需要改一下路径
import cv2# (1)导入yolov4-tiny网络模型结构# 传入模型结构.cfg文件,模型权重参数.weight文件net = cv2.dnn.readNet('C:\\Users\\17242\\Desktop\\yolov4-tiny.cfg', 'C:\\Users\\17242\\Desktop\\yolov4-tiny.weights')# 定义一个目标检测模型,将模型传进去model = cv2.dnn_DetectionModel(net)# 设置模型的输入model.setInputParams(size=(320, 320), scale=1 / 255)# (2)获取分类文本的信息classes = [] # 存放每个分类的名称with open('C:\\Users\\17242\\Desktop\\classes.txt') as file_obj:# 获取文本中的每一行for class_name in file_obj.readlines():# 删除文本中的换行符、空格等class_name = class_name.strip()# 将每个分类名保存到列表中classes.append(class_name)# (3)视频捕获cap = cv2.VideoCapture('C:\\Users\\17242\\Desktop\\1.mp4')# (4)对每一帧视频图像处理while True:# 返回是否读取成功ret和读取的帧图像frameret, frame = cap.read()# 图像比较大把它缩小一点frame = cv2.resize(frame, (1280, 720))# 视频比较短,循环播放if cap.get(cv2.CAP_PROP_POS_FRAMES) == cap.get(cv2.CAP_PROP_FRAME_COUNT):# 如果当前帧==总帧数,那就重置当前帧为0cap.set(cv2.CAP_PROP_POS_FRAMES, 0)# 目标检测classids, scores, bboxes = model.detect(frame, 0.5, 0.3)print('classids:', classids) # 如:[0]print('score:', scores) # 如:0.9469002print('bboxes:', bboxes) # 如:[159 176 816 533]# (5)显示检测结果# 遍历所有的检测框信息,把它们绘制出来for class_id, score, bbox in zip(classids, scores, bboxes):# 获取检测框的左上角坐标和宽高x, y, w, h = bbox# 获取检测框对应的分类名class_name = classes[class_id]# 绘制矩形框cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 255, 0), 2)# 显示分类文本cv2.putText(frame, class_name, (x, y + h + 20), cv2.FONT_HERSHEY_COMPLEX, 1, (0, 255, 0), 2)# 显示类别概率cv2.putText(frame, str(int(score * 100)) + '%', (x, y - 5), cv2.FONT_HERSHEY_COMPLEX, 1, (0, 255, 255), 2)# (6)显示图像cv2.imshow('Image', frame) # 窗口名,图像变量if cv2.waitKey(30) & 0xFF == 27: # 每帧滞留30毫秒后消失break# 释放视频资源cap.release()cv2.destroyAllWindows()
https://blog.csdn.net/weixin_41868104/article/details/115748281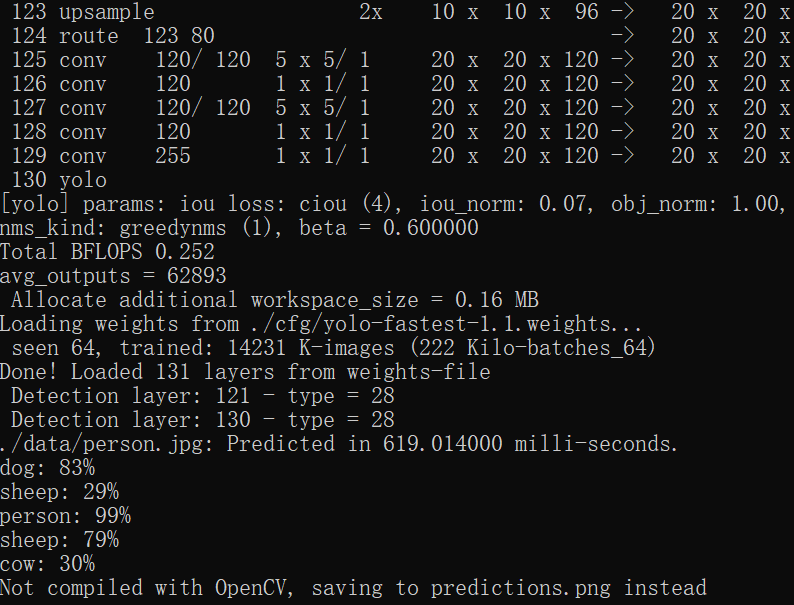

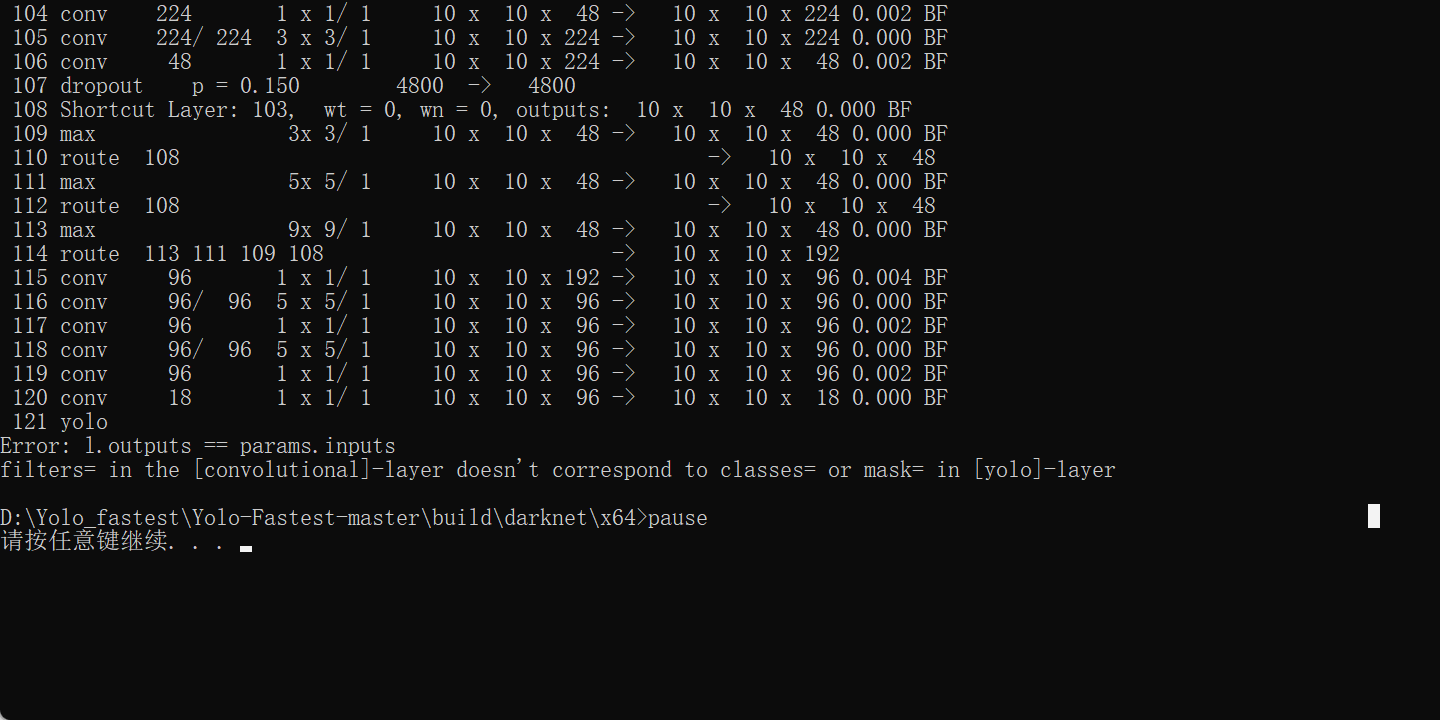
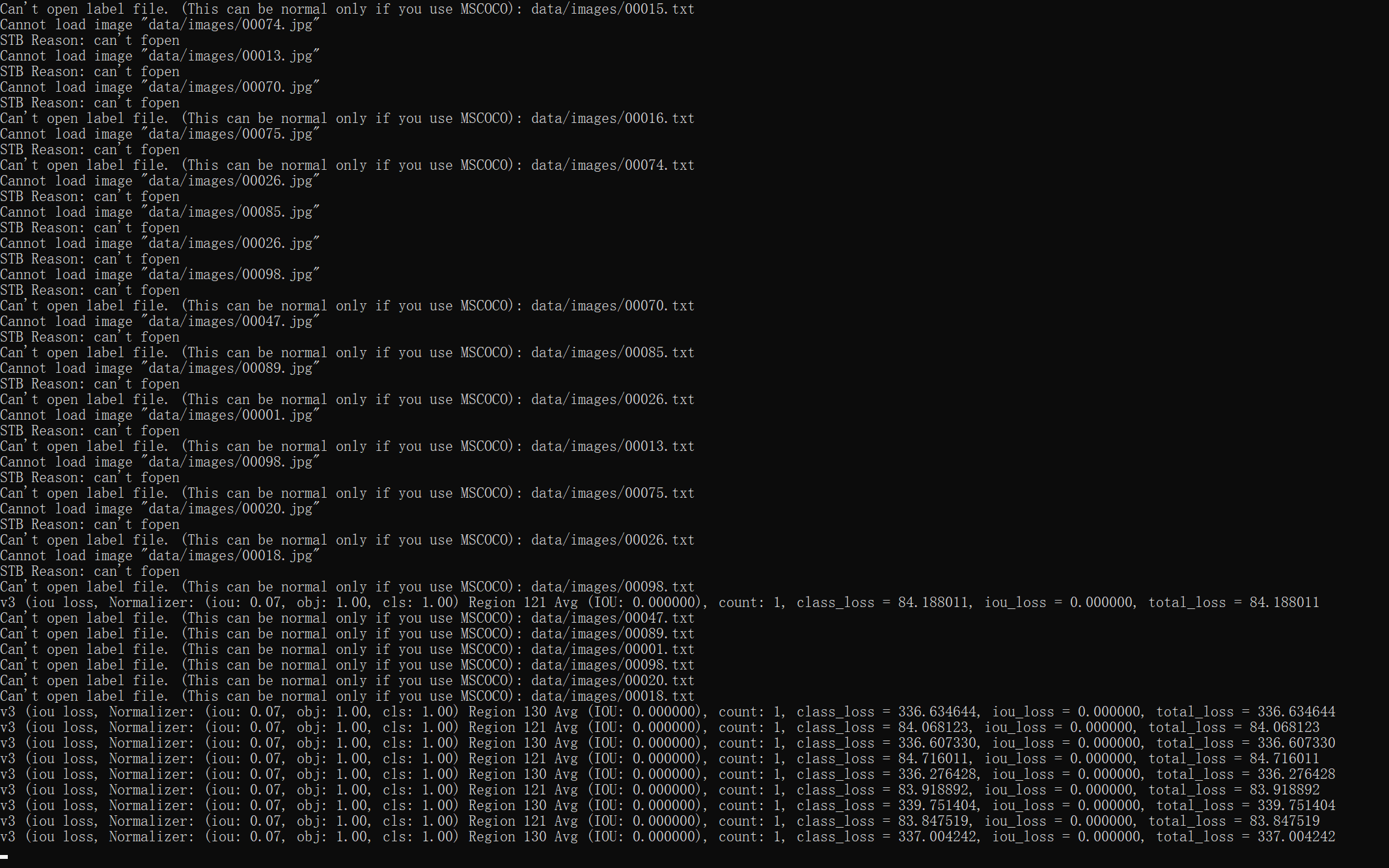
上图解决。
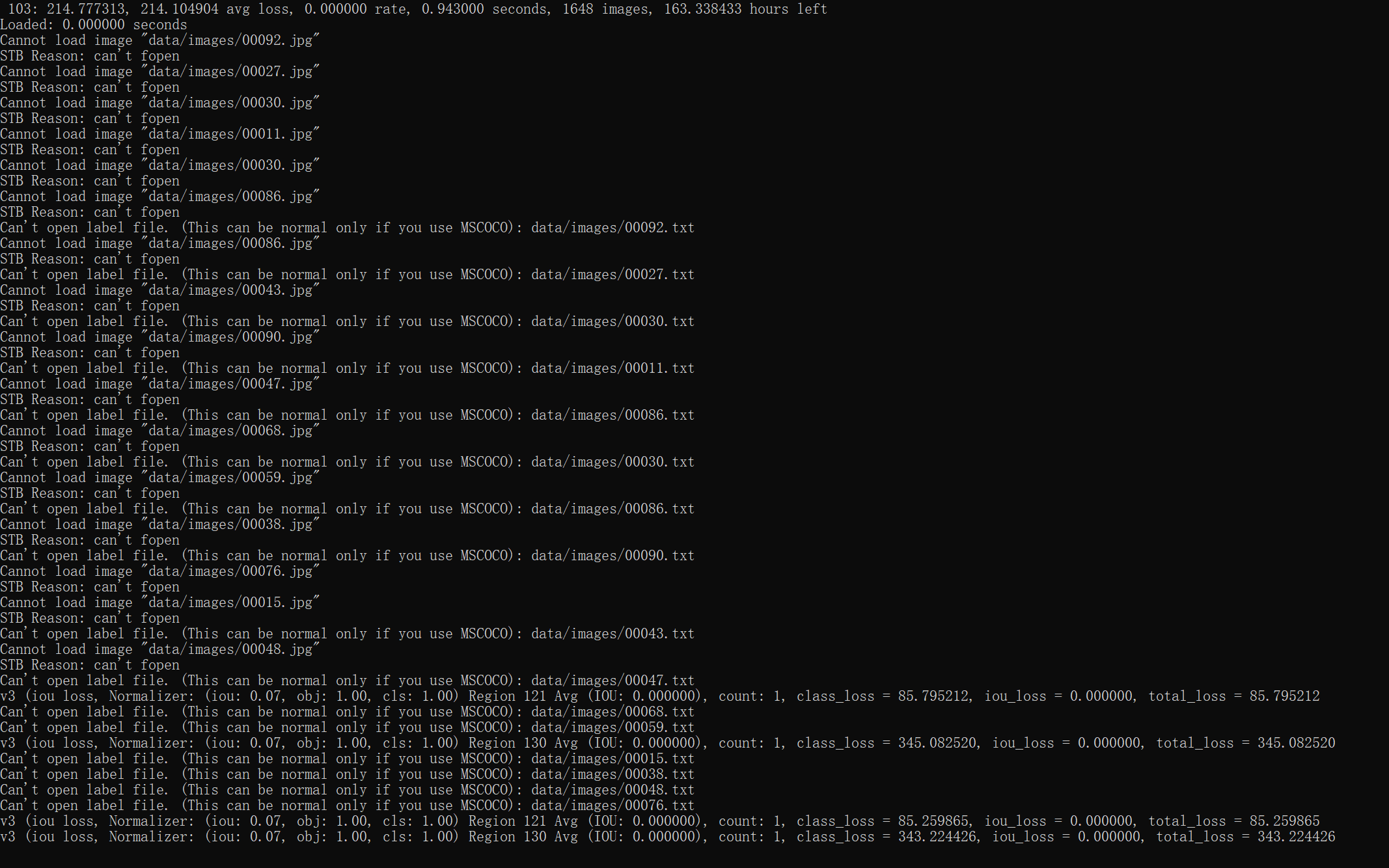

若有收获,就点个赞吧
0 人点赞
