一、通过一个案例进行复习
需求:看数据
7369,SMITH,CLERK,7902,1980-12-17,800,null,207499,ALLEN,SALESMAN,7698,1981-02-20,1600,300,307521,WARD,SALESMAN,7698,1981-02-22,1250,500,307566,JONES,MANAGER,7839,1981-04-02,2975,null,207654,MARTIN,SALESMAN,7698,1981-09-28,1250,1400,307698,BLAKE,MANAGER,7839,1981-05-01,2850,null,307782,CLARK,MANAGER,7839,1981-06-09,2450,null,107788,SCOTT,ANALYST,7566,1987-04-19,3000,null,207839,KING,PRESIDENT,null,1981-11-17,5000,null,107844,TURNER,SALESMAN,7698,1981-09-08,1500,0,307876,ADAMS,CLERK,7788,1987-05-23,1100,null,207900,JAMES,CLERK,7698,1981-12-03,950,null,307902,FORD,ANALYST,7566,1981-12-02,3000,null,207934,MILLER,CLERK,7782,1982-01-23,1300,null,103423,laoyan,MANAGER,8899,2022-01-01,50000,100000,40
分析: emono,name,job,mgr,fire_date,salary,comm,deptno
求:哪些员工有上级领导。
实操:
前提是:已经启动了hdfs, yarn , hive
1、上传数据到本地
2、根据我们的日志文件,创建hive表
use qfdb; 切换数据库
create table if not exists emp(empno int,ename string,job string,mgr int,hiredate string,sal int,comm int,deptno int)row format delimitedfields terminated by ',';
show tables; // 查看数据库
如果出现了以下问题: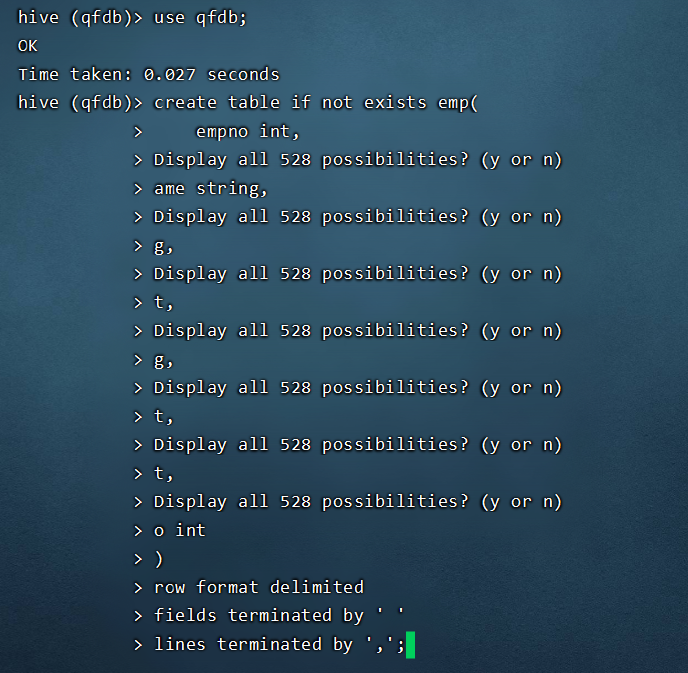
把SQL语句每一行的空格去掉。
3、导入本地数据到hive
load data local inpath ‘/hivedata/emp.txt’ into table qfdb.emp;
select from emp; // 查看数据无问题
4、编写HQL语句,完成需求
第一个SQL,是不准确的。
select from emp where mgr is not null;
为什么不准确呢?
3423,laoyan,MANAGER,8899,2022-01-01,50000,100000,40
laoyan 上级领导的编号,压根就没有这个人,所以laoyan 也是没有领导。
添加如上所述的数据:
insert into emp values(7980,’laoyan’,’CLERK’,8899,’2022-01-01’,50000,100000,40);
第二个SQL语句:
select p1. from emp p1 join emp p2 on p1.mgr=p2.empno;
第三个SQL语句: 是对上面的SQL语句的优化—使用exists
select from emp p1 where exists(select 1 from emp p2 where p1.mgr=p2.empno);
面试MySQL常见的面试题:
1) SQL优化方案
2) mySQL数据是基于磁盘的,理论讲每次查询都会有IO,IO比较的慢,但是我们查询的时候速度是很快的,为什么? 答案—缓冲池
3)MySQL的优化中有一个索引,索引的数据结构是什么? HASH以及B-TREE/B+TREE
问:为什么要选择使用B-TREE,而不用二叉树\红黑树
昨天的内容:
Hive —> Hive是对结构化的数据的一种表的映射关系,可以通过HQL语句,执行底层的MapReduce任务,从而降低了我们数据处理的难度。
二、内部表与外部表的关系
区别:
desc formatted emp; 查看一个表是内部表还是外部表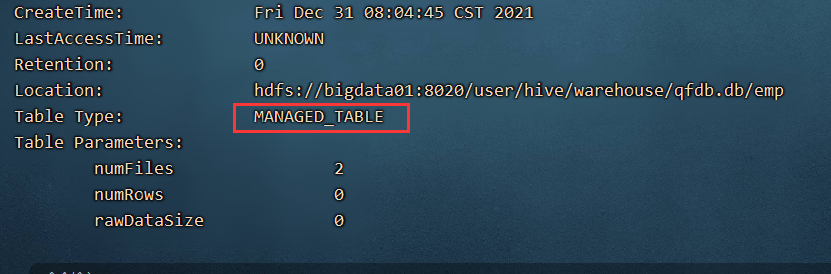
1、创建时的SQL语句不同:
create table emp(id int,name string); // MANAGER_TABLE
create EXTERNAL table out_table(id int,name string); // EXTERNAL_TABLE
2、删除内部表和外部表的时候,数据不一样
删除内部表— 删除mysql中的元数据,hdfs上的文件夹以及文件都会被删除
删除外部表 — 只删除mysql中的元数据,不会删除hdfs上的文件
drop table t_user;
drop table out_table;
如何查看数据库中的元数据呢?
数据库的元数据:
表的元数据:
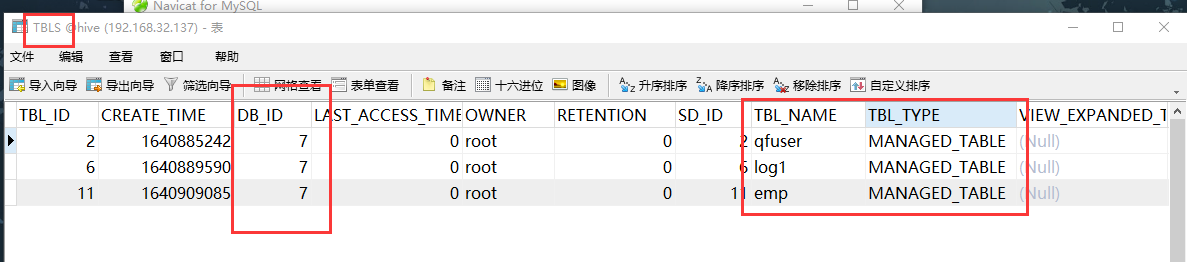
3、位置不同
内部表:数据存储在hdfs上的/user/hive/warehouse 下
外部表:创建表的时候可以使用location 指定 hdfs的任意位置,如果创建表的时候不指定,也会存放在/user/hive/warehouse 下。
使用场景: 一般在企业中外部表使用的频率是最高的。外部表的数据因为是不删除的,刚好符合我们hdfs存储的场景。
三、关于表的使用的几个技巧
1、通过insert into 将查询出来的数据导入到一个新的表中。
create table if not exists emp_new(empno int,ename string,job string,mgr int,hiredate string,sal int,comm int,deptno int)row format delimitedfields terminated by ',';insert into emp_new select * from emp ;
2、克隆表结构,不带数据
create table if not exists emp2 like emp;
可以通过desc emp2 查看表中的字段。
3、克隆表,并且带数据
create table if not exists t5 like emp location ‘/user/hive/warehouse/qfdb.db/emp’;
另一种比较简单的形式:
create table t6 as select from emp;
4、内部表和外部表的一个转换
alter table a1 set tblproperties(‘EXTERNAL’=’TRUE’); ###内部表转外部表,true一定要大写;
alter table a1 set tblproperties(‘EXTERNAL’=’false’);##false大小写都没有关系
5、可以通过set 查看所有hive的参数
6、有时候我们在linux中,就想临时的操作一下hive,没必要进入hive,再退出,可以在linux操作系统中:
hive -e “select from qfdb.emp”
7、可以导入sql语句
在linux操作系统中,如果有一个xxx.sql 语句,可以通过 hive -f /root/laoyan.sql 执行该sql语句。
8、在hive中可以执行linux命令以及hdfs命令
在hive中可以操作部分linux命令 以!开始 ; 结束
!ls /usr/local/;
在hive 中可以进行hdfs的操作,而且比linux操作hdfs要快很多。
dfs -mkdir laoyan;
dfs -ls /;
四、讲解基本数据类型
1、制造一个数据文件 /hivedata/base.txt
233,12,342523,455345345,30000,600005,nihao,helloworld2,2017-06-02
12,13,342526,455345346,80000,100000,true,helloworld1,2017-06-02 11:41:30
2、创建表
create table if not exists bs1(
id1 tinyint,
id2 smallint,
id3 int,
id4 bigint,
sla float,
sla1 double,
isok boolean,
content binary,
dt timestamp
)
row format delimited fields terminated by ',';
3、将数据导入到hive
load data local inpath ‘/hivedata/base.txt’ into table bs1;
4、查看数据 select * from bs1;
分析问题: 233 对应的数据类型是 tinyint == byte (-128~127) 数据大于我的边界,所以出现NULL
nihao 对应的数据类型是 boolean 类型,类型不匹配,所以是NULL
binary 是二进制文件,所以无法使用文本来展示,所以看着像乱码。
timestamp : 要求数据是 时间戳,需要带时分秒的,而对应的数据没有,所以null.
综上所述: hive导入数据的时候,如果类型不匹配或者数据超过了边界值,不会报错,只会将不匹配的数据展示为NULL。
基本数据类型: 常用的就是 int ,string 即可。
五、复杂数据类型
1、array 数组类型
zhangsan 78,89,92,96
lisi 67,75,83,94
wangwu 89,96
创建表:
create table if not exists arr1(
name string,
scores array<int>
)
row format delimited
fields terminated by '\t'
collection items terminated by ',';
导入数据:
load data local inpath ‘/hivedata/arr1.txt’ into table arr1;
————————————
1)查询每一个人的第一个成绩是多少?
select name,scores[0] from arr1;
2) 查询每一个人的成绩的数量
select name,size(scores) from arr1;
3)查询每一个人的总成绩
select name,scores[0]+scores[1]+scores[2]+scores[3] from arr1;
缺点:wangwu 的成绩为null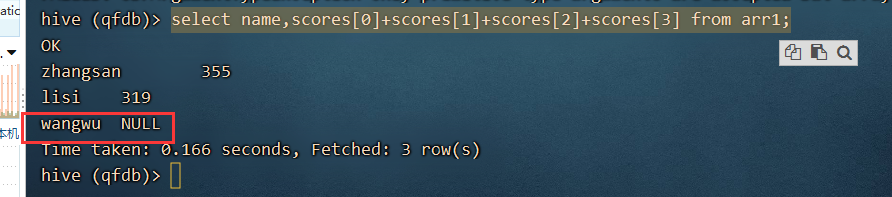
select name,scores[0]+scores[1]+nvl(scores[2],0)+nvl(scores[3],0) from arr1;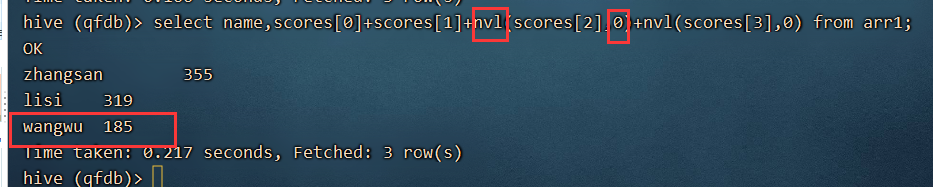
缺点是:如果成绩非常的多,这样不断的相加不是办法。
通过explode 函数,将列转为行。
select explode(scores) from arr1;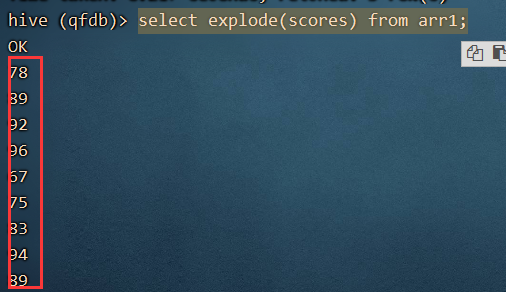
select name ,cj from arr1 lateral view explode(scores) scoretable as cj;
每一个人的总成绩就是,根据name进行分组,然后将成绩进行汇总
select name ,sum(cj) from arr1 lateral view explode(scores) scoretable as cj group by name;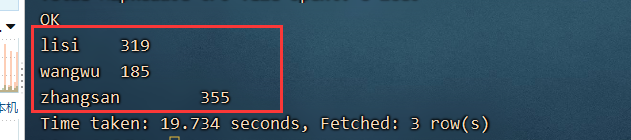
另一个题目:
原生数据:
zhangsan 78
zhangsan 89
zhangsan 92
zhangsan 96
lisi 67
lisi 75
lisi 83
lisi 94
wangwu 89
wangwu 96
将其转换为:
zhangsan 78,89,92,96
lisi 67,75,83,94
wangwu 89,96
怎么办?行转为列
1)创建新的表,将原数据导入到表中,使用了克隆表的技术
create table arr2 as (查找的结果)
create table arr2 as select name ,cj from arr1 lateral view explode(scores) scoretable as cj ;
2) 通过collect_set() / collect_list() 函数,将其合并在一起
select name,collect_list(cj) from arr2 group by name;
2、map类型
原始数据:
zhangsan chinese:90,math:87,english:63,nature:76
lisi chinese:60,math:30,english:78,nature:0
wangwu chinese:89,math:25,english:81,nature:9
创建表:
create table if not exists map1(
name string,
scores map<string,int>
)
row format delimited
fields terminated by ' '
collection items terminated by ','
map keys terminated by ':';
将数据导入到hive中:
load data local inpath ‘/hivedata/map1.txt’ into table map1;
查看结果:
1) 查询每一个人的语文和英语成绩
select name,scores[‘chinese’],scores[‘english’] from map1;
2)查询数学成绩高于50分的学生的英语和语文成绩
select name,scores[‘chinese’],scores[‘english’] from map1 where scores[‘math’] > 50;
3) 计算每一个科目的总成绩
分步骤拆分:
通过展开函数,展开一个map
select explode(scores) from map1;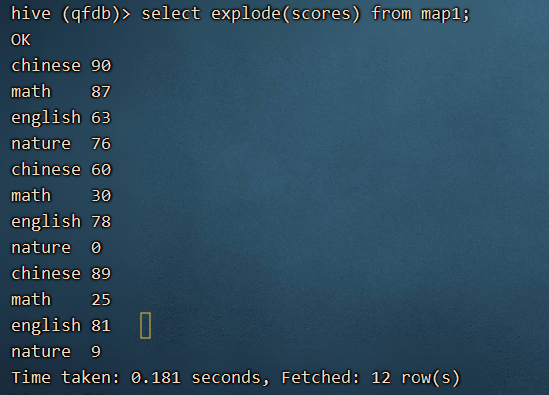
select subject ,cj from map1 lateral view explode(scores) sc_table as subject,cj;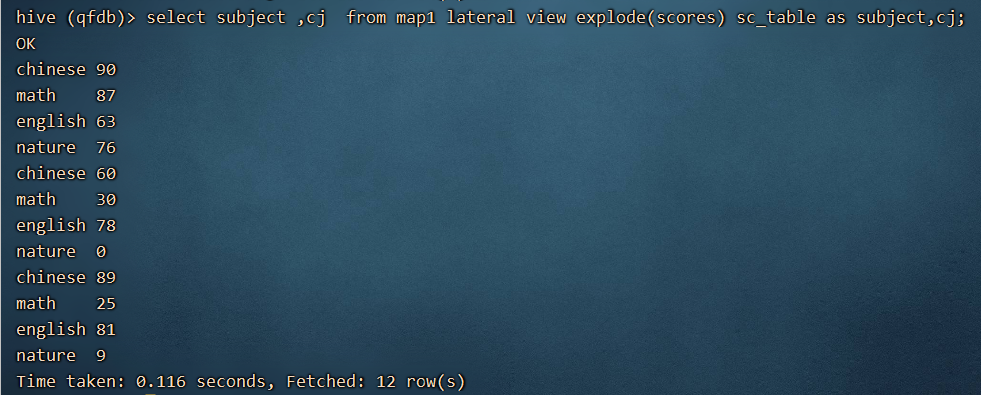
然后根据 subject 进行分组,然后对成绩进行合并。
select subject ,sum(cj) from map1 lateral view explode(scores) sc_table as subject,cj group by subject;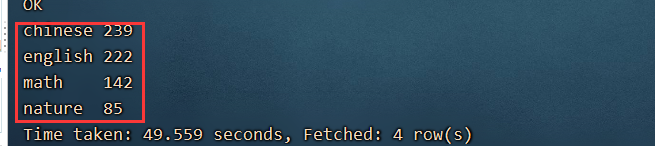
4)查询姓名,科目,成绩
select name,subject ,cj from map1 lateral view explode(scores) sc_table as subject,cj;
5) 查询每一个人的总成绩
select name,sum(cj) from map1 lateral view explode(scores) sc_table as subject,cj group by name;
6) 将第四步的数据形成一个新的表,将表数据变为map集合的形式:
select name,subject ,cj from map1 lateral view explode(scores) sc_table as subject,cj;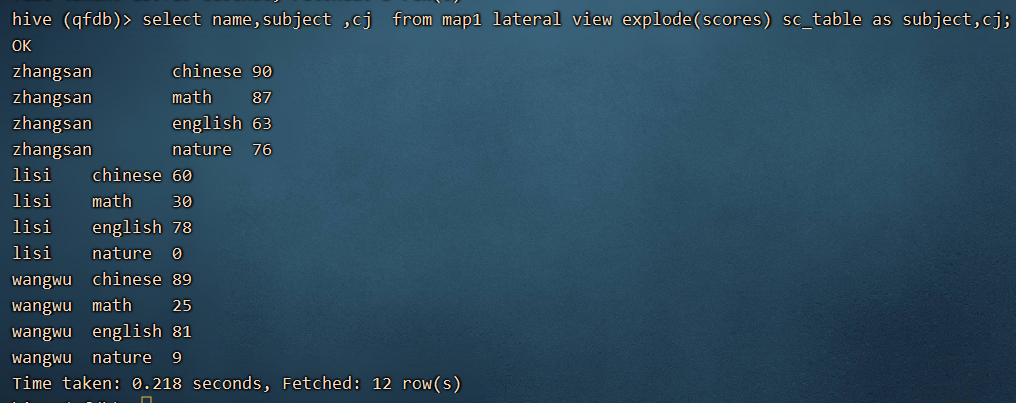
创建一个新的表:map2
create table map2 as select name,subject ,cj from map1 lateral view explode(scores) sc_table as subject,cj;
要将其变为之前的map集合,我们需要借助一个函数 str_to_map
select str_to_map(‘key1:value1,key2:value2’,’,’,’:’);
第一个参数:是一个string
第二个参数:每一个键值对的分隔符
第三个参数:键值对中间的分隔符
1) 将科目和成绩拼接起来
select name , concat (subject,’:’,cj) from map2;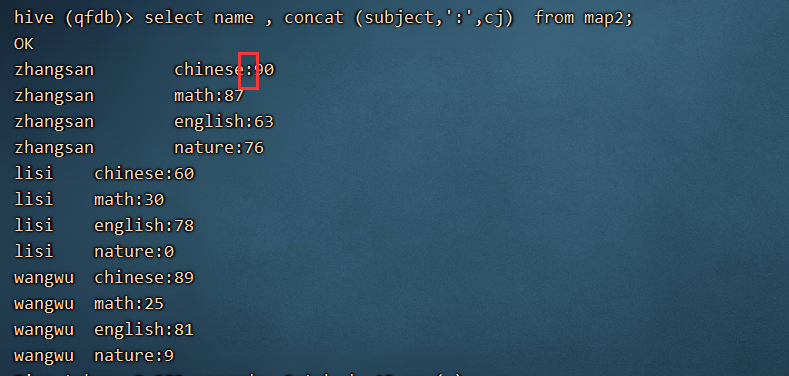
2) 将每一个人的所有科目合并起来
select name, collect_list(concat (subject,’:’,cj)) from map2 group by name;
select name, concat_ws(‘,’,collect_list(concat (subject,’:’,cj))) from map2 group by name;
字符串如何变为map集合呢?
select name, str_to_map(concat_ws(‘,’,collect_list(concat (subject,’:’,cj))) ,’,’,’:’)from map2 group by name;
3、struct 类型—类似于java中的类
搞一点数据:
zhangsan 河南省,郑州市,惠济区
lisi 河南省,洛阳市,偃师区
王五 江苏省,苏州市,xxx区
编写一个表:
create table if not exists struct1(
name string,
addr struct<province:string,city:string,street:string>
)
row format delimited
fields terminated by '\t'
collection items terminated by ',';
导入数据:load data local inpath ‘/hivedata/struct1.txt’ into table struct1;
需求:查询在河南省的人的数据
select name,addr.province from struct1 where addr.province=’河南省’;
select * from struct1 where scores.province=’河南省’;

若有收获,就点个赞吧
0 人点赞
