摘要:目前最先进的MCTS算法,alphazero,仍然依赖于仅部分理解的手工启发式算法。alphazero的搜索启发式,近似于特定正则化优化问题的解。本文提出了alphazero的一个变体,它使用这个策略优化问题的精确解决方案,可在多个领域的性能优于原始方案。
Introduction:MCTS选择动作的灵感来自赌博机。本文主要的贡献来自于结合MCTS算法,使用alphazero算法,以及一种最新的无模型的策略优化算法。并且,我们还表明alphazero的搜索动作的经验访问概率分布,近似于正则化策略优化目标。因此我们的第二个贡献是对于alphazero算法的改进,使得性能有很大的提升,尤其是在alphazero被观察到失败的情况下,如在每个搜索模拟的预算很低的情况。
Background:
2.1alphazero家族在选择动作的过程中结合了UCT算法。
2.2 策略优化旨在找到一个全局最优策略,一般使用迭代更新的方式进行优化。每次迭代更新当前策略都是解决公式中的局部最大问题。它的过程就是最大化Q值,可能会使用正则化项。正则化项可以使策略更加稳定,并且可以加速收敛,例如TRPO中使用KL散度被发现可以加速收敛。
MCTS as regularized policy optimization:
3.1 符号表示
UCT算法与MCTS结合就是:
经验访问分布可以写成:
定义了一个乘数算子为:
因此(1)可以写成如下形式。简化形式为(6)

3.2 一个相关的正则化策略优化问题 解的表示。
解的表示。
3.3 AlphaZero作为策略优化
用两个命题证明alphazero的搜索策略遵循准确的正则化策略优化问题。命题1表示alphazero的策略遵循凹函数的梯度。
搜索算法通过树搜索最终影响的唯一东西是访问计数分布。
3.4 通用MCTS算法的推广 用这个策略去替换(1)中的策略,得到本文中的最优动作选择策略。
用这个策略去替换(1)中的策略,得到本文中的最优动作选择策略。
Algorithmic benefits:
在低模拟预算Nsim下有几点缺点:1.当一个有更高value值的叶节点被发现时,在Π尖中需要许多额外的模拟信息,而Π横直接通过Q值计算。2,在Nsim较低的时候,Π尖具有有限的表达能力,这样可能会到一个次优的策略。3.对于某些需要大量模拟预算采样一次的操作来说,这可能会产生问题。 上述缺点导致MCTS对模拟预算Nsim具有高度敏感性,
4.2 对alphazero提出的改进:
1.act 取样动作通过a~Π横()。
2.search 根据Π横进行随机动作取样。
3.learn 
4.3AlphaZero和无模型策略优化之间的结合:
我们可以将LEARN理解为使用树搜索来估计Qπ的策略优化算法。
Experiments:
baseline为muzero。
附录:
A:alphazero的搜索过程
选择,扩张,回传。 Q值在back-up过程中做了正规化处理。
Q值在back-up过程中做了正规化处理。
B:
超参数、网络结构设计、优化器。使用m个分开的Q表。
C:
PPO的性能有时候会很好。
DPX ALF中的探索策略:


这里的 并且
并且 。
。
为了使等式解可解,我们对参数进行了再参数化。
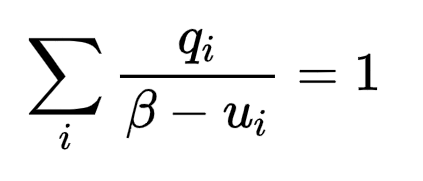
我们使用newton(优化算法)的方法进行更新:
https://blog.csdn.net/a493823882/article/details/81416213
https://www.zhihu.com/question/376091644
https://blog.csdn.net/google19890102/article/details/41087931
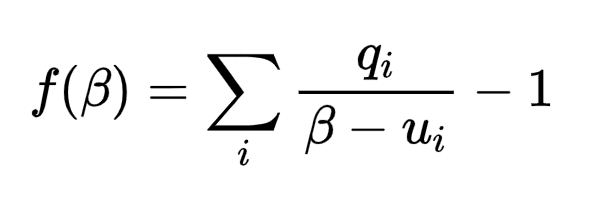
使得:
论文概括:作者发现正则化可以加速收敛,就像TRPO中应用KL散度可以加速收敛。而策略算法优化的目标在于找出最大的Q值,因此,作者希望使用 该公式,通过RL中给出的Q值和策略概率分布值来找到一个策略近似化最优策略从而最大化Q值。然后作者通过公式证明,该策略可以近似得到最大化的Q值。
该公式,通过RL中给出的Q值和策略概率分布值来找到一个策略近似化最优策略从而最大化Q值。然后作者通过公式证明,该策略可以近似得到最大化的Q值。
而代码中通过再参数化和牛顿法优化,可以得到这个最优策略。牛顿法是算法优化的方法之一,它的最突出的优点是收敛速度快,具有局部二阶收敛性。

若有收获,就点个赞吧
0 人点赞
