核心配置文件:
<?xml version="1.0" encoding="utf-8"?><!--mybatis配置文件中的约束--><!DOCTYPE configurationPUBLIC "-//mybatis.org//DTD Config 3.0//EN""http://mybatis.org/dtd/mybatis-3-config.dtd"><configuration><!--设置类型的别名--><typeAliases><!--设置某个类型的别名--><!--alias不设置,默认设置别名为类名,切不区分大小写--><!-- <typeAlias type="cn.domian.User" alias="User"></typeAlias>--><!--设置包下的所有类的别名,默认设置别名为类名--><package name="cn.domian"/></typeAliases><plugins><!-- 设置分页插件--><plugin interceptor="com.github.pagehelper.PageInterceptor"></plugin></plugins><!-- 配置多个数据库的环境属性:default多个环境中的其中一个环境的id也就是说我们可以配置多套<environment>环境--><environments default="development"><!--设置具体的环境id:表示连接数据库具体环境的唯一标识,不能重复--><environment id="development"><!--transactionManager 事务管理器:设置事务管理方式type的值有JDBC和MANAGEDJDBC – 这个配置直接使用了 JDBC 的提交和回滚设施,它依赖从数据源获得的连接来管理事务作用域。事务的提交和回滚需要手动处理MANAGED - 被管理,例如:spring--><transactionManager type="JDBC"/><!--dataSourcedataSource 数据源 连接数据库的信息dbcp | c3p0 | druidtype="[UNPOOLED|POOLED|JNDI]"POOLED意思有连接池的连接UNPOOLED意思没有连接池的连接JNDI 使用上下文中的数据源--><dataSource type="POOLED"><!--JDBC 驱动名称--><property name="driver" value="com.mysql.jdbc.Driver"/><!--url数据库的 JDBC URL地址--><property name="url" value="jdbc:mysql:///manhan?useUnicode=yes&characterEncoding=utf-8&rewriteBatchedStatements=true"/><property name="username" value="root"/><property name="password" value="zax"/><!--defaultTransactionIsolationLevel – 默认的连接事务隔离级别。–>--><!--<property name="defaultTransactionIsolationLevel" value=""/>--><!--defaultNetworkTimeout – 等待数据库操作完成的默认网络超时时间(单位:毫秒)–>--><!--<property name="efaultNetworkTimeout" value=""/>--></dataSource></environment></environments><!--引入映射文件--><mappers><!-- 使用相对于类路径的资源引用 --><!-- <mapper resource="mapper/UserMapper.xml"/>--><!-- 使用完全限定资源定位符(URL)不推荐使用<mapper url="E:\JetBrains\mybatis学习\Mybatis-study\Mybatis-03\src\main\java\asia\xiaojiang\mybatis03\dao\UserMapper.xml"/>--><!-- 使用映射器接口实现类的完全限定类名使用注意点:接口和其配置文件必须同名, 必须在同一个包下--><!-- <mapper class="asia.xiaojiang.mybatis03.dao.UserMapper"/>--><!--引入包下所有的映射文件两个要求:1.mapper接口和映射文件所在的包名要一致2.mapper接口和映射文件名字一致--><package name="cn.mapper"/></mappers></configuration>
映射文件:
<?xml version=”1.0” encoding=”utf-8”?>
<!DOCTYPE mapper PUBLIC “-//mybatis.org//DTD Mapper 3.0//EN” “http://mybatis.org/dtd/mybatis-3-mapper.dtd"_>
**
<mapper namespace=”cn.mapper.UserMapper”>
_<insert id=”insertUser”>
insert user values(‘12121’,’2112’);
</insert>
</mapper>
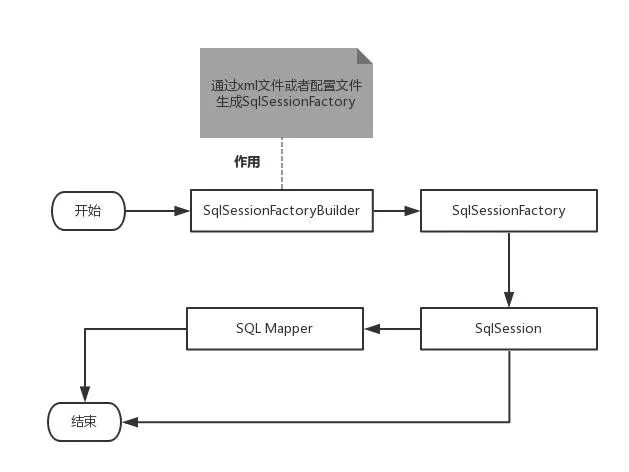
- 加载核心配置文件
- 获取SqlSessionFactoryBuilder对象
- 通过SqlSessionFactoryBuilder对象获取SqlSessionFactory对象
- 再通过SqlSessionFactory对象获取SqlSession
- 通过SqlSession对象代理模式获取Mapper接口对象
- 调用Mapper对象中的方法执行sql语句
- SqlSession.commit方法提交事务
- Mapper接口初始在SQLSessionFactory注册的。
- Mapper接口注册在MapperRegistry类的HashMap中,key是mapper的接口类名,value是创建当前代理工厂。
- Mapper注册之后,可以从过SQLSession来获取get对象。
- SQLSession.getMapper运用了JDK动态代理,产生了目标Mapper接口的代理对象,动态代理的代理类是MapperProxy,实现了增删改查调用。
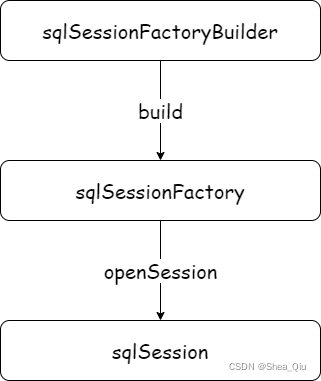
//加载核心配置文件
_InputStream is = Resources._getResourceAsStream(“mybatis-config.xml”);
SqlSessionFactoryBuilder ssfb=new SqlSessionFactoryBuilder();
SqlSessionFactory sqlSessionFactory = ssfb.build(is);
//java程序和数据库之间的会话
//设置是否自动提交事务,默认是不自动提交
_SqlSession sqlSession = sqlSessionFactory.openSession(true);
//通过动态代理获取mapper接口的对象
_UserMapper mapper = sqlSession.getMapper(UserMapper.class);
SqlSessionFactoryBuilder SqlSessionFactory
SqlSessionFactory
SqlSession
生命周期和作用域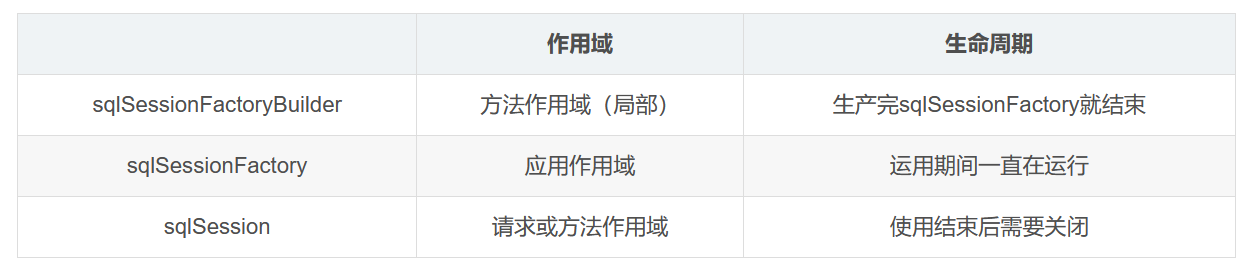
动态sql标签
1.
也叫
sql语句
引用sql语句
2.
根据where其后是否有sql,判断拼接 where,满足条件就拼接,否则不拼接。 可以自动去除多余的and和or
select from animal
and name = #{name}
3.
类似于Java中的switch分支。只进入一个满足when的条件,如果所有when都不满足,则进入otherwise。
select from animal
hobby = #{hobby} and name = #{name}
hobby = #{hobby}
name = #{name}
4.
用于遍历List、Map、Array , 属性如下:
- collection:指定需要遍历的元素
- item:遍历之后的每一项
- separator:定义foreach里面语句的分隔符如“and”“or”“,”
- open:以什么开始如“(”
- close:以什么结尾如 “)”
- index:map中代表key,数组中代表数组下标
5.
prefix: 在trim标签中内容前缀添加指定内容 如“and”“or”
suffix:在trim标签中内容后缀添加指定内容
prefixoverrides:在trim标签中内容前缀删除指定内容
suffixoverrides:在trim标签中内容后缀删除指定内容
缓存机制
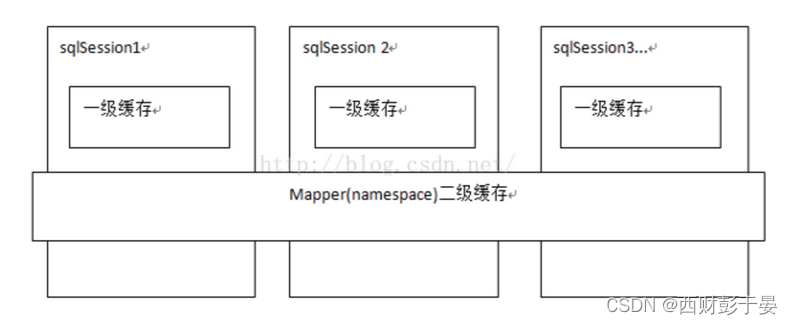
mybatis缓存机制:若连续执行两条相同的SQL语句,可以直接从缓存中获取,如果获取不到,再去数据库中查找。
缓存分为一级缓存、二级缓存、第三方缓存
(1)一级缓存:表示将数据存在SQLSession中,每次查询的时候都会开启一个会话,关闭后数据失效,默认是开启状态。
(2)二级缓存:全局范围的缓存,在SqlSession关闭后才会生效
(3)第三方缓存:继承第三方插件,来充当缓存的作用
一级缓存:
- 一级缓存是SQLSession级别缓存,在操作数据库时都需要构造SQLSession对象,在对象中有一个数据结构(HashMap)用于存储缓存数据,不同的SQLSession之间的缓存数据区域是互不影响的。
- 一级缓存的作用于是在同一个SQLSession,在同一个SQLSession中执行相同的两次SQL,第一次执行完毕在后会将数据写到缓存中,第二次从缓存中进行后去就不在数据库中查询,从而提高了效率,
- 当一个SQLSession结束后该SQLSession中的一级缓存也就不存在了,mybatis默认开启一级缓存。
二级缓存:
- 二级缓存是mapper级别缓存,多个SQLSession去操作同一个mapper的SQL语句,多个SQLSession操作都会存在二级缓存中,多个SQLSession共用二级缓存,二级缓存是跨SQLSession的。
- 二级缓存是多个SQLSession共享的,作用域是mapper下的同一个namespace。不同的SQLSession两次执行相同的namespace下的SQL最终能获取相同的SQL语句结果。
缓存顺序:
(1)一级缓存和二级缓存是不会同时存在的,因为二级缓存是在sqlSession关闭后生效的,如果一级缓存存在,那么意味着sqlSession还未关闭(一级缓存是在sqlSession关闭后失效),若二级缓存存在,意味着sqlSession已关闭,且不管一级、二级缓存存在哪个,在接下来的查询是从缓存中拿取数据,那侧面也可体现出一二级缓存不会同时存在
(2)先查二级缓存再查一级缓存最后查数据库
二级缓存
Mybatis逆向工程:
导入依赖
<plugin>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-maven-plugin</artifactId>
<version>1.3.2</version>
<dependencies>
<dependency>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-core</artifactId>
<version>1.3.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.3</version>
</dependency>
</dependencies>
<configuration>
<verbose>true</verbose>
<overwrite>false</overwrite>
<configurationFile>src/main/resources/generatorConfig.xml</configurationFile>
</configuration>
</plugin>
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE generatorConfigurationPUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN""http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd"><generatorConfiguration><!--targetRuntime :执行生成的逆向工程版本MyBatis3Simple:生成基本的CRUD(清新简洁版)只有增 删 改 查所有、查单条五个条件MyBatis3:生成带条件的CRUD(奢华尊享版)会生成xxxExample类--><context id="testTables" targetRuntime="MyBatis3"><!--数据库连接的信息:驱动类、连接地址、用户名、密码 --><jdbcConnection driverClass="com.mysql.jdbc.Driver"connectionURL="jdbc:mysql:///k2502?useUnicode=yes&characterEncoding=utf-8&rewriteBatchedStatements=true"userId="root"password="zax"></jdbcConnection><!--javaBean生成策略--><javaModelGenerator targetPackage="com.kgc.domain" targetProject=".\src\main\java"><!-- enableSubPackages:是否使用子包 --><property name="enableSubPackages" value="true"/><!-- 解析数据库中的表反向生成的实体类,映射文件数据库表字段名转换成实体类属性trimStrings:去除掉字段名前后的空格--><property name="trimStrings" value="true"/></javaModelGenerator><!-- 映射文件生成策略--><sqlMapGenerator targetPackage="com.kgc.dao" targetProject=".\src\main\java"><property name="enableSubPackages" value="true"/></sqlMapGenerator><!-- mapper接口生成策略 --><javaClientGenerator type="XMLMAPPER" targetPackage="com.kgc.dao"targetProject=".\src\main\java"><property name="enableSubPackages" value="true"/></javaClientGenerator><!-- 指定逆向分析的表--><!-- tableName为*时,可对应数据库下所有的表,此时不用写domainObjectName--><!-- domainObjectName指定生成出来的实体类的类名--><table tableName="grade" domainObjectName="Grade"/><table tableName="student" domainObjectName="Student" /><!-- enableCountByExample="false"--><!-- enableUpdateByExample="false"--><!-- enableDeleteByExample="false"--><!-- enableSelectByExample="false"--><!-- selectByExampleQueryId="false"--></context></generatorConfiguration>
逆向工程自动生成的Example类
属性:
orderByClause:用于指定ORDER BY条件,这个条件没有构造方法,直接通过传递字符串值指定。
distinct: 是用来指定是否要去重查询的,true为去重,false不去重。
oredCriteria:是用来指定查询条件的。
方法:
example.setOrderByClause(“字段名 ASC”); 添加升序排列条件,DESC为降序
example.setDistinct(false) 去除重复,boolean型,true为选择不重复的记录。


XXXExample example=new XXXExample();
用Example类对象调用createCriteria()方法获取一个Criteria对象
XXXExample.Criteria criteria = example.createCriteria();
- criteria.andXxxIsNull 添加字段xxx为null的条件
- criteria.andXxxIsNotNull 添加字段xxx不为null的条件
- criteria.andXxxEqualTo(value) 添加xxx字段等于value条件
- criteria.andXxxNotEqualTo(value) 添加xxx字段不等于value条件
- criteria.andXxxGreaterThan(value) 添加xxx字段大于value条件
- criteria.andXxxGreaterThanOrEqualTo(value) 添加xxx字段大于等于value条件
- criteria.andXxxLessThan(value) 添加xxx字段小于value条件
- criteria.andXxxLessThanOrEqualTo(value) 添加xxx字段小于等于value条件
- criteria.andXxxIn(List<?>) 添加xxx字段值在List<?>条件
用于批量删除、批量添加
- criteria.andXxxNotIn(List<?>) 添加xxx字段值不在List<?>条件
- criteria.andXxxLike(“%”+value+”%”) 添加xxx字段值为value的模糊查询条件
- criteria.andXxxNotLike(“%”+value+”%”) 添加xxx字段值不为value的模糊查询条件
- criteria.andXxxBetween(value1,value2) 添加xxx字段值在value1和value2之间条件
- criteria.andXxxNotBetween(value1,value2) 添加xxx字段值不在value1和value2之间条件
1.对应的 XXXExample.java 中添加两个属性,以及对于的 getter 和 setter 方法
//开始查询的位置protected int startRow;//每页显示的行数protected int pageSize;public int getStartRow() {return startRow;}public void setStartRow(int startRow) {this.startRow = startRow;}public int getPageSize() {return pageSize;}public void setPageSize(int pageSize) {this.pageSize = pageSize;}
2.对应的xxxMapper.xml文件, id为selectByExample 的语句前加上
<if test="startRow != null and pageSize != null and pageSize != 0">limit #{startRow},#{pageSize}</if>

逆向工程多表级联查询:
1.先创建一个类继承员工实体类
2.多对一映射关系,属性为部门实体类对象
如果一对多映射关系,属性为员工实体集合
3.在对应的员工mapper接口中添加一个新的方法用于多表联查
4.在对应的sql映射文件中添加sql语句
中间内容的sql直接复制id为selectByExample 的
分页插件分页:
1.导入依赖
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.2.0</version>
</dependency>
2.在mybatis核心配置文件中配置插件
<plugins>
<plugin interceptor=”com.github.pagehelper.PageInterceptor”></plugin>
</plugins>
3.查询步骤之前开启分页
PageHelper.startPage(当前页码,每页显示数据的行数)
_// 把条件对象作为参数传入
_List
4.分页之后获取分页相关的数据
PageInfo
映射文件转义符
< <> ><> <>& &' '" "

若有收获,就点个赞吧
0 人点赞
