Presto 简介
- presto 是一个开源的分布式 SQL 查询引擎,适用于交互式分析查询,数据量支持 GB 到 PB 字节
- presto 的设计和编写完全是为了解决像 Facebook 这样规模的商业数据仓库的交互式分析和处理速度的问题
- 主要用来处理秒级查询场景
具体可以查看官网

Presto 架构
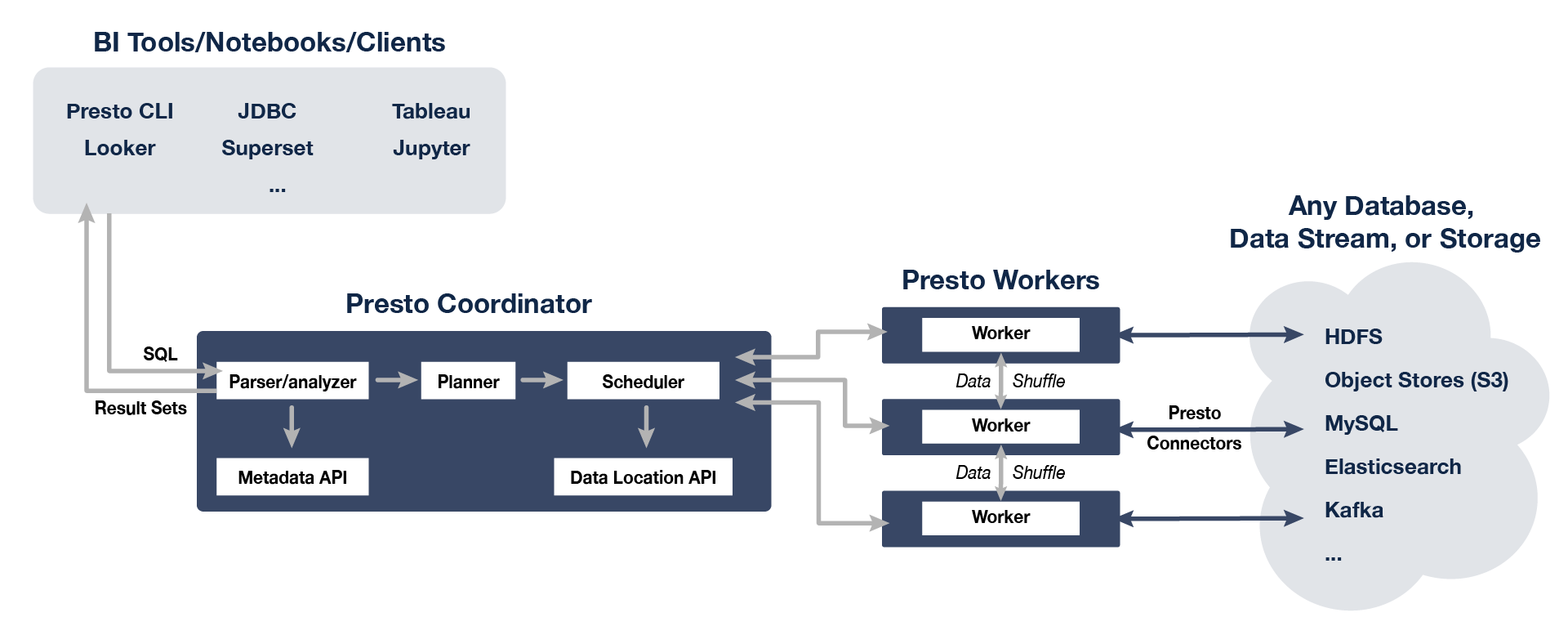
presto 架构图

Presto 安装
集群环境规划
| 机器名称 | IP地址 | 角色 |
|---|---|---|
| node01 | IPaddress1 | Worker |
| node02 | IPaddress2 | Worker |
| node03 | IPaddress3 | Worker |
| node04 | IPaddress4 | Coordinator |
| node05 | IPaddress4 | Presto CLI |
下载并安装 Presto
- 下载并解压 Presto ```bash cd /usr/local
tar xvf presto-server-0.273.3.tar.gz
- 建立软链接,便于后期版本更换```bashln -s presto-server-0.273.3/ presto-server
添加 Presto 到环境变量
打开配置文件
vi /etc/profile
添加 Hadoop 到环境变量
export PRESTO_HOME=/usr/local/presto-serverexport PATH=$PRESTO_HOME/bin:$PATH
使环境变量生效
source /etc/profile
配置 Presto
创建 Presto 配置文件目录和数据文件目录
```bash
创建 Presto 配置文件目录
mkdir /usr/local/presto-server/etc
创建 Presto 数据文件目录
mkdir /usr/local/presto-server/data
<a name="qOr4P"></a>### 切换到 Presto 配置文件目录```bashcd /usr/local/presto-server/etc
配置文件目录中放入以下配置信息:
- 节点属性:每个节点的环境配置信息。
- JVM 配置:JVM 的命令行选项。
- 配置属性:Presto Server 的配置信息。
- Catalog 属性:Connectors(数据源)的配置信息
创建 log.properties
可以在这个配置文件中设置 Logger 的最小日志级别。在 Presto 的日志配置文件中可以设置的日志级别一共4个:INFO、DEBUG、WARN、ERROR。
com.facebook.presto=INFO
创建 jvm.config
Presto 开发语言是 Java,每个 Presto 服务进程都是运行在 JVM 之上的,因此需要在 JVM 的配置文件中指定 Presto 服务进程的 Java 运行环境。该配置文件包含一系列在启动 JVM 时需要使用的命令行选项。
这份配置文件的格式为:每行一个命令行参数。由于该配置文件中的内容不会被 Shell 使用。因此即使某一行命令行参数包含了空格或者其他的特殊字符,也不需要使用引号括起来。
-server-Xmx8G-XX:+UseG1GC-XX:G1HeapRegionSize=32M-XX:+UseGCOverheadLimit-XX:+ExplicitGCInvokesConcurrent-XX:+HeapDumpOnOutOfMemoryError-XX:+ExitOnOutOfMemoryError-DHADOOP_USER_NAME=hdfs
由于 OutOfMemoryError 会导致 JVM 处于不一致状态,所以遇到这种错误的时候我们一般的处理措施就是将 dump headp中的信息(用于debugging),然后强制终止进程。
:::warning
配置说明:
-Xmx 指定最大 Heap 的大小
:::
创建 config.properties
在 Presto 集群中,每个节点都上都会启动一个 Presto 服务进程,该配置文件的配置项会应用于每个 Presto 的服务进程。每个服务进程既可以作为 Coordinator 也可以作为 Worker。但是在一个大型集群中,应该选定一个特定节点上的 Presto 服务进程只作为 Coordinator 提供服务,这样会提供更加卓越的性能。
Presto 集群中 Coordinator 节点的配置文件内容如下
coordinator=truenode-scheduler.include-coordinator=falsehttp-server.http.port=10008query.max-memory=50GBquery.max-memory-per-node=1GBquery.max-total-memory-per-node=2GBdiscovery-server.enabled=truediscovery.uri=http://node04:10008
Presto 集群中 Worker 节点的配置文件内容如下
coordinator=falsenode-scheduler.include-coordinator=truehttp-server.http.port=10008query.max-memory=50GBquery.max-memory-per-node=1GBquery.max-total-memory-per-node=2GBdiscovery.uri=http://node04:10008
安装 presto 时 worker 启动失败: Configuration property ‘discovery-server.enabled’ was not used
注释掉 woker 节点中(etc/config.properties): discovery-server.enabled=true 再启动即可
:::warning
- 如果我们只是使用一台机器用于测试,这台服务器既可以作为 Coordinator 也可以作为 Worker,那么就需要将配置属性 coordinator 和 node-scheduler.include-coordinator 设置为 true
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=10008
query.max-memory=50GB
query.max-memory-per-node=1GB
query.max-total-memory-per-node=2GB
discovery-server.enabled=true
discovery.uri=http://localhost:10008
:::
注意⚠️: max-total-memory-per-node 和 heap-headroom-per-node 加起来的内存不能超过
jvm.config-Xmx 指定最大 Heap 的大小,否则启动 presto 的时候会报错 The sum of max total query memory per node (2147483648) and heap headroom (644245094) cannot be larger than the available heap memory (2147483648)
:::warning 配置说明:
- coordinator
是否指定当前节点作为 Coordinator 节点,即当前节点可以接收来自客户端的查询请求,并且管理每个查询的执行过程。在 Presto 集群中 Coordinator 节点上配置文件中该属性值为 true,Worker 节点上配置文件中该属性值为 false。需要注意的是在 Coordinator 节点的配置文件和 Worker 节点的配置文件中该属性值是不同的。
- node-scheduler.include-coordinator
是否允许在 Coordinator 节点上执行计算任务。若允许执行计算任务,则 Coordinator 节点除了要接受客户端的查询请求,管理查询的执行过程外,还需要执行普通的计算任务。在大型的集群中,若在 Coordinator 节点上执行计算任务,反而会影响查询、生成查询计划和调度的效率,因为对于一些需要大量资源的计算任务,Coordinator 的大部分资源可能会被用于执行计算任务或者根本不能提供大型计算任务所需要的资源。
- http-server.http.port
指定HTTP服务器的端口。Presto 通过 HTTP 协议进行内部和外部的所有通信。
- query.max-memory
单个查询可以使用的最大内存。
- query.max-memory-per-node
单个查询可在一个节点上使用的最大用户内存(user memory)。
- query.max-total-memory-per-node
单个查询可在一个节点上使用的最大用户和系统内存(user memory + system memory)。
- discovery-server.enabled
Presto 使用 Discovery 服务来查找集群中所有节点。每个 Presto 实例在启动时都会向 Discovery 服务注册自己。Presto 为了简化部署,并且为了避免再增加一个新的服务,Presto 的 Coordinator 可以运行一个内嵌在 Coordinator 里面的 Discovery 服务。内嵌的 Discovery 服务与 Presto 共享 HTTP Server 并且使用相同的端口。
- discovery.uri
Discovery 服务的URI。因为我们已经将 Discovery 内嵌在 Coordinator 服务中,因此该 URI 就是 Presto 的 Coordinator 服务的 URI。例如,URI:http://localhost:10008,该 URI 其实就是 Coordinator 的 URI。注意:这个URI一定不能以/结尾。 :::
创建 node.properties
在每个 Presto 节点上都需要进行节点属性配置。node.properties 配置文件包含针对于每个节点的特定的配置信息。
配置文件至少包含如下配置信息
node.environment=prodnode.id=D17FDC86-8113-4AF0-9EC2-681A45ECFC2Enode.data-dir=/usr/local/presto-server/data
:::warning 配置说明:
- node.environment
Presto 运行环境名称。属于同一个集群中的 Presto 节点必须拥有相同的运行环境名称。
- node.id
每个 Presto 节点的唯一标示。同一个集群的每个 Presto 节点的 node.id
必须是不同的。在 Presto 进行重启或者升级过程中每个节点的 node.id
必须保持不变。如果在一个节点上安装多个 Presto 实例(例如:在同一台机器上安装多个 Presto 节点),那么每个 Presto 节点必须拥有唯一的 node.id。可以使用 Linux 命令 uuidgen生成 uuid 来指定该属性的内容。
- node.data-dir
数据存储目录的位置。Presto 将会把日志以及其它的 Presto 数据存储在这个目录下 :::
创建 catalog
catalog 目录下保存的是 Connectors(数据源)的配置信息
创建 catalog 配置目录
mkdir /usr/local/presto-server/etc/catalog
配置 Hive 的连接器 ```bash vim hive.properties
connector.name=hive-hadoop2 hive.metastore.uri=thrift://localhost:9083 hive.config.resources=/usr/local/hadoop/etc/hadoop/core-site.xml,/usr/local/hadoop/etc/hadoop/hdfs-site.xml
<a name="pQF2A"></a>## 启动 Presto 集群- 切换目录```bashcd /usr/local/presto-server/
先前台启动 Presto,观察输出日志,如果启动成功再后台启动
bin/launcher run
后台启动 Presto
bin/launcher start
停止 Presto
bin/launcher stop
启动 Presto 客户端
下载 Presto 客户端
下载 Presto 客户端 ```bash cd /usr/local
> 注意⚠️:> 一定要下载 [presto-cli-0.273.3-executable.jar](https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.273.3/presto-cli-0.273.3-executable.jar) 而不是 [presto-cli-0.273.3.jar](https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.273.3/presto-cli-0.273.3.jar),否则启动 Presto 客户端的时候会报错>> presto syntax error near unexpected token `)'- 添加执行权限```bashchmod 755 presto-cli-0.273.3-executable.jar
- 建立软链接,便于后期版本更换
ln -s presto-cli-0.273.3-executable.jar presto-cli
进入 Presto 客户端
- 进入 Presto 客户端
./presto-cli --server node04:10008 --catalog hive --schema default
配置说明:
- catalog 指定连接器
- schema 指定数据库
- 使用 Hive 创建一张表 ```bash beeline -u jdbc:hive2://localhost:10000 -n root
CREATE TABLE stuinfo(
idnumber STRING,
basicinfo STRUCT
)
COMMENT ‘学生信息表’
TBLPROPERTIES (‘creator’=’freeit’);
- 查看 Hive 表来判断是否创建成功```bashpresto:default> show tables;Table---------stuinfo(1 row)Query 20220708_090741_00024_jpfff, FINISHED, 1 nodeSplits: 19 total, 19 done (100.00%)174ms [1 rows, 24B] [5 rows/s, 138B/s]
- 查询 Hive 表 ```bash presto:default> select * from stuinfo; idnumber | basicinfo | score —————+—————-+———- (0 rows)
Query 20220711_061738_00010_pa8qc, FINISHED, 1 node Splits: 17 total, 17 done (100.00%) 236ms [0 rows, 0B] [0 rows/s, 0B/s]
> 查询的时候会遇到 lzo 压缩问题,错入如下:> failed: Unable to create input format com.hadoop.mapred.DeprecatedLzoTextInputFormat>> 需要将 hadoop-lzo-0.4.20.jar 加入到 presto-server 中,并重启服务就可以了:> wget https://maven.twttr.com/com/hadoop/gplcompression/hadoop-lzo/0.4.20/hadoop-lzo-0.4.20.jar> mv hadoop-lzo-0.4.20.jar /usr/local/presto-server/plugin/hive-hadoop2/>> QingMR 安装的 hadoop 也有这个 jar 包,路径为 /opt/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar- 我们还可以访问其 UI:http://localhost:10008/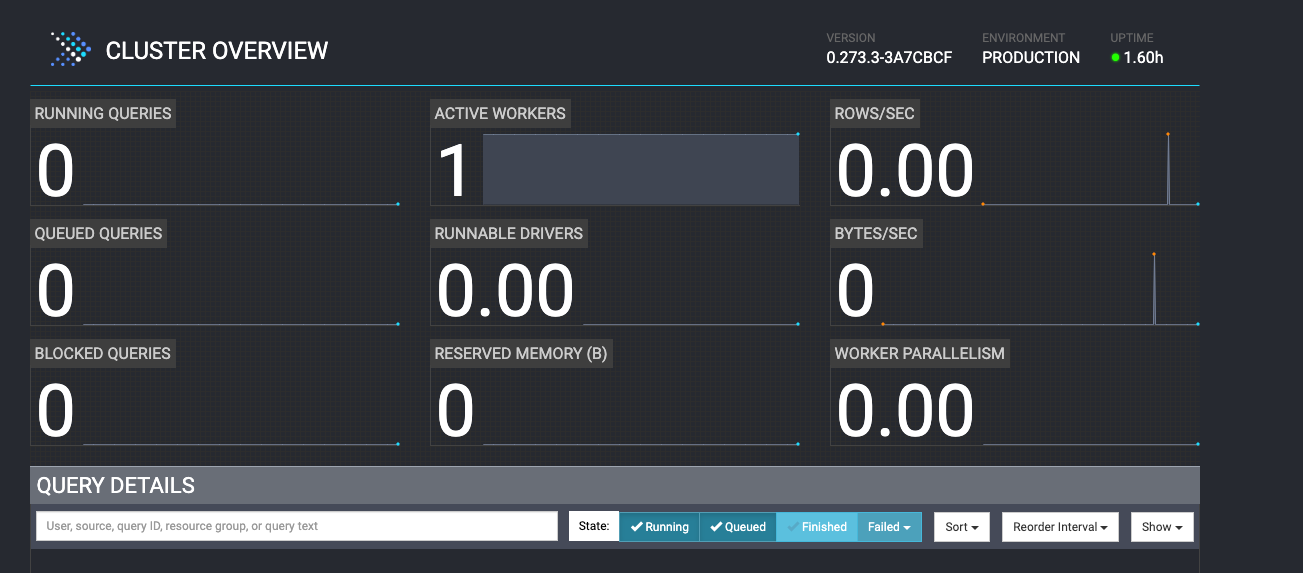<a name="Cdjju"></a># **使用 Presto 查询 **Hudi- 我们下载的 Presto 版本已经包含 hudi-presto-bundle-0.10.1.jar,如果要使用 0.11.1 版本的 hudi 需要下载 hudi-presto-bundle-0.11.1.jar 并将其放在 <presto_install>/plugin/hive-hadoop2/ 中,并删除 hudi-presto-bundle-0.10.1.jar```bashwget https://repo.maven.apache.org/maven2/org/apache/hudi/hudi-presto-bundle/0.11.1/hudi-presto-bundle-0.11.1.jarmv hudi-presto-bundle-0.11.1.jar /usr/local/presto-server/plugin/hive-hadoop2/
wget https://repo.maven.apache.org/maven2/org/apache/hudi/hudi-hadoop-mr-bundle/0.11.1/hudi-hadoop-mr-bundle-0.11.1.jar
参考文档

若有收获,就点个赞吧
0 人点赞
