前言
如何设置
partition的数量 ?
但是老实说,这个问题想回答好,其实并不太容易,因为这里没有一个统一的标准答案,你可以根据当前这个 topic 所属业务的某个维度来,也可以按照你 kafka 的 broker 数量来决定,还可以根据 kafka 系统默认的分区数量来。
但是有一点必须要搞清楚的是,在建立 topic 时必须要确定 partition 的数量(虽然后期可以动态增加),其根本目的在于:决定后续计算引擎对数据处理的并发度。
因为对于任何一个大数据生态下的存储组件,你如何存数据一定是由你怎么使用数据来决定的,也就是你上游的数据形态必须由下游依赖的处理模式来定。
01. kafka的技术架构
虽然是分布式的存储系统,但是 kafka 却是一个**去中心化的**技术组件,它没有一般分布式系统的 master 和 slaver 的角色之分,因此不存在说哪个节点挂掉了,导致整个集群不可用。
因为没有 master 这个老大,所有的 broker 都是独立而平等的,他们之间属于一种合作共赢的关系,任何一个 kafka 集群可以由任意个 broker 实例组成。
虽然不是一般的 master 和 slaver 这种有中心化的架构,但是 kafka 也并非完全没有中心,只不过它的中心是以 partition 为单位,每个 partition 由一个 leader 和 0 或多个 follower 组成,其中这个 leader 就是中心,是数据写入的入口,这个一旦挂掉,那么这个 partition 的数据就暂时不可用,需要等待新的 leader 被选举出来
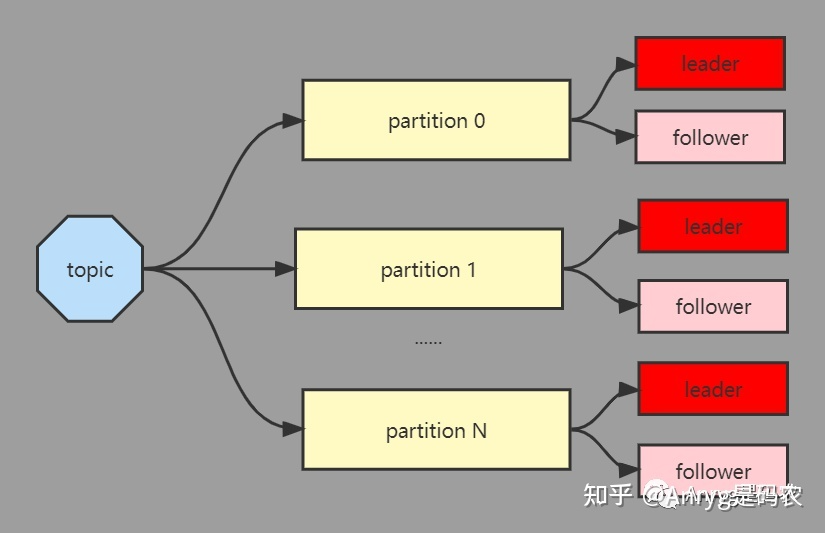
每个 topic 通过若干个 partition 来分治,核心目的除了分摊单个 broker 的压力(IO压力、存储压力、连接压力等)外,还有一个很重要的原因是给后续的计算引擎提供一个很好的[并行度],让数据处理的效率更高。
- 分摊 broker 的压力
- 提高消费的并行度
我们都知道在用分布式计算引擎消费kafka的数据时,都会指定一个[Consumer Group],那为什么不是单个 Consumer,而是Group呢?原因就是在消费 Topic 数据时(一个或者多个),一般都有多个 partition 组成,而我们需要一个 partition 对应一个consumer,因此消费多个 partition 的 consumer 就构成了一个Group。
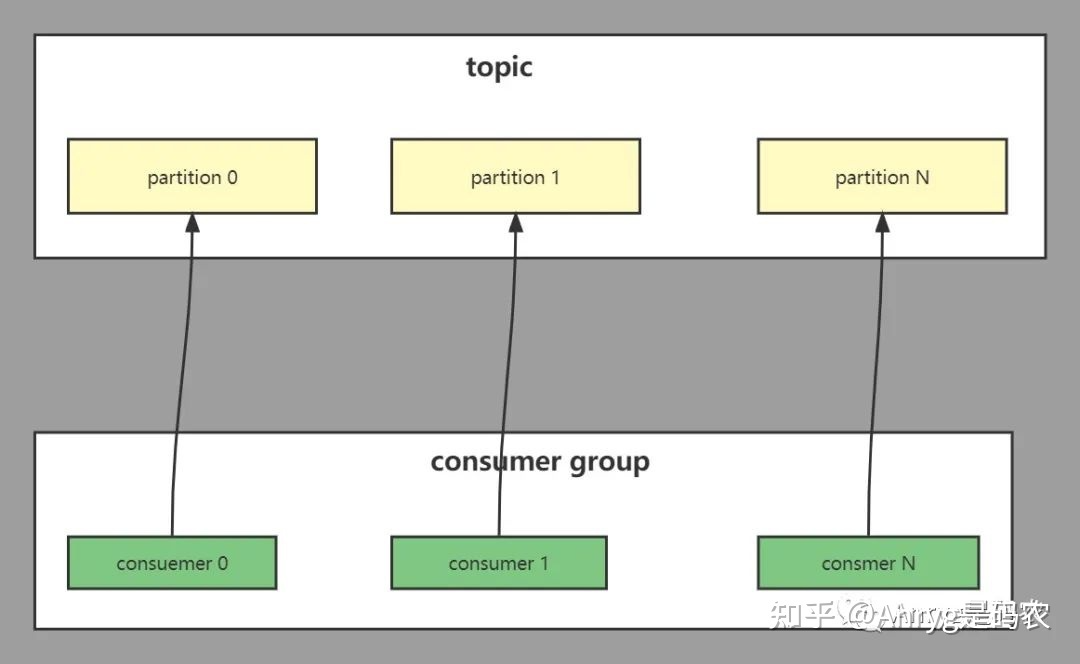
02. 根据业务特点确定 partition 数量
怎么理解呢?我们都知道一个 topic 肯定是跟某个业务强相关,比如电商业务中的用户登录数据,会用一个专门的 topic,而购买数据而会用另外一个 topic。
以用户登录数据为例,定多少个 partition,可以根据你后续要如何对这个数据进行处理来定。
我们知道 partition 之间的数据是没有办法保证有序,且没有业务逻辑关系的,默认情况下,当用客户端向某个 topic 灌数据时,如果没有指定消息的 key 和要写入的 partition,那么数据会以 round-robin 的方式均匀写到 topic 的每个 partition 中。
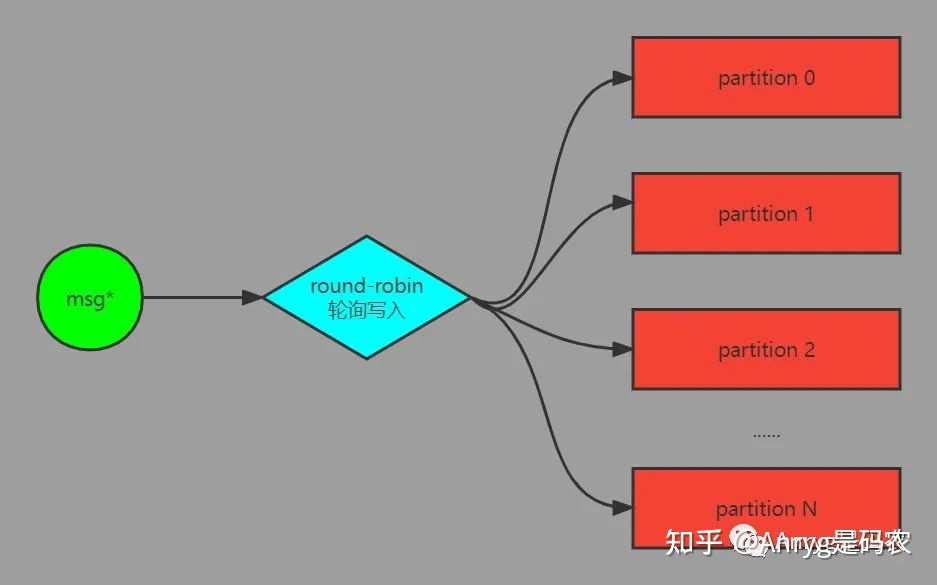
假如这些数据来自全国各地,而你后续要对这个数据根据各个省份的登录情况进行汇总统计,按照这种大家最常见的数据写入方式,那么后续计算引擎对其处理的流程大概是这样的: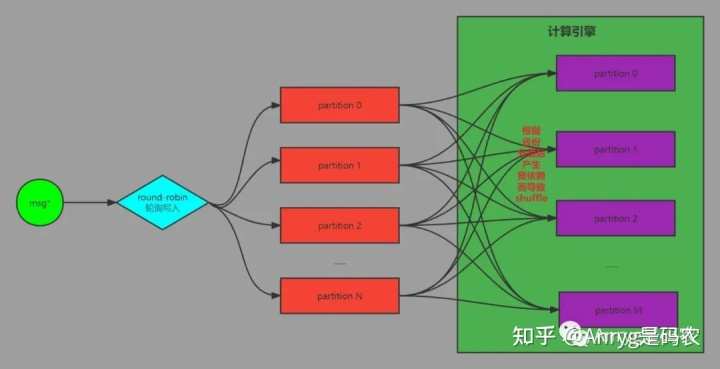
这样做最大的坏处就是数据读到计算引擎后,会因为根据省份分组而导致宽依赖的产生,而宽依赖则会导致计算引擎的shuffle操作,而shuffle是计算引擎性能的坟墓,需要尽可能的避免。
但是如果根据省份分组这个业务特点,将你的 partition 数量设置为省份的个数,且每条数据在写入 partition 前以当前省份作为消息的 key,例如:key: hubei value: msg
通过 kafka 的 api 就是这样来写:
/**如果添加key,相同key的数据只会推送到同一个partition*/ProducerRecord record = new ProducerRecord<>(topic, "hubei", msg);
这样,数据就会按照这个 key 进行 hash 然后跟 partition 的个数取模,最终进入到特定的 partition 中。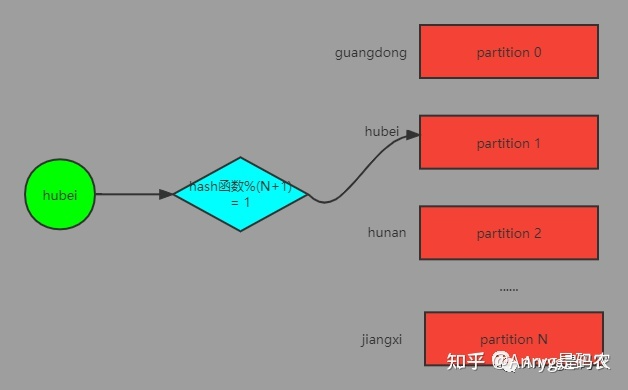
这样,同一个省份的数据就必然处在同一个partition中,而又因为partition的数量跟省份的数量保持一致。因此,每个 partition 中的数据都来自某一个省份,后续计算引擎对其分组处理就是这个样子: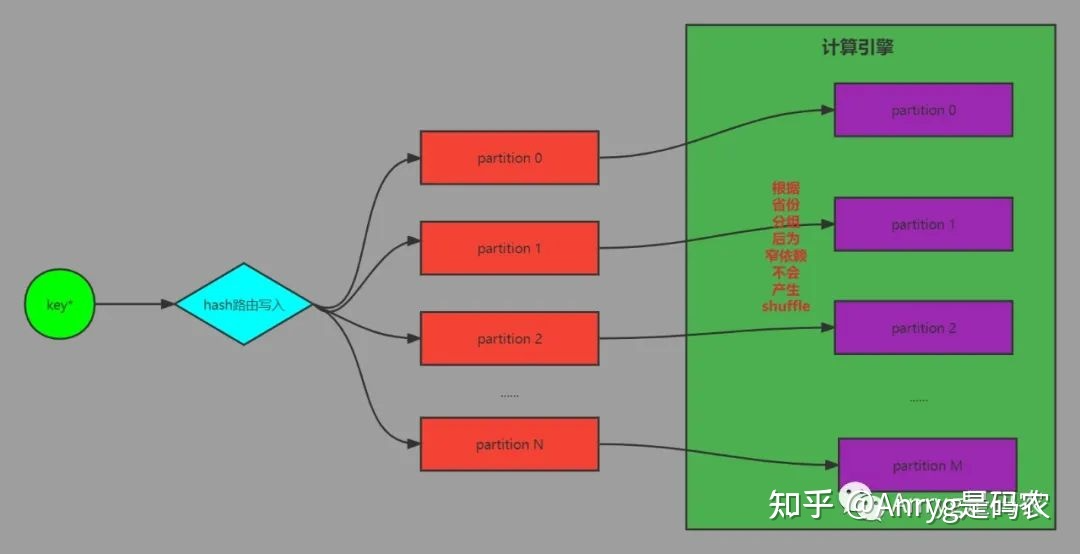
kafka 的分区数据跟计算引擎的分区数据完全一一对应,这样最大的好处在于,当计算引擎读取数据后,对数据进行聚合分组时,因为数据在写入kafka时就已经按业务分好了组,因此当你用同样的的并行度来取数据时,此时的数据是天然按照省份分组的,因此避免了宽依赖的产生,而没有宽依赖就不会有shuffle,数据的处理性能自然大大提升。
因此,通过 key 路由的方式写入 partition,可以大大提高后续数据的处理效率。这个也是我们在实际项目中优化计算速度很重要的一个优化点。
03. 根据并行度确定 partition 数量
如果说你的业务处理并没有像上面那样对数据有分组统计的要求,单纯的只需要对数据进行分布式处理就好了。
那么就可以根据你后续数据要处理的并行度来定 partition 个数,为了防止单个节点负载过高,可以定为跟 broker 数量一样,或者跟后续计算引擎要并行的数量一致。
这个时候有同学会说,何必那么麻烦,我的 partition 随便定一个比较小的值就可以了,不用考虑后续数据处理的并行度,因为这个并行度我可以随时改的。
确实可以改,比如拿 spark 举例,你可以通过 reparation 和 coalesce 这两个函数来修改你要想的并行度。但是,你知道这样带来了什么代价吗?
来看下源码的解释:
将原本小的 partition 数改大,必定会导致宽依赖的产生,而宽依赖则一定会产生 shuffle,既然产生shuffle,那数据处理效率也就必然下降。
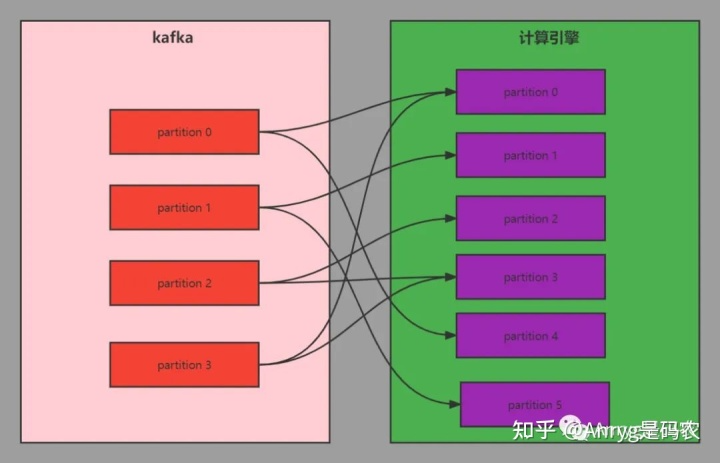
因此,并不是像一些同学所说的没有关系,只是看这个关系会对你产生多大的影响罢了。
04. 说说分区数与并行度
发现有些同学搞不清楚这两种的区别,这里说说我的理解。
- 分区数(partition 数量):由数据源决定,是个相对静态的概念,一旦这个数据源决定了,那么你用计算引擎读取数据时候的初始分区数量也就定了,反映的是数据源的划分多少;
- 并行度:由消费数据源的计算引擎决定,是通过任务提交参数来定义的,是一个相对可调整的数值,是相对动态的,反映的是可以并行同时处理多少数据源的数据;
两者关系: 并行度 <= 分区数。
05 关于 Kafka 有序
- 在 Kafka 中 Partition (分区) 是真正保存消息的地方,发送的消息都存放在这里。Partition (分区)又存在于 Topic(主题)中,并且一个 Topic(主题)可以指定多个 Partition(分区)。
- 在 Kafka 中,只保证 Partition(分区)内有序,不保证 Topic 所有分区都是有序的。
- 所以 Kafka 要保证消息的消费顺序,可以有2种方法:
- 1个 Topic(主题)只创建 1 个 Partition(分区),这样生产者的所有数据都发送到了一个 Partition(分区),保证了消息的消费顺序。
- 生产者在发送消息的时候指定要发送到哪个 Partition(分区)。
我们需要将 producer 发送的数据封装成一个 ProducerRecord 对象。
- 指明 partition 的情况下,直接将指明的值直接作为 partiton 值;
- 没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值;
- 既没有 partition 值又没有 key 值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition 值,也就是常说的 round-robin 算法。

若有收获,就点个赞吧
0 人点赞
