1. Canal 介绍
canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
它是阿里巴巴纯 Java 开发的开源软件,它主要是一个应用和 mysql 之间的数据同步中间件。类似 Mq 等这样的消息中间件,但他不需要借助其他的系统发消息,他是直接监听 Mysql 数据库,它伪装成 mysql 的从库通过对 binlog 日志的解析从而实现了数据库增删改查的监听。
源码地址:https://github.com/alibaba/canal
主要业务场景
- 数据库实时备份
- 数据库镜像
- 搜索引擎索引更新&建立
- 业务缓存的更新
- 充当消息组件(订单变更、商品资料变更)
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
2. Canal 工作原理
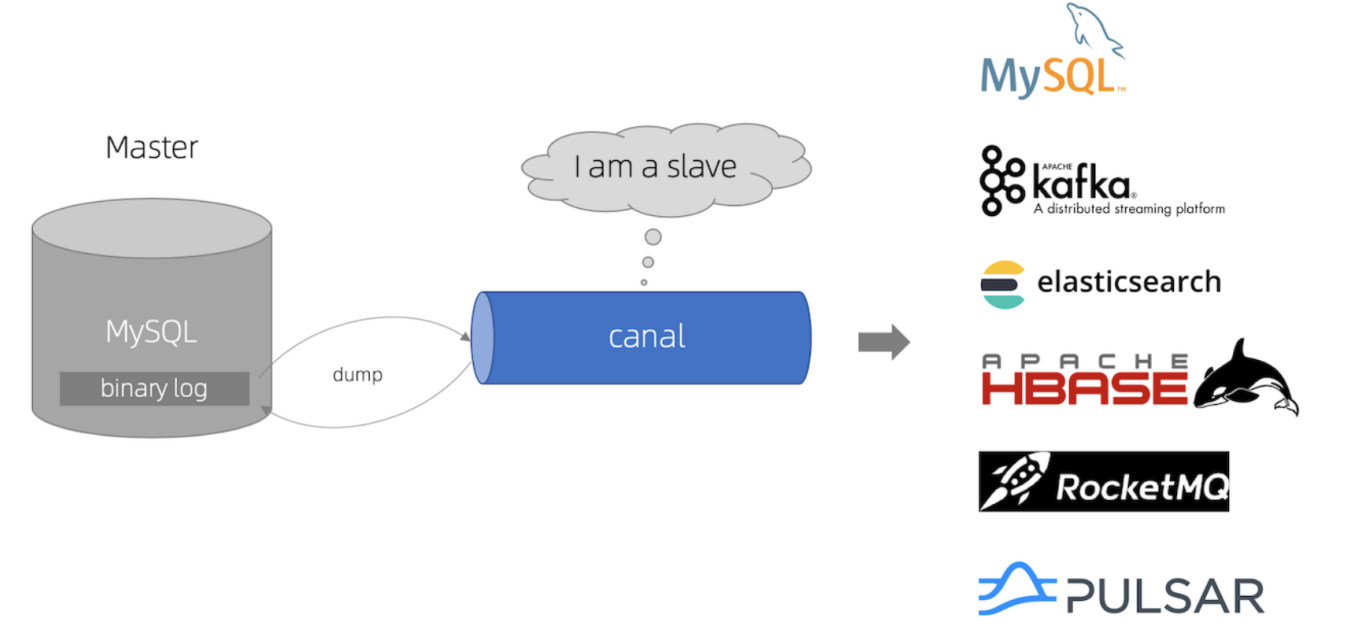
- canal 模拟 mysql slave 的交互协议,伪装自己为 mysql slave,向 mysql master 发送 dump 协议
- mysql master 收到 dump 请求,开始推送 binary log 给 slave (也就是 canal)
- canal 解析 binary log 对象(原始为 byte 流)
2.1 架构
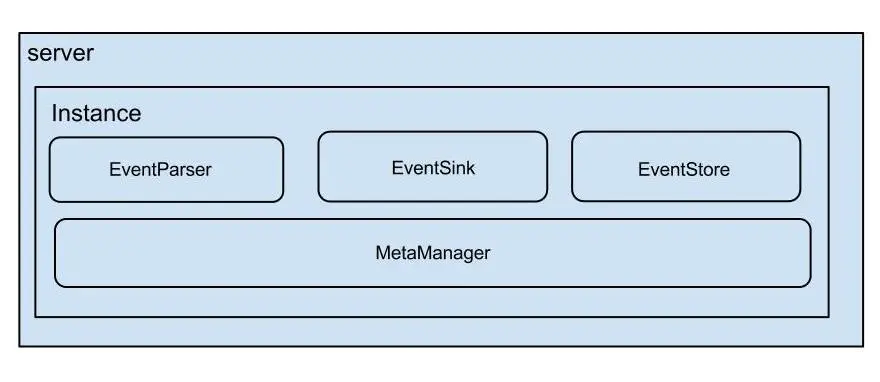
说明:
- server代表一个canal运行实例,对应于一个jvm
- instance对应于一个数据队列 (1个server对应1..n个instance)
instance模块:
- eventParser (数据源接入,模拟slave协议和master进行交互,协议解析)
- eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
- eventStore (数据存储)
- metaManager (增量订阅&消费信息管理器)
2.2 mysql 的 Binlay Log 介绍
简单点说:
- mysql 的 binlog 是多文件存储,定位一个 LogEvent 需要通过 binlog filename + binlog position,进行定位
- mysql 的 binlog 数据格式,按照生成的方式,主要分为:statement-based、row-based、mixed。
mysql> show variables like 'binlog_format';+---------------+-------+| Variable_name | Value |+---------------+-------+| binlog_format | ROW |+---------------+-------+1 row in set (0.00 sec)
目前 canal 支持所有模式的增量订阅(但配合同步时,因为 statement 只有 sql,没有数据,无法获取原始的变更日志,所以一般建议为 ROW 模式)
2.3 EventParser设计
大致过程:
整个parser过程大致可分为几步:
- Connection获取上一次解析成功的位置 (如果第一次启动,则获取初始指定的位置或者是当前数据库的binlog位点)
- Connection建立链接,发送BINLOG_DUMP指令
// 0. write command number
// 1. write 4 bytes bin-log position to start at
// 2. write 2 bytes bin-log flags
// 3. write 4 bytes server id of the slave
// 4. write bin-log file name - Mysql开始推送Binaly Log
- 接收到的Binaly Log的通过Binlog parser进行协议解析,补充一些特定信息
// 补充字段名字,字段类型,主键信息,unsigned类型处理 - 传递给EventSink模块进行数据存储,是一个阻塞操作,直到存储成功
- 存储成功后,定时记录Binaly Log位置
3. Canal 环境部署
3.1 搭建 mysql
编辑 mysql 安装目录下的 my.ini 文件
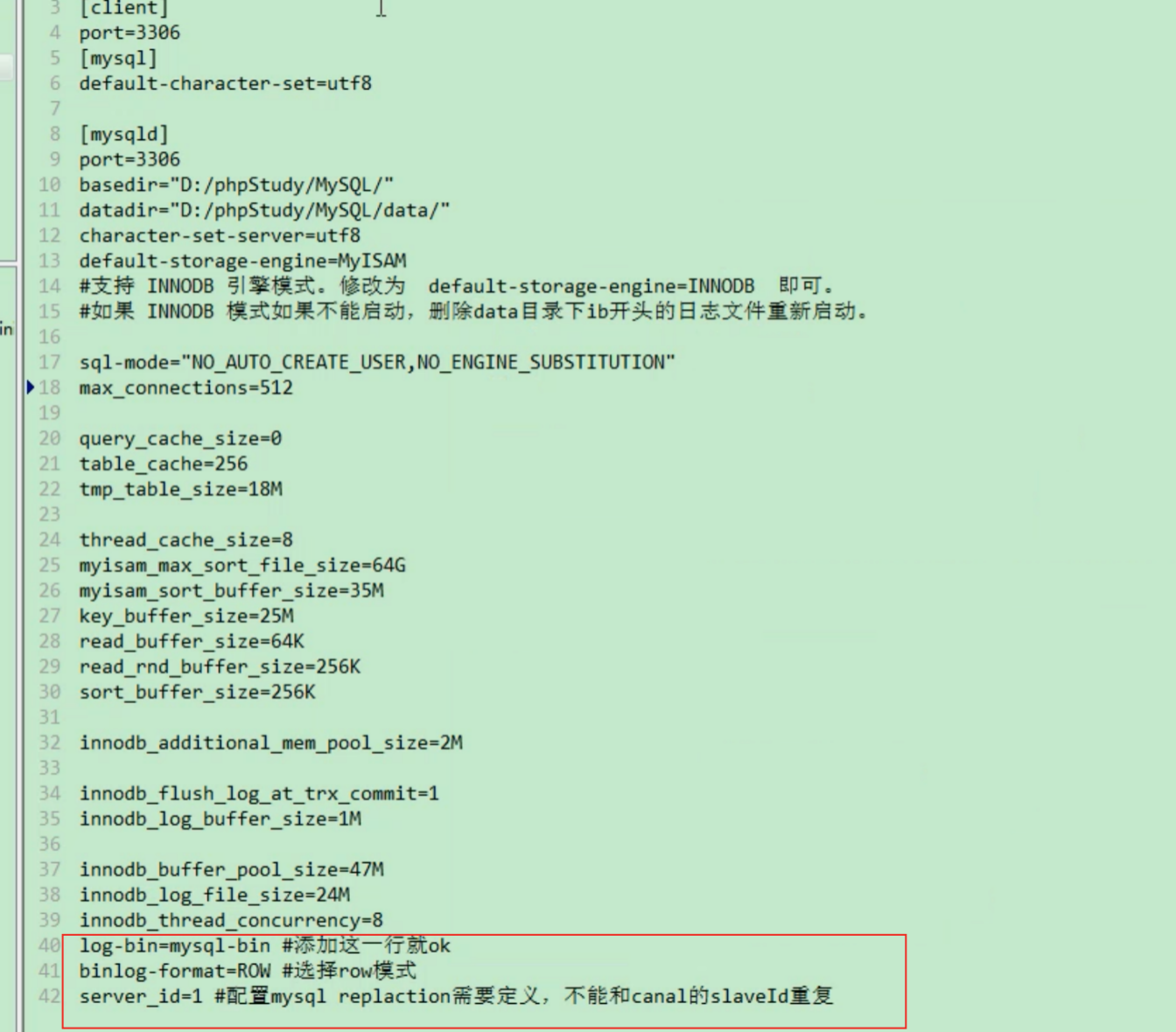
mysql需要开启binlog日志功能。配置如下:
log-bin=mysql-bin #添加这一行就 okbinlog-format=ROW #选择row模式server_id=1 #有其他的副本的话需要定义,不能和canal的slaveId重复
在 mysql 中给 canal 创建一个用户,并配置相关 slave 的权限,具体命令如下:
- 创建「canal」用户:
CREATE USER canal IDENTIFIED BY ‘canal’; - 为「canal」用户赋予相应权限:
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON . TO ‘canal’@’%’; - 刷新权限:
FLUSH PRIVILEGES; - 上述操作全部做完后,重启下 mysql。
3.2 搭建 Canal
1.编译 canal
git clone git@github.com:alibaba/canal.gitcd canal;mvn clean install -Dmaven.test.skip -Denv=release
编译完成后,会在根目录下产生 target/canal.deployer-$version.tar.gz
你也可以在github上下载编译好的包:https://github.com/alibaba/canal/releases
2.解压缩
mkdir /tmp/canaltar zxvf canal.deployer-$version.tar.gz -C /tmp/canal
解压完成后,进入/tmp/canal目录,可以看到如下结构:
drwxr-xr-x 2 jianghang jianghang 136 2013-02-05 21:51 bindrwxr-xr-x 4 jianghang jianghang 160 2013-02-05 21:51 confdrwxr-xr-x 2 jianghang jianghang 1.3K 2013-02-05 21:51 libdrwxr-xr-x 2 jianghang jianghang 48 2013-02-05 21:29 logs
3.修改配置
vi conf/example/instance.properties
################################################### mysql serverIdcanal.instance.mysql.slaveId = 1234#position info,需要改成自己的数据库信息canal.instance.master.address = 127.0.0.1:3306canal.instance.master.journal.name =canal.instance.master.position =canal.instance.master.timestamp =#canal.instance.standby.address =#canal.instance.standby.journal.name =#canal.instance.standby.position =#canal.instance.standby.timestamp =#username/password,需要改成自己的数据库信息canal.instance.dbUsername = canalcanal.instance.dbPassword = canalcanal.instance.defaultDatabaseName =canal.instance.connectionCharset = UTF-8#table regexcanal.instance.filter.regex = .*\..*#################################################
如果系统是1个 cpu,需要将canal.instance.parser.parallel设置为false
3.启动
4.查看日志**
vi logs/canal/canal.log
2013-02-05 22:45:27.967 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## start the canal server.2013-02-05 22:45:28.113 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ## start the canal server[10.1.29.120:11111]2013-02-05 22:45:28.210 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## the canal server is running now ......
具体 instance 的日志:
vi logs/example/example.log
2013-02-05 22:50:45.636 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [canal.properties]2013-02-05 22:50:45.641 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [example/instance.properties]2013-02-05 22:50:45.803 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start CannalInstance for 1-example2013-02-05 22:50:45.810 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start successful....
5.关闭
sh bin/stop.sh
3.3 Canal HA 模式:
- 安装 zk
- 修改配置文件
调用端链接方式修改
使用 zookeeper 管理,但是同时只有一台服务可以从 mysql 中读取数据,在机器没有挂的情况下,其他的都在等待。
4. Java 调用 API
4.1 增加依赖
<dependency><groupId>com.alibaba.otter</groupId><artifactId>canal.client</artifactId><version>1.1.2</version></dependency>
4.2 核心 API 介绍
在了解具体API之前,需要提前了解下 canal client 的类设计,这样才可以正确的使用好canal.
大致分为几部分:
- ClientIdentity
canal client和server交互之间的身份标识,目前clientId写死为1001. (目前canal server上的一个instance只能有一个client消费,clientId的设计是为1个instance多client消费模式而预留的,暂时不需要理会) - CanalConnector
SimpleCanalConnector/ClusterCanalConnector : 两种connector的实现,simple针对的是简单的ip直连模式,cluster针对多ip的模式,可依赖CanalNodeAccessStrategy进行failover控制 - CanalNodeAccessStrategy
SimpleNodeAccessStrategy/ClusterNodeAccessStrategy:两种failover的实现,simple针对给定的初始ip列表进行failover选择,cluster基于zookeeper上的cluster节点动态选择正在运行的canal server. - ClientRunningMonitor/ClientRunningListener/ClientRunningData
client running相关控制,主要为解决client自身的failover机制。canal client允许同时启动多个canal client,通过running机制,可保证只有一个client在工作,其他client做为冷备. 当运行中的client挂了,running会控制让冷备中的client转为工作模式,这样就可以确保canal client也不会是单点. 保证整个系统的高可用性.
javadoc查看:
- CanalConnector :(http://alibaba.github.io/canal/apidocs/1.0.13/com/alibaba/otter/canal/client/CanalConnector.html)
4.2.1 server/client交互协议


get/ack/rollback协议介绍:
- Message getWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回的对象为Message,包含的内容为:
a. batch id 唯一标识
b. entries 具体的数据对象,可参见下面的数据介绍 - getWithoutAck(int batchSize, Long timeout, TimeUnit unit),相比于getWithoutAck(int batchSize),允许设定获取数据的timeout超时时间
a. 拿够batchSize条记录或者超过timeout时间
b. timeout=0,阻塞等到足够的batchSize - void rollback(long batchId),顾命思议,回滚上次的get请求,重新获取数据。基于get获取的batchId进行提交,避免误操作
- void ack(long batchId),顾命思议,确认已经消费成功,通知server删除数据。基于get获取的batchId进行提交,避免误操作
canal的get/ack/rollback协议和常规的jms协议有所不同,允许get/ack异步处理,比如可以连续调用get多次,后续异步按顺序提交ack/rollback,项目中称之为流式api.
流式api设计的好处:
- get/ack异步化,减少因ack带来的网络延迟和操作成本 (99%的状态都是处于正常状态,异常的rollback属于个别情况,没必要为个别的case牺牲整个性能)
- get获取数据后,业务消费存在瓶颈或者需要多进程/多线程消费时,可以不停的轮询get数据,不停的往后发送任务,提高并行化. (作者在实际业务中的一个case:业务数据消费需要跨中美网络,所以一次操作基本在200ms以上,为了减少延迟,所以需要实施并行化)
流式api设计:
- 每次get操作都会在meta中产生一个mark,mark标记会递增,保证运行过程中mark的唯一性
- 每次的get操作,都会在上一次的mark操作记录的cursor继续往后取,如果mark不存在,则在last ack cursor继续往后取
- 进行ack时,需要按照mark的顺序进行数序ack,不能跳跃ack. ack会删除当前的mark标记,并将对应的mark位置更新为last ack cursor
- 一旦出现异常情况,客户端可发起rollback情况,重新置位:删除所有的mark, 清理get请求位置,下次请求会从last ack cursor继续往后取

4.2.2 数据对象格式简单介绍
EntryHeaderlogfileName [binlog文件名]logfileOffset [binlog position]executeTime [binlog里记录变更发生的时间戳,精确到秒]schemaNametableNameeventType [insert/update/delete类型]entryType [事务头BEGIN/事务尾END/数据ROWDATA]storeValue [byte数据,可展开,对应的类型为RowChange]RowChangeisDdl [是否是ddl变更操作,比如create table/drop table]sql [具体的ddl sql]rowDatas [具体insert/update/delete的变更数据,可为多条,1个binlog event事件可对应多条变更,比如批处理]beforeColumns [Column类型的数组,变更前的数据字段]afterColumns [Column类型的数组,变更后的数据字段]ColumnindexsqlType [jdbc type]name [column name]isKey [是否为主键]updated [是否发生过变更]isNull [值是否为null]value [具体的内容,注意为string文本]
说明:
- 可以提供数据库变更前和变更后的字段内容,针对binlog中没有的name,isKey等信息进行补全
- 可以提供ddl的变更语句
- insert只有after columns, delete只有before columns,而update则会有before / after columns数据.
4.2.3 Client使用例子
1.创建Connector
a. 创建 SimpleCanalConnector (直连ip,不支持server/client的failover机制)
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(AddressUtils.getHostIp(),11111), destination, "", "");
b. 创建 ClusterCanalConnector (基于zookeeper获取canal server ip,支持server/client的failover机制)
CanalConnector connector = CanalConnectors.newClusterConnector("10.20.144.51:2181", destination, "", "");
c. 创建 ClusterCanalConnector (基于固定canal server的地址,支持固定的 server ip 的 failover 机制,不支持client的 failover 机制
CanalConnector connector = CanalConnectors.newClusterConnector(Arrays.asList(new InetSocketAddress(AddressUtils.getHostIp(),11111)), destination,"", "");
2.get/ack/rollback使用

2.3.3.RowData数据处理

5. 实战
5.1 创建链接
// 创建链接CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("172.0.0.1",11111), "example", "", "");connector.connect();connector.subscribe(".*\\..*");connector.rollback();
5.2 获取数据
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据long batchId = message.getId();int size = message.getEntries().size();
5.3 数据处理
private static void printEntry(List<Entry> entrys) {for (Entry entry : entrys) {if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {continue;}RowChange rowChage = null;try {rowChage = RowChange.parseFrom(entry.getStoreValue());} catch (Exception e) {throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),e);}EventType eventType = rowChage.getEventType();System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),eventType));for (RowData rowData : rowChage.getRowDatasList()) {if (eventType == EventType.DELETE) {printColumn(rowData.getBeforeColumnsList());} else if (eventType == EventType.INSERT) {printColumn(rowData.getAfterColumnsList());} else {System.out.println("-------> before");printColumn(rowData.getBeforeColumnsList());System.out.println("-------> after");printColumn(rowData.getAfterColumnsList());}}}}
5.4 完整代码
import java.net.InetSocketAddress;import java.util.List;import com.alibaba.otter.canal.client.CanalConnectors;import com.alibaba.otter.canal.client.CanalConnector;import com.alibaba.otter.canal.common.utils.AddressUtils;import com.alibaba.otter.canal.protocol.Message;import com.alibaba.otter.canal.protocol.CanalEntry.Column;import com.alibaba.otter.canal.protocol.CanalEntry.Entry;import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;import com.alibaba.otter.canal.protocol.CanalEntry.EventType;import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;import com.alibaba.otter.canal.protocol.CanalEntry.RowData;public class SimpleCanalClientExample {public static void main(String args[]) {// 创建链接CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(AddressUtils.getHostIp(),11111), "example", "", "");int batchSize = 1000;int emptyCount = 0;try {connector.connect();connector.subscribe(".*\\..*");connector.rollback();int totalEmptyCount = 120;while (emptyCount < totalEmptyCount) {Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据long batchId = message.getId();int size = message.getEntries().size();if (batchId == -1 || size == 0) {emptyCount++;System.out.println("empty count : " + emptyCount);try {Thread.sleep(1000);} catch (InterruptedException e) {}} else {emptyCount = 0;// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);printEntry(message.getEntries());}connector.ack(batchId); // 提交确认// connector.rollback(batchId); // 处理失败, 回滚数据}System.out.println("empty too many times, exit");} finally {connector.disconnect();}}private static void printEntry(List<Entry> entrys) {for (Entry entry : entrys) {if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {continue;}RowChange rowChage = null;try {rowChage = RowChange.parseFrom(entry.getStoreValue());} catch (Exception e) {throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),e);}EventType eventType = rowChage.getEventType();System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),eventType));for (RowData rowData : rowChage.getRowDatasList()) {if (eventType == EventType.DELETE) {printColumn(rowData.getBeforeColumnsList());} else if (eventType == EventType.INSERT) {printColumn(rowData.getAfterColumnsList());} else {System.out.println("-------> before");printColumn(rowData.getBeforeColumnsList());System.out.println("-------> after");printColumn(rowData.getAfterColumnsList());}}}}private static void printColumn(List<Column> columns) {for (Column column : columns) {System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());}}
5.5 运行Client
启动 Canal Client 后,可以从控制台从看到类似消息:
empty count : 1empty count : 2empty count : 3empty count : 4
此时代表当前数据库无变更数据,触发数据库变更
mysql> use test;Database changedmysql> CREATE TABLE `xdual` (-> `ID` int(11) NOT NULL AUTO_INCREMENT,-> `X` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,-> PRIMARY KEY (`ID`)-> ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 ;Query OK, 0 rows affected (0.06 sec)mysql> insert into xdual(id,x) values(null,now());Query OK, 1 row affected (0.06 sec)
可以从控制台中看到:
empty count : 1empty count : 2empty count : 3empty count : 4================> binlog[mysql-bin.001946:313661577] , name[test,xdual] , eventType : INSERTID : 4 update=trueX : 2013-02-05 23:29:46 update=true
注意:
- 客户端(tomcat 服务)垮掉,此时修改数据库,然后再启动客户端,数据是不会丢的,重启后能监听到数据库更改的数据(mysql 不分片的情况下)。
- 如果不想客户端启动后加载之前数据库的操作,可以删掉
mata.dat文件后再进行客户端的启动 - mysql 分片时,mysql 有多少个,就有多少个配置
6. 投递数据到 Kafka
canal 1.1.1 版本之后, 默认支持将 canal server 接收到的 binlog 数据直接投递到 MQ, 目前默认支持的 MQ 系统有:
- kafka: (https://github.com/apache/kafka)
- RocketMQ :(https://github.com/apache/rocketmq)
6.1 配置修改
基于前面第二章节内容我们搭建的 canal server(Billow自编译版本为1.1.3,支持动态Topic配置),我们在instance 的配置文件中做配置的修改。6.1.1 修改instance 配置文件
vi conf/example/instance.properties
# 按需修改成自己的数据库信息#################################################...canal.instance.master.address=192.168.1.20:3306# username/password,数据库的用户名和密码...canal.instance.dbUsername = canalcanal.instance.dbPassword = canal...# mq configcanal.mq.topic=example# 针对库名或者表名发送动态topic#canal.mq.dynamicTopic=mytest,.*,mytest.user,mytest\\..*,.*\\..*canal.mq.partition=0# hash partition config#canal.mq.partitionsNum=3#库名.表名: 唯一主键,多个表之间用逗号分隔#canal.mq.partitionHash=mytest.person:id,mytest.role:id#################################################
对应 ip 地址的 MySQL 数据库需进行相关初始化与设置, 可参考前面 Billow 发的文章:
dynamicTopic 规则: 表达式如果只有库名则匹配库名的数据都会发送到对应名称 topic, 如果是库名.表名则匹配的数据会发送到以’库名_表名’为名称的 topic。如要指定 topic名称,则可以配置:
canal.mq.dynamicTopic=examp2:.*;exmaple3:mytest\\..*,mytest2\\..*;example4:mytest3.user
以 topic 名 ‘:’ 正则规则作为配置, 多个topic配置之间以 ‘;’隔开, message 会发送到所有符合规则的 topic
6.1.2 修改canal 配置文件
vi /usr/local/canal/conf/canal.properties
# ...# 可选项: tcp(默认), kafka, RocketMQcanal.serverMode = kafka# ...# kafka/rocketmq 集群配置: 192.168.1.117:9092,192.168.1.118:9092,192.168.1.119:9092canal.mq.servers = 127.0.0.1:6667canal.mq.retries = 0canal.mq.batchSize = 16384canal.mq.maxRequestSize = 1048576canal.mq.lingerMs = 1canal.mq.bufferMemory = 33554432# Canal的batch size, 默认50K, 由于kafka最大消息体限制请勿超过1M(900K以下)canal.mq.canalBatchSize = 50# Canal get数据的超时时间, 单位: 毫秒, 空为不限超时canal.mq.canalGetTimeout = 100# 是否为flat json格式对象canal.mq.flatMessage = truecanal.mq.compressionType = nonecanal.mq.acks = all# kafka消息投递是否使用事务canal.mq.transaction = false
6.2 mq相关参数说明


canal.mq.dynamicTopic 表达式说明
canal 1.1.3版本之后, 支持配置格式:schema 或 schema.table,多个配置之间使用逗号分隔
- 例子1:test.test 指定匹配的单表,发送到以 test_test为名字的topic上
- 例子2:...* 匹配所有表,每个表都会发送到各自表名的topic上
- 例子3:test 指定匹配对应的库,一个库的所有表都会发送到库名的topic上
- 例子4:test.* 指定匹配的表达式,针对匹配的表会发送到各自表名的topic上
- 例子5:test,test1.test1,指定多个表达式,会将test库的表都发送到test的topic上,test1.test1的表发送到对应的test1_test1 topic上,其余的表发送到默认的canal.mq.topic值
支持指定topic名称匹配, 配置格式:topicName:schema 或 schema.table,多个配置之间使用逗号分隔, 多组之间使用 ; 分隔
- 例子:test:test,test1.test1;test2:test2,test3.test1 针对匹配的表会发送到指定的topic上
大家可以结合自己的业务需求,设置匹配规则,建议MQ开启自动创建topic的能力
表达式说明
canal 1.1.3版本之后, 支持配置格式:schema.table:pk1^pk2,多个配置之间使用逗号分隔
- 例子1:test.test:pk1^pk2 指定匹配的单表,对应的hash字段为pk1 + pk2
- 例子2:...*:id 正则匹配,指定所有正则匹配的表对应的hash字段为id
- 例子3:...*:
 正则匹配,指定所有正则匹配的表对应的hash字段为表主键(自动查找)
正则匹配,指定所有正则匹配的表对应的hash字段为表主键(自动查找) - 例子4: 匹配规则啥都不写,则默认发到0这个partition上
- 例子5:...* ,不指定pk信息的正则匹配,将所有正则匹配的表,对应的hash字段为表名
- 按表hash: 一张表的所有数据可以发到同一个分区,不同表之间会做散列 (会有热点表分区过大问题)
- 例子6: test.test:id,...* , 针对test的表按照id散列,其余的表按照table散列
注意:大家可以结合自己的业务需求,设置匹配规则,多条匹配规则之间是按照顺序进行匹配(命中一条规则就返回)
mq 顺序性问题
binlog本身是有序的,写入到mq之后如何保障顺序是很多人会比较关注,在issue里也有非常多人咨询了类似的问题,这里做一个统一的解答
- canal目前选择支持的kafka/rocketmq,本质上都是基于本地文件的方式来支持了分区级的顺序消息的能力,也就是binlog写入mq是可以有一些顺序性保障,这个取决于用户的一些参数选择
- canal支持MQ数据的几种路由方式:单topic单分区,单topic多分区、多topic单分区、多topic多分区
- canal.mq.dynamicTopic,主要控制是否是单topic还是多topic,针对命中条件的表可以发到表名对应的topic、库名对应的topic、默认topic name
- canal.mq.partitionsNum、canal.mq.partitionHash,主要控制是否多分区以及分区的partition的路由计算,针对命中条件的可以做到按表级做分区、pk级做分区等
- canal的消费顺序性,主要取决于描述2中的路由选择,举例说明:
- 单topic单分区,可以严格保证和binlog一样的顺序性,缺点就是性能比较慢,单分区的性能写入大概在2~3k的TPS
- 多topic单分区,可以保证表级别的顺序性,一张表或者一个库的所有数据都写入到一个topic的单分区中,可以保证有序性,针对热点表也存在写入分区的性能问题
- 单topic、多topic的多分区,如果用户选择的是指定table的方式,那和第二部分一样,保障的是表级别的顺序性(存在热点表写入分区的性能问题),如果用户选择的是指定pk hash的方式,那只能保障的是一个pk的多次binlog顺序性 ** pk hash的方式需要业务权衡,这里性能会最好,但如果业务上有pk变更或者对多pk数据有顺序性依赖,就会产生业务处理错乱的情况. 如果有pk变更,pk变更前和变更后的值会落在不同的分区里,业务消费就会有先后顺序的问题,需要注意
启动
cd /usr/local/canal/sh bin/startup.sh
查看日志
a.查看 logs/canal/canal.log
vi logs/canal/canal.log
b. 查看 instance 的日志:
vi logs/example/example.log
关闭
cd /usr/local/canal/sh bin/stop.sh
MQ数据消费
canal 源码中有实例代码;如下
public class CanalKafkaClientExample {protected final static Logger logger = LoggerFactory.getLogger(CanalKafkaClientExample.class);private KafkaCanalConnector connector;private static volatile boolean running = false;private Thread thread = null;private Thread.UncaughtExceptionHandler handler = new Thread.UncaughtExceptionHandler() {public void uncaughtException(Thread t, Throwable e) {logger.error("parse events has an error", e);}};public CanalKafkaClientExample(String zkServers, String servers, String topic, Integer partition, String groupId){connector = new KafkaCanalConnector(servers, topic, partition, groupId, null, false);}public static void main(String[] args) {try {final CanalKafkaClientExample kafkaCanalClientExample = new CanalKafkaClientExample(AbstractKafkaTest.zkServers,AbstractKafkaTest.servers,AbstractKafkaTest.topic,AbstractKafkaTest.partition,AbstractKafkaTest.groupId);logger.info("## start the kafka consumer: {}-{}", AbstractKafkaTest.topic, AbstractKafkaTest.groupId);kafkaCanalClientExample.start();logger.info("## the canal kafka consumer is running now ......");Runtime.getRuntime().addShutdownHook(new Thread() {public void run() {try {logger.info("## stop the kafka consumer");kafkaCanalClientExample.stop();} catch (Throwable e) {logger.warn("##something goes wrong when stopping kafka consumer:", e);} finally {logger.info("## kafka consumer is down.");}}});while (running);} catch (Throwable e) {logger.error("## Something goes wrong when starting up the kafka consumer:", e);System.exit(0);}}public void start() {Assert.notNull(connector, "connector is null");thread = new Thread(new Runnable() {public void run() {process();}});thread.setUncaughtExceptionHandler(handler);thread.start();running = true;}public void stop() {if (!running) {return;}running = false;if (thread != null) {try {thread.join();} catch (InterruptedException e) {// ignore}}}private void process() {while (!running) {try {Thread.sleep(1000);} catch (InterruptedException e) {}}while (running) {try {connector.connect();connector.subscribe();while (running) {try {List<Message> messages = connector.getListWithoutAck(100L, TimeUnit.MILLISECONDS); // 获取messageif (messages == null) {continue;}for (Message message : messages) {long batchId = message.getId();int size = message.getEntries().size();if (batchId == -1 || size == 0) {// try {// Thread.sleep(1000);// } catch (InterruptedException e) {// }} else {// printSummary(message, batchId, size);// printEntry(message.getEntries());logger.info(message.toString());}}connector.ack(); // 提交确认} catch (Exception e) {logger.error(e.getMessage(), e);}}} catch (Exception e) {logger.error(e.getMessage(), e);}}try {connector.unsubscribe();} catch (WakeupException e) {// No-op. Continue process}connector.disconnect();}}
资料

若有收获,就点个赞吧
0 人点赞
