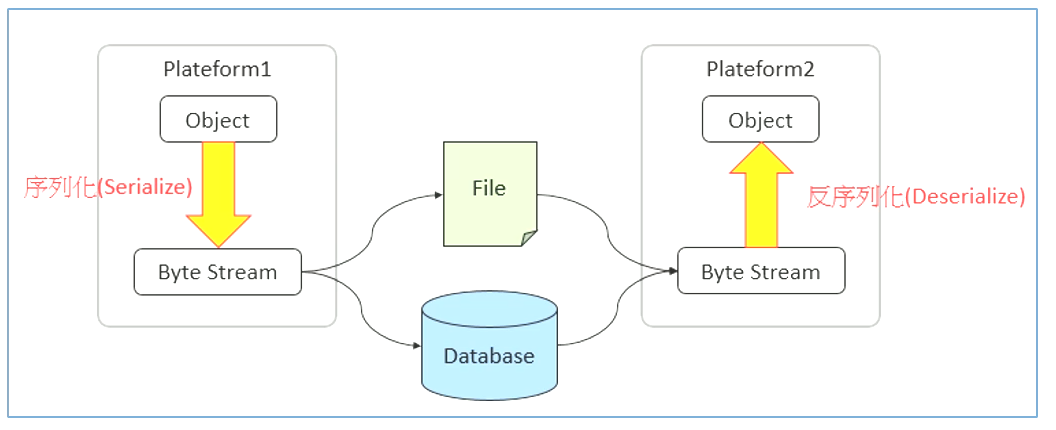
什么是序列化
- 序列化(Serialization)
将结构化对象转换成字节流以便于进行网络传输或写入持久存储的过程。
- 反序列化( Deserialization )
将字节流转换为一系列结构化对象的过程,重新创建该对象。
Java序列化机制
Java中一切都是对象。 开发程序中,经常会涉及到下述场景∶ 跨进程、跨网络传递对象;将对象数据持久化存储; 这就需要有一种可以在两端传输数据的协议。 Java序列化机制就是为了解决这个问题而产生。
- Java对象序列化的机制,把对象表示成一个二进制的字节数组,里面包含了对象的数据,对象的类型信息,对象内部的数据的类型信息等等。通过保存或则转移这些二进制数组达到持久化、传递的目的。
要实现序列化,需要实现java.io.Serializable接口。反序列化是和序列化相反的过程,就是把二进制数组转化为对象的过程。
Hadoop序列化机制
Hadoop的序列化没有采用java的序列化机制,而是实现了自己的序列化机制Writable。
原因在于java的序列化机制比较臃肿,重量级,是一种不断的创建对象的机制,并且会额外附带很多信息(校验、继承关系系统等)。 但在Hadoop的序列化机制中,用户可以复用对象,这样就减少了java对象的分配和回收,提高了应用效率。 Hadoop通过Writable接口实现的序列化机制,接口提供两个方法
write和readFields。write叫做序列化方法,用于把对象指定的字段写出去﹔
- readFields叫做反序列化方法,用于从字节流中读取字段重构对象﹔

Hadoop没有提供对象比较功能,所以和java中的Comparable接口合并,提供一个接口WritableComparable。
WritableComparable接口可用于用户自定义对象的比较规则。

Hadoop提供了如下内容的数据类型,这些数据类型都实现了WritableComparable接口,以便用这些类型定义的数据可以被序列化进行网络传输和文件存储,以及进行大小比较。


若有收获,就点个赞吧
0 人点赞
