参考学习资料:
https://blog.51cto.com/u_15072910/3977350
https://cs.stanford.edu/people/karpathy/reinforcejs/gridworld_dp.html
摘要:
本文提出 sampled muzero是对muzero算法的扩展,通过规划取样动作能够在任意复杂的动作空间中学习。
introduction:
现实世界的很多问题都设计到了复杂的动作空间,因此RL算法必须能适应复杂的动作空间才能在现实世界中应用。
而近年来深度学习和强化学习的结合在分布式动作空间中的表现超过了人类,如围棋。
虽然基于模型的muzero方法使应用于现实生后中更近一步,但只适用于动作空间相对较小的领域,小到可以被基于树的搜索完全枚举。
因此,基于抽样的方法为算法应用于大型复杂空间中提供了可能。抽样要在整个行动空间(而不仅仅是样本)正确地改进或评估政策,必须了解抽样程序如何与政策改进和政策评估相互作用。
本文提出的算法为Sampled MuZero,它是基于muzero算法,同时为了证明该算法的通用性,本文在两个持续控制的基准上做了验证: the DeepMind Control Suite 和 Real-World RL Suite,并且也在大的分布式空间:围棋上进行了验证。
Related work:
之前在复杂持续空间中的强化学习研究集中在无模型的方法中,如ddpg中的Q值可微;D4PG使用分布式价值函数和分布式训练设置;trpo使用KL约束,ppo使用KL散度或者clip操作。
高维空间中基于模型的方法只考虑对策略进行优化而不是对模型进行优化。与本文中方法相似的一个方法,同样为基于策略进行采样,但是这个方法中是基于KL正则化目标对策略进行优化,而不是对MCTS中的策略进行优化。
稀疏取样算法在高维状态空间中是一个有效的算法,其思想是对每个状态采样K个可能的状态转移,这样这些样例可以构造出一个小的搜索树,并且我们知道,采样的方法可以解决一些情况中的维度灾难问题。然而这种方法需要枚举每个状态的所有可能的动作,并不适用于大的动作空间。而本文的创新点在于可适用于大的动作空间,并且利用确定性转移模型。
之前的工作希望能将 AlphaZero和MuZero进行结合,用于持续动作空间。但这种只在低维空间中可用,高维中表现不好。
文中所描述的因式分解策略在各个领域中都可以有良好的表现,它通过使用单独的分类分布表示每个动作的维度,它有效地避免了简单离散化方案所面临的动作数量的指数爆炸。
background:
我们提出的框架将主要关注:如何使用改进的局部策略来学习全局策略,如何使用它来行动,如何对改进后的规划政策进行明确的局部政策评估,这些步骤如何相互作用。
策略迭代是估计接下来策略的策略提升。
衡量两者效率的一个方向是,通过使用一个模型,从当前状态评估几个可能的行动,甚至几个可能的未来轨迹,而不是从已执行的轨迹中提取信息。
Muzero算法可以看作结合了策略评估和策略提升的过程。
Sample-based Policy Iteration:
这里我们定义一个策略Π和一个提升的策略IΠ,可以知道 。当动作空间很大的时候,我们只能用一部分动作子集来做策略提升。但是目前没有明确的算法说明这个通过局部取样动作提升的策略较好。
。当动作空间很大的时候,我们只能用一部分动作子集来做策略提升。但是目前没有明确的算法说明这个通过局部取样动作提升的策略较好。
我们提出了一个框架,该框架依赖于将两个操作写为对完全改进的策略 Iπ 的期望,并使用我们必须估计的样本来估计这些期望。
4.1 . Operator view of Policy Improvement
这里我们将策略提升映射到两个算子中。一个是将策略提升算子I映射为所有策略中能带来更大收益的策略;另一个是投影算符P,这是一种在真实策略中找到策略提升的最优近似。
4.2. Action-Independent Policy Improvement Operator 
4 .3. Sample-Based Action-Independent Policy Improvement Operator 
4.4. Computing an expectation with respect to Iπ 
这里我们定义一个随机变量X,有如上的工时,因此可以说这个服从正态分布。
因此我们推论,基于采样的策略提升算子会收敛于真正的策略提升算子。
Sampled MuZero
我们将采样过程应用于muzero中,成为sampled muzero。这里可以被理解为,muzero内部通过mcts结合了策略迭代过程,外部是整个和环境的交互过程。
5.1. Inner Policy Evaluation and Improvement 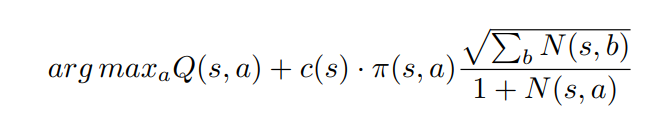
muzero的策略评估是n步迭代的返回值,策略提升是通过PUCT公式的迭代最大化得到下一个用于评估和扩张的节点值。
一种对muzero最直接的采样过程就是不修改PUCT公式,直接通过PUCT中的策略函数来进行动作采样。用他的访问概率分布f来构造 ,但是这样会导致不稳固的结果。
,但是这样会导致不稳固的结果。
然后,我们用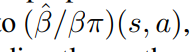 中的
中的 来替换PUCT中的Π(S,A)
来替换PUCT中的Π(S,A)
PUCT中用Πbeta代替Π。
5.2. Outer Policy Improvement  访问概率分布。
访问概率分布。
5.3. Outer Policy Evaluation
外部策略评估步骤和之前一样,都是基于采样的提升策略采样的动作,得到n步的返回值来评估。
5.4. Search Tree Node Expansion
在节点扩张时,muzero是用Π来采样N=动作空间个动作,而在sampled muzero中,我们会通过beta分布来采样K个动作。
5.5. Sampling distribution β
我们使用 在这里我们也给beta和Π加入了噪声。
在这里我们也给beta和Π加入了噪声。
6. Experiments
如何看采样的是否充分:可以与在全部空间中进行搜索进行对比,查看效果。
附录:
在搜索过程中PUCT公式如下:
使用之前的正则化优化方法的话,最优策略可以写成如下形式:其中的beta可以是均匀分布也可以直接就是策略Π,

若有收获,就点个赞吧
0 人点赞
