对MySQL事务回顾
1. 事务 参考文章
ACID
- A:原子性(Atomicity)
一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
就像你买东西要么交钱收货一起都执行,要么要是发不出货,就退钱。
- C:一致性(Consistency)
事务的一致性指的是在一个事务执行之前和执行之后数据库都必须处于一致性状态。如果事务成功地完成,那么系统中所有变化将正确地应用,系统处于有效状态。如果在事务中出现错误,那么系统中的所有变化将自动地回滚,系统返回到原始状态。
- I:隔离性(Isolation)
指的是在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。由并发事务所做的修改必须与任何其他并发事务所做的修改隔离。事务查看数据更新时,数据所处的状态要么是另一事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看到中间状态的数据。
打个比方,你买东西这个事情,是不影响其他人的。
- D:持久性(Durability)
指的是只要事务成功结束,它对数据库所做的更新就必须永久保存下来。即使发生系统崩溃,重新启动数据库系统后,数据库还能恢复到事务成功结束时的状态。
打个比方,你买东西的时候需要记录在账本上,即使老板忘记了那也有据可查。
实现原理:
事务的ACID是通过InnoDB日志和锁来保证。事务的隔离性是通过数据库锁的机制实现的,持久性通过redo log(重做日志)来实现,原子性和一致性通过Undo log来实现。
UndoLog的原理很简单,为了满足事务的原子性,在操作任何数据之前,首先将数据备份到一个地方(这个存储数据备份的地方称为UndoLog)。然后进行数据的修改。如果出现了错误或者用户执行了ROLLBACK语句,系统可以利用Undo Log中的备份将数据恢复到事务开始之前的状态。
和Undo Log相反,RedoLog记录的是新数据的备份。在事务提交前,只要将RedoLog持久化即可,不需要将数据持久化。当系统崩溃时,虽然数据没有持久化,但是RedoLog已经持久化。系统可以根据RedoLog的内容,将所有数据恢复到最新的状态。 对具体实现过程有兴趣的同学可以去自行搜索扩展。
2. Asgard :
Asgard :中间件,部署在独立的服务器上,业务代码如同在使用单一数据库一样使用它,实际上它内部管理着很多的数据源,当有数据库请求时,它会对 SQL 语句做必要的改写,然后发往指定的数据源。
主从原理:主库通过同步binlog到从库,relaylog去读 ; 从库有延迟可以通过缓存 冗余数据来解决 ;
3. 分库分表
写主库,(返回用户ID)(水平分库,用hash直接hash路由id到对应的库的对应的表,64个库,64张表)
分库分表 参考文章 单表单库:QPS:2000/s,单表磁盘存储200w
- 垂直拆分:业务维度分成不同的表
- 水平拆分:单一表的数据拆分成多个表存储 (表结构不变)
- 某一个字段的hash 比如主键先分库hash 再分表hash
按照某一个字段的哈希值做拆分,这种拆分规则比较适用于实体表,比如说用户表,内容表,我们一般按照这些实体表的 ID 字段来拆分。比如说我们想把用户表拆分成 16 个库,每个库是 64 张表,那么可以先对用户 ID 做哈希,哈希的目的是将 ID 尽量打散,然后再对 16 取余,这样就得到了分库后的索引值;对 64 取余,就得到了分表后的索引值
4. 数据库主从数据库数据一致性问题:
数据一致性问题:半同步复制,也就是主库将数据写入带binlog文件的时候强制从库将数据同步到数据库,直到从库完成返回ack才算完成。
Zookeeper ZAB协议 (分布式事务一致性)
Zookeeper Automic Broadcast(ZAB),即Zookeeper原子性广播,是Paxos经典实现
术语:
quorum:集群过半数的集合
1. ZAB(zookeeper)中节点分四种状态
looking:选举Leader的状态(崩溃恢复状态下)
following:跟随者(follower)的状态,服从Leader命令
leading:当前节点是Leader,负责协调工作。
observing:observer(观察者),不参与选举,只读节点。
2. ZAB中的两个模式(ZK是如何进行选举的)
崩溃恢复、消息广播
1)崩溃恢复
leader挂了,需要选举新的leader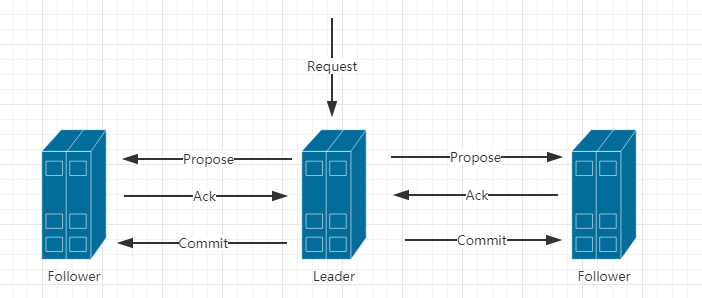
a.每个server都有一张选票,如(3,9),选票投自己。
b.每个server投完自己后,再分别投给其他还可用的服务器。如把Server3的(3,9)分别投给Server4和Server5,一次类推
c.比较投票,比较逻辑:优先比较Zxid,Zxid相同时才比较myid。比较Zxid时,大的做leader;比较myid时,小的做leader
d.改变服务器状态(崩溃恢复->数据同步,或者崩溃恢复->消息广播)
相关概念补充说明:
epoch周期值
acceptedEpoch(比喻:年号):follower已经接受leader更改年号的(newepoch)提议。
currentEpoch(比喻:当前的年号):当前的年号
lastZxid:history中最近接收到的提议zxid(最大的值)
history:当前节点接受到事务提议的log
Zxid数据结构说明:
cZxid = 0x10000001b
64位的数据结构
高32位:10000
Leader的周期编号+myid的组合
低32位:001b
事务的自增序列(单调递增的序列)只要客户端有请求,就+1
当产生新Leader的时候,就从这个Leader服务器上取出本地log中最大事务Zxid,从里面读出epoch+1,作为一个新epoch,并将低32位置0(保证id绝对自增)
2)消息广播(类似2P提交)

a.Leader接受请求后,将这个请求赋予全局的唯一64位自增Id(zxid)。
b.将zxid作为议案发给所有follower。
c.所有的follower接受到议案后,想将议案写入硬盘后,马上回复Leader一个ACK(OK)。
d.当Leader接受到合法数量(过半)Acks,Leader给所有follower发送commit命令。
e.follower执行commit命令。
注意:到了这个阶段,ZK集群才正式对外提供服务,并且Leader可以进行消息广播,如果有新节点加入,还需要进行同步。
3)数据同步
a.取出Leader最大lastZxid(从本地log日志来)
b.找到对应zxid的数据,进行同步(数据同步过程保证所有follower一致)
c.只有满足quorum同步完成,准Leader才能成为真正的Leader

若有收获,就点个赞吧
0 人点赞
