信息replicate到其余节点,也不保证注册信息是否replicate成功
- 当数据出现不一致时,虽然A, B上的注册信息不彻底相同,但每一个Eureka节点依然可以正常对外提供服务,这会出现查询服务信息时若是请求A查不到,但请求B就能查到。如此保证了可用性但牺牲了一致性。
其余方面,eureka就是个servlet程序,跑在servlet容器中; Consul则是go编写而成。
Nacos -> AP/CP
Nacos是阿里开源的,Nacos 支持基于 DNS 和基于 RPC 的服务发现。在Spring Cloud中使用Nacos,只须要先下载 Nacos 并启动 Nacos server,Nacos只须要简单的配置就能够完成服务的注册发现。
Nacos除了服务的注册发现以外,还支持动态配置服务。动态配置服务可让您以中心化、外部化和动态化的方式管理全部环境的应用配置和服务配置。动态配置消除了配置变动时从新部署应用和服务的须要,让配置管理变得更加高效和敏捷。配置中心化管理让实现无状态服务变得更简单,让服务按需弹性扩展变得更容易。
一句话归纳就是Nacos = Spring Cloud注册中心 + Spring Cloud配置中心。
ETCD -> AP
etcd 是云原生架构中重要的基础组件,由 CNCF 孵化托管。etcd 在微服务和 Kubernates 集群中不仅可以作为服务注册于发现,还可以作为 key-value 存储的中间件。
http server:用于处理用户发送的API请求及其他etcd节点的同步与心跳信息请求
store:用于处理etcd支持的各类功能的事务,包括:数据索引、节点状态变更、监控与反馈、事件处理与执行等等,是etcd对用户提供大多数API功能的具体实现
raft:强一致性算法,是etcd的核心
wal(write ahead log):预写式日志,是etcd的数据存储方式。除了在内存中存有所有数据的状态及节点的索引外,还通过wal进行持久化存储。
- 在wal中,所有的数据提交前都会事先记录日志
- entry是存储的具体日志内容
- snapshot是为了防止数据过多而进行的状态快照
ETCD是一个高可用的分布式键值数据库,可用于共享配置、服务的注册和发现。ETCD采用Raft一致性算法,基于Go语言实现。ETCD作为后起之秀,又非常大的优势。
- 1、基于HTTP+JSON的API,使用简单;
- 2、可选SSL客户认证机制,更安全;
- 3、单个实例支持每秒千次写操作,快速。
- 4、采用Raft一致性算法保证分布式。
etcd的特点
etcd的目标是构建一个高可用的分布式键值(key-value)数据库。具有以下特点:
- 简单:安装配置简单,而且提供了 HTTP API 进行交互,使用也很简单
- 键值对存储:将数据存储在分层组织的目录中,如同在标准文件系统中
- 监测变更:监测特定的键或目录以进行更改,并对值的更改做出反应
- 安全:支持 SSL 证书验证
- 快速:根据官方提供的 benchmark 数据,单实例支持每秒 2k+ 读操作
- 可靠:采用 raft 算法,实现分布式系统数据的可用性和一致性
etcd 采用 Go 语言编写,它具有出色的跨平台支持,很小的二进制文件和强大的社区。 etcd 机器之间的通信通过 raft 算法处理。
etcd的功能
etcd 是一个高度一致的分布式键值存储,它提供了一种可靠的方式来存储需要由分布式系统或机器集群访问的数据。它可以优雅地处理网络分区期间的 leader 选举,以应对机器的故障,即使是在 leader 节点发生故障时。
从简单的 Web 应用程序到 Kubernetes 集群,任何复杂的应用程序都可以从 etcd 中读取数据或将数据写入 etcd。
etcd的应用场景
最常用于服务注册与发现,作为集群管理的组件使用
也可以用于K-V存储,作为数据库使用
关于etcd的存储
etcd 是一个键值存储的组件,其他的应用都是基于其键值存储的功能展开。
etcd 的存储有如下特点:
1、采用kv型数据存储,一般情况下比关系型数据库快。
2、支持动态存储(内存)以及静态存储(磁盘)。
3、分布式存储,可集成为多节点集群。
4、存储方式,采用类似目录结构。
- 只有叶子节点才能真正存储数据,相当于文件。
- 叶子节点的父节点一定是目录,目录不能存储数据。
服务注册与发现
分布式系统中最常见的问题之一:在同一个分布式集群中的进程或服务如何才能找到对方并建立连接
服务发现就可以解决此问题。
从本质上说,服务发现就是要了解集群中是否有进程在监听 UDP 或者 TCP 端口,并且通过名字就可以进行查找和链接

若有收获,就点个赞吧
0 人点赞
