1. 介绍
在项目初期的时候,大家都是赶着上线,一般来说对日志没有过多的考虑,当然日志量也不大,所以用 log4j 就够了,随着应用的越来越多,日志散落在各个服务器的 logs 文件夹下,确实有点不大方便。
ELK 因此就应运而生,那么为什么要用 ELK 呢?ELK 又能给我们解决哪些问题呢?
- 日志统一收集,管理,访问。查找问题方便安全
- 收集放到搜索引擎中。也就就是 ELK 中的 E 表示 es:分布式搜索引擎存储库。
- 它是一个 Nosql 数据库。其核心是倒排索引库。可存 TB 级的数据。
- 使用简单,可以大大提高定位问题的效率:一个页面搞定所有查询。K:kibana。
- 可以对收集起来的 log 进行分析。L:Logstash,就是用收集日志。会部署到应用服务器上面。还可以提供过滤功能。
- 能够提供错误报告,监控机制。
2. ELK 架构设计
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件
1. LogStash
它可以流放到各自的服务器上收集 Log 日志,通过内置的ElasticSearch插件解析后输出到 ES 中
2.ElasticSearch
这是一个基于 Lucene 的分布式全文搜索框架,可以对 logs 进行分布式存储,有点像 hdfs。此为 ELK 的核心组件,日志的分析以及存储全部由 es 完成。
3. Kibana:论坛。大屏展示
它可以多维度的展示 es 中的数据。可提供图表展示,造出一些非常炫酷的页面。这也解决了用 mysql 存储带来了难以可视化的问题。他提供了丰富的UI组件,简化了使用难度。
目前 ELK 有两种框架:
- 普通框架:这套框架不会影响原生应用,只是 logstash 会消耗一点系统资源
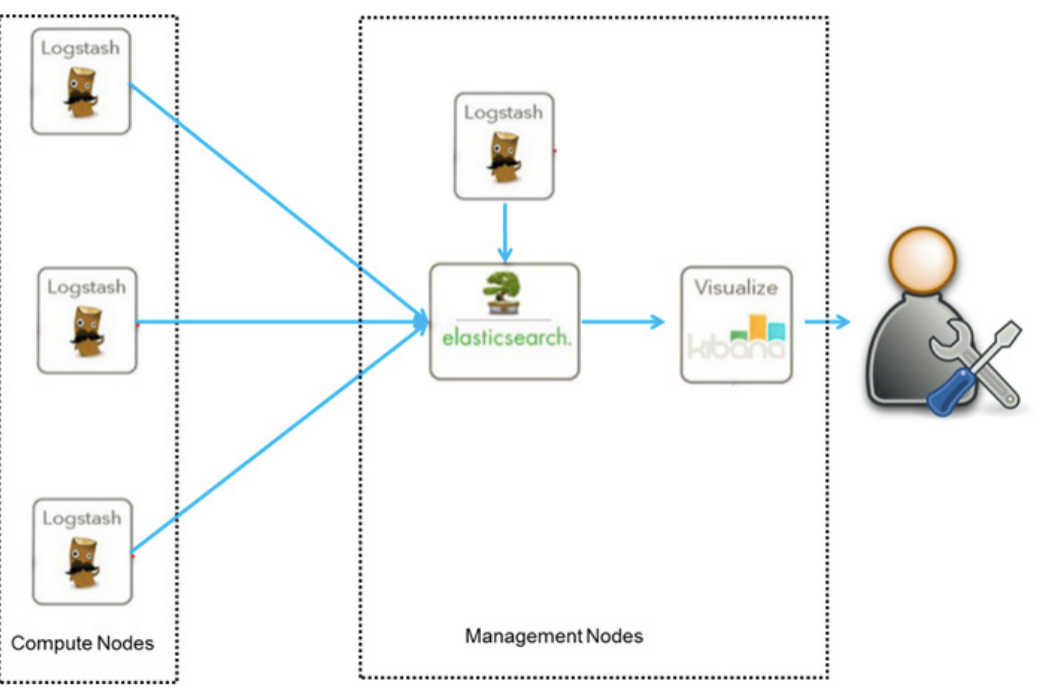
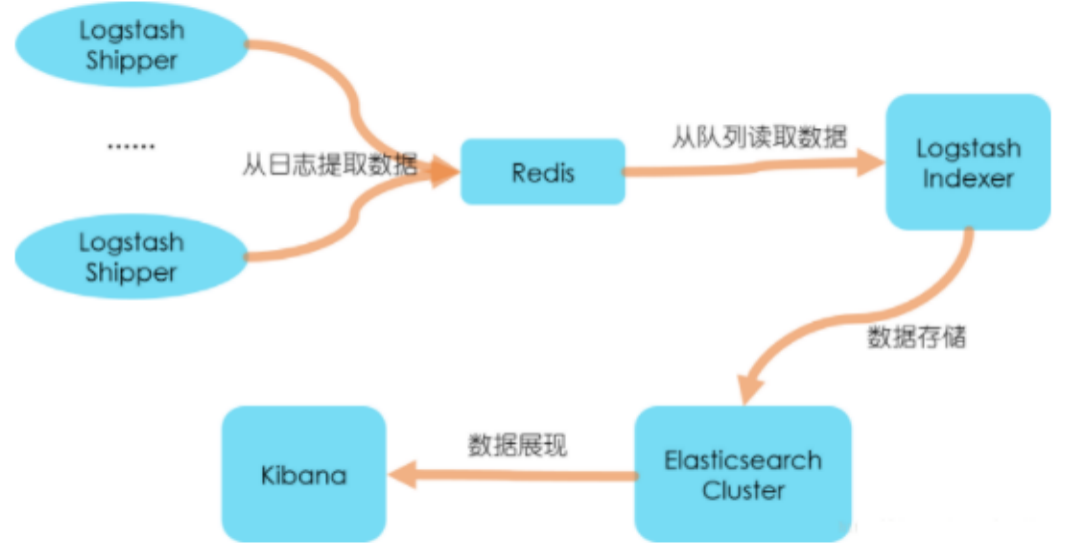
- 个性化扩展框架(针对日志数据需要二次处理以及多方使用的场景)
kafka 不建议使用,除非针对 TB 级数据
Filebeat: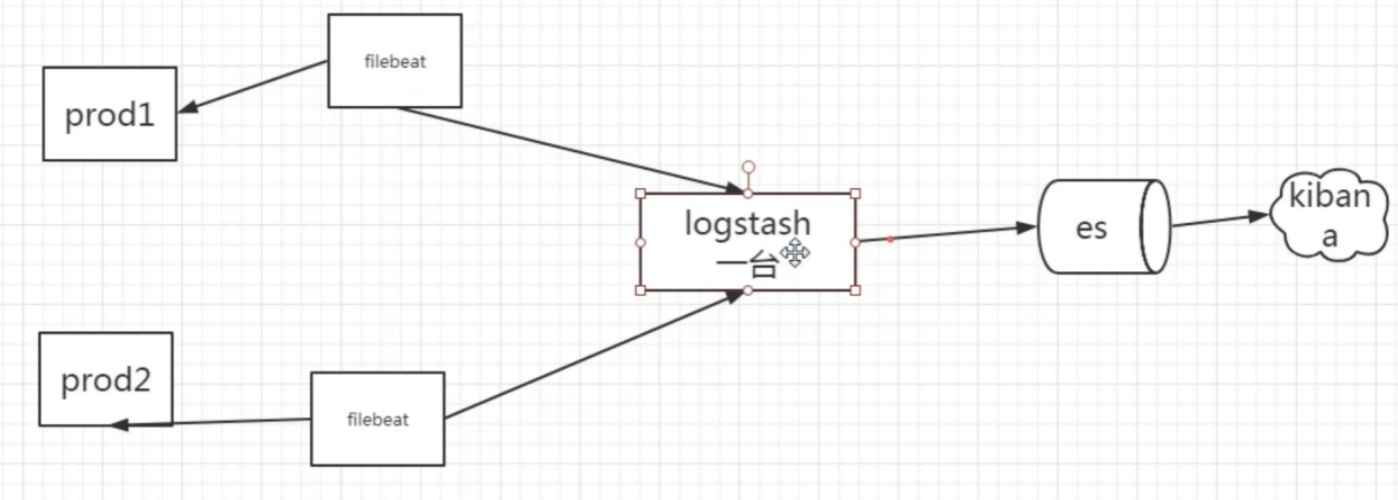
Logstash 比较重,所以用 先用 filebeat。Logstash 部署一台就行,因为它是比较高可用的,也可以部署多台,它是支持分布式的。
3. 快速搭建 ELK 环境
- 官方下载 :https://www.elastic.co/cn/products/4.6.1
- 版本:elasticsearch 2.4.6, lucene版本. 5.x,6. 7.
如果对数据检索的实时性要求特别高的系统就用es5.6+版本。
kibana4.6.1 ,logstash2.4.0三个版本(注意 JDK需要1.7+)
- 安装logstash
(1) 解压,在config(自己建的)目录建:logstash.conf (建配置文件)
(2) 做好 input ,filter,output 三大块, 其中input是吸取logs文件下的所有 log 后缀的日志文件,filter是一个过滤函数,配置则可进行个性化过滤,output 配置了导入到
hosts 为 127.0.0.1:9200的 elasticsearch 中,每天一个索引
input {file {type => "log"path => ["/export/home/tomcat/domains/*/*/logs/*.out"]start_position => "end"ignore_older => 0codec=> multiline { //配置log换行问题pattern => "^%{TIMESTAMP_ISO8601}"negate => truewhat => "previous"}}beats {port => 5044}}output {if [type] == "log" {elasticsearch {hosts => ["http://127.0.0.1:9200"]index => "log-%{+YYYY.MM}"}}}
说明:start_position 是监听的位置,默认是 end,即一个文件如果没有记录它的读取信息,则从文件的末尾开始读取,也就是说,仅仅读取新添加的内容。对于一些更新的日志类型的监听,通常直接使用end就可以了;相反,beginning就会从一个文件的头开始读取。但是如果记录过文件的读取信息,则不会从最开始读取。重启读取信息不会丢失。
(3) bin 目录下启动 logstash 了,配置文件设置为 conf/logstash.conf
启动命令:./logstash -f ../config/logstash.conf
后台启动:nohup ./bin/logstash -f config/log.conf > log.log &
(4) 配置多个文件:./logstash -f ../config 指定启动目录,然后启动目录下配置多个*.conf文件。里面指定不同的 logpath。
4.安装 ElasticSearch
ELK 中的核心,启动的时候一定要注意,因为 es 不可以进行 root 账户启动,所以你还需要重新添加一个账户,我这里是 apps。
(1) 解压 es
(2) 到 config 修改配置文件:
cluster.name: my.elk #集群名称,如果有多个集群,那么每个集群名就得是唯一的node.name: node-192.168.0.8 #节点名称node.master: true #该节点是否是master,true表示是的,false表示否,默认是truenode.data: true #该节点是否存储数据,默认true表示是的http.port: 9200 #http访问端口,默认是9200,通过这个端口,调用方可以索引查询请求transport.tcp.port: 9300 #节点之间通信的端口,默认为9300network.host: 0.0.0.0 #访问地址 配置外网访问#discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:8300"]#node.max_local_storage_nodes: 2 #设置一台机子能运行的节点数目,一般采用默认的1即可,因为我们一般也只在一台机子上部署一个节点
启动命令:./bin/elasticSearch ``–``d 启动。-d表示后台启动
(3)安装 head 插件
在bin目录下:./`` plugin`` install mobz/ elasticsearch-head
验证是否已经成功:http://x.x.x.x:9200
访问图形界面:http://192.168.0.8:9200/_plugin/head/
- 安装 kibana
这个安装比较简单,解压后在 kibana.yml 文件中指定一下你需要读取的 elasticSearch 地址和可供外网访问的bind 地址就可以了。
下面为配置文件:
elasticsearch.url: http://localhost:9200
server.host: 0.0.0.0
<br />启动命令:`./kibana`` `<br />后台启动:`nohup ./bin/kibana &`<br /> <br />**同学关心较多问题:FileBeat 和 Logstash 如何集成:**<br />filebeat 作为轻量级的 logs shipper,帮助用户将无数 client 端上的 log 文件以一种轻量级的方式转发并集中日志和文件到 ELK stack 中,不能很好的支持过滤等个性化需求。一般可采取 fileBeat 收集服务器日志,发送到 Logstash 中进行果过滤
集成:安装好 fileBeat 后只需要在 logstash 上面修改下 input,改为从 fileBeat 读取即可。
input {beats {port => filebeat的端口号,默认为5044}}
fileBeat 配置:
filebeat.inputs:- type: logenabled: truepaths:- /var/log/*.logoutput.logstash: //也可以直接配置发送到es里面去,可以查看官方文档hosts: ["url:5044"]
4. IK 分词
分词概念:就是将一句话把他分词成词组
分词算法: Tire 字典树。英文字典树:比较简单。双数组链表的概念。其算法设计的核心就是以空间换速度。可以去看我的字典树视频,里面讲了原理实现;字典树会把我们的词打散成字。形成的结构如下所示:
实践步骤:
1. IK 配置分词器:主词典,停用词:建议网上找一下有一个非常好的停用词库。
2. 注意如果没有 IKAnalyzer.cfg.xml 文件 在自己的工程下加就可以。
3. 分词粒度:IKSegmenter ik = new IKSegmenter(new StringReader(str), true); True 表示粗,false 标识细
4. 建索引的时用细粒度
5. 搜索的时候用粗粒度
参考源码:/Users/zhangchuanqiang/Downloads/图灵学院/五、VIP课程:分布式框架专题/分布式之ELK/28-es使用进阶:基于电商项目实战-赵云/es-基于电商项目实战(第三节)/my-search-api
分词应用场景
1. 敏感词过滤:只有我改写的源码才有效.网上自行下载的没有此功能
2. 做 NLP。文本分析:
3. 配合 like 查询:10w like。但是 like 又不能匹配句子,因为句子中有很多无用词。比如:图灵的哈哈 图灵/哈哈
一千万数据大致会有 1G到2G的数据 ES 不能链表查询,连表查的情况,会放在一个里面,表做冗余字段。
5. Lucene 原理
倒排索引:因为我们形成的是一个 value->key 的结构所以称之为倒排索引。
倒排索引是 存储在内存中,数据存储在磁盘。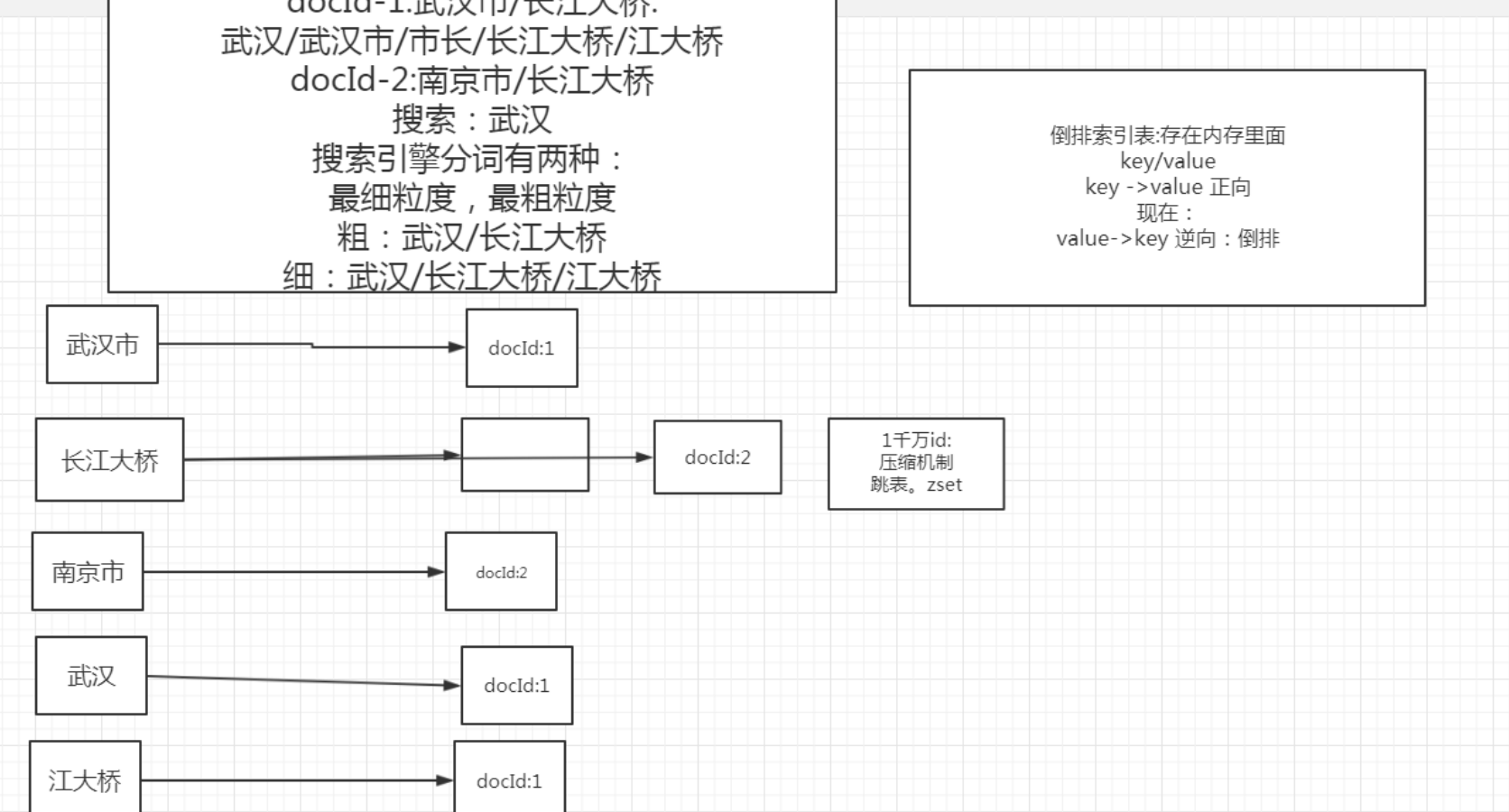
分词对Lucene的意义:
- Lucene 其核心就是一个倒排索引库,在建立索引的时候需要先将文本进行分词。再根据分好的词建立与文档的对应关系。
- 分词的好坏直接决定 lucene 查询的 精准度
- 分词还可以直接决定索引的大小。
ES 默认的分词:一个个字的分开。内存爆炸。搜到很多没用的。
ES 和 Lucene 是什么关系?
ES 基于 Lucene。只是在这基础上做出来一个分布式索引库,提供了集群的概念,还提供了api查询接口。Es和solr是一样的原理。
1000w 商品数据,要你做一个搜索功能?
分词加 like 不行(适用10w级)这个不必要用 es。维护成本高 ,ES 适用千万级以上,稳定性搞,查询量大,ES 支持分布式查询。
最佳方案:分词+Lucene(单机版),但是不适用高并发。

若有收获,就点个赞吧
0 人点赞
