单机还是分布式?
需要的运行资源是Hadoop yarn分配还是本机系统自己分配?
设置
运行何种模式,取决于参数:mapreduce.framework.name
- yarn:YARN集群模式、
- local:本地模式
- 如果不指定,默认是local模式
- 在
mapred-default.xml中定义 - 如果代码中
conf.set、运行的环境中有配置mapred-site.xml,会默认覆盖default配置。



YARN集群模式
- MapReduce程序提交给yarn集群,分发到多个节点上分布式并发执行。数据通常位于HDFS。
需要配置参数∶
mapreduce.framework.name=yarnyarn.resourcemanager.hostname=node1.itcast.cn
提交集群的实现步骤︰
- 确保Hadoop集群启动(HDFS集群、YARN集群);
- 将程序打成jar包,上传jar到Hadoop集群的任意一个节点;
- 执行命令启动。
上述的两个参数,在集群的运行环境已经配置完成

打jar包:
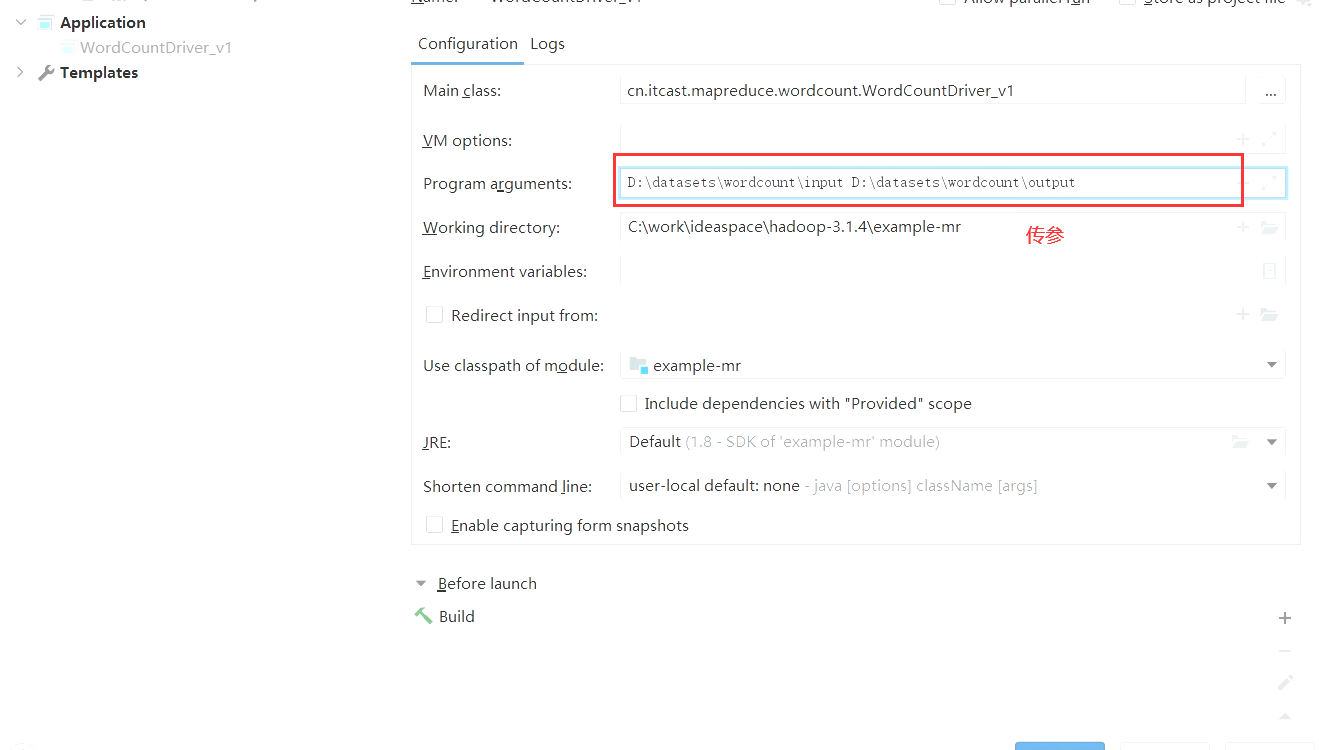
运行:

local模式
用于调试
- MapReduce程序是被提交给lpcalJobRunner在本地以单进程的形式运行。是单机程序。
- 输入和输出的数据可以在本地文件系统,也可以在HDFS上。
- 本地模式非常便于进行业务逻辑的debug。
- 右键直接运行main方法所在的主类即可。

如何区别模式
代码的注解模式是最高的
(1)方法1:登录YARN集群查看,是否有程序执行过的记录(这是最准确靠谱的)
(2)方式2∶通过查看执行日志

若有收获,就点个赞吧
0 人点赞
