选择框架:Pytorch
yolo版本:yolov5-6.0
环境:win11+pycharm2019+anaconda
github下载
文件架构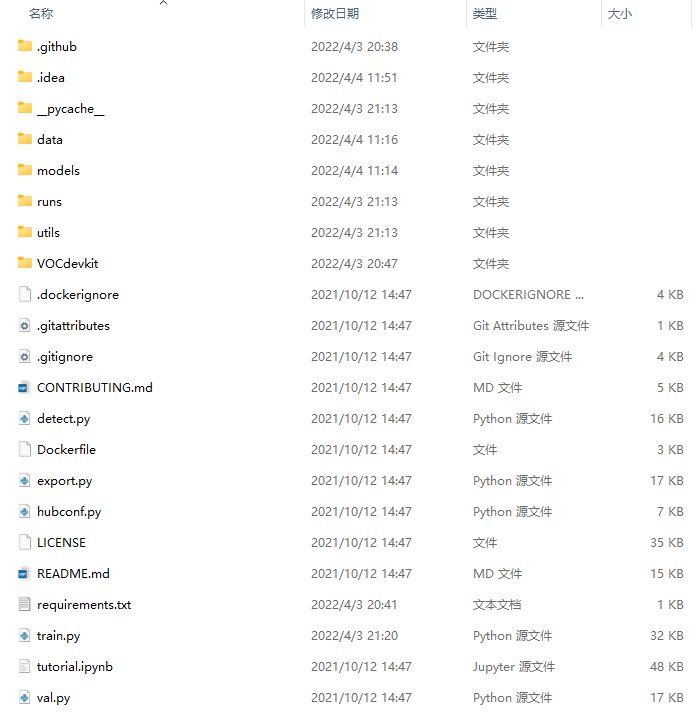
1、xml文件转换
由于数据集标出来的格式为VOC2007
用脚本转换:la.py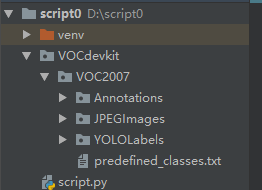
需要放成如图示的架构,修改:
#根据你要修改的来进行,一个是类别,一个是训练集和数据集的比例(ratio)classes = ['crack']TRAIN_RATIO = 80
import xml.etree.ElementTree as ETimport pickleimport osfrom os import listdir, getcwdfrom os.path import joinimport randomfrom shutil import copyfile#修改你要训练的类classes = ['crack']# classes=["ball"]TRAIN_RATIO = 80def clear_hidden_files(path):dir_list = os.listdir(path)for i in dir_list:abspath = os.path.join(os.path.abspath(path), i)if os.path.isfile(abspath):if i.startswith("._"):os.remove(abspath)else:clear_hidden_files(abspath)def convert(size, box):dw = 1. / size[0]dh = 1. / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)def convert_annotation(image_id):in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' % image_id)out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' % image_id, 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')in_file.close()out_file.close()wd = os.getcwd()wd = os.getcwd()data_base_dir = os.path.join(wd, "VOCdevkit/")if not os.path.isdir(data_base_dir):os.mkdir(data_base_dir)work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")if not os.path.isdir(work_sapce_dir):os.mkdir(work_sapce_dir)annotation_dir = os.path.join(work_sapce_dir, "Annotations/")if not os.path.isdir(annotation_dir):os.mkdir(annotation_dir)clear_hidden_files(annotation_dir)image_dir = os.path.join(work_sapce_dir, "JPEGImages/")if not os.path.isdir(image_dir):os.mkdir(image_dir)clear_hidden_files(image_dir)yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")if not os.path.isdir(yolo_labels_dir):os.mkdir(yolo_labels_dir)clear_hidden_files(yolo_labels_dir)yolov5_images_dir = os.path.join(data_base_dir, "images/")if not os.path.isdir(yolov5_images_dir):os.mkdir(yolov5_images_dir)clear_hidden_files(yolov5_images_dir)yolov5_labels_dir = os.path.join(data_base_dir, "labels/")if not os.path.isdir(yolov5_labels_dir):os.mkdir(yolov5_labels_dir)clear_hidden_files(yolov5_labels_dir)yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")if not os.path.isdir(yolov5_images_train_dir):os.mkdir(yolov5_images_train_dir)clear_hidden_files(yolov5_images_train_dir)yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")if not os.path.isdir(yolov5_images_test_dir):os.mkdir(yolov5_images_test_dir)clear_hidden_files(yolov5_images_test_dir)yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")if not os.path.isdir(yolov5_labels_train_dir):os.mkdir(yolov5_labels_train_dir)clear_hidden_files(yolov5_labels_train_dir)yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")if not os.path.isdir(yolov5_labels_test_dir):os.mkdir(yolov5_labels_test_dir)clear_hidden_files(yolov5_labels_test_dir)train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')train_file.close()test_file.close()train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')list_imgs = os.listdir(image_dir) # list image filesprob = random.randint(1, 100)print("Probability: %d" % prob)for i in range(0, len(list_imgs)):path = os.path.join(image_dir, list_imgs[i])if os.path.isfile(path):image_path = image_dir + list_imgs[i]voc_path = list_imgs[i](nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))annotation_name = nameWithoutExtention + '.xml'annotation_path = os.path.join(annotation_dir, annotation_name)label_name = nameWithoutExtention + '.txt'label_path = os.path.join(yolo_labels_dir, label_name)prob = random.randint(1, 100)print("Probability: %d" % prob)if (prob < TRAIN_RATIO): # train datasetif os.path.exists(annotation_path):train_file.write(image_path + '\n')convert_annotation(nameWithoutExtention) # convert labelcopyfile(image_path, yolov5_images_train_dir + voc_path)copyfile(label_path, yolov5_labels_train_dir + label_name)else: # test datasetif os.path.exists(annotation_path):test_file.write(image_path + '\n')convert_annotation(nameWithoutExtention) # convert labelcopyfile(image_path, yolov5_images_test_dir + voc_path)copyfile(label_path, yolov5_labels_test_dir + label_name)train_file.close()test_file.close()
2、加入预训练权重文件
3、修改
3.1 修改文件 VOC.yaml
data/VOC.yaml
内容根据实际需要修改:
路径、类别数、类名。
需要与之前数据集标注和脚本转换一致。
复制一份粘贴下去
train: VOCdevkit/VOC2007/images/trainval: VOCdevkit/VOC2007/images/valnc: 1names: ['crack']
3.2 修改文件 yolov5s1.yaml
models/yolov5s1.yaml
修改:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parametersnc: 1 # number of classesdepth_multiple: 0.33 # model depth multiplewidth_multiple: 0.50 # layer channel multipleanchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbonebackbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 headhead:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
3.3 修改文件 train.py
首先是几个路径
紧接着是训练参数,解释如下
if __name__ == '__main__':"""opt模型主要参数解析:--weights:初始化的权重文件的路径地址--cfg:模型yaml文件的路径地址--data:数据yaml文件的路径地址--hyp:超参数文件路径地址--epochs:训练轮次--batch-size:喂入批次文件的多少--img-size:输入图片尺寸--rect:是否采用矩形训练,默认False--resume:接着打断训练上次的结果接着训练--nosave:不保存模型,默认False--notest:不进行test,默认False--noautoanchor:不自动调整anchor,默认False--evolve:是否进行超参数进化,默认False--bucket:谷歌云盘bucket,一般不会用到--cache-images:是否提前缓存图片到内存,以加快训练速度,默认False--image-weights:使用加权图像选择进行训练--device:训练的设备,cpu;0(表示一个gpu设备cuda:0);0,1,2,3(多个gpu设备)--multi-scale:是否进行多尺度训练,默认False--single-cls:数据集是否只有一个类别,默认False--adam:是否使用adam优化器--sync-bn:是否使用跨卡同步BN,在DDP模式使用--local_rank:DDP参数,请勿修改--workers:最大工作核心数--project:训练模型的保存位置--name:模型保存的目录名称--exist-ok:模型目录是否存在,不存在就创建"""parser = argparse.ArgumentParser()parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')parser.add_argument('--cfg', type=str, default='', help='model.yaml path')parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path')parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')parser.add_argument('--epochs', type=int, default=300)parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')parser.add_argument('--rect', action='store_true', help='rectangular training')parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')parser.add_argument('--notest', action='store_true', help='only test final epoch')parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')parser.add_argument('--project', default='runs/train', help='save to project/name')parser.add_argument('--entity', default=None, help='W&B entity')parser.add_argument('--name', default='exp', help='save to project/name')parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')parser.add_argument('--quad', action='store_true', help='quad dataloader')parser.add_argument('--linear-lr', action='store_true', help='linear LR')parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')opt = parser.parse_args()




4、参考文献

若有收获,就点个赞吧
0 人点赞
