安装并启动 MySQL、PostgreSQL
- 安装并启动 MySQL(Server version: 8.0.28-0ubuntu0.20.04.3 )
sudo apt updatesudo apt install mysql-serversudo systemctl enable mysqlsudo systemctl status mysql
:::warning 注意⚠️:需要开启 binlog 以及 binlog_format 必须是 row 格式,默认配置即可,不需要做额外操作
log-bin=/var/lib/mysql/mysql-bin.log # 指定 binlog 日志存储位置
binlog_format=ROW # 这里一定是 row 格式
expire-logs-days = 14 # 日志保留时间
max-binlog-size = 500M # 日志滚动大小
:::
- 安装并启动 PostgreSQL( PostgreSQL 12.9-0ubuntu0.20.04.1)
sudo apt updatesudo apt install postgresql postgresql-contribsudo systemctl enable postgresqlsudo systemctl status postgresql
安装并启动 Elasticsearch 和 Kibana
- 安装并启动 Elasticsearch 和 Kibana
sudo apt updatesudo apt install apt-transport-https ca-certificateswget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -sudo sh -c 'echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" > /etc/apt/sources.list.d/elastic-7.x.list'sudo apt updatesudo apt install elasticsearchsudo apt-get install kibanasudo systemctl enable --now elasticsearch.servicesudo systemctl enable --now kibana.service
(可选)配置 Elasticsearch 远程访问
修改 elasticsearch.yml 配置文件
cat <<EOF >> /etc/elasticsearch/elasticsearch.ymlnetwork.host: 0.0.0.0discovery.seed_hosts: ["127.0.0.1"] # 必须配置,否则报错EOF
重启 Elasticsearch 服务,使得应用生效
sudo systemctl daemon-reloadsudo systemctl restart elasticsearch
(可选)配置 Kibana 远程访问
打开 kibana.yml 配置文件
cat <<EOF >> /etc/kibana/kibana.ymlserver.host: 0.0.0.0EOF
重启 Kibana 服务,使得应用生效
sudo systemctl daemon-reloadsudo systemctl restart kibana
安装并启动 Kafka
在 Ubuntu 20.04 LTS 上安装 Apache Kafka
安装并启动 Debezium
切换到 kafka 安装目录
cd /usr/local/kafka
创建存放 Kafka 连接器的文件夹
mkdir kafka-connectors
切换到 Kafka 连接器文件夹
cd kafka-connectors
下载 Kafka 连接器并解压 ```bash wget https://repo1.maven.org/maven2/io/debezium/debezium-connector-mysql/1.8.1.Final/debezium-connector-mysql-1.8.1.Final-plugin.tar.gz
tar xfz debezium-connector-mysql-1.8.1.Final-plugin.tar.gz && rm debezium-connector-mysql-1.8.1.Final-plugin.tar.gz
tar xfz debezium-connector-postgres-1.8.1.Final-plugin.tar.gz && rm debezium-connector-postgres-1.8.1.Final-plugin.tar.gz
- 修改 kafka connect 配置文件,配置插件位置,这里使用集群模式```bashcat <<EOF >> /usr/local/kafka/config/connect-distributed.propertiesplugin.path=/usr/local/kafka/kafka-connectorsEOF
:::info
Connect 也支持单机模式
单机模式与集群模式类似,只是配置文件为 connect-standalone.properties,在启动时使用bin/connect-standalone.sh,启动的进程是 ConnectStandalone
单机模式使用起来更简单,特别是在开发和诊断问题的时候,或者是在需要让连接器和任务运行在某台特定机器上的时候
:::
:::info Connect 有以下几个重要的配置参数
- bootstrap.servers:该参数列出了将要与Connect协同工作的broker服务器,连接器将会向这些broker写入数据或者从它们那里读取数据。你不需要指定集群所有的broker,不过建议至少指定3个
- group.id:具有相同 group id 的 worker 属于同一个Connect集群。集群的连接器和它们的任务可以运行在任意一个worker上。
- key.converter和value.converter:Connect可以处理存储在Kafka里的不同格式的数据。这两个参数分别指定了消息的键和值所使用的转换器。默认使用Kafka提供的JSONConverter,当然也可以配置成Confluent Schema Registry提供的AvroConverter
- 有些转换器还包含了特定的配置参数。例如,通过将key.converter.schema.enable设置成true或者false来指定JSON消息是否可以包含schema。值转换器也有类似的配置,不过它的参数名是value.converter.schema.enable。Avro消息也包含了schema,不过需要通过key.converter.schema.registry.url和value.converter.schema.registry.url来 指 定Schema Registry的位置。 :::
(可选)可以将 key.converter.schema.enable 和 value.converter.schema.enable 设置成 false,这样 JSON 消息不会包含 schema,减少冗余存储
key.converter.schemas.enable=falsevalue.converter.schemas.enable=false
启动连接器 ```bash cd /usr/local/kafka
bin/connect-distributed.sh -daemon config/connect-distributed.properties
:::info可以将 /usr/local/kafka 拷贝其他机器上,在其他机器上也启动连接器,这些机器组成一个集群:::- 查看日志```bashtail -f logs/connectDistributed.out
查看是否正常启动,ConnectDistributed 就是启动的进程
jps8147 Jps596 Kafka680 QuorumPeerMain8012 ConnectDistributed
为了更方便查看 json 数据,我们需要安装 jq
apt install jq
通过 REST API 查看是否正常启动,返回当前 Connect 的版本号 ```bash curl -H “Accept:application/json” localhost:8083 | jq { “version”: “2.8.1”, “commit”: “839b886f9b732b15”, “kafka_cluster_id”: “-41s96u9Rz6XECIr-Pruzw” }
- 查看 connectors```bashcurl -H "Accept:application/json" localhost:8083/connectors | jq[]
- 查看已经安装好的连接器插件
可以看到 debezium 的 MySQL和 Postgres 的连接器已经安装好curl -H "Accept:application/json" localhost:8083/connector-plugins | jq[{"class": "io.debezium.connector.mysql.MySqlConnector","type": "source","version": "1.8.1.Final"},{"class": "io.debezium.connector.postgresql.PostgresConnector","type": "source","version": "1.8.1.Final"},{"class": "org.apache.kafka.connect.file.FileStreamSinkConnector","type": "sink","version": "2.8.1"},{"class": "org.apache.kafka.connect.file.FileStreamSourceConnector","type": "source","version": "2.8.1"},{"class": "org.apache.kafka.connect.mirror.MirrorCheckpointConnector","type": "source","version": "1"},{"class": "org.apache.kafka.connect.mirror.MirrorHeartbeatConnector","type": "source","version": "1"},{"class": "org.apache.kafka.connect.mirror.MirrorSourceConnector","type": "source","version": "1"}]
使用 Debezium 同步 MySQL 数据到 Kafka
:::info MySQL: 商品表 products 和 订单表 orders 将存储在该数据库中, 这两张表将和 Postgres 数据库中的物流表 shipments 进行关联,得到一张包含更多信息的订单表 enriched_orders :::
在 MySQL 数据库中准备数据
使用 root 用户登录 MySQL
mysql
创建数据库和表 products,orders,并插入数据 ```json — MySQL CREATE DATABASE mydb;
USE mydb;
CREATE TABLE products ( id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY, name VARCHAR(255) NOT NULL, description VARCHAR(512) );
ALTER TABLE products AUTO_INCREMENT = 101;
INSERT INTO products VALUES (default,”scooter”,”Small 2-wheel scooter”), (default,”car battery”,”12V car battery”), (default,”12-pack drill bits”,”12-pack of drill bits with sizes ranging from #40 to #3”), (default,”hammer”,”12oz carpenter’s hammer”), (default,”hammer”,”14oz carpenter’s hammer”), (default,”hammer”,”16oz carpenter’s hammer”), (default,”rocks”,”box of assorted rocks”), (default,”jacket”,”water resistent black wind breaker”), (default,”spare tire”,”24 inch spare tire”);
CREATE TABLE orders ( order_id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY, order_date DATETIME NOT NULL, customer_name VARCHAR(255) NOT NULL, price DECIMAL(10, 5) NOT NULL, product_id INTEGER NOT NULL, order_status BOOLEAN NOT NULL — Whether order has been placed ) AUTO_INCREMENT = 10001;
INSERT INTO orders VALUES (default, ‘2020-07-30 10:08:22’, ‘Jark’, 50.50, 102, false), (default, ‘2020-07-30 10:11:09’, ‘Sally’, 15.00, 105, false), (default, ‘2020-07-30 12:00:30’, ‘Edward’, 25.25, 106, false);
<a name="UtZQo"></a>## 创建 Debezium 用于同步数据的用户并授权- 使用 root 用户登录 MySQL```jsonmysql
- 创建 Debezium 用于同步数据的用户并授权 ```bash CREATE USER ‘debezium’@’%’ IDENTIFIED BY ‘123456’;
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON . TO ‘debezium’;
FLUSH PRIVILEGES;
<a name="B82G8"></a>## 配置 MySQL 连接信息(Distributed 模式)- 切换到 kafka 安装目录```jsoncd /usr/local/kafka
- 将 MySQL 连接信息保存到 dbz-mysql-connector.json 文件中
cat <<EOF > kafka-connectors/dbz-mysql-connector.json{"name":"dbz-mysql-connector","config":{"connector.class":"io.debezium.connector.mysql.MySqlConnector","tasks.max":"1","database.hostname":"localhost","database.port":"3306","database.user":"debezium","database.password":"123456","database.server.id":"184054","database.server.name":"mysql","database.include.list":"mydb","database.history.kafka.bootstrap.servers":"localhost:9092","database.history.kafka.topic":"dbhistory.mysql","database.allowPublicKeyRetrieval":"true","decimal.handling.mode":"double","tombstones.on.delete":"false"}}EOF
:::info
- name:标识连接器的名称
- connector.class:对应数据库类
- tasks.max:默认1
- database.hostname:数据库 ip
- database.port:数据库端口
- database.user:数据库登录名
- database.password:数据库密码
- database.server.id:数据库 id,标识当前库,不重复就行
- database.server.name:给数据库取别名
- database.include.list:类似白名单,里面的库可以监控到,不在里面监控不到,多库逗号分隔,支持正则匹配
- database.history.kafka.bootstrap.servers:保存表 DDL 相关信息的 kafka 地址
- database.history.kafka.topic:表 DDL 相关信息会保存在这个 topic 里面
- decimal.handling.mode:当处理 decimal和 Int 类型时,默认是二进制显示,我们改为 double 显示
- snapshot.mode:快照模式,这个需要具体情况,具体分析,因为我只需要实时数据,不需要历史数据,所以设置为 schema_only
- tombstones.on.delete:默认是 True,当我们删除记录的时候,会产生两天数据,第二条为NULL,但是我们不希望出现NULL,所以设置为 False
- table.include.list:类似白名单,里面的表可以监控到,不在里面监控不到,多表逗号分隔,支持正则匹配 :::
:::danger
MySQL v8 报错 Unable to connect: Public Key Retrieval is not allowed,需要添加配置项
“database.allowPublicKeyRetrieval”:”true”,
https://rmoff.net/2019/10/23/debezium-mysql-v8-public-key-retrieval-is-not-allowed/
:::
启动连接器
bin/connect-distributed.sh -daemon config/connect-distributed.properties
配置 MySQL 连接信息
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors/ -d @kafka-connectors/dbz-mysql-connector.json
查看 Kafka 的 Topic 列表
bin/kafka-topics.sh --zookeeper localhost:2181 --list__consumer_offsetsconnect-configsconnect-offsetsconnect-statusdbhistory.mysqlmysqlmysql.mydb.ordersmysql.mydb.products
Kafka 主题名称使用
. . 这样的格式。 查看 Kafka 的 Topic 信息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic mysql.mydb.orders | jq{"before": null,"after": {"order_id": 10001,"order_date": 1596103702000,"customer_name": "Jark","price": "50.50000","product_id": 102,"order_status": 0},"source": {"version": "1.8.1.Final","connector": "mysql","name": "mysql","ts_ms": 1648193001632,"snapshot": "true","db": "mydb","sequence": null,"table": "orders","server_id": 0,"gtid": null,"file": "binlog.000005","pos": 3100,"row": 0,"thread": null,"query": null},"op": "r","ts_ms": 1648193001637,"transaction": null}{"before": null,"after": {"order_id": 10002,"order_date": 1596103869000,"customer_name": "Sally","price": "15.00000","product_id": 105,"order_status": 0},"source": {"version": "1.8.1.Final","connector": "mysql","name": "mysql","ts_ms": 1648193001641,"snapshot": "true","db": "mydb","sequence": null,"table": "orders","server_id": 0,"gtid": null,"file": "binlog.000005","pos": 3100,"row": 0,"thread": null,"query": null},"op": "r","ts_ms": 1648193001641,"transaction": null}{"before": null,"after": {"order_id": 10003,"order_date": 1596110430000,"customer_name": "Edward","price": "25.25000","product_id": 106,"order_status": 0},"source": {"version": "1.8.1.Final","connector": "mysql","name": "mysql","ts_ms": 1648193001641,"snapshot": "true","db": "mydb","sequence": null,"table": "orders","server_id": 0,"gtid": null,"file": "binlog.000005","pos": 3100,"row": 0,"thread": null,"query": null},"op": "r","ts_ms": 1648193001642,"transaction": null}
清除环境
删除 connector
curl -X DELETE http://localhost:8083/connectors/dbz-mysql-connector
停止 Kafka Connect
jps | grep ConnectDistributed | awk '{print $1}' | xargs kill -9
删除 topic ```json bin/kafka-topics.sh —zookeeper localhost:2181 —delete —topic mysql bin/kafka-topics.sh —zookeeper localhost:2181 —delete —topic dbhistory.mysql bin/kafka-topics.sh —zookeeper localhost:2181 —delete —topic mysql.mydb.products bin/kafka-topics.sh —zookeeper localhost:2181 —delete —topic mysql.mydb.orders
bin/kafka-topics.sh —zookeeper localhost:2181 —delete —topic connect-configs bin/kafka-topics.sh —zookeeper localhost:2181 —delete —topic connect-offsets bin/kafka-topics.sh —zookeeper localhost:2181 —delete —topic connect-status
bin/kafka-topics.sh —zookeeper localhost:2181 —list
:::info注意⚠️:Standalone 模式在启动 Kafka Connect 的时候通过 connector.properties 进行配置。- 将 MySQL 连接信息保存到 dbz-mysql-connector.properties 文件中:::```bashcat <<EOF > kafka-connectors/dbz-mysql-connector.propertiesname=dbz-mysql-connectorconnector.class=io.debezium.connector.mysql.MySqlConnectortasks.max=1database.hostname=localhostdatabase.port=3306database.user=debeziumdatabase.password=123456database.server.id=184054database.server.name=mysqldatabase.include.list=mydbdatabase.history.kafka.bootstrap.servers=localhost:9092database.history.kafka.topic=dbhistory.mysqldatabase.allowPublicKeyRetrieval=truedecimal.handling.mode=doubletombstones.on.delete=falseEOF
:::info
启动连接器 :::
/usr/local/kafka/bin/connect-standalone.sh config/connect-standalone.properties kafka-connectors/dbz-mysql-connector.properties
使用 Debezium 同步 Postgres 数据到 Kafka
:::info Postgres: 物流表 shipments 将存储在该数据库中 :::
配置 Postgres 数据库
修改 postgresql.conf ```json vim /etc/postgresql/12/main/postgresql.conf
更改wal日志方式为 logical
wal_level = logical # minimal, replica, or logical
中断那些停止活动超过指定毫秒数的复制连接,可以适当设置大一点(默认60s)
wal_sender_timeout = 180s # in milliseconds; 0 disable
- 修改 pg_hba.conf```jsonvim /etc/postgresql/12/main/pg_hba.conf# TYPE DATABASE USER ADDRESS METHOD############ REPLICATION ##############local replication all trusthost replication all 127.0.0.1/32 trusthost replication all ::1/128 trust
:::info
- METHOD 这里指定的是
trust,无条件地允许连接。这种方法允许任何可以与 PostgreSQL 数据库服务器连接的用户以他们期望的任意 PostgreSQL 数据库用户身份登入,而不需要口令或者其他任何认证。 - USER 这里指定的是
all,如果已创建具有 REPLICATION 和 LOGIN 权限的其他用户,可以更改为其他用户。 - ADDRESS 这里指定的是
127.0.0.1/32(IPv4 回环地址) 和::1/128(IPv6 回环地址),可以更改为0.0.0.0/0表示所有 IPv4 地址,::0/0表示所有 IPv6 地址 :::
hba 配置参考文章 http://www.postgres.cn/docs/9.6/auth-pg-hba-conf.html
重启 postgresql 服务生效,所以一般是在业务低峰期更改
sudo systemctl daemon-reloadsudo systemctl restart postgresql
(可选)使用 wal2json 插件
使用 wal2json 插件
使用
wal2json插件(需要安装),也可以使用 pgsql 自带的pgoutput(不需要安装)。安装 wal2json 插件
sudo apt-get install postgresql-12-wal2json
修改 postgresql.conf
# 使用 wal2json 插件shared_preload_libraries = 'wal2json'
测试 wal2json 插件
创建名为 test 的数据库和名为 test_table 的表 ```json CREATE DATABASE test;
\c test
CREATE TABLE test_table ( id char(10) NOT NULL, code char(10), PRIMARY KEY (id) );
- 为 test 的数据库创建名为 test_slot 的槽,使用 wal2json```jsonsudo su - postgrespg_recvlogical -d test --slot test_slot --create-slot -P wal2json
开始从 test 数据库的逻辑复制槽 test_slot 流式传输更改
pg_recvlogical -d test --slot test_slot --start -o pretty-print=1 -f -
在 test_table 执行一些基本的 DML 操作以触发 INSERT/UPDATE/DELETE 更改事件 ```json INSERT INTO test_table (id, code) VALUES(‘id1’, ‘code1’);
update test_table set code=’code2’ where id=’id1’;
delete from test_table where id=’id1’;
:::warning注意⚠️:表 test_table 的 REPLICA IDENTITY 设置为 DEFAULT:::在发生 INSERT、UPDATE 和 DELETE 事件时,wal2json 插件输出由 pg_recvlogical 捕获的表更改。- INSERT 事件的输出```json{"change": [{"kind": "insert","schema": "public","table": "test_table","columnnames": ["id", "code"],"columntypes": ["character(10)", "character(10)"],"columnvalues": ["id1 ", "code1 "]}]}
UPDATE 事件的输出
{"change": [{"kind": "update","schema": "public","table": "test_table","columnnames": ["id", "code"],"columntypes": ["character(10)", "character(10)"],"columnvalues": ["id1 ", "code2 "],"oldkeys": {"keynames": ["id"],"keytypes": ["character(10)"],"keyvalues": ["id1 "]}}]}
DELETE 事件的输出
{"change": [{"kind": "delete","schema": "public","table": "test_table","oldkeys": {"keynames": ["id"],"keytypes": ["character(10)"],"keyvalues": ["id1 "]}}]}
测试完成后,可以通过以下命令删除 test 数据库的槽 test_slot
pg_recvlogical -d test --slot test_slot --drop-slot
删除 test 数据库 ```json \c postgres
drop database test;
:::infoREPLICA IDENTITY,是一个 PostgreSQL 特定的表级设置,它确定在 UPDATE 和 DELETE 事件的情况下可用于逻辑解码的信息量。REPLICA IDENTITY 有 4 个可能的值:- DEFAULT - UPDATE 和 DELETE 事件将仅包含表的主键列的旧值- NOTHING - UPDATE 和 DELETE 事件将不包含有关任何表列上旧值的任何信息- FULL - UPDATE 和 DELETE 事件将包含表中所有列的旧值- INDEX 索引名称 - UPDATE 和 DELETE 事件将包含名为 index name 的索引定义中包含的列的旧值可以使用以下命令修改和检查表的副本 REPLICA IDENTITY::::```jsonALTER TABLE test_table REPLICA IDENTITY FULL;test=# \d+ test_tableTable "public.test_table"Column | Type | Modifiers | Storage | Stats target | Description-------+---------------+-----------+----------+--------------+------------id | character(10) | not null | extended | |code | character(10) | | extended | |Indexes:"test_table_pkey" PRIMARY KEY, btree (id)Replica Identity: FULL
:::info 这是 wal2json 插件在 UPDATE 事件和 REPLICA IDENTITY 设置为 FULL 时的输出。 与 REPLICA IDENTITY 设置为 DEFAULT 时的相应输出进行比较。
UPDATE 事件的输出 :::
{"change": [{"kind": "update","schema": "public","table": "test_table","columnnames": ["id", "code"],"columntypes": ["character(10)", "character(10)"],"columnvalues": ["id1 ", "code2 "],"oldkeys": {"keynames": ["id", "code"],"keytypes": ["character(10)", "character(10)"],"keyvalues": ["id1 ", "code1 "]}}]}
在 Postgres 数据库中准备数据
使用 postgres 用户登录 PostgreSQL
sudo -u postgres psql
创建数据库和创建表 shipments,并插入数据 ```json — PG CREATE DATABASE mydb;
\c mydb
CREATE TABLE shipments ( shipment_id SERIAL NOT NULL PRIMARY KEY, order_id SERIAL NOT NULL, origin VARCHAR(255) NOT NULL, destination VARCHAR(255) NOT NULL, is_arrived BOOLEAN NOT NULL );
ALTER SEQUENCE public.shipments_shipment_id_seq RESTART WITH 1001;
— 更改复制标识包含更新和删除之前值 ALTER TABLE public.shipments REPLICA IDENTITY FULL;
INSERT INTO shipments VALUES (default,10001,’Beijing’,’Shanghai’,false), (default,10002,’Hangzhou’,’Shanghai’,false), (default,10003,’Shanghai’,’Hangzhou’,false);
<a name="fEW8Z"></a>## 创建 Debezium 用于同步数据的用户并授权- 使用 postgres 用户登录 PostgreSQL```jsonsudo -u postgres psql
- 创建 Debezium 用于同步数据的用户并授权
使用 pgoutput
-- 创建 debezium 用户并赋予 REPLICATION LOGIN 权限CREATE USER debezium WITH PASSWORD '123456' REPLICATION LOGIN;-- 创建一个 replication_group 用于共享所有权CREATE ROLE replication_group;-- 将现有表所有者和复制用户添加到该组GRANT replication_group TO postgres;GRANT replication_group TO debezium;-- 将表的所有权转交给 replication_group,这样 debezium 和 postgres都用表的所有权ALTER TABLE public.shipments OWNER TO replication_group;-- 把 mydb 数据库创建新的模式和发布的权限赋给 debeziumGRANT CREATE ON DATABASE mydb TO debezium;
:::info 如果使用 pgoutput 需要 REPLICATION,LOGIN,CREATE,SELECT 权限,并且必须是表的所有者,表所有者自动拥有表的 SELECT 权限,所以只需要 CREATE 权限。 :::
(可选)使用 wal2json
-- 创建 debezium 用户并赋予 REPLICATION LOGIN 权限CREATE USER debezium WITH PASSWORD '123456' REPLICATION LOGIN;-- 把 shipments 表查询权限赋给用户GRANT SELECT ON public.shipments TO debezium;
:::info
如果使用 wal2json 插件需要 REPLICATION,LOGIN,SELECT 权限,也可以使用下面语句把 schema public 下所有表查询权限赋给用户
GRANT SELECT ON ALL TABLES IN SCHEMA public TO debezium;
:::
PostgreSQL 权限配置参考文章 PostgreSQL 角色管理 PostgreSQL 权限
配置 PostgresSQL 连接信息(Distributed 模式)
切换到 kafka 安装目录
cd /usr/local/kafka
将 PostgresSQL 连接信息保存到 dbz-postgresql-connector.json 文件中
使用 pgoutput
cat <<EOF > kafka-connectors/dbz-pg-connector.json{"name":"dbz-pg-connector","config": {"connector.class": "io.debezium.connector.postgresql.PostgresConnector","tasks.max": "1","database.hostname": "localhost","database.port": "5432","database.user": "debezium","database.password": "123456","database.dbname" : "mydb","database.server.id":"121041","database.server.name": "pg","decimal.handling.mode":"double","tombstones.on.delete":"false","heartbeat.interval.ms":"100","publication.autocreate.mode":"filtered","plugin.name":"pgoutput"}}EOF
:::info
在使用 pgoutput 插件时,建议将过滤publication.autocreate.mode 配置为 filtered。 如果使用 all_tables(publication.autocreate.mode 的默认值)并且未找到该发布,则连接器会尝试使用 CREATE PUBLICATION <publication_name> FOR ALL TABLES; 创建一个,但由于缺少权限而失败。
:::
(可选)使用 wal2json
cat <<EOF > kafka-connectors/dbz-pg-connector.json{"name":"dbz-pg-connector","config": {"connector.class": "io.debezium.connector.postgresql.PostgresConnector","tasks.max": "1","database.hostname": "localhost","database.port": "5432","database.user": "debezium","database.password": "123456","database.dbname" : "mydb","database.server.id":"121041","database.server.name": "pg","decimal.handling.mode":"String","tombstones.on.delete":"false","heartbeat.interval.ms":"100","plugin.name":"wal2json"}}EOF
:::info
- name:标识连接器的名称
- connector.class:对应数据库类
- database.hostname:数据库ip
- database.port:数据库端口
- database.user:数据库登录名
- database.password:数据库密码
- database.dbname:数据库名称
- database.server.name:给数据库取别名
- schema.include.list:类似白名单,里面的模式可以监控到,不在里面监控不到,多模式逗号分隔,支持正则匹配
- slot.name:slot的名称
- snapshot.mode:快照模式,这个需要具体情况,具体分析,因为我只需要实时数据,不需要历史数据,所以设置为never
- table.include.list:类似白名单,里面的表可以监控到,不在里面监控不到,多表逗号分隔,支持正则匹配
- publication.autocreate.mode:发布表处理策略
- disabled - 连接器不会尝试创建 Publicatin
- all_tables - 如果 pg 中不存在该 Publication,则自动创建一个包含所有表的 Publicatin
- filtered - 与 all_talbes 不同的是自动创建只包含 table.include.list 的 Publication
- decimal.handling.mode:当处理 decimal 和 Int 类型时,默认是二进制显示,我们改为字符串显示
- heartbeat.interval.ms:控制连接器向 Kafka 主题发送心跳消息的频率。默认行为是连接器不发送心跳消息(毫秒)
- tombstones.on.delete:默认是 True,当我们删除记录的时候,会产生两条数据,第二条为 NULL,但是我们不希望出现 NULL,所以设置为 False
plugin.name:使用wal2json插件(需要安装),也可以使用pgsql 自带的 pgoutput (不需要安装) :::
启动连接器
bin/connect-distributed.sh -daemon config/connect-distributed.properties
配置 PostgresSQL 连接信息
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors/ -d @kafka-connectors/dbz-pg-connector.json
查看 Kafka 的 Topic 列表
bin/kafka-topics.sh --zookeeper localhost:2181 --list__consumer_offsets__debezium-heartbeat.pgconnect-configsconnect-offsetsconnect-statuspg.public.shipments
Kafka 主题名称使用 serverName.schemaName.tableName 这样的格式。
Kafka 的 Topic 信息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic pg.public.shipments | jq{"before": null,"after": {"shipment_id": 1001,"order_id": 10001,"origin": "Beijing","destination": "Shanghai","is_arrived": false},"source": {"version": "1.8.1.Final","connector": "postgresql","name": "pg","ts_ms": 1648199166117,"snapshot": "true","db": "mydb","sequence": "[null,\"23741376\"]","schema": "public","table": "shipments","txId": 511,"lsn": 23741376,"xmin": null},"op": "r","ts_ms": 1648199166120,"transaction": null}{"before": null,"after": {"shipment_id": 1002,"order_id": 10002,"origin": "Hangzhou","destination": "Shanghai","is_arrived": false},"source": {"version": "1.8.1.Final","connector": "postgresql","name": "pg","ts_ms": 1648199166123,"snapshot": "true","db": "mydb","sequence": "[null,\"23741376\"]","schema": "public","table": "shipments","txId": 511,"lsn": 23741376,"xmin": null},"op": "r","ts_ms": 1648199166123,"transaction": null}{"before": null,"after": {"shipment_id": 1003,"order_id": 10003,"origin": "Shanghai","destination": "Hangzhou","is_arrived": false},"source": {"version": "1.8.1.Final","connector": "postgresql","name": "pg","ts_ms": 1648199166124,"snapshot": "last","db": "mydb","sequence": "[null,\"23741376\"]","schema": "public","table": "shipments","txId": 511,"lsn": 23741376,"xmin": null},"op": "r","ts_ms": 1648199166124,"transaction": null}
清除环境
删除 connector
curl -X DELETE http://localhost:8083/connectors/dbz-pg-connector
停止 Kafka Connect
jps | grep ConnectDistributed | awk '{print $1}' | xargs kill -9
删除 topic ```json bin/kafka-topics.sh —zookeeper localhost:2181 —delete —topic pg.public.shipments bin/kafka-topics.sh —zookeeper localhost:2181 —delete —topic __debezium-heartbeat.pg
bin/kafka-topics.sh —zookeeper localhost:2181 —delete —topic connect-configs bin/kafka-topics.sh —zookeeper localhost:2181 —delete —topic connect-offsets bin/kafka-topics.sh —zookeeper localhost:2181 —delete —topic connect-status
bin/kafka-topics.sh —zookeeper localhost:2181 —list
<a name="PqeWn"></a># 使用 Flink SQL 进行 ETL:::infoElasticsearch: 最终的订单表 enriched_orders 将写到 Elasticsearch:::<a name="aKv0u"></a>## 安装并启动 Flink- 下载 [Flink 1.13.6](https://dlcdn.apache.org/flink/flink-1.13.6/flink-1.13.6-bin-scala_2.12.tgz) (使用的是 scala_2.12 版本)并将其解压至目录 flink-1.13.6```jsonwget https://dlcdn.apache.org/flink/flink-1.13.6/flink-1.13.6-bin-scala_2.12.tgztar -xvf flink-1.13.6-bin-scala_2.12.tgz
- 下载下面列出的依赖包,并将它们放到目录 flink-1.13.6/lib/ 下 ```json cd flink-1.13.6/lib/
wget https://jdbc.postgresql.org/download/postgresql-42.3.3.jar
- [flink-sql-connector-kafka_2.12-1.13.6.jar](https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-kafka_2.12/1.13.6/flink-sql-connector-kafka_2.12-1.13.6.jar)- [flink-connector-jdbc_2.12-1.13.6.jar](https://repo.maven.apache.org/maven2/org/apache/flink/flink-connector-jdbc_2.12/1.13.6/flink-connector-jdbc_2.12-1.13.6.jar)- [42.3.3 JDBC 42 (postgresql.org)](https://jdbc.postgresql.org/download/postgresql-42.3.3.jar)- [flink-sql-connector-elasticsearch7_2.12-1.13.6.jar](https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-elasticsearch7_2.12/1.13.6/flink-sql-connector-elasticsearch7_2.12-1.13.6.jar)- 启动 flink 集群```jsoncd ~/flink-1.13.6bin/start-cluster.sh
在 Flink SQL CLI 中使用 Flink DDL 创建 Source 表
启动 sql-client
bin/sql-client.sh
开启 checkpoint,每隔 3 秒做一次 checkpoint
SET 'execution.checkpointing.interval' = '3s';
Flink SQL 创建 Source 表 ```json CREATE TABLE products ( id INT, name STRING, description STRING, PRIMARY KEY (id) NOT ENFORCED ) WITH ( ‘connector’ = ‘kafka’, ‘topic’ = ‘mysql.mydb.products’, ‘properties.bootstrap.servers’ = ‘localhost:9092’, ‘scan.startup.mode’ = ‘earliest-offset’, ‘format’ = ‘debezium-json’ );
CREATE TABLE orders ( order_id INT, order_date BIGINT, — debezium MySQL 插件会将 DATETIME 转换成 INT64 customer_name STRING, price DECIMAL(10, 5), product_id INT, order_status BOOLEAN, PRIMARY KEY (order_id) NOT ENFORCED ) WITH ( ‘connector’ = ‘kafka’, ‘topic’ = ‘mysql.mydb.orders’, ‘properties.bootstrap.servers’ = ‘localhost:9092’, ‘scan.startup.mode’ = ‘earliest-offset’, ‘format’ = ‘debezium-json’ );
CREATE TABLE shipments ( shipment_id INT, order_id INT, origin STRING, destination STRING, is_arrived BOOLEAN, PRIMARY KEY (shipment_id) NOT ENFORCED ) WITH ( ‘connector’ = ‘kafka’, ‘topic’ = ‘pg.public.shipments’, ‘properties.bootstrap.servers’ = ‘localhost:9092’, ‘scan.startup.mode’ = ‘earliest-offset’, ‘format’ = ‘debezium-json’ );
:::infoorder_date 类型为 BIGINT 而不是 TIMESTAMP(0)<br />对于 json 格式,debezium MySQL 插件会将 DATETIME 转换成 INT64::::::info在某些情况下,用户在设置 Debezium Kafka Connect 时,可能会开启 Kafka 的配置 'value.converter.schemas.enable',用来在消息体中包含 schema 信息需要在上述 DDL WITH 子句中添加选项 'debezium-json.schema-include' = 'true'(默认为 false)。通常情况下,建议不要包含 schema 的描述,因为这样会使消息变得非常冗长,并降低解析性能:::<a name="GNCGh"></a>## 关联订单数据并且将其写入 Elasticsearch 中- Flink SQL 创建 Sink 表```jsonCREATE TABLE enriched_orders (order_id INT,order_date BIGINT, -- debezium MySQL 插件会将 DATETIME 转换成 INT64customer_name STRING,price DECIMAL(10, 5),product_id INT,order_status BOOLEAN,product_name STRING,product_description STRING,shipment_id INT,origin STRING,destination STRING,is_arrived BOOLEAN,PRIMARY KEY (order_id) NOT ENFORCED) WITH ('connector' = 'elasticsearch-7','hosts' = 'http://localhost:9200','index' = 'enriched_orders');
关联订单数据
SELECT o.*, p.name, p.description, s.shipment_id, s.origin, s.destination, s.is_arrivedFROM orders AS oLEFT JOIN products AS p ON o.product_id = p.idLEFT JOIN shipments AS s ON o.order_id = s.order_id;
关联订单数据并且将其写入 Elasticsearch 中 ```json
INSERT INTO enriched_orders SELECT o.*, p.name, p.description, s.shipment_id, s.origin, s.destination, s.is_arrived FROM orders AS o LEFT JOIN products AS p ON o.product_id = p.id LEFT JOIN shipments AS s ON o.order_id = s.order_id;
<a name="FlaFo"></a>### 在 Kibana 中看到包含商品和物流信息的订单数据- 访问 [http://localhost:5601/app/kibana#/management/kibana/index_pattern](http://localhost:5601/app/kibana#/management/kibana/index_pattern) 创建 index pattern enriched_orders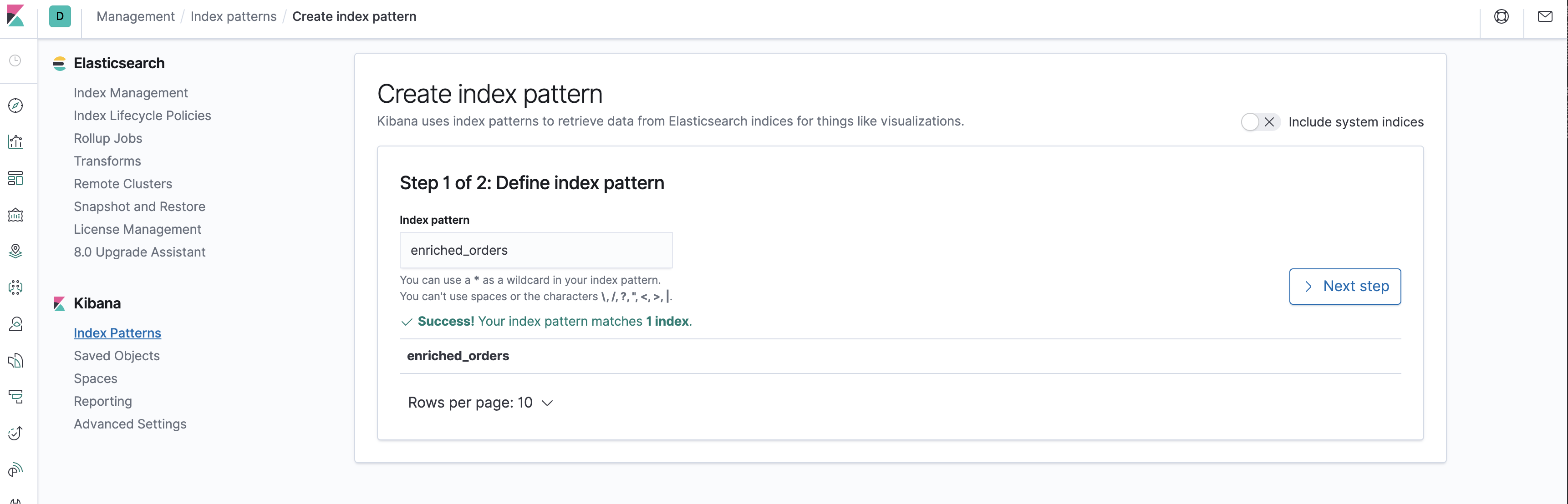- 在 [http://localhost:5601/app/kibana#/discover](http://localhost:5601/app/kibana#/discover) 看到写入的数据了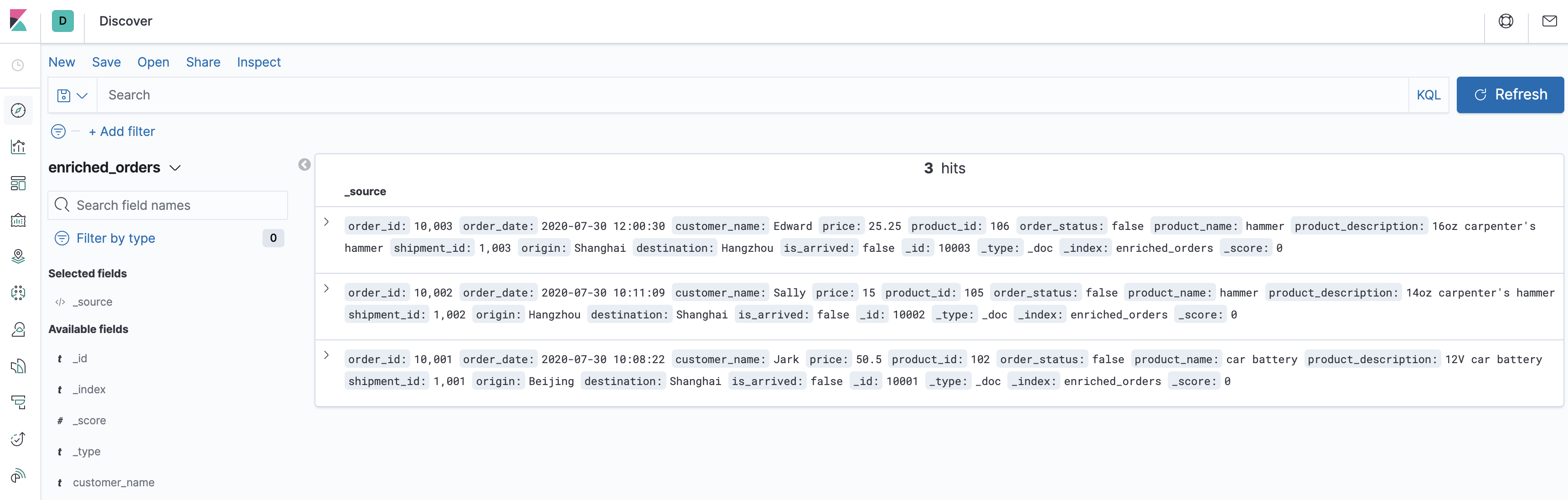<a name="mFc82"></a>### 修改 MySQL 和 Postgres 数据库中表的数据- 在 MySQL 的 orders 表中插入一条数据```json--MySQLINSERT INTO ordersVALUES (default, '2020-07-30 15:22:00', 'Jark', 29.71, 104, false);
在 Postgres 的 shipment 表中插入一条数据
--PGINSERT INTO shipmentsVALUES (default,10004,'Shanghai','Beijing',false);
在 MySQL 的 orders 表中更新订单的状态(未生效)
--MySQLUPDATE orders SET order_status = true WHERE order_id = 10004;
在 Postgres 的 shipment 表中更新物流的状态
--PGUPDATE shipments SET is_arrived = true WHERE shipment_id = 1004;
在 MYSQL 的 orders 表中删除一条数据
--MySQLDELETE FROM orders WHERE order_id = 10004;
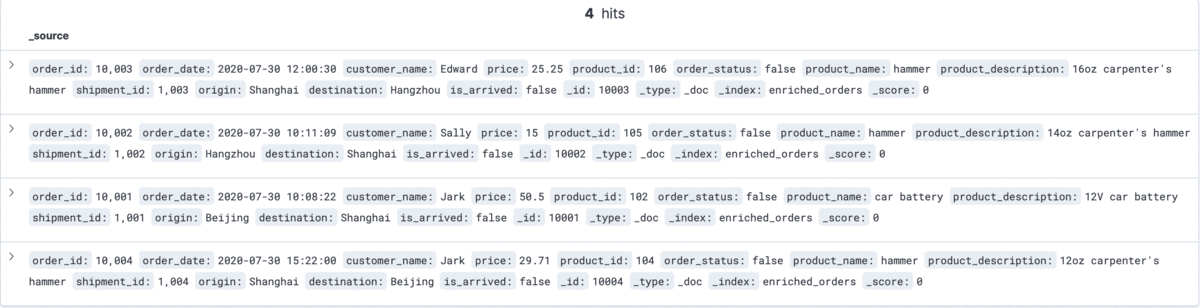
每执行一步就刷新一次 Kibana,可以看到 Kibana 中显示的订单数据将实时更新,如下所示:
关联订单数据并且将其写入 PostgreSQL
使用 postgres 用户登录 PostgreSQL
sudo -u postgres psql
创建 flink 用于同步数据的用户并授权
CREATE USER flink WITH PASSWORD '123456';
使用 flink 用户登录 PostgreSQL
psql -U flink -d mydb -h 127.0.0.1
在 PostgreSQL 目标数据库中创建 enriched_orders 表
CREATE TABLE enriched_orders (order_id INTEGER NOT NULL PRIMARY KEY,order_date BIGINT,customer_name TEXT,price DECIMAL(10, 5),product_id INTEGER,order_status BOOLEAN,product_name TEXT,product_description TEXT,shipment_id INTEGER,origin TEXT,destination TEXT,is_arrived BOOLEAN);
:::info 必须设置主键,这里设置 order_id 为主键 :::
Flink SQL 创建 Sink 表
CREATE TABLE enriched_orders (order_id INT,order_date BIGINT, -- debezium MySQL 插件会将 DATETIME 转换成 INT64customer_name STRING,price DECIMAL(10, 5),product_id INT,order_status BOOLEAN,product_name STRING,product_description STRING,shipment_id INT,origin STRING,destination STRING,is_arrived BOOLEAN,PRIMARY KEY (order_id) NOT ENFORCED) WITH ('connector' = 'jdbc','url' = 'jdbc:postgresql://localhost:5432/mydb', -- 请替换为实际 PostgreSQL 连接参数'table-name' = 'enriched_orders', -- 需要写入的数据表'username' = 'flink', -- 数据库访问的用户名(需要提供 INSERT 权限)'password' = '123456' -- 数据库访问的密码);
关联订单数据并且将其写入 PostgreSQL 中 ```json
INSERT INTO enriched_orders SELECT o.*, p.name, p.description, s.shipment_id, s.origin, s.destination, s.is_arrived FROM orders AS o LEFT JOIN products AS p ON o.product_id = p.id LEFT JOIN shipments AS s ON o.order_id = s.order_id; ```
:::info
备注:
order_date 类型为 BIGINT 而不是 TIMESTAMP(0)
对于 json 格式,debezium MySQL 插件会将 DATETIME 转换成 INT64
所以 Elasticsearch 保存的是 BIGINT 类型,Kibana 看到的应该显示为整数
这里直接使用 Flink CDC 的截图,所以看到的是 TIMESTAMP,你应该看到的是整数
:::
数据类型映射
当前,JSON schema 将会自动从 table schema 之中自动推导得到。不支持显式地定义 JSON schema。
| Flink SQL 类型 | JSON 类型 |
|---|---|
| CHAR / VARCHAR / STRING | string |
| BOOLEAN | boolean |
| BINARY / VARBINARY | string with encoding: base64 |
| DECIMAL | number |
| TINYINT | number |
| SMALLINT | number |
| INT | number |
| BIGINT | number |
| FLOAT | number |
| DOUBLE | number |
| DATE | string with format: date |
| TIME | string with format: time |
| TIMESTAMP | string with format: date-time |
| TIMESTAMP_WITH_LOCAL_TIME_ZONE | string with format: date-time (with UTC time zone) |
| INTERVAL | number |
| ARRAY | array |
| MAP / MULTISET | object |
| ROW | object |

若有收获,就点个赞吧
0 人点赞
