1. Hystrix 是什么?
在分布式系统中,每个服务都可能会调用很多其他服务,被调用的那些服务就是依赖服务,有的时候某些依赖服务出现故障也是很正常的。Hystrix 可以让我们在分布式系统中对服务间的调用进行控制,加入一些调用延迟或者依赖故障的容错机制。
Hystrix 通过将依赖服务进行资源隔离,进而阻止某个依赖服务出现故障时在整个系统所有的依赖服务调用中进行蔓延;同时 Hystrix 还提供故障时的 fallback 降级机制。
总而言之,Hystrix 通过这些方法帮助我们提升分布式系统的可用性和稳定性。
1.1 Hystrix 的设计原则
- 对依赖服务调用时出现的调用延迟和调用失败进行控制和容错保护。
- 在分布式系统中,阻止某一个依赖服务的故障在整个系统中蔓延。
- 提供
fail-fast(快速失败)和快速恢复的支持。 - 提供 fallback 优雅降级的支持。
- 支持近实时的监控、报警以及运维操作。
Hystrix 可以对其进行资源隔离,比如限制服务 B 只有 40 个线程调用服务 C。当此 40 个线程被 hang 住时,其它 60 个线程依然能正常调用工作。从而确保整个系统不会被拖垮。
1.2 Hystrix 更加细节的设计原则
- 阻止任何一个依赖服务耗尽所有的资源,比如 tomcat 中的所有线程资源。
- 避免请求排队和积压,采用限流和
fail fast来控制故障。 - 提供
fallback降级机制来应对故障。 - 使用资源隔离技术,比如
bulkhead(舱壁隔离技术)、swimlane(泳道技术)、circuit breaker(断路技术)来限制任何一个依赖服务的故障的影响。 - 通过近实时的统计/监控/报警功能,来提高故障发现的速度。
- 通过近实时的属性和配置热修改功能,来提高故障处理和恢复的速度。
- 保护依赖服务调用的所有故障情况,而不仅仅只是网络故障情况。
2. 电商网站的商品详情页系统架构
2.1 小型电商网站的商品详情页系统架构
小型电商网站的页面展示采用页面全量静态化的思想。数据库中存放了所有的商品信息,页面静态化系统,将数据填充进静态模板中,形成静态化页面,推入 Nginx 服务器。用户浏览网站页面时,取用一个已经静态化好的 html 页面,直接返回回去,不涉及任何的业务逻辑处理。
这样做,好处在于,用户每次浏览一个页面,不需要进行任何的跟数据库的交互逻辑,也不需要执行任何的代码,直接返回一个 html 页面就可以了,速度和性能非常高。
对于小网站,页面很少,很实用,非常简单,Java 中可以使用 velocity、freemarker、thymeleaf 等等,然后做个 cms 页面内容管理系统,模板变更的时候,点击按钮或者系统自动化重新进行全量渲染。
坏处在于,仅仅适用于一些小型的网站,比如页面的规模在几十到几万不等。对于一些大型的电商网站,亿级数量的页面,你说你每次页面模板修改了,都需要将这么多页面全量静态化,靠谱吗?每次渲染花个好几天时间,那你整个网站就废掉了。
2.2 大型电商网站的商品详情页系统架构
大型电商网站商品详情页的系统设计中,当商品数据发生变更时,会将变更消息压入 MQ 消息队列中。缓存服务从消息队列中消费这条消息时,感知到有数据发生变更,便通过调用数据服务接口,获取变更后的数据,然后将整合好的数据推送至 redis 中。Nginx 本地缓存的数据是有一定的时间期限的,比如说 10 分钟,当数据过期之后,它就会从 redis 获取到最新的缓存数据,并且缓存到自己本地。
用户浏览网页时,动态将 Nginx 本地数据渲染到本地 html 模板并返回给用户。
虽然没有直接返回 html 页面那么快,但是因为数据在本地缓存,所以也很快,其实耗费的也就是动态渲染一个 html 页面的性能。如果 html 模板发生了变更,不需要将所有的页面重新静态化,也不需要发送请求,没有网络请求的开销,直接将数据渲染进最新的 html 页面模板后响应即可。
在这种架构下,我们需要保证系统的高可用性。
如果系统访问量很高,Nginx 本地缓存过期失效了,redis 中的缓存也被 LRU 算法给清理掉了,那么会有较高的访问量,从缓存服务调用商品服务。但如果此时商品服务的接口发生故障,调用出现了延时,缓存服务全部的线程都被这个调用商品服务接口给耗尽了,每个线程去调用商品服务接口的时候,都会卡住很长时间,后面大量的请求过来都会卡在那儿,此时缓存服务没有足够的线程去调用其它一些服务的接口,从而导致整个大量的商品详情页无法正常显示。
这其实就是一个商品接口服务故障导致缓存服务资源耗尽的现象。
3. 基于 Hystrix 线程池技术实现资源隔离
Hystrix 里面核心的一项功能,其实就是所谓的资源隔离,要解决的最最核心的问题,就是将多个依赖服务的调用分别隔离到各自的资源池内。避免说对某一个依赖服务的调用,因为依赖服务的接口调用的延迟或者失败,导致服务所有的线程资源全部耗费在这个服务的接口调用上。一旦说某个服务的线程资源全部耗尽的话,就可能导致服务崩溃,甚至说这种故障会不断蔓延。
Hystrix 实现资源隔离,主要有两种技术:
- 线程池
- 信号量
默认情况下,Hystrix 使用线程池模式。
Hystrix 进行资源隔离,其实是提供了一个抽象,叫做 Command。这也是 Hystrix 最最基本的资源隔离技术。
3.1 利用 HystrixCommand 获取单条数据
我们通过将调用商品服务的操作封装在 HystrixCommand 中,限定一个 key,比如下面的 GetProductInfoCommandGroup,在这里我们可以简单认为这是一个线程池,每次调用商品服务,就只会用该线程池中的资源,不会再去用其它线程资源了。
public class GetProductInfoCommand extends HystrixCommand<ProductInfo> {private Long productId;public GetProductInfoCommand(Long productId) {super(HystrixCommandGroupKey.Factory.asKey("GetProductInfoCommandGroup"));this.productId = productId;}@Overrideprotected ProductInfo run() {String url = "http://localhost:8081/getProductInfo?productId=" + productId;// 调用商品服务接口String response = HttpClientUtils.sendGetRequest(url);return JSONObject.parseObject(response, ProductInfo.class);}}
我们在缓存服务接口中,根据 productId 创建 Command 并执行,获取到商品数据。
@RequestMapping("/getProductInfo")@ResponseBodypublic String getProductInfo(Long productId) {HystrixCommand<ProductInfo> getProductInfoCommand = new GetProductInfoCommand(productId);// 通过command执行,获取最新商品数据ProductInfo productInfo = getProductInfoCommand.execute();System.out.println(productInfo);return "success";}
上面执行的是 execute() 方法,其实是同步的。也可以对 command 调用 queue() 方法,它仅仅是将 command 放入线程池的一个等待队列,就立即返回,拿到一个 Future 对象,后面可以继续做其它一些事情,然后过一段时间对 Future 调用 get() 方法获取数据。这是异步的。
3.2 利用 HystrixObservableCommand 批量获取数据
只要是获取商品数据,全部都绑定到同一个线程池里面去,我们通过 HystrixObservableCommand 的一个线程去执行,而在这个线程里面,批量把多个 productId 的 productInfo 拉回来。
public class GetProductInfosCommand extends HystrixObservableCommand<ProductInfo> {private String[] productIds;public GetProductInfosCommand(String[] productIds) {// 还是绑定在同一个线程池super(HystrixCommandGroupKey.Factory.asKey("GetProductInfoGroup"));this.productIds = productIds;}@Overrideprotected Observable<ProductInfo> construct() {return Observable.unsafeCreate((Observable.OnSubscribe<ProductInfo>) subscriber -> {for (String productId : productIds) {// 批量获取商品数据String url = "http://localhost:8081/getProductInfo?productId=" + productId;String response = HttpClientUtils.sendGetRequest(url);ProductInfo productInfo = JSONObject.parseObject(response, ProductInfo.class);subscriber.onNext(productInfo);}subscriber.onCompleted();}).subscribeOn(Schedulers.io());}}
在缓存服务接口中,根据传来的 id 列表,比如是以 , 分隔的 id 串,通过上面的 HystrixObservableCommand,执行 Hystrix 的一些 API 方法,获取到所有商品数据。
public String getProductInfos(String productIds) {String[] productIdArray = productIds.split(",");HystrixObservableCommand<ProductInfo> getProductInfosCommand = new GetProductInfosCommand(productIdArray);Observable<ProductInfo> observable = getProductInfosCommand.observe();observable.subscribe(new Observer<ProductInfo>() {@Overridepublic void onCompleted() {System.out.println("获取完了所有的商品数据");}@Overridepublic void onError(Throwable e) {e.printStackTrace();}/*** 获取完一条数据,就回调一次这个方法* @param productInfo*/@Overridepublic void onNext(ProductInfo productInfo) {System.out.println(productInfo);}});return "success";}
我们回过头来,看看 Hystrix 线程池技术是如何实现资源隔离的。
从 Nginx 开始,缓存都失效了,那么 Nginx 通过缓存服务去调用商品服务。缓存服务默认的线程大小是 10 个,最多就只有 10 个线程去调用商品服务的接口。即使商品服务接口故障了,最多就只有 10 个线程会 hang 死在调用商品服务接口的路上,缓存服务的 Tomcat 内其它的线程还是可以用来调用其它的服务,干其它的事情。
4. 基于 Hystrix 信号量机制实现资源隔离
- 线程池机制,每个 command 运行在一个线程中,限流是通过线程池的大小来控制的;
- 信号量机制,command 是运行在调用线程中(也就是 Tomcat 的线程池),通过信号量的容量来进行限流。
默认的策略**就是线程池。
前面已经说过线程池技术了,这一小节就来说说信号量机制实现资源隔离,以及这两种技术的区别与具体应用场景。
4.1 信号量机制
信号量的资源隔离只是起到一个开关的作用,比如,服务 A 的信号量大小为 10,那么就是说它同时只允许有 10 个 tomcat 线程来访问服务 A,其它的请求都会被拒绝,从而达到资源隔离和限流保护的作用。
线程池与信号量区别
线程池隔离技术,并不是说去控制类似 tomcat 这种 web 容器的线程。更加严格的意义上来说,Hystrix 的线程池隔离技术,控制的是 tomcat 线程的执行。Hystrix 线程池满后,会确保说,tomcat 的线程不会因为依赖服务的接口调用延迟或故障而被 hang 住,tomcat 其它的线程不会卡死,可以快速返回,然后支撑其它的事情。
线程池隔离技术,是用 Hystrix 自己的线程去执行调用;而信号量隔离技术,是直接让 tomcat 线程去调用依赖服务。信号量隔离,只是一道关卡,信号量有多少,就允许多少个 tomcat 线程通过它,然后去执行。
适用场景:
- 线程池技术,适合绝大多数场景,比如说我们对依赖服务的网络请求的调用和访问、需要对调用的 timeout 进行控制(捕捉 timeout 超时异常)。
- 信号量技术,适合说你的访问不是对外部依赖的访问,而是对内部的一些比较复杂的业务逻辑的访问,并且系统内部的代码,其实不涉及任何的网络请求,那么只要做信号量的普通限流就可以了,因为不需要去捕获 timeout 类似的问题。
信号量简单 Demo
业务背景里,比较适合信号量的是什么场景呢?
比如说,我们一般来说,缓存服务,可能会将一些量特别少、访问又特别频繁的数据,放在自己的纯内存中。
举个栗子。一般我们在获取到商品数据之后,都要去获取商品是属于哪个地理位置、省、市、卖家等,可能在自己的纯内存中,比如就一个 Map 去获取。对于这种直接访问本地内存的逻辑,比较适合用信号量做一下简单的隔离。性能相对高一些。
假如这是本地缓存,我们可以通过 cityId,拿到 cityName。
public class LocationCache {private static Map<Long, String> cityMap = new HashMap<>();static {cityMap.put(1L, "北京");}/*** 通过cityId 获取 cityName** @param cityId 城市id* @return 城市名*/public static String getCityName(Long cityId) {return cityMap.get(cityId);}}
写一个 GetCityNameCommand,策略设置为信号量。run() 方法中获取本地缓存。我们目的就是对获取本地缓存的代码进行资源隔离。
public class GetCityNameCommand extends HystrixCommand<String> {private Long cityId;public GetCityNameCommand(Long cityId) {// 设置信号量隔离策略super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("GetCityNameGroup")).andCommandPropertiesDefaults(HystrixCommandProperties.Setter().withExecutionIsolationStrategy(HystrixCommandProperties.ExecutionIsolationStrategy.SEMAPHORE)));this.cityId = cityId;}@Overrideprotected String run() {// 需要进行信号量隔离的代码return LocationCache.getCityName(cityId);}}
在接口层,通过创建 GetCityNameCommand,传入 cityId,执行 execute() 方法,那么获取本地 cityName 缓存的代码将会进行信号量的资源隔离。
@RequestMapping("/getProductInfo")@ResponseBodypublic String getProductInfo(Long productId) {HystrixCommand<ProductInfo> getProductInfoCommand = new GetProductInfoCommand(productId);// 通过command执行,获取最新商品数据ProductInfo productInfo = getProductInfoCommand.execute();Long cityId = productInfo.getCityId();GetCityNameCommand getCityNameCommand = new GetCityNameCommand(cityId);// 获取本地内存(cityName)的代码会被信号量进行资源隔离String cityName = getCityNameCommand.execute();productInfo.setCityName(cityName);System.out.println(productInfo);return "success";}
5. Hystrix 隔离策略细粒度控制
Hystrix 实现资源隔离,有两种策略:
- 线程池隔离
- 信号量隔离
5.1 execution.isolation.strategy
指定了 HystrixCommand.run() 的资源隔离策略:THREAD or SEMAPHORE,一种基于线程池,一种基于信号量。
// to use thread isolationHystrixCommandProperties.Setter().withExecutionIsolationStrategy(ExecutionIsolationStrategy.THREAD)// to use semaphore isolationHystrixCommandProperties.Setter().withExecutionIsolationStrategy(ExecutionIsolationStrategy.SEMAPHORE)
线程池其实最大的好处就是对于网络访问请求,如果有超时的话,可以避免调用线程阻塞住。
而使用信号量的场景,通常是针对超大并发量的场景下,每个服务实例每秒都几百的 QPS,那么此时你用线程池的话,线程一般不会太多,可能撑不住那么高的并发,如果要撑住,可能要耗费大量的线程资源,那么就是用信号量,来进行限流保护。一般用信号量常见于那种基于纯内存的一些业务逻辑服务,而不涉及到任何网络访问请求。
5.2 command key & command group
我们使用线程池隔离,要怎么对依赖服务、依赖服务接口、线程池三者做划分呢?
每一个 command,都可以设置一个自己的名称 command key,同时可以设置一个自己的组 command group。
private static final Setter cachedSetter = Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("ExampleGroup")).andCommandKey(HystrixCommandKey.Factory.asKey("HelloWorld"));public CommandHelloWorld(String name) {super(cachedSetter);this.name = name;}
command group 是一个非常重要的概念,默认情况下,就是通过 command group 来定义一个线程池的,而且还会通过 command group 来聚合一些监控和报警信息。同一个 command group 中的请求,都会进入同一个线程池中。
5.3 command thread pool
ThreadPoolKey 代表了一个 HystrixThreadPool,用来进行统一监控、统计、缓存。默认的 ThreadPoolKey 就是 command group 的名称。每个 command 都会跟它的 ThreadPoolKey 对应的 ThreadPool 绑定在一起。
如果不想直接用 command group,也可以手动设置 ThreadPool 的名称。
private static final Setter cachedSetter =Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("ExampleGroup")).andCommandKey(HystrixCommandKey.Factory.asKey("HelloWorld")).andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("HelloWorldPool"));public CommandHelloWorld(String name) {super(cachedSetter);this.name = name;}
5.4 command key & command group & command thread pool
- command key ,代表了一类 command,一般来说,代表了下游依赖服务的某个接口。
- command group ,代表了某一个下游依赖服务,这是很合理的,一个依赖服务可能会暴露出来多个接口,每个接口就是一个 command key。command group 在逻辑上对一堆 command key 的调用次数、成功次数、timeout 次数、失败次数等进行统计,可以看到某一个服务整体的一些访问情况。一般来说,推荐根据一个服务区划分出一个线程池,command key 默认都是属于同一个线程池的。
- thread pool key:如果说 command group 对应了一个服务,而这个服务暴露出来的几个接口,访问量很不一样,差异非常之大。你可能就希望在这个服务对应 command group 的内部,对应多个接口的 command key 做一些细粒度的资源隔离。就是说,希望对同一个服务的不同接口,使用不同的线程池。
**
command key -> command groupcommand key -> 自己的 thread pool key
逻辑上来说,多个 command key 属于一个command group,在做统计的时候,会放在一起统计。每个 command key 有自己的线程池,每个接口有自己的线程池,去做资源隔离和限流。
说白点,就是说如果你的 command key 要用自己的线程池,可以定义自己的 thread pool key,就 ok 了。
5.5 coreSize 设置线程池大小
设置线程池的大小,默认是 10。一般来说,用这个默认的 10 个线程大小就够了。
HystrixThreadPoolProperties.Setter().withCoreSize(int value);
5.6 queueSizeRejectionThreshold 线程池队列
当说线程池中的 10 个线程都在工作,没有空闲的线程来做其它的事情,此时再有请求过来,会先进入队列积压。如果说队列积压满了,再有请求过来,就直接 reject,拒绝请求,执行 fallback 降级的逻辑,快速返回。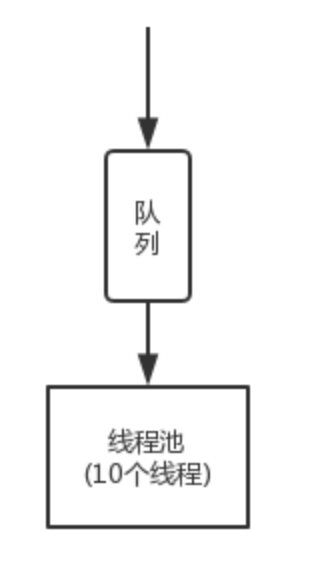
控制 queue 满了之后 reject 的 threshold,因为 maxQueueSize 不允许热修改,因此提供这个参数可以热修改,控制队列的最大大小。
HystrixThreadPoolProperties.Setter().withQueueSizeRejectionThreshold(int value);
5.7 execution.isolation.semaphore.maxConcurrentRequests
设置使用 SEMAPHORE 隔离策略的时候允许访问的最大并发量,超过这个最大并发量,请求直接被 reject。
这个并发量的设置,跟线程池大小的设置,应该是类似的,但是基于信号量的话,性能会好很多,而且 Hystrix 框架本身的开销会小很多。
默认值是 10,尽量设置的小一些,因为一旦设置的太大,而且有延时发生,可能瞬间导致 tomcat 本身的线程资源被占满。
HystrixCommandProperties.Setter().withExecutionIsolationSemaphoreMaxConcurrentRequests(int value);
6. 深入 Hystrix 执行时内部原理
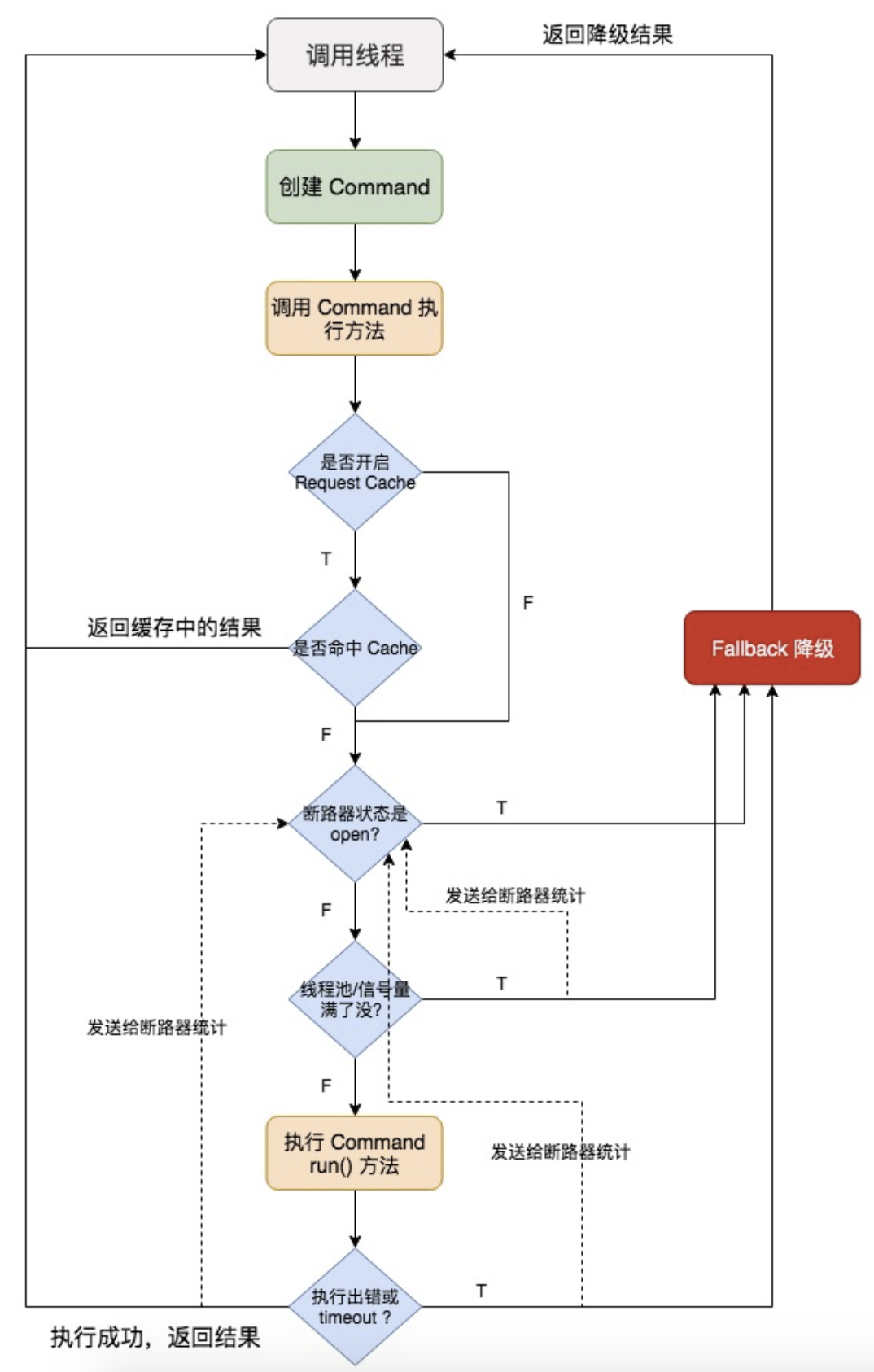
步骤一:创建 command
一个 HystrixCommand 或 HystrixObservableCommand 对象,代表了对某个依赖服务发起的一次请求或者调用。创建的时候,可以在构造函数中传入任何需要的参数。
- HystrixCommand 主要用于仅仅会返回一个结果的调用。
- HystrixObservableCommand 主要用于可能会返回多条结果的调用。
// 创建 HystrixCommandHystrixCommand hystrixCommand = new HystrixCommand(arg1, arg2);// 创建 HystrixObservableCommandHystrixObservableCommand hystrixObservableCommand = new HystrixObservableCommand(arg1, arg2);
步骤二:调用 command 执行方法
执行 command,就可以发起一次对依赖服务的调用。
要执行 command,可以在 4 个方法中选择其中的一个:execute()、queue()、observe()、toObservable()。
其中 execute() 和 queue() 方法仅仅对 HystrixCommand 适用。
execute():调用后直接 block 住,属于同步调用,直到依赖服务返回单条结果,或者抛出异常。queue():返回一个 Future,属于异步调用,后面可以通过 Future 的get()方法获取单条结果。observe():订阅一个 Observable 对象,Observable 代表的是依赖服务返回的结果,获取到一个那个代表结果的 Observable 对象的拷贝对象。toObservable():返回一个 Observable 对象,如果我们订阅这个对象,就会执行 command 并且获取返回结果。
K value = hystrixCommand.execute();Future<K> fValue = hystrixCommand.queue();Observable<K> oValue = hystrixObservableCommand.observe();Observable<K> toOValue = hystrixObservableCommand.toObservable();
execute() 实际上会调用 queue().get() 方法,可以看一下 Hystrix 源码。
public R execute() {try {return queue().get();} catch (Exception e) {throw Exceptions.sneakyThrow(decomposeException(e));}}
而在 queue()方法中,会调用 toObservable().toBlocking().toFuture()。
final Future<R> delegate = toObservable().toBlocking().toFuture();
也就是说,先通过 toObservable() 获得 Future 对象,然后调用 Future 的 get() 方法。那么,其实无论是哪种方式执行 command,最终都是依赖于 toObservable() 去执行的。
步骤三:检查是否开启缓存(不太常用)
从这一步开始,就进入到 Hystrix 底层运行原理啦,看一下 Hystrix 一些更高级的功能和特性。
如果这个 command 开启了请求缓存 Request Cache,而且这个调用的结果在缓存中存在,那么直接从缓存中返回结果。否则,继续往后的步骤。
步骤四:检查是否开启了断路器
检查这个 command 对应的依赖服务是否开启了断路器。如果断路器被打开了,那么 Hystrix 就不会执行这个 command,而是直接去执行 fallback 降级机制,返回降级结果。
步骤五:检查线程池/队列/信号量是否已满
如果这个 command 线程池和队列已满,或者 semaphore 信号量已满,那么也不会执行 command,而是直接去调用 fallback 降级机制,同时发送 reject 信息给断路器统计。
步骤六:执行 command
调用 HystrixObservableCommand 对象的 construct() 方法,或者 HystrixCommand 的 run() 方法来实际执行这个 command。
- HystrixCommand.run() 返回单条结果,或者抛出异常。
// 通过command执行,获取最新一条商品数据ProductInfo productInfo = getProductInfoCommand.execute();
- HystrixObservableCommand.construct() 返回一个 Observable 对象,可以获取多条结果。
Observable<ProductInfo> observable = getProductInfosCommand.observe();// 订阅获取多条结果observable.subscribe(new Observer<ProductInfo>() {@Overridepublic void onCompleted() {System.out.println("获取完了所有的商品数据");}@Overridepublic void onError(Throwable e) {e.printStackTrace();}/*** 获取完一条数据,就回调一次这个方法** @param productInfo 商品信息*/@Overridepublic void onNext(ProductInfo productInfo) {System.out.println(productInfo);}});
如果是采用线程池方式,并且 HystrixCommand.run() 或者 HystrixObservableCommand.construct() 的执行时间超过了 timeout 时长的话,那么 command 所在的线程会抛出一个 TimeoutException,这时会执行 fallback 降级机制,不会去管 run() 或 construct() 返回的值了。另一种情况,如果 command 执行出错抛出了其它异常,那么也会走 fallback 降级。这两种情况下,Hystrix 都会发送异常事件给断路器统计。
注意,我们是不可能终止掉一个调用严重延迟的依赖服务的线程的,只能说给你抛出来一个 TimeoutException。
如果没有 timeout,也正常执行的话,那么调用线程就会拿到一些调用依赖服务获取到的结果,然后 Hystrix 也会做一些 logging 记录和 metric 度量统计。
步骤七:断路健康检查
Hystrix 会把每一个依赖服务的调用成功、失败、Reject、Timeout 等事件发送给 circuit breaker 断路器。断路器就会对这些事件的次数进行统计,根据异常事件发生的比例来决定是否要进行断路(熔断)。如果打开了断路器,那么在接下来一段时间内,会直接断路,返回降级结果。
如果在之后,断路器尝试执行 command,调用没有出错,返回了正常结果,那么 Hystrix 就会把断路器关闭。
步骤八:调用 fallback 降级机制
在以下几种情况中,Hystrix 会调用 fallback 降级机制。
- 断路器处于打开状态;
- 线程池/队列/semaphore满了;
command执行超时;run()或者construct()抛出异常。
一般在降级机制中,都建议给出一些默认的返回值,比如静态的一些代码逻辑,或者从内存中的缓存中提取一些数据,在这里尽量不要再进行网络请求了。
在降级中,如果一定要进行网络调用的话,也应该将那个调用放在一个 HystrixCommand 中进行隔离。
- HystrixCommand 中,实现
getFallback()方法,可以提供降级机制。 - HystrixObservableCommand 中,实现
resumeWithFallback()方法,返回一个 Observable 对象,可以提供降级结果。
如果没有实现 fallback,或者 fallback 抛出了异常,Hystrix 会返回一个 Observable,但是不会返回任何数据。
不同的 command 执行方式,其 fallback 为空或者异常时的返回结果不同。
- 对于
execute(),直接抛出异常。 - 对于
queue(),返回一个 Future,调用get()时抛出异常。 - 对于
observe(),返回一个 Observable 对象,但是调用subscribe()方法订阅它时,立即抛出调用者的onError()方法。 - 对于
toObservable(),返回一个 Observable 对象,但是调用subscribe()方法订阅它时,立即抛出调用者的onError()方法。
不同的执行方式
execute(),获取一个Future.get(),然后拿到单个结果。queue(),返回一个 Future。observe(),立即订阅 Observable,然后启动 8 大执行步骤,返回一个拷贝的 Observable,订阅时立即回调给你结果。toObservable(),返回一个原始的 Observable,必须手动订阅才会去执行 8 大步骤。
7. 基于 request cache 请求缓存技术优化批量商品数据查询接口
Hystrix command 执行时 8 大步骤第三步,就是检查 Request cache 是否有缓存。
首先,有一个概念,叫做 Request Context 请求上下文,一般来说,在一个 web 应用中,如果我们用到了 Hystrix,我们会在一个 filter 里面,对每一个请求都施加一个请求上下文。就是说,每一次请求,就是一次请求上下文。然后在这次请求上下文中,我们会去执行 N 多代码,调用 N 多依赖服务,有的依赖服务可能还会调用好几次。
在一次请求上下文中,如果有多个 command,参数都是一样的,调用的接口也是一样的,而结果可以认为也是一样的。那么这个时候,我们可以让第一个 command 执行返回的结果缓存在内存中,然后这个请求上下文后续的其它对这个依赖的调用全部从内存中取出缓存结果就可以了。
这样的话,好处在于不用在一次请求上下文中反复多次执行一样的 command,避免重复执行网络请求,提升整个请求的性能。
举个栗子。比如说我们在一次请求上下文中,请求获取 productId 为 1 的数据,第一次缓存中没有,那么会从商品服务中获取数据,返回最新数据结果,同时将数据缓存在内存中。后续同一次请求上下文中,如果还有获取 productId 为 1 的数据的请求,直接从缓存中取就好了。
HystrixCommand 和 HystrixObservableCommand 都可以指定一个缓存 key,然后 Hystrix 会自动进行缓存,接着在同一个 request context 内,再次访问的话,就会直接取用缓存。
下面,我们结合一个具体的业务场景,来看一下如何使用 request cache 请求缓存技术。当然,以下代码只作为一个基本的 Demo 而已。
现在,假设我们要做一个批量查询商品数据的接口,在这个里面,我们是用 HystrixCommand 一次性批量查询多个商品 id 的数据。但是这里有个问题,如果说 Nginx 在本地缓存失效了,重新获取一批缓存,传递过来的 productIds 都没有进行去重,比如 productIds=1,1,1,2,2,那么可能说,商品 id 出现了重复,如果按照我们之前的业务逻辑,可能就会重复对 productId=1 的商品查询三次,productId=2 的商品查询两次。
我们对批量查询商品数据的接口,可以用 request cache 做一个优化,就是说一次请求,就是一次 request context,对相同的商品查询只执行一次,其余重复的都走 request cache。
7.1 实现 Hystrix 请求上下文过滤器并注册
定义 HystrixRequestContextFilter 类,实现 Filter 接口。
/*** Hystrix 请求上下文过滤器*/public class HystrixRequestContextFilter implements Filter {@Overridepublic void init(FilterConfig filterConfig) throws ServletException {}@Overridepublic void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) {HystrixRequestContext context = HystrixRequestContext.initializeContext();try {filterChain.doFilter(servletRequest, servletResponse);} catch (IOException | ServletException e) {e.printStackTrace();} finally {context.shutdown();}}@Overridepublic void destroy() {}}
然后将该 filter 对象注册到 SpringBoot Application 中。
@SpringBootApplicationpublic class EshopApplication {public static void main(String[] args) {SpringApplication.run(EshopApplication.class, args);}@Beanpublic FilterRegistrationBean filterRegistrationBean() {FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean(new HystrixRequestContextFilter());filterRegistrationBean.addUrlPatterns("/*");return filterRegistrationBean;}}
7.2 command 重写 getCacheKey() 方法
在 GetProductInfoCommand 中,重写 getCacheKey() 方法,这样的话,每一次请求的结果,都会放在 Hystrix 请求上下文中。下一次同一个 productId 的数据请求,直接取缓存,无须再调用 run() 方法。
public class GetProductInfoCommand extends HystrixCommand<ProductInfo> {private Long productId;private static final HystrixCommandKey KEY = HystrixCommandKey.Factory.asKey("GetProductInfoCommand");public GetProductInfoCommand(Long productId) {super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("ProductInfoService")).andCommandKey(KEY));this.productId = productId;}@Overrideprotected ProductInfo run() {String url = "http://localhost:8081/getProductInfo?productId=" + productId;String response = HttpClientUtils.sendGetRequest(url);System.out.println("调用接口查询商品数据,productId=" + productId);return JSONObject.parseObject(response, ProductInfo.class);}/*** 每次请求的结果,都会放在Hystrix绑定的请求上下文上** @return cacheKey 缓存key*/@Overridepublic String getCacheKey() {return "product_info_" + productId;}/*** 将某个商品id的缓存清空** @param productId 商品id*/public static void flushCache(Long productId) {HystrixRequestCache.getInstance(KEY,HystrixConcurrencyStrategyDefault.getInstance()).clear("product_info_" + productId);}}
这里写了一个 flushCache() 方法,用于我们开发手动删除缓存。
7.3 controller 调用 command 查询商品信息
在一次 web 请求上下文中,传入商品 id 列表,查询多条商品信息。每个 productId,都创建一个 command。如果 id 列表没有去重,那么重复的 id,第二次查询的时候就会直接走缓存。
@Controllerpublic class CacheController {/*** 一次性批量查询多条商品数据的请求** @param productIds 以,分隔的商品id列表* @return 响应状态*/@RequestMapping("/getProductInfos")@ResponseBodypublic String getProductInfos(String productIds) {for (String productId : productIds.split(",")) {// 对每个productId,都创建一个commandGetProductInfoCommand getProductInfoCommand = new GetProductInfoCommand(Long.valueOf(productId));ProductInfo productInfo = getProductInfoCommand.execute();System.out.println("是否是从缓存中取的结果:" + getProductInfoCommand.isResponseFromCache());}return "success";}}
发起请求
调用接口,查询多个商品的信息。
http://localhost:8080/getProductInfos?productIds=1,1,1,2,2,5
在控制台,我们可以看到以下结果。
调用接口查询商品数据,productId=1是否是从缓存中取的结果:false是否是从缓存中取的结果:true是否是从缓存中取的结果:true调用接口查询商品数据,productId=2是否是从缓存中取的结果:false是否是从缓存中取的结果:true调用接口查询商品数据,productId=5是否是从缓存中取的结果:false
第一次查询 productId=1 的数据,会调用接口进行查询,不是从缓存中取结果。而随后再出现查询 productId=1 的请求,就直接取缓存了,这样的话,效率明显高很多。
删除缓存
我们写一个 UpdateProductInfoCommand,在更新商品信息之后,手动调用之前写的 flushCache(),手动将缓存删除。
public class UpdateProductInfoCommand extends HystrixCommand<Boolean> {private Long productId;public UpdateProductInfoCommand(Long productId) {super(HystrixCommandGroupKey.Factory.asKey("UpdateProductInfoGroup"));this.productId = productId;}@Overrideprotected Boolean run() throws Exception {// 这里执行一次商品信息的更新// ...// 然后清空缓存GetProductInfoCommand.flushCache(productId);return true;}}
这样,以后查询该商品的请求,第一次就会走接口调用去查询最新的商品信息。
8. 基于本地缓存的 fallback 降级机制
Hystrix 出现以下四种情况,都会去调用 fallback 降级机制:
- 断路器处于打开的状态。
- 资源池已满(线程池+队列 / 信号量)。
- Hystrix 调用各种接口,或者访问外部依赖,比如 MySQL、Redis、Zookeeper、Kafka 等等,出现了任何异常的情况。
- 访问外部依赖的时候,访问时间过长,报了 TimeoutException 异常。
8.1 两种最经典的降级机制
- 纯内存数据
在降级逻辑中,你可以在内存中维护一个 ehcache,作为一个纯内存的基于 LRU 自动清理的缓存,让数据放在缓存内。如果说外部依赖有异常,fallback 这里直接尝试从 ehcache 中获取数据。 - 默认值
fallback 降级逻辑中,也可以直接返回一个默认值。
在 HystrixCommand,降级逻辑的书写,是通过实现 getFallback() 接口;而在 HystrixObservableCommand 中,则是实现 resumeWithFallback() 方法。
比如,有这么个场景。我们现在有个包含 brandId 的商品数据,假设正常的逻辑是这样:拿到一个商品数据,根据 brandId 去调用品牌服务的接口,获取品牌的最新名称 brandName。假如说,品牌服务接口挂掉了,那么我们可以尝试从本地内存中,获取一份稍过期的数据,先凑合着用。
步骤一:本地缓存获取数据
本地获取品牌名称的代码大致如下。
/*** 品牌名称本地缓存**/public class BrandCache {private static Map<Long, String> brandMap = new HashMap<>();static {brandMap.put(1L, "Nike");}/*** brandId 获取 brandName** @param brandId 品牌id* @return 品牌名*/public static String getBrandName(Long brandId) {return brandMap.get(brandId);}}
步骤二:实现 GetBrandNameCommand
在 GetBrandNameCommand 中,run() 方法的正常逻辑是去调用品牌服务的接口获取到品牌名称,如果调用失败,报错了,那么就会去调用 fallback 降级机制。而在 getFallback() 方法中,就是我们的降级逻辑,我们直接从本地的缓存中,获取到品牌名称的数据。
这里,我们直接模拟接口调用报错,给它抛出个异常。
/*** 获取品牌名称的command**/public class GetBrandNameCommand extends HystrixCommand<String> {private Long brandId;public GetBrandNameCommand(Long brandId) {super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("BrandService")).andCommandKey(HystrixCommandKey.Factory.asKey("GetBrandNameCommand")).andCommandPropertiesDefaults(HystrixCommandProperties.Setter()// 设置降级机制最大并发请求数.withFallbackIsolationSemaphoreMaxConcurrentRequests(15)));this.brandId = brandId;}@Overrideprotected String run() throws Exception {// 这里正常的逻辑应该是去调用一个品牌服务的接口获取名称// 如果调用失败,报错了,那么就会去调用fallback降级机制// 这里我们直接模拟调用报错,抛出异常throw new Exception();}@Overrideprotected String getFallback() {return BrandCache.getBrandName(brandId);}}
FallbackIsolationSemaphoreMaxConcurrentRequests 用于设置 fallback 最大允许的并发请求量,默认值是 10,是通过 semaphore 信号量的机制去限流的。如果超出了这个最大值,那么直接 reject。
步骤三:CacheController 调用接口
在 CacheController 中,我们通过 productInfo 获取 brandId,然后创建 GetBrandNameCommand 并执行,去尝试获取 brandName。这里执行会报错,因为我们在run() 方法中直接抛出异常,Hystrix 就会去调用 getFallback() 方法走降级逻辑。
@Controllerpublic class CacheController {@RequestMapping("/getProductInfo")@ResponseBodypublic String getProductInfo(Long productId) {HystrixCommand<ProductInfo> getProductInfoCommand = new GetProductInfoCommand(productId);ProductInfo productInfo = getProductInfoCommand.execute();Long brandId = productInfo.getBrandId();HystrixCommand<String> getBrandNameCommand = new GetBrandNameCommand(brandId);// 执行会抛异常报错,然后走降级String brandName = getBrandNameCommand.execute();productInfo.setBrandName(brandName);System.out.println(productInfo);return "success";}}
关于降级逻辑的演示,基本上就结束了。

若有收获,就点个赞吧
0 人点赞
