一、复习
1、什么是MapReduce?—分布式计算的一个技术
计算跟着数据走。
2、Hadoop
HDFS—> 存储大量数据的,将我们的多台电脑,合并为一个大的集群环境。将一个大文件切割为很多小问题。跟数据放在Linux的硬盘上有什么区别?
Yarn —> 进行分布式计算运行的一个操作系统。
ResourceManager、NodeManager、Conteror、AppMaster
3、要知道的是开发流程。
运行的逻辑—MapTask 、ReduceTask、Map方法、Reduce方法
4、Shuffler 过程 — 重点
二、Hive理论
今天的一个理解的重点-- Hive就是我们的hdfs格式化文件的一个映射。可以通过sql语句,运行MapReduce任务。<br />Hive是一个基于Hadoop的数据仓库工具,可以将结构化的数据文件映射成一张数据表,并可以使用类似SQL的方式来对数据文件进行读写以及管理。这套Hive SQL 简称HQL。Hive的执行引擎可以是MR、Spark、Tez。<br /> 比如:我们昨天流量统计,可以将结构化的数据导入到Hive中,然后通过编写HQL语句的形式,统计每一个手机号的上行流量下行流量,总流量的大小。<br />select sum(up),sum(down),(sum(up)+sum(down)) from phone_flow group by phoneNum;<br />出现的背景: 会编写MapReduce的人很少,但是会写SQL语句的人很多,可以通过hive技术,将会编写SQL语句的工程师纳入到数据统计的阵营中。<br />关于元数据:<br /> 通过命令将结构化的数据导入到hive中,实际上数据是存储在Hdfs上的,Hive类似于一个数据库,Hive中创建的数据库,表,字段等信息是需要一个地方存储的,这些信息称之为元数据。<br /> Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括(表名、表所属的数据库名、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等) <br />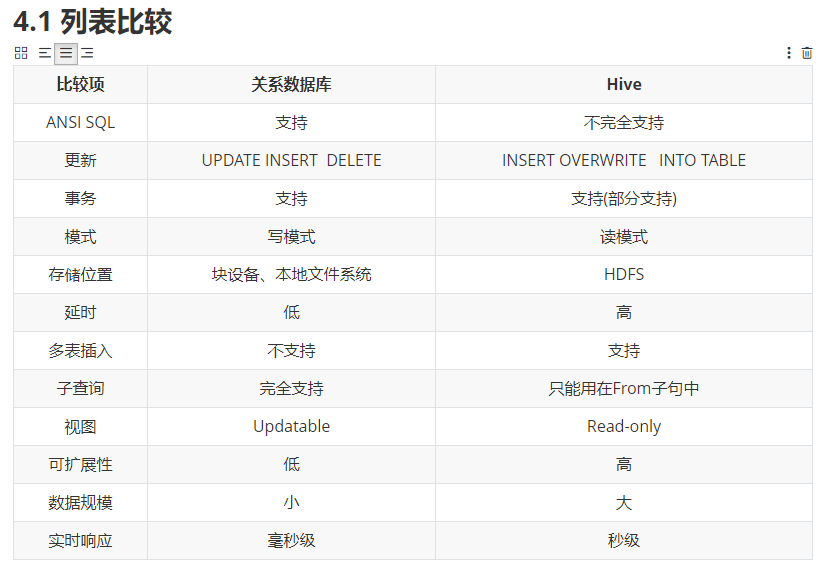<br />Hive的存储是基于HDFS的,hive的计算是基于MapReduce。
三、Hive的安装
1、上传安装包
2、解压 tar -xvf apache-hive-2.1.1-bin.tar.gz -C /usr/local
3、进入到/usr/local 进行重命名 mv apache-hive-2.1.1-bin hive
4、配置环境变量 /etc/profile
由于已经编写了path路径,可以进行一次合并
export JAVA_HOME=/usr/local/jdkexport HADOOP_HOME=/usr/local/hadoopexport HIVE_HOME=/usr/local/hiveexport PATH=$PATH:$HIVE_HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5、刷新一下环境变量 source /etc/profile
6、复制一个hive-env.sh 出来
进入到 /usr/local/hive/conf
cp hive-env.sh.template hive-env.sh
7、修改hive-env.sh 的可执行权限 chmod u+x hive-env.sh
8、修改hive-env.sh里面的数据
export JAVA_HOME=/usr/local/jdkexport HIVE_CONF_DIR=/usr/local/hive/confexport HIVE_AUX_JARS_PATH=/usr/local/hive/libexport HADOOP_HOME=/usr/local/hadoop
9、拷贝一个配置文件
cp hive-default.xml.template hive-site.xml
10、在hdfs上创建目录
根据hive-site.xml 中的配置:
创建目录 之前,一定要确保你的hdfs是启动的,否则肯定失败。
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -mkdir -p /tmp/hive
hdfs dfs -chmod 777 /user/hive/warehouse
hdfs dfs -chmod 777 /tmp/hive
11、在本地创建临时文件夹
mkdir iotmp chmod 777 iotmp
12、修改hive-site.xml 中的东西

把hive-site.xml 中所有包含 ${system:Java.io.tmpdir}替换成/usr/local/hive/iotmp.
如果系统默认没有指定系统用户名,那么要把配置${system:user.name}替换成当前用户名root
13、重新启动hadoop集群 start-all.sh stop-all.sh
14、进入到/usr/local/hive 文件夹下,进行hive的初始化:
schematool -initSchema -dbType derby
15、进入 bin/hive 直接进入hive
二、本地模式
嵌入式模式,缺点是每一次只能有一个用户在使用,其他用户无法使用。单Session的形式。
本地模式是支持多人会话的,多Session形式。
要想使用本地化模式,必须安装有关系型数据库,我们选择使用mysql.
1、MySQL的安装
1) rpm -qa|grep mariadb
rpm -e mariadb-libs-5.5.64-1.el7.x86_64 —nodeps
2)、将mysql 的安装包上传至 /root/software 下
tar -xvf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
3)、安装
tar -xvf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
yum install -y net-tools
yum install -y perl
rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm
4) 修改默认密码
grep password /var/log/mysqld.log 查找默认密码是哪个
启动mysql 服务: systemctl start mysqld
启动之后,可以通过查看状态 systemctl status mysqld
如果启动,就可以拿着默认密码登录 mysql -uroot -p 回车,粘贴密码即可。
修改密码之前,先把mysql 关于密码的设置降低一下要求,否则设置不成功的。
# 1. 修改MySQL的密码策略(安全等级)# MySQL默认的密码安全等级有点高,在设置密码的时候,必须同时包含大小写字母、数字、特殊字符,以及对位数有要求show variables like '%validate_password%'; # 查看密码策略set global validate_password_policy=LOW; # 修改密码策略等级为LOWset global validate_password_length=4; # 密码的最小长度set global validate_password_mixed_case_count=0; # 设置密码中至少要包含0个大写字母和小写字母set global validate_password_number_count=0; # 设置密码中至少要包含0个数字set global validate_password_special_char_count=0; # 设置密码中至少要包含0个特殊字符
进行密码的设置以及允许别的电脑进行远程连接
# 2. 修改密码alter user root@localhost identified by '123456';# 3. 远程授权grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option;
退出mysql客户端,再次通过新的密码进入:mysql -uroot -p123456
6) 找到/usr/local/hive/conf 下的hive-site.xml
修改如下内容:
<!--配置mysql的连接字符串--><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value><description>JDBC connect string for a JDBC metastore</description></property><!--配置mysql的连接驱动--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value><description>Driver class name for a JDBC metastore</description></property><!--配置登录mysql的用户--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value><description>username to use against metastore database</description></property><!--配置登录mysql的密码--><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value><description>password to use against metastore database</description></property>
7) 就是复制一个驱动包到 hive家目录的 /lib 下
cp /root/software/mysql-connector-java-5.1.28-bin.jar /usr/local/hive/lib/
8) 删除关于derby的相关联的初始化文件
rm -rf metastore_db/
rm -rf derby.log
9) 初始化 hive
bin/schematool -initSchema -dbType mysql
10) 进入查看 bin/hive
区别是: 使用嵌入式模式(Derby模式) 每次只能有一个用户使用,另一个窗口是无法使用的
本地模式: 开启多个窗口,每一个窗口都可以使用hive进行操作。 元数据存储在mysql数据库中。
四、远程模式
将hive做为一个后台服务启动,然后前端可以通过各种方式去连接我的hive,类似于数据库。
和本地模式差不多,只是将元数据放在别的服务器上,这种的就是咱们常说的集群模式。
可以有一个hive的server和多个hive的client。
bigdata01上:
1) scp -r hive bigdata02:/usr/local 将本地的hive拷贝到bigdata02上
2) scp /etc/profile bigdata02:/etc/ 将环境变量拷贝到bigdata02上
在bigdata02上:
1)刷新环境变量 source /etc/profile
cp hive-site.xml hive-site.xml.bak 备份一份
在bigdata01上:
后台启动 hiveserver2 服务:
hive —service hiveserver2 &
bigdata02上进行远程连接:
beeline 回车
在beeline的服务中:!connect jdbc:hive2://bigdata01:10000
输入bigdata01 的账号和密码: root root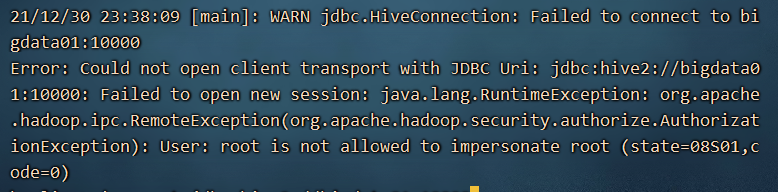
通过以上的异常觉察到是用户权限的问题:hadoop 中的core-site.xml中添加:
<!-- 当前用户全设置成root -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 不开启权限检查 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
复制core-site.xml 文件都bigdata02,bigdata03中。
xsync.sh /usr/local/hadoop/etc/hadoop/core-site.xml
重新启动整个集群环境。 stop-all.sh start-all.sh
需要杀死RunJar程序 kill -9 123213 杀死某个进程
bigdata01 重新启动服务:
hive —service hiveserver2 &
bigdata02 继续通过beeline 进行连接即可: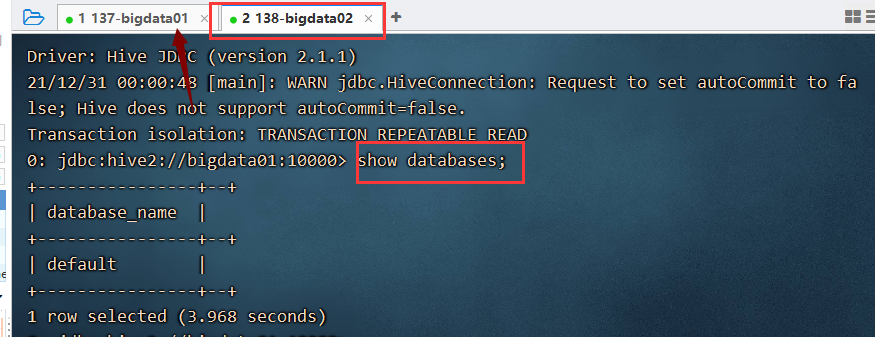
以上只是远程连接的一种方式,还有一种metastore的形式。
在bigdata01中不使用 hive —service hiveserver2 &
而是采用 hive —service metastore &
通过bigdata02进行连接:
需要修改bigdata02中的 hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://bigdata01:9083</value>
</property>
</configuration>
在bigdata02中直接输入 hive 即可。
如果不修改hive-site.xml ,就属于本地连接。
远程连接看着是两种形式 hiveserver2 和 metastore 实际上只有一个metastore,因为hiveserver2 服务是对metastore的一种封装形式,一般我们会选择使用 hiveserver2的形式。
五、通过其他软件进行远程访问
务必在连接之前,启动我们的后台服务 bin/hiveserver2 服务。
1、通过IDEA进行远程连接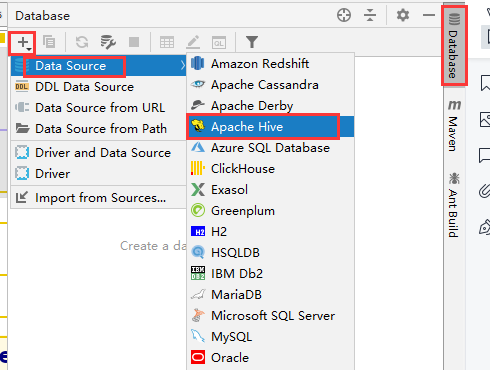
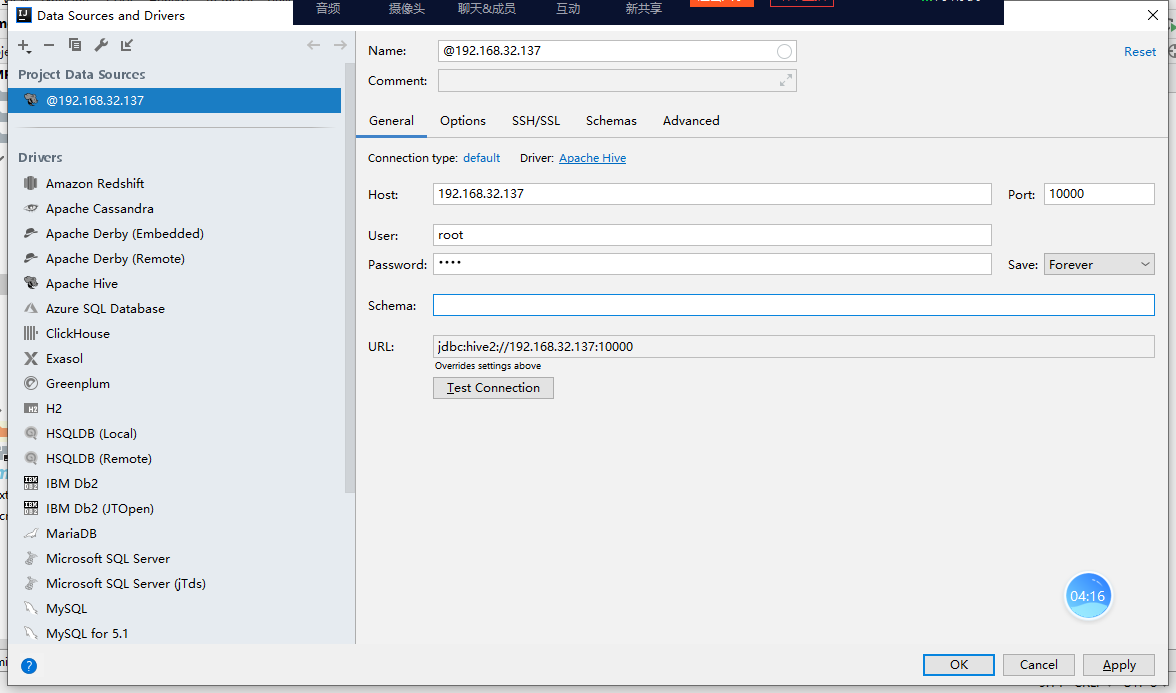
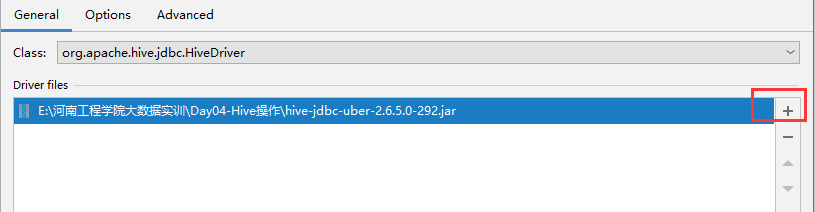

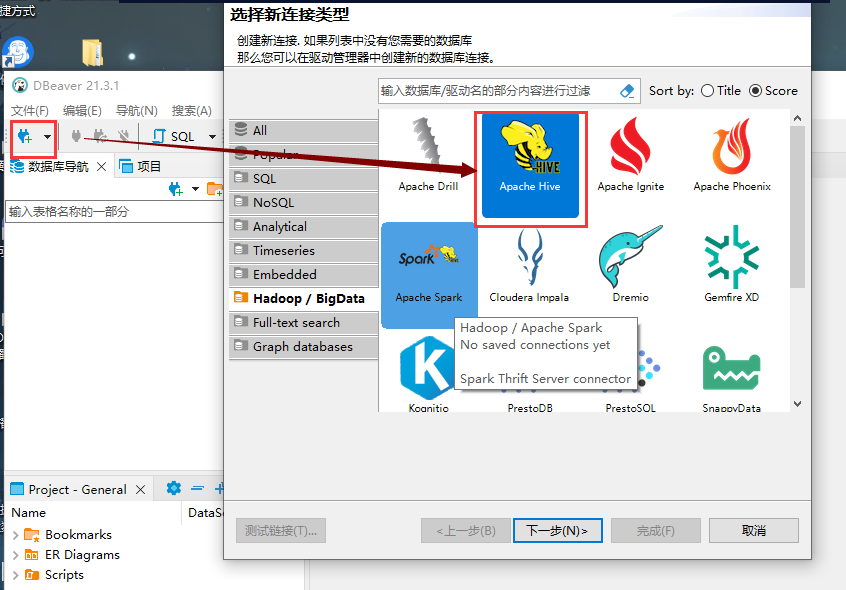


六、Hive的使用
1、创建数据库
create database zoo;
create database if not exists zoo;
create database if not exists qfdb comment ‘这是我的第一个hive数据库’;
2、创建表
use qfdb;
CREATE table t_user(id int,name string);
通过以上的语句我们知道,hive中的HQL ,跟我们的SQL基本一致。
关于hive中的字段:
常用的: int string varchar
1.Hive-0.12.0版本引入了VARCHAR类型,VARCHAR类型使用长度指示器(1到65355)创建,长度指示器定义了在字符串中允许的最大字符数量。如果一个字符串值转换为或者被赋予一个varchar值,其长度超过了长度指示器则该字符串值会自动被截断。
2.STRING存储变长的文本,对长度没有限制。理论上将STRING可以存储的大小为2GB,但是存储特别大的对象时效率可能受到影响,可以考虑使用Sqoop提供的大对象支持。
3、搞一个小技巧
可以通过该 HQL 语句查找当前正在使用哪个数据库:select CURRENT_DATABASE();
不太方便,最好是我操作哪个数据库,直接就能看到最好。
hive中查询当前的数据库 select current_database();
可以在/usr/local/hive/conf目录下,创建 .hiverc 文件,添加
set hive.cli.print.current.db=true;
这样每次进入hive之后会出现每次操作的数据库的名字。非常的方便。
以上方式适用于本地模式。
4、创建表的常用方式
分析:hive是对结构化的文件进行映射的,也就是说先有数据,后建表,将数据导入到hive的表中。
比如: user.csv
1,zhangsan
2,lisi
3,wangwu
4,zhaoliu
如何建表:
create table qfuser(
id int ,
name string
)
row format delimited
fields terminated by ','
lines terminated by '\n';
练习关于表的HQL:
show tables;
show tables in qfdb;
desc qfuser;
desc formatted qfuser;
show create table qfuser;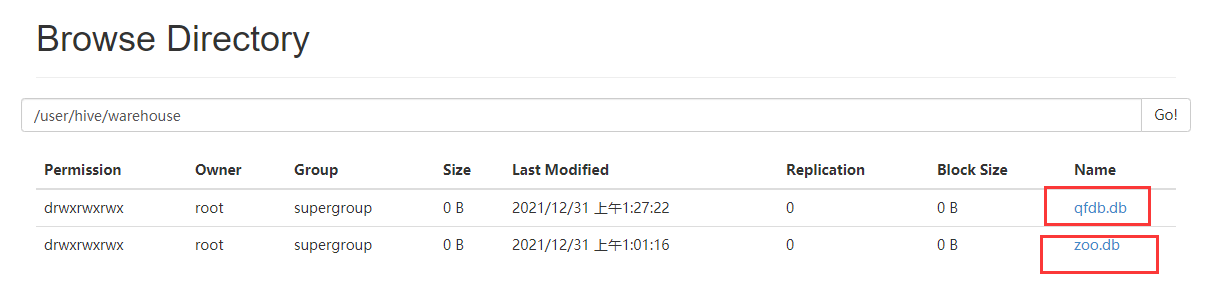
通过我们查看hdfs上的文件,我们知道所谓的创建数据库就是在/user/hive/warehouse 中创建文件夹而已。创建表就是创建数据库下的文件夹。default 数据库对应的文件夹是 /user/hive/warehouse
演示:将本地数据导入到hive中
1、在linux中创建一个文件,里面放入一些数据
mkdir /hivedata
vi user.csv
2、启动本地化的hive 直接关闭RunJar 进程,直接 hive
3、在hive 中执行 load data local inpath ‘/hivedata/user.csv’ into table qfdb.qfuser;
4、查询结果数据: select from user;
5、如果再次执行导入操作
load data local inpath ‘/hivedata/user.csv’ into table qfdb.qfuser;
查看数据,数据又增加一倍,说明是追加,如果想覆盖之前的数据需要加入overwrite
load data local inpath ‘/hivedata/user.csv’ overwrite into table qfdb.qfuser;
会将之前的数据全部覆盖,只留当前最新的数据:
演示:*将hdfs上的数据导入到hive中
1、创建本地数据
2、将数据推送到hdfs平台上 hdfs dfs -put /hivedata/user2.csv /
3、将数据导入到hive中 load data inpath ‘/user2.csv’ into table qfdb.qfuser;
4、观察 hdfs上原本的数据不见了,本移动到了hive数据仓库文件夹下。
本地上传hive相当于是复制数据,从hdfs上导入hive相当于是剪切。
hive中元数据存储在mysql上。
七、案例实战
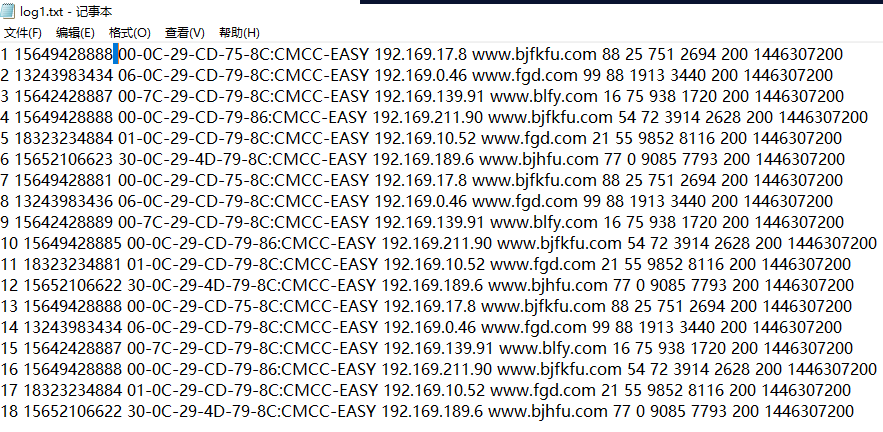
求:每一个手机号的总流量是多少?
求:访问量最大的三个网址是什么?
1、创建表
create table log1(
id int,
phoneNumber string,
mac string,
ip string,
url string,
status1 string,
status2 string,
upflow int,
downflow int,
status3 string,
dt string
)
row format delimited
fields terminated by ' '
lines terminated by '\n';
2、上传数据到linux本地
3、将本地数据导入到hive中
load data local inpath ‘/hivedata/log1.txt’ into table qfdb.log1;
4、编写SQL
select phoneNumber,round(sum(upflow+downflow)/1024.0,2) as total from log1 group by phoneNumber;
SQL语句会变为mapreduce 任务,非常的慢,不便于本地开发,将运行模式修改为本地模式:
5、修改本地模式
在/usr/local/hive/conf 文件夹下,创 .hiverc
复制如下内容:
set hive.exec.mode.local.auto=true;
set hive.exec.mode.local.auto.inputbytes.max=134217728;
set hive.exec.mode.local.auto.input.files.max=4;
set hive.cli.print.current.db=true;
需要重新启动hive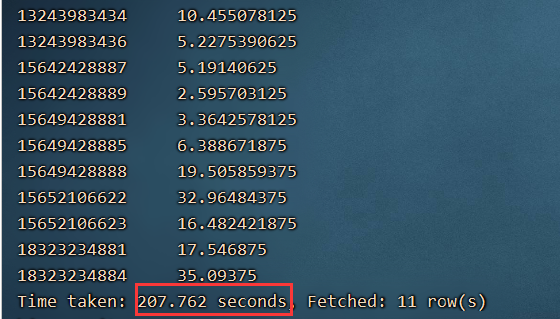
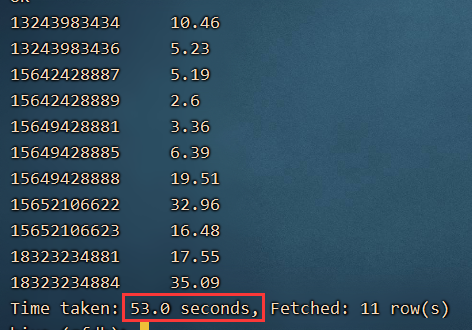
6、需求:求排名前三的网址地址是什么?
select url,count(url) as urlcount from log1 group by url order by urlcount desc limit 3;
结果截图: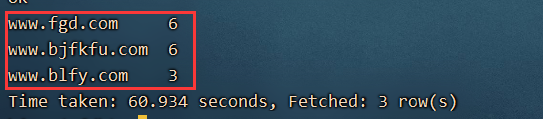

若有收获,就点个赞吧
0 人点赞
