一、实验背景及实验目的
目前越来越多的现实世界的应用要求智能体选择动作的空间为连续动作空间,并且随着任务复杂性的提升,选择动作的维度已不再局限于一维动作空间。因此,如何进行动作的选择,使得智能体能够在持续复杂的动作空间中选出最优动作,从而取到最大Q值,是本文需要讨论的主要问题。
在传统的强化学习(RL)算法当中,动作的选择通常是使用随机策略 ϵ - greedy 策略或是高斯分布来增加随机噪声,增大智能体的探索空间,避免收敛到局部最优。相较于上述算法,蒙特卡洛树搜索算法中利用上限置信区间算法(UCB)进行动作的选择,可以更多的利用之前已获取的信息,能够处理更加复杂的任务。
针对上述问题,并且为了加速模型收敛,提高算法性能,探究MCTS在探索和利用上的表现,本文对MCTS中的UCB算法的改进算法进行了调研,并且针对各种算法进行了对比实验。
二、实验步骤
- UCB算法初期调研:UCB算法调研 - 飞书云文档 (feishu.cn)
- UCB与RL结合的几种变体算法的论文解读:
1) MUCT[6]: 【论文muzero】Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model · 语雀 (yuque.com)
2) KB-Tree[4]:kb-tree实验报告 - 飞书云文档 (feishu.cn)
3) KR-DL-UCB[5]:【论文 KR-DL-UCT】Deep Reinforcement Learning in Continuous Action Spaces: a Case Study in the Game of Simulated Curling · 语雀 (yuque.com)
4) Reg_Policy[3]: Monte-Carlo tree search as regularized policy optimization论文解读 - 飞书云文档 (feishu.cn)
- 前期实验知识积累。具体内容在5.4。
- 进行代码开发工作。首先利用的环境为muzero_pendulum,可在本地进行训练,动作空间为1维动作空间。该环境代码跑通完全后,可将代码的动作空间扩展到多维,本文利用的多维动作空间为muzero_parking环境,在集群上进行训练任务。
- 进行算法对比实验
1) 将四种算法分别跑3组实验。选出每种算法的最优实验结果。
2) 将四种算法的最优实验结果进行对比。
3) 做KB-Tree算法内部参数c自对比实验。范围为0.1~0.8,间隔为0.1参考公式如下: 
4) 做KB-Tree算法内部参数lambda自对比实验。范围为0.6~0.9,间隔为0.1。参考公式如下: 
三、实验结果
实验结果对照2.5中所做实验。
实验一: |
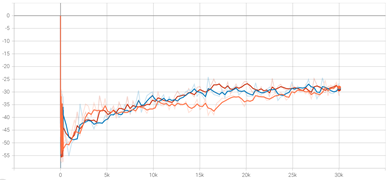
(a)MUCT |
(b)KB-Tree | | —- | —- | |
(c)KR-DL-UCB |
(d)Reg_Policy |实验二:
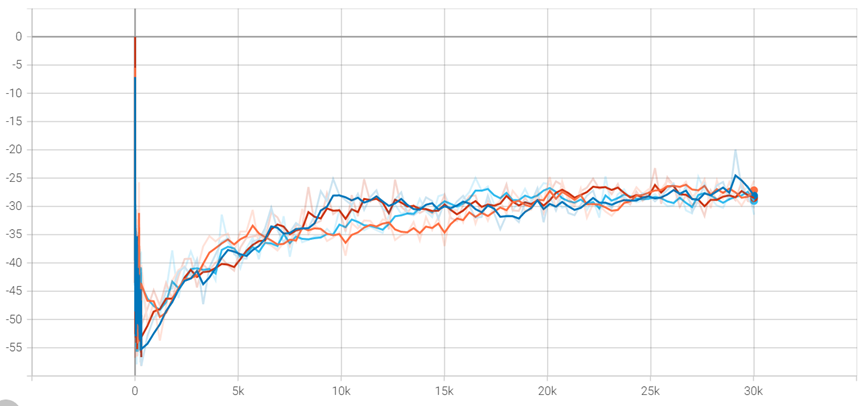
红色:Reg_Policy 蓝色:KB-Tree 橙色:KR-DL-UCB 浅蓝色:MUCB
- 实验三:
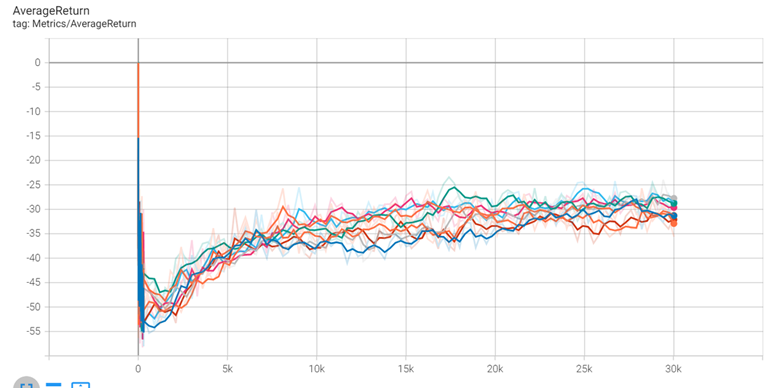
- 实验四:

四、实验结论
- 从实验一中可看出,每种算法的实验结果大约会有数值为7左右的偏差。其中MUCB算法在实验训练中期有较大的偏差,说明MUCB算法收敛速度较慢,所需训练时间较长。但最后结果偏差很小,因此算法的探索较为充分。KB-Tree算法在实验训练前期会有较大的偏差,而在后期趋于稳定。KR-DL-UCB算法在实验训练后期会有较大的偏差,并且在实验结束的返回值上差值较大,说明随机环境对该方法的影响较大。Reg_Policy算法在实验训练前期的差值相对于后期较大,但在最后趋于相同点,说明该算法较大概率能够得到最优策略。总体来看,Reg_Policy算法差值最小,稳定度最高,而KB-Tree次之。
- 实验二中红色曲线为Reg_Policy算法,而蓝色曲线为KB-Tree算法,可以看出这两种算法相较于橙色曲线KR-DL-UCB算法,浅蓝色曲线MUCB算法来讲能够较快收敛到最优策略,节省模型训练时间。而KB-Tree算法从图像上看相较于Reg_Policy来讲在训练次数为10k时表现更好一些,说明核回归方法更能把握数据内部信息,数据信息利用充分。而对于最终收敛效果来讲,四种算法的收敛结果相差不大。说明四种算法在空间探索方面较为充分,都能够得到最优策略,而不会收敛到局部最优。
- 而从实验三、四中可以看到参数c、lambda的值改变对结果影响不大,且每次实验也会存在随机性的影响,因此,c=0.3,lambda=0.7可应用在KB-Tree算法上作为该算法的最优参数设置。
经过上述实验,可以看到KB-Tree算法和Reg_Policy算法虽利用的方法不同,分别利用核回归方法和正则化优化,但都能较快收敛到最优结果,节省模型训练时间,大约在训练次数为15k时,已经可以得到最优策略,使模型的迭代周期变短。
五、实验条件
实验硬件设备:
联想ThinkPad笔记本一台,可用于跑深度学习的集群平台:3090和2080。相关书籍及参考文献若干。
- 实验软件设备:
Ubuntu 20.04操作系统,地平线开源代码框架ALF,分布式版本控制系统Git。
- 实验知识储备:
- 对深度学习有一定的了解和知识积累。能够利用深度学习进行一些神经网络模型的搭建,并理解其中的原理和目的。
- PyTorch深度学习框架的掌握。能够利用基于Python语言的PyTorch进行代码的开发工作,并能够理解他人所书写的基于Python语言的代码。
- Linux环境下的开发工作的理解。基本掌握了Linux环境下的开发方式。
实验知识积累:
- 双系统的配置和操作[1]。通过学习在Windows10系统下配置Ubuntu 20.04双系统,能够在本机上进行代码调试工作,提交代码开发效率。
- 地平线开源代码框架ALF的学习和理解。本文的代码搭建依靠地平线信息技术有限公司所提供的开源代码框架ALF,在此基础上进行代码开发工作。需要理解ALF的总体架构,参数意义,场景目标,结果指标等,进而在指定的代码块进行论文的复现工作。
- Git是一种分布式版本控制系统[2],可用于团队间的代码开发。通过对Git的学习,可提高团队间代码开发的效率。
- 集群概念学习及集群配置。集群可部署多台服务器协同完成一项任务,效率更高,速度更快。通过对集群的使用,使得本实验的完整训练周期约为3天/次。
- 理解高斯核函数,核密度回归和核回归。利用核函数建立非线性回归模型,核估计使用高斯核函数,能够计算两点之间的相似度,更为有效的利用已知的策略分布估计和Q值估计信息来进行动作选择。
- 了解高斯核函数的PyTorch实现,以及PyTorch对于多维矩阵的处理。
六、未来计划
调研最新参考文献,研究其他UCT变体算法,探究其余UCT变体算法对本环境的优化提升效果。
- 尝试结合目前实验结果较好的两种算法:KB-Tree和Reg_Policy算法,探究是否能够带来更优的结果。
参考文献:
[1]双系统安装。https://blog.csdn.net/weixin_42128001/article/details/123659721?spm=1001.2014.3001.5501
[2]Git学习。https://blog.csdn.net/weixin_42128001/article/details/124709872?spm=1001.2014.3001.5502
[3] Grill J B , F Altché, Tang Y , et al. Monte-Carlo Tree Search as Regularized Policy Optimization[J]. 2020.
[4] Lei L, Luo R, Zheng R, et al. KB-Tree: Learnable and Continuous Monte-Carlo Tree Search for Autonomous Driving Planning[C]//2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 4493-4500.
[5] Lee K, Kim S A, Choi J, et al. Deep reinforcement learning in continuous action spaces: a case study in the game of simulated curling[C]//International conference on machine learning. PMLR, 2018: 2937-2946.
[6] Schrittwieser J, Antonoglou I, Hubert T, et al. Mastering atari, go, chess and shogi by planning with a learned model[J]. Nature, 2020, 588(7839): 604-609.

若有收获,就点个赞吧
0 人点赞
