Elasticsearch 今生前世
需求的诞生
刘备一大早就来到了公司,一看张飞和关羽已经在公司了,就问道:“两位贤弟,今天来的还蛮早啊。”
张飞一听就炸毛了,“大哥,你让我和二哥去做什么搜索功能,我们已经一晚没睡了,昨天就没回去好嘛。”
关羽也来气,“大哥,是啊,我们刚刚才上线电商网站,你这边又要加什么需求,现在用数据库检索不是好好的么,能不能让我们歇口气。”
“两位兄弟辛苦了,我也不想啊,最近咱们一单生意都没有啊。昨天我和一位朋友聊,他说我们的网站很不好用,找不到他想要的鞋,结果只好去别的地方买了。
不过他给我推荐了一位黑客高手,叫诸葛亮的家伙,说是啥都得懂,我们今天找他取经去。”
三顾茅庐
三人一行来找诸葛亮,不过前面两次都碰了壁。
据诸葛亮书童说,诸葛亮不在家,到了第三次,还是不在家。张飞仔细一听,明明是有人在家啊,而且玩游戏喊的声音还这么大,张飞怒了,搭梯子把诸葛亮家的保险给拔了。诸葛亮正郁闷呢,咋停电了呢?算了,今天没得玩了,于是让书童请他们进来。
“在下诸葛名亮,字孔明,不知三位…”,三人一说,是这么这么回事。诸葛亮一听,“哦,原来是这么这么回事啊,你们的网站我刚看了,你们家的草鞋品种确实不 Nan 少 Kan。
如今客户上网站找东西,都是先用网站的搜索来搜一下,但是你们网站的搜索功能实在是太 La 弱 Ji,明摆在那里的商品我都搜不出来,实在是大问题啊。”
“这样啊,我看你们仨都是好人,给你们推荐一个好东西,叫做 Elasticsearch,这个肯定可以帮助你们。”
“翼德,把先生放下来吧。”
“是,大哥。二哥,你把刀也放下吧。”
关羽一听,好像在哪里听说过 Elasticsearch,“大哥,这个东西好像有点耳熟啊,哦,诸葛亮先生这一说,我倒是记起来了,隔壁公司的吕布最近神神秘秘的,好像就是在用这个,难怪他们最近公司业务好的很”。
Elasticsearch 的故事
诸葛亮清了清嗓子,又从抽屉里摸出一把扇子,“还是让我来给你们讲讲吧”。
“Elasticsearch 以前叫 Elastic Search。顾名思义,就是“弹性的搜索”。很明显,它一开始是围绕着搜索功能,打造了一个分布式搜索引擎,底层是基于开源的搜索引擎库 Lucene,是由 Java 语言编写的,项目大概是 2010 年 2 月份在 Github 正式落户的。
咳咳,有必要首先给你介绍一下 Lucene。
Lucene 是一个非常古老的搜索引擎工具包,也是用 Java 编写,主要用来构建倒排索引(一种数据结构)和对这些索引进行检索,从而实现全文检索功能。
Lucene 很强大,使用起来也非常灵活,缺点是它仅仅是一个基础类库,也没有考虑到高并发和分布式的场景。
如果你想在自己的程序里面使用 Lucene,还是需要做很多工作,并且涉及很多搜索原理和索引数据结构的知识,这就给我们带来了不少挑战。所以,Lucene 的上手时间一般都比较长。”
关羽插了一句,“Lucene 我知道,确实贼难用,使用起来一堆问题啊,我之前试过来着。” 关羽说完,脸又红了。
诸葛亮接着说。“时间一晃来到 2004 年,有一个以色列小伙子,名字叫谢伊·班农( Shay Banon),他成亲不久来到伦敦,因为当时他的夫人正好在伦敦学厨师。
初来乍到,也没有找到工作,于是班农就打算写一个叫作 iCook 的小程序来管理和搜索菜谱,一来练练手,方便找工作;二来这个小工具还可以给其夫人用。
班农在编写 iCook 的过程中,使用了 Lucene,感受到了直接使用 Lucene 开发程序的各种暴击和痛苦,于是他在 Lucene 之上,封装了一个叫作 Compass 的程序框架,与 Hibernate 和 JPA 等 ORM 框架进行集成,通过操作对象的方式来自动地调用 Lucene 以构建索引。
这样做的好处是,可以很方便地实现对‘领域对象’进行索引的创建,并实现‘字段级别’的检索,以及实现‘全文搜索’功能。可以说,Compass 大大简化了给 Java 程序添加搜索功能的开发。Compass 开源出来,变得很流行。
在 Compass 编写到 2.x 版本的时候,社区里面出现了更多需求,比如需要有处理更多数据的能力以及分布式的设计。班农发现只有重写 Compass ,才能更好地实现这些分布式搜索的需求,于是 Compass 3.0 就没有了,取而代之的是一个全新的项目,也就是 Elasticsearch。”
让人怦然心动的 Elasticsearch
看到刘备三人听的入迷,诸葛亮轻挥羽扇,继续说了下去。
“得益于 Compass 项目的积累,Elasticsearch 问世之初就考虑到了功能的易用性。
Elasticsearch 作为一个独立的搜索服务器,提供了非常方便的搜索功能。用户完全不用关心底层 Lucene 的细节,只需要通过标准的 Http+RESTful 风格的 API,就可以进行索引数据的增删改查。数据的输入输出采用 JSON 格式,以文档和面向对象的方式,这样就能非常方便地理解和表达领域数据。”
张飞一拍桌子,“Elasticsearch 简直就是一个 Compass 的 RESTful 实现啊!”
“没错。同时,Elasticsearch 基于分片和副本的方式实现了一个分布式的 Lucene Directory,再结合Map-reduce 的理念,实现了一个简单的搜索请求分发合并的策略,能轻松化解海量索引和分布式高可用的问题。
可以说,仅仅依靠这两点,Elasticsearch就已经秒杀了当时市面上所有的搜索引擎服务或是程序库,我当时看到 Elasticsearch 也眼前一亮。
如今,Elasticsearch 基本上已经是搜索引擎市场排名第一的产品了,从 DB-Engines 网站的排名可以看到,Elasitcsearch 基本上是一骑绝红尘,拉开第二名远远一大截。” 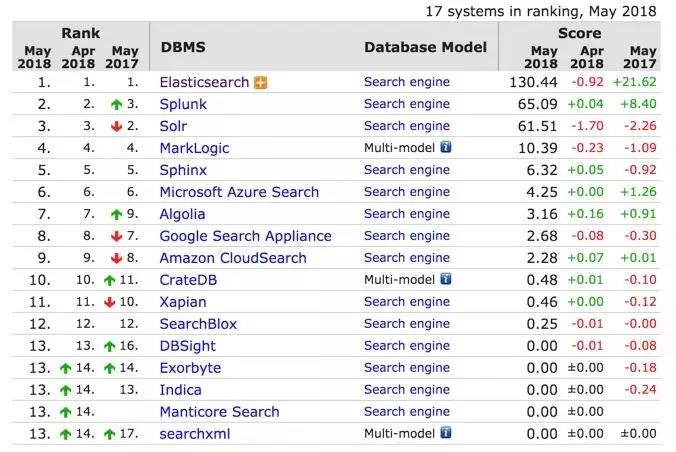
ELK 横空出世
诸葛亮口水狂飙,显得很兴奋,“如果只是 Elasticsearch 单独使用,那我们的故事也就结束了,事实上好戏这才刚刚开始。俗话说,一个好汉三个帮,开源社区亦是如此。”
“这一个好汉三个帮,说的不就是咱仨嘛。” 刘备接过话茬。
“别打岔,”诸葛亮继续说,“这里我要说的是 ‘ELK’ 的出现,不过首先我要给你们讲讲 Logstash。”
Logstash 是一个开源的日志收集工具,用 JRuby 写的,主要特点是基于灵活的 Pipeline 管道架构来处理数据。
什么意思呢?可以理解为将数据放进一个管道内进行处理,并且就跟真正的自来水管一样,管道由一截一截管子组成,每一个小管代表着一个数据处理的流程,每一个流程只做一件事情,然后可以根据数据的处理需要,选择多个不同类型的管子灵活组装。
Logstash 社区非常活跃,支持多种输入数据源和多种输出数据源。一开始, Elasticsearch 只是作为其中一个输出的存储,主要用于日志数据的存储。
不过,随着大家把日志发送到 Elasticsearch 之后,大家发现这家伙用起来很方便嘛,不仅能够存储大量的数据,水平伸缩还很方便。更关键的是,你能够很方便地把数据找出来,也就是进行全文搜索。
全文搜索在日志分析里面是非常基础的一个功能,通过一个关键字就能定位具体的详细日志,相比存放到关系型数据库和普通的文件存储,Elasticsearch 优势非常明显。于是 Logstash 搭配 Elasticsearch 变得很受欢迎。
Kibana 的故事
不过 Logstash 自带的 UI 查询日志的界面有点简陋,于是有一个叫作 Rashid Khan 的运维工程师表示完全忍不了了,用 PHP 写了一个叫作 Kibana 的程序,一个更好看和更好用的前端界面。PHP 写完一版,他又用 Ruby 写一版,后面又用 AngularJS 写了一版,不仅有日志的搜索和查看,还加上了一些统计展示功能。
Kibana 的名字其实是俩个水果的名字的组合(Kiwi+Banana)。
张飞听到这里:“工作不饱和啊这家伙”。孔明瞪了他一眼,继续说道。
这个时候,Elasticsearch 已经有 Facet 概念,也就是分面统计( 注:1.0 之后推出了 Aggregation 来代替 Facet),可以对数据里面的某个字段进行单个维度的统计,支持多种统计类型。
比如, TermFacet 可以计算字段里面某些值出现了多少次;Histogram Facet 还可以按时间区间进行汇总统计等。
这些统计功能在前端 UI 就可以被利用起来,展示一些饼图、时间曲线等等,在运维的分析里面自然也都是需要的。慢慢的 Kibana 越做越复杂,支持的功能越来越多,Kibana 3 变得流行起来。
于是乎,ELK 横空出世(Elasticsearch、Logstash 和 Kibana 这三个产品的首字母缩写),风靡了整个运维界。
故事讲到这里,相信你们对于 Elasticsearch 就有了一个大概的认识,可以用它做搜索,也可以用它做日志。”
张飞点点头,“还是相当的强悍嘛。”
Elastic Stack 平台的魅力
“不过,这还没完。”诸葛亮吞了吞口水,继续说。
“Elastic 后面又引入了 Beats 家族。这是一系列非常轻量级的数据收集端,我给你介绍几个比较典型的,比如:
- Packetbeat 可以实时监听网卡流量,并实时解析网络协议数据,可用来做 NPM 网络数据分析;
- Metricbeat 可以用来收集服务器,以及服务器上部署的应用服务的各项监控指标数据,这样就可以替代 Zabbix 等传统的监控软件,来做服务器的性能指标分析;
- Auditbeat可以实时收集服务器的行为事件,用于安全方面的入侵检测和安全日志审计分析;
- Winlogbeat用于 Windows 平台的事件日志收集;
- Filebeat 用于日志文件的收集等。
Elasticsearch、Logstash、Kibana、Beats ,这几个放在一起,就叫作 Elastic Stack。
如今,Elastic 的版图越来越大,前年,Elastic 收购 Opbeat,开源了业界第一个完整的 APM 解决方案,通过探针可以实现无侵入的代码级别的应用性能监控;
去年7月又收购了代码搜索 http://Insight.IO,后续可以实现代码级别的语义检索。今年又收购了一个做终端安全的厂商 Endgame。这样 Elastic Stack 这一个平台就可以同时做到:
- 日志分析
- 性能指标分析
- 安全日志分析
- APM 应用性能分析
- NPM 网络性能分析
- 网站站内搜索
- 企业级搜索
- 代码搜索
- 实时 BI 业务分析
- SIEM 解决方案
- 终端设备安全
- ……
试想一下:
在一个风和日丽的下午,你手机上收到一条告警短信,于是点击链接,打开 Kibana 的监控仪表盘,发现某台服务器的 CPU 达到 100% 了。
于是,你顺手点击过滤这台服务器的所有相关信息,可以看到相关的日志显示,是这台服务器上面部署的某一个业务服务的 QPS 有显著下降,然后过滤到这个业务的日志,发现有很多异常的日志信息,前端 Nginx 代理日志还显示有很多请求被拒绝,看样子是后端的微服务处理能力达到瓶颈。
这个时候,继续点击 APM 的分析面板,切换到事务和会话分析界面,看到有很多数据库链接处于开启状态。
你点击查看调用代码,立马就找到了性能瓶颈的原因,原来是某个类的某个方法调用 MySQL 却没有及时释放链接造成了泄露,于是修改这行代码,提交上线,问题解决。然后,你可以若无其事地继续浏览相亲网站啦。
尽管这是一个假想的例子,但是可以看到,基于 Elastic Stack ,你可以覆盖一整套完整的,从全局性能监控到具体代码级别的排障和解决问题的过程,并且使用起来要比很多现有的方案更加高效和便捷。
好了,现在你们是否对 Elasticsearch 已经有了一个初步的了解呢?是不是也有跃跃欲试的打算?”
刘备点点头:“今天来先生这里真的是收获不少,之前多有冒犯,还请多多包涵啊。”
关羽也说:“大哥,明天我就和三弟开始研究 Elasticsearch,争取早日改造好咱们的网站。”
“刚说的相亲网站要不也发我一下”,张飞连忙问道。刘备没好气白了一眼张飞。
“天色已晚,告辞了!”
刘备三人作别孔明,各自高兴的回家了。
“慢走不送,有空来喝茶啊。”
孔明抹了一把额头,总算送走这仨了,恐怕从此江湖上估计要不平静喽。
Elasticsearch 概述
https://blog.csdn.net/py_123456/article/details/81707633
概述
ElasticSearch是一个基于Lucene 的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
ElasticSearch 与 Solr 区别
Solr 定义:
Solr是Apache 下的一个开源项目,使用Java基于Lucene开发的全文检索服务是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
ElasticSearch vs Solr 优缺点
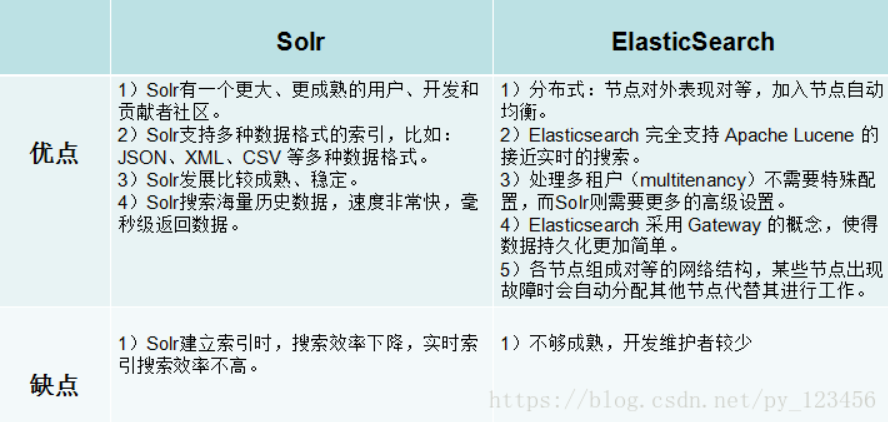
ElasticSearch 与 Solr 检索速度区别
1.当单纯的对已有数据进行搜索时,Solr更快。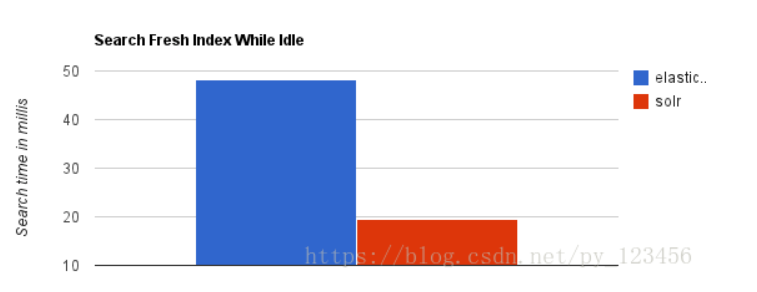
2.当实时建立索引时, Solr会产生io阻塞,查询性能较差, Elasticsearch具有明显的优势。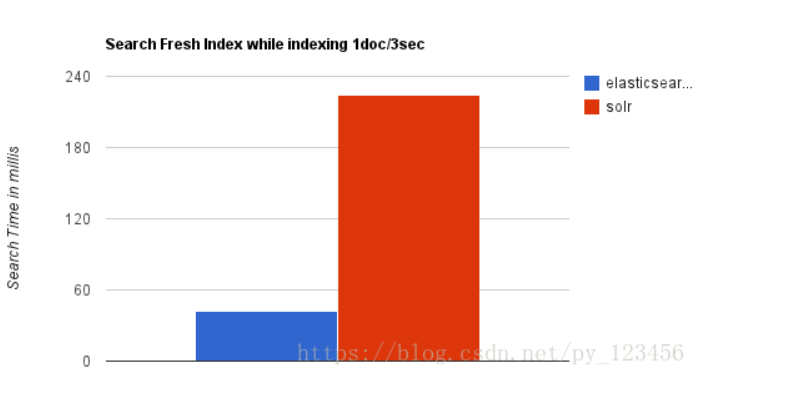
3.随着数据量的增加,Solr的搜索效率会变得更低,而Elasticsearch却没有明显的变化。
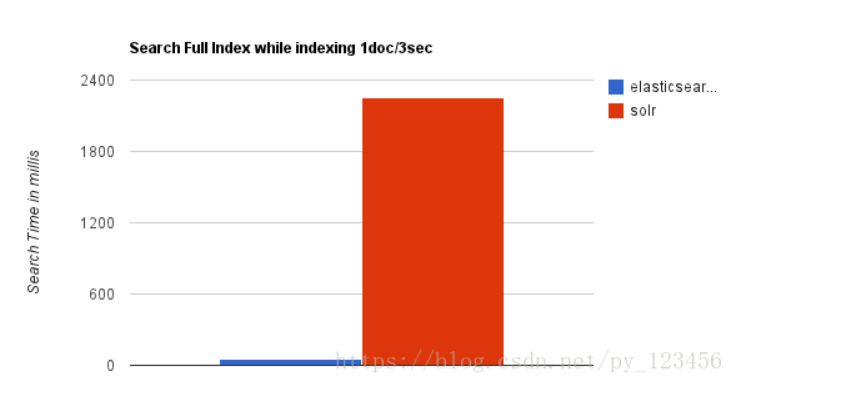
4.大型互联网公司,实际生产环境测试,将搜索引擎从Solr转到Elasticsearch以后的平均查询速度有了50倍的提升。
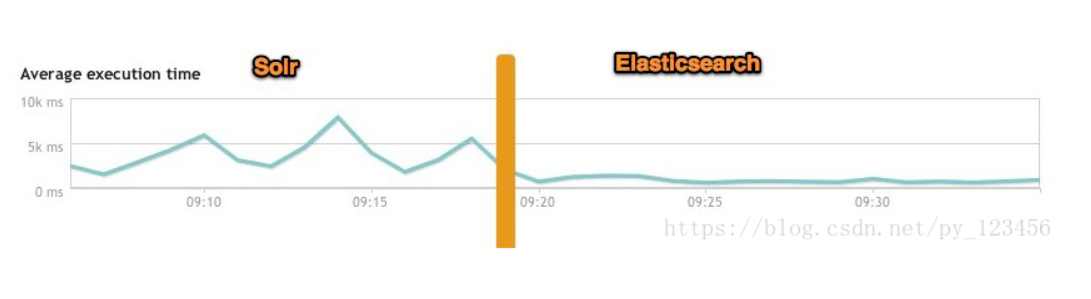
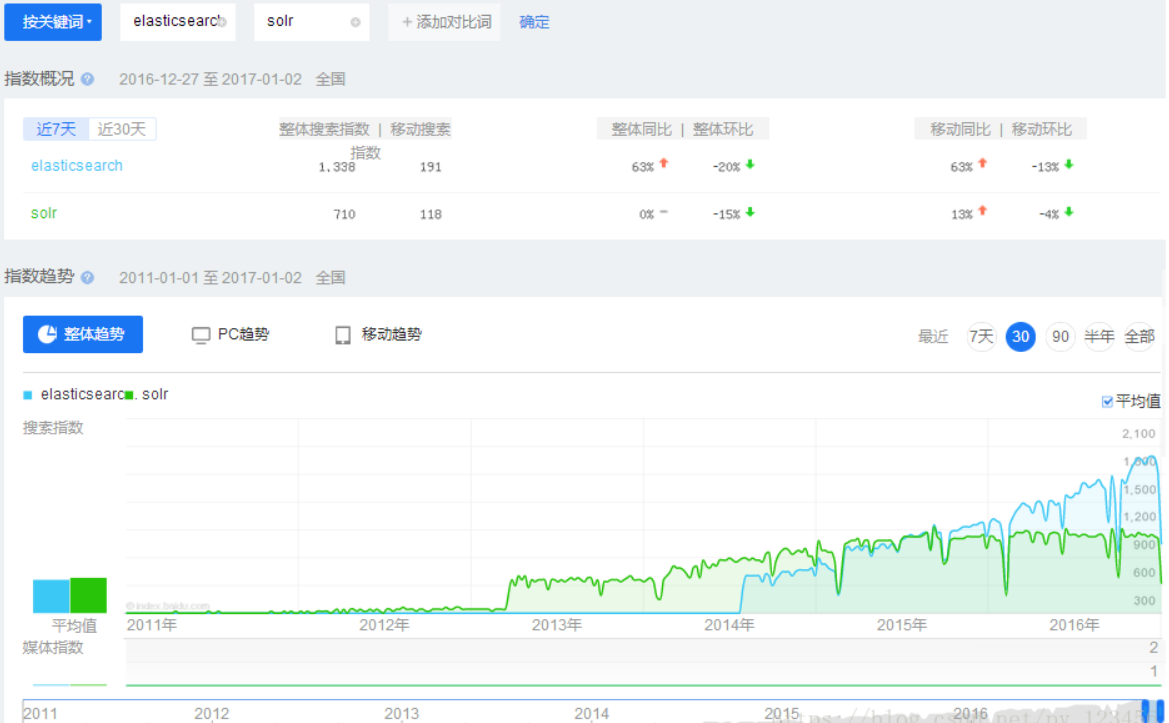
ElasticSearch 与 Solr 热度
ElasticSearch 与 Solr 总结
二者安装都很简单
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能。
- Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式。
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供。
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
- Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
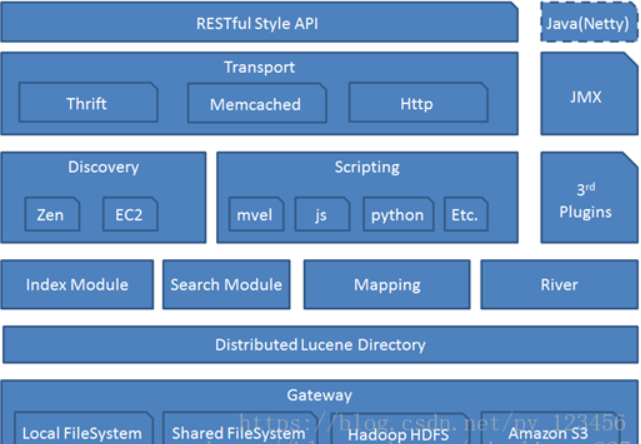
ElasticSearch 架构
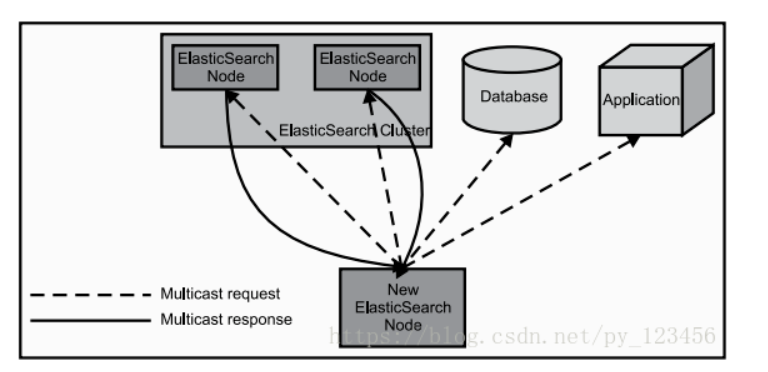
ElasticSearch 工作原理
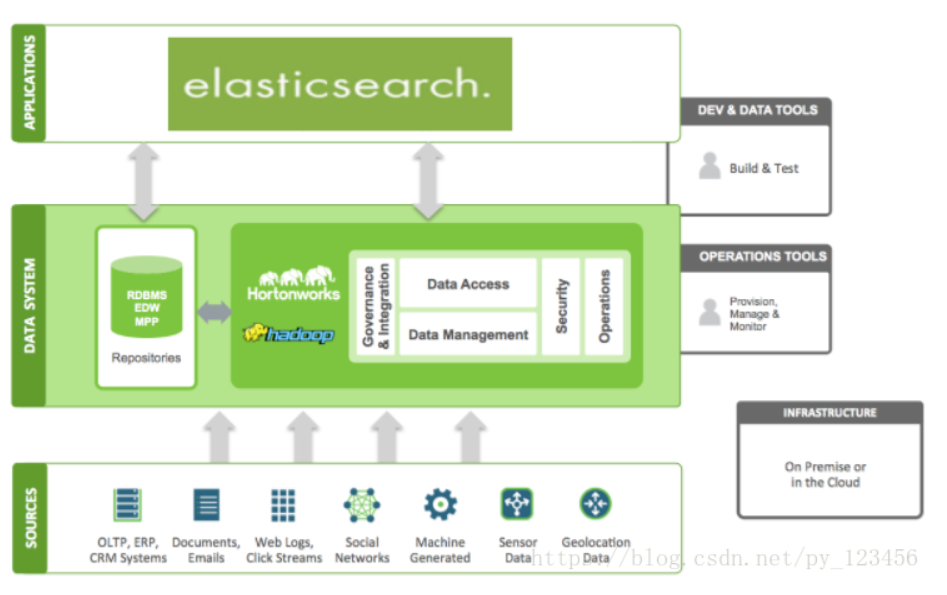
ElasticSearch 在Hadoop生态圈的位置
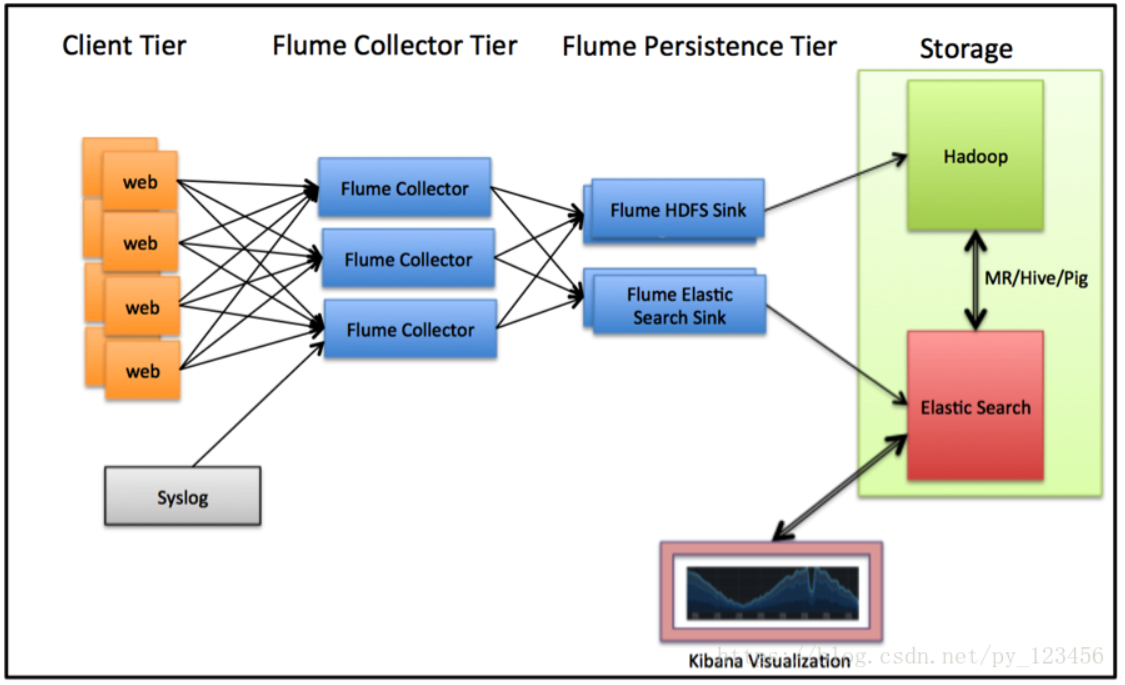
ElasticSearch 应用场景
1.站内搜索:主要和 Solr 竞争,属于后起之秀
2.NoSQL Json文档数据库:主要抢占 Mongo 的市场,它在读写性能上优于 Mongo ,同时也支持地理位置查询,还方便地理位置和文本混合查询。
3.监控:统计、日志类时间序的数据存储和分析、可视化,这方面是引领者
4.国外:Wikipedia(维基百科)使用ES提供全文搜索并高亮关键字、StackOverflow(IT问答网站)结合全文搜索与地理位置查询、Github使用Elasticsearch检索1300亿行的代码
5.国内:百度(在云分析、网盟、预测、文库、钱包、风控等业务上都应用了ES,单集群每天导入30TB+数据,总共每天60TB+)、新浪 、阿里巴巴、腾讯等公司均有对ES的使用
6.使用比较广泛的平台ELK(ElasticSearch, Logstash, Kibana)
Elasticsearch 前期准备工作
Elasticsearch 安装
安装 Elasticsearch 前提条件,必须本地环境安装 JDK1.8或以上环境。
下载地址
https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-6-2
 文件目录详解
文件目录详解
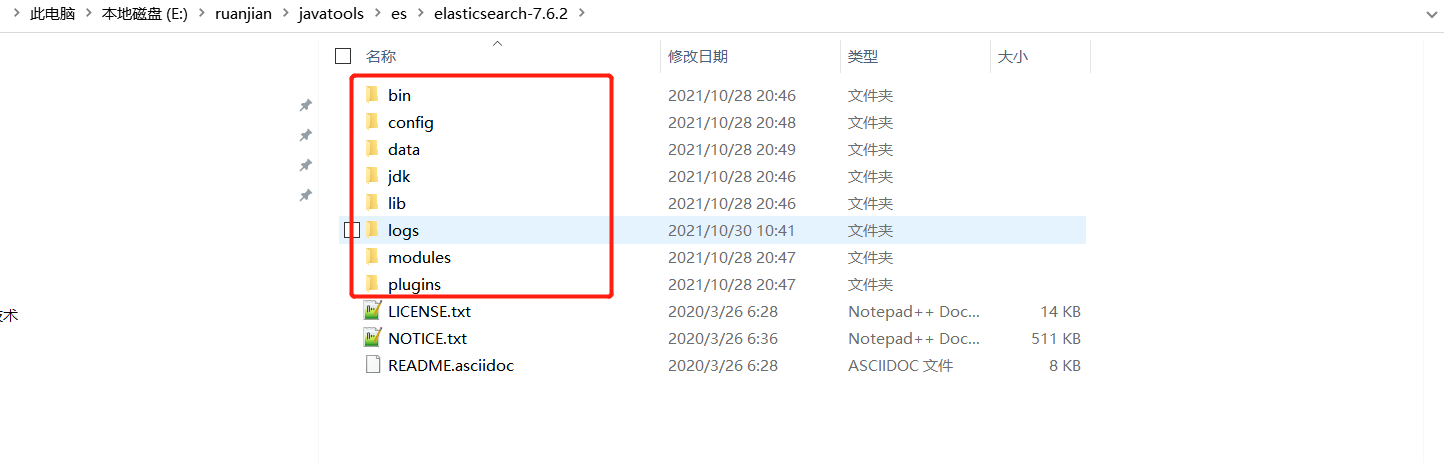
bin 启动config 配置elasticsearch.yml 配置文件jvm.options jvm 参数配置log4j2.properties 日志文件配置lib jar目录logs 日志文件目录modules 模块目录plugins 插件目录(以后安装的插件都要放在这个目录下)
启动 ES
点击E:\ruanjian\javatools\es\elasticsearch-7.6.2\bin\elasticsearch.bat 启动 Elasticsearch 
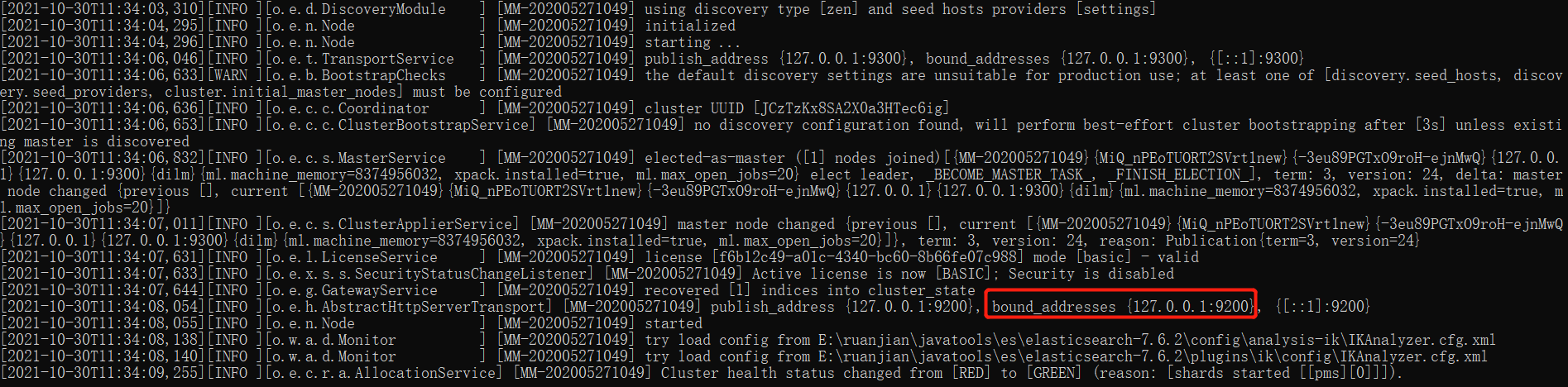 访问地址:
访问地址: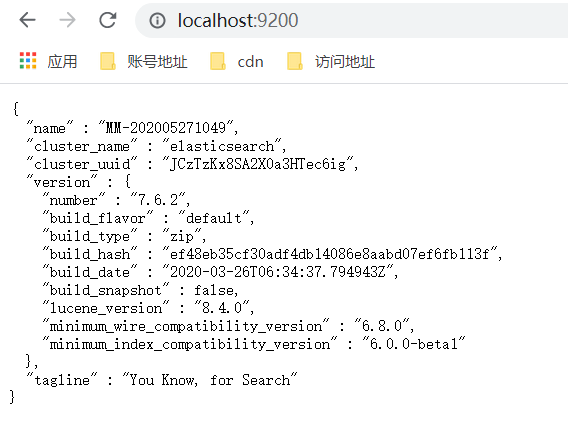
kibana 安装
下载地址
https://artifacts.elastic.co/downloads/kibana/kibana-7.6.2-windows-x86_64.zip
下载完成,解压后在bin目录下,双击【kibana.bat】,启动Kibana。
启动需要一定时间
默认启动后,通过浏览器访问 【http://localhost:5601】即可访问kibana。 
通过 Dev Tools 工具,可以使用 DSL 语句查询ES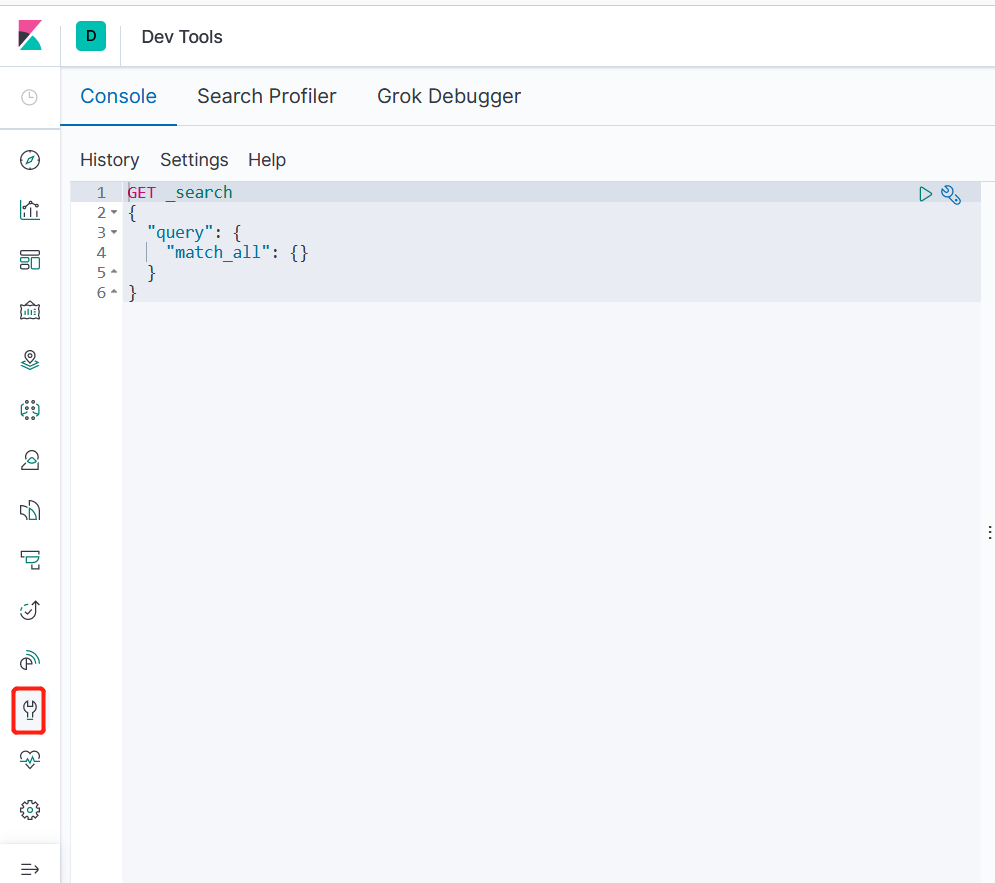
IK 分词器
下载地址
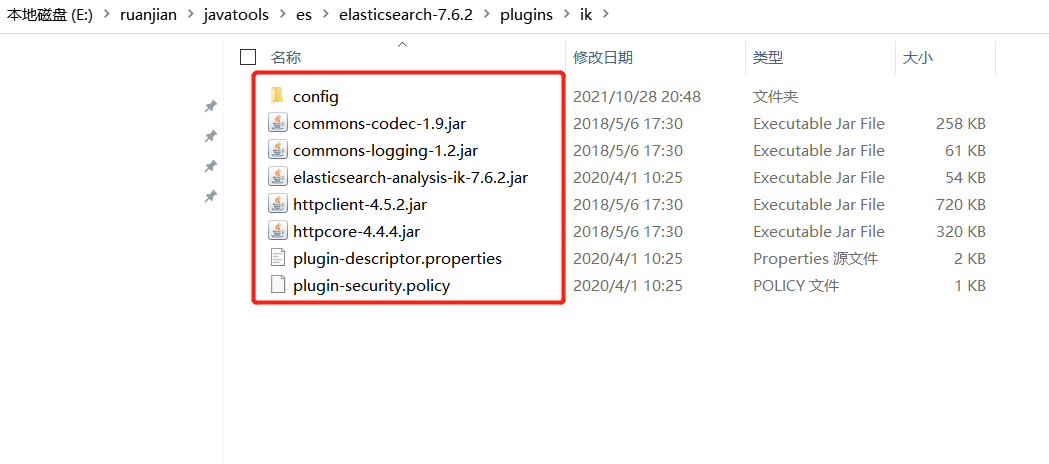
把下载ik分词器解压到E:\javaTools\es\elasticsearch-7.6.2\plugins\ik 如下图
ElasticSearch-Head插件
安装node环境
- 从地址:https://nodejs.org/en/download/ 下载相应系统的msi,双击安装。
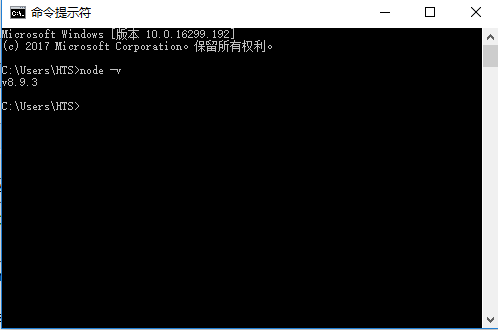
- 安装完成用cmd进入安装目录执行 node -v可查看版本号
- 执行 npm install -g grunt-cli 安装grunt ,安装完成后执行grunt -version查看是否安装成功,会显示安装的版本号

- 开始安装head
① 进入ES安装目录下的config目录,修改elasticsearch.yml文件.在文件的末尾加入以下代码,支持跨域调用ES服务
然后去掉network.host: 192.168.0.1的注释并改为network.host: 0.0.0.0,去掉cluster.name;node.name;http.port的注释(也就是去掉#)http.cors.enabled: truehttp.cors.allow-origin: "*"node.master: true node.data: true
② 双击elasticsearch.bat重启es
下载 elasticsearch-head
在 https://github.com/mobz/elasticsearch-head 中下载head插件,选择下载zip
④解压到指定文件夹下,G:\elasticsearch-7.6.2\elasticsearch-head-master\ 进入该文件夹,修改G:\elasticsearch-7.6.2\elasticsearch-head-master\Gruntfile.js 在对应的位置加上hostname:’*’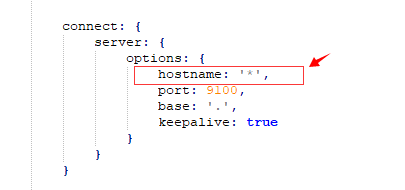
⑤在G:\elasticsearch-7.6.2\elasticsearch-head-master\ 下执行 npm install 安装完成后执行 npm run start 运行head插件,如果不成功重新安装grunt。成功如下
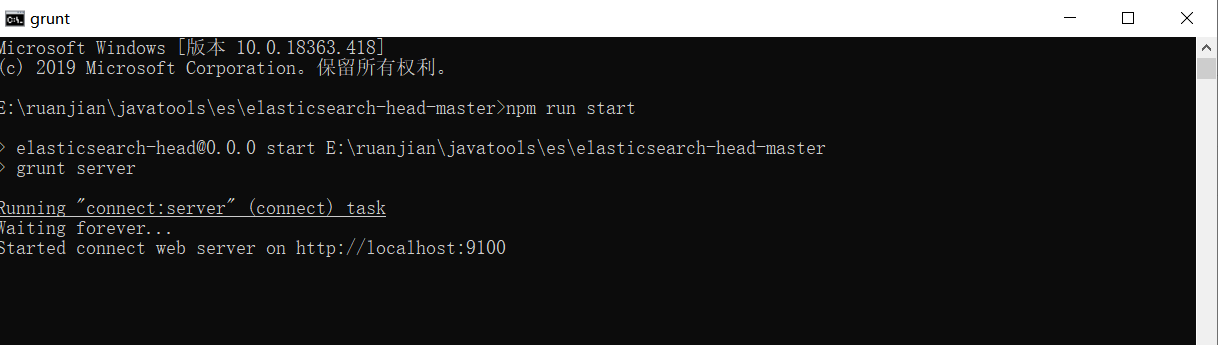
访问地址 : http://localhost:9100/
Elasticsearch 中 CRUD
创建索引
https://blog.csdn.net/weixin_43453386/article/details/108673982
https://blog.csdn.net/weixin_33806300/article/details/89566183
NBA的新的赛季又开始了,我相信大部分人有精彩比赛的时候还是会去关注的,我们创建一个 NBA 球队的索引,开始我们的学习之路,索引名称需是小写。
备注:在 7.X 版本中,直接去除了 type 的概念,就是说 index 不再会有 type。
原因分析
1、为何要去除 type 的概念?
答: 因为 Elasticsearch 设计初期,是直接查考了关系型数据库的设计模式,存在了 type(数据表)的概念。
但是,其搜索引擎是基于 Lucene 的,这种 “基因”决定了 type 是多余的。 Lucene 的全文检索功能之所以快,是因为 倒序索引 的存在。
而这种 倒序索引 的生成是基于 index 的,而并非 type。多个type 反而会减慢搜索的速度。
为了保持 Elasticsearch “一切为了搜索” 的宗旨,适当的做些改变(去除 type)也是无可厚非的,也是值得的。
所以,Why not?!
PUT /nba{"settings":{"number_of_shards": 1,"number_of_replicas": 0},"mappings":{"properties":{"name_cn":{"type":"text"},"name_en":{"type":"text"},"gymnasium":{"type":"text"},"topStar":{"type":"text"},"championship":{"type":"integer"},"date":{"type":"date"}}}}
如果格式书写正确,我们会得到如下返回信息,表示创建成功
{"acknowledged" : true,"shards_acknowledged" : true,"index" : "nba"}
设置分片和副本信息
"settings":{"number_of_shards": 1,"number_of_replicas": 0}
字段说明:
| 字段名称 | 字段说明 |
|---|---|
| nba | 索引 |
| number_of_shards | 分片数 |
| number_of_replicas | 副本数 |
| name_cn | 球队中文名 |
| name_en | 球队英文名 |
| gymnasium | 球馆名称 |
| championship | 总冠军次数 |
| topStar | 当家球星 |
| date | 加入NBA年份 |
添加
索引创建完成之后,我们往索引中加入球队数据,1,2,3 是我们指定的 ID,如果不写 ES 会默认ID。
其实我们可以不创建上面的索引 mapping 直接推送数据,但是这样 ES 会根据数据信息自动为我们设定字段类型,这会造成索引信息不准确的风险。
PUT /nba/_doc/1{"name_en":"San Antonio Spurs SAS","name_cn":"圣安东尼安马刺","gymnasium":"AT&T中心球馆","championship": 5,"topStar":"蒂姆·邓肯","date":"1995-04-12"}PUT /nba/_doc/2{"name_en":"Los Angeles Lakers","name_cn":"洛杉矶湖人","gymnasium":"斯台普斯中心球馆","championship": 16,"topStar":"科比·布莱恩特","date":"1947-05-12"}PUT /nba/_doc/3{"name_en":"Golden State Warriors","name_cn":"金州勇士队","gymnasium":"甲骨文球馆","championship": 6,"topStar":"斯蒂芬·库里","date":"1949-06-13"}PUT /nba/_doc/4{"name_en":"Miami Heat","name_cn":"迈阿密热火队","gymnasium":"美国航空球场","championship": 3,"topStar":"勒布朗·詹姆斯","date":"1988-06-13"}PUT /nba/_doc/5{"name_en":"Cleveland Cavaliers","name_cn":"克利夫兰骑士队","gymnasium":"速贷球馆","championship": 1,"topStar":"勒布朗·詹姆斯","date":"1970-06-13"}
修改
put 修改
put 修改必须字段全部映射上,不然会映射为空字段(丢失字段)
说明:修改id = 5 这条数据,把 “name_cn”:”克利夫兰骑士队” 为 “洛杉矶湖人队”
PUT /nba/_doc/5{"name_en":"Cleveland Cavaliers","name_cn":"洛杉矶湖人队","gymnasium":"速贷球馆","championship": 5,"topStar":"勒布朗·詹姆斯","date":"1970-06-13"}
返回结果
修改成功:version 版本会自动+1
{"_index" : "nba","_type" : "_doc","_id" : "5","_version" : 2,"result" : "updated","_shards" : {"total" : 1,"successful" : 1,"failed" : 0},"_seq_no" : 5,"_primary_term" : 2}
修改单个字段
POST /nba/_doc/5/_update{"doc":{"name_cn":"洛杉矶湖人队2"}}
返回结果
{"_index" : "nba","_type" : "_doc","_id" : "5","_version" : 7,"_seq_no" : 10,"_primary_term" : 2,"found" : true,"_source" : {"name_en" : "Cleveland Cavaliers","name_cn" : "洛杉矶湖人队2","gymnasium" : "速贷球馆","championship" : 5,"topStar" : "勒布朗·詹姆斯","date" : "1970-06-13"}}
查询
上面新增完数据之后,这时候我们再执行开始的 MATCH_ALL ,就会发现我们自己的索引信息也在查询的结果里面了,只是查询的结果是全部信息,其中包括索引、分片和副本的信息,内容比较多。我们可单独查询自己需要的索引信息。
Elasticsearch 提供丰富且灵活的查询语言叫做 DSL 查询 (Query Domain Specific language) ,它允许你构建更加复杂、强大的搜索。
匹配查询 match,match_all
GET /nba/_doc/_search{"query": {"match_all": {}}}
查询返回结果
{----------------first part--------------------"took" : 5,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},-----------------second part---------------------"hits" : {"total" : {"value" : 5,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "nba","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"name_en" : "San Antonio Spurs SAS","name_cn" : "圣安东尼安马刺","gymnasium" : "AT&T中心球馆","championship" : 5,"topStar" : "蒂姆·邓肯","date" : "1995-04-12"}},{"_index" : "nba","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"name_en" : "Los Angeles Lakers","name_cn" : "洛杉矶湖人","gymnasium" : "斯台普斯中心球馆","championship" : 16,"topStar" : "科比·布莱恩特","date" : "1947-05-12"}},{"_index" : "nba","_type" : "_doc","_id" : "3","_score" : 1.0,"_source" : {"name_en" : "Golden State Warriors","name_cn" : "金州勇士队","gymnasium" : "甲骨文球馆","championship" : 6,"topStar" : "斯蒂芬·库里","date" : "1949-06-13"}},{"_index" : "nba","_type" : "_doc","_id" : "4","_score" : 1.0,"_source" : {"name_en" : "Miami Heat","name_cn" : "迈阿密热火队","gymnasium" : "美国航空球场","championship" : 3,"topStar" : "勒布朗·詹姆斯","date" : "1988-06-13"}},{"_index" : "nba","_type" : "_doc","_id" : "5","_score" : 1.0,"_source" : {"name_en" : "Cleveland Cavaliers","name_cn" : "克利夫兰骑士队","gymnasium" : "速贷球馆","championship" : 1,"topStar" : "勒布朗·詹姆斯","date" : "1970-06-13"}}]}}
描述:响应的数据结果分为两部分
第一部分为:分片副本信息,第二部分 hits 包装的为查询的数据集。
match 查询
查询英文名称为:”Golden State Warriors” 的球队信息
GET /nba/_doc/_search{"query": {"match": {"name_en": "Golden State Warriors"}}}
查看所有的索引
GET _cat/indices
返回结果
yellow open testquery XVxmphCKRm6NZOZqskTSAw 1 1 1 0 3.1kb 3.1kbyellow open multimatchtest 5DV6kiD0TmOOhCja-slXHQ 1 1 0 0 283b 283bgreen open .kibana_task_manager_1 ZcvulkaOTSi_t39rKLyU1A 1 0 2 1 26.8kb 26.8kbgreen open .apm-agent-configuration MQK1xmi8T2yLF14df0v00Q 1 0 0 0 283b 283bgreen open pms waSiNQFjSX-XC-F9_QAPEA 1 0 64 0 26.3kb 26.3kbyellow open testquery2 y3w_9mXoS8aPAHQjs2Vrxg 1 1 1 0 3.1kb 3.1kbgreen open nba wRQCEB8DRv6rn5Q5f286Nw 1 0 5 0 6.3kb 6.3kbgreen open .kibana_1 IhQxb6mhT2-0crKIe_7gTA 1 0 22 2 45.5kb 45.5kbgreen open zlp uHZF61y4Sl2gPxNndRoubA 1 0 5 0 10.3kb 10.3kb
指定字段查询
根据球队中文名称查询
GET /nba/_search
{
"query": {
"match": {
"name_cn": "洛杉矶湖人"
}
}
}
返回结果
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 4.697637,
"hits" : [
{
"_index" : "nba",
"_type" : "_doc",
"_id" : "2",
"_score" : 4.697637,
"_source" : {
"name_en" : "Los Angeles Lakers",
"name_cn" : "洛杉矶湖人",
"gymnasium" : "斯台普斯中心球馆",
"championship" : 16,
"topStar" : "科比·布莱恩特",
"date" : "1947-05-12"
}
},
{
"_index" : "nba",
"_type" : "_doc",
"_id" : "5",
"_score" : 4.097939,
"_source" : {
"name_en" : "Cleveland Cavaliers",
"name_cn" : "洛杉矶湖人队2",
"gymnasium" : "速贷球馆",
"championship" : 5,
"topStar" : "勒布朗·詹姆斯",
"date" : "1970-06-13"
}
}
]
}
}
布尔值查询
must (and),所有的条件都要符合,相当Mysql Where age = 19 and username = xxx
GET nba/_search
{
"query": {
"bool": {
"must": [
{
"match": {"name_cn": "洛杉矶湖人"}
},
{
"match": {
"topStar":"勒布朗·詹姆斯"
}
}
]
}
}
}
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 8.156839,
"hits" : [
{
"_index" : "nba",
"_type" : "_doc",
"_id" : "5",
"_score" : 8.156839,
"_source" : {
"name_en" : "Cleveland Cavaliers",
"name_cn" : "洛杉矶湖人队2",
"gymnasium" : "速贷球馆",
"championship" : 5,
"topStar" : "勒布朗·詹姆斯",
"date" : "1970-06-13"
}
},
{
"_index" : "nba",
"_type" : "_doc",
"_id" : "2",
"_score" : 5.213199,
"_source" : {
"name_en" : "Los Angeles Lakers",
"name_cn" : "洛杉矶湖人",
"gymnasium" : "斯台普斯中心球馆",
"championship" : 16,
"topStar" : "科比·布莱恩特",
"date" : "1947-05-12"
}
}
]
}
}
should (or),所有的条件符合一个即可, 相当Mysql Where age = 19 and username = xxx
GET zlp/_search
{
"query": {
"bool": {
"should": [
{
"match": {"username": "change"}
},{
"match": {"age": 44}
}
]
}
}
}
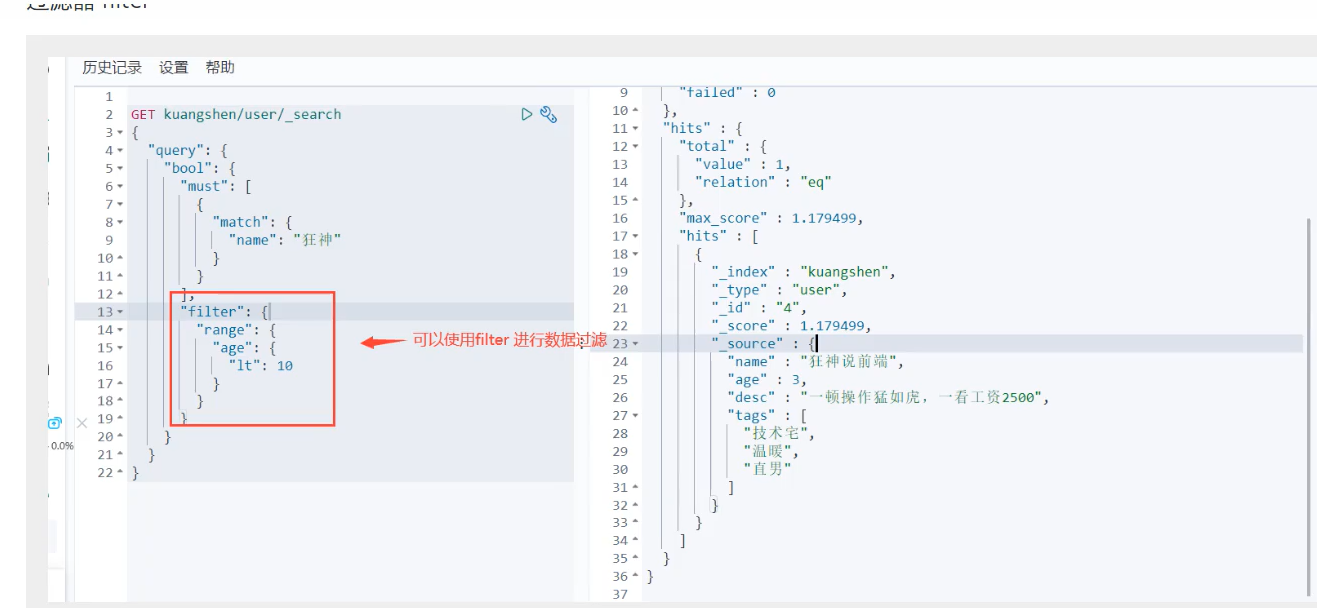
过滤器查询
GET zlp/_search
{
"query": {
"bool": {
"should": [
{
"match": {"username": "change"}
}
],
"filter": [
{
"range": {
"age": {
"gte": 10,
"lte": 30
}
}
}
]
}
}
}
term 与 match 区别
全文搜索, 通常用于对text类型字段的查询,会对进行查询的文本先进行分词操作,如下图
term
精确查询,通常用于对 keyword 类型 和有精确值的字段进行查询,不会对进行查询的文本进行分词操作,精确匹配,
如果字段类型设置了分词器,会查询分词器倒排索引分词 如下图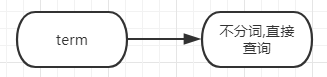
新建索引
PUT /testquery
{
"mappings": {
"properties": {
"bookName":{
"type":"text",
"analyzer": "ik_max_word"
}
}
}
}
测试分词效果
GET /_analyze
{
"analyzer": "ik_max_word",
"text": ["Java编程思想"]
}
{
"tokens" : [
{
"token" : "java",
"start_offset" : 0,
"end_offset" : 4,
"type" : "ENGLISH",
"position" : 0
},
{
"token" : "编程",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "思想",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 2
}
]
}
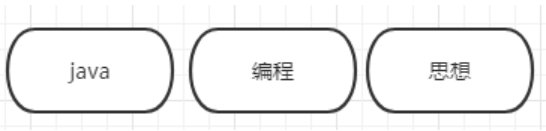
添加数据
POST /testquery/_doc/1
{
"bookName":"Java编程思想"
}
先看看 Java 的分词效果
GET /_analyze
{
"analyzer": "ik_max_word",
"text": ["Java"]
}
返回结果
{
"tokens": [
{
"token": "java",
"start_offset": 0,
"end_offset": 4,
"type": "ENGLISH",
"position": 0
}
]
}
存在, 所以是可以查询到的
POST /testquery/_search
{
"query": {
"match": {
"bookName": "Java"
}
}
}
{
"took": 60,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.2876821,
"hits": [
{
"_index": "testquery",
"_type": "books",
"_id": "vYOz-msB_TzP5bFY5JlL",
"_score": 0.2876821,
"_source": {
"bookName": "Java编程思想"
}
}
]
}
}
测试term查询, 不进行分词操作
查看上面的分词结果, java是在分词结果中的,所以可以查询到
POST /testquery/_search
{
"query": {
"term": {
"bookName": "java"
}
}
}
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.2876821,
"hits": [
{
"_index": "testquery",
"_type": "books",
"_id": "vYOz-msB_TzP5bFY5JlL",
"_score": 0.2876821,
"_source": {
"bookName": "Java编程思想"
}
}
]
}
}
查询 Java
Java不在上面的分词结果中, 结果当然就查询不到
POST /testquery/_search
{
"query": {
"term": {
"bookName": "Java"
}
}
}
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 0,
"max_score": null,
"hits": []
}
}
分词器
GET /_analyze
{
"analyzer": "ik_max_word",
"text": ["Java编程思想"]
}
返回结果
{
"tokens" : [
{
"token" : "java",
"start_offset" : 0,
"end_offset" : 4,
"type" : "ENGLISH",
"position" : 0
},
{
"token" : "编程",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "思想",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 2
}
]
}
分页
from:起始数量,size: 每页显示多少条,相当于数据库中 limit x,y
GET zlp/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 2
}
删除
删除索引
DELETE /zlp
删除文档记录
删除单条记录
DELETE /zlp/1
高亮
在使用match查询的同时,加上一个highlight属性:
- pre_tags:前置标签
- post_tags:后置标签
- fields:需要高亮的字段
GET zlp/_search
{
"query": {
"match": {
"username": "change"
}
},
"highlight": {
"pre_tags": "<font color='red'>",
"post_tags": "</font>",
"fields": {
"username": {}
}
}
}
返回结果
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 0.7079357,
"hits" : [
{
"_index" : "zlp",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.7079357,
"_source" : {
"username" : "change",
"age" : 23,
"birthday" : "1970-06-13"
},
"highlight" : {
"username" : [
"<font color='red'>change</font>"
]
}
},
{
"_index" : "zlp",
"_type" : "_doc",
"_id" : "5",
"_score" : 0.4889865,
"_source" : {
"username" : "change study java",
"age" : 34,
"birthday" : "1970-06-13"
},
"highlight" : {
"username" : [
"<font color='red'>change</font> study java"
]
}
},
{
"_index" : "zlp",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.4889865,
"_source" : {
"username" : "change study java2",
"age" : 34,
"birthday" : "1970-06-13"
},
"highlight" : {
"username" : [
"<font color='red'>change</font> study java2"
]
}
}
]
}
}
Elasticsearch 整合 SpringBoot
pom依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.6.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!-- elasticsearch启动器 (必须)-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>4.5.7</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
application.yml 文件配置
## 服务启动端口号
server:
port: 9190
spring:
data:
## Elasticsearch配置文件
elasticsearch:
## 集群名称
cluster-name: elasticsearch
## 访问地址
cluster-nodes: 10.3.149.131:9300
索引操作
创建索引和映射
SpringBoot-data-elasticsearch 提供了面向对象的方式操作 elasticsearch
业务:创建一个商品对象,有这些属性:
id,title,categoryId,brandid,price……,图片地址在 SpringDataElasticSearch 中,只需要操作对象,就可以操作elasticsearch中的数据
ES实体类
首先我们准备好实体类:
/**
* @author :ZouLiPing
* @description:商品 entity
* @date :2021-11-3 11:29:14
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@Document(indexName = "good", replicas = 0)
public class Googs {
/**
* 作用在成员变量,标记一个字段作为id主键
*/
@Id
private Long id;
/**
* 标题
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String title;
/**
* 分类
*/
@Field(type = FieldType.Keyword)
private String category;
/**
* 品牌
*/
@Field(type = FieldType.Keyword)
private String brandName;
/**
* 价格
*/
@Field(type = FieldType.Long)
private Long price;
/**
* 图片地址
*/
@Field(index = false, type = FieldType.Keyword)
private String images;
}
映射—注解
Spring Data 通过注解来声明字段的映射属性,有下面的三个注解:
- @Document 作用在类,标记实体类为文档对象,一般有两个属性indexName:对应索引库名称type:对应在索引库中的类型
- shards:分片数量,默认5
- replicas:副本数量,默认1
- @Id 作用在成员变量,标记一个字段作为id主键
- @Field 作用在成员变量,标记为文档的字段,并指定字段映射属性:
- type:字段类型,是枚举:FieldType,可以是 text、long、short、date、integer、object等
- text:存储数据时候,会自动分词,并生成索引
- keyword:存储数据时候,不会分词建立索引
- Numerical:数值类型,分两类
- 基本数据类型:long、interger、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
- 需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时再还原。
- Date:日期类型
- elasticsearch 可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。
- index:是否索引,布尔类型,默认是true
- store:是否存储,布尔类型,默认是false
- analyzer:分词器名称,这里的ik_max_word即使用ik分词器
创建索引
ElasticsearchTemplate 中提供了创建索引的API: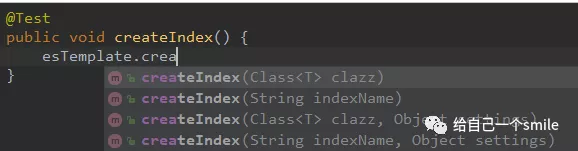
可以根据类的信息自动生成,也可以手动指定 indexName 和 Settings
映射相关的API
一样,可以根据类的字节码信息(注解配置)来生成映射,或者手动编写映射
我们这里采用类的字节码信息创建索引并映射,下面是测试类代码:
@RestController
@RequiredArgsConstructor
public class ElasticsearchController {
private final ElasticsearchRestTemplate elasticsearchRestTemplate;
/**
* 创建 Goods 文档对象
*/
@GetMapping("createIndex")
public boolean createIndex() {
boolean result = elasticsearchRestTemplate.createIndex(Googs.class);
return result;
}
}
运行 createIndex(),索引创建成功后打开 elasticsearch-head-master 插件(es-head插件的安装)查看索引信息,
索引信息: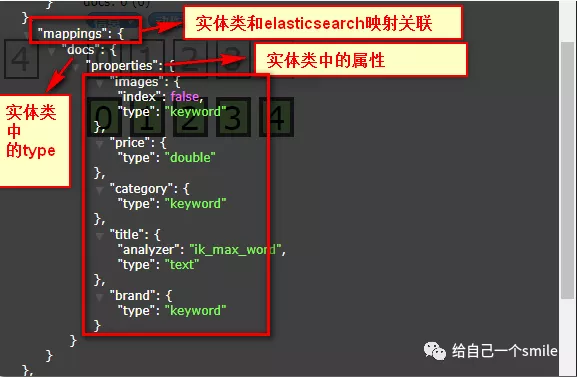
删除索引
可以根据类名或索引名删除。
/**
* 删除索引
*/
@GetMapping("testDeleteIndex")
public boolean testDeleteIndex() {
boolean result = elasticsearchRestTemplate.deleteIndex(Googs.class);
return result;
}
新增文档数据
Repository接口
Spring Data 的强大之处,就在于你不用写任何DAO处理,自动根据方法名或类的信息进行CRUD操作。只要你定义一个接口,然后继承Repository提供的一些子接口,就能具备各种基本的CRUD功能。
我们看到有一个 ElasticsearchCrudRepository 接口:
所以,我们只需要定义接口,然后继承它就OK了
/**
* @author :ZouLiPing
* @description:定义ItemRepository 接口
* @date :2021-11-3 11:43:51
*/
public interface GoodsRepository extends ElasticsearchRepository<Googs,Long> {
}
接下来,我们测试新增数据:
新增一个对象
@Autowiredprivate
GoodsRepository coodsRepository;
@GetMapping("insert")
public void insert() {
Googs item = new Googs(10L, "荣耀10", " 手机", "华为", 349900L, "http://image.baidu.com/13123.jpg");
coodsRepository.save(item);
}

批量新增
代码如下:
/**
* @desc 定义批量新增方法
*
*/
@GetMapping("insertList")public void insertList() {
List<Googs> list = new ArrayList<>();
list.add(new Googs(11L, "小米R1", " 手机", "锤子", 369900L, "http://image.baidu.com/13123.jpg")); list.add(new Googs(12L, "vivo10", " 手机", "华为", 280000L, "http://image.baidu.com/13123.jpg"));
list.add(new Googs(13L, "华为META10", " 手机", "华为", 44993L, "http://image.baidu.com/13123.jpg"));
list.add(new Googs(14L, "华为META10", " 手机", "华为", 44993L, "http://image.baidu.com/13123.jpg"));
list.add(new Googs(15L, "华为META10", " 手机", "华为", 44993L, "http://image.baidu.com/13123.jpg"));
list.add(new Googs(16L, "华为META10", " 手机", "华为", 44993L, "http://image.baidu.com/13123.jpg"));
// 接收对象集合,实现批量新增
coodsRepository.saveAll(list);
}
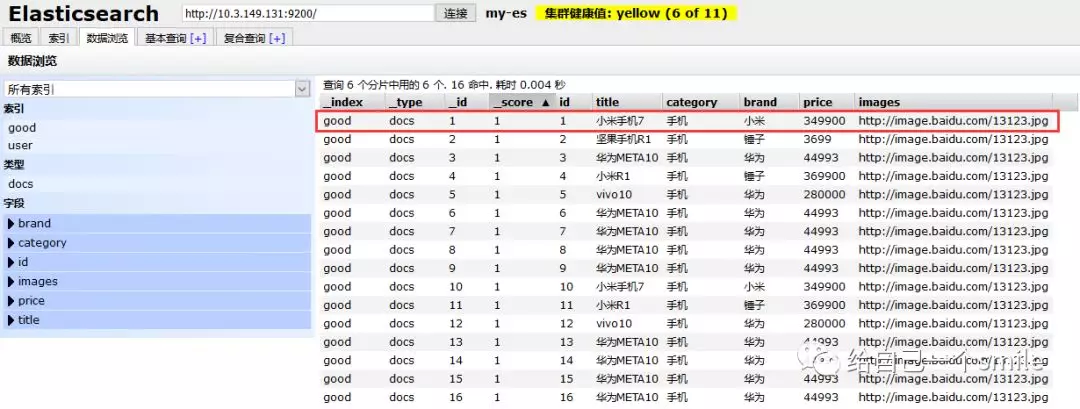
再次去页面查询: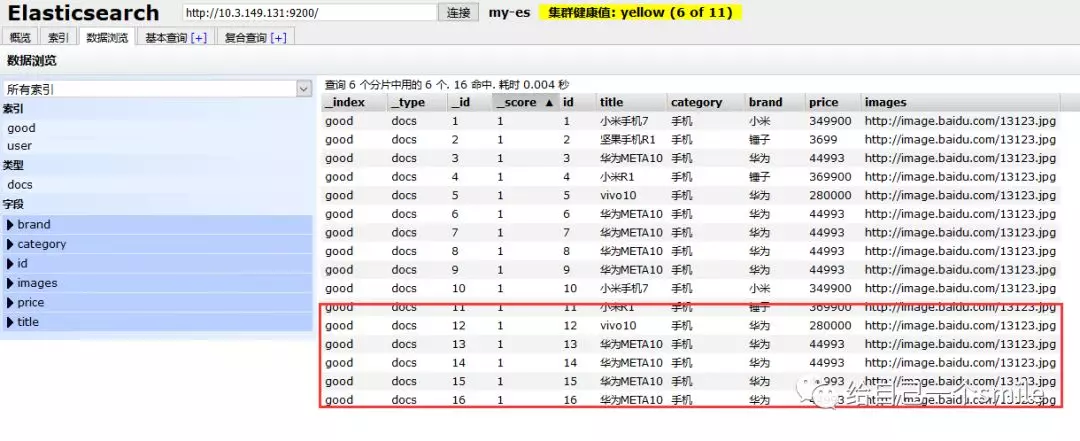
OK,批量新增成功!
修改
elasticsearch中本没有修改,它的修改原理是该是先删除在新增
修改和新增是同一个接口,区分的依据就是id。
/**
* 定义修改方法
*/
@GetMapping("update")
public void update(){
Googs item = new Googs(1L, "苹果XSMax", " 手机",
"小米", 349923L, "http://image.baidu.com/13123.jpg");
coodsRepository.save(item);
}
查询
基本查询
ElasticsearchRepository提供了一些基本的查询方法:
我们来试试查询所有:
/**
* 定义查询方法,含对价格的降序、升序查询
*/
@GetMapping("testQueryAll")
public void testQueryAll(){
// 查找所有
//Iterable<Item> list = this.itemRepository.findAll();
// 对某字段排序查找所有 Sort.by("price").descending() 降序
// Sort.by("price").ascending():升序
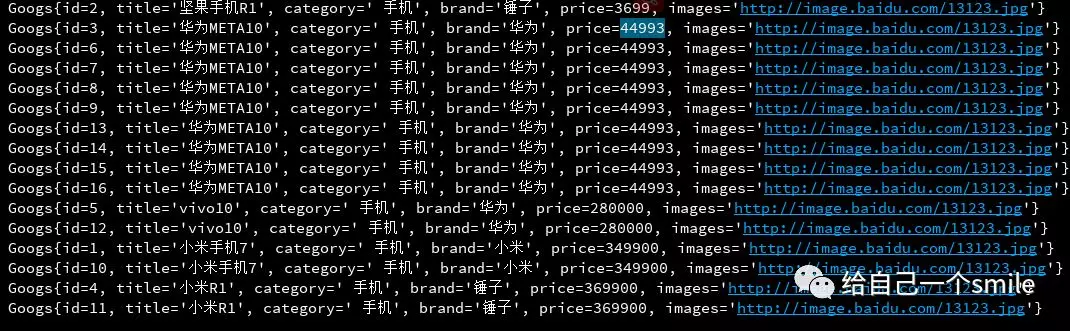
Iterable<Googs> list = this.coodsRepository.findAll(Sort.by("price").ascending());
for (Googs item:list){
System.out.println(item);
}
}
自定义方法
Spring Data 的另一个强大功能,是根据方法名称自动实现功能。
比如:你的方法名叫做:findByTitle,那么它就知道你是根据title查询,然后自动帮你完成,无需写实现类。
当然,方法名称要符合一定的约定:
Keyword Sample
And findByNameAndPrice
Or findByNameOrPrice → 或
Is findByName → 是 相当于and
Not findByNameNot
Between findByPriceBetween →查询价格范围直接
LessThanEqual findByPriceLessThan →小于等于
GreaterThanEqual findByPriceGreaterThan
Before findByPriceBefore → 小于
After findByPriceAfter → 大于
Like findByNameLike → 模糊
StartingWith findByNameStartingWith
EndingWith findByNameEndingWith
Contains/Containing findByNameContaining
In findByNameIn(Collection<String>names)
NotIn findByNameNotIn(Collection<String>names)
Near findByStoreNear
True findByAvailableTrue
False findByAvailableFalse
OrderBy findByAvailableTrueOrderByNameDesc
例如,我们来按照价格区间查询,定义这样的一个方法:
/**
* @author :ZouLiPing
* @description:定义ItemRepository 接口
* @date :2019/9/2 18:06
*/
public interface GoodsRepository extends ElasticsearchRepository<Googs,Long> {
/**
* @Description:根据价格区间查询
* @Param price1
* @Param price2
*/
List<Googs> findByPriceBetween(Long price1, Long price2);
}
/**
* @description:matchQuery底层采用的是词条匹配查询
*/
@GetMapping("testMatchQuery")
public Page<Googs> testMatchQuery(){
// 构建查询条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 添加基本分词查询
queryBuilder.withQuery(QueryBuilders.matchQuery("title", "小米手机"));
// 搜索,获取结果
Page<Googs> items = this.coodsRepository.search(queryBuilder.build());
// 总条数
long total = items.getTotalElements();
System.out.println("total = " + total);
for (Googs goods : items) {
System.out.println(goods.toString());
}
return items;
}
NativeSearchQueryBuilder:Spring提供的一个查询条件构建器,帮助构建json格式的请求体
QueryBuilders.matchQuery(“title”, “小米手机”):利用QueryBuilders来生成一个查询。QueryBuilders提供了大量的静态方法,用于生成各种不同类型的查询:
Page
totalElements:总条数
totalPages:总页数
Iterator:迭代器,本身实现了Iterator接口,因此可直接迭代得到当前页的数据
其它属性:
结果:
聚合
聚合可以让我们极其方便的实现对数据的统计、分析。
例如:
- 什么品牌的手机最受欢迎?
- 这些手机的平均价格、最高价格、最低价格?
- 这些手机每月的销售情况如何?
- 实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
聚合基本概念
Elasticsearch中的聚合,包含多种类型,最常用的两种,一个叫桶,一个叫度量:
桶(bucket)
桶的作用,是按照某种方式对数据进行分组,每一组数据在ES中称为一个桶,例如我们根据国籍对人划分,可以得到中国桶、英国桶,日本桶……或者我们按照年龄段对人进行划分:010,1020,2030,3040等。
Elasticsearch中提供的划分桶的方式有很多:
Date Histogram Aggregation:根据日期阶梯分组,例如给定阶梯为周,会自动每周分为一组
Histogram Aggregation:根据数值阶梯分组,与日期类似
Terms Aggregation:根据词条内容分组,词条内容完全匹配的为一组
Range Aggregation:数值和日期的范围分组,指定开始和结束,然后按段分组
……
综上所述,我们发现bucket aggregations 只负责对数据进行分组,并不进行计算,因此往往bucket中往往会嵌套另一种聚合:metrics aggregations即度量
度量(metrics)
分组完成以后,我们一般会对组中的数据进行聚合运算,例如求平均值、最大、最小、求和等,这些在ES中称为度量
比较常用的一些度量聚合方式:
Avg Aggregation:求平均值
Max Aggregation:求最大值
Min Aggregation:求最小值
Percentiles Aggregation:求百分比
Stats Aggregation:同时返回avg、max、min、sum、count等
Sum Aggregation:求和
Top hits Aggregation:求前几
Value Count Aggregation:求总数
……
注意:在ES中,需要进行聚合、排序、过滤的字段其处理方式比较特殊,因此不能被分词。这里我们将color和make这两个文字类型的字段设置为keyword类型,这个类型不会被分词,将来就可以参与聚合
ok,SpringBoot整合Spring Data Elasticsearch到此完结
要是还有不太明白的地方请留言,评论必回
要是对我的文章感兴趣的话,关注一下吧,谢谢!
高亮查询
/**
* 高亮查询
* @date: 2021/11/3 15:34
* @return: boolean
*/
@GetMapping("hightLightSearch")
public Pager hightLightSearch(
@RequestParam(required = false) String keyword,
@RequestParam(required = false, defaultValue = "0") Integer pageNum,
@RequestParam(required = false, defaultValue = "5") Integer pageSize
) {
Pageable pageable = PageRequest.of(pageNum, pageSize);
Page page;
// 构建查询条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 添加基本分词查询
queryBuilder.withQuery(QueryBuilders.matchQuery("title", keyword));
// 高亮查询
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<font color=\"red\">");
highlightBuilder.postTags("</font>");
highlightBuilder.highlighterType("unified");
highlightBuilder.field("title");
highlightBuilder.requireFieldMatch(false);//多次段高亮需要设置为false
queryBuilder.withHighlightBuilder(highlightBuilder);
NativeSearchQuery build = queryBuilder.build();
// 搜索,获取结果
SearchHits<Googs> searchHits = this.elasticsearchRestTemplate.search(build,Googs.class);
if (searchHits.getTotalHits() <= 0){
return new Pager();
}
log.info("DSL:{}", build.getQuery().toString());
List<Googs> searchProductList = searchHits.stream().map(SearchHit::getContent).collect(Collectors.toList());
List<Map<String, List<String>>> highlightFields = searchHits.stream().map(SearchHit::getHighlightFields).collect(Collectors.toList());
log.info("highlightFields={}", JSON.toJSONString(highlightFields));
for (int i = 0; i < searchProductList.size(); i++) {
Map<String, List<String>> fieldListMap = highlightFields.get(i);
Googs googs = searchProductList.get(i);
googs.setTitle(fieldListMap.get("title").get(0));
}
log.info("searchProductList={}",JSON.toJSONString(searchProductList));
page = new PageImpl<>(searchProductList, pageable, searchHits.getTotalHits());
return Pager.restPage(page);
}

若有收获,就点个赞吧
0 人点赞
