摘要:KB-TREE是一种可用于可持续和可学习的MCTS方法,它可以被应用于自动驾驶的运动规划中。它的创新型在于提出了一种KR-AUCB的方法用于UCB算法中,去提升探索和利用的表现。并且还在MCTS选择(selection)过程中通过适应性贝叶斯优化,优化了持续空间中的取样过程。此外,论文中还使用了自定义GNN作为特征提取来提升学习的表现。
Introduction:自动驾驶中,运动规划非常重要。而传统的关于运动规划的问题中,分为基于抽样的规划和基于优化的规划。基于抽样的规划将动作离散化,这样可能会导致次优的结果。而基于优化的规划在持续空间中会有效率的问题。并且传统的规划无法很好的处理交互场景。近年来,使用神经网络生成端到端的运动轨迹是不可解释的,而且也会有安全问题。而之前的alphaGo将MCTS与RL结合,提出了KR-DL-UCT,具有学习性和可解释性,但是在增加节点时生成的曲线会有逐步加宽的问题,因此还需要手动设计阈值。因此为了解决上述问题,我们提出了KB-TREE,这里我们应用了KR-AUCB,BO,GNN。我们用BO替代曲线逐步加宽的问题,用于扩张(expand)过程,无需手动设计阈值,并且可利用更多的信息。KR-AUCB用于selection过程,去平衡探索和利用。GNN用于特征提取,混合密度网络(MDN)作为策略模型。贡献是:1.首个将可学习和可持续的MCTS应用于自动驾驶的运动规划场景。2.提出了KR-AUCB和BO。3.进行了大量的实验,baseline有PPO和KR-DL-UCT。
RELATED WORK:
1.MCTS&RL AlphaGo利用专家经验达到更好的效果。AlphaGo Zero的策略和值网络使用了统一的结构,取得了更加显著的效果。MuZero将一个学习模型应用于训练过程中与动态环境进行交互,达到更好的效果。
2。连续蒙特卡洛树搜索 现有的处理连续动作的MCTS方法主要有三种:Progressive Widening:它维护一个有限的可用节点列表来搜索,并根据节点的访问次数逐步将子节点添加到列表中;层次划分:这个方法考虑树搜索空间中的每个节点均可用于预算黑盒优化算法,并且基于分层优化的方法可用于找到近似全局最优值;贝叶斯优化(Bayesian Optimization):使用贝叶斯优化用于每个分支步骤中的动作选择。
PRELIMINARIES:
A.RL:MDP马尔可夫决策过程。B.MCTS:MCTS中经常使用UCB算法,在树中扩展为UCT算法。 C。高斯混合模型GMM:
C。高斯混合模型GMM:
METHODOLOGY:
A。Problem F ormulation
输入:地理位置,移动轨迹,道路感知信息等。
输出:横向速度[-2,2](m/s)和纵向加速度[-23,23](度)。
reward:分为稀疏reward和稠密reward。
稠密reward: 由当前点和目标点的欧式距离,角距离,角度决定。
由当前点和目标点的欧式距离,角距离,角度决定。
稀疏reward: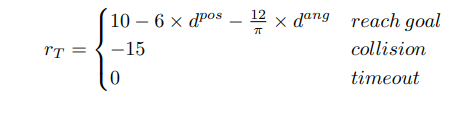
B。Feature Representation by Graph Neural Networks
(1)特征表示有:汽车形状,汽车历史轨迹,道路场景信息。对于汽车的形状,我们用向量来连接四个角落,对于汽车历史轨迹,我们用时间序列向量进行编码,对于道路信息,我们将它分段,然后建立为图。(2)网络结构:每个node首先通过一个全连接图卷积层,然后使用池化层去集成不同节点之间的信息,然后用多头注意力用于全局节点,最后再通过MLP得到随机策略和值估计。
C. Mixture Density Network Training
请注意,GMM引入了多模型分布,直观地可以更好地模拟自动驾驶环境下的动作分布。策略值网络目的在于最大化动作概率到树搜概率的相似性,最小化估计v和模拟v的误差。策略值网络目的在于最大化动作概率到树搜概率的相似性,最小化估计v和模拟v的误差。
D. Monte-Carlo Tree Search in Continuous Action Spaces
KB-TREE的关键是使用KR-AUCB确定节点的选择,以及使用贝叶斯优化于扩张。它最初偏好没有选择过的动作,然后慢慢的选择具有高先验概率或者低访问次数的动作,最后偏好一些具有更好value值的动作。
KR-AUCB:
(1)
(2)
(3,4)
(5)
公式如上。E(a),W(a)应用核回归中的高斯概率分布。而P(a)是渐进函数,会根据训练的次数越来越偏好利用先验概率。
Bayesian Optimization :
当当前的节点node没有孩子时,可以用策略随机取样一些动作用于扩张。或者,我们也可以使用贝叶斯优化去选择候选节点,而期望值的先验概率可以被建模为高斯过程。
d(a)是为了使选择的动作a与其余动作的相似度最小。
首先通过贝叶斯优化去选择一个动作a,放入被访问过的集合A中,然后用KR-AUCB去选择一个动作a,如果a不是a,就从A中移除,然后用a去进行扩张。
EXPERIMENTS:
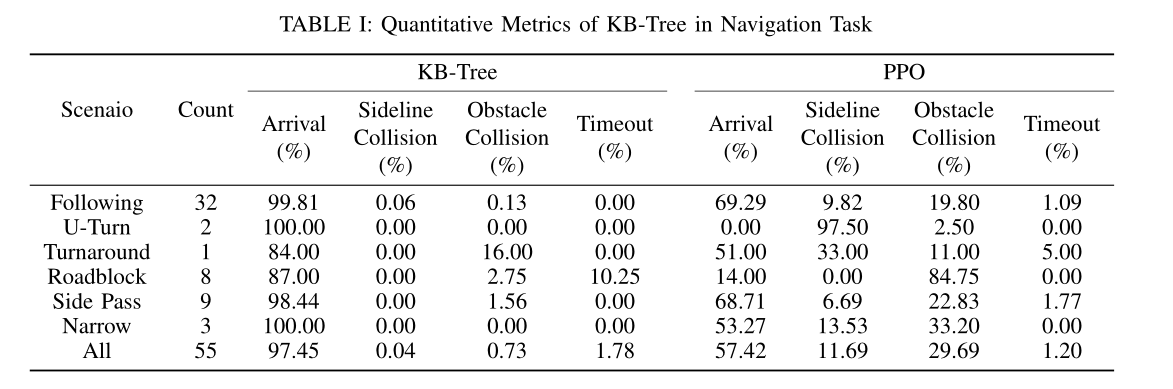
实验比较:与离散空间,与KR-DL-UCT,与PPO。

编写代码:
def KB_TREE_KR_AUCB(self,trees,parents):
kr_ucb_exploration = 0.3
import torch
from torch.distributions import Normal
prior = trees.prior[parents]
value_score, child_visit_count = self._value_score(trees, parents)
value_score[prior == 0] = -MAXIMUM_FLOAT_VALUE
# parent_visit_count = trees.visit_count[parents].unsqueeze(-1)
selected_action = trees.action[parents]#(parent,action_num,action_dim)
normal=Normal(selected_action.clone().detach(),1)
sibling_child=selected_action.squeeze(-1).unsqueeze(1).expand(selected_action.shape[0],selected_action.shape[1],selected_action.shape[1])
gaussian_probability=normal.log_prob(sibling_child).exp()
expended_value_score=value_score.unsqueeze(-1).expand(value_score.shape[0],value_score.shape[1],value_score.shape[1])
expended_child_visit_count=child_visit_count.unsqueeze(-1).expand(child_visit_count.shape[0],child_visit_count.shape[1],child_visit_count.shape[1])
kerner_regression = torch.sum(gaussian_probability expended_child_visit_count,dim=-2)
kernel_density_estimation = torch.sum(gaussian_probability expended_value_score * expended_child_visit_count,dim=-2) / kerner_regression
sum_kerner_regression=torch.sum(kerner_regression,dim=-1)
sum_kerner_regression=sum_kerner_regression.unsqueeze(-1).expand(kerner_regression.shape[0],kerner_regression.shape[1])
kr_uct = torch.sqrt(sum_kerner_regression) / kerner_regression#(parent_node,action_node)<br /> #<br /> kr_uct = kernel_density_estimation + kr_ucb_exploration * self.KB_Tree_Pasym(prior)*kr_uctreturn kr_uct<br />def KB_Tree_Pasym(self,prior):<br /> Plambda=self.KB_Tree_get_Plambda()<br /> uniform=np.ones_like(prior)<br /> uniform=uniform/uniform.shape[1]<br /> Pasym=Plambda*prior+(1-Plambda)*uniform<br /> return Pasym<br />def KB_Tree_get_Plambda(self):<br /> progress = Trainer.progress()<br /> return min(progress,0.7)
KR-DL-UCB:
def KR_UCT(self,trees,parents):
# import time
# start=time.clock()
import torch
from torch.distributions import Normal
kr_uct_c = 0.1
prior = trees.prior[parents]
value_score, child_visit_count = self._value_score(trees, parents)
value_score[prior == 0] = -MAXIMUM_FLOAT_VALUE
parent_visit_count = trees.visit_count[parents].unsqueeze(-1)
selected_action = trees.action[parents]#(parent,action_num,action_dim)
normal=Normal(selected_action.clone().detach(),1)
sibling_child=selected_action.expand(selected_action.shape[0],selected_action.shape[1],selected_action.shape[1])
gaussian_probability=normal.log_prob(sibling_child).exp()
expended_value_score=value_score.unsqueeze(-1).expand(value_score.shape[0],value_score.shape[1],value_score.shape[1])
expended_child_visit_count=child_visit_count.unsqueeze(-1).expand(child_visit_count.shape[0],child_visit_count.shape[1],child_visit_count.shape[1])
kerner_regression = torch.sum(gaussian_probability expended_child_visit_count,dim=-1)
kernel_density_estimation = torch.sum(gaussian_probability expended_value_score * expended_child_visit_count,dim=-1) / kerner_regression
sum_kerner_regression=torch.sum(kerner_regression,dim=-1)
sum_kerner_regression=sum_kerner_regression.unsqueeze(-1).expand(kerner_regression.shape[0],kerner_regression.shape[1])
kr_uct = torch.sqrt(torch.log1p(sum_kerner_regression) / kerner_regression)<br /> #<br /> kr_uct=kernel_density_estimation+kr_uct_c*kr_uct<br /> return kr_uct

若有收获,就点个赞吧
0 人点赞
