1. 日志收集方式
Kubernetes的业务Pod日志有两种输出方式:一种是直接打到标准输出或者标准错误,第二种是将日志写到特定目录下的文件种。针对这两种不同场景,提供了不同的容器日志收集思路。
1.1. kubernetes收集思路
1.1.1. 使用节点代理收集日志
在各个Node节点上以Deamonset方式部署log-agent-pod,将宿主机上的日志目录挂载到log-agent-pod里面,由log-agent-pod将日志发送出去。常用的log-agent是通过Fluentd实现的。
1.1.2. 使用边车模式收集日志
在每个业务Pod中,启动一个辅助容器,将主容器的日志目录挂载到辅助容器中,将主容器刷盘的日志推送出去。这种模式下,辅助容器必须要在主容器之前启动,避免主容器丢日志。常用的辅助容器是filebeat实现的。
1.1.3. 日志输出方式转换
- 标准输出—>写文件:command >/logs/stdout.log 2>/logs/stderr.log
- 写文件—>标准输出:tail -f xxx.log
1.2. 拓扑图
本实验采用辅助容器(边车模式)收集日志到ELK集群系统,本实验先将日志写到Kafka集群,然后再通过logstash消费Kafka中的数据,并写入Elasticsearch,这种方式是异步的,虽然消息的及时性不是特别高,但是性能比直接写Elasticsearch高很高。
以日志nginx为主日志程序, 简单的收集access.log和error.log日志
2. 安装zookeeper
ZK集群是有状态的服务,其选择Leader的方式和ETCD类似,要求集群节点是不低于3的奇数个。
| 主机 | IP地址 | 角色 |
|---|---|---|
| hdss7-11 | 10.4.7.11 | zk1 |
| hdss7-12 | 10.4.7.12 | zk2 |
| hdss7-21 | 10.4.7.21 | zk3 |
2.1. 安装JDK
自行准备JDK版本安装包 涉及主机 hdss7-11 hdss8-12 hdss7-21
[root@hdss7-11 ~]# cd /opt[root@hdss7-11 opt]# tar -xf jdk-8u131-linux-x64.tar.gz[root@hdss7-11 opt]# ln -s jdk1.8.0_131/ jdk[root@hdss7-11 opt]# ll jdklrwxrwxrwx 1 root root 13 12月 2 17:05 jdk -> jdk1.8.0_131/[root@hdss7-11 opt]# vim /etc/profile....export JAVA_HOME=/opt/jdkexport PATH=$JAVA_HOME/bin:$PATHexport CLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jar[root@hdss7-11 opt]# source /etc/profile[root@hdss7-11 opt]# java -versionjava version "1.8.0_131"Java(TM) SE Runtime Environment (build 1.8.0_131-b11)Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
2.2. 配置DNS解析
[root@hdss7-11 ~]# vim /var/named/odl.com.zone$ORIGIN odl.com.$TTL 600 ; 10 minutes@ IN SOA dns.odl.com. dnsadmin.odl.com. (2020091710 ; serial10800 ; refresh (3 hours)900 ; retry (15 minutes)604800 ; expire (1 week)86400 ; minimum (1 day))NS dns.odl.com.$TTL 60 ; 1 minutedns A 10.4.7.11harbor A 10.4.7.200k8s-yaml A 10.4.7.200traefik A 10.4.7.10dashboard A 10.4.7.10zk1 A 10.4.7.11zk2 A 10.4.7.12zk3 A 10.4.7.21[root@hdss7-11 ~]# systemctl restart named[root@hdss7-11 ~]# dig -t A zk3.odl.com @10.4.7.11 +short10.4.7.21
2.3. 安装zookeeper
涉及节点: hdss7-11 hdss7-12 hdss7-21
当前使用版本为 3.4.14
如果需要使用 supervisor 管理,需要调整启动脚本,比如配置Java环境变量
[root@hdss7-11 opt]# cd /opt
[root@hdss7-11 opt]# wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
[root@hdss7-11 opt]# tar -xf zookeeper-3.4.14.tar.gz
[root@hdss7-11 opt]# ln -s zookeeper-3.4.14 zookeeper
[root@hdss7-11 opt]# ll zookeeper
lrwxrwxrwx 1 root root 16 12月 2 17:40 zookeeper -> zookeeper-3.4.14
# 新建zk数据目录和日志目录
[root@hdss7-11 opt]# mkdir -p /data/zookeeper/data /data/zookeeper/logs
# 新建zk配置文件
[root@hdss7-11 opt]# vim /opt/zookeeper/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper/data
dataLogDir=/data/zookeeper/logs
clientPort=2181
server.1=zk1.odl.com:2888:3888
server.2=zk2.odl.com:2888:3888
server.3=zk3.odl.com:2888:3888
# 修改日志文件 如无修改此项 则会在启动的当前路径下生成一个zookeeper.out的日志文件
[root@hdss7-11 ~]# vim /opt/zookeeper/bin/zkEnv.sh
if [ "x${ZOO_LOG_DIR}" = "x" ]
then
#ZOO_LOG_DIR="."
ZOO_LOG_DIR="/data/zookeeper/logs"
fi
# 设置节点ID, 三个节点分别为1, 2 , 3
[root@hdss7-11 ~]# echo 1 > /data/zookeeper/data/myid
[root@hdss7-12 ~]# echo 2 > /data/zookeeper/data/myid
[root@hdss7-21 ~]# echo 3 > /data/zookeeper/data/myid
# 帮助信息
[root@hdss7-11 ~]# /opt/zookeeper/bin/zkServer.sh --help
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Usage: /opt/zookeeper/bin/zkServer.sh {start|start-foreground|stop|restart|status|upgrade|print-cmd}
# 启动
[root@hdss7-11 ~]# /opt/zookeeper/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
# 查看状态 其中一个为leader,其它为follower
[root@hdss7-11 ~]# /opt/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
.Mode: follower
[root@hdss7-12 ~]# /opt/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[root@hdss7-21 ~]# /opt/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Mode: leader
3. 安装elasticsearch
Elasticsearch 是一个有状态的服务,不建议部署在Kubernetes集群中,本次实验采用单节点部署Elasticsearch,部署节点为 hdss7-12.host.com (10.4.7.12)。 当前elasticsearch版本为 6.8.6 该节点已安装JDK
3.1. 安装es
[root@hdss7-12 ~]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.8.6.tar.gz
[root@hdss7-12 ~]# tar -xf elasticsearch-6.8.6.tar.gz -C /opt/
# 做软链接,方便以后升级
[root@hdss7-12 ~]# ln -s /opt/elasticsearch-6.8.6 /opt/elasticsearch
# 创建elk用户,该服务无法使用root启动
[root@hdss7-12 ~]# useradd elk -M ; groupadd elk
[root@hdss7-12 ~]# chown -R elk:elk /opt/elasticsearch-6.8.6 /opt/elasticsearch
# 修改elasticsearch配置文件
[root@hdss7-12 ~]# vim /opt/elasticsearch/config/elasticsearch.yml
node.name: hdss7-12.host.com
path.data: /data/elasticsearch
path.logs: /data/logs/elasticsearch/
bootstrap.memory_lock: true
network.host: 10.4.7.12
http.port: 9200
discovery.zen.ping.unicast.hosts: ["10.4.7.12"]
# 指定JVM内存上线,生产环境一般不超过32G
[root@hdss7-12 ~]# vim /opt/elasticsearch/config/jvm.options
## JVM configuration
-Xms1g
-Xmx1g
## 创建数据目录和日志目录
[root@hdss7-12 ~]# mkdir -p /data/elasticsearch /data/logs/elasticsearch/
[root@hdss7-12 ~]# chown -R elk:elk /data/elasticsearch /data/logs/elasticsearch/
## 修改elk用户限制
[root@hdss7-12 ~]# vim /etc/security/limits.conf
elk hard nofile 65535
elk soft nofile 131072
elk soft memlock unlimited
elk hard memlock unlimited
## 修改/etc/systemd/system.conf
[root@hdss7-12 ~]# vim /etc/systemd/system.conf
DefaultLimitNOFILE=65535
DefaultLimitNPROC=32000
DefaultLimitMEMLOCK=infinity
# 使其生效
[root@hdss7-12 ~]# systemctl daemon-reexec
## 修改内核参数
[root@hdss7-12 ~]# vim /etc/sysctl.conf
vm.max_map_count=262144
[root@hdss7-12 ~]# sysctl -p
vm.max_map_count = 262144
3.2. supervisorctl启动
[root@hdss7-12 ~]# vim /etc/supervisord.d/elasticsearch.ini
[program:elasticsearch-7-12]
command=/opt/elasticsearch/bin/elasticsearch -p "/data/elasticsearch/pid"
environment=JAVA_HOME=/opt/jdk
numprocs=1
directory=/opt/elasticsearch
autostart=true
autorestart=true
startsecs=30
startretries=3
exitcodes=0,2
stopsignal=QUIT
stopwaitsecs=10
user=elk
redirect_stderr=true
stdout_logfile=/data/logs/elasticsearch/elasticsearch.stdout.log
stdout_logfile_maxbytes=64MB
stdout_logfile_backups=5
stdout_capture_maxbytes=1MB
stdout_events_enabled=false
stopasgroup=true
killasgroup=true
更新配置并启动
[root@hdss7-12 ~]# supervisorctl update [root@hdss7-12 ~]# supervisorctl status elasticsearch-7-12 RUNNING pid 837, uptime 0:09:25 etcd-server-7-12 RUNNING pid 940, uptime 0:09:20查看集群状态
[root@hdss7-12 ~]# curl 'http://10.4.7.12:9200/_cluster/health?pretty' { "cluster_name" : "elasticsearch", "status" : "green", "timed_out" : false, "number_of_nodes" : 1, "number_of_data_nodes" : 1, "active_primary_shards" : 0, "active_shards" : 0, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 }
4. 安装kafka
4.1. 安装kafka
Kafka需要是有状态的服务,一般部署在Kubernetes之外,本次部署在 hdss7-11.host.com(10.4.7.12)。由于后面需要部署的Kafka-manager只支持到 2.2.0 版本,因此这次部署采用kafka_2.12-2.2.0版本,其中2.12为Scala版本号。
[root@hdss7-12 ~]# tar -xf kafka_2.12-2.2.0.tgz -C /opt/
[root@hdss7-12 ~]# ln -s /opt/kafka_2.12-2.2.0 /opt/kafaka
[root@hdss7-12 ~]# vim /opt/kafaka/config/server.properties
# 此为数据目录并非日志目录
log.dirs=/data/logs/kafka
# 超过10000条日志强制刷盘,超过1000ms刷盘
log.flush.interval.messages=10000
log.flush.interval.ms=1000
# 填写需要连接的 zookeeper 集群地址,当前连接本地的 zk 集群。
zookeeper.connect=localhost:2181
[root@hdss7-12 ~]# mkdir -p /data/kafka /data/logs/kafka
[root@hdss7-12 ~]# /opt/kafaka/bin/kafka-server-start.sh -daemon /opt/kafaka/config/server.properties
[root@hdss7-12 ~]# netstat -lntp
tcp6 0 0 :::9092 :::* LISTEN 10912/java
4.2. supervisord启动
[root@hdss7-12 ~]# vim /etc/supervisord.d/kafka.ini
[program:kafka-7-12]
command=/opt/kafaka/bin/kafka-server-start.sh /opt/kafaka/config/server.properties
numprocs=1
environment=JAVA_HOME=/opt/jdk
autostart=true
autorestart=true
startsecs=30
startretries=3
exitcodes=0,2
stopsignal=QUIT
stopwaitsecs=10
user=root
redirect_stderr=true
stdout_logfile=/data/logs/kafka/kafka.stdout.log
stdout_logfile_maxbytes=64MB
stdout_logfile_backups=5
stdout_capture_maxbytes=1MB
stdout_events_enabled=false
stopasgroup=true
killasgroup=true
[root@hdss7-12 ~]# supervisorctl update
[root@hdss7-12 ~]# supervisorctl status
elasticsearch-7-12 RUNNING pid 837, uptime 1 day, 17:34:20
etcd-server-7-12 RUNNING pid 940, uptime 1 day, 17:34:15
kafka-7-12 RUNNING pid 69394, uptime 0:01:24
[root@hdss7-12 ~]# netstat -tnlp | grep 9092
tcp6 0 0 :::9092 :::* LISTEN 69394/java
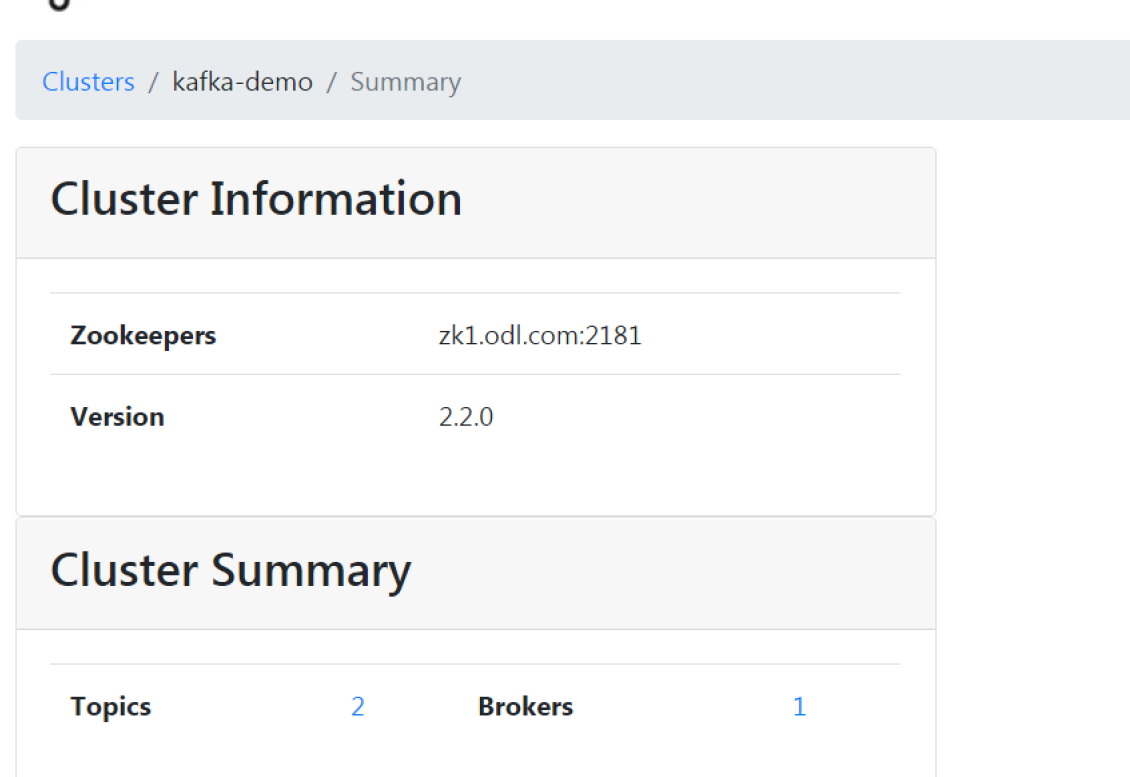
5. 安装kafka-manager
5.1. 准备镜像资源
如下列方法最后失败了 可使用sbt编译后的zip包来生成镜像
# 这里存在几个问题:
# 1. kafka-manager 改名为 CMAK,压缩包名称和内部目录名发生了变化
# 2. sbt 编译需要下载很多依赖,因为不可描述的原因,速度非常慢,个人非VPN网络大概率失败
# 3. 因本人不具备VPN条件,编译失败。又因为第一条,这个dockerfile大概率需要修改
# 4. 生产环境中一定要自己重新做一份!
~]# mkdir /opt/kafka-manager-dockerfile ; cd /opt/kafka-manager-dockerfile
kafka-manager-dockerfile]# wget https://github.com/yahoo/kafka-manager/archive/2.0.0.2.tar.gz
kafka-manager-dockerfile]# cat >repositories<<EOF
[repositories]
local
aliyun: https://maven.aliyun.com/repository/public
typesafe: https://repo.typesafe.com/typesafe/ivy-releases/, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext], bootOnly
ivy-sbt-plugin:https://dl.bintray.com/sbt/sbt-plugin-releases/, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext]
sonatype-oss-releases
maven-central
sonatype-oss-snapshots
EOF
#############################################################
kafka-manager-dockerfile]# cat > Dockerfile<<EOF
FROM hseeberger/scala-sbt
ENV ZK_HOSTS=localhost:2181 \
KM_VERSION=2.0.0.2
RUN mkdir -p /tmp
COPY repositories ~/.sbt/
COPY ${KM_VERSION}.tar.gz /tmp
WORKDIR /tmp
RUN tar xf ${KM_VERSION}.tar.gz && \
mv CMAK-${KM_VERSION} kafka-manager-${KM_VERSION} && \
cd /tmp/kafka-manager-${KM_VERSION} && \
sbt clean dist && \
unzip -d / ./target/universal/kafka-manager-${KM_VERSION}.zip && \
rm -fr /tmp/${KM_VERSION} /tmp/kafka-manager-${KM_VERSION}
WORKDIR /kafka-manager-${KM_VERSION}
EXPOSE 9000
ENTRYPOINT ["./bin/kafka-manager","-Dconfig.file=conf/application.conf"]
EOF
# 此步骤尽量使用翻墙,否则会非常慢 甚至超时失败, 此处选择本地代理进行build
docker build --build-arg https_proxy=http://10.4.7.1:2346 -t harbor.odl.com/public/kafka-manager:v2.0.0.2 .
docker push harbor.odl.com/public/kafka-manager:v2.0.0.2
使用编译后的kafka-manager-2.0.0.2.zip的dockerfile文件
FROM hseeberger/scala-sbt
ENV ZK_HOSTS=localhost:2181 \
KM_VERSION=2.0.0.2
WORKDIR /
COPY kafka-manager-${KM_VERSION}.zip .
RUN unzip kafka-manager-${KM_VERSION}.zip && rm -fr kafka-manager-${KM_VERSION}.zip
WORKDIR /kafka-manager-${KM_VERSION}
EXPOSE 9000
ENTRYPOINT ["./bin/kafka-manager","-Dconfig.file=conf/application.conf"]
5.2. 资源配置清单
deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka-manager
namespace: infra
labels:
name: kafka-manager
spec:
replicas: 1
selector:
matchLabels:
app: kafka-manager
template:
metadata:
labels:
app: kafka-manager
spec:
containers:
- name: kafka-manager
image: harbor.odl.com/public/kafka-manager:v2.0.0.2
ports:
- containerPort: 9000
protocol: TCP
env:
- name: ZK_HOSTS
value: zk1.odl.com:2181
- name: APPLICATION_SECRET
value: letmein
service.yaml
apiVersion: v1
kind: Service
metadata:
name: kafka-manager
namespace: infra
spec:
ports:
- protocol: TCP
port: 9000
targetPort: 9000
selector:
app: kafka-manager
ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kafka-manager
namespace: infra
spec:
rules:
- host: kafka-manager.odl.com
http:
paths:
- path: /
backend:
serviceName: kafka-manager
servicePort: 9000
5.3. 应用配置清单
kubectl apply -f deployment
kubectl apply -f service.yaml
kubectl apply -f ingress.yaml
5.4. 配置DNS解析
[root@hdss7-11 ~]# cat /var/named/odl.com.zone
......
kafka-manager A 10.4.7.10
[root@hdss7-11 ~]# systemctl restart named
[root@hdss7-11 ~]# host kafka-manager.odl.com
kafka-manager.odl.com has address 10.4.7.10

6. 准备filebeat镜像
[root@hdss7-200 ~]# mkdir /opt/filebeat-dockerfile ; cd /opt/filebeat-dockerfile
[root@hdss7-200 filebeat-dockerfile]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.4.0-linux-x86_64.tar.gz -O filebeat-7.4.0.tar.gz
Dockerfile
FROM debian:jessie
ENV FILEBEAT_VERSION=7.4.0 \
FILEBEAT_SHA1=c63bb1e16f7f85f71568041c78f11b57de58d497ba733e398fa4b2d071270a86dbab19d5cb35da5d3579f35cb5b5f3c46e6e08cdf840afb7c347777aae5c4e11
COPY filebeat-${FILEBEAT_VERSION}.tar.gz /opt/
RUN set -x && \
cd /opt && \
echo "${FILEBEAT_SHA1} filebeat-${FILEBEAT_VERSION}.tar.gz" | sha512sum -c - && \
tar xzvf filebeat-${FILEBEAT_VERSION}.tar.gz && \
cd filebeat-* && \
cp filebeat /bin && \
cd /opt &&
rm -rf filebeat*
COPY entrypoint.sh /
ENTRYPOINT ["/entrypoint.sh"]
entrypoint.sh
如果不使用环境变量导入脚本变量,完全可以将配置文件以configmap形式存放,镜像启动方式更改为filebeat -c /etc/filebeat.yaml
#!/bin/bash
PROJ_NAME=${PROJ_NAME:-"no-define"} # project 名称,关系到topic
MULTILINE=${MULTILINE:-"^\d{2}"} # 多行匹配,根据日志格式来定
KAFKA_ADDR=${KAFKA_ADDR:-'"10.4.7.12:9092"'}
cat > /etc/filebeat.yaml <<EOF
filebeat.inputs:
- type: log
fields_under_root: true
fields:
topic: ${PROJ_NAME}
paths:
- /logm/*.log
scan_frequency: 120s
max_bytes: 10485760
multiline.pattern: '$MULTILINE'
multiline.negate: true
multiline.match: after
multiline.max_lines: 100
output.kafka:
hosts: [${KAFKA_ADDR}]
topic: log-%{[topic]}
version: 2.0.0
required_acks: 0
max_message_bytes: 10485760
EOF
set -xe
if [[ "$1" == "" ]]; then
exec filebeat -c /etc/filebeat.yaml
else
exec "$@"
fi
[root@hdss7-200 filebeat]# chmod +x entrypoint.sh
[root@hdss7-200 filebeat]# docker build . -t harbor.odl.com/public/filebeat:v7.4.0
[root@hdss7-200 filebeat]# docker push harbor.odl.com/public/filebeat:v7.4.0
- 报错
Exiting: error loading config file: config file (“/etc/filebeat.yaml”) can only be writable by the owner but the permissions are “-rwxrwxrwx” (to fix the permissions use: ‘chmod go-w /etc/filebeat.yaml’)
7. 准备logstash镜像
[root@hdss7-200 ~]# docker pull logstash:6.8.3
[root@hdss7-200 ~]# docker tag logstash:6.8.3 harbor.odl.com/public/logstash:v6.8.3
[root@hdss7-200 ~]# docker push harbor.odl.com/public/logstash:v6.8.3
7.1. 方法一: 在hdss7-200以容器启动
# 启动logstash,可以交付到k8s中,相关配置采用configmap方式挂载
# k8s在不同项目的名称空间中,可以创建不同的logstash,制定不同的索引
[root@hdss7-200 ~]# cat /etc/logstash/logstash-nginx.conf
input {
kafka {
bootstrap_servers => "10.4.7.12:9092"
client_id => "10.4.7.200"
consumer_threads => 4
group_id => "nginx"
topics_pattern => "log-nginx"
}
}
filter {
json {
source => "message"
}
}
output {
elasticsearch {
hosts => ["10.4.7.12:9200"]
index => "log-nginx-%{+YYYY.MM}"
}
}
[root@hdss7-200 ~]# docker run -d --name logstash-nginx \
-v /etc/logstash:/etc/logstash \
harbor.odl.com/public/logstash:v6.8.3 \
-e xpack.monitoring.elasticsearch.hosts="http://10.4.7.12:9200" \
-f /etc/logstash/logstash-nginx.conf
7.2. 方法二: 交付至k8s启动
[root@hdss7-200 ~]# vim logstash_nginx_configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-nginx-conf
namespace: default
data:
logstash-nginx.conf: |-
input {
kafka {
bootstrap_servers => "10.4.7.12:9092"
client_id => "10.4.7.200"
consumer_threads => 4
group_id => "nginx"
topics_pattern => "log-nginx"
}
}
filter {
json {
source => "message"
}
}
output {
elasticsearch {
hosts => ["10.4.7.12:9200"]
index => "log-nginx-%{+YYYY.MM}"
}
}
7.3. 启动logstash (方法二)
logstash_deployment.yaml 环境变量 xpack.monitoring.elasticsearch.hosts的定义避免logstash日志报错 http://elasticsearch:9200/][Manticore::ResolutionFailure] elasticsearch: Name or service not known”
[root@hdss7-200 ~]# vim logstash_deployment.yaml
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: logstash-nginx
namespace: default
spec:
replicas: 1
template:
metadata:
labels:
run: logstash-nginx
spec:
containers:
- name: logstash-nginx
image: harbor.odl.com/public/logstash:v6.8.3
env:
- name: xpack.monitoring.elasticsearch.hosts
value: "http://10.4.7.12:9200"
volumeMounts:
- mountPath: /etc/localtime
name: vol-localtime
readOnly: true
- name: logstash-nginx-conf
mountPath: /etc/logstash
volumes:
- name: vol-localtime
hostPath:
path: /etc/localtime
- name: logstash-nginx-conf
configMap:
name: logstash-nginx-conf
kubectl apply -f logstash_deployment.yaml
10. 准备kibana
[root@hdss7-200 ~]# docker pull kibana:6.8.3
[root@hdss7-200 ~]# docker tag kibana:6.8.3 harbor.odl.com/public/kibana:v6.8.3
[root@hdss7-200 ~]# docker push harbor.odl.com/public/kibana:v6.8.3
10.1. 准备资源配置清单
deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: infra
labels:
name: kibana
spec:
replicas: 1
selector:
matchLabels:
name: kibana
template:
metadata:
labels:
app: kibana
name: kibana
spec:
containers:
- name: kibana
image: harbor.odl.com/public/kibana:v6.8.3
ports:
- containerPort: 5601
protocol: TCP
env:
- name: ELASTICSEARCH_URL
value: http://10.4.7.12:9200
service.yaml
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: infra
spec:
ports:
- protocol: TCP
port: 80
targetPort: 5601
selector:
app: kibana
ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kibana
namespace: infra
spec:
rules:
- host: kibana.odl.com
http:
paths:
- path: /
backend:
serviceName: kibana
servicePort: 80
10.2. 应用配置清单
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.odl.com/devops/ELK/kibana/deployment.yaml
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.odl.com/devops/ELK/kibana/ingress.yaml
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.odl.com/devops/ELK/kibana/service.yaml
[root@hdss7-11 ~]# vim /var/named/odl.com.zone
......
kibana A 10.4.7.10
[root@hdss7-11 ~]# systemctl restart named
- 报错
PollError Request Timeout after 30000ms
elasticsearch内存不足,IO读写阻塞。
11. 准备nginx资源并启动
nginx.conf # 此处为原镜像的nginx.conf配置文件修改
user abc;
worker_processes 4;
pid /run/nginx.pid;
include /etc/nginx/modules/*.conf;
events {
worker_connections 768;
# multi_accept on;
}
http {
keepalive_timeout 65;
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for" '
'"$upstream_addr" "$upstream_status" "$upstream_response_time" "$request_time"'
'"$hostname"';
error_log /config/log/nginx/error.log;
gzip on;
server {
listen 80 default_server;
root /config/www;
index index.html index.htm index.php;
server_name _;
if ($time_iso8601 ~ "^(\d{4})-(\d{2})-(\d{2})") {
set $year $1;
set $month $2;
set $day $3;
}
access_log /config/log/nginx/access-$year$month$day.log main;
client_max_body_size 0;
location / {
try_files $uri $uri/ /index.html /index.php?$args =404;
}
}
}
daemon off;
nginx-pod.yaml 将配置文件都挂载至容器中
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
spec:
template:
metadata:
labels:
name: nginx-svc
namespace: default
spec:
selector:
run: nginx-pod
ports:
- protocol: TCP
port: 8080
targetPort: 80
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: nginx-svc
spec:
replicas: 2
template:
metadata:
labels:
run: nginx-pod
annotations:
blackbox_port: "80"
blackbox_scheme: tcp
# blackbox_path: /hello?name=health
spec:
containers:
- name: nginx-svc
image: harbor.odl.com/public/nginx:v1.18.0
ports:
- containerPort: 80
volumeMounts:
- mountPath: /etc/localtime
name: vol-localtime
readOnly: true
- name: nginx-log
mountPath: /config/log/nginx/
- name: nginx-conf
mountPath: /config/nginx/
- name: filebeat
image: harbor.odl.com/public/filebeat:v7.4.0
env:
- name: PROJ_NAME
value: nginx
volumeMounts:
- name: nginx-log
mountPath: /logm
- name: vol-localtime
mountPath: /etc/localtime
readOnly: true
volumes:
- name: vol-localtime
hostPath:
path: /etc/localtime
- name: nginx-log
emptyDir: {}
- name: nginx-conf
configMap:
name: nginx-conf
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ngx-svc
annotations:
kubernetes.io/ingress.class: traefik
spec:
rules:
- host: nginx.odl.com
http:
paths:
- path: /
backend:
serviceName: nginx-svc
servicePort: 8080
# 创建以nginx.conf配置文件的configmap资源 (如果要更新配置需要删除资源再创建, 无法使用apply)
kubectl create configmap nginx-conf --from-file=./nginx.conf
# 创建nginx资源
kubectl apply -f nginx-pod.yaml
配置DNS解析
[root@hdss7-11 ~]# cat /var/named/odl.com.zone
$ORIGIN odl.com.
$TTL 600 ; 10 minutes
@ IN SOA dns.odl.com. dnsadmin.odl.com. (
2020091717 ; serial
10800 ; refresh (3 hours)
900 ; retry (15 minutes)
604800 ; expire (1 week)
86400 ; minimum (1 day)
)
NS dns.odl.com.
$TTL 60 ; 1 minute
dns A 10.4.7.11
harbor A 10.4.7.200
k8s-yaml A 10.4.7.200
traefik A 10.4.7.10
dashboard A 10.4.7.10
nginx A 10.4.7.10
[root@hdss7-11 ~]# systemctl restart named
# 访问nginx
curl nginx.odl.com
12. 查看kibana相关数据信息



模拟访问nginx, 查看kibana是否有数据生成

13. 思考
保持当前架构,将nginx的日志目录持久化到本地会发生什么?
持久化本地,那么多个nginx pod同时共享一个日志, 当访问产生日志后,pod filebeat都会获取到日志,从而推送N条重复数据,这就有问题了!
那么 filebeat就需要单独以pod容器生成,将nginx本地持久化的日志目录挂载到里面

若有收获,就点个赞吧
0 人点赞
