Source
Hoodie DeltaStreamer 可以从各种来源读取数据。
分布式文件系统 (DFS)
请参阅存储配置页面以查看 Hudi 可以从中读取的 DFS 应用程序的一些示例。
以下是 Hudi 可以在 DFS 源上读取/写入的支持的文件格式。 (注意:仍然可以使用 Spark/Flink reader 从其他格式读取数据,然后将数据写入 Hudi 格式)
- CSV
- AVRO
- JSON
- PARQUET
- ORC
-
Kafka
Hudi 可以直接从 Kafka 集群中读取数据。 查看有关 HoodieDeltaStreamer 的更多详细信息,以了解如何使用 exactly-once 的语义、检查点和插件转换来设置流式摄取。 从 Kafka 读取数据时支持以下格式:
AVRO
- JSON
S3 Events
AWS S3 存储提供事件通知服务,当 S3 存储桶中发生某些事件时,它会发布通知:https://docs.aws.amazon.com/AmazonS3/latest/userguide/NotificationHowTo.html AWS 会将这些事件放在一个简单的队列服务 (SQS)。 Apache Hudi 提供了一个 S3EventsSource,它可以从 SQS 读取,以在 S3 上可用时立即触发/处理新的或更改的数据。
设置
- 启用 S3 事件通知 https://docs.aws.amazon.com/AmazonS3/latest/userguide/NotificationHowTo.html
- 下载 aws-java-sdk-sqs jar。
- 找到队列 URL 和区域以设置这些配置:
- hoodie.deltastreamer.s3.source.queue.url=https://sqs.us-west-2.amazonaws.com/queue/url
- hoodie.deltastreamer.s3.source.queue.region=us-west-2
- 使用 HoodieDeltaStreamer 实用程序启动 S3EventsSource 和 S3EventsHoodieIncrSource,如下面的示例命令所示:
此博客中的代码示例:https://hudi.apache.org/blog/2021/08/23/s3-events-source/#configuration-and-setup
JDBC Source
Hudi 可以从 JDBC 源读取完整的表,或者 Hudi 甚至可以通过 JDBC 源的检查点来增量读取。
| 配置 | 说明 | 示例 |
|---|---|---|
| hoodie.deltastreamer.jdbc.url | JDBC 连接的 URL | jdbc:postgresql://localhost/test |
| hoodie.deltastreamer.jdbc.user | 用于验证 JDBC 连接的用户 | fred |
| hoodie.deltastreamer.jdbc.password | 用于验证 JDBC 连接的密码 | secret |
| hoodie.deltastreamer.jdbc.password.file | 如果你更喜欢使用密码文件进行连接 | |
| hoodie.deltastreamer.jdbc.driver.class | 用于 JDBC 连接的驱动程序类 | |
| hoodie.deltastreamer.jdbc.table.name | my_table | |
| hoodie.deltastreamer.jdbc.table.incr.column.name | 如果以增量模式运行,该字段将用于增量拉取新数据 | |
| hoodie.deltastreamer.jdbc.incr.pull | JDBC 连接会执行增量拉取吗? | |
| hoodie.deltastreamer.jdbc.extra.options. | 通常指定 spark.read.option() 传递额外配置 | hoodie.deltastreamer.jdbc.extra.options.fetchSize=100 hoodie.deltastreamer.jdbc.extra.options.upperBound=1 hoodie.deltastreamer.jdbc.extra.options.lowerBound=100 |
| hoodie.deltastreamer.jdbc.storage.level | 用于控制持久性级别 | Default = MEMORY_AND_DISK_SER |
| hoodie.deltastreamer.jdbc.incr.fallback.to.full.fetch | 布尔值,如果设置为 true,则如果增量读取中存在任何错误,则增量获取回退到完整获取 | FALSE |
SQL Source
从任何表读取的 SQL 源,主要用于处理特定分区日期的回填作业。 这不会将 deltastreamer.checkpoint.key 更新为已处理的提交,而是会获取最新的成功检查点的key 并将该值设置为此回填提交检查点,这样它就不会中断常规增量处理。 要获取和使用最新的增量检查点,还需要为 deltastremer 作业设置此 hoodie_conf:hoodie.write.meta.key.prefixes = 'deltastreamer.checkpoint.key'
Spark SQL 应该使用以下 hoodie 配置进行配置:hoodie.deltastreamer.source.sql.sql.query = ‘select * from source_table’
Flink 摄取
CDC 摄取
CDC(变更数据捕获)跟踪源系统中不断演变的数据变化,以便下游流程或系统可以对这些变化采取行动。 我们推荐两种将 CDC 数据同步到 Hudi 的方法: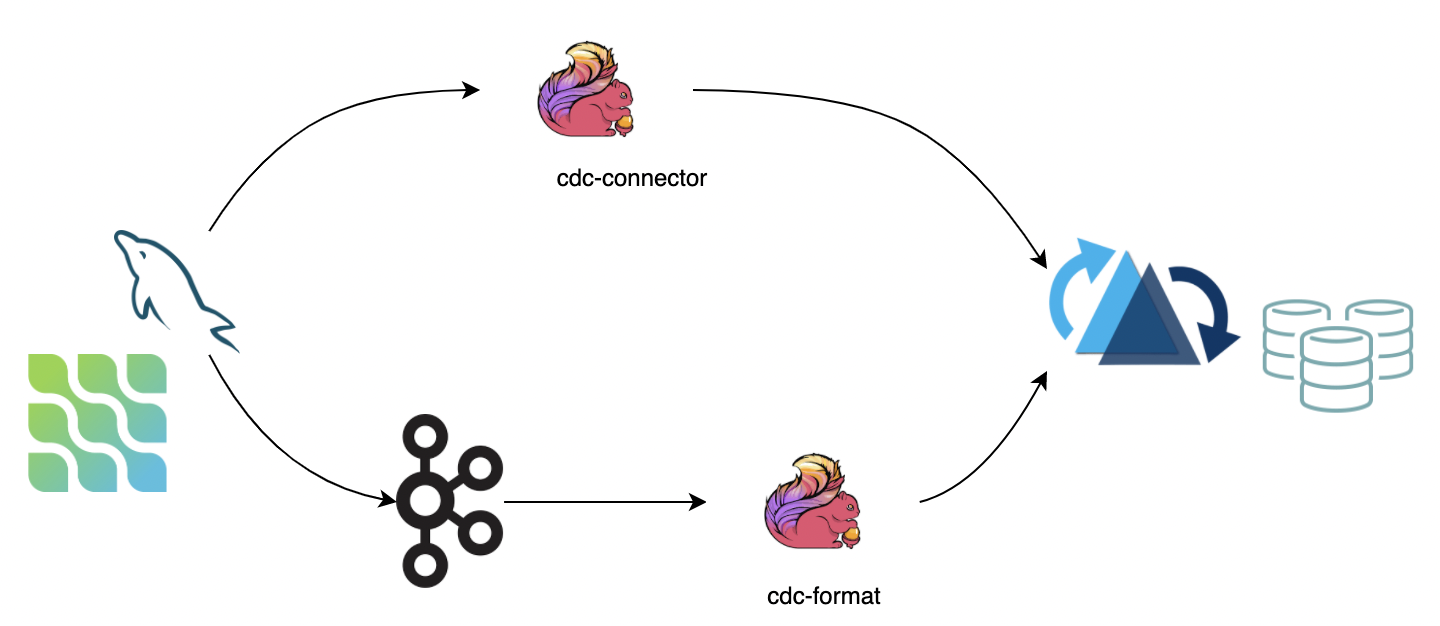
- 使用 flink-cdc-connectors 直接连接 DB Server 将 binlog 数据同步到 Hudi。 优点是不依赖消息队列,缺点是对 db server 造成压力;
- 使用 cdc 格式 flink 从消息队列(例如 Kafka)中消费数据,优点是它具有高度可扩展性,但缺点是它依赖于消息队列。
:::info NOTE
- 如果上游数据不能保证顺序,需要显式指定选项
write.precombine.field; - 现在 MOR 表不能按事件时间顺序处理 DELETE,从而导致数据丢失。 最好通过选项
changelog.enabled开启 changelog 模式。 :::
Bulk Insert(离线批量导入)
针对存量(snapshot)数据导入的需求,如果存量数据来源于其他数据源,可以使用离线批量导入功能(bulk_insert),快速将存量数据导入 Hudi。
:::info
NOTE
bulk_insert 省去了 avro 的序列化以及数据的 merge 过程,后续也不会再有去重操作。所以,数据的唯一性需要自己来保证。
:::
NOTE
bulk_insert 在 batch execution mode 模式下执行更加高效。 batch execution mode 模式默认会按照 partition path 排序输入消息再写入 Hudi, 避免 file handle 频繁切换导致性能下降。
:::
NOTE
bulk_insert 的 write tasks 的并发是通过参数 write.tasks 来指定,并发的数量会影响到小文件的数量,理论上,bulk_insert 的 write tasks 的并发数就是划分的 bucket 数, 当然每个 bucket 在写到文件大小上限(parquet 120 MB)的时候会回滚到新的文件句柄,所以最后:写文件数量 >= write.bucket_assign.tasks。
:::
| 名称 | Required | 默认值 | 备注 |
|---|---|---|---|
| write.operation | true | upsert | 开启 bulk_insert 功能 |
| write.tasks | false | 4 | bulk_insert write tasks 的并发,最后的文件数 >= write.bucket_assign.tasks |
| write.bulk_insert.shuffle_by_partition | false | true | 是否将数据按照 partition 字段 shuffle 后,再通过 write task 写入,开启该参数将减少小文件的数量,但是有数据倾斜的风险 |
| write.bulk_insert.sort_by_partition | false | true | 是否将数据线按照 partition 字段排序后,再通过 write task 写入,当一个 write task 写多个 partition时,开启可以减少小文件数量 |
| write.sort.memory | false | 128 | sort 算子的可用 managed memory(单位 MB)。默认为 128 MB |
Index Bootstrap(全量接增量)
针对全量数据导入后,接增量的需求(snapshot data + incremental data)。如果已经有全量(snapshot data)的离线 Hudi 表(通过 Bulk Insert),需要接上实时写入(incremental data),并且保证数据不重复,可以开启全量接增量(index bootstrap)功能。
:::info 如果觉得流程冗长,可以在写入全量数据的时候资源调大直接走流模式写,全量走完接新数据再将资源调小(或者开启 写入限流 )。 :::
| 名称 | Required | 默认值 | 备注 |
|---|---|---|---|
| index.bootstrap.enabled | true | false | 开启 index bootstrap 索引加载后,会将已存在的 Hudi 表的数据一次性加载到 state 中 |
| index.partition.regex | false | * | 设置正则表达式进行分区筛选,默认为加载全部分区 |
使用流程
CREATE TABLE创建和 Hudi 表对应的语句,注意 table.type 必须正确- 设置
index.bootstrap.enabled=true开启索引加载(index bootstrap)功能 - 在
flink-conf.yaml中设置 checkpoint 失败容忍 :execution.checkpointing.tolerable-failed-checkpoints = n(取决于checkpoint 调度次数) - 等待第一次 checkpoint 完成,表示索引加载完成
- 索引加载完成后可以退出并保存
savepoint(也可以直接用 externalized checkpoint) - 重启任务,将
index.bootstrap.enable设置为false,参数配置到合适的大小
NOTE
- 索引加载是阻塞式,所以在索引加载过程中 checkpoint 无法完成
- 索引加载由数据流触发,需要确保每个 partition 都至少有1条数据,即上游 source 有数据进来
- 索引加载为并发加载,根据数据量大小加载时间不同,可以在 log 中搜索
finish loading the index under partition和Load record form file日志内容来观察索引加载的进度 - 第一次 checkpoint 成功就表示索引已经加载完成,后续从 checkpoint 恢复时无需再次加载索引 :::
Changelog 模式
针对使用 Hudi 保留消息的所有中间变更(I / -U / U / D),然后通过 Flink 引擎的有状态计算实现全链路近实时数仓生产(增量计算)的需求,Hudi 的 MOR 表通过行存原生支持保留消息的所有变更(format 层面的集成),通过 Flink 流读 MOR 表可以消费到所有的变更记录。
| 名称 | Required | 默认值 | 备注 |
|---|---|---|---|
| changelog.enabled | false | false | 默认是关闭状态,即 UPSERT 语义,所有的消息仅保证最后一条合并消息,中间的变更可能会被 merge 掉;改成 true 支持保留所有变更 |
NOTE
批(快照)读仍然会合并所有的中间变更,不管 format 是否已存储中间变更消息。 :::
NOTE
设置 changelog.enable 为 true 后,中间的变更的保留也只是尽力而为(best effort):异步的 compaction 任务会将中间变更记录合并成 1 条记录,所以如果流读消费不够及时,被压缩后只能读到最后一条记录。当然,通过调整压缩的缓存时间可以预留一定的时间缓冲给 reader,比如调整压缩的两个参数:compaction.delta_commits and compaction.delta_seconds。 :::
追加模式
如果使用 INSERT 操作进行摄取,对于 COW 表,默认不合并小文件; 对于 MOR 表,始终采用小文件策略:MOR 将增量记录附加到日志文件。
小文件策略导致性能下降。 如果 COW 表要采用文件合并,打开选项 write.insert.cluster,值得一提的是记录键没有合并。
| 名称 | Required | 默认值 | 备注 |
|---|---|---|---|
| write.insert.cluster | false | false | 是否在摄取时合并小文件,对于 COW 表,打开选项启用小文件合并策略(key 不去重但会影响吞吐量) |
写入限流
针对将历史全量数据(百亿数量级)与实时增量先同步到 Kafka,再通过 Flink 从 earliest offset 将 Kafka 中的数据直接导成 Hudi 表的需求,因为直接消费全量数据:量大 (吞吐高)、乱序严重(写入的 partition 随机),会导致写入性能退化,出现吞吐毛刺等情况,对于这种情况可以开启限速参数,保证流量平稳写入。
| 名称 | Required | 默认值 | 备注 |
|---|---|---|---|
| write.rate.limit | false | 0 | 默认关闭限速 |
流式查询
默认情况下,hoodie 表是批量读取的,即读取最新的快照数据集并返回。 通过将选项 read.streaming.enabled 设置为 true 来打开流式读取模式。 设置选项 read.start-commit 以指定读取开始偏移量,如果要使用所有历史数据集,请指定最早的值。
| 名称 | Required | 默认值 | 备注 |
|---|---|---|---|
| read.streaming.enabled | false | false | 指定 true 开启流式读取模式 |
| read.start-commit | false | the latest commit | ‘yyyyMMddHHmmss’ 格式的开始提交时间,最早从开始提交时间开始消费 |
| read.streaming.skip_compaction | false | false | 是否在读取时跳过压缩提交,通常有两个目的:1)避免使用压缩瞬间的重复项 2)启用 changelog 模式时,仅消费正确语义的更改日志。 |
| clean.retain_commits | false | 10 | 清理前要保留的最大提交数,当启用 changelog 模式时,调整此选项以调整 changelog 的实时时间。 例如,如果检查点间隔设置为 5 分钟,则默认策略会保留 50 分钟的更改日志。 |
增量查询
增量查询有 3 个场景:
- 流式查询:使用选项 read.start-commit 指定开始提交;
- 批量查询:使用选项 read.start-commit 指定开始提交,用选项 read.end-commit 指定结束提交,间隔是封闭的:开始提交和结束提交都包含;
- TimeTravel:瞬间批量消费,指定 read.end-commit 就足够了,因为默认情况下开始提交是最新的。
| 名称 | Required | 默认值 | 备注 |
|---|---|---|---|
| read.start-commit | false | the latest commit | 从开始提交指定最早消费 |
| read.end-commit | false | the latest commit | — |

若有收获,就点个赞吧
0 人点赞
