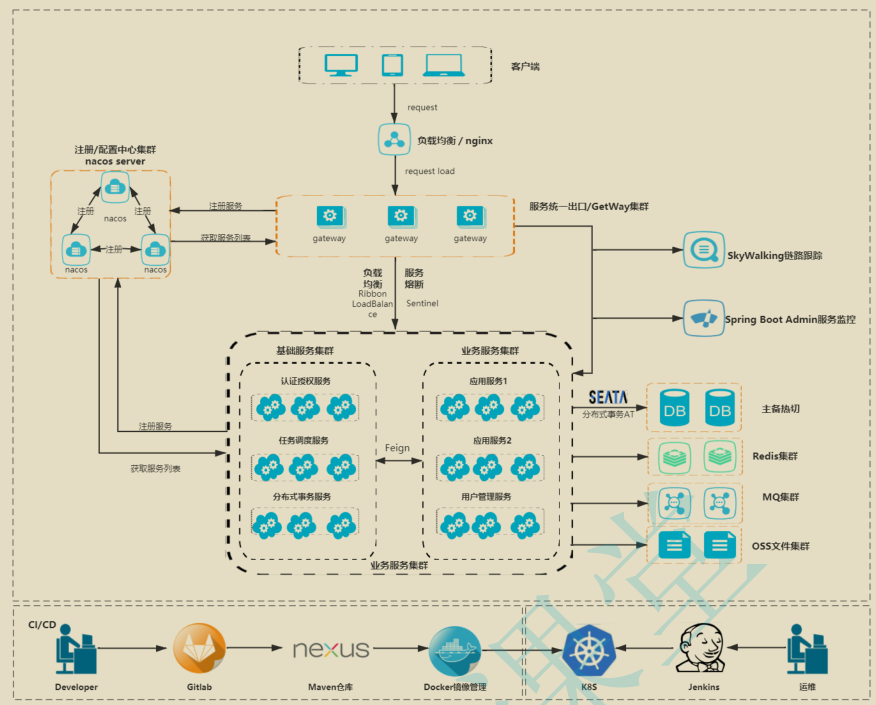
- 微服务介绍
- Nacos
- Nacos 服务注册
- Nacos 配置中心
- Ribbon
- OpenFeign
- Sentienl
- Sentinel 控制台
- Spring Cloud Alibaba 整合 Sentinel
- openfeign 整合 sentinel
- Sentinel持久化模式
- Seata 分布式事务
- 源码分析
- Gateway 网关
- - Path=/order/** # 路径匹配
- nacos config
- Skywalking 分布式任务链
- 性能分析
- Skywalking 集成日志框架
- SkyWalking 告警功能
- Skywalking高可用

代码地址:https://gitee.com/gaibianzlp/springcould-alibaba-example.git
学习视频地址:https://www.bilibili.com/video/BV1JP4y1b7L5?p=63&spm_id_from=pageDriver
https://blog.csdn.net/m0_45234510/article/details/116676530
微服务介绍
概述
Spring Cloud Alibaba 致力于提供微服务开发的一站式解决方案。包含开发分布式应用微服务的必需组件,方便开发者通过 Spring Cloud 编程模型轻松使用这些组件来开发分布式应用服务。
依托 Spring Cloud Alibaba,您只需要添加一些注解和少量配置,就可以将 Spring Cloud 应用接入阿里微服务解决方案,通过阿里中间件来迅速搭建分布式应用系统。
此外,阿里云同时还提供了 Spring Cloud Alibaba 企业版 微服务解决方案,包括无侵入服务治理(全链路灰度,无损上下线,离群实例摘除等),企业级 Nacos 注册配置中心和企业级云原生网关等众多产品。
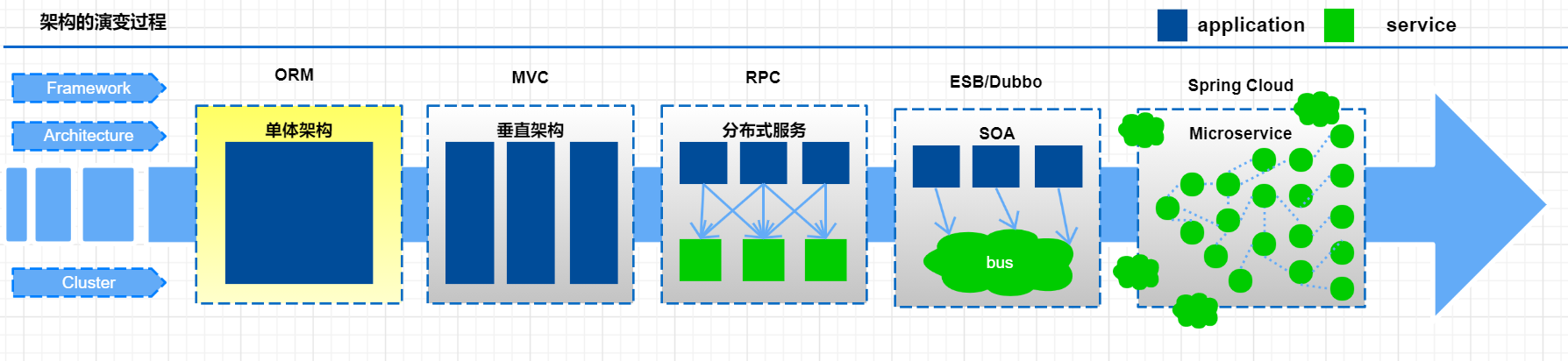
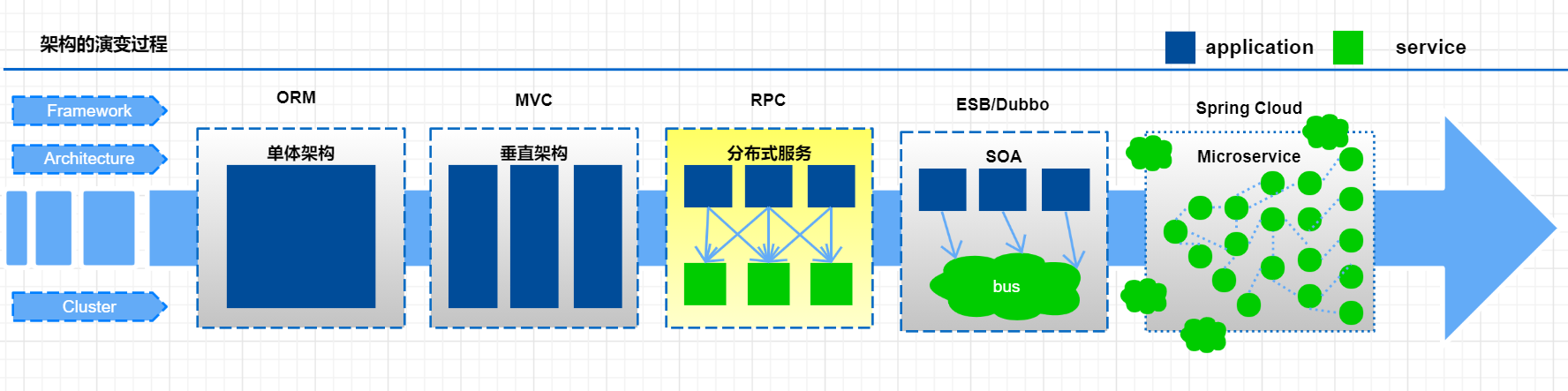
微服务演变过程
随着互联网的发展,网站应用的规模也在不断的扩大,进而导致系统架构也在不断的进行变化。从互联网早起到现在,系统架构大体经历了下面几个过程:
单体应用架构—>垂直应用架构—>分布式架构—>SOA架构—>微服务架构,当然还有悄然兴起Service Mesh(服务网格化)。接下来我们就来了解一下每种系统架构是什么样子的, 以及各有什么优缺点。
单体应用架构
互联网早期,一般的网站应用流量较小,只需一个应用,将所有功能代码都部署在一起就可以,这样可以减少开发、部署和维护的成本。比如说一个电商系统,里面会包含很多用户管理,商品管理,订单管理,物流管理等等很多模块,我们会把它们做成一个web项目,然后部署到一台tomcat服务器上。
优点:
- 项目架构简单,小型项目的话, 开发成本低
- 项目部署在一个节点上, 维护方便
缺点:
- 全部功能集成在一个工程中,对于大型项目来讲不易开发和维护
- 项目模块之间紧密耦合,单点容错率低
- 无法针对不同模块进行针对性优化和水平扩展
垂直应用架构
随着访问量的逐渐增大,单一应用只能依靠增加节点来应对,但是这时候会发现并不是所有的模块都会有比较大的访问量.
还是以上面的电商为例子, 用户访问量的增加可能影响的只是用户和订单模块, 但是对消息模块的影响就比较小. 那么此时我们希望只多增加几个订单模块, 而不增加消息模块. 此时单体应用就做不到了, 垂直应用就应运而生了.
所谓的垂直应用架构,就是将原来的一个应用拆成互不相干的几个应用,以提升效率。比如我们可以将上面电商的单体应用拆分成:
- 电商系统(用户管理 商品管理 订单管理)
- 后台系统(用户管理 订单管理 客户管理)
- CMS系统(广告管理 营销管理)
这样拆分完毕之后,一旦用户访问量变大,只需要增加电商系统的节点就可以了,而无需增加后台和CMS的节点。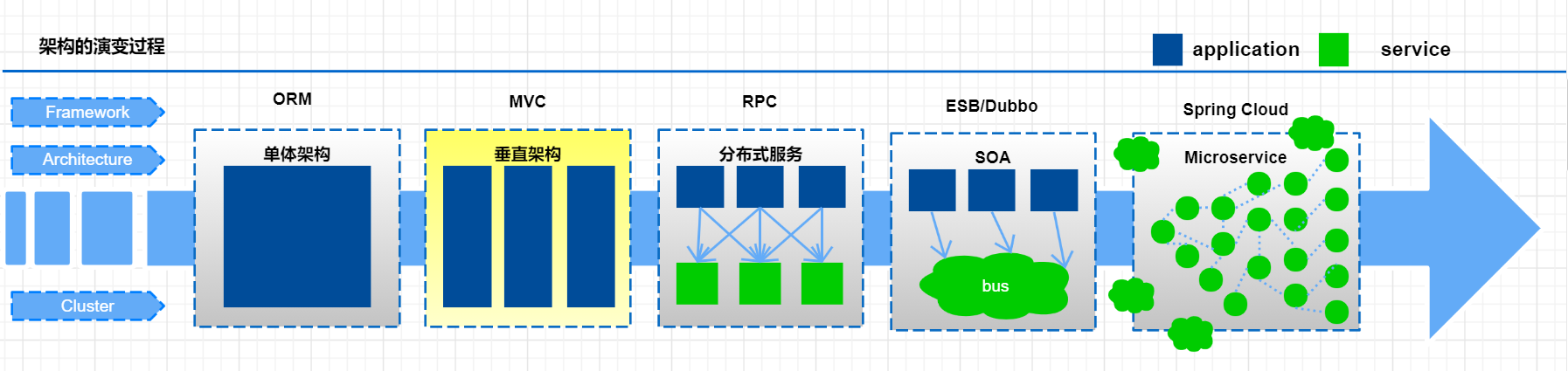 优点:
优点:
- 系统拆分实现了流量分担,解决了并发问题,而且可以针对不同模块进行优化和水扩展
- 一个系统的问题不会影响到其他系统,提高容错率
缺点:
- 系统之间相互独立, 无法进行相互调用
- 系统之间相互独立, 会有重复的开发任务
分布式架构
当垂直应用越来越多,重复的业务代码就会越来越多。这时候,我们就思考可不可以将重复的代码抽取出来,做成统一的业务层作为独立的服务,然后由前端控制层调用不同的业务层服务呢?
这就产生了新的分布式系统架构。它将把工程拆分成表现层和服务层两个部分,服务层中包含业务逻辑。表现层只需要处理和页面的交互,业务逻辑都是调用服务层的服务来实现。
 优点:
优点:
- 抽取公共的功能为服务层,提高代码复用性
缺点:
-
SOA架构
在分布式架构下,当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加
一个调度中心对集群进行实时管理。此时,用于资源调度和治理中心(SOA Service Oriented
Architecture)是关键。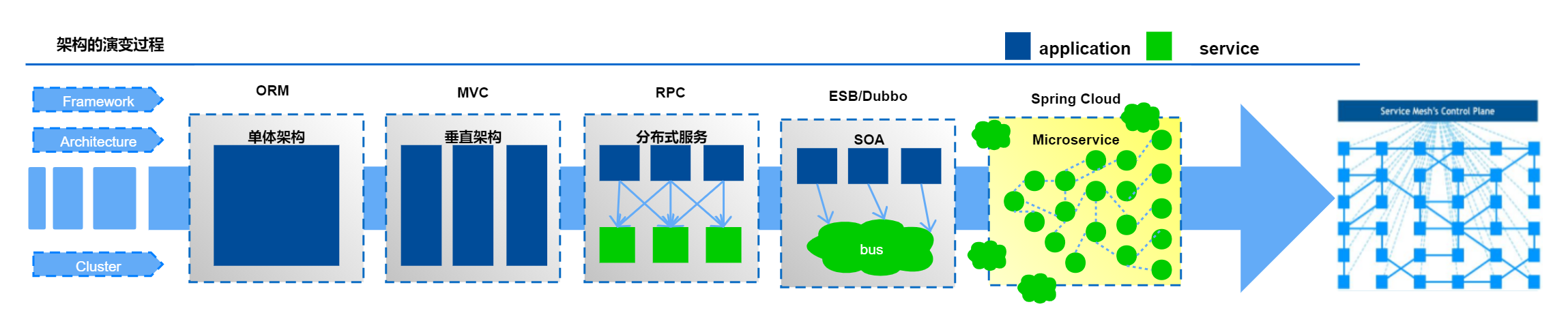
优点: 使用治理中心(ESB\dubbo)解决了服务间调用关系的自动调节
缺点:
- 服务间会有依赖关系,一旦某个环节出错会影响较大( 服务雪崩 )
- 服务关系复杂,运维、测试部署困难
微服务架构
微服务架构在某种程度上是面向服务的架构SOA继续发展的下一步,它更加强调服务的”彻底拆分”。
微服务架构与SOA架构的不同
微服务架构比 SOA架构粒度会更加精细,让专业的人去做专业的事情(专注),目的提高效率,每个服务于服务之间互不影响,微服务架构中,每个服务必须独立部署,微服务架构更加轻巧,轻量级。
SOA 架构中可能数据库存储会发生共享,微服务强调独每个服务都是单独数据库,保证每个服务于服务之间互不影响。项目体现特征微服务架构比 SOA 架构更加适合与互联网公司敏捷开发、快速迭代版本,因为粒度非常精细。
优点:
- 服务原子化拆分,独立打包、部署和升级,保证每个微服务清晰的任务划分,利于扩展
- 微服务之间采用Restful等轻量级http协议相互调用
缺点:
- 分布式系统开发的技术成本高(容错、分布式事务等)
- 复杂性更高。各个微服务进行分布式独立部署,当进行模块调用的时候,分布式将会变得更加麻烦。
微服务架构介绍
①:英文:https://martinfowler.com/articles/microservices.html
②: 中文:http://blog.cuicc.com/blog/2015/07/22/microservices
微服务其实是一种架构风格 ,我们在开发一个应用的时候这个应用应该是由一组小型服务组成,每个小型服务都运行在自己的进程内;小服务之间通过HTTP的方式进行互联互通。
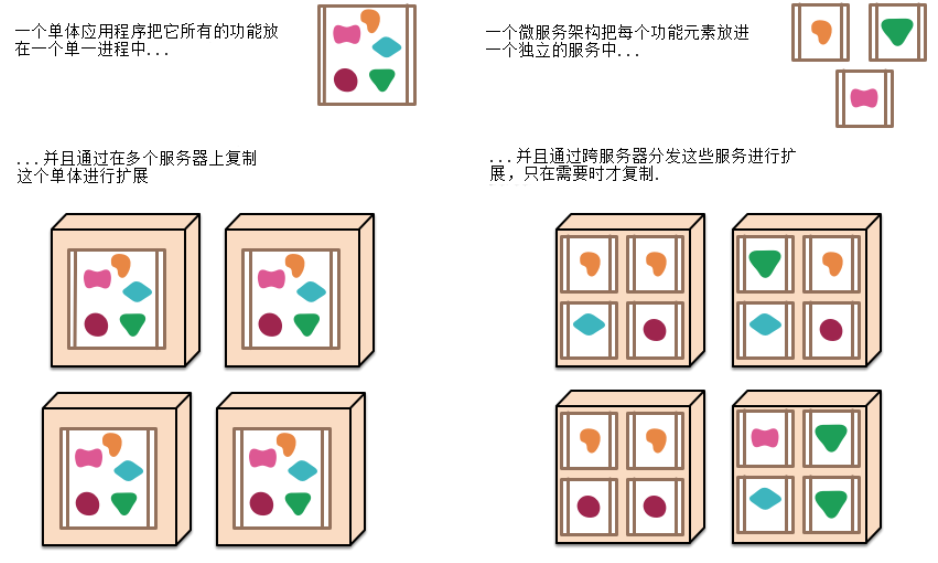
微服务架构的常见问题
一旦采用微服务系统架构,就势必会遇到这样几个问题:
- 这么多小服务,如何管理他们?(服务治理 注册中心[服务注册 发现 剔除]) nacos
- 这么多小服务,他们之间如何通讯?(restful rpc dubbo feign) httpclient(“url”,参数), springBootrestTemplate(“url”,参数) ,, feign
- 这么多小服务,客户端怎么访问他们?(网关) gateway
- 这么多小服务,一旦出现问题了,应该如何自处理?(容错) sentinel
- 这么多小服务,一旦出现问题了,应该如何排错? (链路追踪) skywalking
4个9 52.6分钟 5个9 5分钟
对于上面的问题,是任何一个微服务设计者都不能绕过去的,因此大部分的微服务产品都针对每一
个问题提供了相应的组件来解决它们。
常见微服务架构
dubbo: zookeeper +dubbo + SpringMVC/SpringBoot
- 配套 通信方式:rpc
- 注册中心:zookeeper / redis
- 配置中心:diamond
SpringCloud:全家桶+轻松嵌入第三方组件(Netflix)
- 配套 通信方式:http restful
- 注册中心:eruka / consul
- 配置中心:config
- 断 路 器:hystrix
- 网关:zuul
- 分布式追踪系统:sleuth + zipkin
SpringCloud Alibaba
Spring Cloud 以微服务为核心的分布式系统构建标准
“分布式系统中的常见模式”给了 Spring Cloud 一个清晰的定位,即“模式”。也就是说 Spring Cloud 是针对分布式系统开发所做的通用抽象,
是标准模式的实现。这个定义非常抽象,看完之后并不能知道 Spring Cloud 具体包含什么内容。再来看一下 Spring 官方给出的一个 High Light 的
架构图,就可以对这套模式有更清晰的认识: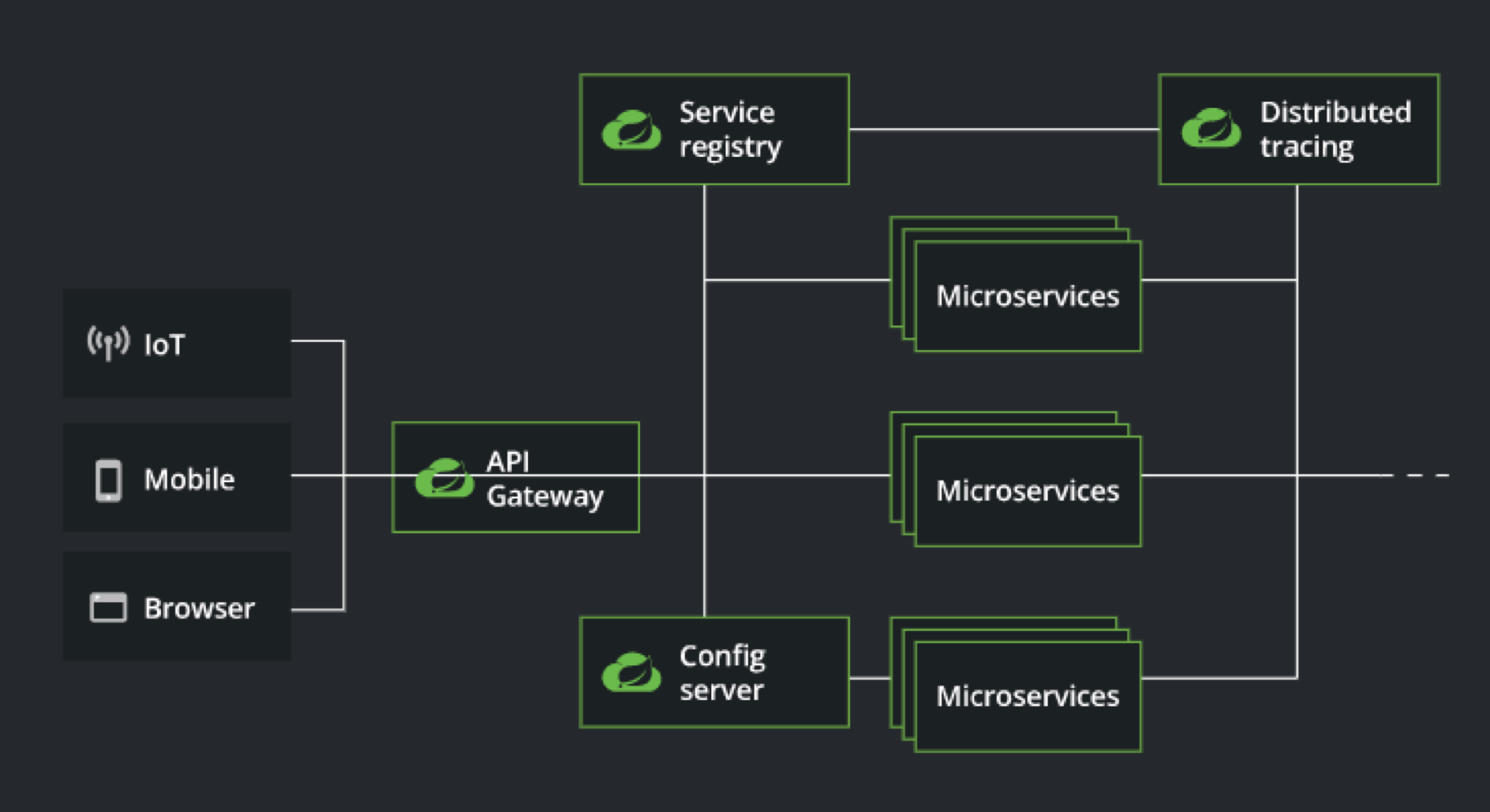 可以看到这个图中间就是各个 Microservice,也就是我们的这个微服务的实现,周边周围的话就是去围绕这个微服务来去做各种辅助的信息事情。
可以看到这个图中间就是各个 Microservice,也就是我们的这个微服务的实现,周边周围的话就是去围绕这个微服务来去做各种辅助的信息事情。
例如分布式追踪、服务注册、配置服务等,都绕微服务运行时所依赖的必不可少的的支持性功能。我们可以得出这样一个结论:Spring Cloud 是以微服务为核心的分布式系统的一个构建标准。
Spring Cloud Alibaba 介绍
Spring Cloud Alibaba 致力于提供微服务开发的一站式解决方案。此项目包含开发微服务架构的必需组件,方便开发者通过 Spring Cloud 编程模型轻松使用这些组件来开发微服务架构。
依托 Spring Cloud Alibaba,您只需要添加一些注解和少量配置,就可以将 Spring Cloud 应用接入阿里分布式应用解决方案,通过阿里中间件来迅速搭建分布式应用系统。
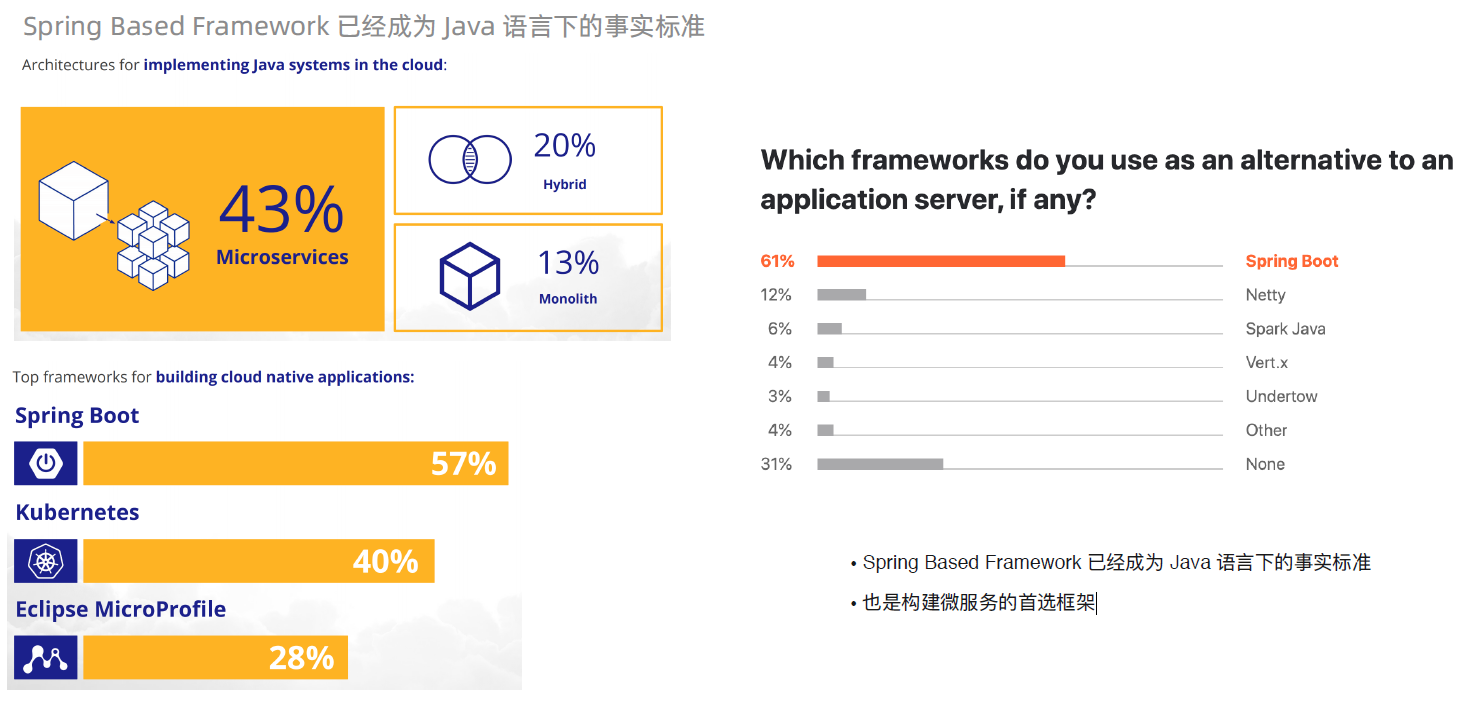
根据 Jakarta 2019 年的调研报告,Spring Boot 拥有非常高的占比。熟悉 Java 语言的同学,应该对 Spring 框架都不会陌生。其倡导的依赖倒置、
面向切面编程等特性已经形成了 Java 语言的事实标准,几乎所有三方框架都会提供对 Spring 框架的支持。
Spring Cloud Alibaba 的定位
既然说 Spring Cloud 是标准,那么自然少不了针对标准的实现。这里,为大家介绍下 Spring Cloud Alibaba 这套实现。先给出下面这张图帮助大
家理解 Spring Cloud Alibaba 的定位: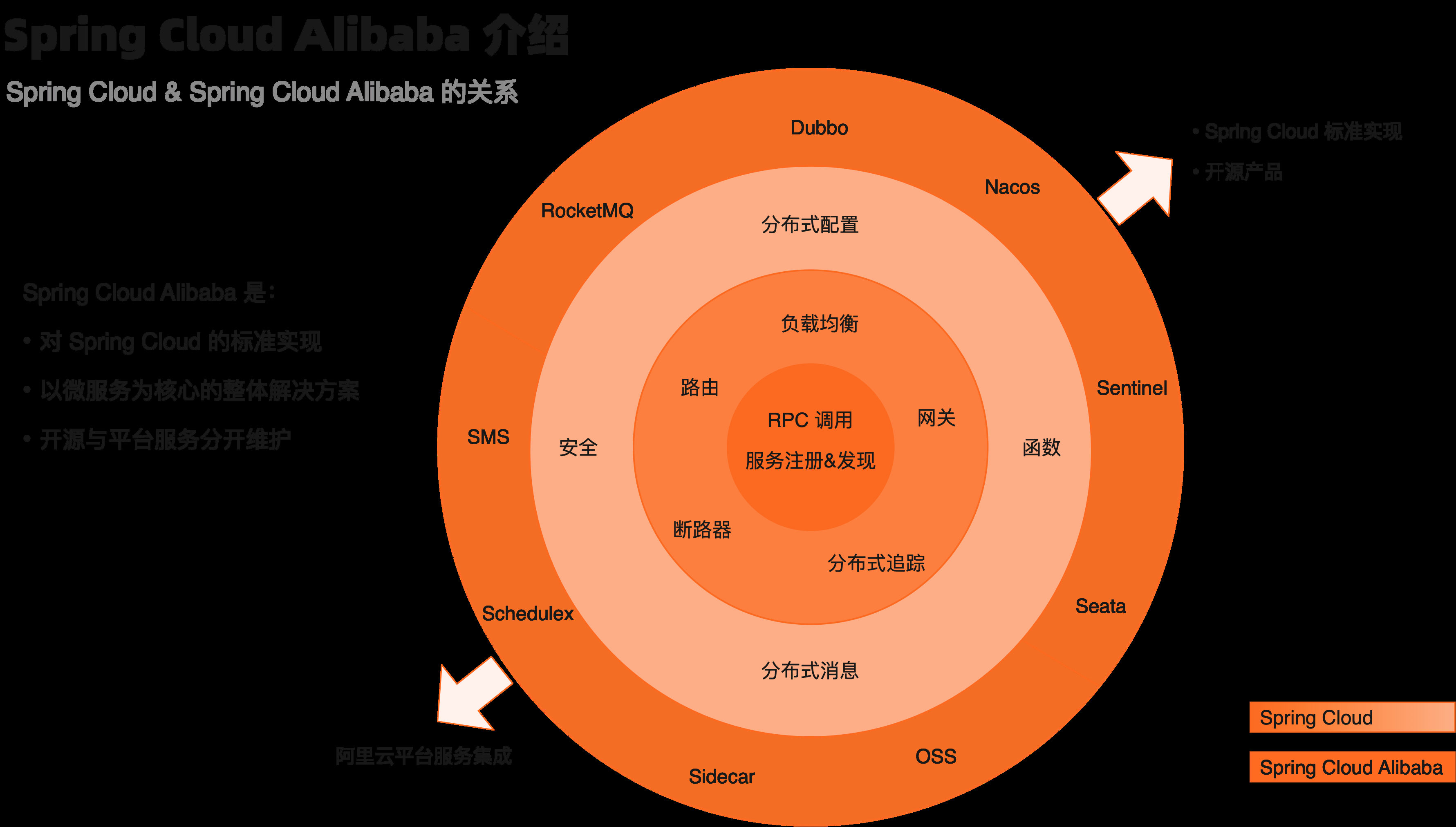
这里给大家这么一个公式,这个叫做:“3 加 2”。
3 指的就是图中深色的部分,其实它就是 Spring Cloud 标准,一共有 3 层。中间颜色最深的部分就是及整个微服务最核心的内容,包括了“ RPC调用”以及“服务注册与发现”。第二层,也就是围绕着核心的这一圈,是一些辅助微服务更好的工作功能,包括了负载均衡、路由、网关、断路器,还有就是追踪等等这些内容。再外层的话,主要是一些分布式云环境里通用能力。
“3 加 2”中的“2”,指的就是上图中最外面这一圈。这一部分就是这个我们 Spring Cloud Alibaba 的一个定义,它其实包含两个部分的内容:右上部分是对于 Spring Cloud 标准的实现。例如,我们通过 Dubbo 实现了 RPC 调用功能,通过 Nacos 实现了“服务注册与发现”、“分布式配置”,通过 Sentinel 实现了断路器等等,这里就不一一列举了。
左下部分是我们 Spring Cloud Alibaba 对阿里云各种服务的集成。可能很多同学会有这样的一个问题:为什么要加上这一部分呢?此时回头审视一下 Spring Cloud ,它仅仅是一个微服务的一个框架。但是在实际生产过程中,单独使用微服务框架其实并不足以支撑我们去构建一个完整的系统。所以这部分是用阿里帮助开发者完成微服务以外的云产品集成的功能。
这里可能会很多同学会有这么一个担心:是不是使用了 Spring Cloud Alibaba,就会被阿里云平台绑定呢?在此,我们明确的告诉大家,这是不会的。为什么这么说呢?如上面说的,“3 加 2”中的 2 是被分为两个部分的。其中对 Spring Cloud 的实现是完全独立的,开发者可以只是用这部分实现运行在任何云平台中。当然,另一部分,由于天然是对阿里云服务的集成,这部分是和平台相关的。这里给开发者充分的自由,选择只是用其中
的部分还是全部产品。当然,我们也非常欢迎开发者选择使用阿里云的全套服务,我们也会尽量保证使用整套产品时的连贯性与开发的便利性。
Spring Cloud 各套实现对比
Spring Cloud 作为一套标准,它的实现肯定不止一套,那么各套实现都有什么区别呢?我们来一起看一下下面这张图: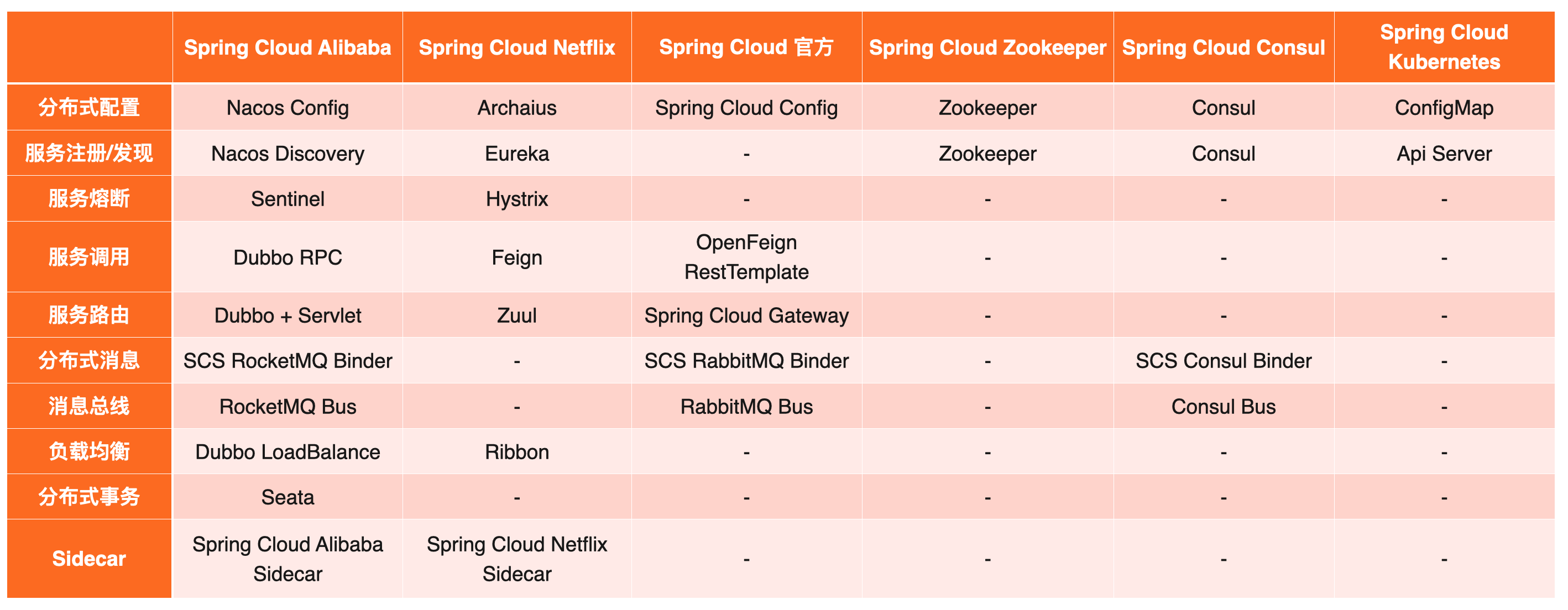
可以发现 Spring Cloud Alibaba 是所有的实现方案中功能最齐全的。尤其是在 Netflix 停止更新了以后,Spring Cloud Alibaba 依然在持续更新和迭代。
图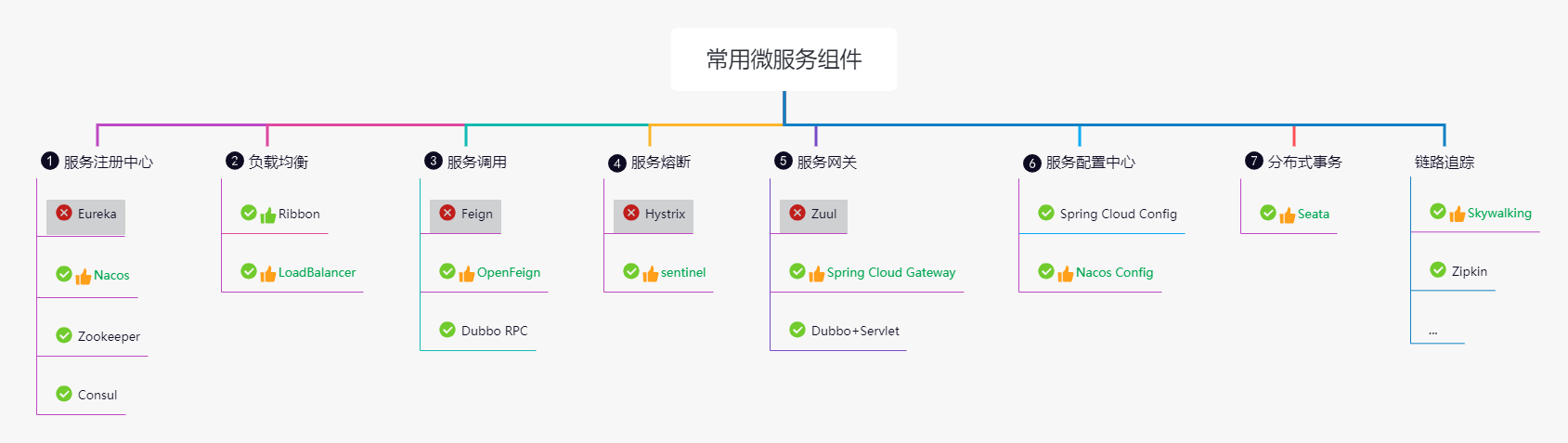
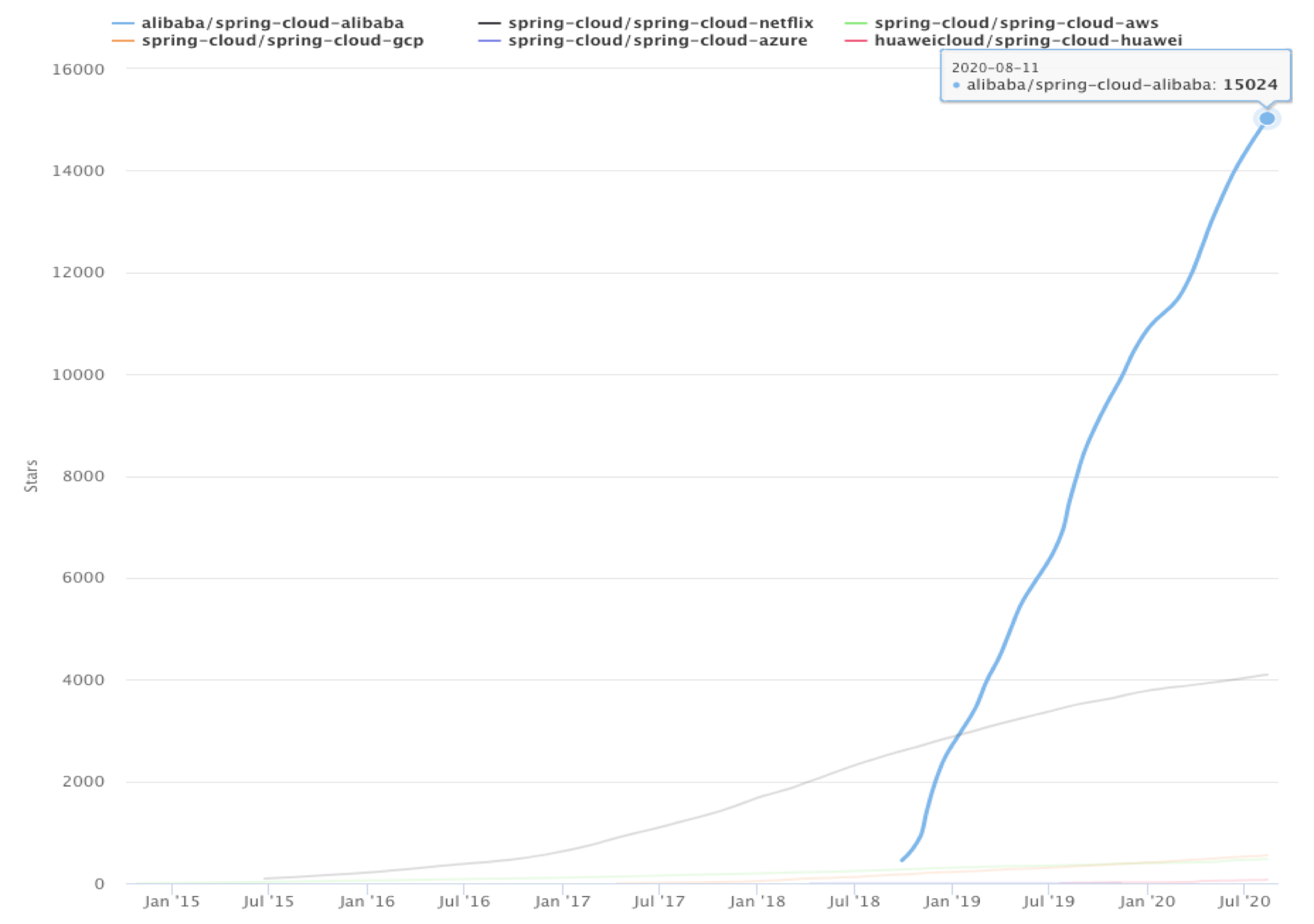 从 18 年 7 月份 Spring Cloud Alibaba 正式提交代码开始,就得到了大家广泛的关注。截止今天,Spring Cloud Alibaba 一共获得了超过了 1.5 万
从 18 年 7 月份 Spring Cloud Alibaba 正式提交代码开始,就得到了大家广泛的关注。截止今天,Spring Cloud Alibaba 一共获得了超过了 1.5 万
的 star 数,已经的领先于所有其他实现的总和。
根据今年 X-lab 开放实验室刚刚发布的《2020 年微服务领域开源数字化报告》,Spring Cloud Alibaba 已经成为最活跃的 Spring Cloud 实现。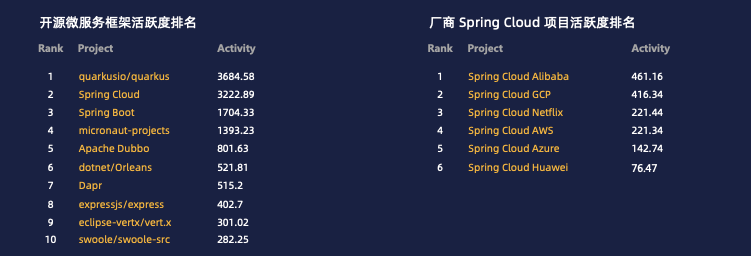
Spring Cloud Alibaba 生态
可以看到除了围绕着 Spring Cloud 的标准实现以外,还有包括的数据、资源、消息、缓存等各种类型的服务。在不同类型的服务下,也有很多具体
的产品可供用户选择。
 Spring Cloud Alibaba 用户数
Spring Cloud Alibaba 用户数
截止到今天,Spring Cloud Alibaba 获得了数超过 1.5w 的 star 数。同时在 Github 上的项目依赖,就是对 Spring Cloud Alibaba 产生依赖关系的产品,也超过了 6000。最重要的,使用 Spring Cloud Alibaba 的公司超过 1000 家。当然不只是外部的公司在使用,阿里内部也在使用。经过了
双十一的洗礼,其实整个这套框架它的这个稳定性可靠性都得到了印证。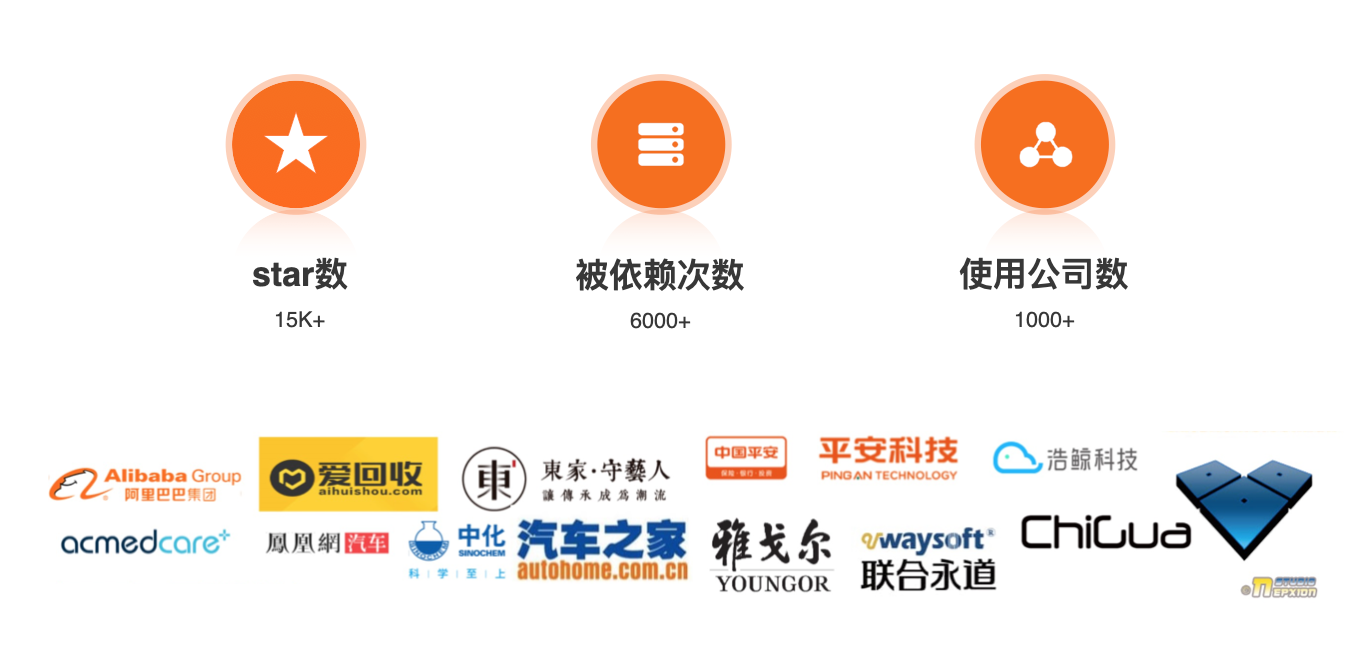
Spring Cloud Alibaba环境搭建
SpringCloud Alibaba 依赖 Java 环境来运行。还需要为此配置 Maven环境,请确保是在以下版本环境中安装使用:
- 基于SpringBoot的父maven项目
2. 创建2个服务(订单服务和库存服务)
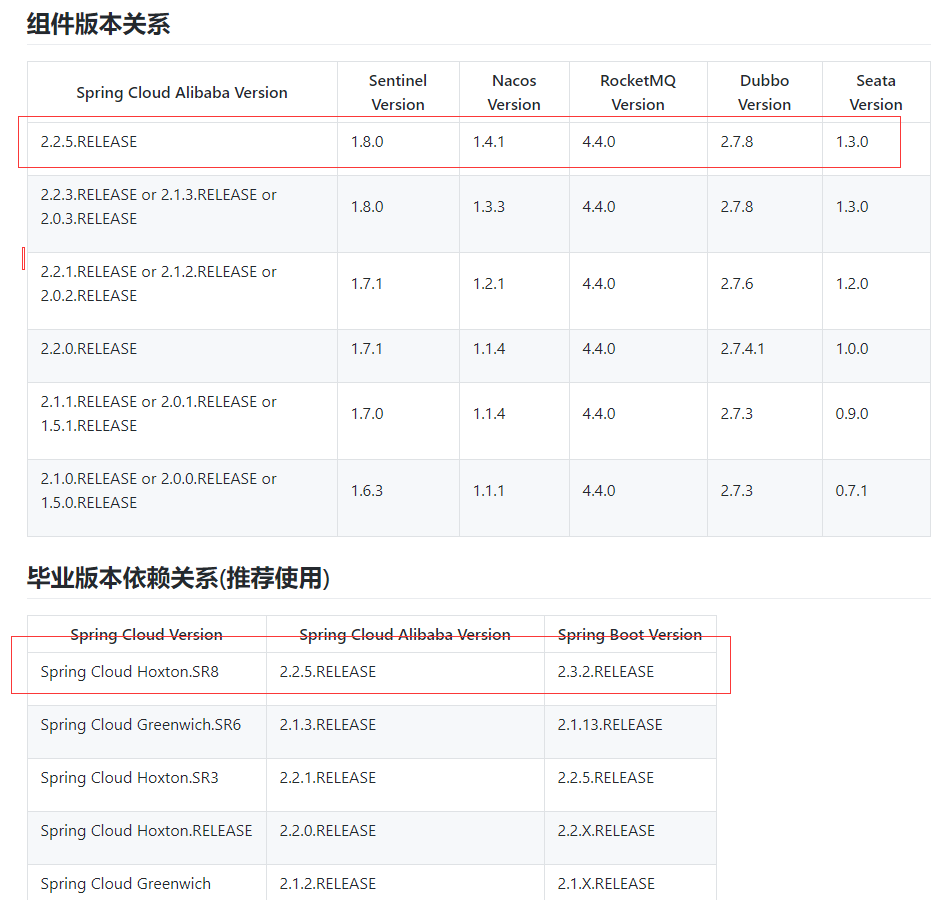
版本说明:https://github.com/alibaba/spring-cloud-alibaba/wiki/%E7%89%88%E6%9C%AC%E8%AF%B4%E6%98%8E
- Spring Cloud Alibaba:2.2.5.RELEASE
- Spring Boot :2.3.2.RELEASE
Spring Cloud:Hoxton.SR8
最新的版本选择: Spring Cloud Alibaba 2.2.5.RELEASE
Java 工程脚手架:更适合亚太区 Java 开发者的脚手架
 很多开发者应该跟我一样,都有过这样的经历:创建新应用时,先找一个我们最熟悉的一个老应用,把它里边的业务代码全部清理干净。然后相关的各种配置名称全部改掉,最终做出一个空的一个应用模板。再把这个应用模板拿过来改个名子,就变成了一个新的应用。
很多开发者应该跟我一样,都有过这样的经历:创建新应用时,先找一个我们最熟悉的一个老应用,把它里边的业务代码全部清理干净。然后相关的各种配置名称全部改掉,最终做出一个空的一个应用模板。再把这个应用模板拿过来改个名子,就变成了一个新的应用。
当然可能有的同学会做的更多一些,例如长期维护这么一个空白模板在那里。下次拿过出来之后再改改个名字,就是一个新的应用。这样做可能是一个相对保险的方案,
但是缺点也非常明显:
- 版本老旧,新特性无法享受
- 团队知识无法沉淀
- 重复劳动
通过提供 Java 工程脚手架来解决这个问题。下面就是 Java 工程脚手架的页面:https://start.aliyun.com/bootstrap.html 在这里,开发者设置项目的基本信息,例如:开发语言、Java 版本、Spring Boot 版本等内容。
在这里,开发者设置项目的基本信息,例如:开发语言、Java 版本、Spring Boot 版本等内容。
Nacos
nacos 官方文档地址:https://nacos.io/zh-cn/docs/what-is-nacos.html
什么是 Nacos
概览
欢迎来到 Nacos 的世界!
Nacos 致力于帮助您服务发现、配置和管理微服务。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据及流量管理。
Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。 Nacos 是构建以“服务”为中心的现代应用架构 (例如微服务范式、云原生范式) 的服务基础设施。
什么是 Nacos?
Nacos 的关键特性包括:
服务发现和服务健康监测 Nacos 支持基于 DNS 和基于 RPC 的服务发现。服务提供者使用 原生SDK、OpenAPI、或一个独立的Agent TODO注册 Service 后,服务消费者可以使用DNS TODO 或HTTP&API查找和发现服务。Nacos 提供对服务的实时的健康检查,阻止向不健康的主机或服务实例发送请求。Nacos 支持传输层 (PING 或 TCP)和应用层 (如 HTTP、MySQL、用户自定义)的健康检查。 对于复杂的云环境和网络拓扑环境中(如 VPC、边缘网络等)服务的健康检查,Nacos 提供了 agent 上报模式和服务端主动检测2种健康检查模式。Nacos 还提供了统一的健康检查仪表盘,帮助您根据健康状态管理服务的可用性及流量。
动态配置服务 动态配置服务可以让您以中心化、外部化和动态化的方式管理所有环境的应用配置和服务配置。动态配置消除了配置变更时重新部署应用和服务的需要,让配置管理变得更加高效和敏捷。配置中心化管理让实现无状态服务变得更简单,让服务按需弹性扩展变得更容易。Nacos 提供了一个简洁易用的UI (控制台样例 Demo) 帮助您管理所有的服务和应用的配置。Nacos 还提供包括配置版本跟踪、金丝雀发布、一键回滚配置以及客户端配置更新状态跟踪在内的一系列开箱即用的配置管理特性,帮助您更安全地在生产环境中管理配置变更和降低配置变更带来的风险。
动态 DNS 服务 动态 DNS 服务支持权重路由,让您更容易地实现中间层负载均衡、更灵活的路由策略、流量控制以及数据中心内网的简单DNS解析服务。动态DNS服务还能让您更容易地实现以 DNS 协议为基础的服务发现,以帮助您消除耦合到厂商私有服务发现 API 上的风险。Nacos 提供了一些简单的 DNS APIs TODO 帮助您管理服务的关联域名和可用的 IP:PORT 列表.
- 服务及其元数据管理Nacos 能让您从微服务平台建设的视角管理数据中心的所有服务及元数据,包括管理服务的描述、生命周期、服务的静态依赖分析、服务的健康状态、服务的流量管理、路由及安全策略、服务的 SLA 以及最首要的 metrics 统计数据。
- 更多的特性列表 …
Nacos 地图
一图看懂 Nacos,下面架构部分会详细介绍 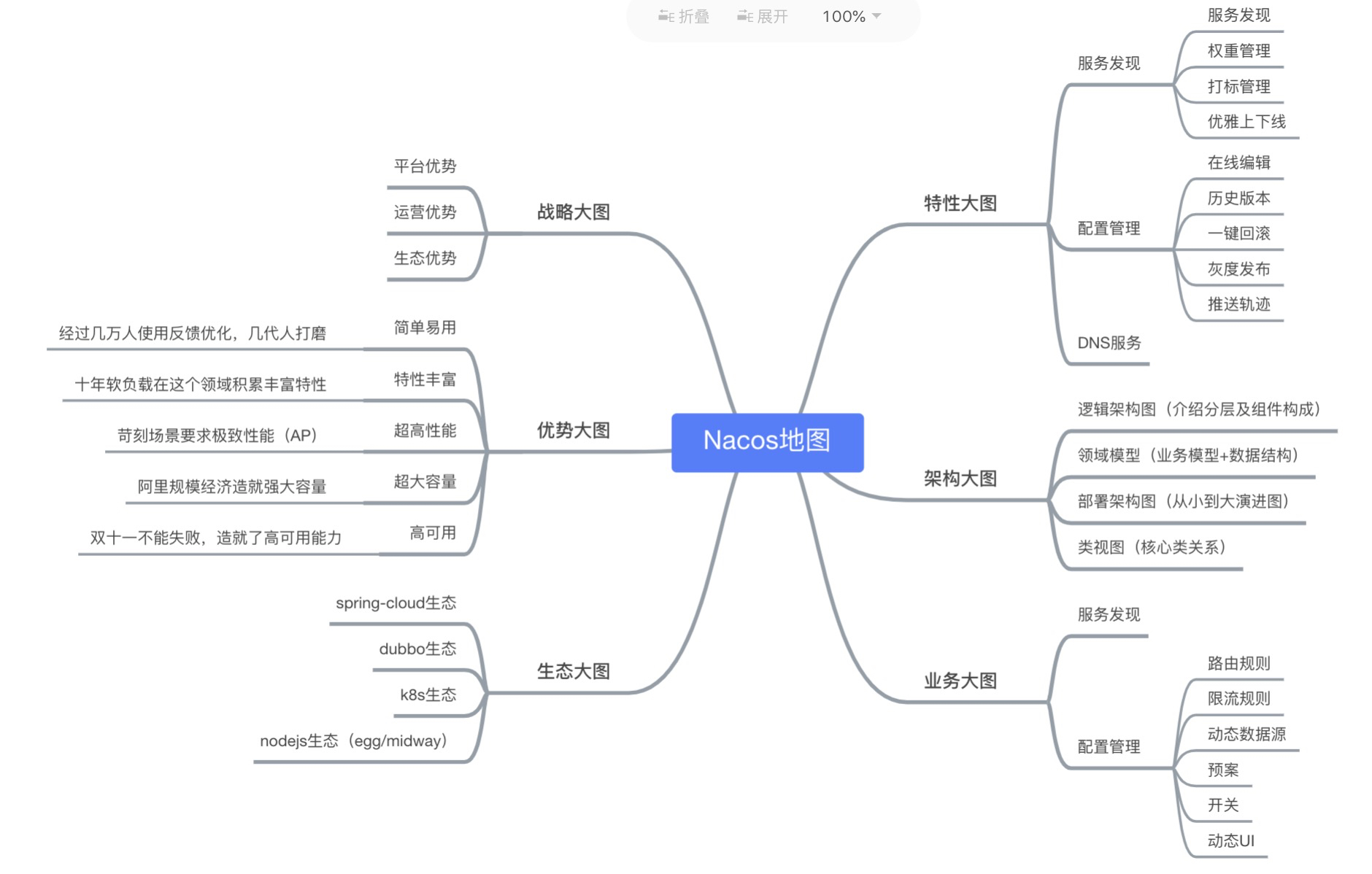
- 特性大图:要从功能特性,非功能特性,全面介绍我们要解的问题域的特性诉求
- 架构大图:通过清晰架构,让您快速进入 Nacos 世界
- 业务大图:利用当前特性可以支持的业务场景,及其最佳实践
- 生态大图:系统梳理 Nacos 和主流技术生态的关系
- 优势大图:展示 Nacos 核心竞争力
- 战略大图:要从战略到战术层面讲 Nacos 的宏观优势
核心功能
服务注册:Nacos Client会通过发送REST请求的方式向Nacos Server注册自己的服务,提供自身的元数据,比如ip地址、端口等信息。Nacos Server接收到注册请求后,就会把这些元数据信息存储在一个双层的内存Map中。
服务心跳:在服务注册后,Nacos Client会维护一个定时心跳来持续通知Nacos Server,说明服务一直处于可用状态,防止被剔除。默认5s发送一次心跳。
服务同步:Nacos Server集群之间会互相同步服务实例,用来保证服务信息的一致性。 leader raft 服务发现:服务消费者(Nacos Client)在调用服务提供者的服务时,会发送一个REST请求给Nacos Server,获取上面
注册的服务清单,并且缓存在Nacos Client本地,同时会在Nacos Client本地开启一个定时任务定时拉取服务端最新的注册表信息更新到本地缓存
服务健康检查:Nacos Server会开启一个定时任务用来检查注册服务实例的健康情况,对于超过15s没有收到客户端心跳的实例会将它的healthy属性置为false(客户端服务发现时不会发现),如果某个实例超过30秒没有收到心跳,直接剔除该实例(被剔除的实例如果恢复发送心跳则会重新注册)
主流的注册中心对比
CAP C 一致性 A可用性 P 分区容错性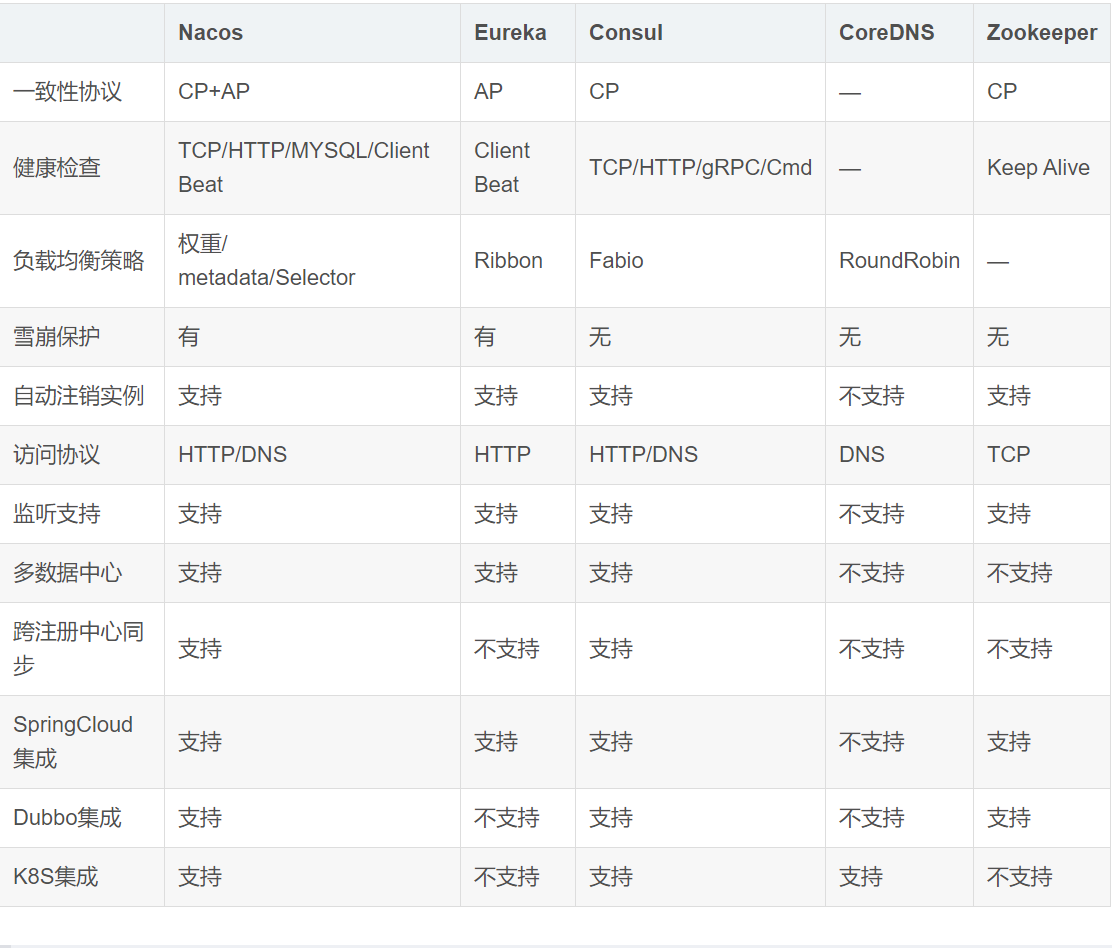
雪崩保护:
保护阈值: 设置0-1之间的值 0.6
临时实例: spring.cloud.nacos.discovery.ephemeral =false, 当服务宕机了也不会从服务列表中剔除
下图代表永久实例:
健康实例、 不健康实例;
健康实例数/总实例数 < 保护阈值`
1/2<0.6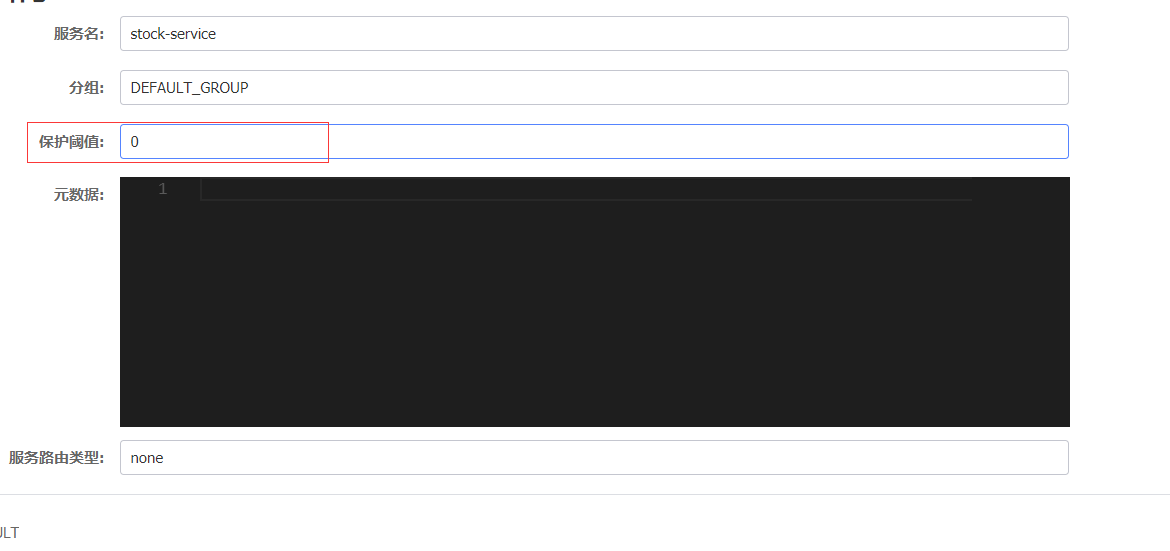
结合负载均衡器 权重的机制, 设置的越大
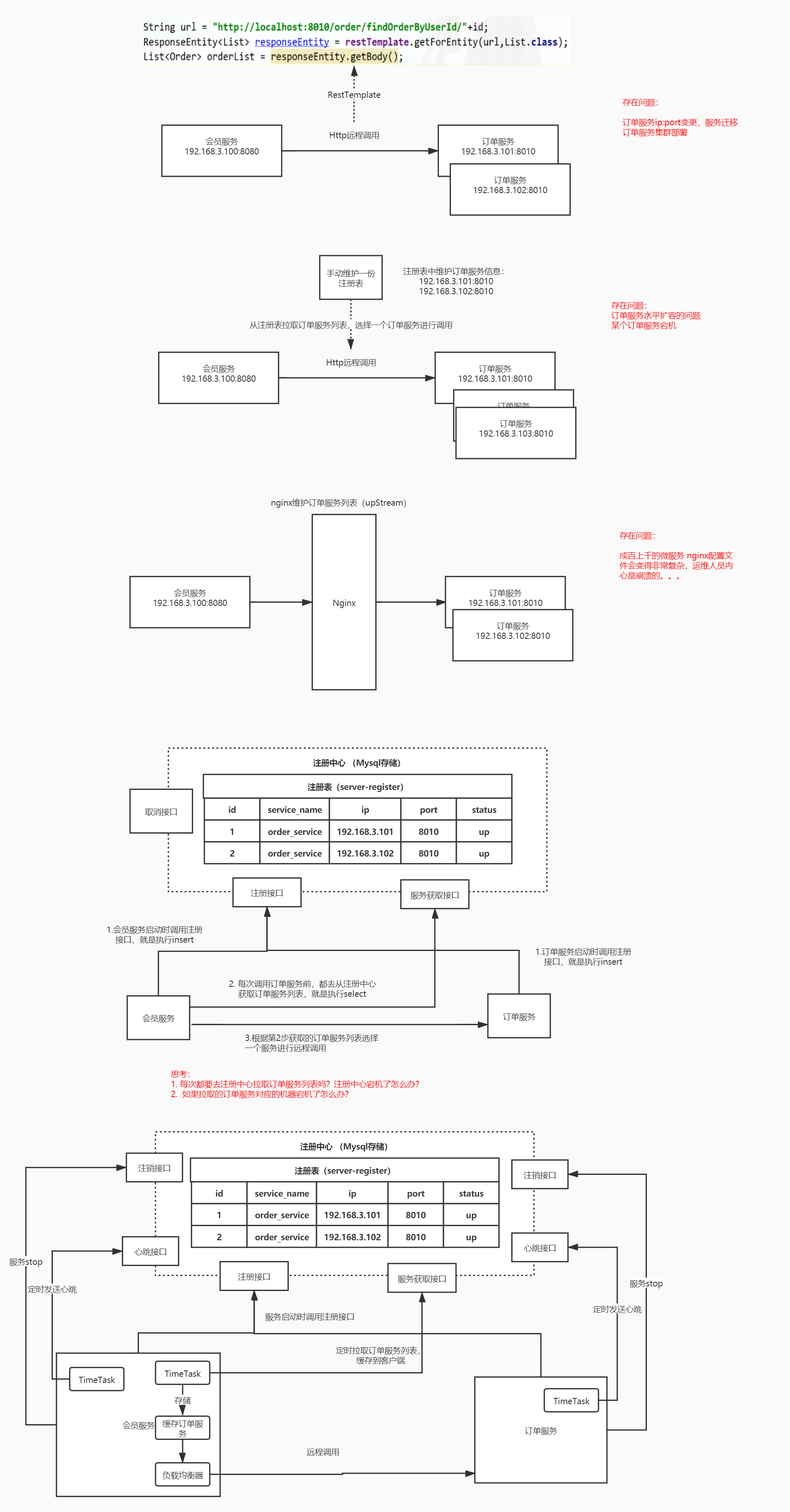
Nacos 服务注册
Nacos 安装
查看上一篇文档 Mall 环境安装文档
执行流程图
搭建 Spring Cloud Alibaba 项目
pom 依赖
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.1.2.RELEASE</version></parent><properties><java.version>1.8</java.version><spring-cloud.version>Greenwich.RELEASE</spring-cloud.version><spring-cloud-alibaba.version>0.2.1.RELEASE</spring-cloud-alibaba.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.16.14</version><scope>provided</scope></dependency><!--alibaba-nacos-discovery(阿里注册中心discovery)--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency></dependencies><dependencyManagement><dependencies><!--Spring Cloud 相关依赖--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>${spring-cloud.version}</version><type>pom</type><scope>import</scope></dependency><!--Spring Cloud Alibaba 相关依赖--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>${spring-cloud-alibaba.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement>
配置文件 application.yml
spring:application:## 注册服务名name: nacos-ordercloud:nacos:## 注册中心地址discovery:server-addr: 127.0.0.1:8848server:## 启动端口port: 8110
下面是 properties 配置
## 注册服务名spring.application.name=nacos-order## 注册中心地址spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848## 启动端口server.port=8111
同一个服务名,不同端口可以启动多个服务,可以做集群
创建启动类-OrderApp
说明:@EnableDiscoveryClient 是开启Spring Cloud的服务注册与发现
@SpringBootApplication@EnableDiscoveryClientpublic class OrderApp {public static void main(String[] args) {SpringApplication.run(OrderApp.class,args);}}

Nacos 界面可以看到服务注册信息
Nacos 配置中心
默认配置中心
概述
下面我们通过一个简单的例子来介绍如何使用Nacos来创建配置内容以及如何在Spring Cloud应用中加载Nacos的配置信息。
Nacos 配置文件
第一步:进入Nacos的控制页面,在配置列表功能页面中,单击右上角的+按钮,进入新建配置页面,如图填写配置信息: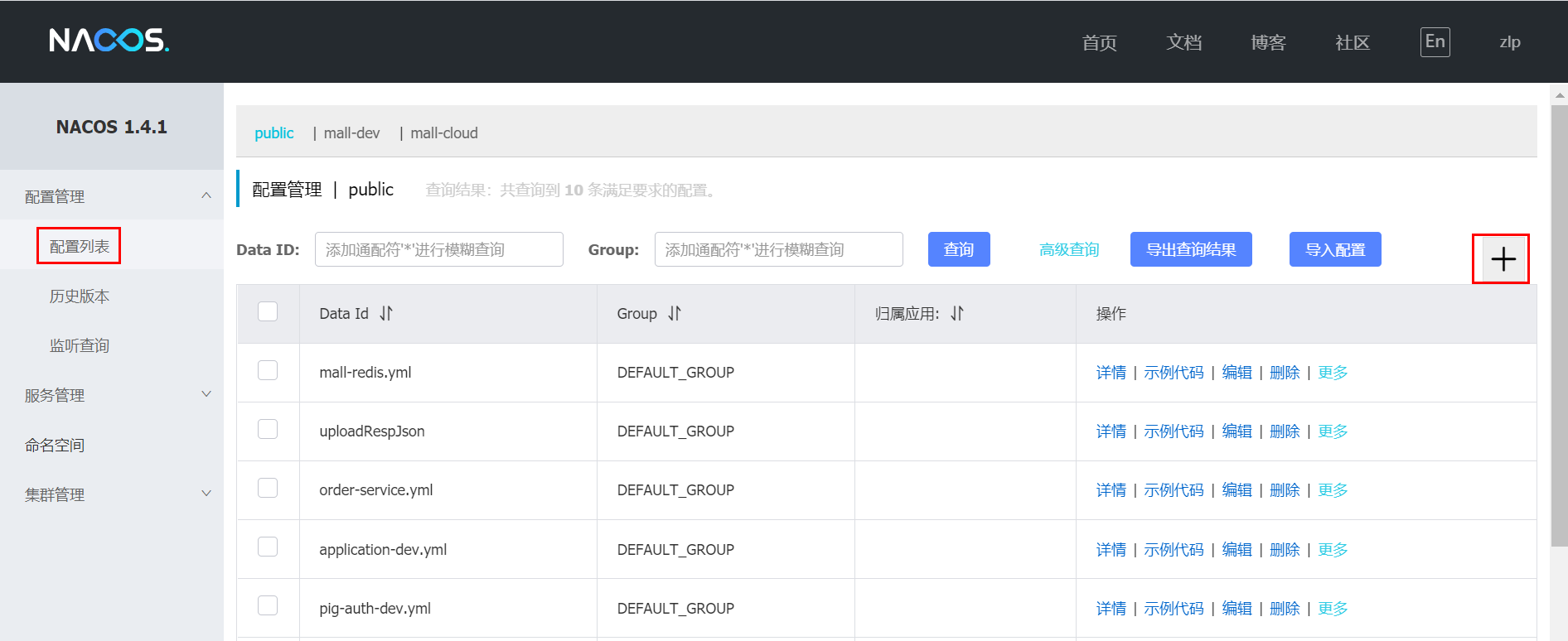
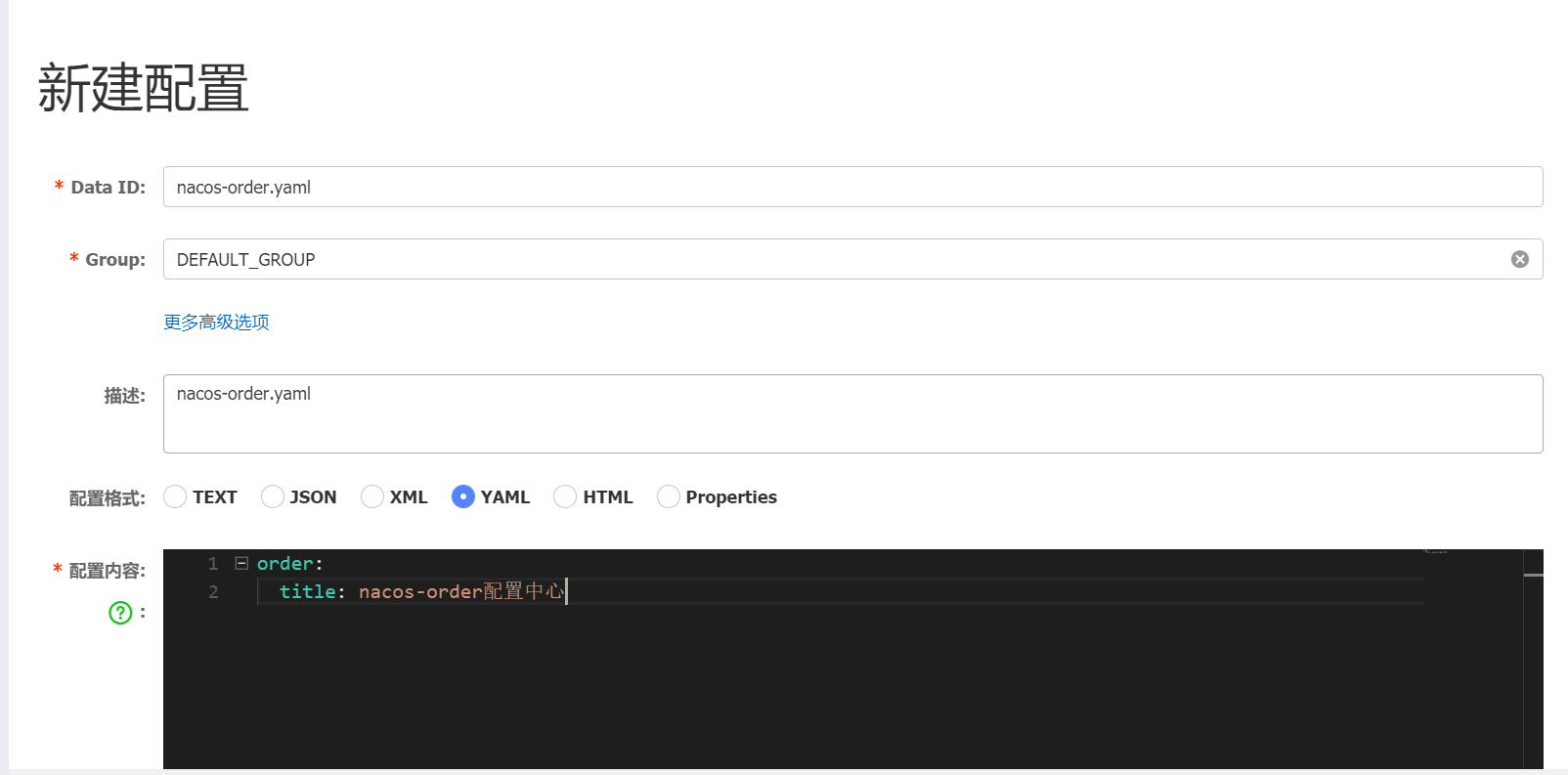 详解说明
详解说明
其中:
- Data ID:填入nacos-order.ymal
- Group:默认值 DEFAULT_GROUP
- 配置格式:选择ymal
- 配置内容:应用要加载的配置内容,这里仅作为示例,做简单配置,比如:order.title=nacos-order配置中心
构建SpringCloudAlibaba Nacos配置中心项目
第一步:创建一个Spring Cloud应用,可以命名为:order-config。
第二步:编辑pom.xml,加入必要的依赖配置
项目搭建采用的版本是
spring-cloud版本是 Greenwich.RELEASE
spring-cloud-alibaba版本是 0.2.1.RELEASE
注意:
1.本项目采用parent模块化构建项目
2.如果你开发工具没有lombok插件,可以把pom中lombok依赖删除掉
pom.xml 依赖
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.1.2.RELEASE</version></parent><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.16.14</version><scope>provided</scope></dependency><!--alibaba-nacos-discovery(阿里注册中心discovery)--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><!--alibaba-config--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-alibaba-nacos-config</artifactId></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>Greenwich.RELEASE</version><type>pom</type><scope>import</scope></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>0.2.1.RELEASE</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement>
配置文件
说明:配置文件加载顺序,SpringBoot中会先加载 bootstrap.yml,后加载 application.yml
注意:如果是yml配置文件,必须是 bootstrap.yml 而不是 application.yml
详解说明: 客户端配置,在bootstrap.yml文件中spring.cloud.nacos.config.file-extension属性声明从配置中心中读取的配置文件格式 该配置的缺省值为properties,即默认是读取properties格式的配置文件。当客户端没有配置该属性,并且在nacos server添加的是yml格式的配置文件,则给客户端会读取不到配置文件,导致启动失败。
server:## 启动端口port: 8130spring:application:## 注册服务名name: nacos-ordercloud:nacos:## 注册中心地址discovery:server-addr: 127.0.0.1:8848## 配置中心地址config:server-addr: 127.0.0.1:8848## 指定读取配置文件的后缀file-extension: yaml## 分组group: DEFAULT_GROUP
启动类
@SpringBootApplication@EnableDiscoveryClientpublic class OrderConfigApp {public static void main(String[] args) {SpringApplication.run(OrderConfigApp.class,args);}}
测试类
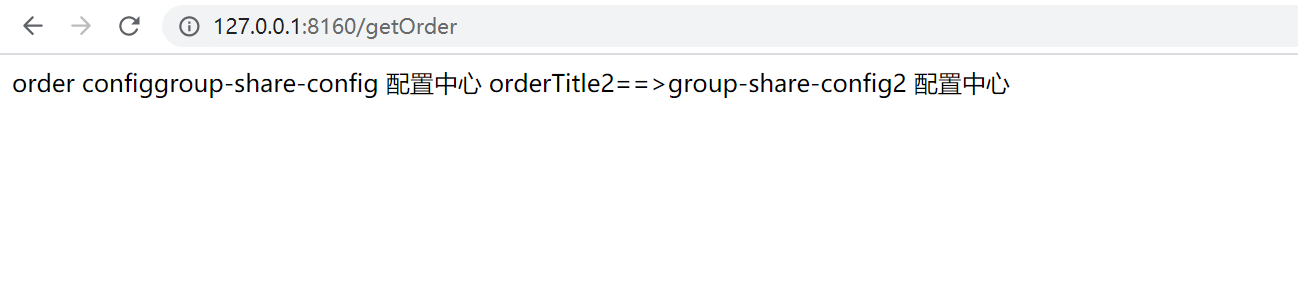
其中通过 @Value 注解,注入了key为order.title的配置(默认为空字符串),这个配置会通过 /getOrder 接口返回,后续我们会通过这个接口来验证Nacos中配置的加载。另外,这里还有一个比较重要的注解@RefreshScope,主要用来让这个类下的配置内容支持动态刷新,也就是当我们的应用启动之后,修改了Nacos中的配置内容之后,这里也会马上生效。
/*** @author: LiPing.Zou* @create: 2020-05-18 15:27**/@RestController@RefreshScopepublic class OrderController {@Value("${order.title}")private String orderTitle;@GetMapping("getOrder")public String getOrder(){return "order config" +orderTitle;}}
控制台输出日志
 浏览器访问,测试成功!
浏览器访问,测试成功!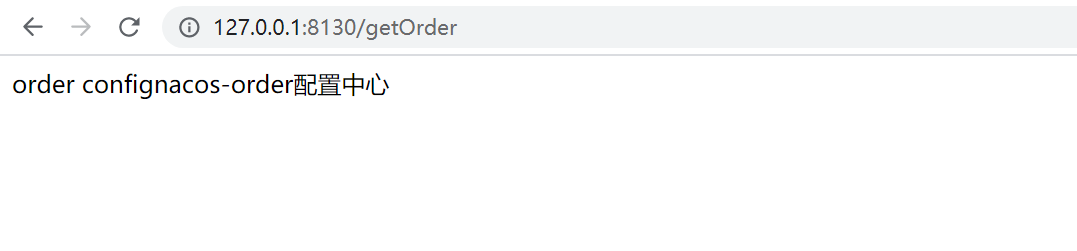
当我们修改配置中心内容,会触发 RefreshEventListener 事件
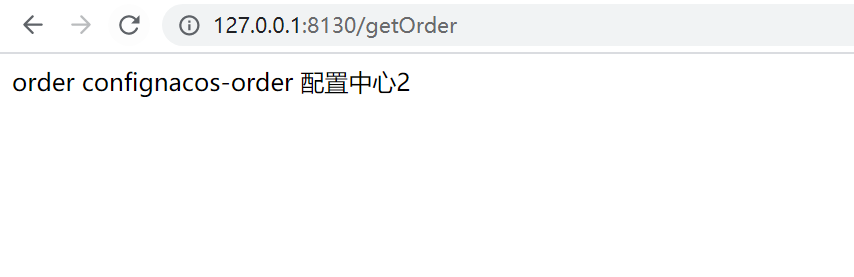
分组配置中心
概述
默认分组为DEFAULT_GROUP,Group 可以将不同的微服务进行分组划分。
Nacos 添加配置文件
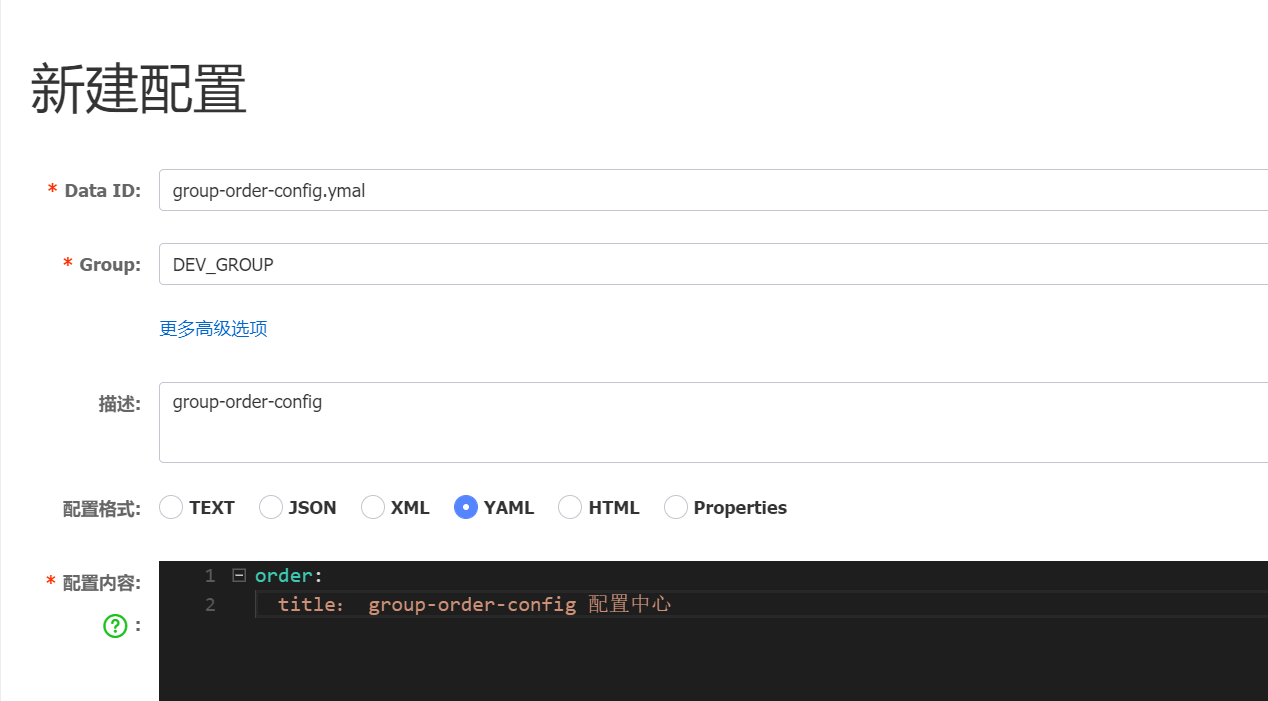
配置文件
server:## 启动端口port: 8160spring:application:## 注册服务名name: group-order-configcloud:nacos:## 注册中心地址discovery:server-addr: 47.103.20.21:8848## 配置中心地址config:server-addr: 47.103.20.21:8848## 指定读取配置文件的后缀file-extension: yaml## 分组group: DEV_GROUP
控制台输出
CompositePropertySource {name='NACOS', propertySources=[NacosPropertySource {name='namespace-order-config-dev.yaml'}, NacosPropertySource {name='namespace-order-config.yaml'}]}
测试结果
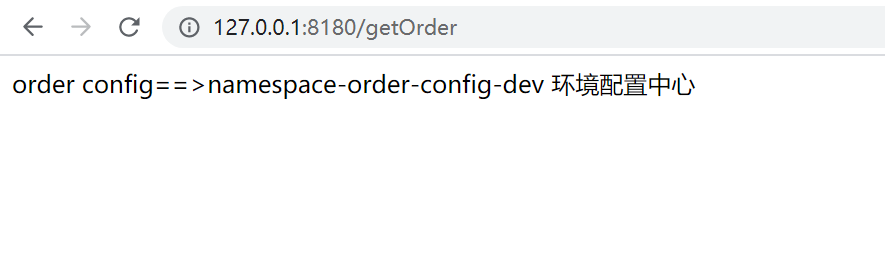
总结
- 优点:通过Group按环境讲各个应用的配置隔离开。可以非常方便的利用Data ID和Group的搜索功能,分别从应用纬度和环境纬度来查看配置。
- 缺点:由于会占用Group纬度,所以需要对Group的使用做好规划,毕竟与业务上的一些配置分组起冲突等问题。
- 建议:这种方式虽然结构上比上一种更好一些,但是依然可能会有一些混乱,主要是在Group的管理上要做好规划和控制。
命名空间配置中心
概述
默认为public,其作用可以用来实现环境隔离作用,比如我们的开发环境、测试环境、生产环境。
Nacos 添加命名空间
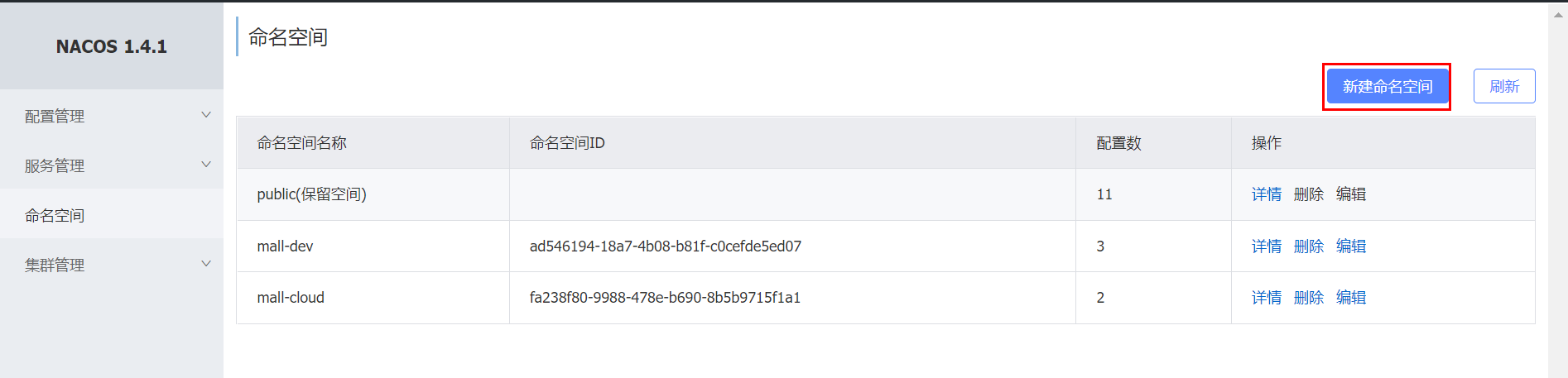

配置文件
添加了 namespace: 9e7bf496-2518-415c-9dcf-d2d47453457e
server:## 启动端口port: 8180spring:application:## 注册服务名name: namespace-order-configcloud:nacos:## 注册中心地址discovery:server-addr: 127.0.0.1:8848## 配置中心地址config:server-addr: 127.0.0.1:8848## 指定读取配置文件的后缀file-extension: yaml## 命名空间namespace: 9e7bf496-2518-415c-9dcf-d2d47453457e
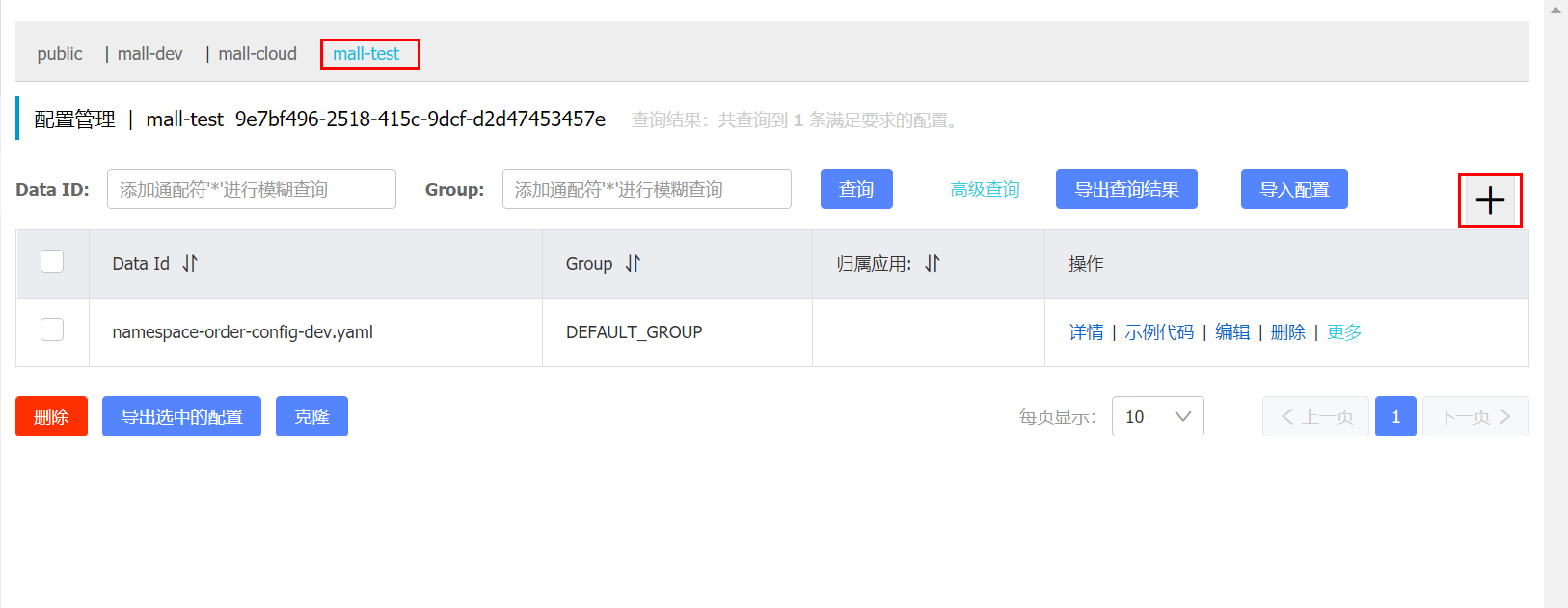
控制台输出
CompositePropertySource {name='NACOS', propertySources=[NacosPropertySource {name='namespace-order-config-dev.yaml'}, NacosPropertySource {name='namespace-order-config.yaml'}]}
测试结果
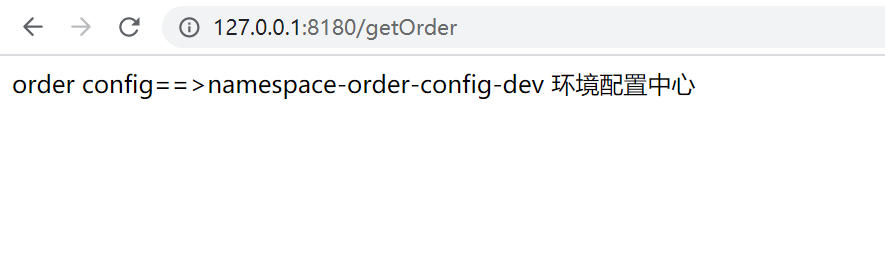
总结
- 优点:官方建议的方式,通过Namespace来区分不同的环境,释放了Group的自由度,这样可以让Group的使用专注于做业务层面的分组管理。同时,Nacos控制页面上对于Namespace也做了分组展示,不需要搜索,就可以隔离开不同的环境配置,非常易用。
- 缺点:没有啥缺点,可能就是多引入一个概念,需要用户去理解吧。
- 建议:直接用这种方式长远上来说会比较省心。虽然可能对小团队而言,项目不多,第一第二方式也够了,但是万一后面做大了呢?
多文件加载与共享配置
概述
有时候我们会对应用的配置根据具体作用做一些拆分,存储在不同的配置文件中,除了归类不同的配置之外,也可以便于共享配置给不同的应用。对于这样的需求,Nacos也可以很好的支持,下面就来具体介绍一下,当使用Nacos时,我们如何加载多个配置,以及如何共享配置。
配置中心添加两个配置文件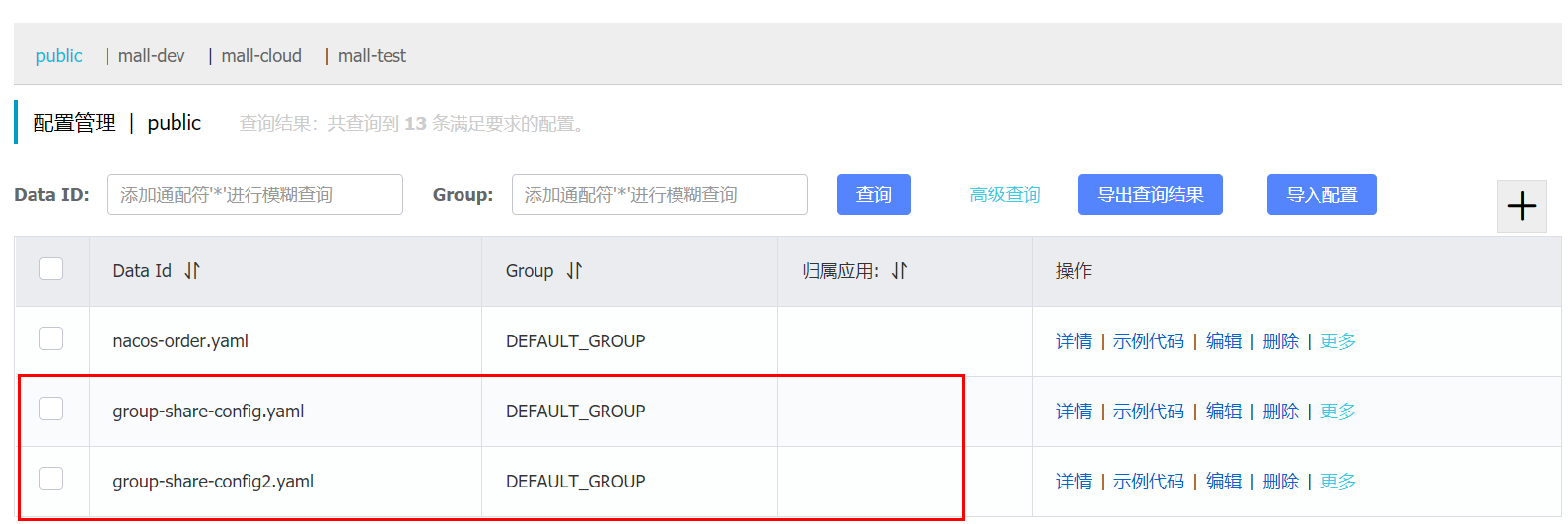
配置文件
group-share-config 服务同时加载两个配置文件 group-share-config.yaml, group-share-config2.yaml
server:## 启动端口port: 8160spring:application:## 注册服务名name: group-share-configcloud:nacos:## 注册中心地址discovery:server-addr: 127.0.0.1:8848## 配置中心地址config:server-addr: 127.0.0.1:8848# ## 指定读取配置文件的后缀# file-extension: yaml# refreshable-dataids: group-share-config.yaml,group-share-config2.yaml# shared-dataids: group-share-config.yaml,group-share-config2.yamlext-config:- data-id: group-share-config.yamlgroup: DEFAULT_GROUPrefresh: truefileExtension: yaml- data-id: group-share-config2.yamlgroup: DEFAULT_GROUPrefresh: truefileExtension: yaml
控制台输出

测试结果
Ribbon
什么是Ribbon
目前主流的负载方案分为以下两种:
- 集中式负载均衡,在消费者和服务提供方中间使用独立的代理方式进行负载,有硬件的(比如 F5),也有软件的(比如Nginx)。
- 客户端根据自己的请求情况做负载均衡,Ribbon 就属于客户端自己做负载均衡。
Spring Cloud Ribbon是基于Netflix Ribbon 实现的一套客户端的负载均衡工具,Ribbon客户端组件提供一系列的完善的配置,如超时,重试等。通过Load Balancer获取到服务提供的所有机器实例,Ribbon会自动基于某种规则(轮询,随机)去调用这些服务。Ribbon也可以实现我们自己的负载均衡算法。
客户端的负载均衡
例如 spring cloud中的 ribbon,客户端会有一个服务器地址列表,在发送请求前通过负载均衡算法选择一个服务器,然后进行访问,这是客户端负载均衡;即在客户端就进行负载均衡算法分配。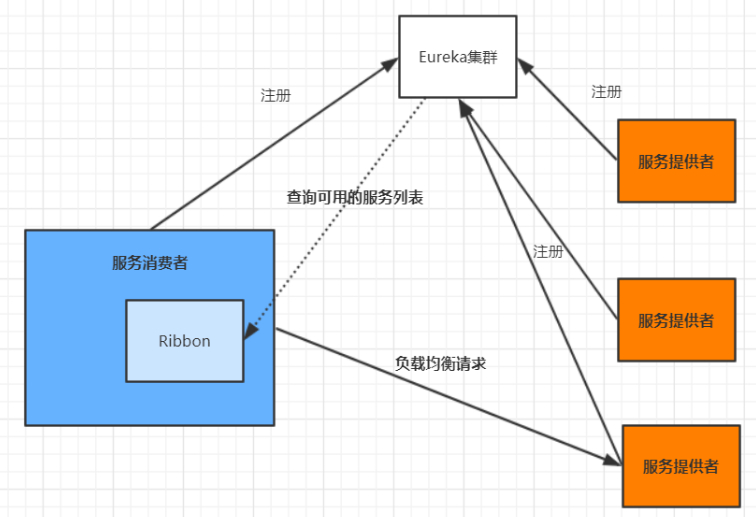
服务端的负载均衡
例如Nginx,通过Nginx进行负载均衡,先发送请求,然后通过负载均衡算法,在多个服务器之间选择一个进行访问;即在服务器端再进行负载均衡算法分配。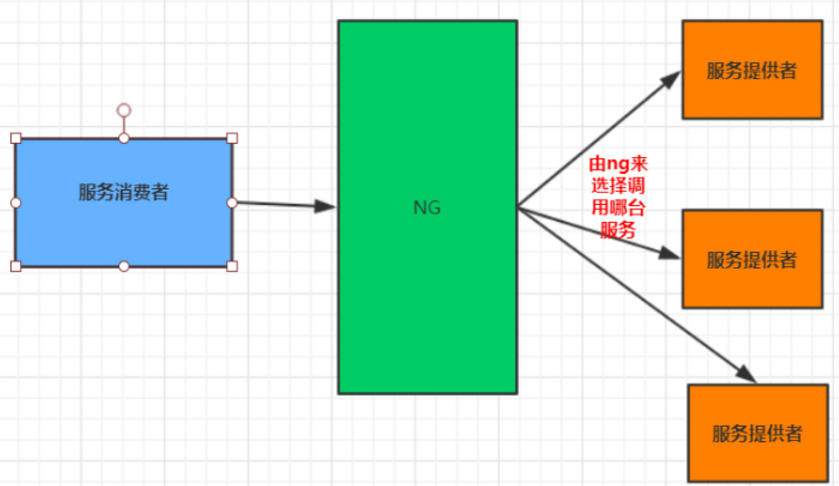
常见负载均衡算法
- 随机: 通过随机选择服务进行执行,一般这种方式使用较少;
- 轮训: 负载均衡默认实现方式,请求来之后排队处理;
- 加权轮训: 通过对服务器性能的分型,给高配置,低负载的服务器分配更高的权重,均衡各个服务器的压力;
- 地址Hash: 通过客户端请求的地址的HASH值取模映射进行服务器调度。 ip —->hash
- 最小链接数: 即使请求均衡了,压力不一定会均衡,最小连接数法就是根据服务器的情况,比如请求积压数等参数,将请求分配到当前压力最小的服务器上。 最小活跃数
Nacos 使用 Ribbon
nacos-discovery依赖了ribbon,可以不用再引入ribbon依赖
添加@LoadBalanced注解
@Configurationpublic class RestTemplateConfig {@Bean@LoadBalancedpublic RestTemplate restTemplate(@Qualifier("simpleClientHttpRequestFactory") ClientHttpRequestFactory factory){return new RestTemplate(factory);}@Beanpublic ClientHttpRequestFactory simpleClientHttpRequestFactory(){SimpleClientHttpRequestFactory factory = new SimpleClientHttpRequestFactory();factory.setConnectTimeout(85000);// 获取数据超时时间 毫秒factory.setReadTimeout(80000);return factory;}}
修改接口实现类调用
private final RestTemplate restTemplate;@Overridepublic Order addOrder() {Order order = new Order();order.setId(1);order.setName("ribbon 订单");order.setAmount(new BigDecimal("10098"));// String url = "http://127.0.0.1:8130/reduct";String url = "http://ribbon-stock/reduct";String object = restTemplate.getForObject(url, String.class);log.info("object={}",object);return order;}
Ribbon负载均衡策略
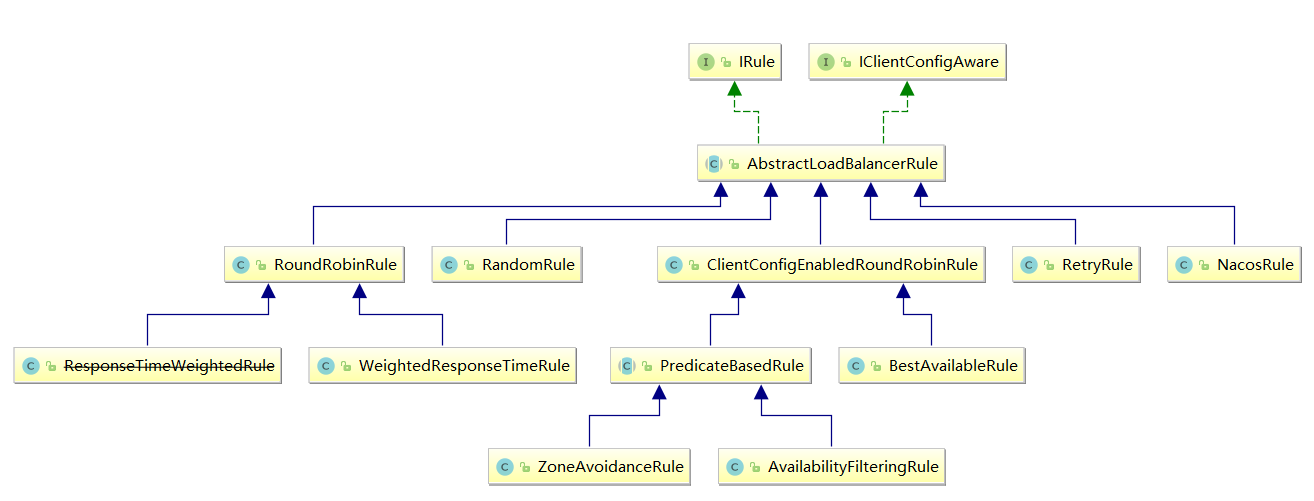
IRule
这是所有负载均衡策略的父接口,里边的核心方法就是choose方法,用来选择一个服务实例。
AbstractLoadBalancerRule
AbstractLoadBalancerRule是一个抽象类,里边主要定义了一个ILoadBalancer,这里定义它的目的主要是辅助负责均衡策略选取合适的服务端实例。
- RandomRule
看名字就知道,这种负载均衡策略就是随机选择一个服务实例,看源码我们知道,在RandomRule的无参构造方法中初始化了一个Random对象,然后在它重写的choose方法又调用了choose(ILoadBalancer lb, Object key)这个重载的choose方法,在这个重载的choose方法中,每次利用random对象生成一个不大于服务实例总数的随机数,并将该数作为下标所以获取一个服务实例。
- RoundRobinRule
RoundRobinRule这种负载均衡策略叫做线性轮询负载均衡策略。这个类的choose(ILoadBalancer lb, Object key)函数整体逻辑是这样的:开启一个计数器count,在while循环中遍历服务清单,获取清单之前先通过incrementAndGetModulo方法获取一个下标,这个下标是一个不断自增长的数先加1然后和服务清单总数取模之后获取到的(所以这个下标从来不会越界),拿着下标再去服务清单列表中取服务,每次循环计数器都会加
1,如果连续10次都没有取到服务,则会报一个警No available alive servers after 10 tries from load balancer: XXXX。
- RetryRule (在轮询的基础上进行重试)
看名字就知道这种负载均衡策略带有重试功能。首先RetryRule中又定义了一个subRule,它的实现类是RoundRobinRule,然后在RetryRule的choose(ILoadBalancer lb, Object key)方法中,每次还是采用RoundRobinRule中的choose规则来选择一个服务实例,如果选到的实例正常就返回,如果选择的服务实例为null或者已经失效,则在失效时间deadline之前不断的进行重试(重试时获取服务的策略还是RoundRobinRule中定义的策略),如果超过了deadline还是没取到则会返回一个null。
WeightedResponseTimeRule( 权重 —nacos的NacosRule ,Nacos还扩展了一个自己的基于配置的权重扩展 )WeightedResponseTimeRule是RoundRobinRule的一个子类,在WeightedResponseTimeRule中对RoundRobinRule的功能进行了扩展,WeightedResponseTimeRule中会根据每一个实例的运行情况来给计算出该实例的一个权重,然后在挑选实例的时候则根据权重进行挑选,这样能够实现更优的实例调用。WeightedResponseTimeRule中有一个名叫DynamicServerWeightTask的定时任务,默认情况下每隔30秒会计算一次各个服务实例的权重,权重的计算规则也很简单,如果一个服务的平均响应时间越短则权重越大,那么该服务实例被选中执行任务的概率也就越大。
ClientConfigEnabledRoundRobinRule
ClientConfigEnabledRoundRobinRule选择策略的实现很简单,内部定义了RoundRobinRule,choose方法还是采用了RoundRobinRule的choose方法,所以它的选择策略和RoundRobinRule的选择策略一致,不赘述。
- BestAvailableRule
BestAvailableRule继承自ClientConfigEnabledRoundRobinRule,它在ClientConfigEnabledRoundRobinRule的基础上主要增加了根据loadBalancerStats中保存的服务实例的状态信息来过滤掉失效的服务实例的功能,然后顺便找出并发请求最小的服务实例来使用。然而loadBalancerStats有可能为null,如果loadBalancerStats为null,则BestAvailableRule将采用它的父类即ClientConfigEnabledRoundRobinRule的服务选取策略(线性轮询)。
- ZoneAvoidanceRule ( 默认规则,复合判断server所在区域的性能和server的可用性选择服务器。 )
ZoneAvoidanceRule是PredicateBasedRule的一个实现类,只不过这里多一个过滤条件,ZoneAvoidanceRule中的过滤条件是以ZoneAvoidancePredicate为主过滤条件和以AvailabilityPredicate 为次过滤条件组成的一个叫做CompositePredicate的组合过滤条件,过滤成功之后,继续采用线性轮询( RoundRobinRule )的方式从过滤结果中选择一个出来。
AvailabilityFilteringRule(先过滤掉故障实例,再选择并发较小的实例)
过滤掉一直连接失败的被标记为circuit tripped的后端Server,并过滤掉那些高并发的后端Server或者使用一个AvailabilityPredicate来包含过滤server的逻辑,其实就是检查status里记录的各个Server的运行状态。
修改默认负载均衡策略
全局配置
@Configurationpublic class RibbonConfig {@Beanpublic IRule iRule(){return new NacosRule();}}
说明:不能写在@SpringbootApplication注解的@CompentScan扫描得到的地方,否则自定义的配置类就会被所有的RibbonClients共享。 不建议这么使用,推荐yml方式
自定义配置
@SpringBootApplication@RibbonClients(value = {@RibbonClient(name="ribbon-stock",configuration = RibbonRandomRuleConfig.class)})public class OrderRibbonApp {public static void main(String[] args) {SpringApplication.run(OrderRibbonApp.class,args);}}
RibbonRandomRuleConfig
@Configurationpublic class RibbonRandomRuleConfig {/*** 方法名一定要叫iRule* @date: 2021/12/3 16:49* @return: com.netflix.loadbalancer.IRule*/@Beanpublic IRule iRule(){return new RandomRule();}}
yml 配置
# 被调用的微服务名ribbon-stock:ribbon:# 指定使用Nacos提供的负载均衡策略(优先调用同一集群的实例,基于随机&权重)NFLoadBalancerRuleClassName: com.zlp.ribbon.rule
public class CustomRule extends AbstractLoadBalancerRule {@Overridepublic Server choose(Object key) {ILoadBalancer loadBalancer = this.getLoadBalancer();// 获得当前请求的服务的实例List<Server> reachableServers = loadBalancer.getReachableServers();int random=ThreadLocalRandom.current().nextInt(reachableServers.size());Server server = reachableServers.get(random);// if(server.isAlive()){// return null;// }return server;}@Overridepublic void initWithNiwsConfig(IClientConfig iClientConfig) {}}
Ribbon内核原理
OpenFeign
JAVA 项目中如何实现接口调用?
Httpclient
HttpClient 是 Apache Jakarta Common 下的子项目,用来提供高效的、最新的、功能丰富的支持 Http 协议的客户端编程工具包,并且它支持 HTTP 协议最新版本和建议。HttpClient相比传统 JDK 自带的 URLConnection,提升了易用性和灵活性,使客户端发送 HTTP 请求变得容易,提高了开发的效率。
Okhttp
一个处理网络请求的开源项目,是安卓端最火的轻量级框架,由 Square 公司贡献,用于替代HttpUrlConnection 和 Apache HttpClient。OkHttp 拥有简洁的 API、高效的性能,并支持多种协议(HTTP/2 和 SPDY)。
HttpURLConnection
HttpURLConnection 是 Java 的标准类,它继承自 URLConnection,可用于向指定网站发送GET 请求、POST 请求。HttpURLConnection 使用比较复杂,不像 HttpClient 那样容易使用。
RestTemplate
RestTemplate 是 Spring 提供的用于访问 Rest 服务的客户端,RestTemplate 提供了多种便捷访问远程 HTTP 服务的方法,能够大大提高客户端的编写效率。上面介绍的是最常见的几种调用接口的方法,我们下面要介绍的方法比上面的更简单、方便,它就是 Feign。
什么是Feign
Feign是Netflix开发的声明式、模板化的HTTP客户端,其灵感来自Retrofit、JAXRS-2.0以及WebSocket。Feign可帮助我们更加便捷、优雅地调用HTTP API。
Feign支持多种注解,例如Feign自带的注解或者JAX-RS注解等。
Spring Cloud openfeign 对Feign进行了增强,使其支持Spring MVC注解,另外还整合了 Ribbon 和 Nacos,从而使得Feign的使用更加方便
优势
Feign 可以做到使用 HTTP 请求远程服务时就像调用本地方法一样的体验,开发者完全感知不到这是远程方法,更感知不到这是个 HTTP 请求。它像 Dubbo 一样,consumer 直接调用接口方法调用 provider,而不需要通过常规的 Http Client 构造请求再解析返回数据。它解决了让开发者调用远程接口就跟调用本地方法一样,无需关注与远程的交互细节,更无需关注分布式环境开发。
Spring Cloud Alibaba 快速整合 OpenFeign
引入依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency>
编写调用接口+@FeignClient注解
@FeignClient(value="feign-stock",contextId = "FeignStockService",path = "stock")public interface FeignStockService {@GetMapping("/reductStock")String reductStock();}
调用端在启动类上添加 @EnableFeignClients 注解
@EnableFeignClients@SpringBootApplicationpublic class FeignOrderApp {public static void main(String[] args) {SpringApplication.run(FeignOrderApp.class,args);}}
发起调用
@RestController@RequestMapping("order")@RequiredArgsConstructorpublic class OrderController {private final FeignStockService feignStockService;@GetMapping("addOrder")public String addOrder(){String stock = feignStockService.reductStock();return "order remoe call feign stock=>"+stock;}}
Spring Cloud Feign 的自定义配置及使用
Feign 提供了很多的扩展机制,让用户可以更加灵活的使用。
日志配置
有时候我们遇到 Bug,比如接口调用失败、参数没收到等问题,或者想看看调用性能,就需要
配置 Feign 的日志了,以此让 Feign 把请求信息输出来。
定义一个配置类,指定日志级别
/*** 此处配置@Configuration注解就会全局生效,如果想指定对应微服务生效,就不能配置* @date: 2021/12/7 20:03* @return:*/@Configurationpublic class FeignConfig {/*** 日志级别* <p>* 1. NONE【性能最佳,适用于生产】:不记录任何日志(默认值)。* 2. BASIC【适用于生产环境追踪问题】:仅记录请求方法、URL、响应状态代码以及* 执行时间。* 3. HEADERS:记录BASIC级别的基础上,记录请求和响应的header。* 4. FULL【比较适用于开发及测试环境定位问题】:记录请求和响应的header、body* 和元数据。* </p>* @date: 2021/12/6 20:40* @return: feign.Logger.Level*/@Beanpublic Logger.Level feignLoggerLevel(){return Logger.Level.BASIC;}}
通过源码可以看到日志等级有 4 种,分别是:
- NONE【性能最佳,适用于生产】:不记录任何日志(默认值)。
- BASIC【适用于生产环境追踪问题】:仅记录请求方法、URL、响应状态代码以及执行时间。
- HEADERS:记录BASIC级别的基础上,记录请求和响应的header。
- FULL【比较适用于开发及测试环境定位问题】:记录请求和响应的header、body 和元数据。
局部配置
让调用的微服务生效,在@FeignClient 注解中指定使用的配置类
/*** FeignStockService* @date: 2021/12/6 20:32*/@FeignClient(value="feign-stock",contextId = "FeignStockService",path = "stock",configuration = FeignConfig.class)public interface FeignStockService {@GetMapping("/reductStock")String reductStock();}
在 yml配置文件中执行 Client 的日志级别才能正常输出日志
# 日志logging:level:com.zlp.feign.order.feign: debug
BASIC 级别日志

契约配置
Spring Cloud 在 Feign 的基础上做了扩展,使用 Spring MVC 的注解来完成Feign的功
能。原生的 Feign 是不支持 Spring MVC 注解的,如果你想在 Spring Cloud 中使用原生的
注解方式来定义客户端也是可以的,通过配置契约来改变这个配置,Spring Cloud 中默认的
是 SpringMvcContract。
Spring Cloud 1 早期版本就是用的原生Fegin. 随着netflix的停更替换成了Open feign
修改契约配置,支持Feign原生的注解
/*** 修改契约配置,支持Feign原生的注解* @return*/@Beanpublic Contract feignContract() {return new Contract.Default();}
注意:修改契约配置后,OrderFeignService 不再支持springmvc的注解,需要使用Feign原生的注解
OrderFeignService 中配置使用Feign原生的注解
@FeignClient(value = "mall‐order",path = "/order")public interface OrderFeignService {@RequestLine("GET /findOrderByUserId/{userId}")public R findOrderByUserId(@Param("userId") Integer userId);}
自定义拦截器实现认证逻辑
控制拦截
/*** Feign 请求头拦截* @date: 2021/12/6 21:01*/@Configuration@Slf4j(topic = "FeignRequestInterceptor")public class FeignRequestInterceptor implements RequestInterceptor {@Overridepublic void apply(RequestTemplate requestTemplate) {String accessToken = UUID.randomUUID().toString();log.info("accessToken={}",accessToken);requestTemplate.header("Authorization",accessToken);}}
控制台输出

超时时间配置
通过 Options 可以配置连接超时时间和读取超时时间,Options 的第一个参数是连接的超时
时间(ms),默认值是 2s;第二个是请求处理的超时时间(ms),默认值是 5s。
全局配置
/*** 超时配置* @date: 2021/12/7 20:20* @return: feign.Request.Options*/@Beanpublic Request.Options options() {return new Request.Options(5000, 10000);}
yml 中配置
feign:client:config:# 连接超时时间,默认2sconnectTimeout: 5000# 请求处理超时时间,默认5sreadTimeout: 10000
测试超时情况:

Sentienl
分布式遇到的问题
服务的可用性问题
 服务的可用性场景
服务的可用性场景

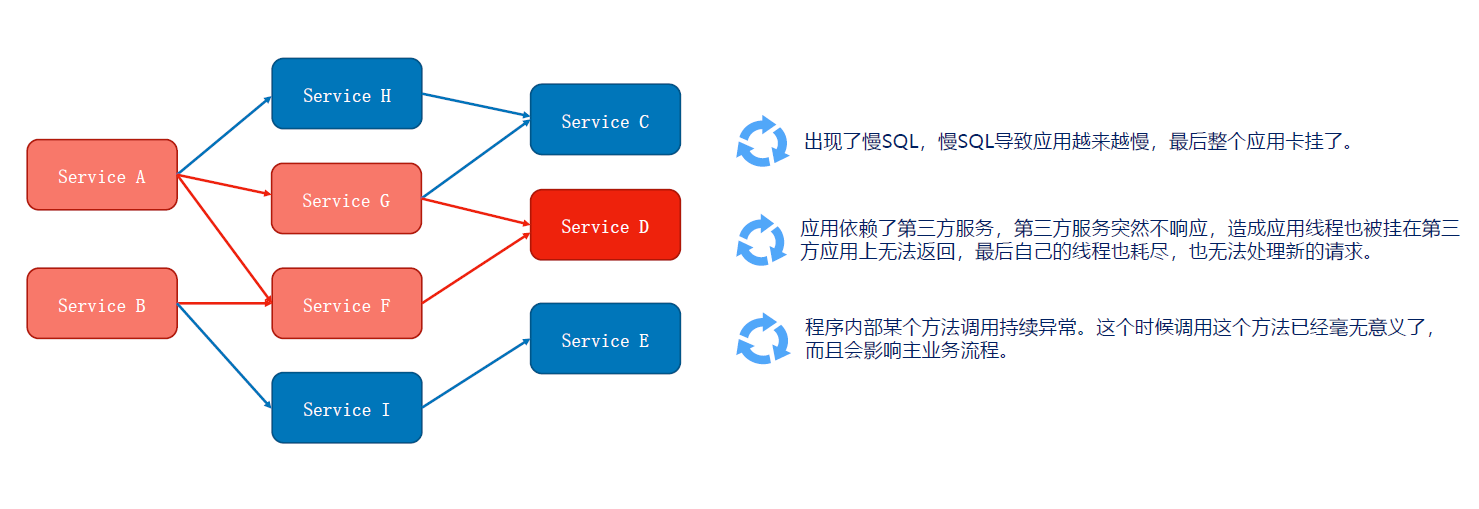
如果其中的下单服务不可用, 就会出现线程池里所有线程都因等待响应而被阻塞, 从而造成整个服务链路不可用, 进而导致整个系统的服务雪崩. 如图所示: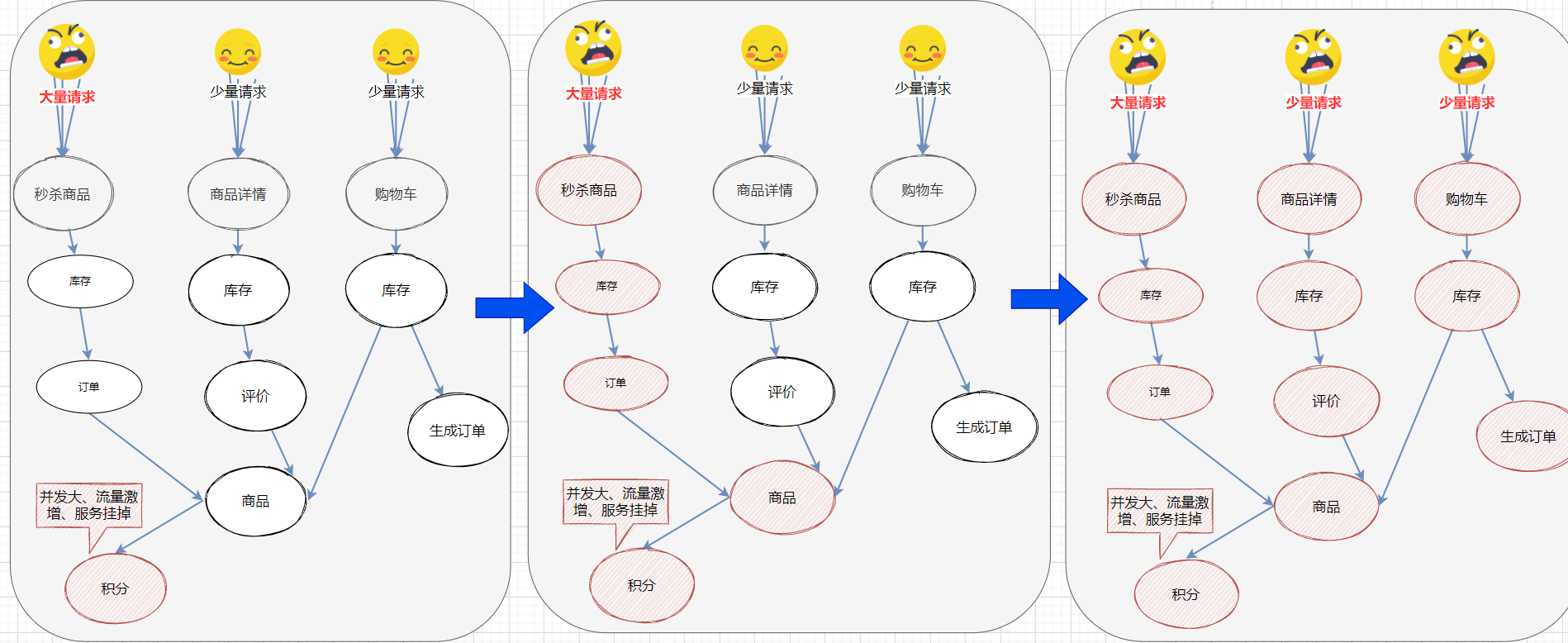
服务雪崩效应:因服务提供者的不可用导致服务调用者的不可用,并将不可用逐渐放大的过程,就叫服务雪崩效应
导致服务不可用的原因:

在服务提供者不可用的时候,会出现大量重试的情况:用户重试、代码逻辑重试,这些重试最终导致:进一步加大请求流量。所以归根结底导致雪崩效应的最根本原因是:大量请求线程同步等待造成的资源耗尽。当服务调用者使用同步调用时, 会产生大量的等待线程占用系统资源。一旦线程资源被耗尽,服务调用者提供的服务也将处于不可用状态, 于是服务雪崩效应产生了。
解决方案

常见的容错机制:
超时机制
在不做任何处理的情况下,服务提供者不可用会导致消费者请求线程强制等待,而造成系统资源耗尽。加入超时机制,一旦超时,就释放资源。由于释放资源速度较快,一定程度上可以抑制资源耗尽的问题。
服务限流
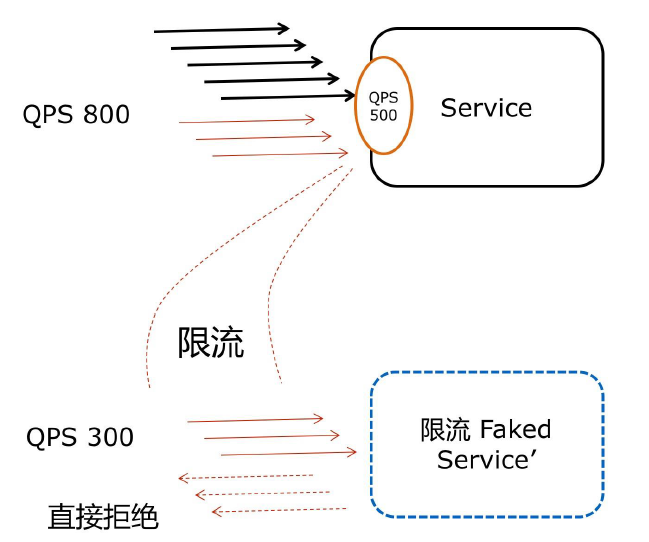
隔离
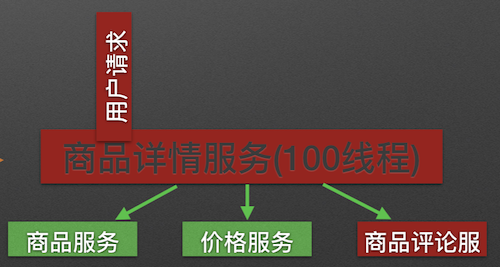
原理:用户的请求将不再直接访问服务,而是通过线程池中的空闲线程来访问服务,如果线程池已满,则会进行降级处理,用户的请求不会被阻塞,至少可以看到一个执行结果(例如返回友好的提示信息),而不是无休止的等待或者看到系统崩溃。
隔离前: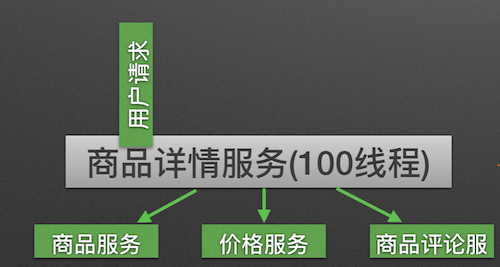
隔离后: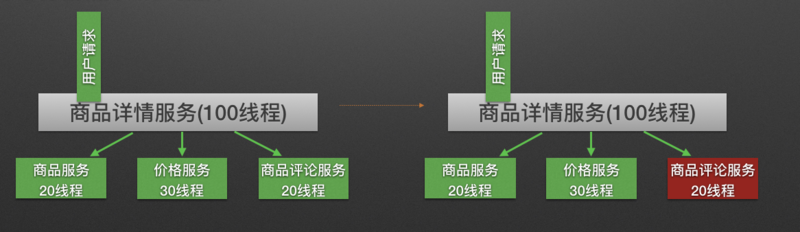
信号隔离:
信号隔离也可以用于限制并发访问,防止阻塞扩散, 与线程隔离最大不同在于执行依赖代码的线程依然是请求线程(该线程需要通过信号申请, 如果客户端是可信的且可以快速返回,可以使用信号隔离替换线程隔离,降低开销。信号量的大小可以动态调整, 线程池大小不可以。
服务熔断
远程服务不稳定或网络抖动时暂时关闭,就叫服务熔断。
现实世界的断路器大家肯定都很了解,断路器实时监控电路的情况,如果发现电路电流异常,就会跳闸,从而防止电路被烧毁。
软件世界的断路器可以这样理解:实时监测应用,如果发现在一定时间内失败次数/失败率达到一定阈值,就“跳闸”,断路器打开——此时,请求直接返回,而不去调用原本调用的逻辑。跳闸一段时间后(例如10秒),断路器会进入半开状态,这是一个瞬间态,此时允许一次请求调用该调的逻辑,如果成功,则断路器关闭,应用正常调用;如果调用依然不成功,断路器继续回到打开状态,过段时间再进入半开状态尝试——通过”跳闸“,应用可以保护自己,而且避免浪费资源;而通过半开的设计,可实现应用的“自我修复“。
所以,同样的道理,当依赖的服务有大量超时时,在让新的请求去访问根本没有意义,只会无畏的消耗现有资源。比如我们设置了超时时间为1s,如果短时间内有大量请求在1s内都得不到响应,就意味着这个服务出现了异常,此时就没有必要再让其他的请求去访问这个依赖了,这个时候就应该使用断路器避免资源浪费.
 服务降级
服务降级
有服务熔断,必然要有服务降级。
所谓降级,就是当某个服务熔断之后,服务将不再被调用,此时客户端可以自己准备一个本地的fallback(回退)回调,返回一个缺省值。 例如:(备用接口/缓存/mock数据) 。这样做,虽然服务水平下降,但好歹可用,比直接挂掉要强,当然这也要看适合的业务场景。

Sentinel 分布式系统流量防卫系统
Sentinel 是什么
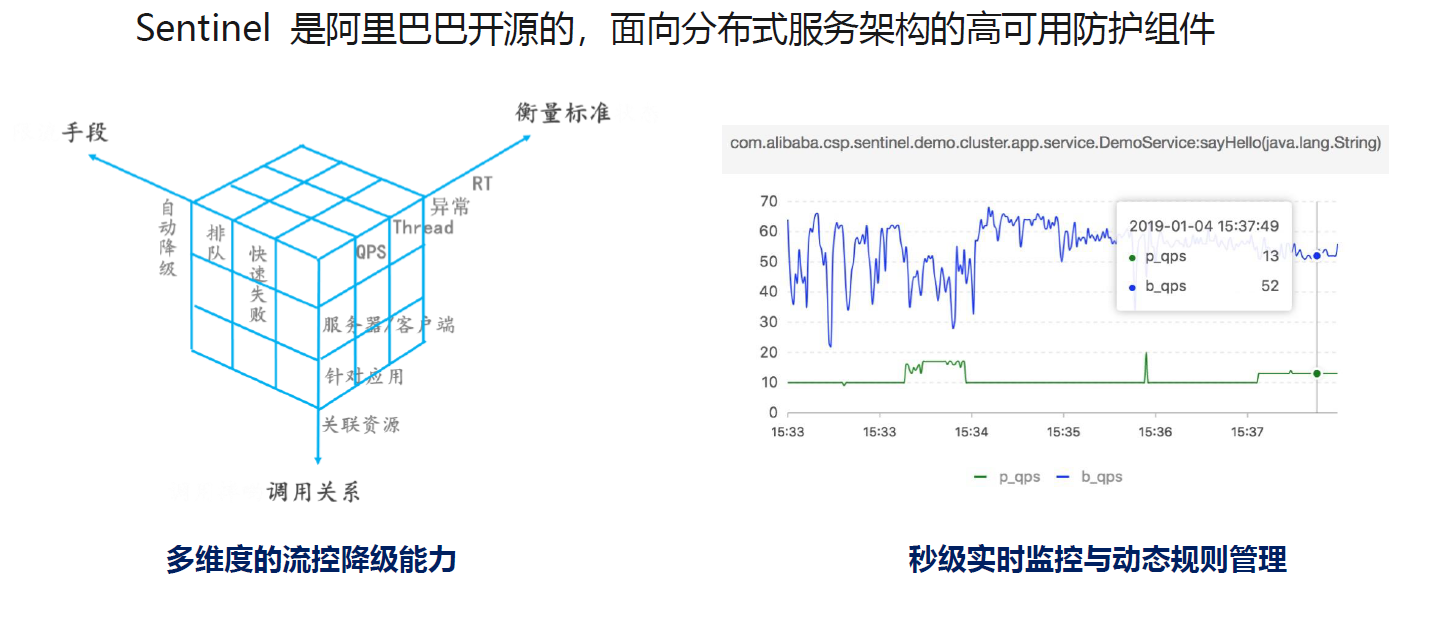
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 是面向分布式服务架构的流量控制组件,主要以流量为切入点,从限流、流量整形、熔断降级、系统负载保护、热点防护等多个维度来帮助开发者保障微服务的稳定性。
源码地址:https://github.com/alibaba/Sentinel
官方文档:https://github.com/alibaba/Sentinel/wiki
Sentinel具有以下特征:
- 丰富的应用场景: Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、实时熔断下游不可用应用等。
- 完备的实时监控: Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
- 广泛的开源生态: Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
- 完善的 SPI 扩展点: Sentinel 提供简单易用、完善的 SPI 扩展点。您可以通过实现扩展点,快速的定制逻辑。例如定制规则管理、适配数据源等。
Sentinel和Hystrix对比
https://github.com/alibaba/Sentinel/wiki/Sentinel%E4%B8%8EHystrix%E7%9A%84%E5%AF%B9%E6%AF%94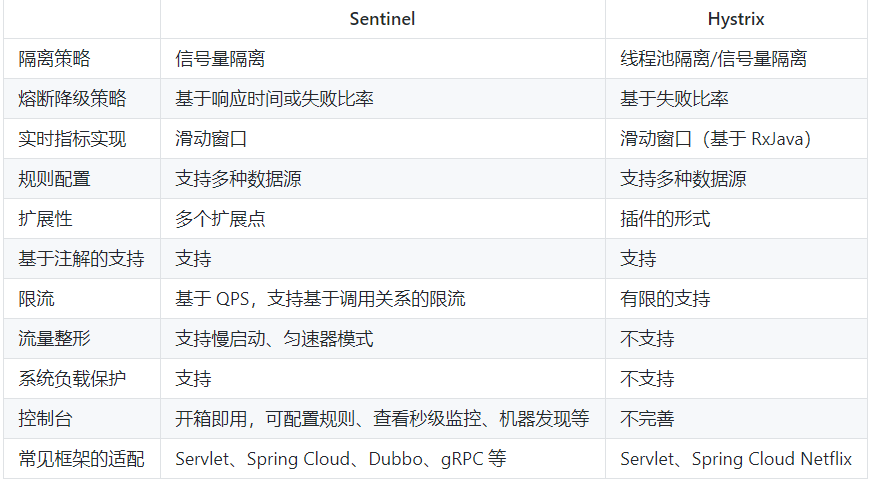
Sentinel 快速开始
https://github.com/alibaba/Sentinel/wiki/%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8
在官方文档中,定义的Sentinel进行资源保护的几个步骤:
1. 定义资源
2. 定义规则
3. 检验规则是否生效
Entry entry = null;// 务必保证 finally 会被执行try {// 资源名可使用任意有业务语义的字符串,注意数目不能太多(超过 1K),超出几千请作为参数传入而不要直接作为资源名// EntryType 代表流量类型(inbound/outbound),其中系统规则只对 IN 类型的埋点生效entry = SphU.entry("自定义资源名");// 被保护的业务逻辑// do something...} catch (BlockException ex) {// 资源访问阻止,被限流或被降级// 进行相应的处理操作} catch (Exception ex) {// 若需要配置降级规则,需要通过这种方式记录业务异常Tracer.traceEntry(ex, entry);} finally {// 务必保证 exit,务必保证每个 entry 与 exit 配对if (entry != null) {entry.exit();}}
Sentinel资源保护的方式
引入依赖
<dependency><groupId>com.alibaba.csp</groupId><artifactId>sentinel‐core</artifactId><version>1.8.0</version></dependency>
编写测试逻辑
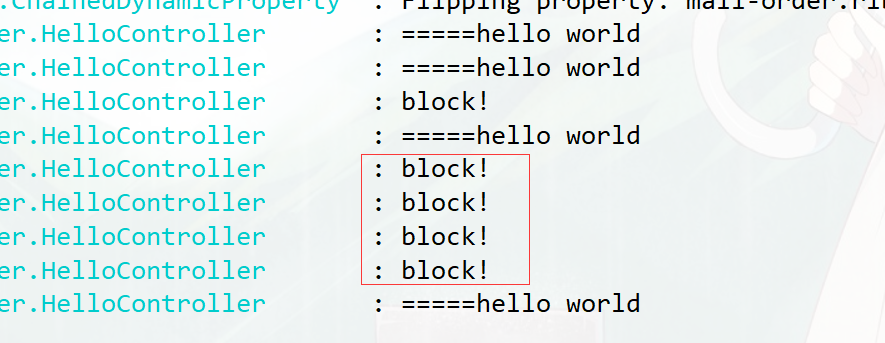
@RestController@Slf4j(topic = "HelloController")public class HelloController {private static final String RESOURCE_NAME = "hello";@RequestMapping(value = "/hello")public String hello() {Entry entry = null;try {// 资源名可使用任意有业务语义的字符串,比如方法名、接口名或其它可唯一标识的字符串。entry = SphU.entry(RESOURCE_NAME);// 被保护的业务逻辑String str = "hello world";log.info("=====" + str);return str;} catch (BlockException e1) {// 资源访问阻止,被限流或被降级//进行相应的处理操作log.info("block!");} catch (Exception ex) {// 若需要配置降级规则,需要通过这种方式记录业务异常Tracer.traceEntry(ex, entry);} finally {if (entry != null) {entry.exit();}}return null;}/*** 定义流控规则*/@PostConstructprivate static void initFlowRules() {List<FlowRule> rules = new ArrayList<>();FlowRule rule = new FlowRule();//设置受保护的资源rule.setResource(RESOURCE_NAME);// 设置流控规则 QPSrule.setGrade(RuleConstant.FLOW_GRADE_QPS);// 设置受保护的资源阈值// Set limit QPS to 20.rule.setCount(1);rules.add(rule);// 加载配置好的规则FlowRuleManager.loadRules(rules);}}
测试效果
缺点:
- 业务侵入性很强,需要在controller中写入非业务代码.
- 配置不灵活 若需要添加新的受保护资源 需要手动添加 init方法来添加流控规则
Sentinel 控制台
下载控制台 jar 包并在本地启动:可以参见 此处文档
https://github.com/alibaba/Sentinel/releases
启动控制台命令
java -jar sentinel‐dashboard‐1.8.0.jar
用户可以通过如下参数进行配置:
-Dsentinel.dashboard.auth.username=sentinel 用于指定控制台的登录用户名为 sentinel ;
-Dsentinel.dashboard.auth.password=123456 用于指定控制台的登录密码为 123456 ;如果省略这两个参数,默认用户和密码均为sentinel ;
-Dserver.servlet.session.timeout=7200 用于指定 Spring Boot 服务端 session 的过期时间,如 7200 表示 7200 秒; 60m 表示 60 分钟,默认为 30 分钟;
为了方便快捷启动可以在桌面创建.bat 文件
java -Dserver.port=8858 -Dsentinel.dashboard.auth.username=sentinel -Dsentinel.dashboard.auth.password=sentinel -jar D:\javaTools\Alibaba\sentinel\sentinel-dashboard-1.8.0.jarpaus
登入界面
访问http://127.0.0.1:8858 ,默认用户名密码: sentinel/sentinel
Sentinel 会在客户端首次调用的时候进行初始化,开始向控制台发送心跳包,所以要确保客户端有访问量;
Spring Cloud Alibaba 整合 Sentinel
引入依赖
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId></dependency><!--加入actuator--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency>
添加yml配置
为微服务设置 sentinel 控制台地址添加Sentinel后,需要暴露/actuator/sentinel端点,而Springboot默认是没有暴露该端点的,所以需要设置,测试 http://localhost:9110/actuator/sentinel
server:## 启动端口port: 9110spring:application:## 注册服务名name: sentinel-ordercloud:nacos:## 注册中心地址discovery:server-addr: 127.0.0.1:8848## sentinel configsentinel:transport:dashboard: localhost:8858main:allow-bean-definition-overriding: true## 暴露端点management:endpoints:web:exposure:include: '*'
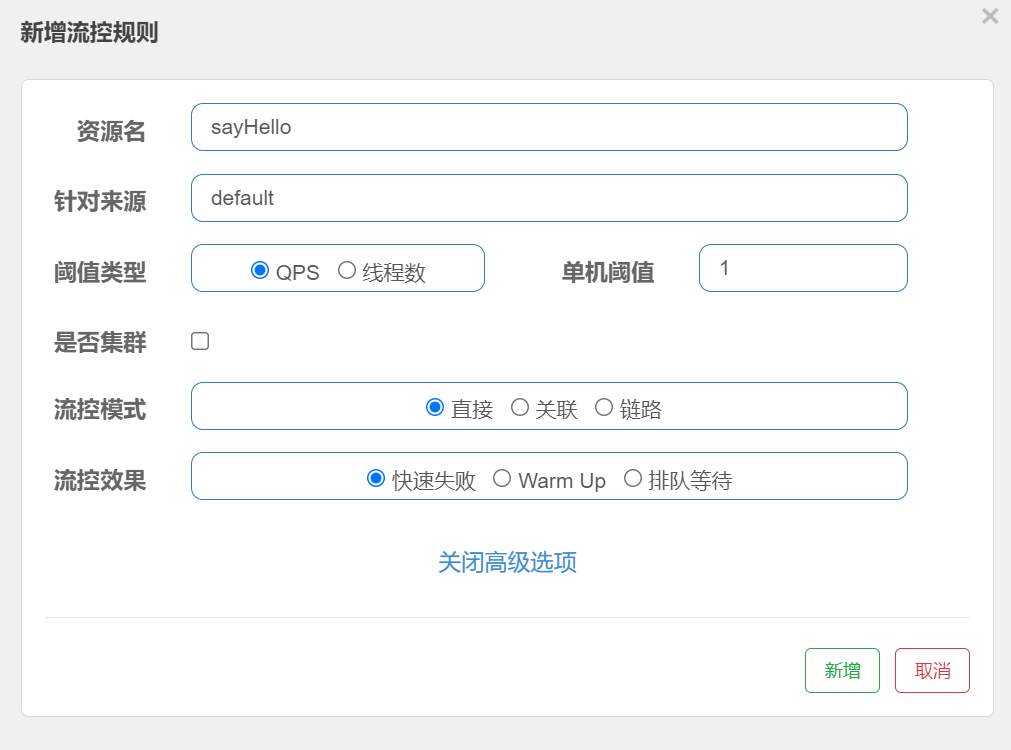
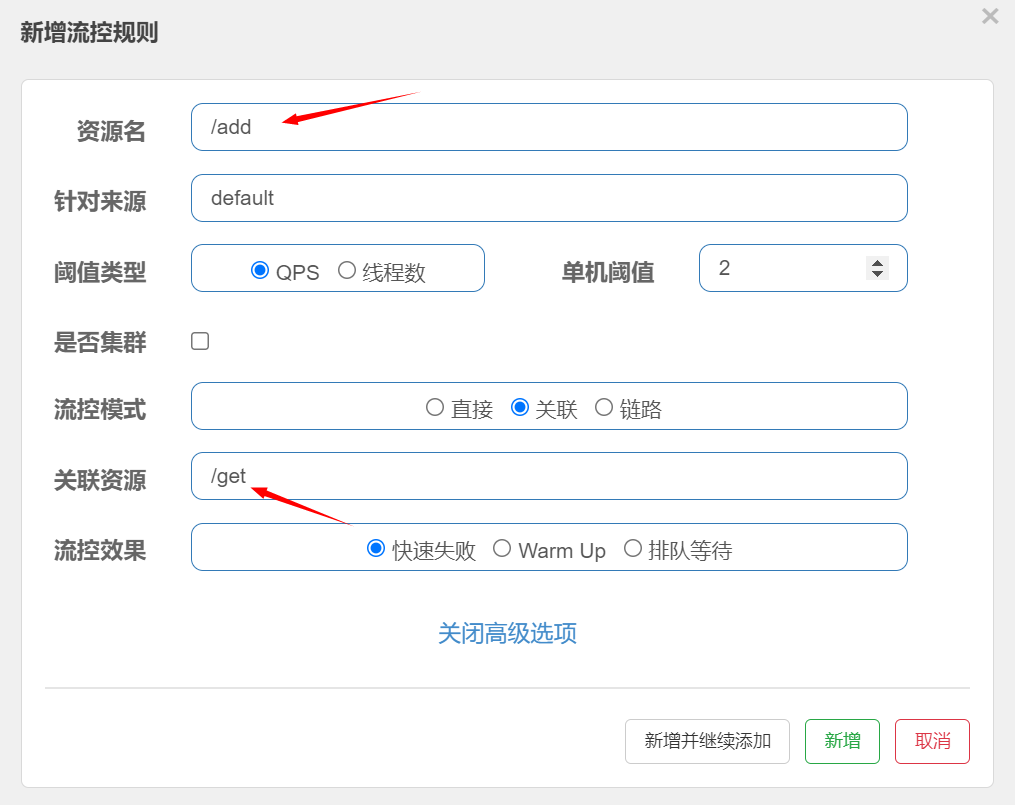
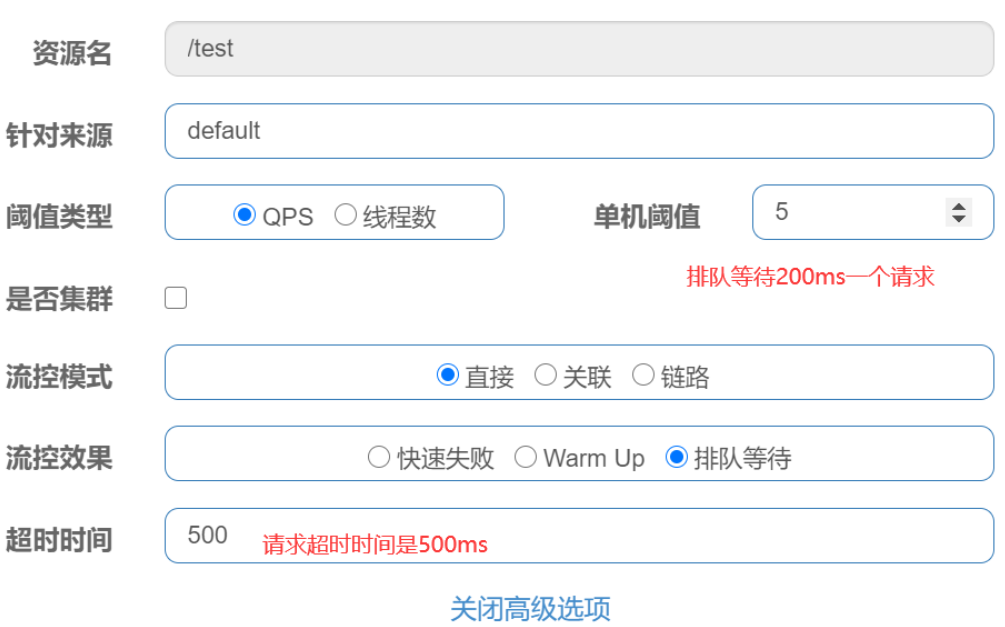
在sentinel控制台中设置流控规则
sentinel 控制台中设置流控规则
- 资源名: 接口的API
- 针对来源: 默认是default,当多个微服务都调用这个资源时,可以配置微服务名来对指定的微服务设置阈值
- 阈值类型: 分为QPS和线程数 假设阈值为10
- QPS类型: 只得是每秒访问接口的次数>10就进行限流
- 线程数: 为接受请求该资源分配的线程数>10就进行限流
QPS 流控
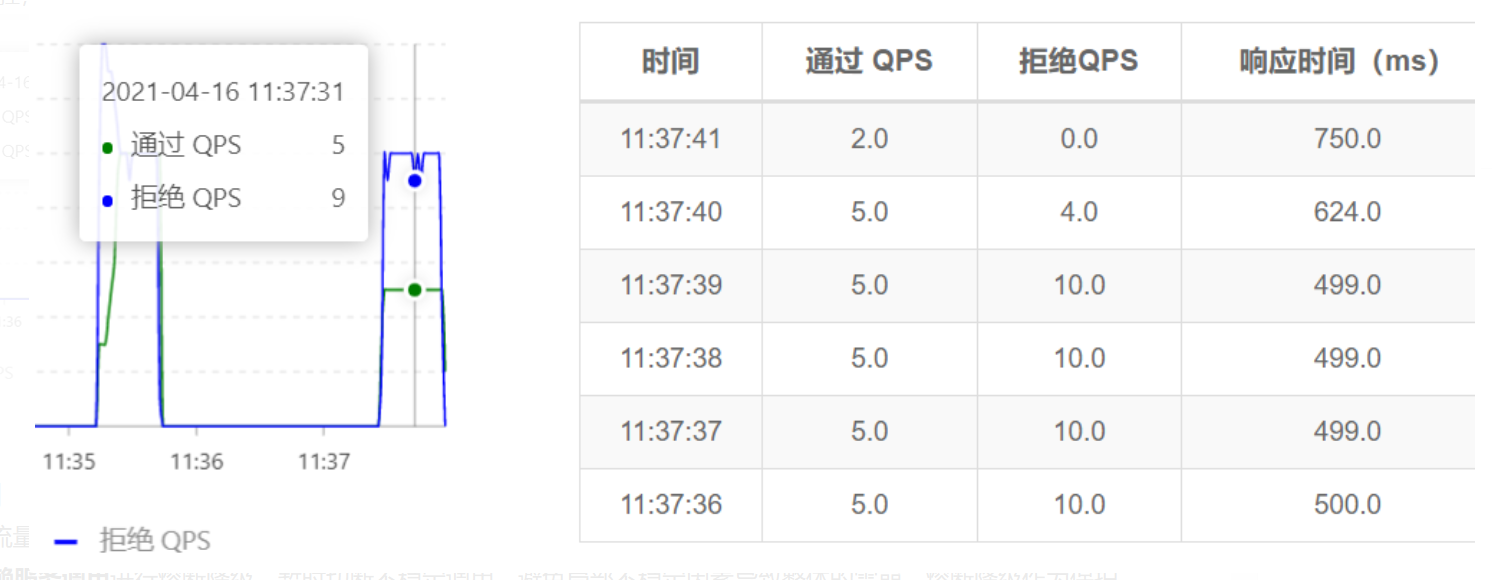
测试: 因为QPS是1,所以1秒内多次访问会出现如下情形: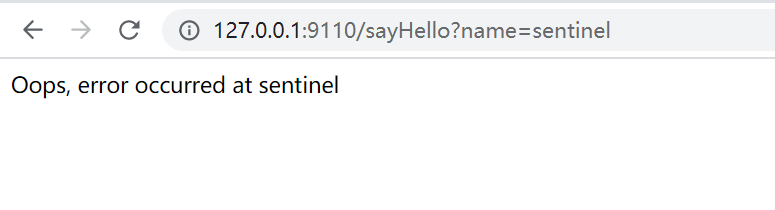
在访问 http://localhost:9110/actuator/sentinel 可以查看 flowRules (流控规则)
{"blockPage": null,"appName": "sentinel-order","consoleServer": [{"r1": "localhost","r2": 8858}],"coldFactor": "3","rules": {"systemRules": [],"authorityRule": [],"paramFlowRule": [],"flowRules": [{"resource": "sayHello","limitApp": "default","grade": 1,"count": 1.0,"strategy": 0,"refResource": null,"controlBehavior": 0,"warmUpPeriodSec": 10,"maxQueueingTimeMs": 500,"clusterMode": false,"clusterConfig": {"flowId": null,"thresholdType": 0,"fallbackToLocalWhenFail": true,"strategy": 0,"sampleCount": 10,"windowIntervalMs": 1000}}],"degradeRules": []},"metricsFileCharset": "UTF-8","filter": {"order": -2147483648,"urlPatterns": ["/**"],"enabled": true},"totalMetricsFileCount": 6,"datasource": {},"clientIp": "192.168.6.92","clientPort": "8720","logUsePid": false,"metricsFileSize": 52428800,"logDir": "C:\\Users\\user.DESKTOP-8A9L631\\logs\\csp\\","heartbeatIntervalMs":10000}
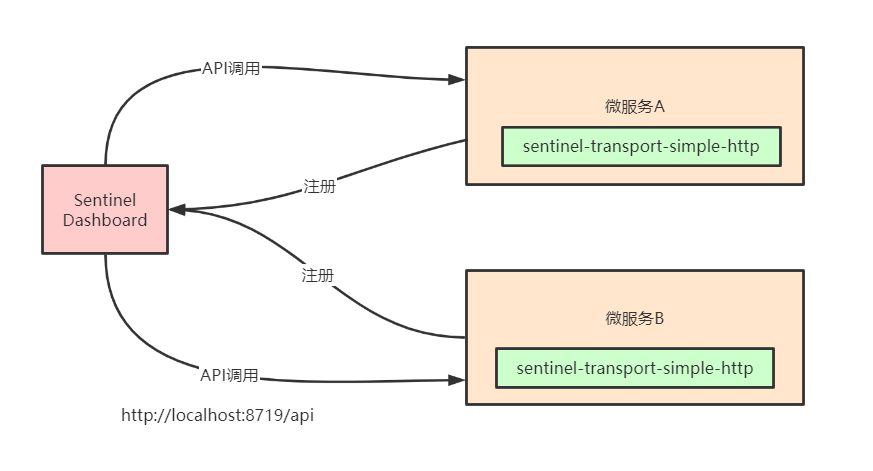
微服务和Sentinel Dashboard通信原理
Sentinel控制台与微服务端之间,实现了一套服务发现机制,集成了Sentinel的微服务都会将元数据传递给Sentinel控制台,架构图如下所示:
流控针对privoder 熔断降级 针对consumer
实时监控
监控接口的通过的QPS和拒绝的QPS 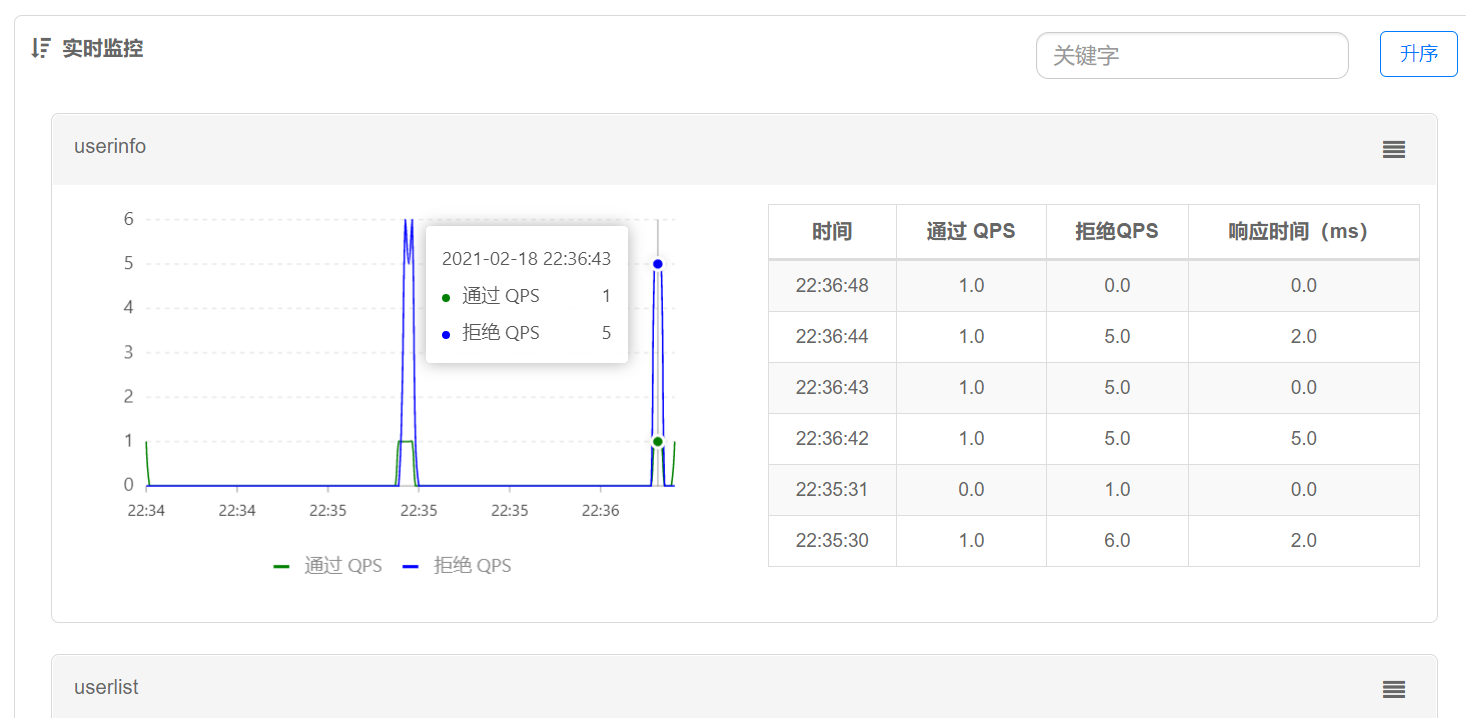
簇点链路
用来显示微服务的所监控的API

流控规则
流量控制
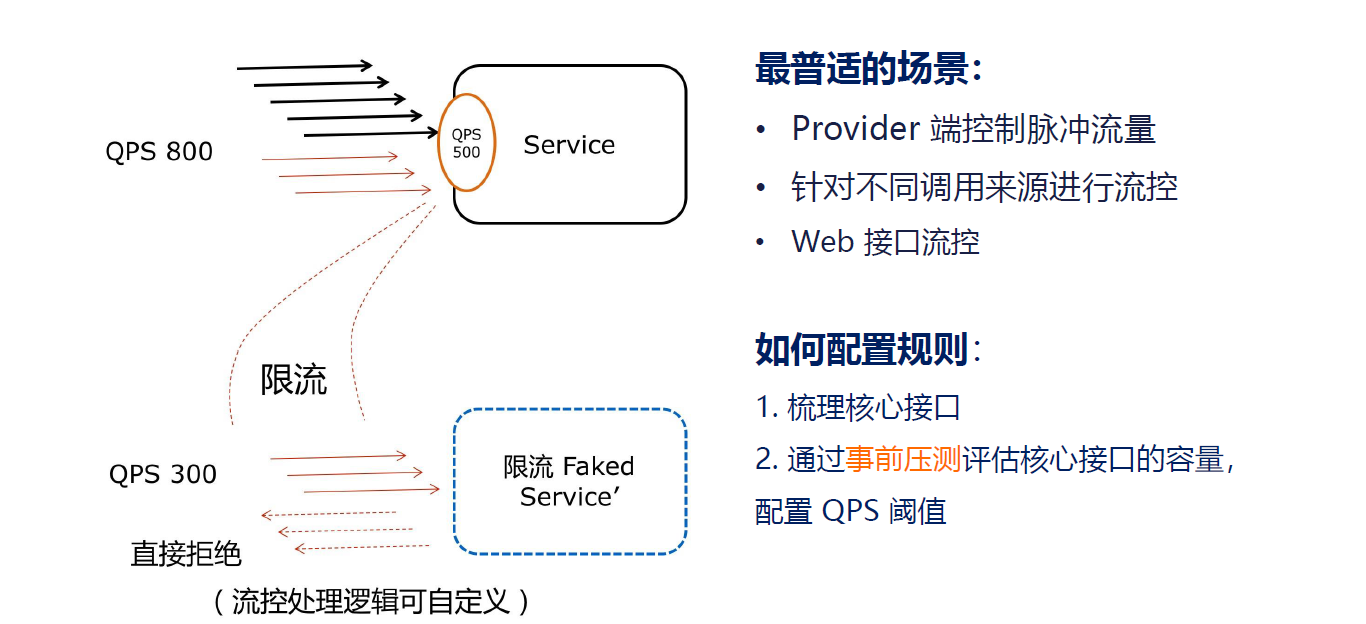
其原理是监控应用流量的 QPS 或并发线程数等指标,当达到指定的阈值时对流量进行控制,
以避免被瞬时的流量高峰冲垮,从而保障应用的高可用性。
FlowRule RT(响应时间) 1/0.2s =5 
同一个资源可以创建多条限流规则。 FlowSlot 会对该资源的所有限流规则依次遍历,直到有规则触发限流或者所有规则遍历完毕。一条限流规则主要由下面几个因素组成,我们可以组合这些元素来实现不同的限流效果。
- resource:资源名,即限流规则的作用对象
- count: 限流阈值
- grade: 限流阈值类型(QPS 或并发线程数)
- limitApp: 流控针对的调用来源,若为 default 则不区分调用来源
- strategy: 调用关系限流策略
- controlBehavior: 流量控制效果(直接拒绝、Warm Up、匀速排队)
参考文档: https://github.com/alibaba/Sentinel/wiki/%E6%B5%81%E9%87%8F%E6%8E%A7%E5%88%B6
限流阈值类型
QPS(Query Per Second):每秒请求数,就是说服务器在一秒的时间内处理了多少个请求。
进入簇点链路选择具体的访问的API,然后点击流控按钮 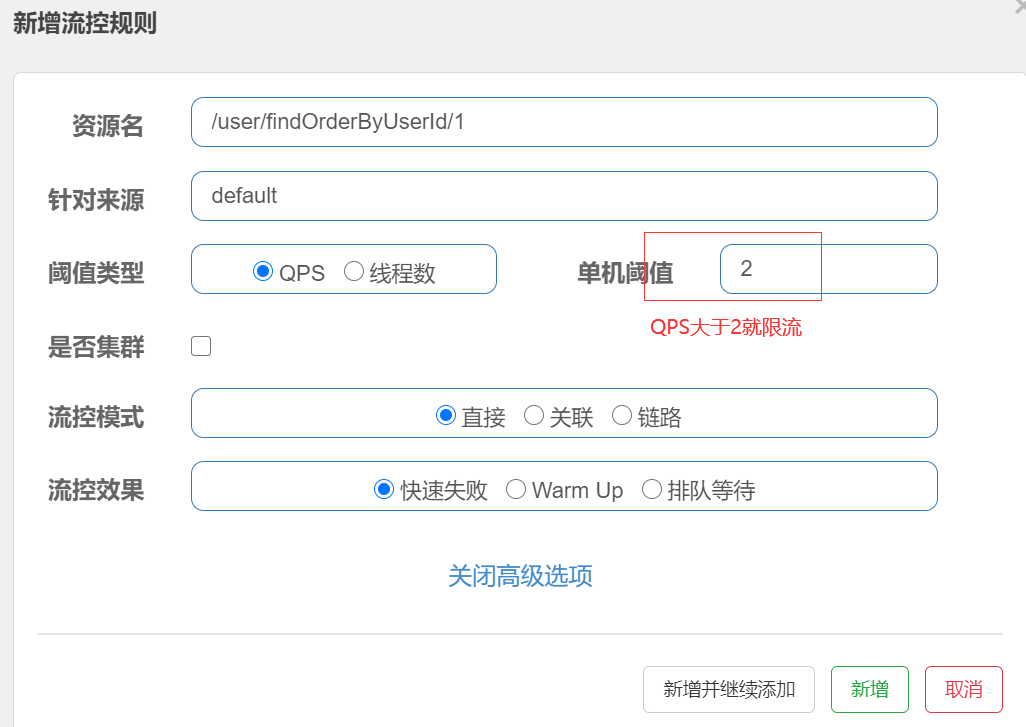
并发线程数
并发数控制用于保护业务线程池不被慢调用耗尽。例如,当应用所依赖的下游应用由于某种原因导致服务不稳定、响应延迟增加,对于调用者来说,意味着吞吐量下降和更多的线程数占用,极端情况下甚至导致线程池耗尽。为应对太多线程占用的情况,业内有使用隔离的方案,比如通过不同业务逻辑使用不同线程池来隔离业务自身之间的资源争抢(线程池隔离)。这种隔离方案虽然隔离性比较好,但是代价就是线程数目太多,线程上下文切换的 overhead 比较大,特别是对低延时的调用有比较大的影响。Sentinel 并发控制不负责创建和管理线程池,而是简单统计当前请求上下文的线程数目(正在执行的调用数目),如果超出阈值,新的请求会被立即拒绝,效果类似于信号量隔离。并发数控制通常在调用端进行配置。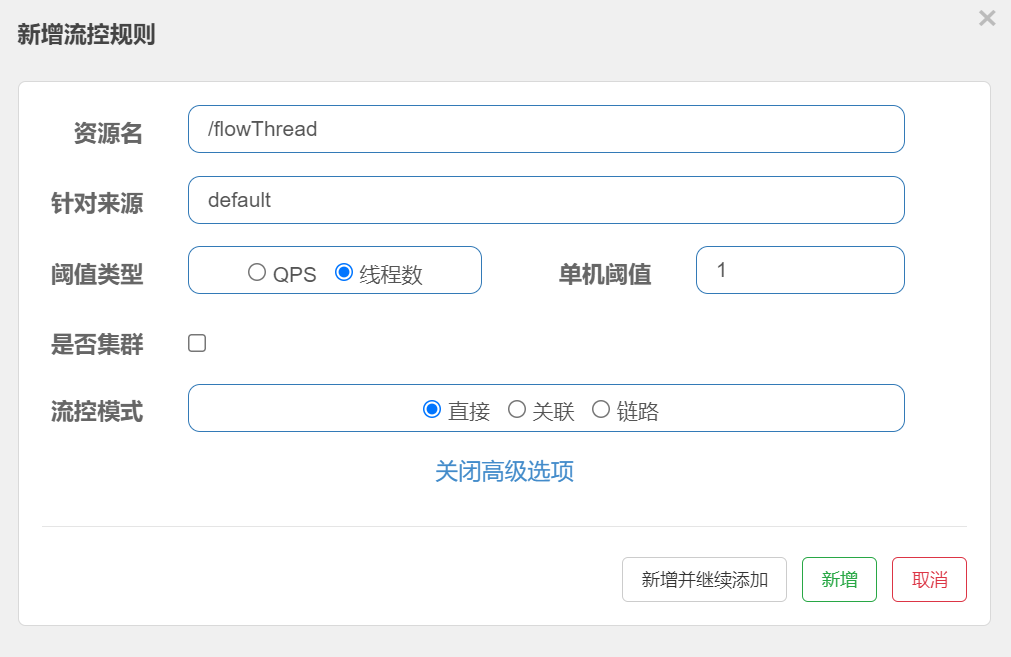
我们让代码休眠2s钟,连续访问接口 http://127.0.0.1:9110/flowThread
@GetMapping("/flowThread")public String flowThread() throws InterruptedException {TimeUnit.SECONDS.sleep(2);log.info("flowThread======>正常访问");return "正常访问";}
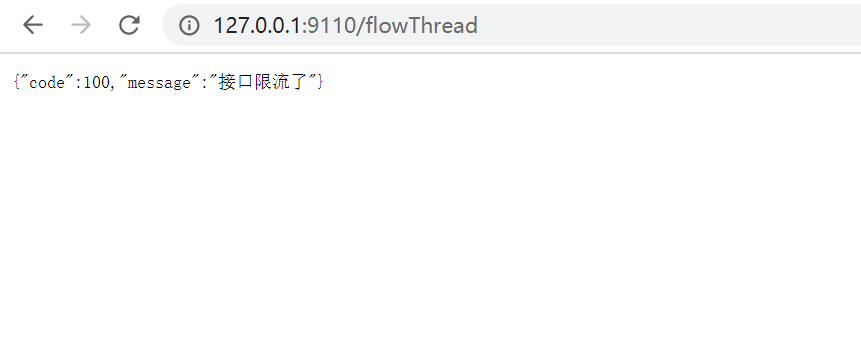
BlockException 异常统一处理
Springwebmvc 接口资源限流入口在 HandlerInterceptor的实现类 AbstractSentinelInterceptor 的preHandle方
法中,对异常的处理是 BlockExceptionHandler 的实现类
自定义BlockExceptionHandler 的实现类统一处理BlockException
/*** 自定义sentinel统一异常* @date: 2021/11/11 11:22*/@Component@Slf4j(topic = "MyBlockExceptionHandler")public class MyBlockExceptionHandler implements BlockExceptionHandler {@Overridepublic void handle(HttpServletRequest httpServletRequest, HttpServletResponse response, BlockException e) throws Exception {log.info("handle BlockException:{}",e.getRule());RespCode respCode = null;if (e instanceof FlowException){respCode = RespCode.FLOW_EXCEPTION;}else if (e instanceof DegradeException) {respCode = RespCode.DEGRADE_EXCEPTION;}else if (e instanceof ParamFlowException) {respCode = RespCode.PARAM_FLOW_EXCEPTION;}else if (e instanceof SystemBlockException) {respCode = RespCode.SYSTEM_BLOCK_EXCEPTION;}else if (e instanceof AuthorityException) {respCode = RespCode.AUTHORITY_EXCEPTION;}response.setStatus(500);response.setCharacterEncoding("utf-8");response.setContentType(MediaType.APPLICATION_JSON_VALUE);response.getWriter().println(JSONUtil.parse(R.failed(respCode)));response.getWriter().flush();}}
流控模式
基于调用关系的流量控制。调用关系包括调用方、被调用方;一个方法可能会调用其它方法,形成一个调用链路的层次关系。
直接
资源调用达到设置的阈值后直接被流控抛出异常
关联
当两个资源之间具有资源争抢或者依赖关系的时候,这两个资源便具有了关联。比如对数据库同一个字段的读操作和写操作存在争抢,读的速度过高会影响写得速度,写的速度过高会影响读的速度。如果放任读写操作争抢资源,则争抢本身带来的开销会降低整体的吞吐量。可使用关联限流来避免具有关联关系的资源之间过度的争抢,举例来说,read_db 和 write_db 这两个资源分别代表数据库读写,我们可以给 read_db 设置限流规则来达到写优先的目的:设置 strategy 为 RuleConstant.STRATEGY_RELATE 同时设置 refResource 为 write_db。这样当写库操作过于频繁时,读数据的请求会被限流。
链路
根据调用链路入口限流。
NodeSelectorSlot 中记录了资源之间的调用链路,这些资源通过调用关系,相互之间构成一棵调用树。这棵树的根节点是一个名字为 machine-root 的虚拟节点,调用链的入口都是这个虚节点的子节点。
一棵典型的调用树如下图所示:
machine-root/ \/ \Entrance1 Entrance2/ \/ \DefaultNode(nodeA) DefaultNode(nodeA)
上图中来自入口 Entrance1 和 Entrance2 的请求都调用到了资源 NodeA,Sentinel 允许只根据某个入口的统计信息对资源限流。
getUser 是实现类业务方法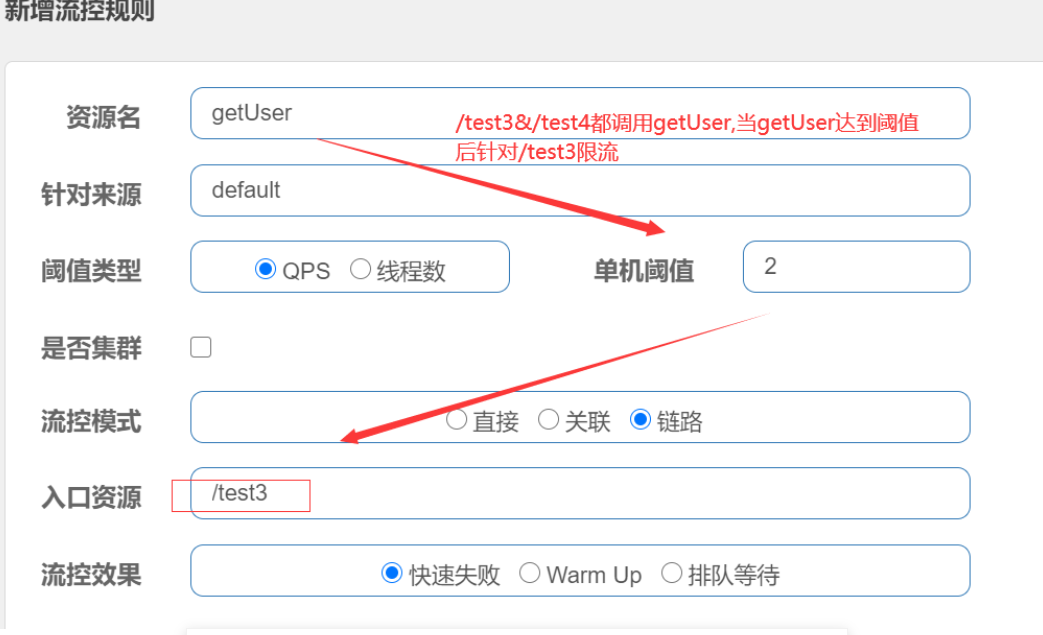
测试会发现链路规则不生效
注意,高版本此功能直接使用不生效,如何解决?
从1.6.3版本开始,Sentinel Web filter默认收敛所有URL的入口context,导致链路限流不生效。 从1.7.0版本开始,官方在CommonFilter引入了WEB_CONTEXT_UNIFY参数,用于控制是否收敛context,将其配置为false即可根据不同的URL进行链路限流。
1.8.0 需要引入sentinel-web-servlet依赖
<!--- 解决流控链路不生效的问题--><dependency><groupId>com.alibaba.csp</groupId><artifactId>sentinel-web-servlet</artifactId></dependency>
添加配置类,配置CommonFilter过滤器,指定WEB_CONTEXT_UNIFY=false,禁止收敛URL的入口context
@Configurationpublic class SentinelConfig {@Beanpublic FilterRegistrationBean sentinelFilterRegistration() {FilterRegistrationBean registration = new FilterRegistrationBean();registration.setFilter(new CommonFilter());registration.addUrlPatterns("/*");// 入口资源关闭聚合 解决流控链路不生效的问题registration.addInitParameter(CommonFilter.WEB_CONTEXT_UNIFY, "false");registration.setName("sentinelFilter");registration.setOrder(1);return registration;}}
再次测试链路规则,链路规则生效,但是出现异常
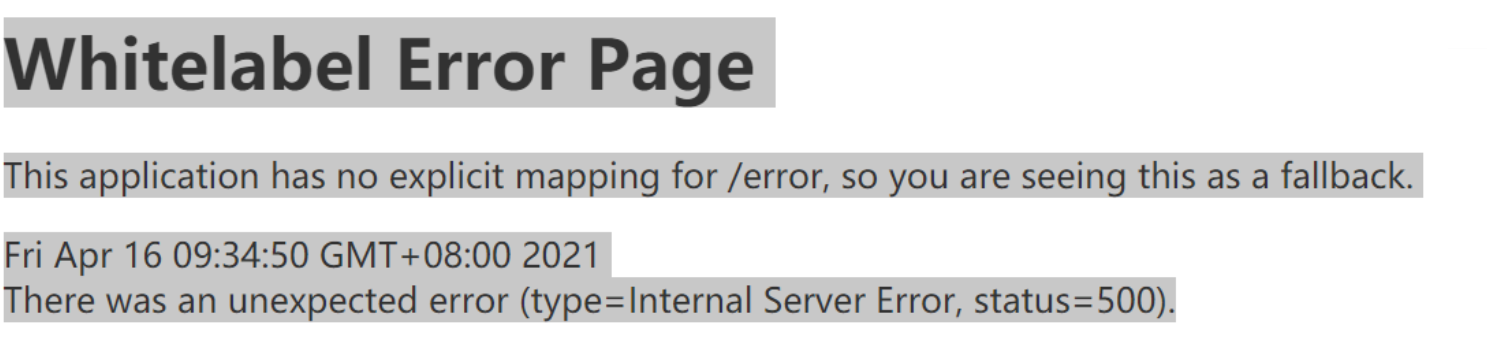
原因分析:
1. Sentinel流控规则的处理核心是 FlowSlot, 对getUser资源进行了限流保护,当请求QPS超过阈值2的时候,就会触发流控规则抛出FlowException异常
2. 对getUser资源保护的方式是@SentinelResource注解模式,会在对应的SentinelResourceAspect切面逻辑中处理BlockException类型的FlowException异常
(解决方案: 在@SentinelResource注解中指定blockHandler处理BlockException)
@Override@SentinelResource(value="getUser",blockHandler = "blockHandlerGetUser")public String getUser() {return "查询用户";}public String blockHandlerGetUser(BlockException e) {return "流控用户";}

流控效果
当 QPS 超过某个阈值的时候,则采取措施进行流量控制。流量控制的效果包括以下几种:快速失败(直接拒绝)、Warm Up(预热)、匀速排队(排队等待)。对应 FlowRule 中的 controlBehavior 字段。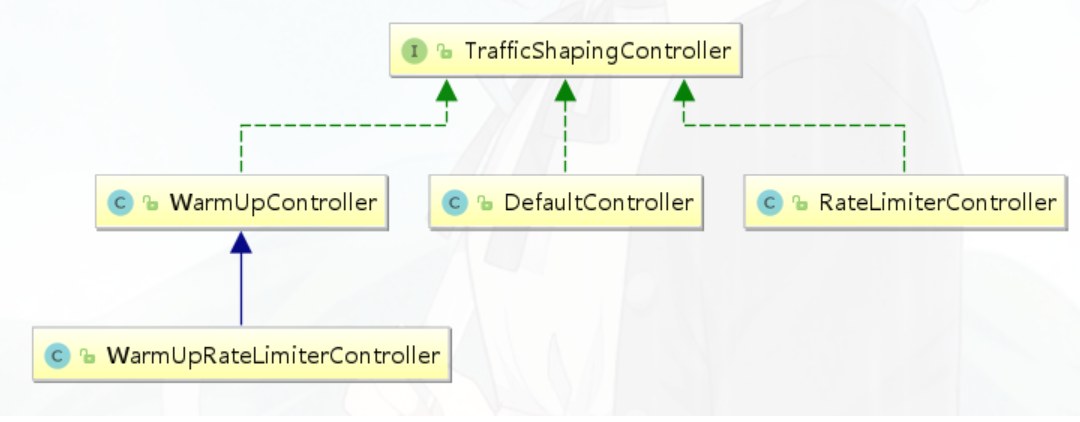
快速失败
(RuleConstant.CONTROL_BEHAVIOR_DEFAULT)方式是默认的流量控制方式,当QPS超过任意规则的阈值后,新的请求就会被立即拒绝,拒绝方式为抛出FlowException。这种方式适用于对系统处理能力确切已知的情况下,比如通过压测确定了系统的准确水位时。
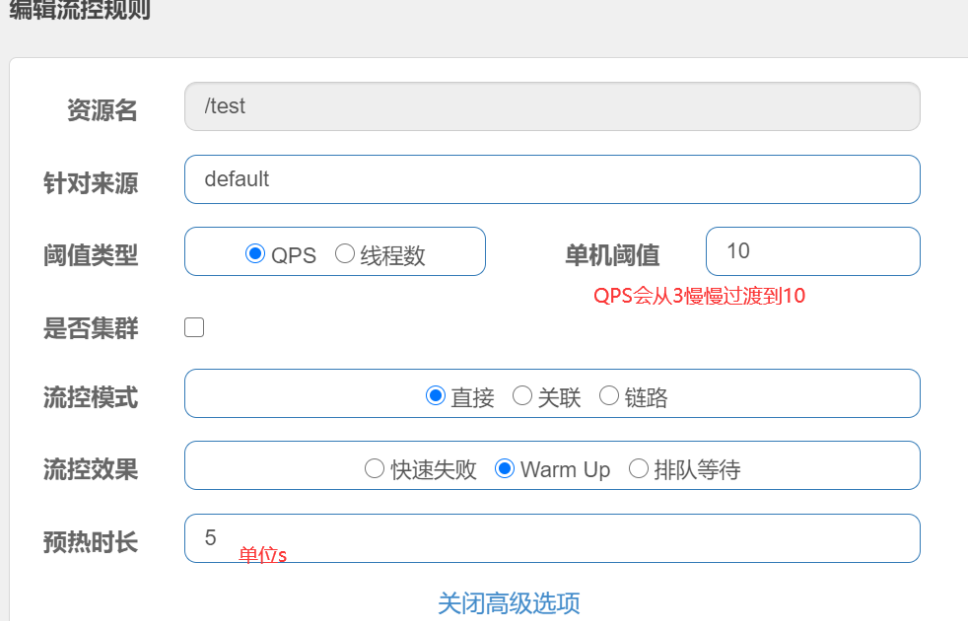
Warm Up
Warm Up(RuleConstant.CONTROL_BEHAVIOR_WARM_UP)方式,即预热/冷启动方式。当系统长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮。通过”冷启动”,让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮。
冷加载因子: codeFactor 默认是3,即请求 QPS 从 threshold / 3 开始,经预热时长逐渐升至设定的 QPS 阈值。
通常冷启动的过程系统允许通过的 QPS 曲线如下图所示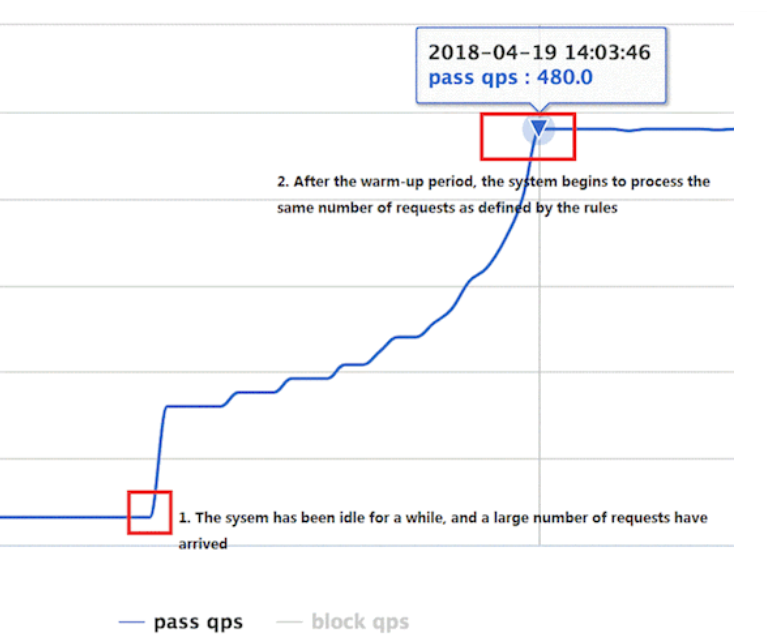
jmeter测试
查看实时监控,可以看到通过QPS存在缓慢增加的过程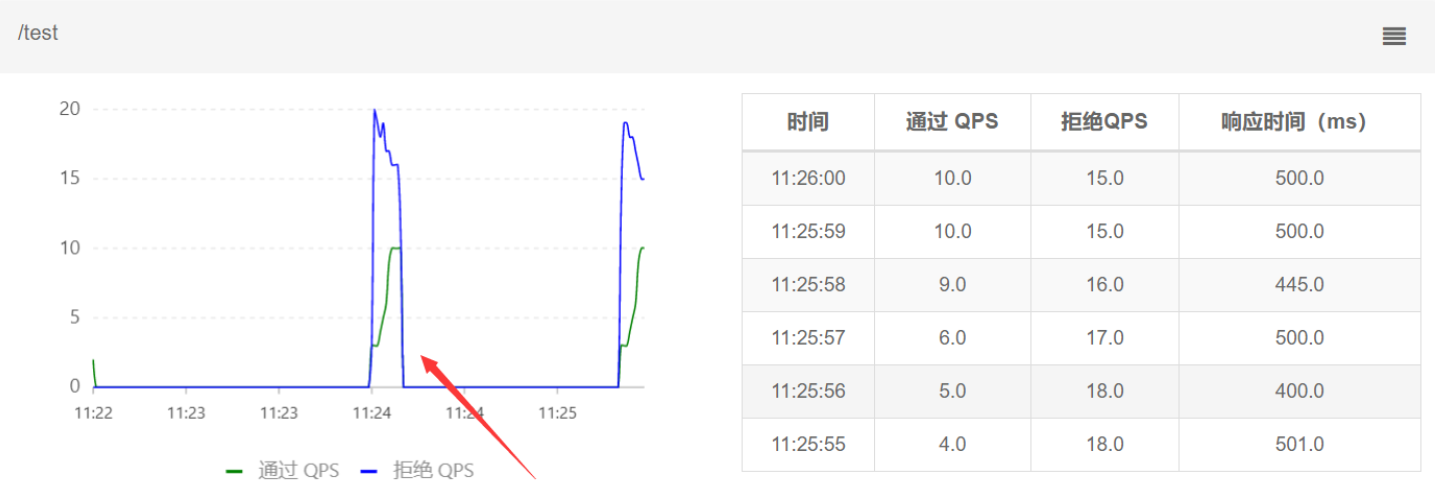
匀速排队
匀速排队(RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER)方式会严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。
该方式的作用如下图所示: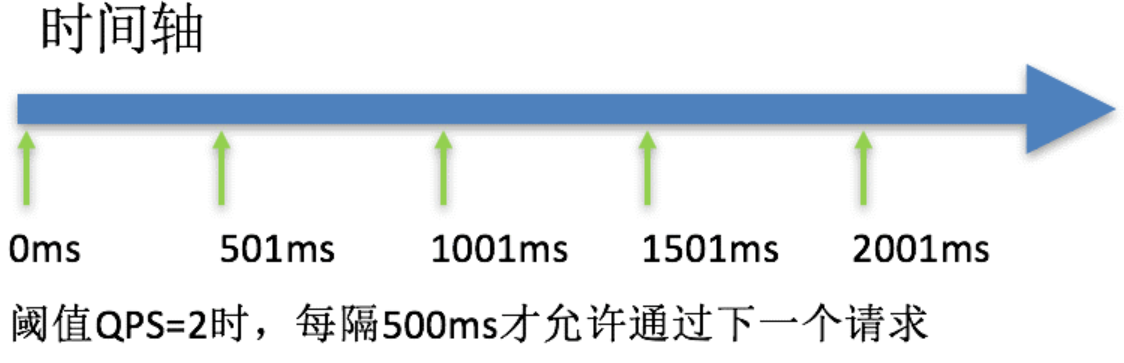
这种方式主要用于处理间隔性突发的流量,例如消息队列。想象一下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。
注意:匀速排队模式暂时不支持 QPS > 1000 的场景。
降级规则
除了流量控制以外,对调用链路中不稳定的资源进行熔断降级也是保障高可用的重要措施之一。我们需要对不稳定的弱依赖服务调用进行熔断降级,暂时切断不稳定调用,避免局部不稳定因素导致整体的雪崩。熔断降级作为保护自身的手段,通常在客户端(调用端)进行配置。
熔断降级规则说明
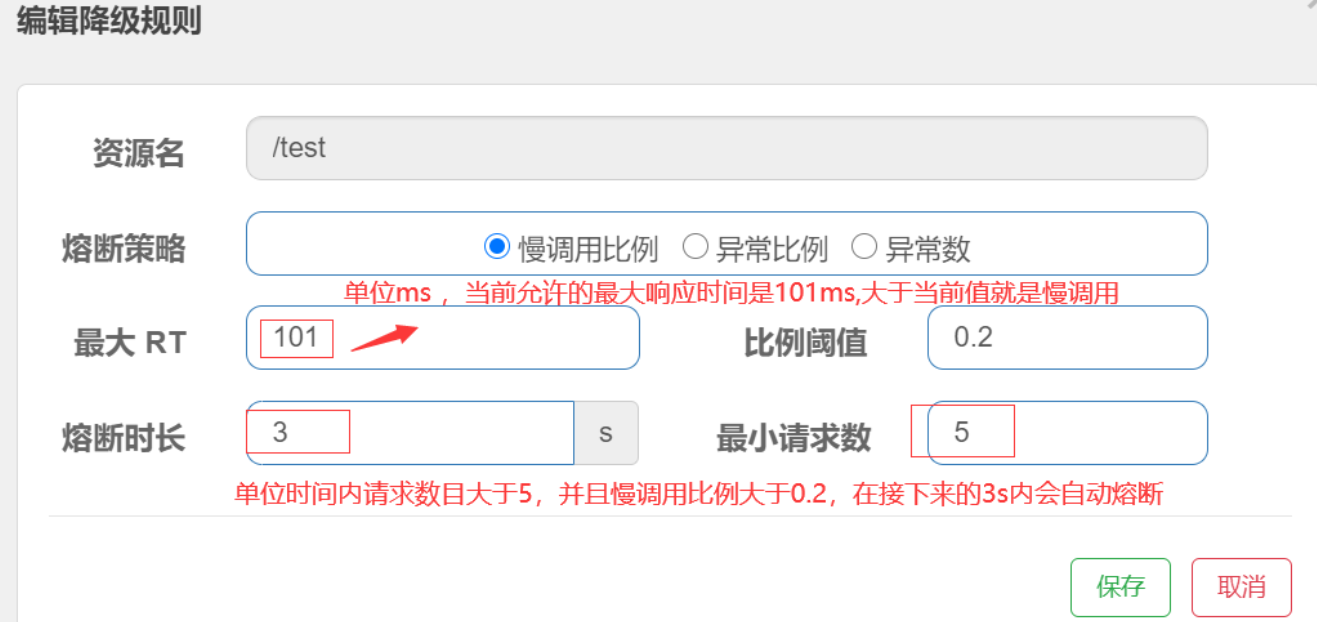
熔断降级规则(DegradeRule)包含下面几个重要的属性:
| Field | 说明 | 默认值 |
|---|---|---|
| resource | 资源名,即规则的作用对象 | |
| grade | 熔断策略,支持慢调用比例/异常比例/异常数策略 | 慢调用比例 |
| count | 慢调用比例模式下为慢调用临界 RT(超出该值计为慢调用);异常比例/异常数模式下为对应的阈值 | |
| timeWindow | 熔断时长,单位为 s | |
| minRequestAmount | 熔断触发的最小请求数,请求数小于该值时即使异常比率超出阈值也不会熔断(1.7.0 引入) | 5 |
| statIntervalMs | 统计时长(单位为 ms),如 60*1000 代表分钟级(1.8.0 引入) | 1000 ms |
| slowRatioThreshold | 慢调用比例阈值,仅慢调用比例模式有效(1.8.0 引入) |
熔断策略
慢调用比例
慢调用比例 (SLOW_REQUEST_RATIO):选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则会再次被熔断。
异常比例
异常比例 (ERROR_RATIO):当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且异常的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%。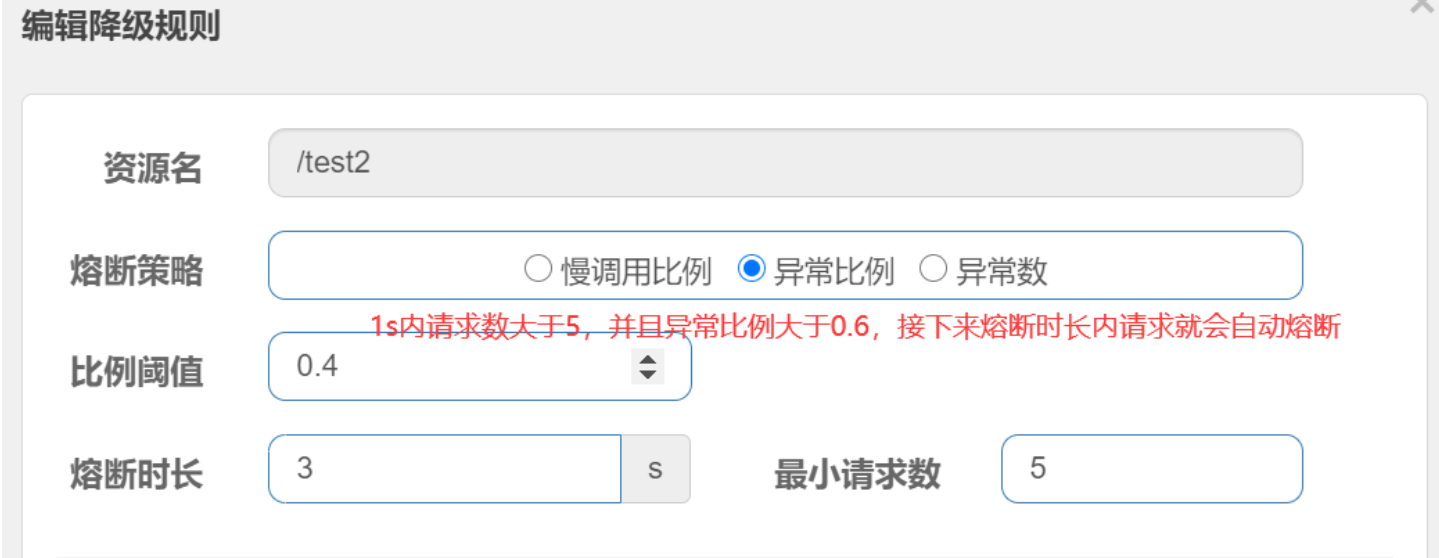
查看实时监控,可以看到断路器熔断效果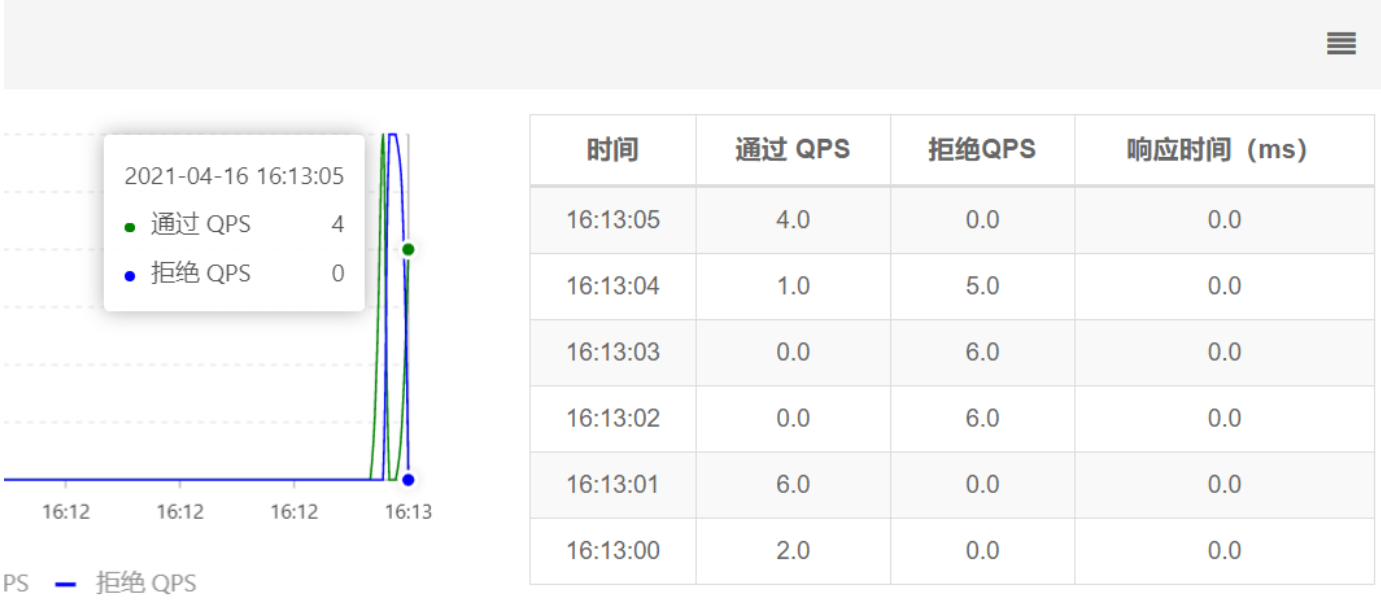
异常数
异常数 (ERROR_COUNT):当单位统计时长内的异常数目超过阈值之后会自动进行熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。
注意:异常降级仅针对业务异常,对 Sentinel 限流降级本身的异常(BlockException)不生效。
配置降级规则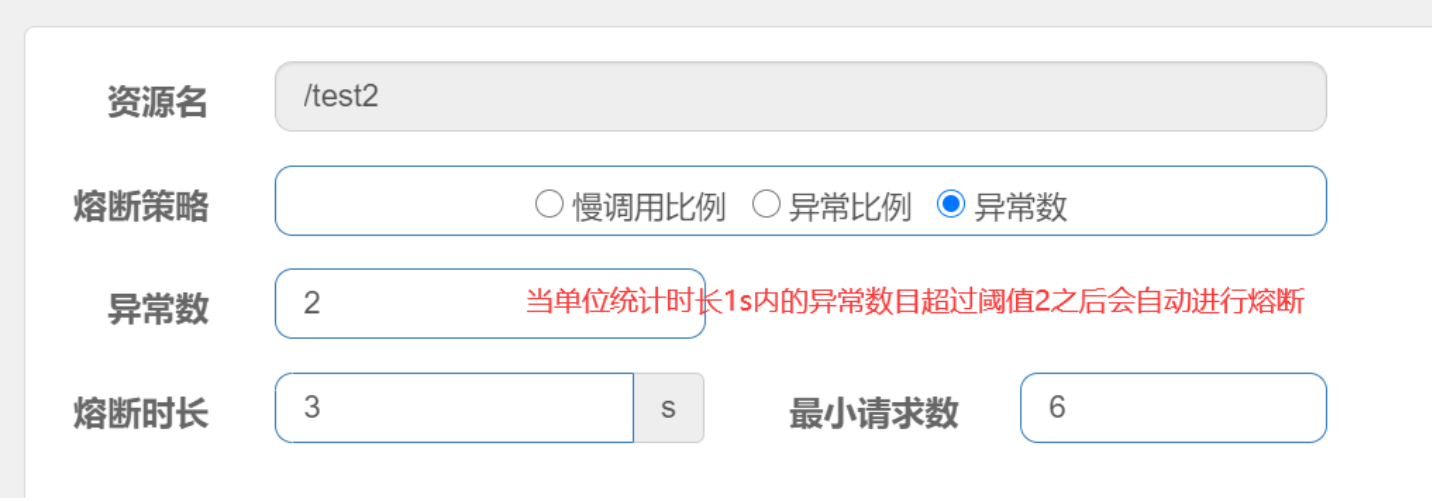
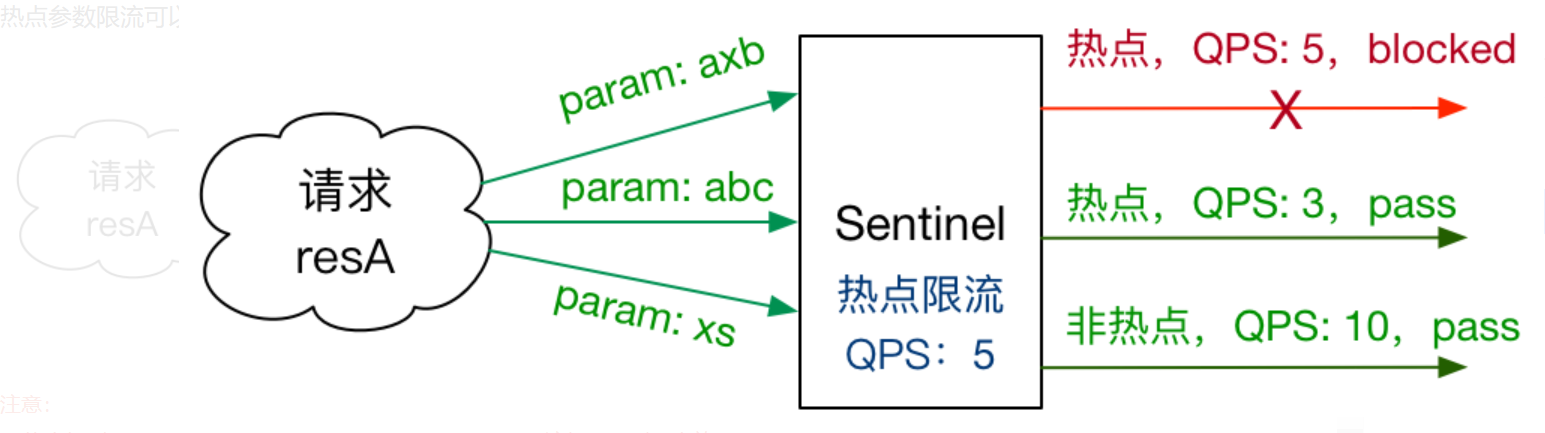
热点参数限流
何为热点?热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的 Top K 数据,并对其访问进行限制。比如:
- 商品 ID 为参数,统计一段时间内最常购买的商品 ID 并进行限制
- 用户 ID 为参数,针对一段时间内频繁访问的用户 ID 进行限制
热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效。
注意:
- 热点规则需要使用@SentinelResource(“resourceName”)注解,否则不生效
- 参数必须是7种基本数据类型才会生效
测试用例
@RequestMapping("/info/{id}")@SentinelResource(value = "userinfo",blockHandlerClass = CommonBlockHandler.class,blockHandler = "handleException2",fallbackClass = CommonFallback.class,fallback = "fallback")public R info(@PathVariable("id") Integer id){UserEntity user = userService.getById(id);return R.ok().put("user", user);}
配置热点参数规则
注意: 资源名必须是@SentinelResource(value=”资源名”)中 配置的资源名,热点规则依赖于注解
具体到参数值限流,配置参数值为3,限流阈值为1
测试:
http://localhost:8800/user/info/1 限流的阈值为3
http://localhost:8800/user/info/3 限流的阈值为1
系统规则
Sentinel 系统自适应限流从整体维度对应用入口流量进行控制,结合应用的 Load、CPU 使用率、总体平均 RT、入口 QPS 和并发线程数等几个维度的监控指标,通过自适应的流控策略,让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
- Load 自适应(仅对 Linux/Unix-like 机器生效):系统的 load1 作为启发指标,进行自适应系统保护。当系统 load1 超过设定的启发值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护(BBR 阶段)。系统容量由系统的 maxQps minRt 估算得出。设定参考值一般是 CPU cores 2.5。
- CPU usage(1.5.0+ 版本):当系统 CPU 使用率超过阈值即触发系统保护(取值范围 0.0-1.0),比较灵敏。
- 平均 RT:当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒。
- 并发线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。
- 入口 QPS:当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护。
编写系统规则
openfeign 整合 sentinel
配置信息
feign:sentinel:# openfeign 整合 sentinelenabled: true
Feign 接口继承
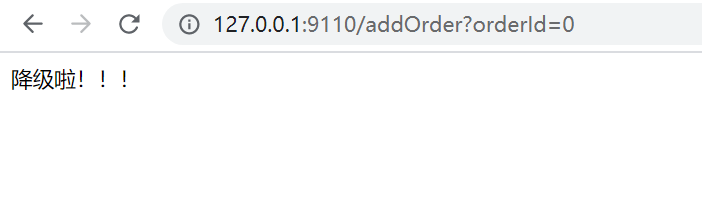
@FeignClient(value="sentinel-stock",path = "/stock",contextId = "StockFeign",fallbackFactory = StockFeignServiceFallbackFactory.class)public interface StockFeign extends StockFeignService {}@Slf4j@Componentpublic class StockFeignServiceFallbackFactory implements FallbackFactory<StockFeignService> {@Overridepublic StockFeignService create(Throwable throwable) {return new StockFeignService() {@Overridepublic String reduct(int orderId) {log.error("原因:{}", throwable.getMessage());return " 降级啦!!!";}};}}
测试结果
Sentinel持久化模式
Sentinel规则的推送有下面三种模式:
| 推送模式 | 说明 | 优点 | 缺点 |
|---|---|---|---|
| 原始模式 | API 将规则推送至客户端并直接更新到内存中,扩展写数据源 (WritableDataSource) |
简单,无任何依赖 | 不保证一致性;规则保存在内存中,重启即消失。严重不建议用于生产环境 |
| Pull 模式 | 扩展写数据源(WritableDataSource), 客户端主 动向某个规则管理中心定期轮询拉取规则,这个规则中心可以是 RDBMS、文件 等 |
简单,无任何依赖;规则持久化 | 不保证一致性;实时性不保证,拉取过 于频繁也可能会有性能问题。 |
| Push 模式 | 扩展读数据源(ReadableDataSource),规则中心统一推送,客户端通过注册监听器的方式时刻监听变化,比如使用 Nacos、 Zookeeper 等配置中心。这种方式有 更好的实时性和一致性保证。生产环境 下一般采用 push 模式的数据源。 |
规则持久化;一致性;快速 | 引入第三方 |
原始模式
如果不做任何修改,Dashboard 的推送规则方式是通过 API 将规则推送至客户端并直接更
新到内存中:
这种做法的好处是简单,无依赖;坏处是应用重启规则就会消失,仅用于简单测试,不能
用于生产环境。
拉模式
pull 模式的数据源(如本地文件、RDBMS 等)一般是可写入的。使用时需要在客户端注册
数据源:将对应的读数据源注册至对应的 RuleManager,将写数据源注册至 transport 的
WritableDataSourceRegistry 中。
推模式
生产环境下一般更常用的是 push 模式的数据源。对于 push 模式的数据源,如远程配置中心
(ZooKeeper, Nacos, Apollo等等),推送的操作不应由 Sentinel 客户端进行,而应该经控
制台统一进行管理,直接进行推送,数据源仅负责获取配置中心推送的配置并更新到本
地。因此推送规则正确做法应该是 配置中心控制台/Sentinel 控制台 → 配置中心 →
Sentinel 数据源 → Sentinel,而不是经 Sentinel 数据源推送至配置中心。
这样的流程就非常清晰了:
基于Nacos配置中心控制台实现推送
官方demo: sentineldemonacosdatasource
引入依赖
<!--nacos 持久化--><dependency><groupId>com.alibaba.csp</groupId><artifactId>sentinel-datasource-nacos</artifactId></dependency>
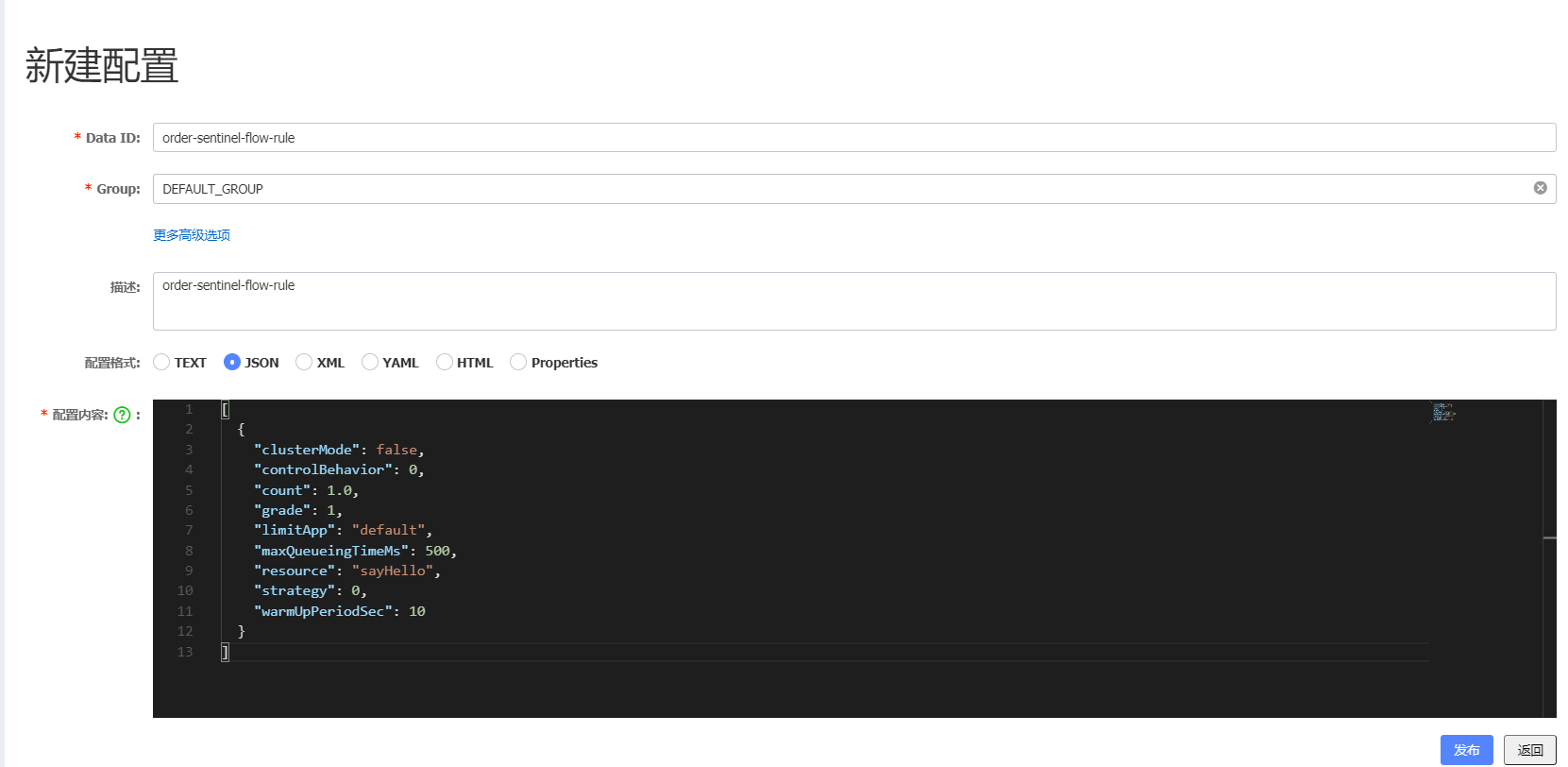
nacos 配置中心中配置流控规则
[{"clusterMode": false,"controlBehavior": 0,"count": 1.0,"grade": 1,"limitApp": "default","maxQueueingTimeMs": 500,"resource": "sayHello","strategy": 0,"warmUpPeriodSec": 10}]
yml 中配置
server:## 启动端口port: 9110spring:application:## 注册服务名name: sentinel-ordercloud:nacos:## 注册中心地址discovery:server-addr: 127.0.0.1:8848## sentinel configsentinel:transport:dashboard: localhost:8858datasource:sayhello-flow‐rules: #名称自定义,唯一nacos:server-addr: localhost:8858username: nacospassword: nacosdataId: order-sentinel-flow-rulerule-type: flowmain:allow-bean-definition-overriding: truefeign:sentinel:# openfeign 整合 sentinelenabled: true## 暴露端点management:endpoints:web:exposure:include: '*'
Seata 分布式事务
事务简介
事务(Transaction)是访问并可能更新数据库中各种数据项的一个程序执行单元(unit)。在关系数据库中,一个事务由一组SQL语句组成。事务应该具有4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。
- 原子性(atomicity):事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要都不做。
- 一致性(consistency):事务必须是使数据库从一个一致性状态变到另一个一致性状态,事的中间状态不能被观察到的。
隔离性(isolation):一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
隔离性又分为四个级别:- 读未提交(read uncommitted)、- 读已提交(read committed,解决脏读)、- 可重复读(repeatableread,解决虚读)、- 串行化(serializable,解决幻读)。
持久性(durability):持久性也称永久性(permanence),指一个事务一旦提交,它对数据库
中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
任何事务机制在实现时,都应该考虑事务的ACID特性,包括:本地事务、分布式事务,及时不能
都很好的满足,也要考虑支持到什么程度。
本地事务
@Transational
大多数场景下,我们的应用都只需要操作单一的数据库,这种情况下的事务称之为本地事务
(Local Transaction)。本地事务的ACID特性是数据库直接提供支持。本地事务应用架构如下所
示: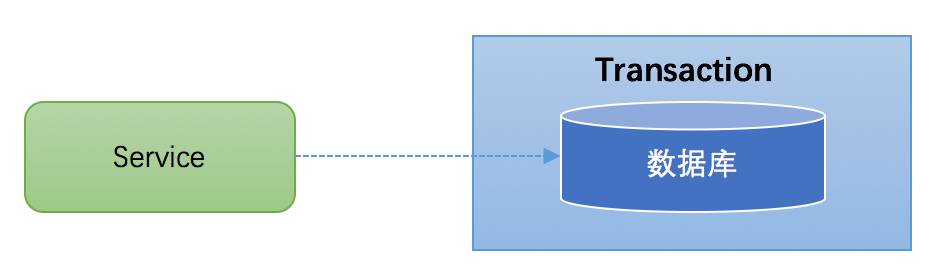
在JDBC编程中,我们通过java.sql.Connection对象来开启、关闭或者提交事务。
代码如下所
Connection conn = ... //获取数据库连接conn.setAutoCommit(false); //开启事务try{//...执行增删改查sqlconn.commit(); //提交事务}catch (Exception e) {conn.rollback();//事务回滚}finally{conn.close();//关闭链接}
分布式事务典型场景
当下互联网发展如火如荼,绝大部分公司都进行了数据库拆分和服务化(SOA)。在这种情况下,完成某一个业务功能可能需要横跨多个服务,操作多个数据库。这就涉及到到了分布式事务,用需要操作的资源位于多个资源服务器上,而应用需要保证对于多个资源服务器的数据的操作,要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同资源服务器的数据一致性。
典型的分布式事务场景:
跨库事务
跨库事务指的是,一个应用某个功能需要操作多个库,不同的库中存储不同的业务数据。笔者见过一个相对比较复杂的业务,一个业务中同时操作了9个库。下图演示了一个服务同时操作2个库的情况: 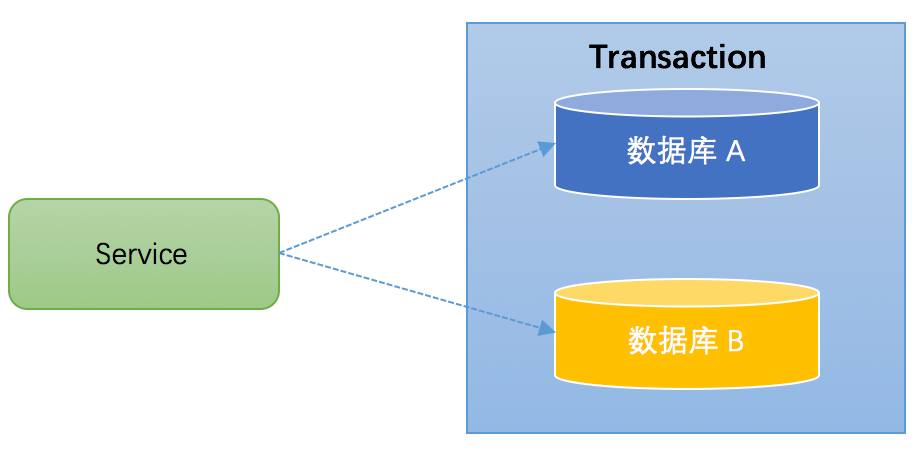
分库分表
通常一个库数据量比较大或者预期未来的数据量比较大,都会进行水平拆分,也就是分库分表。如下图,将数据库B拆分成了2个库: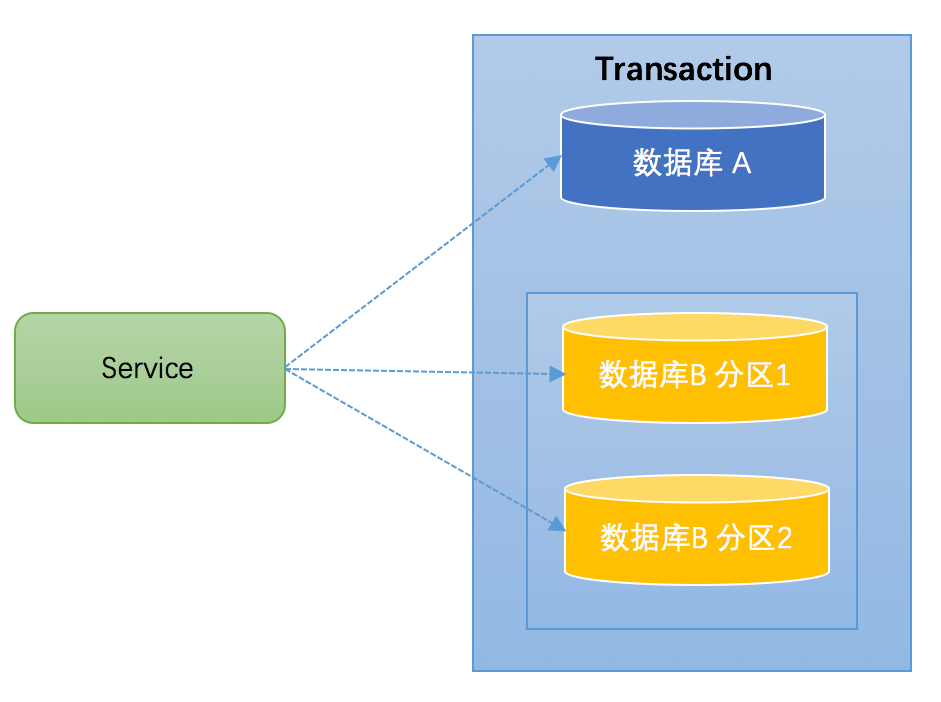
对于分库分表的情况,一般开发人员都会使用一些数据库中间件来降低 sql 操作的复杂性。如,对于sql:insert into user(id,name) values (1,”张三”),(2,”李四”)。这条sql是操作单库的语法,单库情况下,可以保证事务的一致性。但是由于现在进行了分库分表,开发人员希望将1号记录插入分库1,2号记录插入分库2。所以数
据库中间件要将其改写为2条sql,分别插入两个不同的分库,此时要保证两个库要不都成功,要不都失败,因此基本上所有的数据库中间件都面临着分布式事务的问题
服务化
微服务架构是目前一个比较一个比较火的概念。例如上面笔者提到的一个案例,某个应用同时操作了9个库,这样的应用业务逻辑必然非常复杂,对于开发人员是极大的挑战,应该拆分成不同的独立服务,以简化业务逻辑。拆分后,独立服务之间通过RPC框架来进行远程调用,实现彼此的通信。下图演示了一个3个服务之间彼此调用的架构
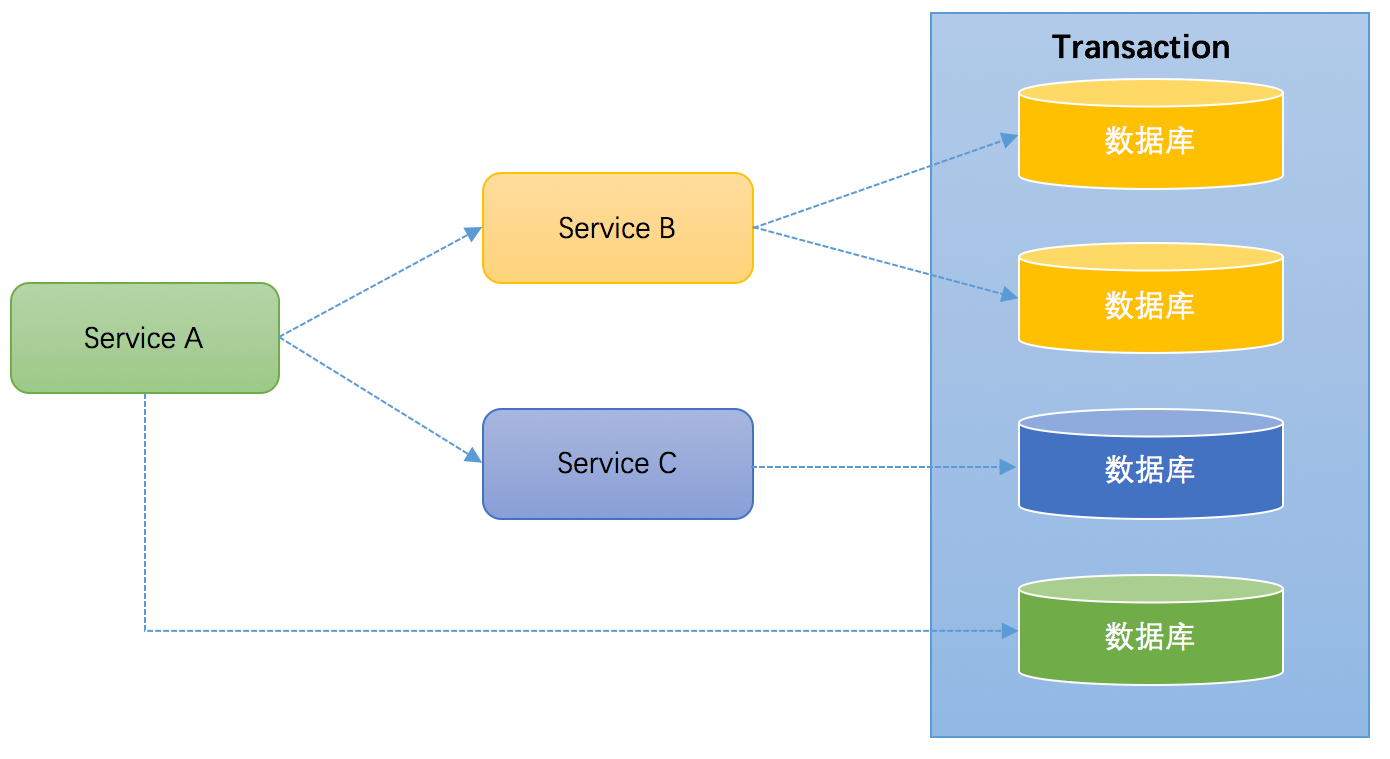
Service A完成某个功能需要直接操作数据库,同时需要调用Service B和Service C,而Service B又同时操作了2个数据库,Service C也操作了一个库。需要保证这些跨服务的对多个数据库的操作要不都成功,要不都失败,实际上这可能是最典型的分布式事务场景。
小结
上述讨论的分布式事务场景中,无一例外的都直接或者间接的操作了多个数据库。如何保证事务的ACID特性,对于分布式事务实现方案而言,是非常大的挑战。同时,分布式事务实现方案还必须要考虑性能的问题,如果为了严格保证ACID特性,导致性能严重下降,那么对于一些要求快速响应的业务,是无法接受的。
常见分布式事务解决方案
常见分布式事务
- seata 阿里分布式事务框架
- 消息队列 (RocketMq RabbitMq)
- saga
- XA
- XXL-LCN
它们都有一个共同点,都是“两阶段(2PC)”。“两阶段”是指完成整个分布式事务,划分成两个步骤完成。
实际上,这五种常见的分布式事务解决方案,分别对应着 分布式事务的五种模式:AT、TCC、Saga、XA、LCN;
五种分布式事务模式,都有各自的理论基础,分别在不同的时间被提出;每种模式都有它的适用场景,同样每个模式也都诞生有各自的代表产品;而这些代表产品,可能就是我们常见的(全局事务、基于可靠消息、最大努力通知、TCC)。
今天,我们会分别来看5种模式(AT、TCC、Saga、XA、LCN)的分布式事务实现。
在看具体实现之前,先讲下分布式事务的理论基础。
分布式事务理论基础
解决分布式事务,也有相应的规范和协议。分布式事务相关的协议有 2PC、3PC。
由于三阶段提交协议3PC 非常难实现,目前市面主流的分布式事务解决方案都是2PC协议。这就是文章开始提及的常见分布式事务解决方案里面,那些列举的都有一个共同点“两阶段”的内在原因。
有些文章分析2PC时,几乎都会用TCC两阶段的例子,第一阶段try,第二阶段完成 confirm 或 cancel。
其实2PC并不是专为实现TCC设计的,2PC具有普适性——协议一样的存在,目前绝大多数分布式解决方案都是以两阶段提交协议2PC为基础的。
TCC(Try-Confirm-Cancel) 实际上是服务化的两阶段提交协议。
2PC两阶段提交协议:
2PC(两阶段提交,Two-Phase Commit)
顾名思义,分为两个阶段:Prepare(预提交) 和 Commit
Prepare:提交事务请求
基本流程图如下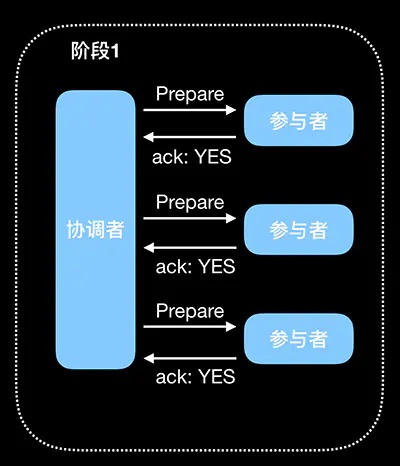
执行流程
1. 询问协调者向所有参与者发送事务请求,询问是否可执行事务操作,然后等待各个参与者的响应。
2. 执行各个参与者接收到协调者事务请求后,执行事务操作(例如更新一个关系型数据库表中的记录),并将
Undo 和 Redo 信息记录事务日志中。
3. 响应如果参与者成功执行了事务并写入 Undo 和 Redo 信息,则向协调者返回 YES 响应,否则返回 NO
响应。当然,参与者也可能宕机,从而不会返回响应。
Commit:执行事务提交
执行事务提交分为两种情况,正常提交和回退。
正常提交事务
流程如下图: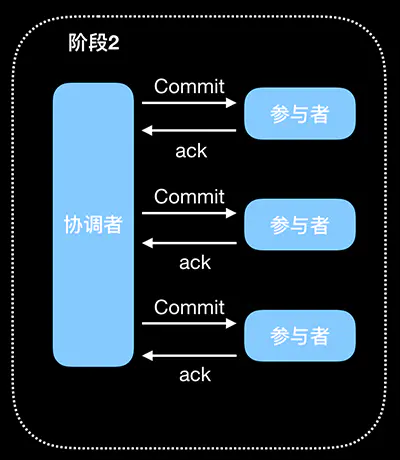
执行流程
- commit 请求协调者向所有参与者发送 Commit 请求。
- 事务提交参与者收到 Commit 请求后,执行事务提交,提交完成后释放事务执行期占用的所有资源。
- 反馈结果参与者执行事务提交后向协调者发送 Ack 响应。
- 完成事务接收到所有参与者的 Ack 响应后,完成事务提交。
中断事务
在执行 Prepare 步骤过程中,如果某些参与者执行事务失败、宕机或与协调者之间的网络中断,那么协调者就无法收到所有参与者的 YES 响应,或者某个参与者返回了 No 响应,此时,协调者就会进入回退流程,对事务进行回退。流程如下图红色部分(将 Commit 请求替换为红色的 Rollback 请求):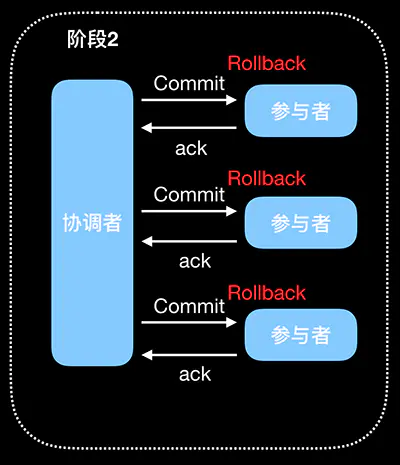
执行流程
- rollback 请求协调者向所有参与者发送 Rollback 请求。
事务回滚 参与者收到 Rollback 后,使用 Prepare 阶段的 Undo 日志执行事务回滚,完成后释放事务执行
期占用的所有资源。
反馈结果 参与者执行事务回滚后向协调者发送 Ack 响应。
- 中断事务 接收到所有参与者的 Ack 响应后,完成事务中断。
2PC 的问题
- 同步阻塞:参与者在等待协调者的指令时,其实是在等待其他参与者的响应,在此过程中,参与者是无法进行其他操作的,也就是阻塞了其运行。 倘若参与者与协调者之间网络异常导致参与者一直收不到协调者信息,那么会导致参与者一直阻塞下去。
- 单点在 2PC 中,一切请求都来自协调者,所以协调者的地位是至关重要的,如果协调者宕机,那么就会使参与者一直阻塞并一直占用事务资源。如果协调者也是分布式,使用选主方式提供服务,那么在一个协调者挂掉后,可以选取另一个协调者继续后续的服务,可以解决单点问题。但是,新协调者无法知道上一个事务的全部状态信息(例如已等待 Prepare 响应的时长等),所以也无法顺利处理上一个事务。
- 数据不一致 Commit 事务过程中 Commit 请求/Rollback 请求可能因为协调者宕机或协调者与参与者网络问题丢失,那么就导致了部分参与者没有收到 Commit/Rollback 请求,而其他参与者则正常收到执行了Commit/Rollback 操作,没有收到请求的参与者则继续阻塞。这时,参与者之间的数据就不再一致了。当参与者执行 Commit/Rollback 后会向协调者发送 Ack,然而协调者不论是否收到所有的参与者的 Ack,该事务也不会再有其他补救措施了,协调者能做的也就是等待超时后像事务发起者返回一个“我不确定该事务是否功”。
- 环境可靠性依赖 协调者 Prepare 请求发出后,等待响应,然而如果有参与者宕机或与协调者之间的网络中断,都会导致协调者无法收到所有参与者的响应,那么在 2PC 中,协调者会等待一定时间,然后超时后,会触发事务中断,在这个过程中,协调者和所有其他参与者都是出于阻塞的。这种机制对网络问题常见的现实环境来说太苛刻了。
分布式事务四种模式
下面我们分别来看4种模式(AT、TCC、Saga、XA)的分布式事务实现。
AT 模式(Auto Transcation)
AT 模式是一种无侵入的分布式事务解决方案。
阿里 seata 框架,实现了该模式。
在 AT 模式下,用户只需关注自己的“业务 SQL”,用户的 “业务 SQL” 作为一阶段,Seata 框架会自动生成事务的二阶段提交和回滚操作。
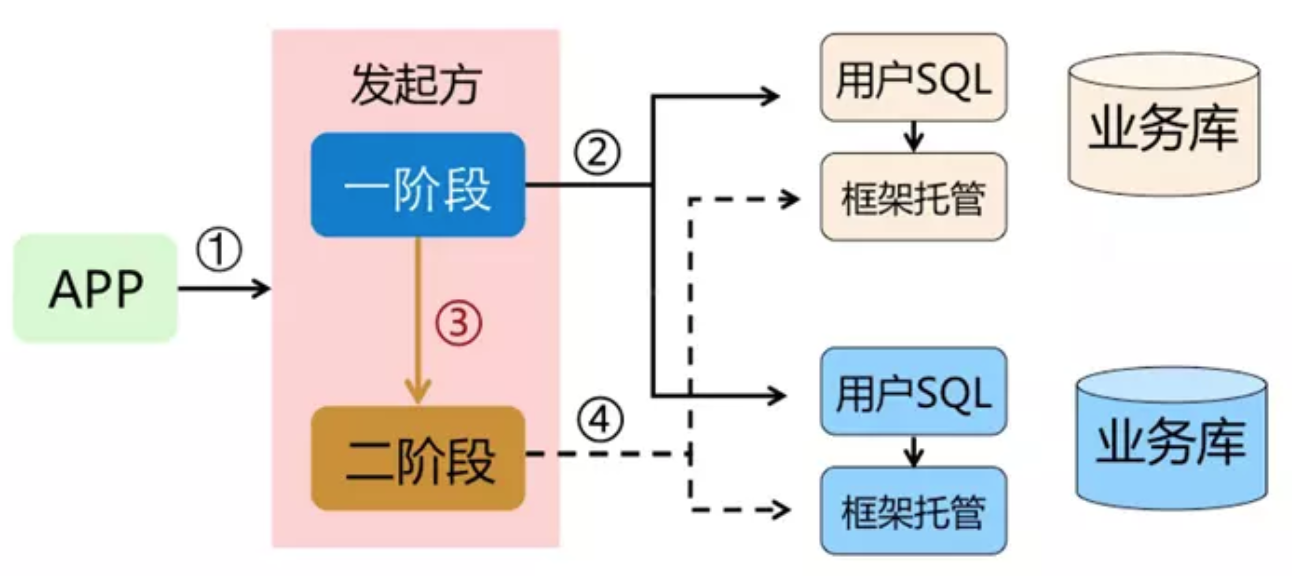
AT 模式如何做到对业务的无侵入
- 一阶段:
在一阶段,Seata 会拦截“业务 SQL”,首先解析 SQL 语义,找到“业务 SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”,然后执行“业务 SQL”更新业务数据,在业务数据更新之后,再将其保存成“after image”,最后生成行锁。以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。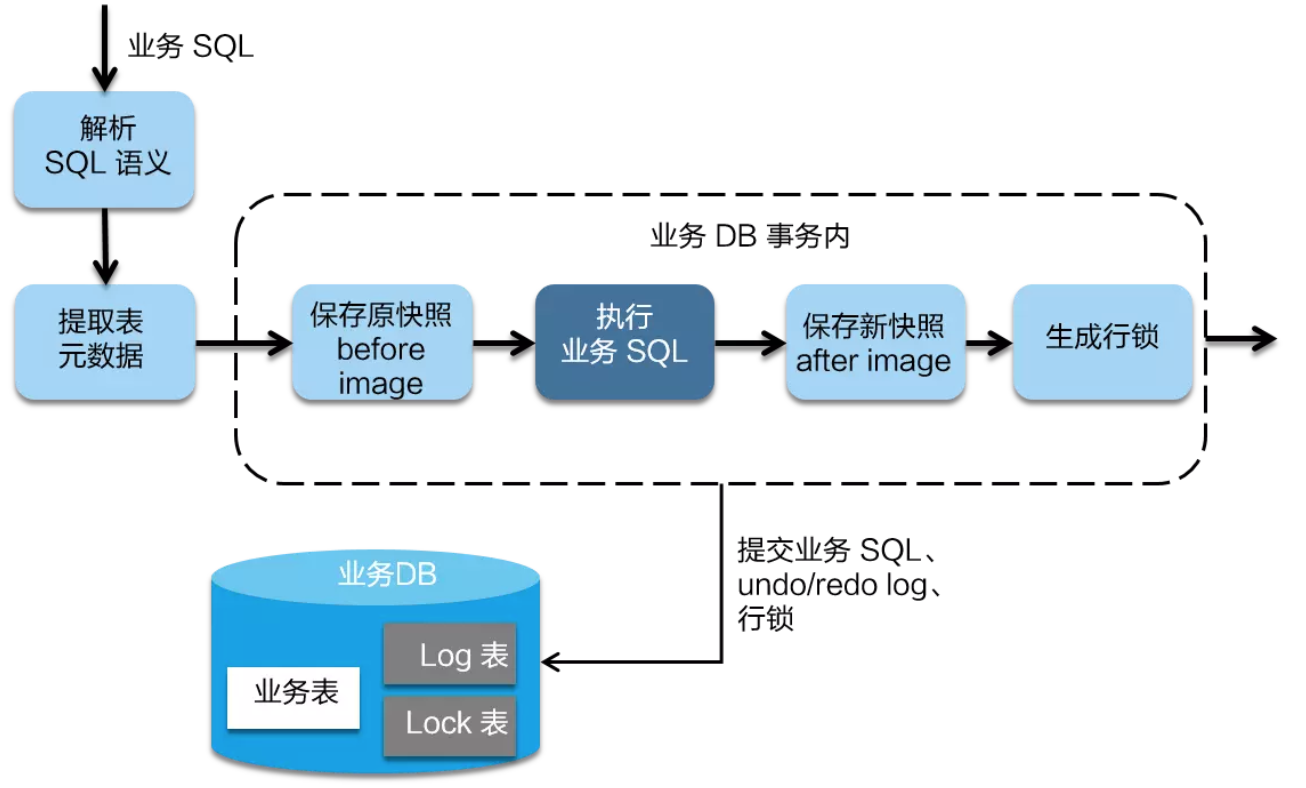
- 二阶段提交:
二阶段如果是提交的话,因为“业务 SQL”在一阶段已经提交至数据库, 所以 Seata 框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。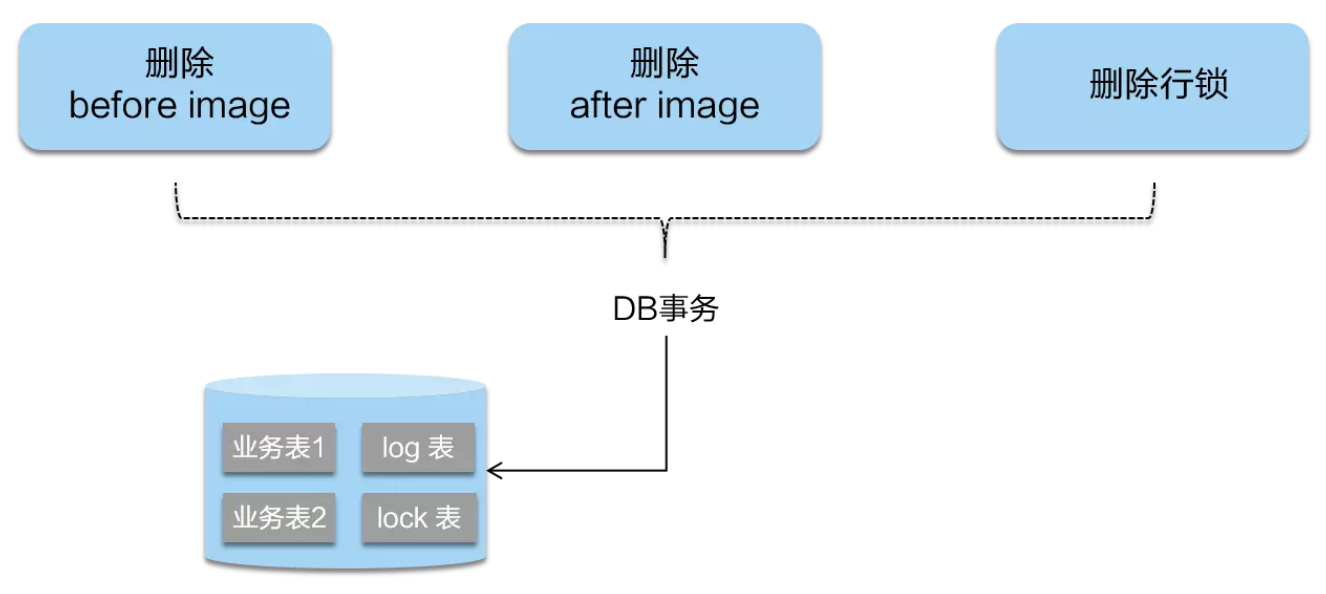
- 二阶段回滚:
二阶段如果是回滚的话,Seata 就需要回滚一阶段已经执行的“业务 SQL”,还原业务数据。回滚方式便是用“before image”还原业务数据;但在还原前要首先要校验脏写,对比“数据库当前业务数据”和 “after image”,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理。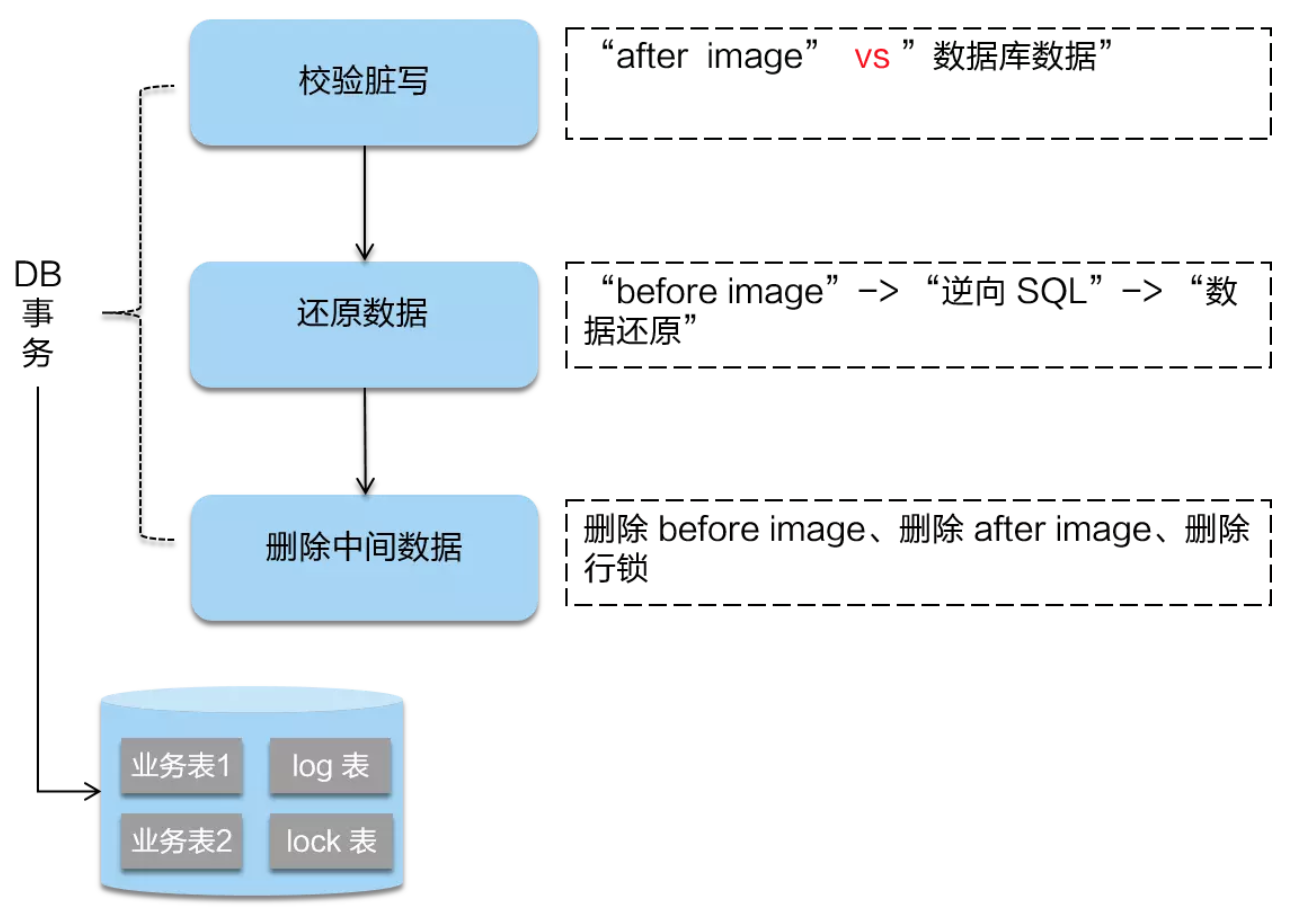
AT 模式的一阶段、二阶段提交和回滚均由 Seata 框架自动生成,用户只需编写“业务 SQL”,便能轻松接入分布式事务,AT 模式是一种对业务无任何侵入的分布式事务解决方案。
TCC 模式
- 侵入性比较强, 并且得自己实现相关事务控制逻辑
- 在整个过程基本没有锁,性能更强
TCC 模式需要用户根据自己的业务场景实现 Try、Confirm 和 Cancel 三个操作;事务发起方在一阶
段执行 Try 方式,在二阶段提交执行 Confirm 方法,二阶段回滚执行 Cancel 方法。
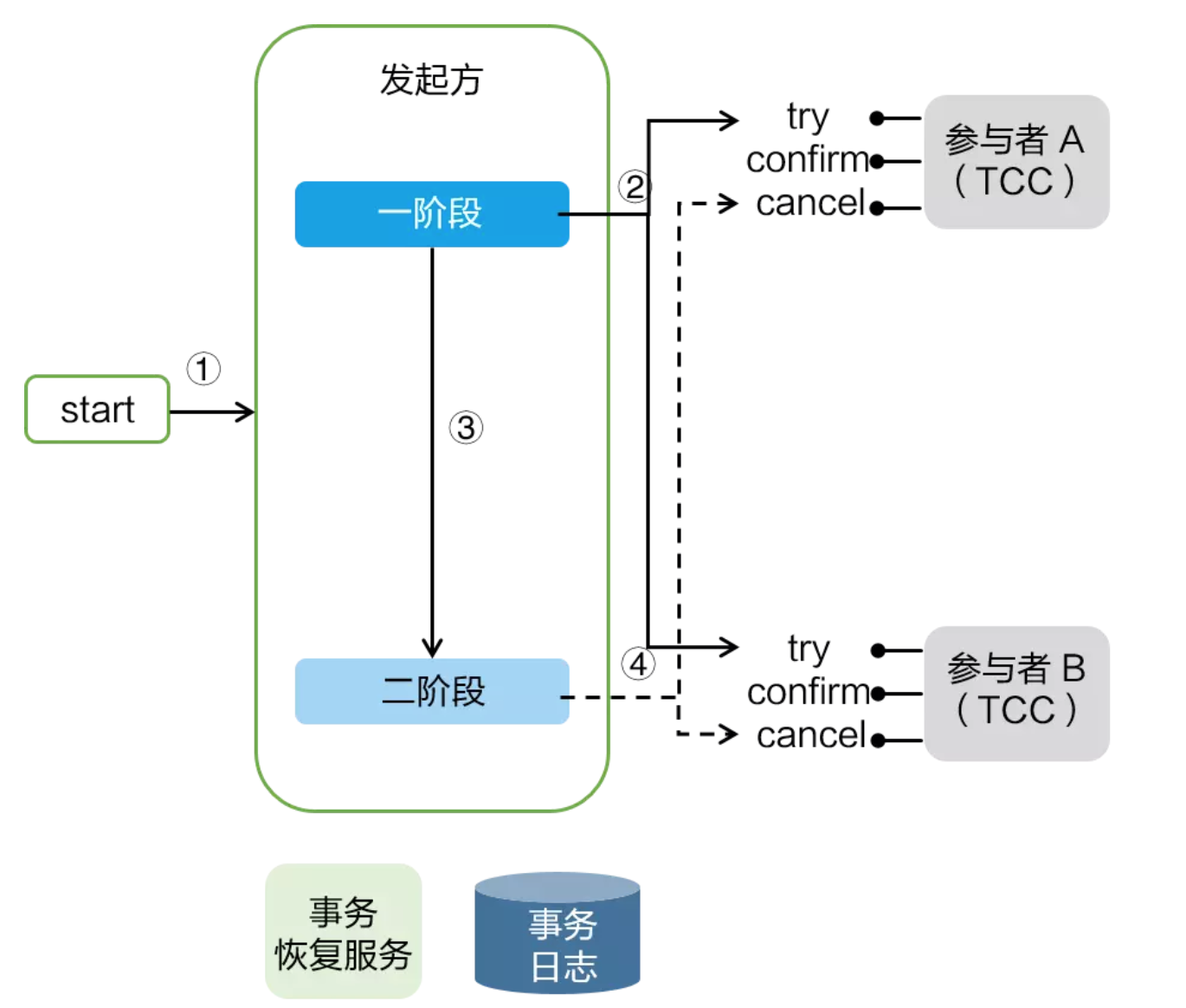
TCC 三个方法描述:
Try:资源的检测和预留;
Confirm:执行的业务操作提交;要求 Try 成功 Confirm 一定要能成功;
Cancel:预留资源释放;
TCC 的实践经验
蚂蚁金服 TCC 实践,总结以下注意事项:
➢业务模型分2阶段设计
➢并发控制
➢允许空回滚
➢防悬挂控制
➢幂等控制
TCC 设计 – 业务模型分 2 阶段设计:
用户接入 TCC ,最重要的是考虑如何将自己的业务模型拆成两阶段来实现。
以“扣钱”场景为例,在接入 TCC 前,对 A 账户的扣钱,只需一条更新账户余额的 SQL 便能完
成;但是在接入 TCC 之后,用户就需要考虑如何将原来一步就能完成的扣钱操作,拆成两阶段,实
现成三个方法,并且保证一阶段 Try 成功的话 二阶段 Confirm 一定能成功。
如下图
如上图所示,Try 方法作为一阶段准备方法,需要做资源的检查和预留。在扣钱场景下,Try 要做的事情是就是检查账户余额是否充足,预留转账资金,预留的方式就是冻结 A 账户的 转账资金。Try方法执行之后,账号 A 余额虽然还是 100,但是其中 30 元已经被冻结了,不能被其他事务使用。
二阶段 Confirm 方法执行真正的扣钱操作。Confirm 会使用 Try 阶段冻结的资金,执行账号扣款。Confirm 方法执行之后,账号 A 在一阶段中冻结的 30 元已经被扣除,账号 A 余额变成 70 元 。
如果二阶段是回滚的话,就需要在 Cancel 方法内释放一阶段 Try 冻结的 30 元,使账号 A 的回到初始状态,100 元全部可用。用户接入 TCC 模式,最重要的事情就是考虑如何将业务模型拆成 2 阶段,实现成 TCC 的 3 个方法,并且保证 Try 成功 Confirm 一定能成功。相对于 AT 模式,TCC 模式对业务代码有一定的侵入性,但是 TCC 模式无 AT 模式的全局行锁,TCC 性能会比 AT 模式高很多。
TCC 设计 – 允许空回滚: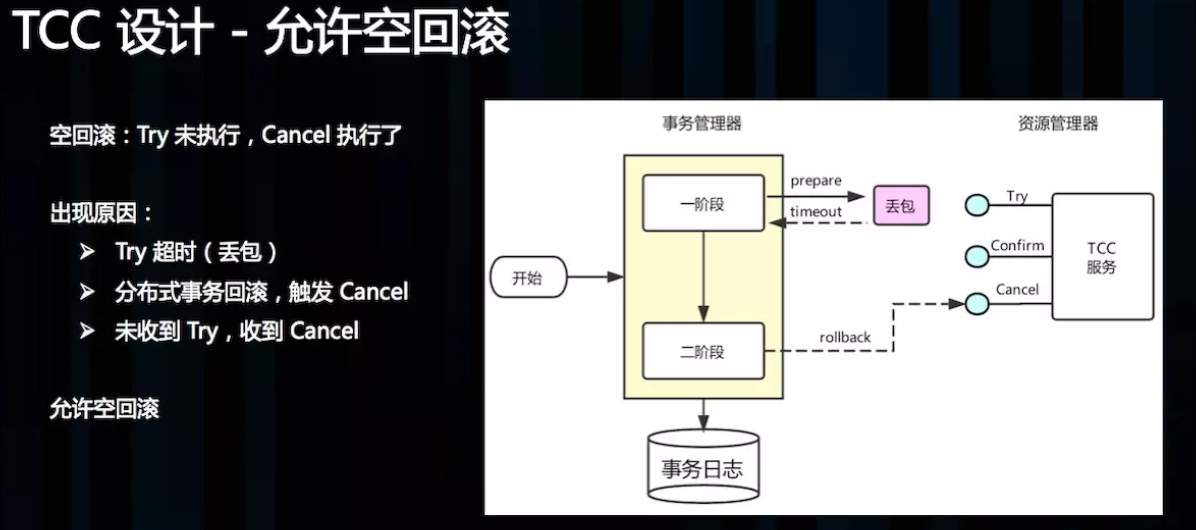
Cancel 接口设计时需要允许空回滚。在 Try 接口因为丢包时没有收到,事务管理器会触发回滚,这时发 Cancel 接口,这时 Cancel 执行时发现没有对应的事务 xid 或主键时,需要返回回滚成功。让事务服务管理器认为已回滚,否则会不断重试,而 Cancel 又没有对应的业务数据可以进行回滚
TCC 设计 – 防悬挂控制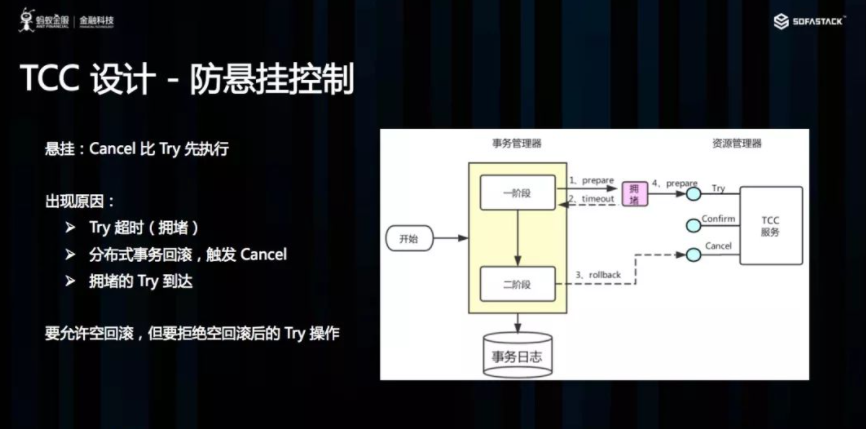
悬挂的意思是:Cancel 比 Try 接口先执行,出现的原因是 Try 由于网络拥堵而超时,事务管理器生成回滚,触发 Cancel 接口,而最终又收到了 Try 接口调用,但是 Cancel 比 Try 先到。按照前面允许空回滚的逻辑,回滚会返回成功,事务管理器认为事务已回滚成功,则此时的 Try 接口不应该执行,否则会产生数据不一致,所以我们在 Cancel 空回滚返回成功之前先记录该条事务 xid 或业务主键,标识这条记录已经回滚过,Try 接口先检查这条事务xid或业务主键如果已经标记为回滚成功过,则不执行 Try 的业务操作。
TCC 设计 – 幂等控制: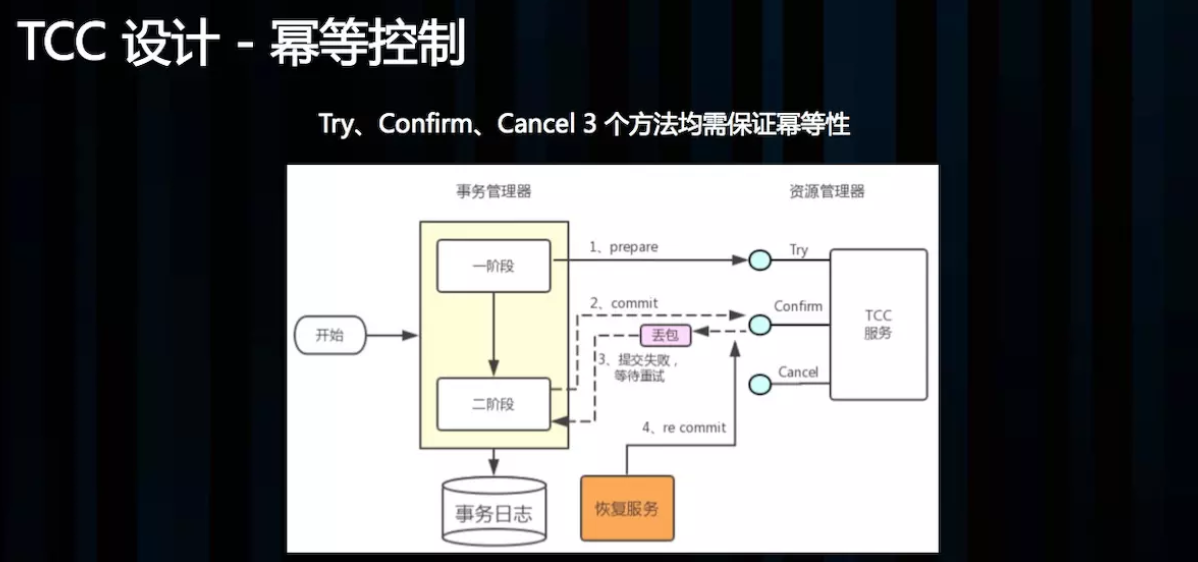
幂等性的意思是:对同一个系统,使用同样的条件,一次请求和重复的多次请求对系统资源的影响是一致的。因为网络抖动或拥堵可能会超时,事务管理器会对资源进行重试操作,所以很可能一个业务操作会被重复调用,为了不因为重复调用而多次占用资源,需要对服务设计时进行幂等控制,通常我们可以用事务 xid 或业务主键判重来控制。
Saga 模式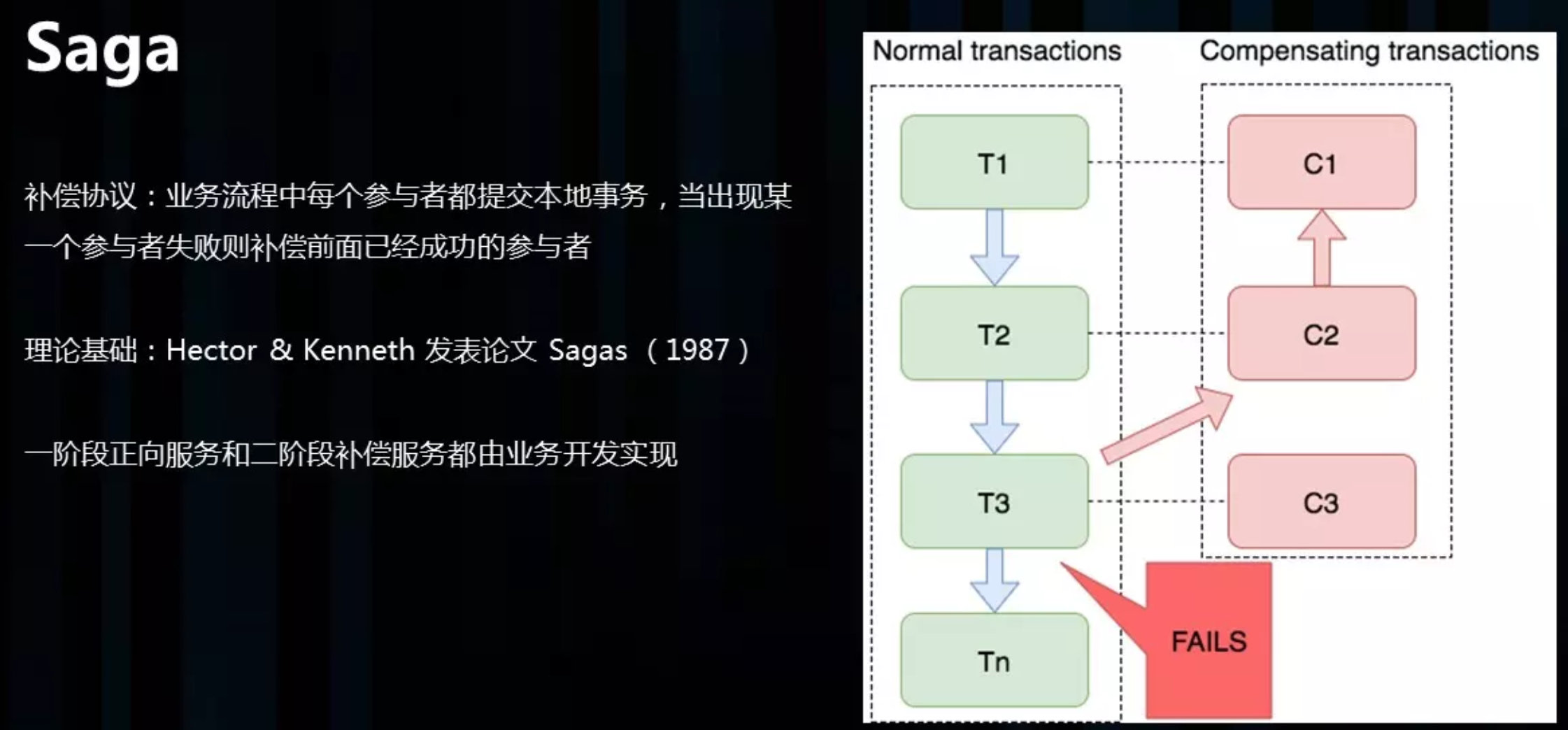
Saga 理论出自 Hector & Kenneth 1987发表的论文 Sagas。
saga模式的实现,是长事务解决方案。
Saga 是一种补偿协议,在 Saga 模式下,分布式事务内有多个参与者,每一个参与者都是一个冲正补偿服务,需要用户根据业务场景实现其正向操作和逆向回滚操作。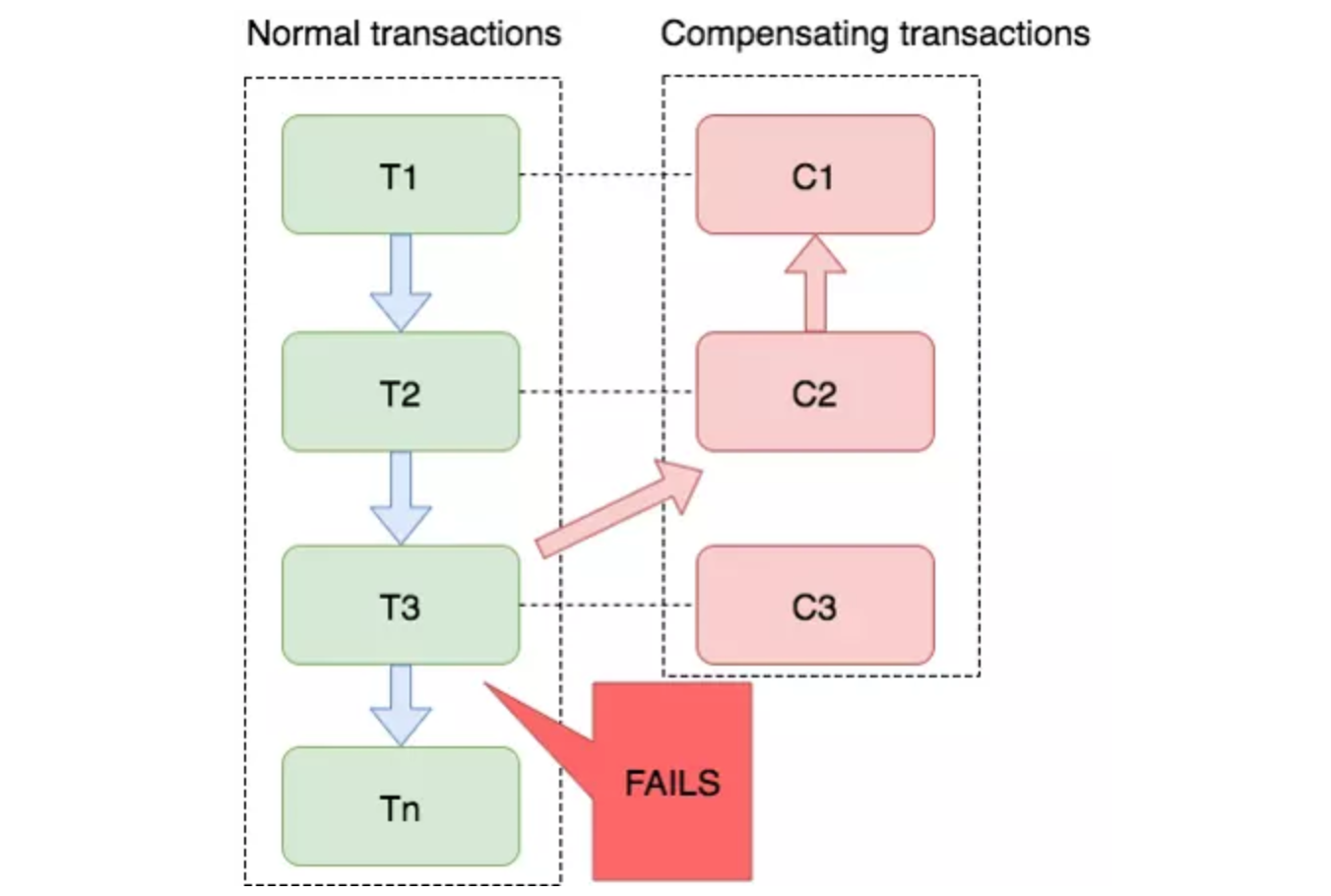
如图:T1~T3 都是正向的业务流程,都对应着一个冲正逆向操作C1~C3
分布式事务执行过程中,依次执行各参与者的正向操作,如果所有正向操作均执行成功,那么分布式事务提交。如果任何一个正向操作执行失败,那么分布式事务会退回去执行前面各参与者的逆向回滚操作,回滚已提交的参与者,使分布式事务回到初始状态。
Saga 正向服务与补偿服务也需要业务开发者实现。因此是业务入侵的。
Saga 模式下分布式事务通常是由事件驱动的,各个参与者之间是异步执行的,Saga 模式是一种长事务解决案。
Saga 模式使用场景
Saga 模式适用于业务流程长且需要保证事务最终一致性的业务系统,Saga 模式一阶段就会提交本地事务,无锁、长流程情况下可以保证性能。事务参与者可能是其它公司的服务或者是遗留系统的服务,无法进行改造和提供 TCC 要求的接口,可以使用 Saga 模式。
Saga模式的优势是
- 一阶段提交本地数据库事务,无锁,高性能;
- 参与者可以采用事务驱动异步执行,高吞吐;
- 补偿服务即正向服务的“反向”,易于理解,易于实现;
缺点:Saga 模式由于一阶段已经提交本地数据库事务,且没有进行“预留”动作,所以不能保证隔离性。后续会讲到对于缺乏隔离性的应对措施。与TCC实践经验相同的是,Saga 模式中,每个事务参与者的冲正、逆向操作,
需要支持:
- 空补偿:逆向操作早于正向操作时;
- 防悬挂控制:空补偿后要拒绝正向操作
- 幂等
XA 模式
XA是X/Open DTP组织(X/Open DTP group)定义的两阶段提交协议,XA被许多数据库(如Oracle、DB2、SQL Server、MySQL)和中间件等工具(如CICS 和 Tuxedo)本地支持 。X/Open DTP模型(1994)包括应用程序(AP)、事务管理器(TM)、资源管理器(RM)。
XA接口函数由数据库厂商提供。 XA规范的基础是两阶段提交协议2PC。
JTA(Java Transaction API) 是Java实现的XA规范的增强版 接口。
在XA模式下,需要有一个[全局]协调器,每一个数据库事务完成后,进行第一阶段预提交,并通知协调器,把结果给协调器。协调器等所有分支事务操作完成、都预提交后,进行第二步;第二步:协调器通知每个数据库进行逐个commit/rollback。其中,这个全局协调器就是XA模型中的TM角色,每个分支事务各自的数据库就是RM。
MySQL 提供的XA实现(https://dev.mysql.com/doc/refman/5.7/en/xa.html )
XA模式下的 开源框架有atomikos,其开发公司也有商业版本。
XA模式缺点:事务粒度大。高并发下,系统可用性低。因此很少使用。
四种模式分析
四种分布式事务模式,分别在不同的时间被提出,每种模式都有它的适用场景
- AT 模式是无侵入的分布式事务解决方案,适用于不希望对业务进行改造的场景,几乎0学习成本。
- TCC 模式是高性能分布式事务解决方案,适用于核心系统等对性能有很高要求的场景。
- Saga 模式是长事务解决方案,适用于业务流程长且需要保证事务最终一致性的业务系统,Saga 模式一阶段就会提交本地事务,无锁,长流程情况下可以保证性能,多用于渠道层、集成层业务系统。事务参与者可能是其它公司的服务或者是遗留系统的服务,无法进行改造和提供TCC 要求的接口,也可以使用 Saga 模式。
- XA模式是分布式强一致性的解决方案,但性能低而使用较少。
总结
分布式事务本身就是一个技术难题,业务中具体使用哪种方案还是需要不同的业务特点自行选择,但是我们也会发现,分布式事务会大大的提高流程的复杂度,会带来很多额外的开销工作,「代码量上去了,业务复杂了,性能下跌了」。所以,当我们真实开发的过程中,能不使用分布式事务就不使用。
Seata 分布式事务概念
Seata 是什么
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和XA 事务模式,为用户打造一站式的分布式解决方案。AT模式是阿里首推的模式,阿里云上有商用版本的GTS(Global TransactionService 全局事务服务)
官网:https://seata.io/zh-cn/index.html
源码: https://github.com/seata/seata
官方Demo : https://github.com/seata/seata-samples
seata版本:v1.4.0
Seata的三大角色
在 Seata 的架构中,一共有三个角色:
TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
其中,TC 为单独部署的 Server 服务端,TM 和 RM 为嵌入到应用中的 Client 客户端。
在 Seata 中,一个分布式事务的生命周期如下:
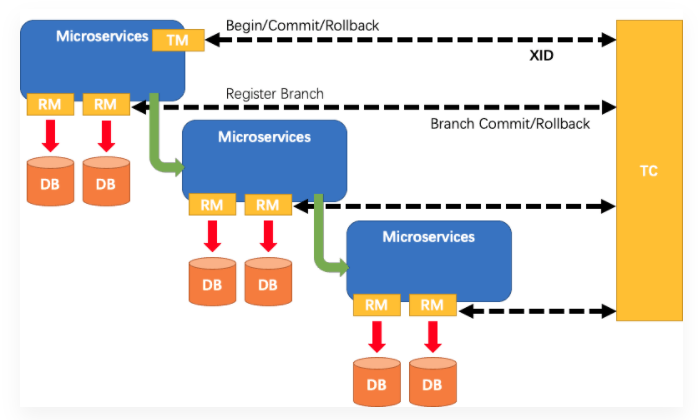
执行流程
TM 请求 TC 开启一个全局事务。TC 会生成一个 XID 作为该全局事务的编号。XID会在微服务的调用链路中传播,保证将多个微服务的子事务关联在一起。当一进入事务方法中就会生成XID ;
(global_table 就是存储的全局事务信息 )
RM 请求 TC 将本地事务注册为全局事务的分支事务,通过全局事务的 XID 进行关联。
当运行数据库操作方法,branch_table 存储事务参与者
- TM 请求 TC 告诉 XID 对应的全局事务是进行提交还是回滚。
- TC 驱动 RM 们将 XID 对应的自己的本地事务进行提交还是回滚。
设计思路
AT模式的核心是对业务无侵入,是一种改进后的两阶段提交,其设计思路如图
- 第一阶段
业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。核心在于对业务 sql 进行解析,转换成 undolog,并同时入库,这是怎么做的呢?先抛出一个概念 DataSourceProxy 代理数据源,通过名字大家大概也能基本猜到是什么个操作,后面做具体分析
参考官方文档: https://seata.io/zh-cn/docs/dev/mode/at-mode.html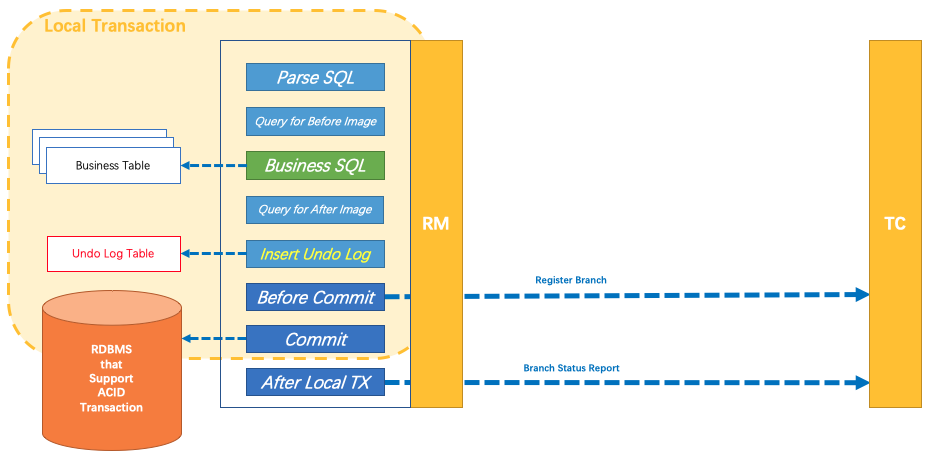
- 第二阶段
分布式事务操作成功,则TC通知RM异步删除undolog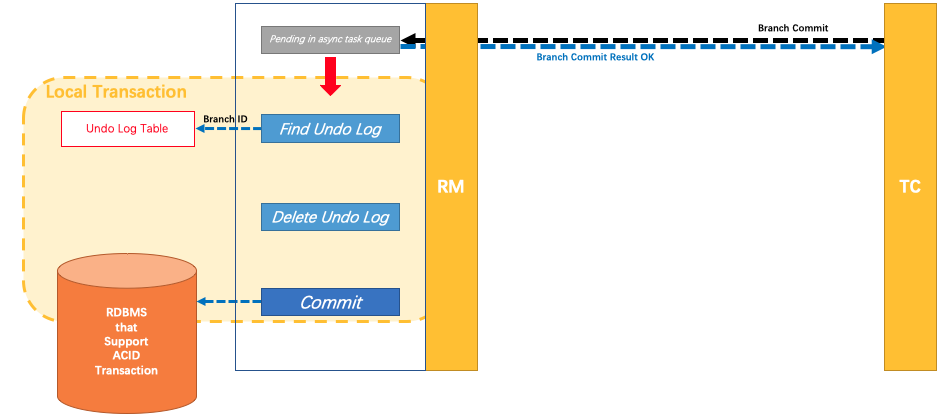
分布式事务操作失败,TM向TC发送回滚请求,RM 收到协调器TC发来的回滚请求,通过 XID 和 Branch ID 找到相应的回滚日志记录,通过回滚记录生成反向的更新 SQL 并执行,以完成分支的回滚。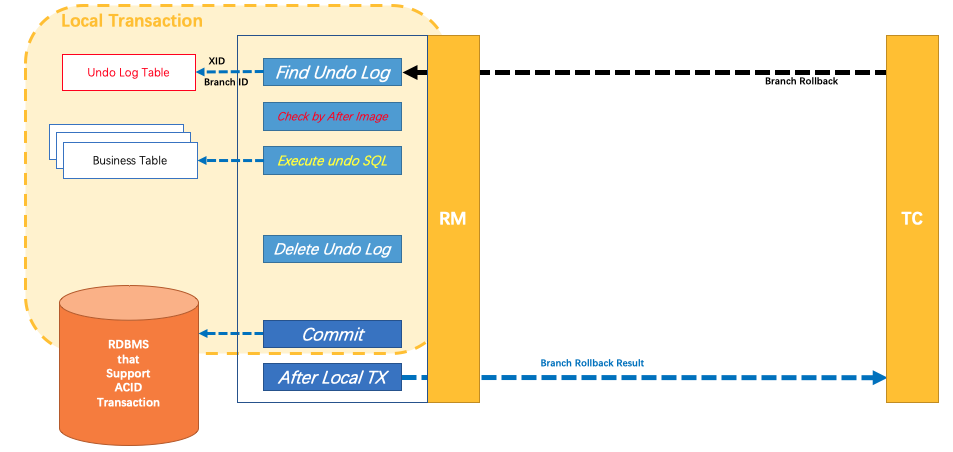
整体执行流程

设计亮点
相比与其它分布式事务框架,Seata架构的亮点主要有几个:
- 应用层基于 SQL解析实现了自动补偿,从而最大程度的降低业务侵入性;
- 将分布式事务中TC(事务协调者)独立部署,负责事务的注册、回滚;
- 通过全局锁实现了写隔离与读隔离。
存在的问题
- 性能损耗
一条 Update 的SQL,则需要全局事务xid获取(与TC通讯)、before image(解析SQL,查询一次数据库)、after image(查询一次数据库)、insert undo log(写一次数据库)、before commit(与TC通讯,判断锁冲突),这些操作都需要一次远程通讯RPC,而且是同步的。另外 undo log 写入时 blob 字段的插入性能也是不高的。每条写SQL都会增加这么多开销,粗略估计会增加5倍响应时间。
- 性价比
为了进行自动补偿,需要对所有交易生成前后镜像并持久化,可是在实际业务场景下,这个是成功率有多高,或者说分布式事务失败需要回滚的有多少比率?按照二八原则预估,为了20%的交易回滚,需要将80%的成功交易的响应时间增加5倍,这样的代价相比于让应用开发一个补偿交易是否是值得?
- 全局锁
热点数据
相比XA,Seata 虽然在一阶段成功后会释放数据库锁,但一阶段在commit前全局锁的判定也拉长了对数据锁的占有时间,这个开销比XA的prepare低多少需要根据实际业务场景进行测试。全局锁的引入实现了隔离性,但带来的问题就是阻塞,降低并发性,尤其是热点数据,这个问题会更加严重。
- 回滚锁释放时间
Seata在回滚时,需要先删除各节点的undo log,然后才能释放TC内存中的锁,所以如果第二阶段是回滚,释放锁的时间会更长。
- 死锁问题
Seata的引入全局锁会额外增加死锁的风险,但如果出现死锁,会不断进行重试,最后靠等待全局锁超时,这种方式并不优雅,也延长了对数据库锁的占有时间。
Seata快速开始
Seata Server(TC)环境搭建
seata 官网文档
https://seata.io/zh-cn/docs/ops/deploy-guide-beginner.html
下载 Seata Server 安装包
https://github.com/seata/seata/releases
Server 端存储模式
- file:(默认) 单机模式,全局事务会话信息内存中读写并持久化本地文件 root.data,性能较高(默认)
- db :(5.7+)高可用模式,全局事务会话信息通过db共享,相应性能差些
```json- 打开config/file.conf- 修改 mode="db"- 修改数据库连接信息(URL\USERNAME\PASSWORD)- 创建数据库seata_server- 新建表: 可以去seata提供的资源信息中下载:- [点击查看](https://github.com/seata/seata/tree/1.3.0/script)- \script\server\db\mysql.sql
transaction log store, only used in seata-server
store {
store mode: file、db、redis
mode = “db”
database store property
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp)/HikariDataSource(hikari) etc.datasource = "druid"## mysql/oracle/postgresql/h2/oceanbase etc.dbType = "mysql"driverClassName = "com.mysql.jdbc.Driver"url = "jdbc:mysql://127.0.0.1:3307/seata-server"user = "root"password = "zlp123456"minConn = 5maxConn = 30globalTable = "global_table"branchTable = "branch_table"lockTable = "lock_table"queryLimit = 100maxWait = 5000
}
}
redis:Seata-Server 1.3及以上版本支持,性能较高,存在事务信息丢失风险,请提前配置适合当前场景的redis持久化配置<br />资源目录: [https://github.com/seata/seata/tree/1.3.0/script](https://github.com/seata/seata/tree/1.3.0/script)- client存放client端sql脚本,参数配置- config-center各个配置中心参数导入脚本,config.txt(包含server和client,原名nacos-config.txt)为通用参数文件- serverserver端数据库脚本及各个容器配置<a name="tM6Zf"></a>### db存储模式+Nacos(注册&配置中心)部署<a name="MgcDM"></a>#### 注册中心将Seata Server注册到Nacos,修改conf目录下的registry.conf配置```jsonregistry {# file 、nacos 、eureka、redis、zk、consul、etcd3、sofatype = "nacos"nacos {application = "seata-server"serverAddr = "127.0.0.1:8848"group = "SEATA_GROUP"namespace = ""cluster = "default"username = "nacos"password = "nacos"}redis {serverAddr = "localhost:6379"db = 0password = ""cluster = "default"timeout = 0}file {name = "file.conf"}}
启动
然后启动注册中心Nacos Server
进入Nacos 安装目录,启动Nacos
startup.bat‐m standalone
启动seata-server 服务,进入\seata\bin目录
seata-server.bat

配置中心
config {# file、nacos 、apollo、zk、consul、etcd3#type = "file"type = "nacos"nacos {serverAddr = "127.0.0.1:8848"namespace = ""group = "SEATA_GROUP"username = "nacos"password = "nacos"}file {name = "file.conf"}}
注意:如果配置了 seata server 使用 nacos 作为配置中心,则配置信息会从nacos读取,file.conf可以不用配置。 客户端配置 registry.conf 使用 nacos 时也要注意group要和seata server中的group一致,默认group是”DEFAULT_GROUP”
获取/seata/script/config-center/config.txt,修改配置信息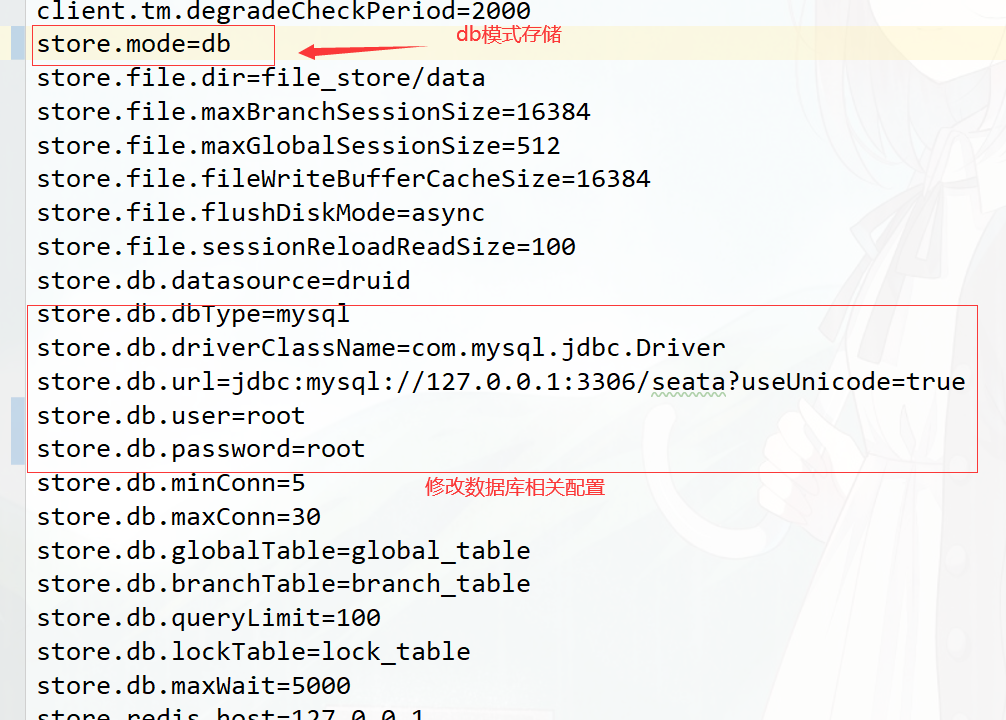
配置事务分组, 要与客户端配置的事务分组一致
#my_test_tx_group 需要与客户端保持一致 default需要跟客户端和 registry.conf 中 registry 中的cluster保持一致
(客户端properties配置:spring.cloud.alibaba.seata.tx‐service‐group=my_test_tx_group)
事务分组: 异地机房停电容错机制
my_test_tx_group 可以自定义 比如:(guangzhou、shanghai…) , 对应的client也要去设置
seata.service.vgroup‐mapping.projectA=guangzhou
default 必须要等于 registry.confi cluster = “default”
配置参数同步到Nacos
shell:
sh ${SEATAPATH}/script/config-center/nacos/nacos‐config.sh ‐h localhost ‐p 8848 ‐g SEATA_GROUP
参数说明:
-h: host,默认值 localhost
-p: port,默认值 8848
-g: 配置分组,默认值为 ‘SEATA_GROUP’
-t: 命名空间信息,对应 Nacos 的命名空间ID字段, 默认值为空 ‘’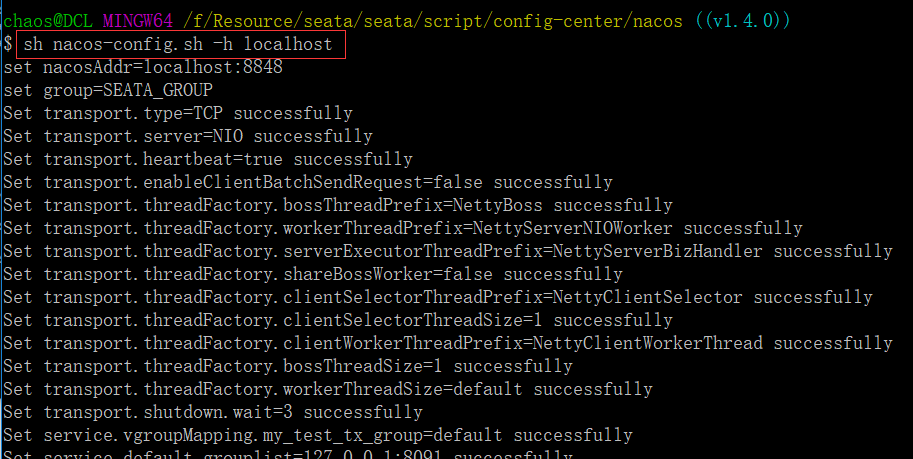
精简配置
service.vgroupMapping.my_test_tx_group=defaultservice.default.grouplist=127.0.0.1:8091service.enableDegrade=falseservice.disableGlobalTransaction=falseclient.rm.asyncCommitBufferLimit=10000client.rm.lock.retryInterval=10client.rm.lock.retryTimes=30client.rm.lock.retryPolicyBranchRollbackOnConflict=trueclient.rm.reportRetryCount=5client.rm.tableMetaCheckEnable=falseclient.rm.sqlParserType=druidclient.rm.reportSuccessEnable=falseclient.rm.sagaBranchRegisterEnable=falseclient.tm.commitRetryCount=5client.tm.rollbackRetryCount=5client.tm.degradeCheck=falseclient.tm.degradeCheckAllowTimes=10client.tm.degradeCheckPeriod=2000store.mode=dbstore.db.datasource=druidstore.db.dbType=mysqlstore.db.driverClassName=com.mysql.jdbc.Driverstore.db.url=jdbc:mysql://127.0.0.1:3306/seata?useUnicode=truestore.db.user=usernamestore.db.password=passwordstore.db.minConn=5store.db.maxConn=30store.db.globalTable=global_tablestore.db.branchTable=branch_tablestore.db.queryLimit=100store.db.lockTable=lock_tablestore.db.maxWait=5000
启动Seata Server
源码启动: 执行server模块下io.seata.server.Server.java的main方法
命令启动: bin/seata-server.sh -h 127.0.0.1 -p 8091 -m db -n 1 -e test

集群模式启动Seata Server
bin/seata‐server.sh ‐p 8091 ‐n 1
bin/seata‐server.sh ‐p 8092 ‐n 2
bin/seata‐server.sh ‐p 8093 ‐n 3
启动成功,默认端口8091
在注册中心中可以查看到seata-server注册成功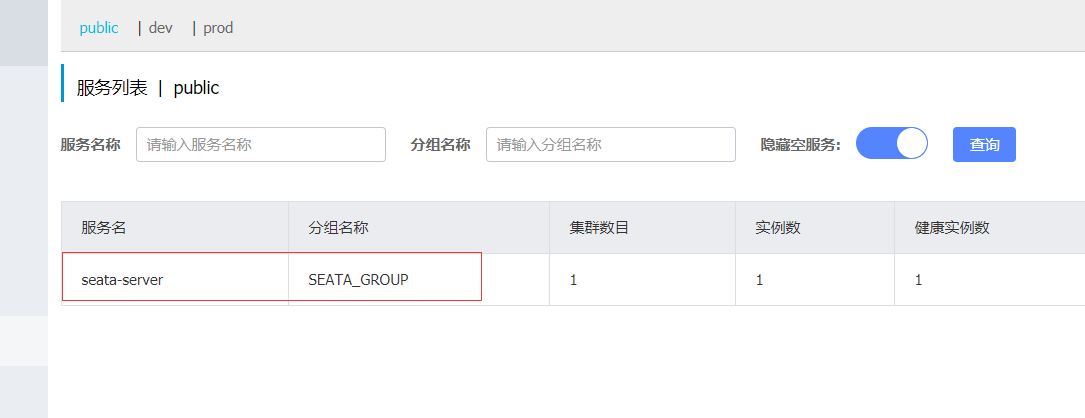
Seata Client 快速开始
接入微服务应用
业务场景:
用户下单,整个业务逻辑由二个微服务构成:
- 订单服务:根据采购需求创建订单。
- 库存服务:对给定的商品扣除库存数量。
启动Seata server端,Seata server使用nacos作为配置中心和注册中心(上一步已完成)
配置微服务整合 seata
第一步:添加pom依赖
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId></dependency>
第二步: 各微服务对应数据库中添加 undo_log表
-- for AT mode you must to init this sql for you business database. the seata server not need it.CREATE TABLE IF NOT EXISTS `undo_log`(`branch_id` BIGINT(20) NOT NULL COMMENT 'branch transaction id',`xid` VARCHAR(100) NOT NULL COMMENT 'global transaction id',`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such as serialization',`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',`log_status` INT(11) NOT NULL COMMENT '0:normal status,1:defense status',`log_created` DATETIME(6) NOT NULL COMMENT 'create datetime',`log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime',UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)) ENGINE = InnoDBAUTO_INCREMENT = 1DEFAULT CHARSET = utf8 COMMENT ='AT transaction mode undo table';
第三步:修改register.conf,配置nacos作为registry.type&config.type,对应seata server也使用nacos
注意:需要指定group = “SEATA_GROUP”,因为Seata Server端指定了group = “SEATA_GROUP” ,必须保证一致
registry {# file 、nacos 、eureka、redis、zk、consul、etcd3、sofatype = "nacos"nacos {application = "seata-server"serverAddr = "127.0.0.1:8848"group = "SEATA_GROUP"namespace = ""cluster = "default"username = "nacos"password = "nacos"}redis {serverAddr = "localhost:6379"db = 0password = ""cluster = "default"timeout = 0}file {name = "file.conf"}}config {# file、nacos 、apollo、zk、consul、etcd3#type = "file"type = "nacos"nacos {serverAddr = "127.0.0.1:8848"namespace = ""group = "SEATA_GROUP"username = "nacos"password = "nacos"}file {name = "file.conf"}}
如果出现这种问题:
一般大多数情况下都是因为配置不匹配导致的:
- 检查现在使用的seata服务和项目maven中seata的版本是否一致
- 检查 tx-service-group,nacos.cluster,nacos.group 参数是否和Seata Server中的配置一致
跟踪源码:seata/discover包下实现了RegistryService#lookup,用来获取服务列表
NacosRegistryServiceImpl#lookup String clusterName = getServiceGroup(key); #获取seata server集群名称 List
firstAllInstances = getNamingInstance().getAllInstances(getServiceName(), getServiceGroup(), clusters)
第四步:修改application.yml配置
配置seata 服务事务分组,要与服务端nacos配置中心中service.vgroup_mapping的后缀对应
server:## 启动端口port: 8150# 数据源spring:datasource:username: rootpassword: zlp123456url: jdbc:mysql://47.103.20.21:3307/zlp-mall?characterEncoding=utf8&useSSL=false&serverTimezone=UTC&driver-class-name: com.mysql.cj.jdbc.Drivertype: com.alibaba.druid.pool.DruidDataSource#初始化时运行sql脚本schema: classpath:sql/schema.sqlinitialization-mode: neverapplication:name: stock-seatacloud:nacos:discovery:server-addr: 127.0.0.1:8848username: nacospassword: nacosalibaba:seata:tx-service-group: my_test_tx_group #配置事务分组#设置mybatismybatis:mapper-locations: classpath:/mapper/*Mapper.xml#config-location: classpath:mybatis-config.xmltypeAliasesPackage: com.zlp.seata.order.pojoconfiguration:mapUnderscoreToCamelCase: trueseata:registry:# 配置seata的注册中心, 告诉seata client 怎么去访问seata server(TC)type: nacosnacos:server-addr: 127.0.0.1:8848 # seata server 所在的nacos服务地址application: seata-server # seata server 的服务名seata-server ,如果没有修改可以不配username: nacospassword: nacosgroup: SEATA_GROUP # seata server 所在的组,默认就是SEATA_GROUP,没有改也可以不配config:type: nacosnacos:server-addr: 127.0.0.1:8848username: nacospassword: nacosgroup: SEATA_GROUPlogging:level:com.zlp.seata.stock.mapper: debug
第五步 微服务发起者(TM 方)需要添加@GlobalTransactional注解
/*** 下单* @date 2021-12-1 14:51:18*/@Override@GlobalTransactionalpublic Order create(Order order) {log.info("create.req order={}", JSON.toJSONString(order));// 插入订单orderMapper.insert(order);// 扣减库存 能否成功?stockService.reduct(order.getProductId());// 异常int a = 1 / 0;return order;}
第六步 测试结果
没有添加 @GlobalTransactional
模拟正常下单、扣库存异常;结果是订单数据库插入成功,扣库存失败
添加 @GlobalTransactional
模拟下单扣库存成功、扣余额失败,订单事务和库存事务正常回滚
源码分析
Gateway 网关
网关简介
Spring Cloud Gateway是Spring Cloud推出的第二代网关框架,取代Zuul网关。网关作为流量的,在微服务系统中有着非常作用,网关常见的功能有路由转发、权限校验、限流控制等作用。相对Zuul有哪些优势?Zuul(1.x) 基于 Servlet,使用阻塞 API,它不支持任何长连接,如 WebSockets,Spring Cloud Gateway 使用非阻塞 API,支持 WebSockets,支持限流等新特性。
为什么要使用网关
大家都都知道在微服务架构中,一个系统会被拆分为很多个微服务。那么作为客户端要如何去调用这么多的微服务呢?如果没有网关的存在,我们只能在客户端记录每个微服务的地址,然后分别去用。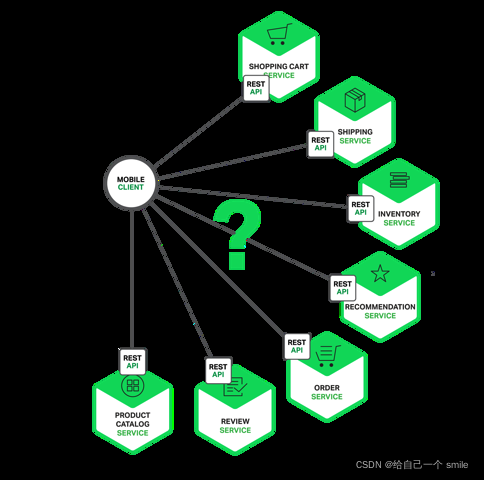
这样的架构,会存在着诸多的问题:
- 每个业务都会需要鉴权、限流、权限校验、跨域等逻辑,如果每个业务都各自为战,自己造轮子实现一遍,会很蛋疼,完全可以抽出来,放到一个统一的地方去做。
- 如果业务量比较简单的话,这种方式前期不会有什么问题,但随着业务越来越复杂,比如淘宝、亚马逊打开一个页面可能会涉及到数百个微服务协同工作,如果每一个微服务都分配一个域名的话,一方面客户端代码会很难维护,涉及到数百个域名,另一方面是连接数的瓶颈,想象一下你打开一个APP,通过抓包发现涉及到了数百个远程调用,这在移动端下会显得非常低效。
- 后期如果需要对微服务进行重构的话,也会变的非常麻烦,需要客户端配合你一起进行改造,比如商品服务,随着业务变的越来越复杂,后期需要进行拆分成多个微服务,这个时候对外提供的服务也需要拆分成多个,同时需要客户端配合你进行改造,非常蛋疼。
上面的这些问题可以借助API网关来解决。
所谓的API网关:就是指系统的统一入口,它封装了应用程序的内部结构,为客户端提供统一服务,一些与业务本身功能无关的公共逻辑可以在这里实现,诸如认证、鉴权、监控、路由转发等等。
添加上API网关之后,系统的架构图变成了如下所示: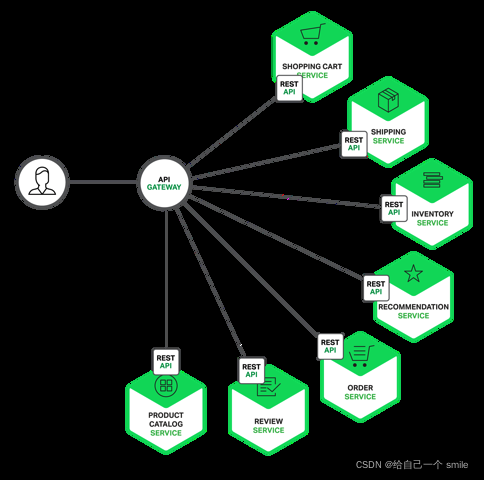
什么是Spring Cloud Gateway
网关作为流量的入口,常用的功能包括路由转发,权限校验,限流等。
Spring Cloud Gateway 是Spring Cloud官方推出的第二代网关框架,定位于取代 Netflix Zuul1.0。相比 Zuul 来说,Spring CloudGateway 提供更优秀的性能,更强大的有功能。
Spring Cloud Gateway 是由 WebFlux + Netty + Reactor 实现的响应式的 API 网关。它不能在传统的 servlet 容器中工作,也不能构建成 war 包。
Spring Cloud Gateway 旨在为微服务架构提供一种简单且有效的 API 路由的管理方式,并基于 Filter 的方式提供网关的基本功能,例如说安全认证、监控、限流等等。
其他的网关组件
在 SpringCloud 微服务体系中,有个很重要的组件就是网关,在1.x版本中都是采用的Zuul网关;但在2.x版本中,zuul的升级一直跳票,SpringCloud最后自己研发了一个网关替代Zuul,那就是SpringCloud Gateway网上很多地方都说Zuul是阻塞的,Gateway是非阻塞的,这么说是不严谨的,准确的讲Zuul1.x是阻塞的,而在2.x的版本中,Zuul也是基于Netty,也是非阻塞的,如果一定要说性能,其实这个真没多大差距。
而官方出过一个测试项目,创建了一个benchmark的测试项目:spring-cloud-gateway-bench,其中对比了:
官网文档:https://docs.spring.io/spring-cloud-gateway/docs/current/reference/html/#gateway-request-predicates-factorieshttps://docs.spring.io/spring-cloud-gateway/docs/current/reference/html/#gateway-request-predicates-factories
Spring Cloud Gateway 特性
- 基于 Java 8 编码;
- 基于Spring Framework 5,Project Reactor和Spring Boot 2.0构建
- 支持动态路由,能够匹配任何请求属性上的路由。
- 支持内置 到 Spring Handler 映射 中的 路 由 匹配;
- 支持基于 HTTP 请求的路由匹配( Path、 Method、 Header、 Host 等);
- 集成了Hystrix断路器
- 过滤器作用于匹配的路 由;
- 过滤器可以修改 HTTP 请求和HTTP 响应( 增加/ 修改 头部、 增加/ 修改 请求 参数、 改写 请求 路径 等);
- 支持 Spring Cloud DiscoveryClient 配置路由,与服务发现与注册配合使用。
- 支持限流
- 支持地址重写
-
核心概念
路由是网关中最基础的部分,路由信息包括一个ID、一个目的URI、一组断言工厂、一组Filter组成。如果断言为真,则说明请求的URL和配置的路由匹配。
断言(predicates)
Java8中的断言函数,SpringCloud Gateway中的断言函数类型是Spring5.0框架中的ServerWebExchange。断言函数允许开发者去定义匹配Http request中的任何信息,比如请求头和参数等。
- 过滤器(Filter)
SpringCloud Gateway中的filter分为Gateway FilIer和Global Filter。Filter可以对请求和响应进行处理。
工作原理
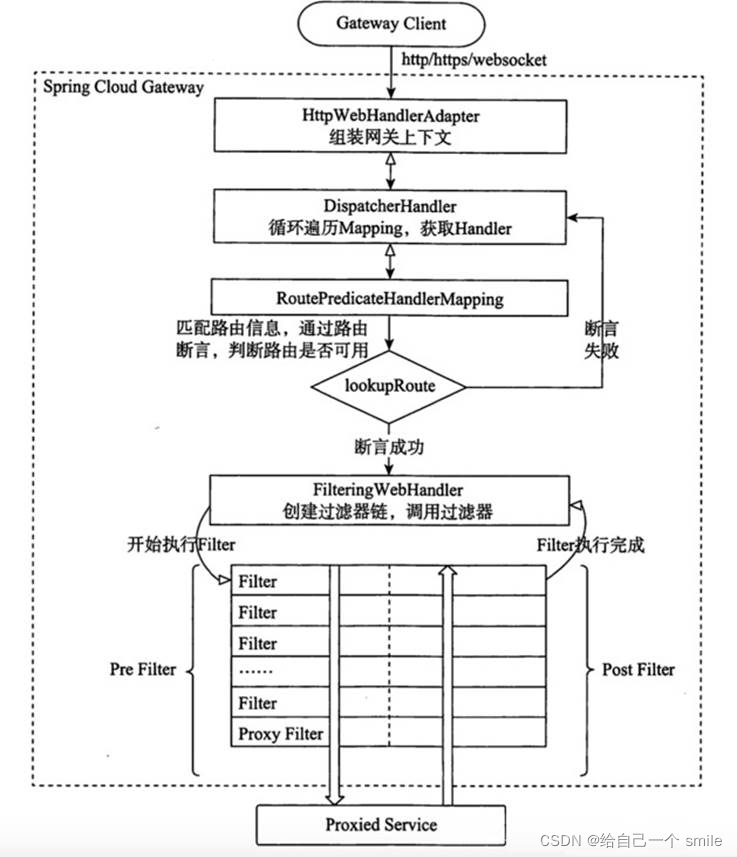
执行流程大体如下:
- Gateway Client向Gateway Server发送请求
- 请求首先会被HttpWebHandlerAdapter进行提取组装成网关上下文
- 然后网关的上下文会传递到DispatcherHandler,它负责将请求分发给RoutePredicateHandlerMapping
- RoutePredicateHandlerMapping负责路由查找,并根据路由断言判断路由是否可用
- 如果过断言成功,由FilteringWebHandler创建过滤器链并调用
- 请求会一次经过PreFilter—微服务—PostFilter的方法,最终返回响应
Spring Cloud Gateway 快速开始
环境搭建
引入依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId></dependency>
yml 配置文件
```java server: port: 9999
spring: application: name: gateway-service cloud: gateway: routes:
- id: order #路由的ID 保证唯一uri: http://localhost:9100 # 目标服务地址:uri以lb://开头(lb代表从注册中心获取服务),后面就是需要转发到的服务名称predicates:# 断言,路径相匹配的进行路由 (谓词)- Path=/order/** # 路径匹配filters:- StripPrefix=1 # 转发去掉第一层路径
<a name="U4zCc"></a>#### geteway-order 客户端服务配置```java<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.6.RELEASE</version></parent><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.16.14</version><scope>provided</scope></dependency></dependencies>
OrderController
@RestController@RequiredArgsConstructorpublic class OrderController {private final OrderService orderService;@GetMapping("getOrder")public OrderDTO getOrder(){return orderService.getOrder();}}
测试访问
通过网关访问 gateway-service 服务
http://127.0.0.1:9999/order/getOrder
集成Nacos
引入依赖
<!--alibaba-nacos-discovery(阿里注册中心discovery)--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency>
yml 配置
server:port: 9999spring:application:name: gateway-servicecloud:gateway:routes:- id: order #路由的ID 保证唯一# uri: http://localhost:9100 # 目标服务地址:uri以lb://开头(lb代表从注册中心获取服务),后面就是需要转发到的服务名称uri: lb://gateway‐orderpredicates:# 断言,路径相匹配的进行路由 (谓词)- Path=/order/** # 路径匹配filters:- StripPrefix=1 # 转发去掉第一层路径# nacos confignacos:discovery:server-addr: 127.0.0.1:8848username: nacospassword: nacos
测试访问
http://127.0.0.1:9999/order/getOrder
gateway-order 服务同上也要配置 nacos 注册中心
动态路由配置
yml 配置
server:port: 9999spring:application:name: gateway-service# nacos confignacos:discovery:server-addr: 127.0.0.1:8848username: nacospassword: nacoscloud:## gateway配置gateway:discovery:locator:# 开启自动代理 (自动装载从配置中心serviceId)enabled: true# 服务id为true --> 这样小写服务就可访问了lower-case-service-id: true
测试访问
http://127.0.0.1:9999/gateway-order/getOrder
说明:gateway-order 服务名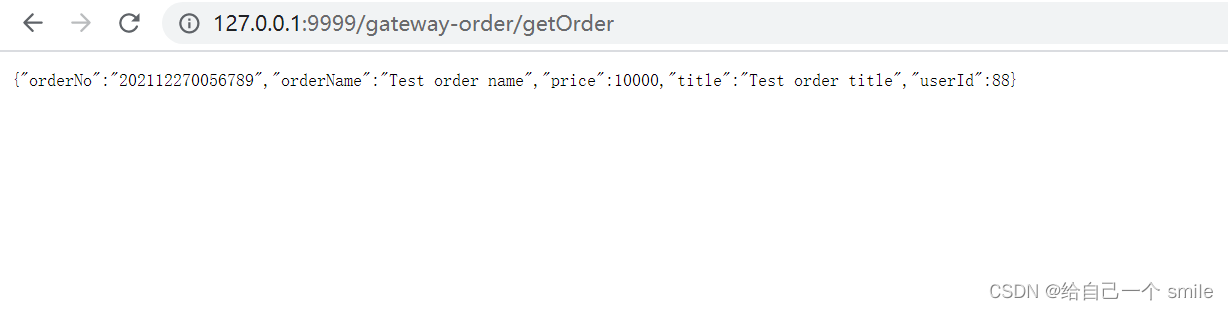
路由断言工厂
Spring Cloud Gateway Predicate Factory
Spring Cloud Gateway 创建 Route 对象时, 使用 RoutePredicateFactory 创建 Predicate 对象,Predicate 对象可以赋值给 Route。
- Spring Cloud Gateway 包含许多内置的 Route Predicate Factories。
- 所有这些断言都匹配 HTTP 请求的不同属性。
- 多个 Route Predicate Factories 可以通过逻辑与(and)结合起来一起使用。
路由断言工厂 RoutePredicateFactory 包含的主要实现类如图所示,包括 Datetime、 请求的远端地址、 路由权重、 请求头、 Host 地址、 请求方法、 请求路径和请求参数等类型的路由断言。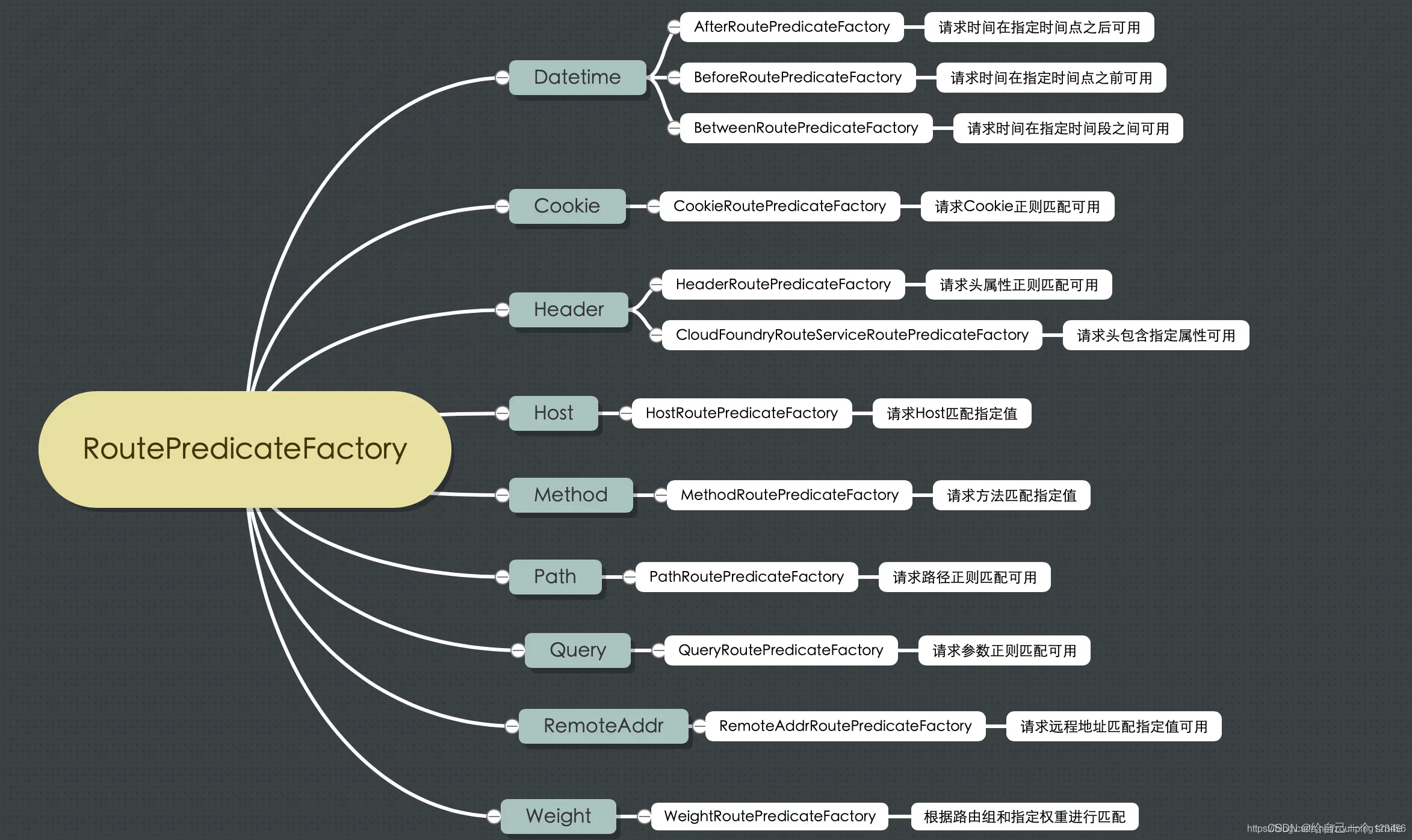
Path 路径匹配
在getaway配置文件中添加 Path
规则:
yml 配置
spring:application:name: gateway-servicecloud:## nacos注册中心nacos:discovery:server-addr: 127.0.0.1:8848gateway:routes:- id: user #路由的ID 保证唯一uri: lb://gateway‐order # 目标服务地址predicates:# 断言,路径相匹配的进行路由 (谓词)- Path=/order/** # 路径匹配
测试结果
http://127.0.0.1:9999/order/getOrderDetail
输出结果
时间断言
yml 配置
spring:cloud:gateway:routes:- id: order #路由的ID 保证唯一uri: lb://gateway-orderpredicates:# 断言,路径相匹配的进行路由 (谓词)# - Path=/order/** # 路径匹配- After=2021-12-27T16:20:00+08:00[Asia/Shanghai] # 在指定时间之后的请求会匹配该路由# nacos confignacos:discovery:server-addr: 127.0.0.1:8848username: nacospassword: nacos
- [Asia/Shanghai] 代表地区
请求URL http://127.0.0.1:9999/order/getOrderDetail
Query 断言
yml 配置
spring:cloud:gateway:routes:- id: order #路由的ID 保证唯一uri: lb://gateway-orderpredicates:# 断言,路径相匹配的进行路由 (谓词)# - Path=/order/** # 路径匹配# - After=2021-12-27T17:20:00+08:00[Asia/Shanghai] # 在指定时间之后的请求会匹配该路由- Query=token,^[0-9]*$ # 可以指定参数和值 ?name=数字 才允许访问# nacos confignacos:discovery:server-addr: 127.0.0.1:8848username: nacospassword: nacos
Query=token:比如,http://127.0.0.1:9999/order/getOrderDetail?token=123
Method断言
yml 配置
spring:cloud:gateway:routes:- id: order #路由的ID 保证唯一uri: lb://gateway-orderpredicates:# 断言,路径相匹配的进行路由 (谓词)# - Path=/order/** # 路径匹配- Method=GET # 必须是Get才可以访问# nacos confignacos:discovery:server-addr: 127.0.0.1:8848username: nacospassword: nacos

-
RemoteAddr
yml配置
```java spring: cloud: gateway:
routes:- id: order #路由的ID 保证唯一uri: lb://gateway-orderpredicates:# 断言,路径相匹配的进行路由 (谓词)
- Path=/order/** # 路径匹配
- RemoteAddr=192.168.10.1/0 # 匹配远程地址请求是 RemoteAddr 的请求,0表示子网掩码
nacos config
nacos:
discovery:server-addr: 127.0.0.1:8848username: nacospassword: nacos
- RemoteAddr=192.168.10.1/0:比如:[http://127.0.0.1:9000/member/getUserInfo?userId=1](http://127.0.0.1:9000/member/getUserInfo?userId=1)<a name="QX1F1"></a>### Header在请求头必须要添加X-Request-Id 字段,value可以正则表达式<a name="zBbOS"></a>### 自定义路由断言配置自定义断言工厂<br />自定义路由断言工厂需要继承 AbstractRoutePredicateFactory 类,重写 apply 方法的逻辑。在 apply 方法中可以通过exchange.getRequest() 拿到 ServerHttpRequest 对象,从而可以获取到请求的参数、请求方式、请求头等信息。<br />1. 必须spring组件 bean1. 类必须加上 RoutePredicateFactory 作为结尾1. 必须继承 AbstractRoutePredicateFactory1. 必须声明静态内部类 声明属性来接收 配置文件中对应的断言的信息1. 需要结合 shortcutFieldOrder 进行绑定1. 通过apply进行逻辑判断 true就是匹配成功 false匹配失败```javapackage com.zlp.gateway.service.config;import lombok.Getter;import lombok.Setter;import lombok.extern.slf4j.Slf4j;import org.springframework.cloud.gateway.handler.predicate.AbstractRoutePredicateFactory;import org.springframework.stereotype.Component;import org.springframework.web.server.ServerWebExchange;import java.util.function.Predicate;/*** 自定义路由断言工厂 <br/>* <p>命名需要以RoutePredicateFactory结尾 比aRoutePredicateFactory 那么yml在使用时a就是断言工厂的名字</p>* @date: 2021/4/16 14:07*/@Slf4j@Componentpublic class CheckAuthRoutePredicateFactory extends AbstractRoutePredicateFactory<CheckAuthRoutePredicateFactory.User> {public CheckAuthRoutePredicateFactory() {super(User.class);}/*** 自定义配置类* @param user* @date: 2021/4/16 14:04* @return: java.util.function.Predicate<org.springframework.web.server.ServerWebExchange>*/@Overridepublic Predicate<ServerWebExchange> apply(User user) {return exchange -> {log.info("进入apply:name={}" ,user.getName());if (user.getName().equals("kitty")) {return true;}return false;};}public static class User{@Setter@Getterprivate String name;}}
yml 配置
spring:cloud:gateway:routes:- id: order #路由的ID 保证唯一uri: lb://gateway-orderpredicates:# 断言,路径相匹配的进行路由 (谓词)- Path=/order/** # 路径匹配- name: CheckAuth # 自定义断言工厂args:name: kitty2# nacos confignacos:discovery:server-addr: 127.0.0.1:8848username: nacospassword: nacos
测试访问
当我们在配置信息中的name和apply方法中的name条件为true就是匹配成功 false匹配失败
return exchange -> {log.info("进入apply:name={}" ,user.getName());if (user.getName().equals("kitty")) {return true;}return false;};
网关过滤器 GatewayFilter
网关过滤器用于拦截并链式处理 Web 请求,可以实现横切与应用无关的需求,比如:安全、访问超时的设置等。修改传入的 HTTP 请求或传出 HTTP 响应。Spring Cloud Gateway 包含许多内置的网关过滤器工厂一共有 22 个,包括头部过滤器、 路径类过滤器、Hystrix 过滤器和重写请求 URL 的过滤器, 还有参数和状态码等其他类型的过滤器。根据过滤器工厂的用途来划分,可以分为以下几种:Header、Parameter、Path、Body、Status、Session、Redirect、Retry、RateLimiter 和 Hystrix。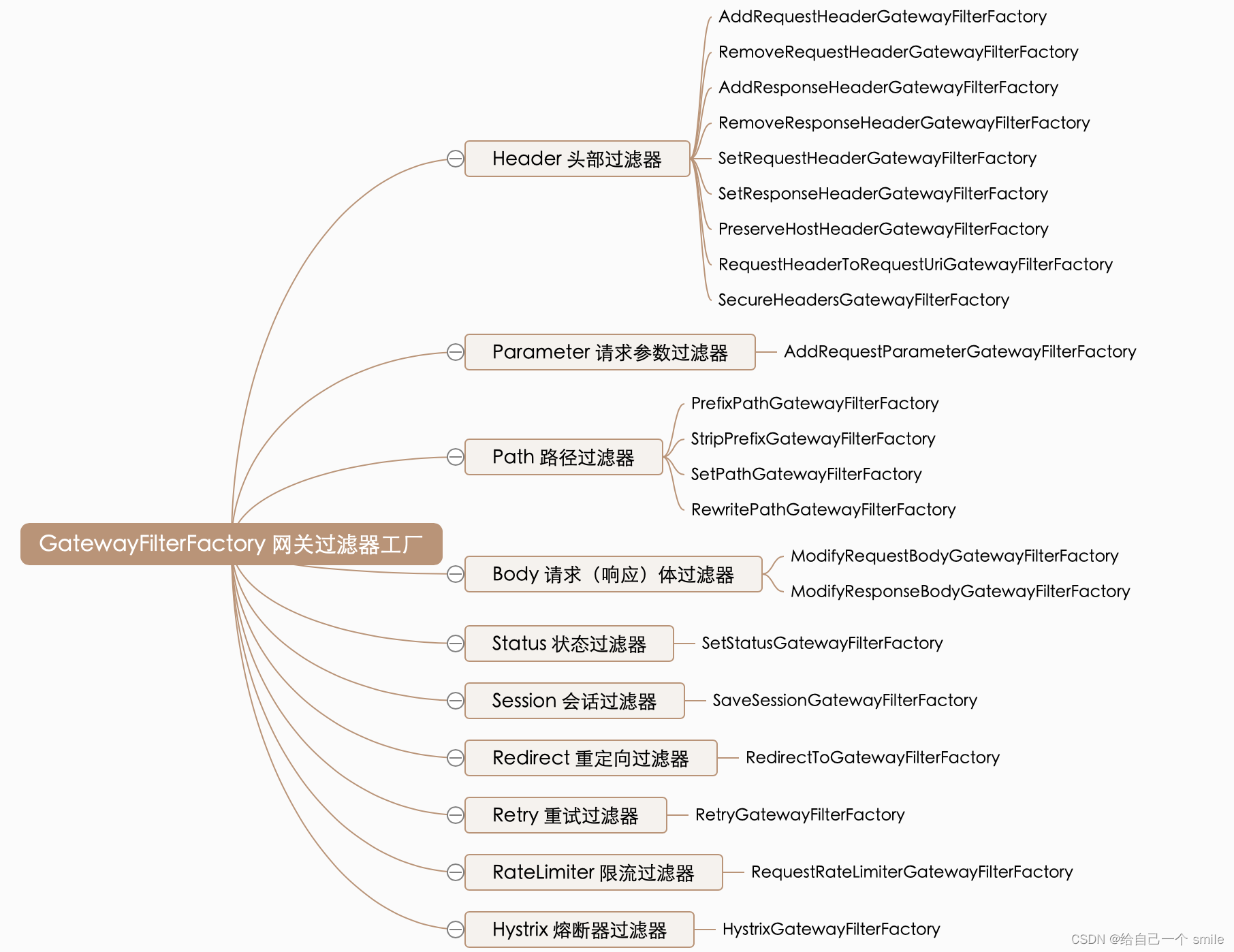

具体详细内容参考我之前写的文章 Spring Cloud : Gateway 网关过滤器 GatewayFilter(四)
Gateway 整合 Sentinel 流控降级
网关作为内部系统外的一层屏障, 对内起到一定的保护作用, 限流便是其中之一. 网关层的限流可以简单地针对不同路由进行限流,也可针对业务的接口进行限流,或者根据接口的特征分组限流。
https://github.com/alibaba/Sentinel/wiki/%E7%BD%91%E5%85%B3%E9%99%90%E6%B5%81
添加依赖
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId></dependency><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-sentinel-gateway</artifactId></dependency>
添加配置
/*** sentinel 配置信息* @date: 2021/12/27 17:07*/@Configurationpublic class GatewayConfig {@PostConstructpublic void init() {//初始化网关限流规则initGatewayRules();//自定义限流异常处理器initBlockRequestHandler();}/*** 初始化限流规则* @date: 2021/12/27 18:02*/private void initGatewayRules() {Set<GatewayFlowRule> rules = new HashSet<>();/*** resource:资源名称,可以是网关中的 route 名称或者用户自定义的 API 分组名称。* count:限流阈值* intervalSec:统计时间窗口,单位是秒,默认是 1 秒。*/rules.add(new GatewayFlowRule("order_route").setCount(1).setIntervalSec(1));// 加载网关规则GatewayRuleManager.loadRules(rules);}/*** 自定义限流异常处理器** @date: 2021/12/27 18:08*/private void initBlockRequestHandler() {HashMap<String, String> result = new HashMap<>(2);result.put("code", String.valueOf(HttpStatus.TOO_MANY_REQUESTS.value()));result.put("msg", HttpStatus.TOO_MANY_REQUESTS.getReasonPhrase());BlockRequestHandler blockRequestHandler = (serverWebExchange, throwable) -> ServerResponse.status(HttpStatus.OK).contentType(MediaType.APPLICATION_JSON).body(BodyInserters.fromValue(result));GatewayCallbackManager.setBlockHandler(blockRequestHandler);}}
测试访问
sentinel 控制台地址:http://localhost:8858/#/dashboard

自动加载限流配置规则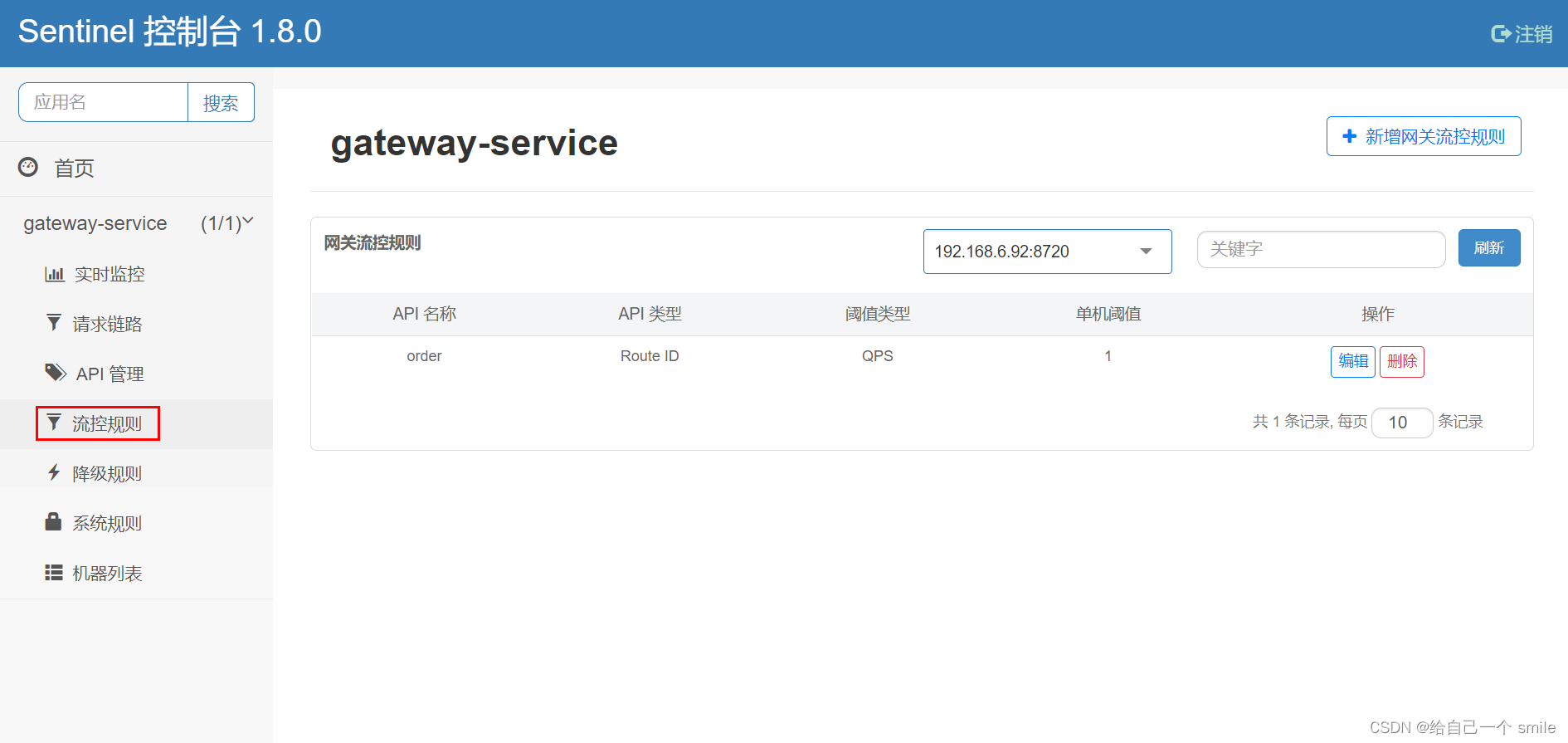

http://127.0.0.1:9999/order/getOrder
配置限流规则是:每秒只能访问一下,超过则限流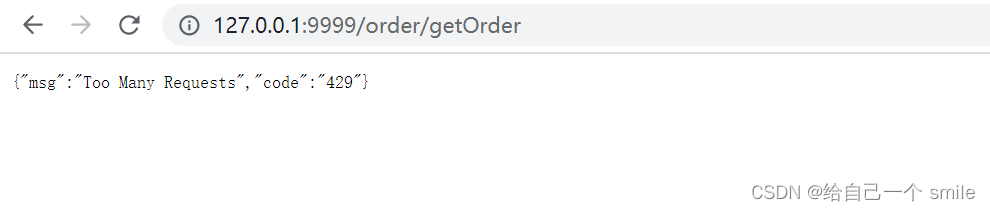

点关注不迷路,觉得对你有帮助请给一个赞或者长按一键三连,谢谢!
Skywalking 分布式任务链
链路追踪介绍
对于一个大型的几十个、几百个微服务构成的微服务架构系统,通常会遇到下面一些问题,比如:
1. 如何串联整个调用链路,快速定位问题?
2. 如何缕清各个微服务之间的依赖关系?
3. 如何进行各个微服务接口的性能分折?
4. 如何跟踪整个业务流程的调用处理顺序?
Skywalking 是什么
skywalking是一个国产开源框架,2015年由吴晟开源 , 2017年加入Apache孵化器。skywalking是分布式系统的应用程序性能监视工具,专为微服务、云原生架构和基于容器(Docker、K8s、Mesos)架构而设计。它是一款优秀的APM(Application Performance Management)工具,包括了分布式追踪、性能指标分析、应用和服务依赖分析等。
官网 : http://skywalking.apache.org/
下载 : http://skywalking.apache.org/downloads/
Github : https://github.com/apache/skywalking
文档: https://skywalking.apache.org/docs/main/v8.4.0/readme/
中文文档: https://skyapm.github.io/document-cn-translation-of-skywalking/
链路追踪框架对比
- Zipkin是Twitter开源的调用链分析工具,目前基于springcloud sleuth得到了广泛的使用,特点是轻量,使用部署简单。
2. Pinpoint是韩国人开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,UI功能强大,接入端无代码侵入。
3. Skywalking是本土开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,UI功能较强,接入端无代码侵入。目前已加入Apache孵化器。
4. CAT是大众点评开源的基于编码和配置的调用链分析,应用监控分析,日志采集,监控报警等一系列的监控平台工具。
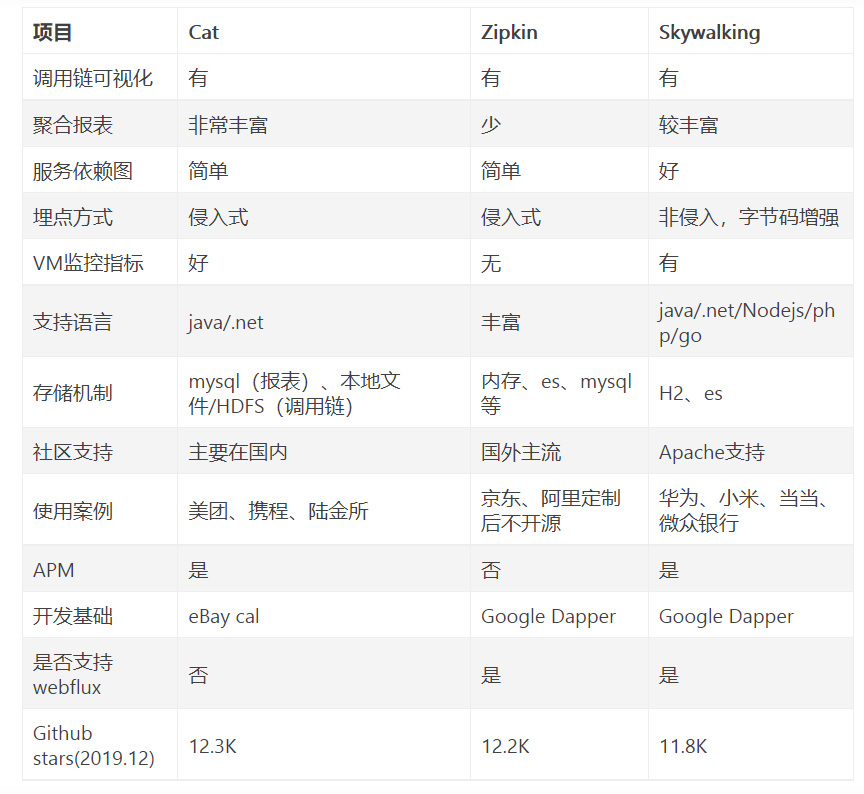
性能对比
模拟了三种并发用户:500,750,1000。使用 jmeter 测试,每个线程发送30个请求,设置思考时间为10ms。使用的采样率为1,即100%,这边与生产可能有差别。pinpoint默认的采样率为20,即50%,通过设置agent的配置文件改为100%。zipkin默认也是1。组合起来,一共有12种。下面看下汇总表:
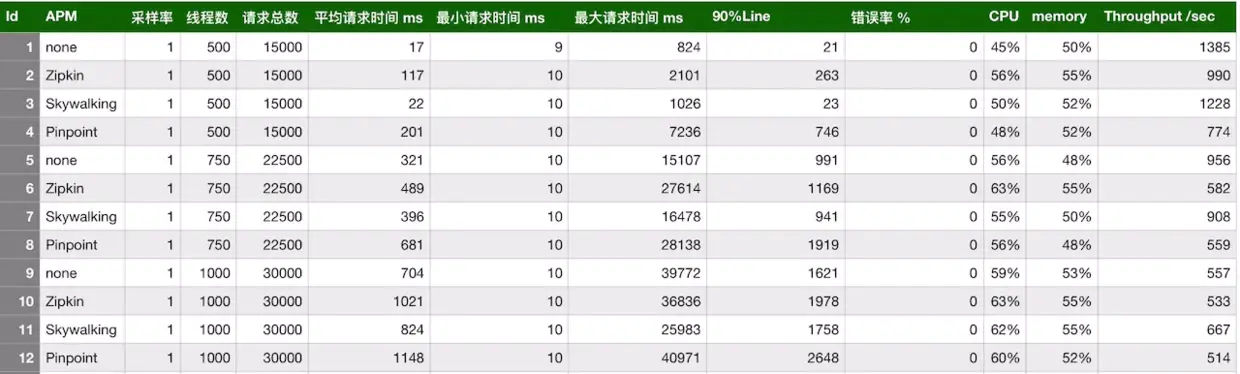
从上表可以看出,在三种链路监控组件中,skywalking的探针对吞吐量的影响最小,zipkin的吞吐量居中。pinpoint的探针对吞吐量的影响较为明显,在500并发用户时,测试服务的吞吐量从1385降低到774,影响很大。然后再看下CPU和memory的影响,在内部服务器进行的压测,对CPU和memory的影响都差不多在10%之内。
Skywalking 主要功能特性
1、多种监控手段,可以通过语言探针和service mesh获得监控的数据;
2、支持多种语言自动探针,包括 Java,.NET Core 和 Node.JS;
3、轻量高效,无需大数据平台和大量的服务器资源;
4、模块化,UI、存储、集群管理都有多种机制可选;
5、支持告警;
6、优秀的可视化解决方案;
架构
SkyWalking 逻辑上分为四部分: 探针, 平台后端, 存储和用户界面.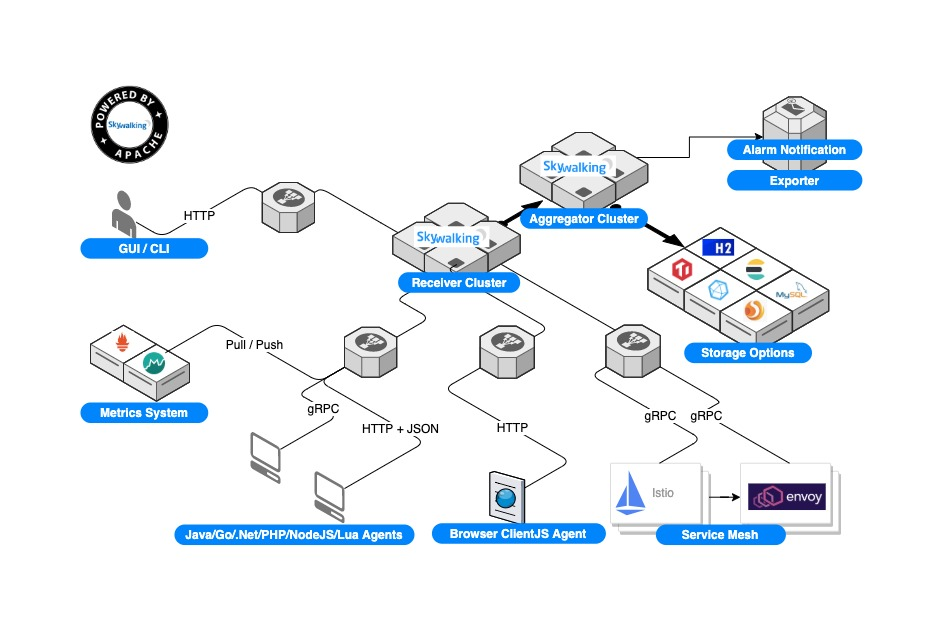
- 探针 基于不同的来源可能是不一样的, 但作用都是收集数据, 将数据格式化为 SkyWalking 适用的格式.
- 平台后端, 支持数据聚合, 数据分析以及驱动数据流从探针到用户界面的流程。分析包括 Skywalking 原生追踪和性能指标以及第三方来源,包括 Istio 及 Envoy telemetry , Zipkin 追踪格式化等。 你甚至可以使用 Observability Analysis Language 对原生度量指标 和 用于扩展度量的计量系统 自定义聚合分析。
- 存储 通过开放的插件化的接口存放 SkyWalking 数据. 你可以选择一个既有的存储系统, ElasticSearch, H2 或 MySQL 集群(Sharding-Sphere 管理),也可以选择自己实现一个存储系统. 当然, 我们非常欢迎你贡献新的存储系统实现。
- UI 一个基于接口高度定制化的Web系统,用户可以可视化查看和管理 SkyWalking 数据。
SkyWalking 环境搭建部署
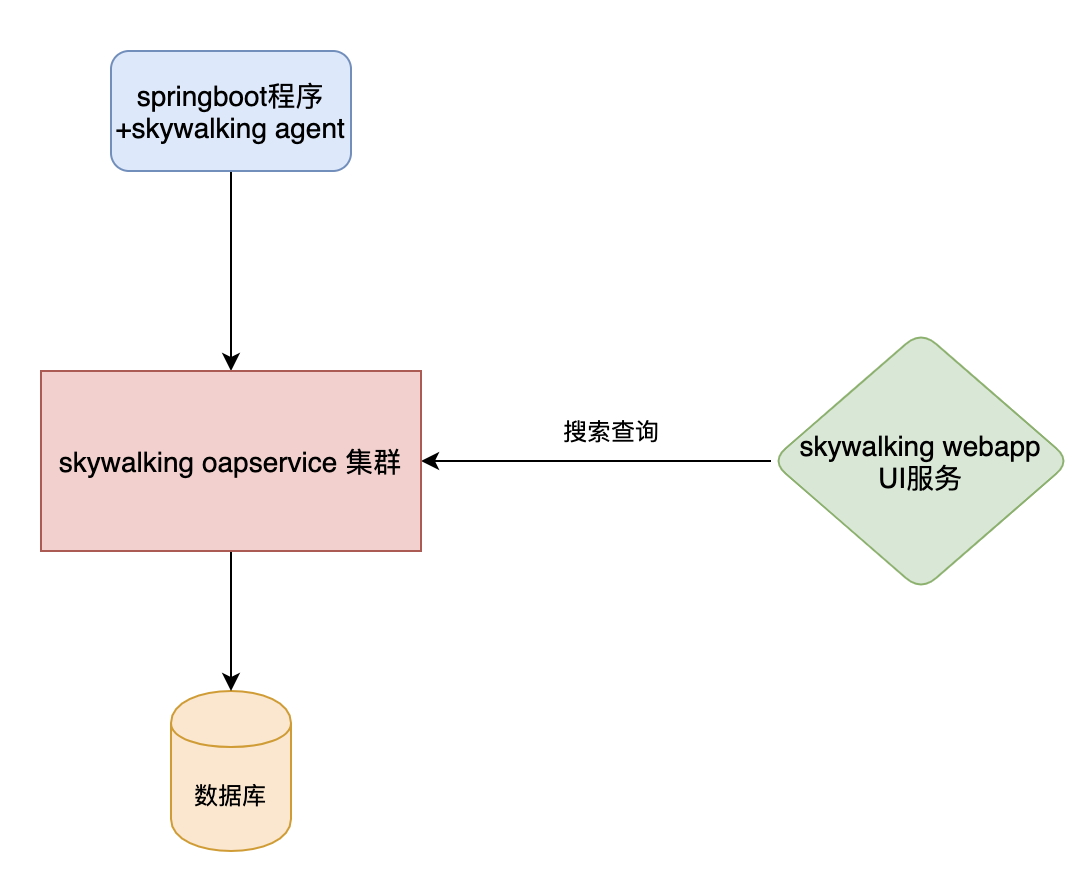
- skywalking agent 和业务系统绑定在一起,负责收集各种监控数据
Skywalking oapservice 是负责处理监控数据的,比如接受skywalking agent的监控数据,并存储在数据库中;
接受skywalking webapp的前端请求,从数据库查询数据,并返回数据给前端。Skywalking oapservice通常以 集群的形式存在。
skywalking webapp,前端界面,用于展示数据。
- 用于存储监控数据的数据库,比如mysql、elasticsearch等
下载 SkyWalking
下载 : http://skywalking.apache.org/downloads/
版本目录地址:https://archive.apache.org/dist/skywalking/
目录结构

搭建SkyWalking OAP 服务
启动脚本 bin/startup.sh
日志信息存储在logs目录
启动成功后会有两个应用程序
启动成功后会启动两个服务,一个是 skywalking-oap-server,一个是 skywalking-web-ui : 8868
skywalking-oap-server 服务启动后会暴露11800 和 12800 两个端口,分别为收集服务监控数据的端口11800和接受前端请求的端口12800 ,修改端口可以修改config/applicaiton.yml
skywalking-web-ui服务会占用 8080 端口, 修改端口可以修改webapp/webapp.yml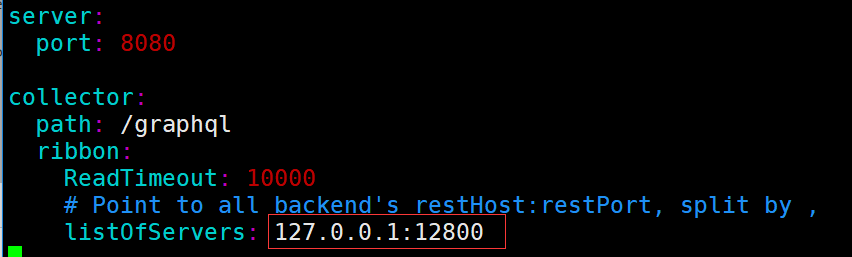
server.port:SkyWalking UI服务端口,默认是8080;
collector.ribbon.listOfServers:SkyWalking OAP服务地址数组,SkyWalking UI界面的数据是通过请求SkyWalking OAP服务来获得;
访问:http://127.0.0.1:8080/ 页面的右下角可以中英文切换,可以切换选择要展示的时间区间的跟踪数据。
页面的右下角可以中英文切换,可以切换选择要展示的时间区间的跟踪数据。
SkyWalking中三个概念
服务(Service) : 表示对请求提供相同行为的一系列或一组工作负载,在使用Agent时,可以定义服务的名字;
服务实例(Service Instance) : 上述的一组工作负载中的每一个工作负载称为一个实例, 一个服务实例实际就是操作系统上的一个真实进程;
端点(Endpoint) : 对于特定服务所接收的请求路径, 如HTTP的URI路径和gRPC服务的类名 + 方法签名;

SkyWalking 接入微服务
linux 环境—通过jar包方式接入
准备一个springboot程序,打成可执行jar包,写一个shell脚本,在启动项目的Shell脚本上,通过 -javaagent 参数进行配置SkyWalking Agent来跟踪微服务;
startup.sh 启动
#!/bin/sh# SkyWalking Agent配置export SW_AGENT_NAME=springboot‐skywalking‐demo #Agent名字,一般使用`spring.application.name`export SW_AGENT_COLLECTOR_BACKEND_SERVICES=127.0.0.1:11800 #配置 Collector 地址。export SW_AGENT_SPAN_LIMIT=2000 #配置链路的最大Span数量,默认为 300。export JAVA_AGENT=‐javaagent:/usr/local/soft/apache‐skywalking‐apm‐bin‐es7/agent/skywalking‐agent.jarjava $JAVA_AGENT ‐jar springboot‐skywalking‐demo‐0.0.1‐SNAPSHOT.jar #jar启动
jar 启动
java ‐javaagent:/usr/local/soft/apache‐skywalking‐apm‐bin‐es7/agent/skywalking‐agent.jar‐DSW_AGENT_COLLECTOR_BACKEND_SERVICES=127.0.0.1:11800‐DSW_AGENT_NAME=springboot‐skywalking‐demo ‐jar springboot‐skywalking‐demo‐0.0.1‐SNAPSHOT.jar
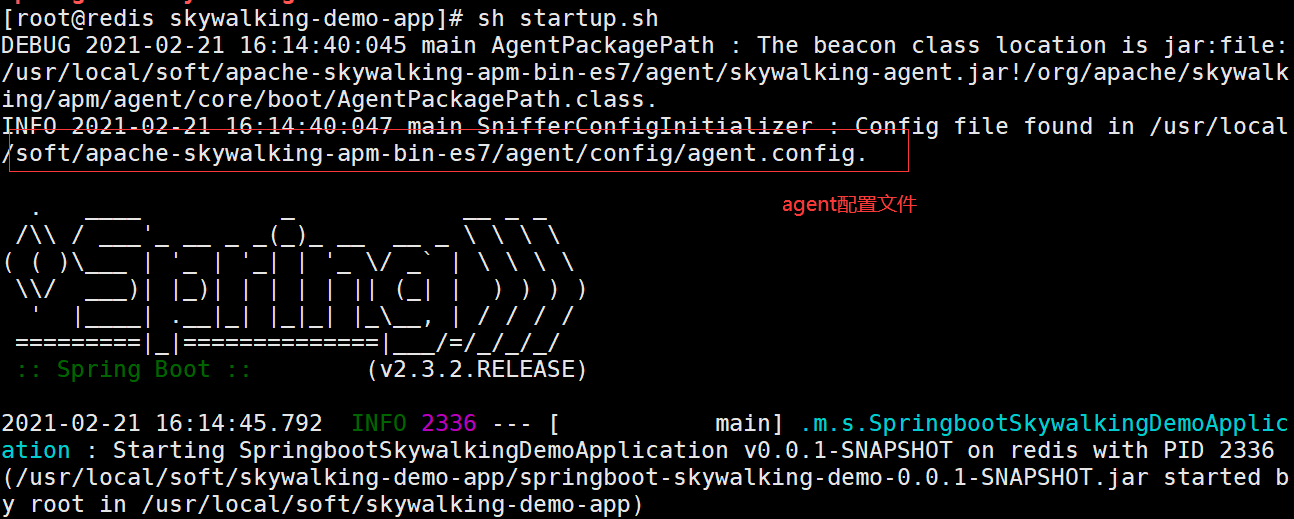
windos 环境—在IDEA中使用 Skywalking
在运行的程序配置jvm参数,如下图所示: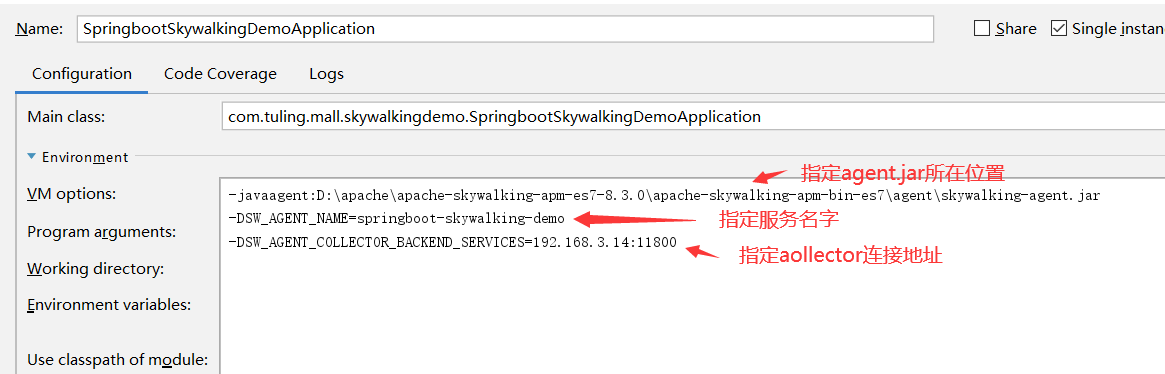
说明: -DSW_AGENT_COLLECTOR_BACKEND_SERVICES 可以指定远程地址,
但是-javaagent必须绑定你本机物理路径的skywalking-agent.jar
# skywalking‐agent.jar的本地磁盘的路径-javaagent:D:\apache\apache‐skywalking‐apm‐es7‐8.4.0\apache‐skywalking‐apm‐bin‐es7\agent\skywalking‐agent.jar# 在skywalking上显示的服务名-DSW_AGENT_NAME=springboot‐skywalking‐demo# skywalking的collector服务的IP及端口-DSW_AGENT_COLLECTOR_BACKEND_SERVICES=192.168.3.100:11800
效果图如下
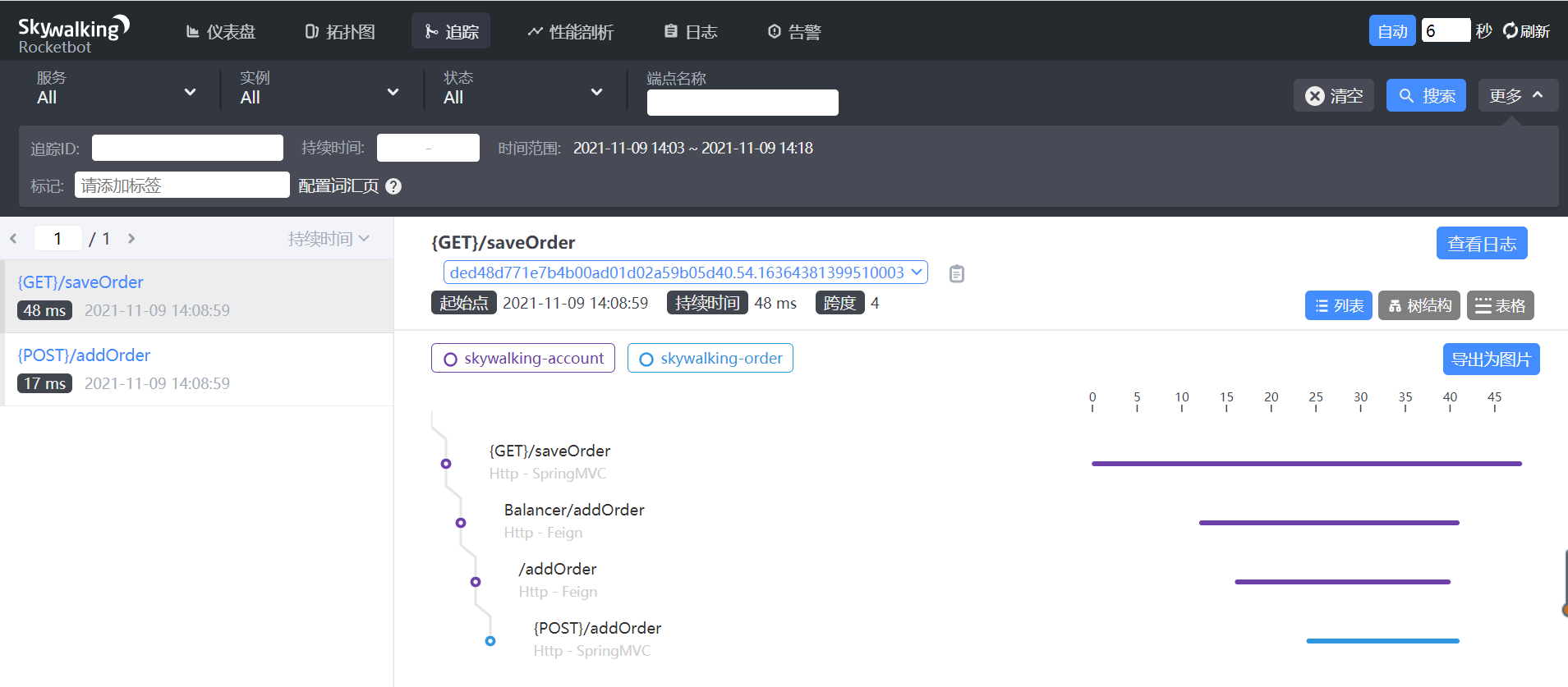
报错调试
http://127.0.0.1:8720/getUserOrder?userId=0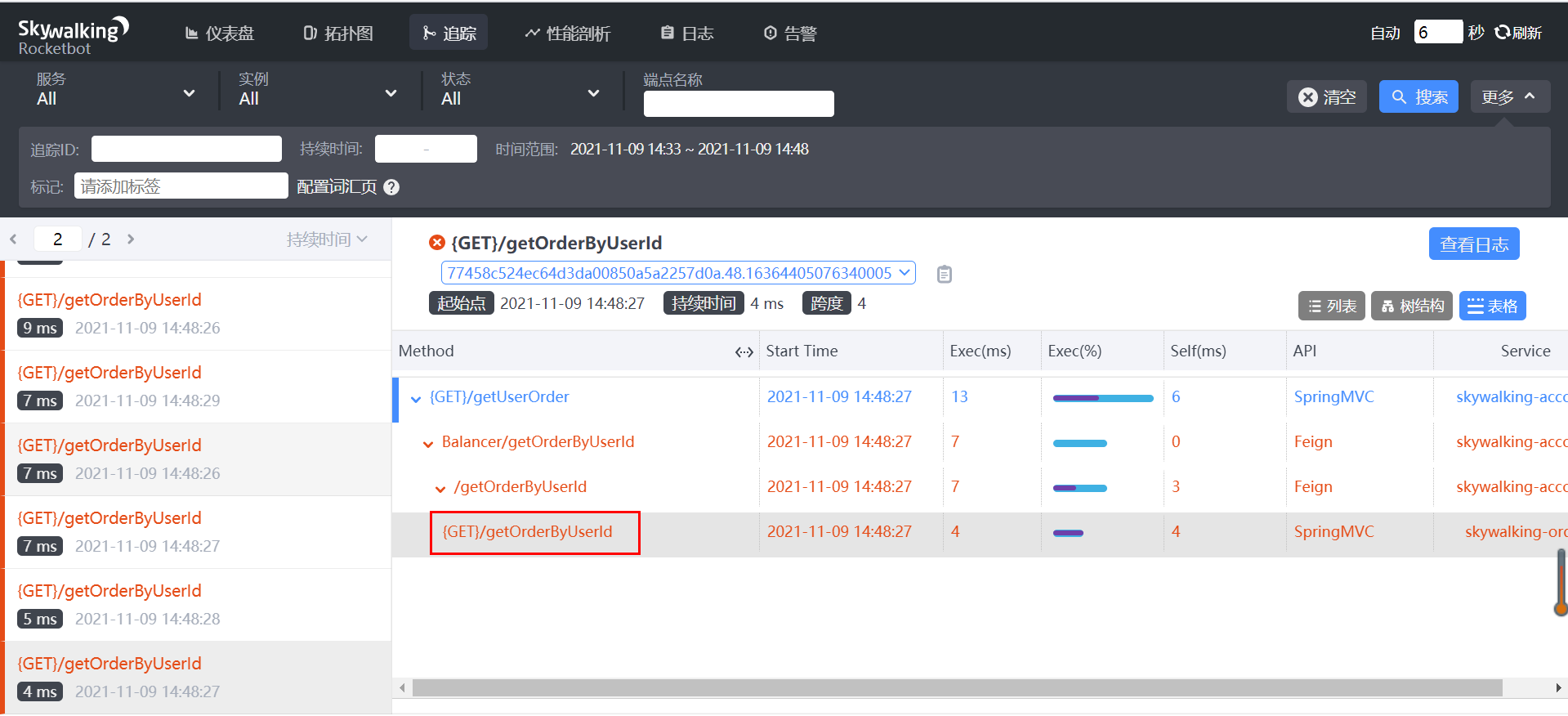 查看报错信息
查看报错信息
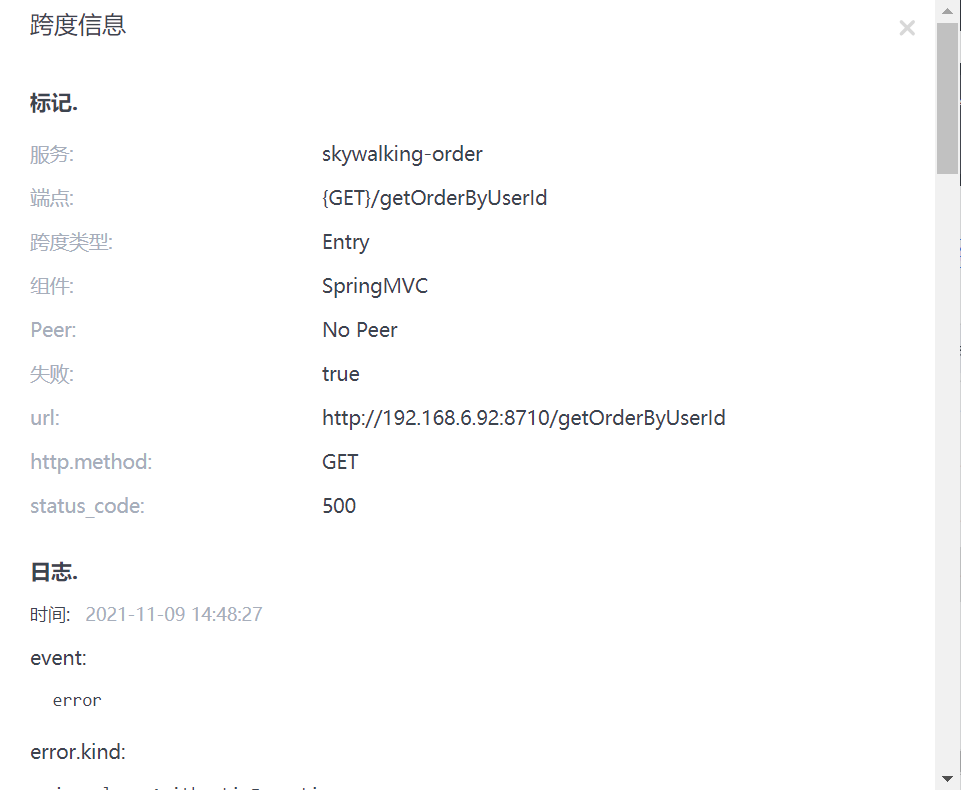
Skywalking持久化跟踪数据
默认使用的H2数据库存储(本地存储)
config/application.yml
解决 gateway 服务不能注册
把 agent/ optional-plugins 目录下的gateway插件拷贝到 agent/ plugins目录
Linux 环境
windows 环境
重新启动 skywalking
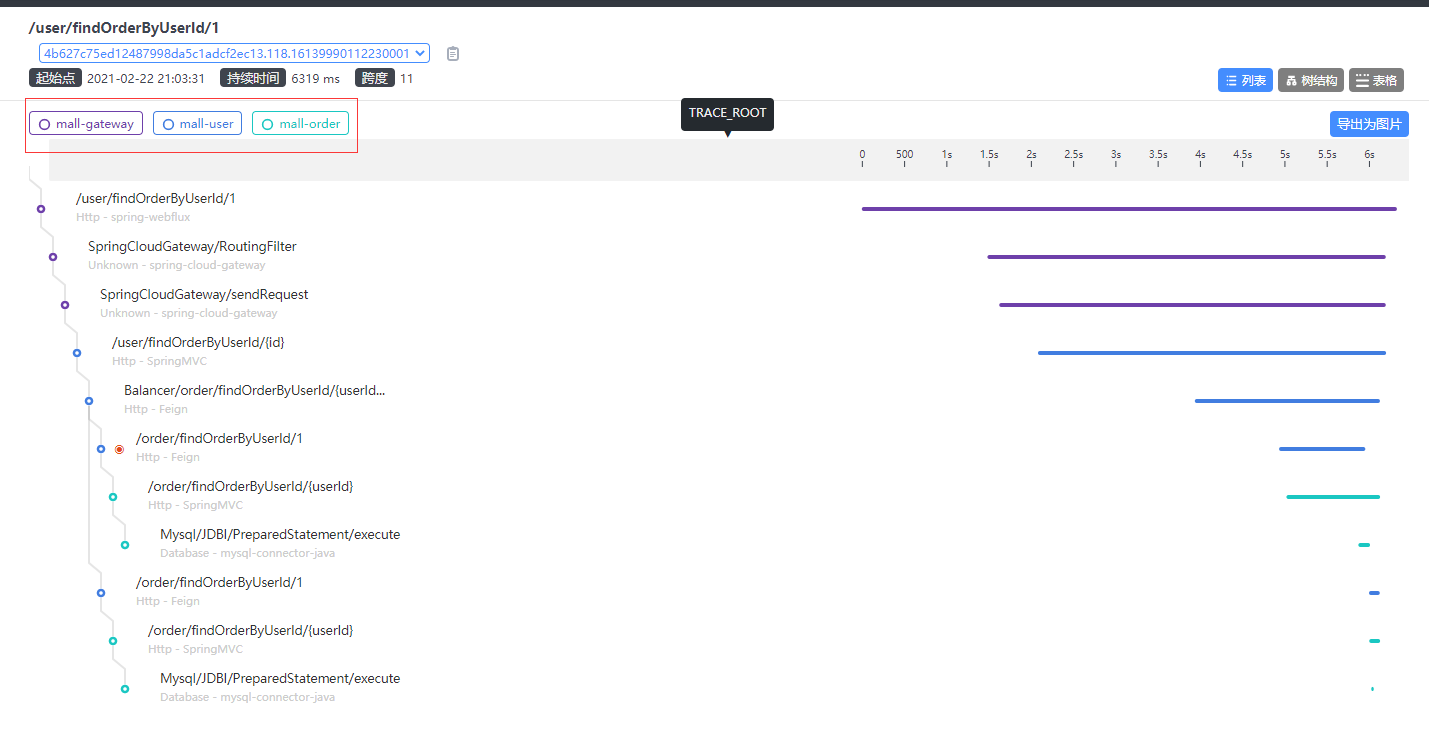
基于mysql持久化
- 修改 config目录下的application.yml, 使用mysql作为持久化存储的仓库

2.修改mysql连接配置
注意:需要添加mysql数据驱动包,因为在lib目录下是没有mysql数据驱动包的,所以修改完配置启动是会报错,启动失败的。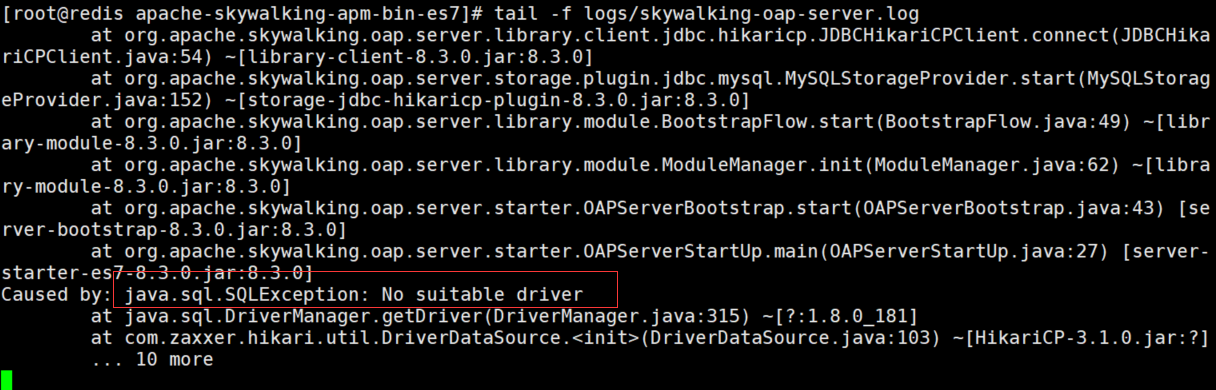
添加mysql数据驱动包到oap-libs目录下
启动Skywalking
查看swtest数据库,可以看到生成了很多表。
说明启动成功了,打开配置对应的地址http://192.168.3.100:8080/,可以看到skywalking的web界面。
测试:重启skywalking,验证跟踪数据会不会丢失
自定义SkyWalking链路追踪
如果我们希望对项目中的业务方法,实现链路追踪,方便我们排查问题,可以使用如下的代码
引入依赖
<dependency><groupId>org.apache.skywalking</groupId><artifactId>apm-toolkit-trace</artifactId><version>8.4.0</version><scope>provided</scope></dependency>
@Trace将方法加入追踪链路
如果一个业务方法想在ui界面的跟踪链路上显示出来,只需要在业务方法上加上@Trace注解即可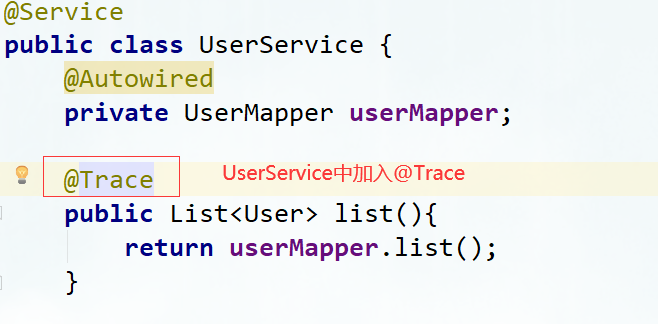
测试
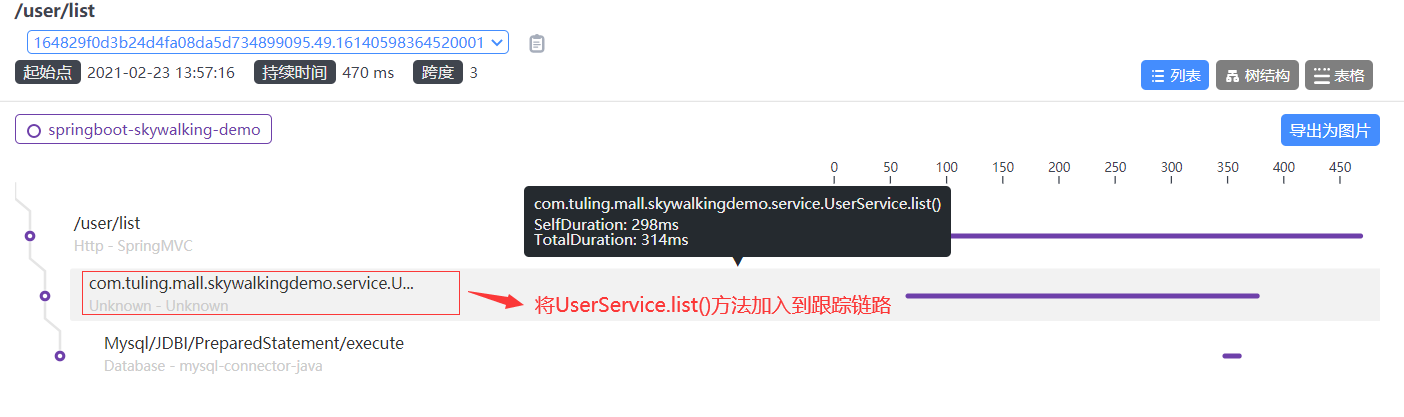
加入@Tags或@Tag
我们还可以为追踪链路增加其他额外的信息,
比如记录参数和返回信息。实现方式:在方法上增加 @Tag 或者@Tags。
@Tag 注解中 key = 方法名 ; value = returnedObj 返回值 arg[0] 参数
@Trace@Tag(key = "list", value = "returnedObj")public List<User> list(){return userMapper.list();}@Trace@Tags({@Tag(key = "param", value = "arg[0]"),@Tag(key = "user", value = "returnedObj")})public User getById(Integer id){return userMapper.getById(id);}
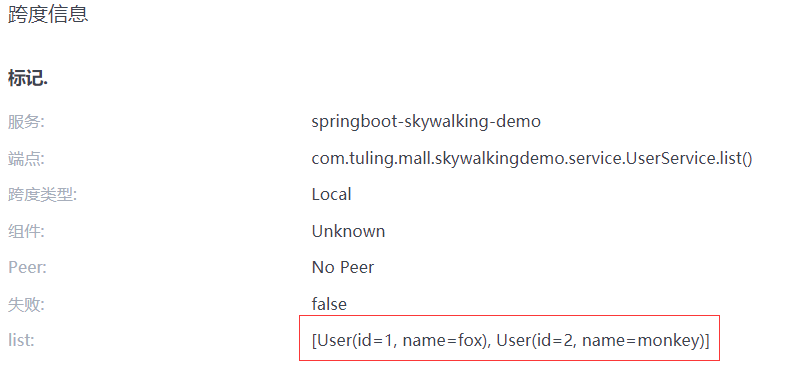
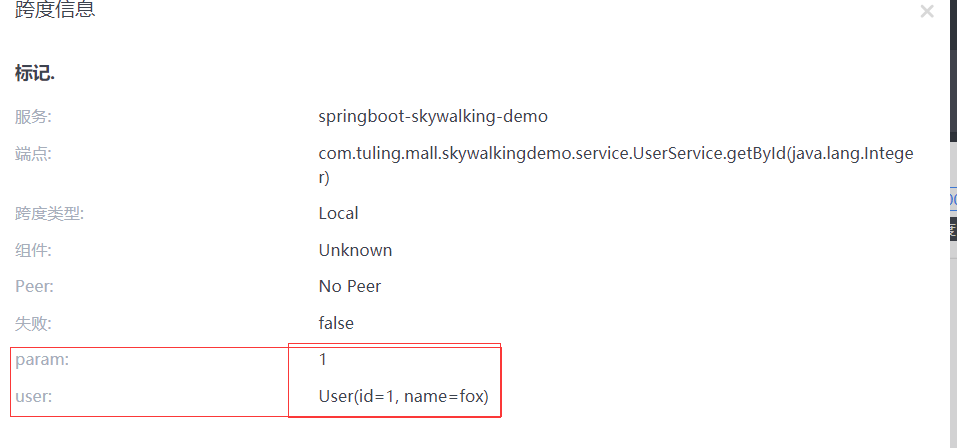
性能分析
skywalking 的性能分析,在根据服务名称、端点名称,以及相应的规则建立了任务列表后,在调用了此任务列表的端点后。skywalking 会自动记录,剖析当前端口,生成剖析结果,具体流程如图: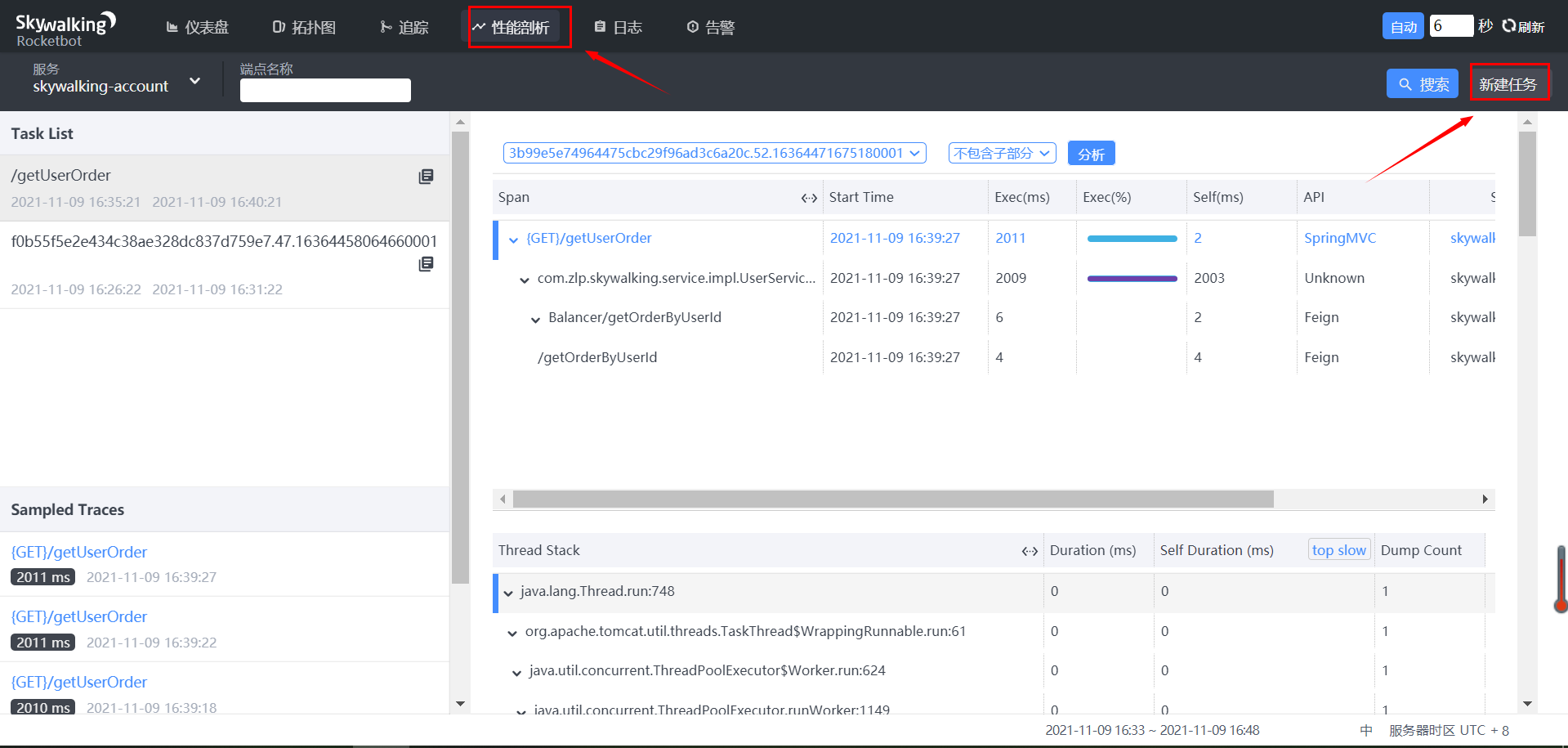
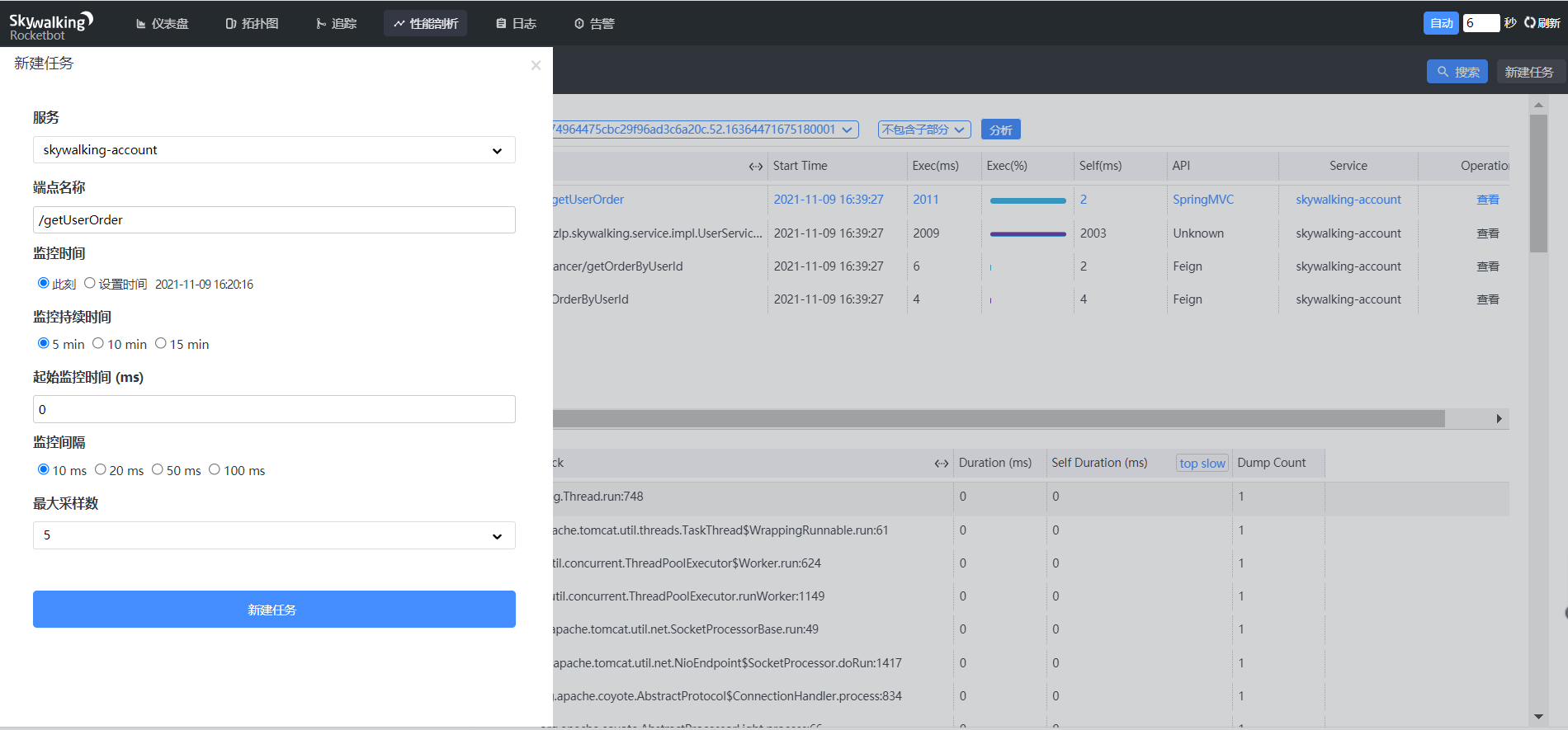

Skywalking 集成日志框架
引入依赖
<!-- apm‐toolkit‐logback‐1.x --><dependency><groupId>org.apache.skywalking</groupId><artifactId>apm-toolkit-logback-1.x</artifactId><version>8.4.0</version></dependency>
添加logback-spring.xml文件
并配置 %tid 占位符
<?xml version="1.0" encoding="UTF-8"?><configuration><!-- 引入 Spring Boot 默认的 logback XML 配置文件 --><include resource="org/springframework/boot/logging/logback/defaults.xml"/><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><!-- 日志的格式化 --><encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder"><layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout"><Pattern>${CONSOLE_LOG_PATTERN}</Pattern></layout></encoder></appender><!-- 设置 Appender --><root level="INFO"><appender-ref ref="console"/></root></configuration>
控制台日志输出
gRPC报告程序可以将收集到的日志转发到SkyWalking OAP服务器上
logback-spring.xml 中添加
<appender name="grpc-log" class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.log.GRPCLogClientAppender"><encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder"><layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.mdc.TraceIdMDCPatternLogbackLayout"><Pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%X{tid}] [%thread] %-5level %logger{36} -%msg%n</Pattern></layout></encoder></appender><!-- 设置 Appender --><root level="INFO"><appender-ref ref="console"/><appender-ref ref="grpc-log"/></root>
打开agent/config/agent.config配置文件, 添加如下配置信息:
plugin.toolkit.log.grpc.reporter.server_host=${SW_GRPC_LOG_SERVER_HOST:192.168.3.100}plugin.toolkit.log.grpc.reporter.server_port=${SW_GRPC_LOG_SERVER_PORT:11800}plugin.toolkit.log.grpc.reporter.max_message_size=${SW_GRPC_LOG_MAX_MESSAGE_SIZE:10485760}plugin.toolkit.log.grpc.reporter.upstream_timeout=${SW_GRPC_LOG_GRPC_UPSTREAM_TIMEOUT:30}
以上配置是默认配置信息,agent与oap在本地的可以不配
| 配置名 | 解释 | 默认值 |
|---|---|---|
| plugin.toolkit.log.transmit_formatted | 是否以格式化或未格式化的格式传输记录的数据 | true |
| plugin.toolkit.log.grpc.reporter.server_host | 指定要向其报告日志数据的grpc服务器的主机 | 127.0.0.1 |
| plugin.toolkit.log.grpc.reporter.server_port | 指定要向其报告日志数据的grpc服务器的端口 | 11800 |
| plugin.toolkit.log.grpc.reporter.max_message_size | 指定grpc客户端要报告的日志数据的最大大小 | 10485760 |
| plugin.toolkit.log.grpc.reporter.upstream_timeout | 客户端向上游发送数据时将超时多长时间。单位是秒 | 30 |
Skywalking UI效果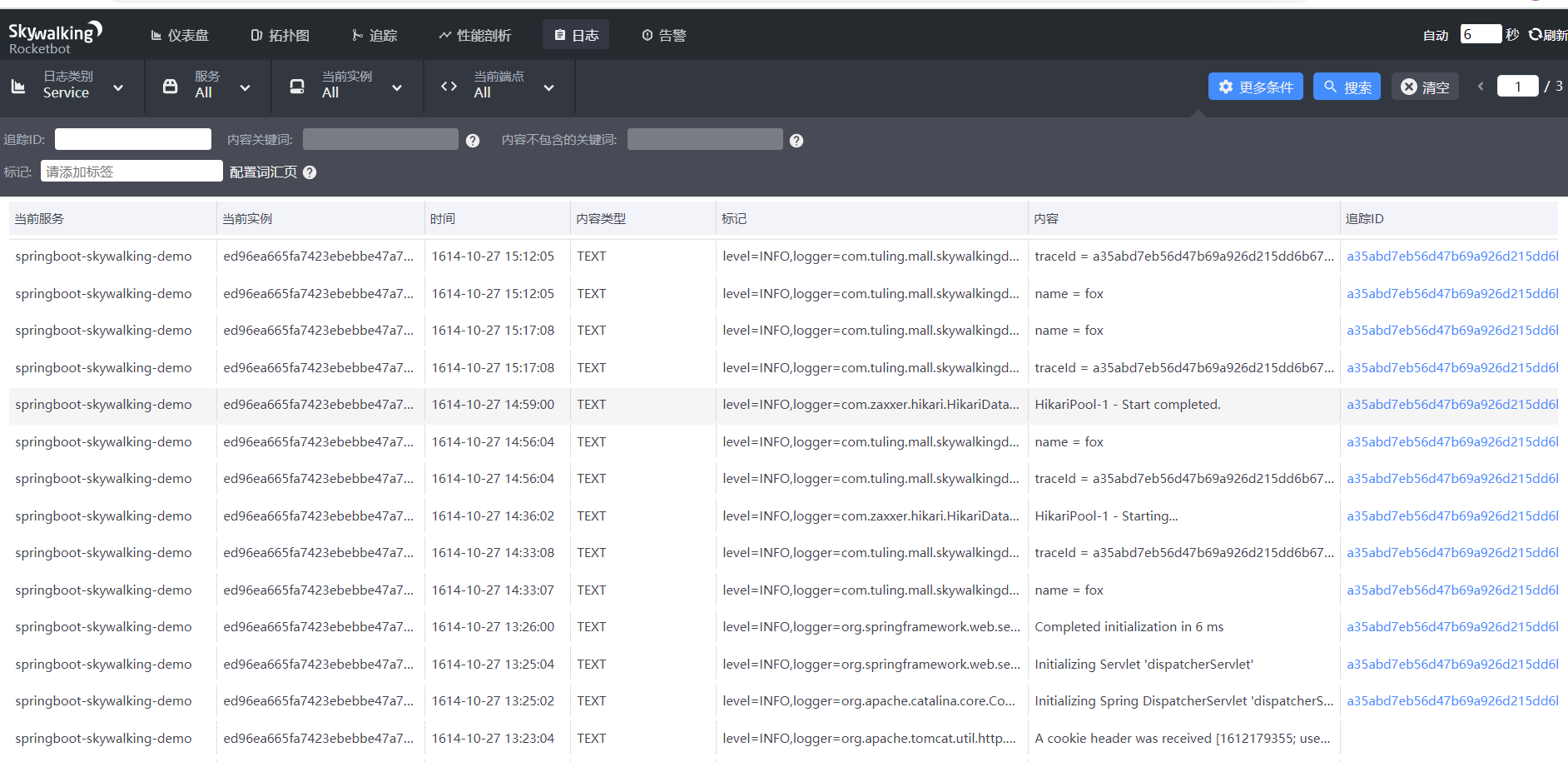
SkyWalking 告警功能
SkyWalking 告警功能是在6.x版本新增的,其核心由一组规则驱动,这些规则定义在config/alarm-settings.yml文件中。 告警规则的定
义分为两部分:
1. 告警规则:它们定义了应该如何触发度量警报,应该考虑什么条件。
2. Webhook(网络钩子):定义当警告触发时,哪些服务终端需要被告知
告警规则
SkyWalking 的发行版都会默认提供config/alarm-settings.yml文件,里面预先定义了一些常用的告警规则。如下:
1. 过去 3 分钟内服务平均响应时间超过 1 秒。
2. 过去 2 分钟服务成功率低于80%。
3. 过去 3 分钟内服务响应时间超过 1s 的百分比
4. 服务实例在过去 2 分钟内平均响应时间超过 1s,并且实例名称与正则表达式匹配。
5. 过去 2 分钟内端点平均响应时间超过 1 秒。
6. 过去 2 分钟内数据库访问平均响应时间超过 1 秒。
7. 过去 2 分钟内端点关系平均响应时间超过 1 秒。
这些预定义的告警规则,打开config/alarm-settings.yml文件即可看到
告警规则配置项的说明:
- Rule name:规则名称,也是在告警信息中显示的唯一名称。必须以_rule结尾,前缀可自定义
- Metrics name:度量名称,取值为oal脚本中的度量名,目前只支持long、double和int类型。详见Official OAL script
- Include names:该规则作用于哪些实体名称,比如服务名,终端名(可选,默认为全部)
- Exclude names:该规则作不用于哪些实体名称,比如服务名,终端名(可选,默认为空)
- Threshold:阈值
- OP: 操作符,目前支持 >、<、=
- Period:多久告警规则需要被核实一下。这是一个时间窗口,与后端部署环境时间相匹配
- Count:在一个Period窗口中,如果values超过Threshold值(按op),达到Count值,需要发送警报
- Silence period:在时间N中触发报警后,在TN -> TN + period这个阶段不告警。 默认情况下,它和Period一样,这意味着相同的告警(在同一个Metrics name拥有相同的Id)在同一个Period内只会触发一次
- message:告警消息
Webhook(网络钩子)
Webhook可以简单理解为是一种Web层面的回调机制,通常由一些事件触发,与代码中的事件回调类似,只不过是Web层面的。由于是Web层面的,所以当事件发生时,回调的不再是代码中的方法或函数,而是服务接口。例如,在告警这个场景,告警就是一个事件。当该事件发生时,SkyWalking就会主动去调用一个配置好的接口,该接口就是所谓的Webhook。
SkyWalking的告警消息会通过 HTTP 请求进行发送,请求方法为 POST,Content-Type 为 application/json,其JSON 数据实基于List
JSON数据示例:
[{"scopeId": 1,"scope": "SERVICE","name": "serviceA","id0": "12","id1": "","ruleName": "service_resp_time_rule","alarmMessage": "alarmMessage xxxx","startTime": 1560524171000}, {"scopeId": 1,"scope": "SERVICE","name": "serviceB","id0": "23","id1": "","ruleName": "service_resp_time_rule","alarmMessage": "alarmMessage yyy","startTime": 1560524171000}]
字段说明:
scopeId、scope:所有可用的 Scope 详见 org.apache.skywalking.oap.server.core.source.DefaultScopeDefine
name:目标 Scope 的实体名称
id0:Scope 实体的 ID
id1:保留字段,目前暂未使用
ruleName:告警规则名称
alarmMessage:告警消息内容
startTime:告警时间,格式为时间戳
邮件告警功能实践
根据以上两个小节的介绍,可以得知:SkyWalking是不支持直接向邮箱、短信等服务发送告警信息的,SkyWalking只会在发生告警时将告警信息发送至配置好的Webhook接口。
但我们总不能人工盯着该接口的日志信息来得知服务是否发生了告警,因此我们需要在该接口里实现发送邮件或短信等功能,从而达到个性化的告警通知。
接下来开始动手实践,这里基于Spring Boot进行实现。首先是添加依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring‐boot‐starter‐mail</artifactId></dependency>
配置邮箱服务:
server:## 启动端口port: 8720spring:application:## 注册服务名name: skywalking-accountcloud:nacos:## 注册中心地址discovery:server-addr: 127.0.0.1:8848main:allow-bean-definition-overriding: true## 邮箱配置 ##mail:from: 发送邮箱@163.comhost: smtp.163.compassword: 你的邮箱服务密钥username: 你的邮箱@163.com# port: 465 # 端口号465或587properties:mail:smtp:auth: truestarttls:enable: truerequired: true
定义 SkyWalking
根据Skywalking发送的JSON数据定义一个DTO,用于接口接收数据:
/*** Alarm message represents the details of each alarm.*/@Setter@Getterpublic class SwAlarmDTO {private int scopeId;private String scope;private String name;private String id0;private String id1;private String ruleName;private String alarmMessage;private List<Tag> tags;private long startTime;private transient int period;private transient boolean onlyAsCondition;}
接着定义一个接口,实现接收SkyWalking的告警通知,并将数据发送至邮箱:
/*** 接收skywalking服务的告警通知并发送至邮箱** 必须是post*/@PostMapping("/receive")public void receive(@RequestBody List<SwAlarmDTO> alarmList) {String content = getContent(alarmList);Mail mail = new Mail();mail.setTo("865391093@qq.com");mail.setTitle("服务接口时间超时");mail.setContent(content);mail.setMsgId(System.currentTimeMillis()+"");new Thread(()->{mailUtil.send(mail);log.info("告警邮件已发送..."+content);}).start();}private String getContent(List<SwAlarmDTO> alarmList) {StringBuilder sb = new StringBuilder();for (SwAlarmDTO dto : alarmList) {sb.append("scopeId: ").append(dto.getScopeId()).append("\nscope: ").append(dto.getScope()).append("\n目标 Scope 的实体名称: ").append(dto.getName()).append("\nScope 实体的 ID: ").append(dto.getId0()).append("\nid1: ").append(dto.getId1()).append("\n告警规则名称: ").append(dto.getRuleName()).append("\n告警消息内容: ").append(dto.getAlarmMessage()).append("\n告警时间: ").append(dto.getStartTime()).append("\n标签: ").append(dto.getTags()).append("\n\n---------------\n\n");}return sb.toString();}
配置 config/alarm-settings.yml文件
最后将该接口配置到SkyWalking中,Webhook的配置位于config/alarm-settings.yml文件的末尾,
格式为http://{ip}:{port}/{uri}。如下示例: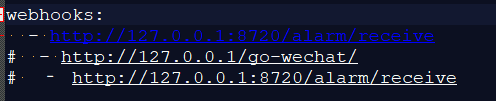
测试告警功能
完成告警接口的开发及配置后,我们来进行一个简单的测试。这里有一条调用链路如下:
我在/producer接口中增加了一行睡2秒的代码:
@Override@Trace@Tag(key="getAll",value="returnedObj")public List<Order> all() throws InterruptedException {TimeUnit.SECONDS.sleep(2);return orderMapper.selectAll();}
http://localhost:8072/order/all
执行完测试代码,等待约两分钟后,告警接口的控制台输出了一段日志信息: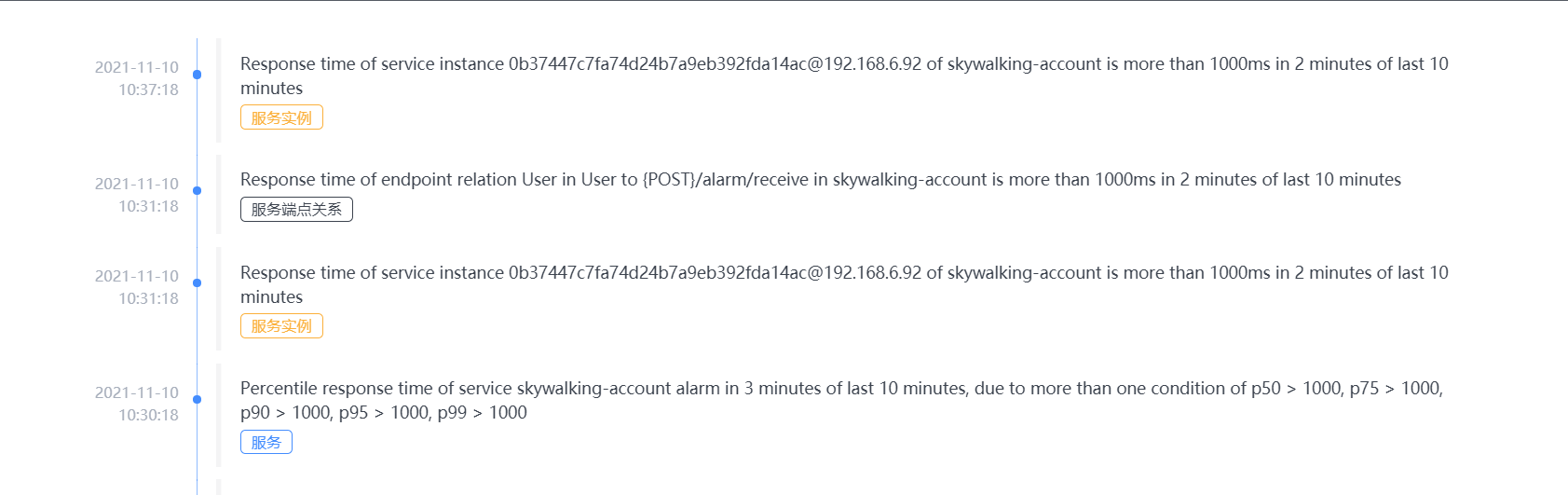
Skywalking高可用
概述
在大多数生产环境中,后端应用需要支持高吞吐量并且支持高可用来保证服务的稳定,所以你始终需要在生产环境进行集群管理。
集群方式
Skywalking集群是将skywalking oap作为一个服务注册到nacos上,只要skywalking oap服务没有全部宕机,保证有一个skywalking oap在运行,就能进行跟踪。
搭建一个skywalking oap集群需要:
(1)至少一个Nacos(也可以是nacos集群)
(2)至少一个ElasticSearch/mysql(也可以是es/msql集群)
(3)至少2个skywalking oap服务;
(4)至少1个UI(UI也可以集群多个,用Nginx代理统一入口)
修改配置文件
修改config/application.yml文件
使用nacos作为注册中心
修改nacos配置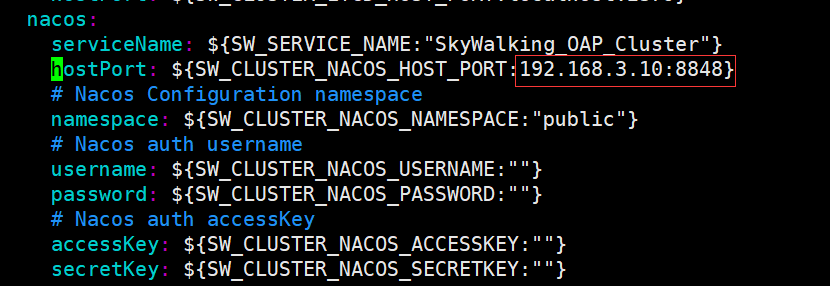
配置ui服务 webapp.yml 文件的listOfServers,写两个地址
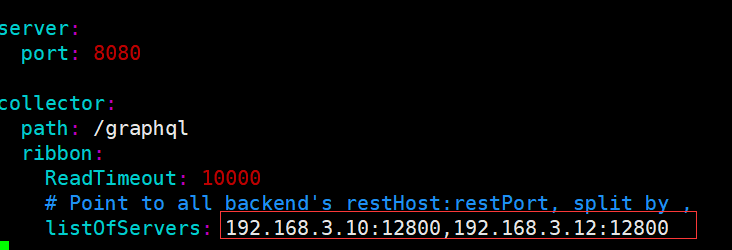
启动服务测试
启动 Skywalking 服务,指定springboot应用的 jvm 参数
‐DSW_AGENT_COLLECTOR_BACKEND_SERVICES=192.168.3.10:11800,192.168.3.12:11800
可以选择性修改监听端口
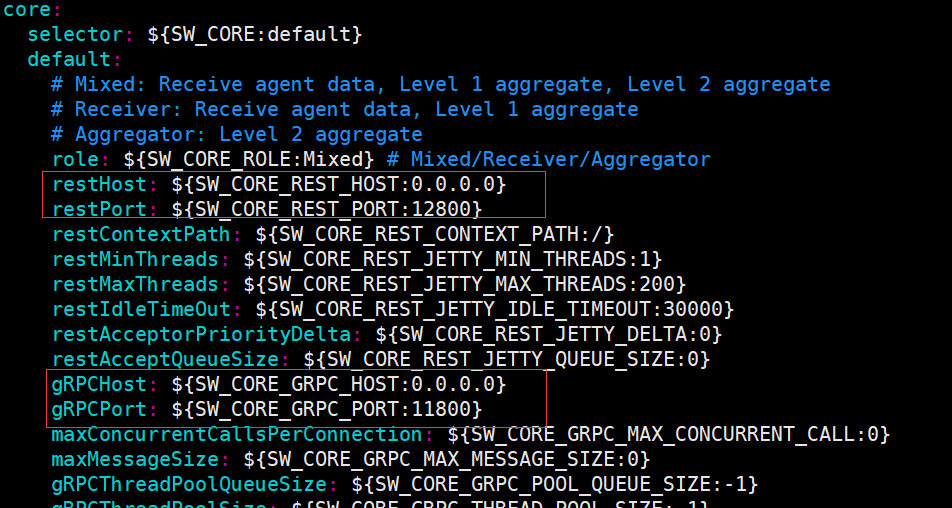
修改存储策略
使用elasticsearch7作为storage

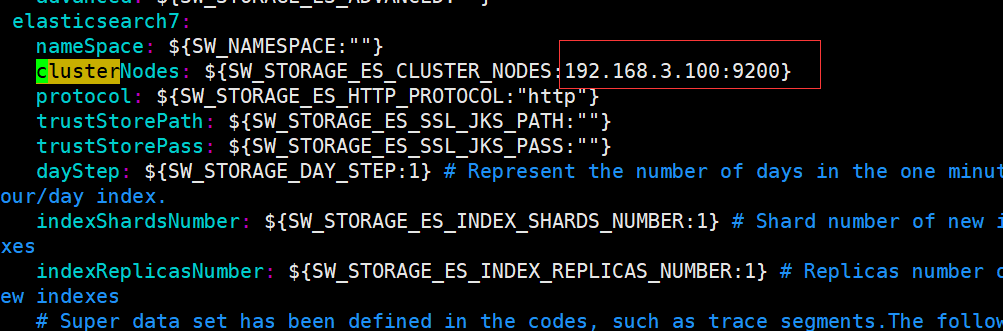

若有收获,就点个赞吧
0 人点赞
