1:介绍。
又一次遇到了深度图,感觉每次遇到深度相关的东西都要重新看一遍,应该是我还没理解这玩意,这一次就再详细的复习一遍。
非常多的效果都需要深度,比如景深,屏幕空间扫描效果,软粒子,阴影,SSAO,近似次表面散射(更确切的说是透射),对于延迟渲染来说,还可以用深度反推世界空间位置降低带宽消耗,还可以用深度做运动模糊,屏幕空间高度雾,距离雾,部分Ray-Marching效果也都需要深度,可以说,深度是一些渲染高级效果必要的条件。另一方面,光栅化渲染本身可以得到正确的效果,就与深度(Z Buffer)有着密不可分的关系。
深度对于实时渲染的意义十分重大,OpenGL,DX,Unity为我们封装好了很多深度相关的内容,如ZTest,ZWrite,CameraDepthMode,Linear01Depth等等。今天我来整理一下与学习过程中遇到的深度相关的一些问题,主要是渲染中深度的一些问题以及Unity中深度图生成,深度图的使用,深度的精度,Reverse-Z等等问题,然后再用深度图,实现一些好玩的效果。
2:参考文章链接。(附效果图片)
https://www.jianshu.com/p/80a932d1f11e
https://blog.csdn.net/puppet_master/article/details/77489948
3:笔记。
1:透视投影和光栅化过程
透视投影的知识点主要在于三角形相似以及小孔成像,透视投影实现的就是一种“近大远小”的效果,其实投影之后的大小(x,y坐标)也刚好就和1/Z呈线性关系。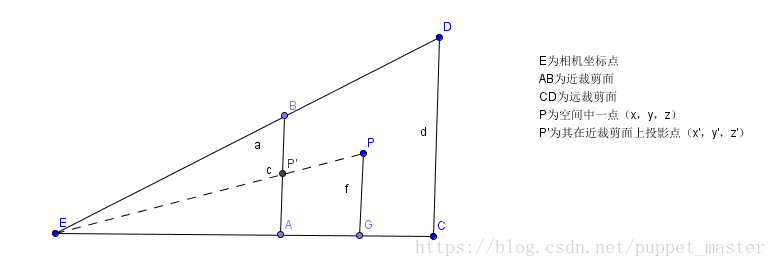
上图是一个视锥体的截面图(只看x,z方向;上为x,右为z吧),P为空间中的一点(x,y,z),那么它在近裁剪面处的投影坐标假设为P’(x’,y’,z’)。在这里我只需要注意三角形相似即可。即三角形EAP’相似于三角形EGP,我们可以得到两个等式:
x’/ x = z’/ z => x’= xz’/ z
y’/ y = z’/ z => y’= yz’/ z
由于投影面就是近裁剪面(因为相似三角形),那么近裁剪面是我们可以定义的,我们设其为N,远裁剪面为F,那么实际上最终的投影坐标就是:(Nx/z,Ny/z,N)Z是其中一条轴,因为这是一个截面图,所以这里默认为N
投影后的Z坐标,实际上已经失去作用了,只用N表示就可以了,但是这个每个顶点都一样,每个顶点带一个的话简直是暴殄天物,浪费了一个珍贵的维度,所以这个Z会被存储一个用于后续深度测试,透视校正纹理映射的变换后的Z值。
但是还有一个问题,这里我们得到是只是顶点的Z值,也就是我们在vertex shader中计算的结果,只有顶点,但是实际上,我们在屏幕上会看到无数的像素。这里我们使用的插值这一个方法。
一个三角形光栅化到屏幕空间上时,我们仅有的就是在三角形三个顶点所包含的各种数据,其中顶点已经是被变换过的了(Unity中常用的MVP变换),在绘制三角形的过程中,根据屏幕空间位置对上述数据进行插值计算,来获得顶点之间对应屏幕上像素点上的颜色或其他数据信息。
这个Z值,还是比较有说道的。在透视投影变换之前,我们的Z实际上是相机空间的Z值,直接把这个Z存下来也无可厚非,但是后续计算会比较麻烦,毕竟没有一个统一的标准。既然我们有了远近裁剪面,有了Z值的上下限,我们就可以把这个Z值映射到[0,1]区间,即当在近裁剪面时,Z值为0,远裁剪面时,Z值为1(暂时不考虑reverse-z的情况)。
首先,能想到的最简单的映射方法就是depth = (Z(eye) - N)/ F - N(相机空间的Z值-近裁剪屏幕 / 远裁剪面 - 近裁剪面)。直接线性映射到(0,1)区间,但是这种方案是不正确的,看下面一张图: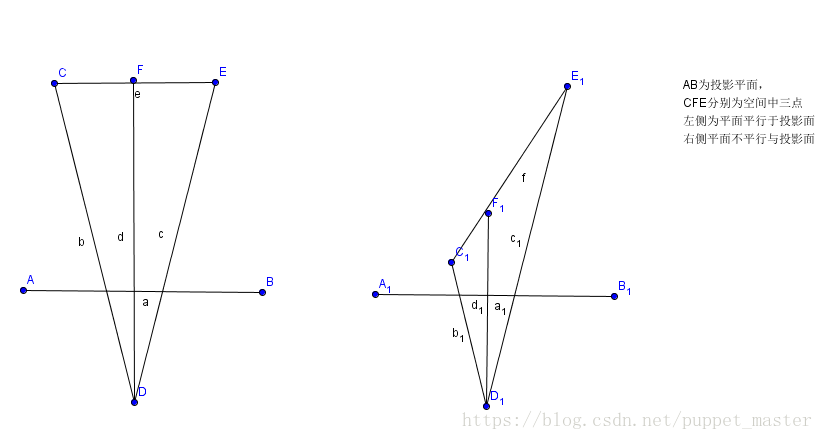
右侧的三角形,在AB近裁剪面投影的大小一致,而实际上C1F1和F1E1相差的距离甚远,换句话说,经过投影变换的透视除法后,我们在屏幕空间插值的数据(根据屏幕空间距离插值),并不能保证其对应点在投影前的空间是线性变换的。关于透视投影和光栅化,可以参照上一篇文章中软渲染透视投影和光栅化的内容。
透视投影变换之后,在屏幕空间进行插值的数据,与Z值不成正比,而是与1/Z成正比。所以,我们需要一个表达式,可以使Z = N时,depth = 0,Z = F时,depth = 1,并且需要有一个z作为分母,可以写成(az + b)/z,带入上述两个条件:
(N a + b) / N = 0 => b = -an
(F a + b) / F = 0 => aF + b = F => aF - aN = F
进而得到:
a = F / (F - N)
b = NF / (N - F)
最终depth(屏幕空间) = (aZ + b)/ Z (Z为视空间深度)。(空间深度从哪来的?)
通过透视投影,在屏幕空间X,Y值都除以了Z(视空间深度),当一个值的Z趋近于无穷远时,那么X,Y值就趋近于0了,也就是类似近大远小的效果了。而对于深度值的映射,从上面看也是除以了Z的,这个现象其实也比较好理解,比如一个人在离相机200米的地方前进了1米,我们基本看不出来距离的变化,但是如果在相机面前2米处前进了1米,那么这个距离变化是非常明显的,这也是近大远小的一种体现。
2:Unity中生成深度图
在Unity5.X版本后,实际上深度的pass就变为了ShadowCaster这个pass,而不需要再进行Shader Raplacement的操作了(但是DepthNormalMap仍然需要),所谓ShadowCaster这个pass,其实就是用于投影的Pass,Unity的所有自带shader都带这个pass,而且只要我们fallback了Unity内置的shader,也会增加ShadowCaster这个pass。
我们应该也可以自己定义ShadowCaster这个pass,防止类似AlphaTest等造成深度图中内容与实际渲染内容不符的情况。
ShadowCaster这个pass实际上是有两个用处,第一个是屏幕空间的深度使用该pass进行渲染,另一方面就是ShadowMap中光方向的深度也是使用该pass进行渲染的,区别主要在与VP矩阵的不同,阴影的pass是相对于光空间的深度,而屏幕空间深度是相对于摄像机的。新版的Unity使用了ScreenSpaceShadowMap,屏幕空间的深度也是必要的(先生成DpehtTexture,再生成ShadowMap,然后生成ScreenSpaceShadowMap,再正常渲染物体采样ScreenSpaceShadowMap)。所以,如果我们开了屏幕空间阴影,再使用DepthTexture,就相当于免费赠送,不用白不用喽。
3:深度图的使用
深度图理解起来比较困难,说了那么多,但其实在unity中使用深度图是很简单的,通过Camera的depthTextureMode即可设置DepthTexture。我们来用一个后处理效果把当前的深度图绘制到屏幕上:
/********************************************************************FileName: DepthTextureTest.csDescription:显示深度贴图Created: 2018/05/27history: 27:5:2018 1:25 by puppet_master*********************************************************************/using System.Collections;using System.Collections.Generic;using UnityEngine;[ExecuteInEditMode]public class DepthTextureTest : MonoBehaviour{private Material postEffectMat = null;private Camera currentCamera = null;void Awake(){currentCamera = GetComponent<Camera>();}void OnEnable(){if (postEffectMat == null)postEffectMat = new Material(Shader.Find("DepthTexture/DepthTextureTest"));currentCamera.depthTextureMode |= DepthTextureMode.Depth;}void OnDisable(){currentCamera.depthTextureMode &= ~DepthTextureMode.Depth;}void OnRenderImage(RenderTexture source, RenderTexture destination){if (postEffectMat == null){Graphics.Blit(source, destination);}else{Graphics.Blit(source, destination, postEffectMat);}}}
//puppet_master//2018.5.27//显示深度贴图Shader "DepthTexture/DepthTextureTest"{CGINCLUDE#include "UnityCG.cginc"sampler2D _CameraDepthTexture;fixed4 frag_depth(v2f_img i) : SV_Target{float depthTextureValue = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, i.uv);//float linear01EyeDepth = LinearEyeDepth(depthTextureValue) * _ProjectionParams.w;float linear01EyeDepth = Linear01Depth(depthTextureValue);return fixed4(linear01EyeDepth, linear01EyeDepth, linear01EyeDepth, 1.0);}ENDCGSubShader{Pass{ZTest OffCull OffZWrite OffFog{ Mode Off }CGPROGRAM#pragma vertex vert_img#pragma fragment frag_depthENDCG}}}


4:LinearEyeDepth&Linear01Depth
在上面的shader中,用了LinearEyeDepth和LinearDepth对深度进行了一个变换之后才输出到屏幕,那么实际上的Z值应该是啥样的呢,我放置了四个距离相等的模型,来看一下常规的Z值直接输出的情况(由于目前开启了Reverse-Z,所以用1-z作为输出),即:
float depthTextureValue = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, i.uv);return 1 - depthTextureValue;


对比两张图我们应该也就比较清楚效果了,没有经过处理的深度,在视空间上不是线性变化的,近处深度变化较明显,而远处几乎全白了,而经过处理的深度,在视空间是线性变化的。
为什么会这样呢,还是得从透视投影和光栅化说起,在视空间,每个顶点的原始的Z值是视空间的深度,但是经过透视投影变换以及透视投影,转化到屏幕空间后,需要保证在屏幕空间的深度与1/z成正比才可以在屏幕空间逐像素地进行插值进而获得屏幕上任意一点像素的屏幕空间深度值,简单来说,这个转化的过程主要是为了从顶点数据获得屏幕空间任意一点的逐像素数据。而得到屏幕空间深度之后,我们要使用时,经过变换的这个屏幕空间的东西,又不是很直观,最直观的还是视空间的深度,所以我们要进行一步变换,把屏幕空间的深度再转换回原始的视空间深度。
上文中,我们推导过从视空间深度转化到屏幕空间深度的公式如下:
a = F / (F - N)
b = NF / (N - F)
depth(屏幕空间) = (aZ + b)/ Z (Z为视空间深度)。
那么,反推回Z(视空间) = b /(depth - a),进一步地,Z(视空间) = 1 / (depth / b - a / b),然后将上述a和b的值代入:
Z(视空间) = 1 / ((depth / (NF / (N - F)) - (F /(F - N)) / (NF / (N - F)))
化简: Z(视空间) = 1 / (((N - F)/ NF) * depth + 1 / N)
Z(视空间) = 1 / (param1 * depth + param2),param1 = (N - F)/ NF,param2 = 1 / N。
下面让我们来看看Unity自带Shader中关于深度值LinearEyeDepth的处理:
// Z buffer to linear depthinline float LinearEyeDepth( float z ){return 1.0 / (_ZBufferParams.z * z + _ZBufferParams.w);}// Values used to linearize the Z buffer (http://www.humus.name/temp/Linearize%20depth.txt)// x = 1-far/near// y = far/near// z = x/far// w = y/farfloat4 _ZBufferParams;
_ZBufferParams.z = _ZBufferParams.x / far = (1 - far / near)/ far = (near - far) / near * far
_ZBufferParams.w = _ZBufferParams.y / far = (far / near) / far = 1 / near
我们推导的param1 = _ZBufferParams.z,param2 = _ZBufferParams.w,实际上Unity中LinearEyeDepth就是将透视投影变换的公式反过来,用zbuffer图中的屏幕空间depth反推回当前像素点的相机空间深度值。
下面再来看一下Linear01Depth函数,所谓01,其实也比较好理解,我们上面得到的深度值实际上是真正的视空间Z值,但是这个值没有一个统一的比较标准,所以这个时候依然秉承着映射大法好的理念,把这个值转化到01区间即可。由于相机实际上可以看到的最远区间就是F(远裁剪面),所以这个Z值直接除以F即可得到映射到(0,1)区间的Z值了:
Z(视空间01) = Z(视空间) / F = 1 / (((N - F)/ N) * depth + F / N)
Z(视空间01) = 1 / (param1 * depth + param2),param1 = (N - F)/ N = 1 - F/N,param2 = F / N。
再来看一下Unity中关于Linear01Depth的处理:
// Z buffer to linear 0..1 depthinline float Linear01Depth( float z ){return 1.0 / (_ZBufferParams.x * z + _ZBufferParams.y);}// Values used to linearize the Z buffer (http://www.humus.name/temp/Linearize%20depth.txt)// x = 1-far/near// y = far/near// z = x/far// w = y/farfloat4 _ZBufferParams;
可以看出我们推导的param1 = _ZBufferParams.x,param2 = _ZBufferParams.y。也就是说,Unity中Linear01Depth的操作值将屏幕空间的深度值还原为视空间的深度值后再除以远裁剪面的大小,将视空间深度映射到(0,1)区间。
Unity应该是OpenGL风格(矩阵,NDC等),上面的推导上是基于DX风格的DNC进行的,不过,如果是深度图的话,不管怎么样都会映射到(0,1)区间的,相当于OpenGL风格的深度再进行一步映射,就与DX风格的一致了。个人感觉OpenGL风格的NDC在某些情况下并不是很方便(见下文Reverse-Z相关内容)。
了解了这两个Unity为我们提供的API具体是干什么的了之后,我们就可以放心大胆的使用了,因为实际上绝大多数情况下,我们都是需要相机空间的深度值或者映射到01区间的相机空间深度值。
5:Z&1/Z
通过上面的深度图具体的使用,我们发现,实际上真正使用的深度,是从顶点的视空间Z,经过投影变成一个1/Z成正比的值(屏幕空间Depth),然后在使用时,再通过投影变换时的计算公式反推回对应视空间像素位置的Z。可见,这个操作还是非常折腾的。那为何要如此费劲地进行上面的操作,而不是直接存一个视空间的值作为真正的深度呢?
其实前辈们也想过这个问题,原来的显卡,甚至是不用我们当今的Z Buffer(存储的是屏幕空间的Depth,也就是与1/Zview成正比的一个值)的,而是用了一个所谓的W Buffer(存储的是视空间的Z)。W Buffer的计算表面上看起来应该是很简单的,即在顶点计算时,直接将当前顶点的z值进行01映射,类似W = Zview / Far,就可以了把视空间的值映射到一个(0,1)区间的深度值。然后我们在Pixel阶段要使用的时候,就需要通过光栅化阶段顶点数据插值得到当前屏幕空间这一点的Z值,但是这又回到了一个问题,Z值是视空间的,经过了透视投影变换之后变成了屏幕空间,我们插值的系数是屏幕空间位置,这个位置是与1/Z成正比的,换句话说,在屏幕空间插值时,必须要进行透视投影校正,类似透视投影校正纹理采样,针对的是uv坐标进行了插值,大致思路是计算时对顶点数据先除以Z,然后屏幕空间逐像素插值,之后再乘回该像素真正的Z值。可见,如果要使用这样的W Buffer,虽然我们使用起来简单了,但是硬件实现上,还是比较麻烦的,毕竟需要多做一次乘除映射。
所以,实际上,现在的Z Buffer使用的仍然是屏幕空间的Depth,也就是在透视投影变换时,使用透视投影矩阵直接相乘把顶点坐标xyz变换到齐次裁剪空间,然后统一透视除法除以w,就得到了一个在屏幕空间是线性的Depth值。这个值可以在屏幕上直接根据像素位置进行简单线性插值,无需再进行透视校正,这样的话,对于硬件实现上来说是最容易的。
小总结:
1:一开始获得得Z Buffer是屏幕空间得Depth。
2:使用透视投影矩阵把顶点坐标变换到齐次裁剪空间。
3:统一透视除法除以w。
4:这样就能得到屏幕空间是线性得Depth值。
其实在Unity中也是分为两种DepthTexture的,一种是DepthTexture,存储的是屏幕空间线性深度,也是最常见的深度的格式,上面已经推导过了。而另一种是DepthNormalTexture(不仅仅是它除了Depth还包含Normal),存的就是相机空间的深度值,这个就是最基本的线性映射,把这个值作为顶点数据走透视投影校正后传递给Fragment阶段,那么这个值其实直接就是在视空间是线性变换的了,不需要再进行类似普通DepthTexture的Linear操作。
DepthNormalTexture的生成用到的相关内容(只看Depth部分):
v2f vert( appdata_base v ){v2f o;o.pos = UnityObjectToClipPos(v.vertex);o.nz.xyz = COMPUTE_VIEW_NORMAL;o.nz.w = COMPUTE_DEPTH_01;return o;}fixed4 frag(v2f i) : SV_Target{return EncodeDepthNormal (i.nz.w, i.nz.xyz);}#define COMPUTE_DEPTH_01 -(UnityObjectToViewPos( v.vertex ).z * _ProjectionParams.w)// x = 1 or -1 (-1 if projection is flipped)// y = near plane// z = far plane// w = 1/far planeuniform vec4 _ProjectionParams;
新版本后处理包中对于深度的采样大概是这个样子的:
// Depth/normal sampling functionsfloat SampleDepth(float2 uv){#if defined(SOURCE_GBUFFER) || defined(SOURCE_DEPTH)float d = LinearizeDepth(SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, uv));#elsefloat4 cdn = tex2D(_CameraDepthNormalsTexture, uv);float d = DecodeFloatRG(cdn.zw);#endifreturn d * _ProjectionParams.z + CheckBounds(uv, d);}
可见,对于两种方式的深度,进行生成和采样的方式是不同的,DepthNormal类型的深度直接就可以乘以远裁剪面还原到视空间深度,而深度图的需要进行Linearize变换。可以根据需要定制自己的DepthTexture。主流一些的方式还是原生的DepthTextue方式,但是这种方式也有很一个很严重的问题,就是精度问题。
4:实现思路。

若有收获,就点个赞吧
0 人点赞
