一、回顾
1、VMWare的安装\CentOS的安装
2、配置了一些Linux的文件
固定IP、hostname、时间的同步、免密登录等
3、安装了jdk、hadoop ,测试hadoop平台
二、搞几个脚本文件
jps-cluster.sh 用于查看多台电脑上的jps进程,省去了切换电脑的麻烦。
1、将以上脚本复制到 /usr/local/bin 下
2、给两个脚本文件赋可以执行的权限
chmod u+x xcall.sh
chmod u+x xsync.sh
chmod u+x jps-cluster.sh
3、三台电脑安装rsync
yum install -y rsync
4、测试一下
给每台电脑都创建一个文件夹 xcall.sh mkdir jiaoben
查看每一个电脑上是否有该文件夹 xcall.sh ls
测试一下文件同步脚本 xsync.sh /etc/profile
三、搭建完全分布式的集群环境
进入到hadoop的安装路径 /usr/local/hadoop/etc/hadoop 中进行修改
1、修改core-site.xml
<property><name>fs.defaultFS</name><value>hdfs://bigdata01:8020</value></property><!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 --><property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop/tmp</value></property>
2、修改hdfs-site.xml
<!-- namenode守护进程管理的元数据文件fsimage存储的位置--><property><name>dfs.namenode.name.dir</name><value>file://${hadoop.tmp.dir}/dfs/name</value></property><!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处--><property><name>dfs.datanode.data.dir</name><value>file://${hadoop.tmp.dir}/dfs/data</value></property><!-- 块的副本数--><property><name>dfs.replication</name><value>3</value></property><!-- 块的大小(128M),下面的单位是字节--><property><name>dfs.blocksize</name><value>134217728</value></property><!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局--><property><name>dfs.namenode.secondary.http-address</name><value>bigdata02:50090</value></property><!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局--><property><name>dfs.namenode.http-address</name><value>bigdata01:50070</value></property>
3、mapred-site.xml (从一个模板拷贝过来的文件 cp mapred-site.xml.template mapred-site.xml)
<!-- 指定mapreduce使用yarn资源管理器--><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- 配置作业历史服务器的地址--><property><name>mapreduce.jobhistory.address</name><value>bigdata01:10020</value></property><!-- 配置作业历史服务器的http地址--><property><name>mapreduce.jobhistory.webapp.address</name><value>bigdata01:19888</value></property>
4、yarn-site.xml
<!-- 指定yarn的shuffle技术--><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定resourcemanager的主机名--><property><name>yarn.resourcemanager.hostname</name><value>bigdata01</value></property><!--下面的可选--><!--指定shuffle对应的类 --><property><name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><!--配置resourcemanager的内部通讯地址--><property><name>yarn.resourcemanager.address</name><value>bigdata01:8032</value></property><!--配置resourcemanager的scheduler的内部通讯地址--><property><name>yarn.resourcemanager.scheduler.address</name><value>bigdata01:8030</value></property><!--配置resoucemanager的资源调度的内部通讯地址--><property><name>yarn.resourcemanager.resource-tracker.address</name><value>bigdata01:8031</value></property><!--配置resourcemanager的管理员的内部通讯地址--><property><name>yarn.resourcemanager.admin.address</name><value>bigdata01:8033</value></property><!--配置resourcemanager的web ui 的监控页面--><property><name>yarn.resourcemanager.webapp.address</name><value>bigdata01:8088</value></property>
5、修改hadoop-env.sh 中的jdk路径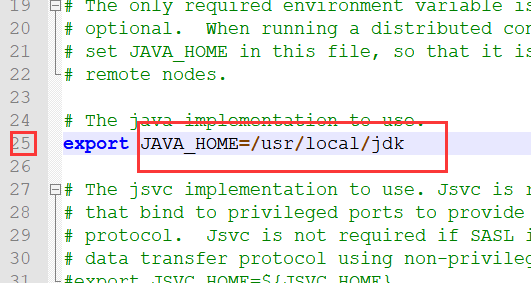
6、修改yarn-env.sh
7、修改slaves:
bigdata01bigdata02bigdata03
修改大概7个文件,然后每一台电脑上都需要修改。可以使用同步的脚本文件命令
xsync.sh /usr/local/hadoop/etc/hadoop/
同步以上文件夹。
8、测试免密登录没问题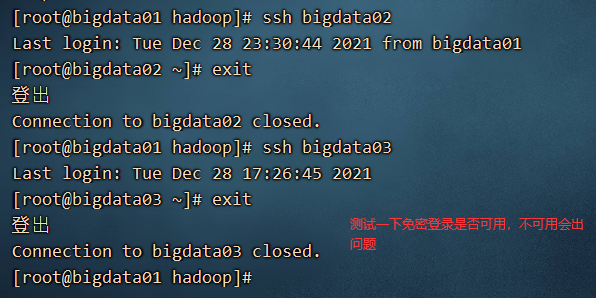
9、格式化namenode
hdfs namenode -format
10、启动hdfs平台
start-dfs.sh
启动过程中的日志,都存储在截图位置上
运行脚本文件 jps-cluster.sh 查看所有电脑的进程,如图所示,表示成功了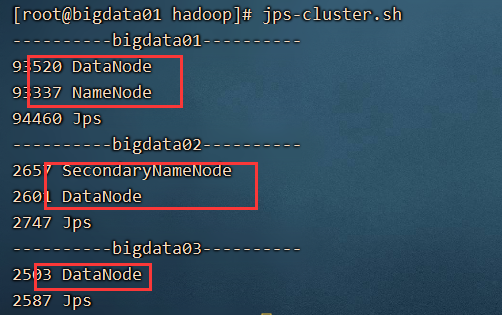
11、启动yarn平台 start-yarn.sh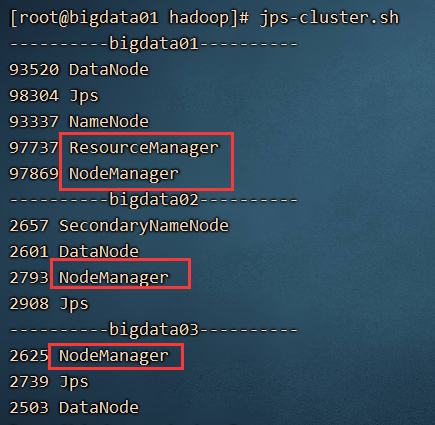
12、可以通过图形化的界面访问我们的hdfs以及yarn平台
hdfs平台的访问地址: 192.168.32.137:50070
访问yarn平台: 192.168.32.137:8088
四、HDFS的操作
1、通过shell命令操作
通过一个场景案例,学习一些shell命令。
通过hdfs平台运行wordcount的案例,学习shell命令
1)创建文件夹 hdfs dfs -mkdir /input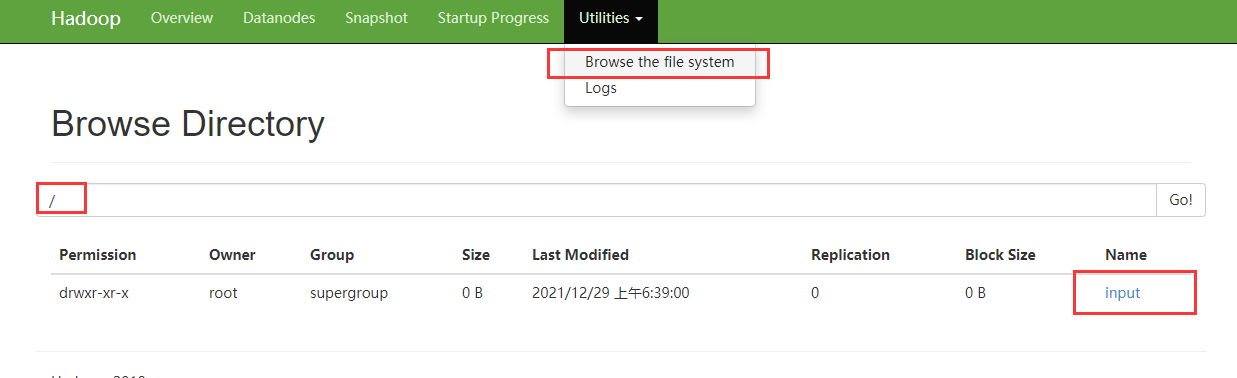
2)需要将统计的数据上传至文件夹下
hdfs dfs -put input/* /input
3)运行wordcount案例,统计结果
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /input /output
以上命令,只能运行一次,如果下次再运行,需要删除 /output文件夹才可以再次运行
4) 查看运行结果
hdfs dfs -cat /output/part-r-00000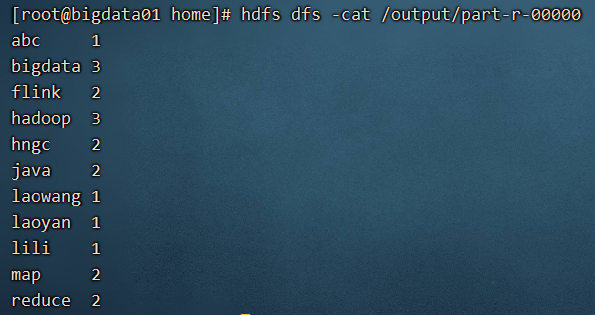
可以通过yarn平台查看已经运行的mapreduce任务:
下一次如果还行运行的话,需要删除输出路径的文件夹
hdfs dfs -rm /output/part-r-00000
hdfs dfs -rm /output/_SUCCESS
hdfs dfs -rmdir /output
如果将运行的结果下载下来呢?
hdfs dfs -get /output/part-r-00000 /home
-r 循环删除一个文件夹下的内容,这个方式也不错。
2、通过java代码操作 (不算是重点,但是环境的安装对mapreduce很重要)
1) 解压hadoop 压缩包,复制路径
2) 配置hadoop的环境变量
点击新增 系统变量,创建hadoop_home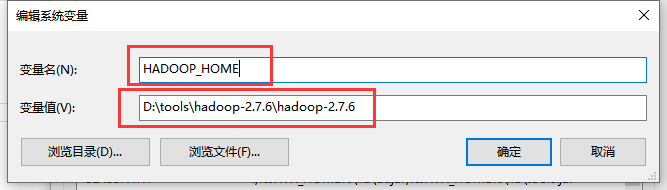
修改Path路径:是追加,不是覆盖
%HADOOP_HOME%\bin;
%HADOOP_HOME%\sbin;
测试一下hadoop环境是否成功
win+R cmd
如果出现java_home 的错误!
需要我们修改 hadoop-env.cmd 中的java_home环境
修改的文件存放在hadoop 解压包下的etc\hadoop文件夹下。
先找到你的jdk安装路径,一般都安装在 C 盘或者D盘下:
D:\Program Files\Java\jdk1.8.0_181
变异为:D:\PROGRA~1\Java\jdk1.8.0_181
如果以上配置,不管用,就将jdk目录换成jre目录。
记得保存,重新打开一个新的黑窗口,运行命令 hadoop version
最后一点点问题:
解压 
将里面的hadoop.dll 和 winutils.exe 复制出来,存放在 hadoop 的bin目录下。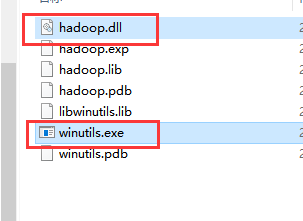
复制,粘贴到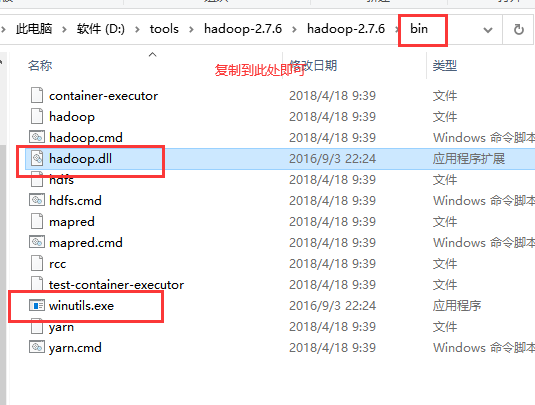
2)准备Maven
将maven解压到一个非中文路径下:
第二步:替换掉 conf 文件夹下的settings.xml配置文件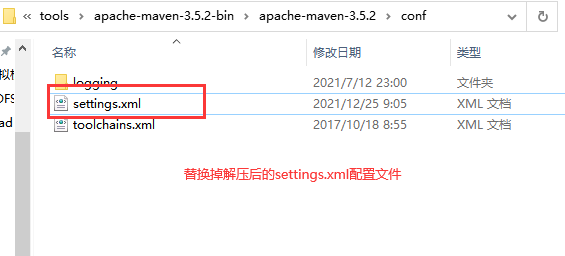
为什么要替换?
1) 修改了本地仓库地址 ,默认是存储在C盘的
2) 修改了阿里云镜像文件,默认是访问的国外的一个网站,网速比较慢
第三步:让我的idea开发工具,和我本地的maven进行关联

将idea和maven关联使用。
3) idea和jdk关联

3、使用java代码操作hdfs
创建项目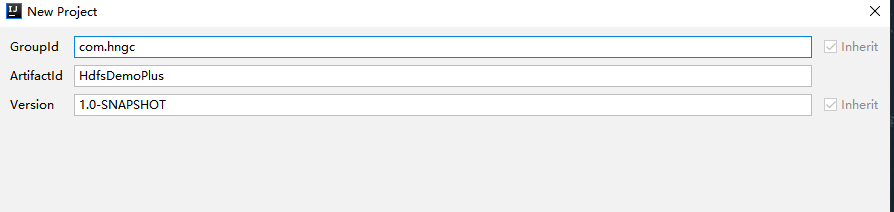

<packaging>jar</packaging>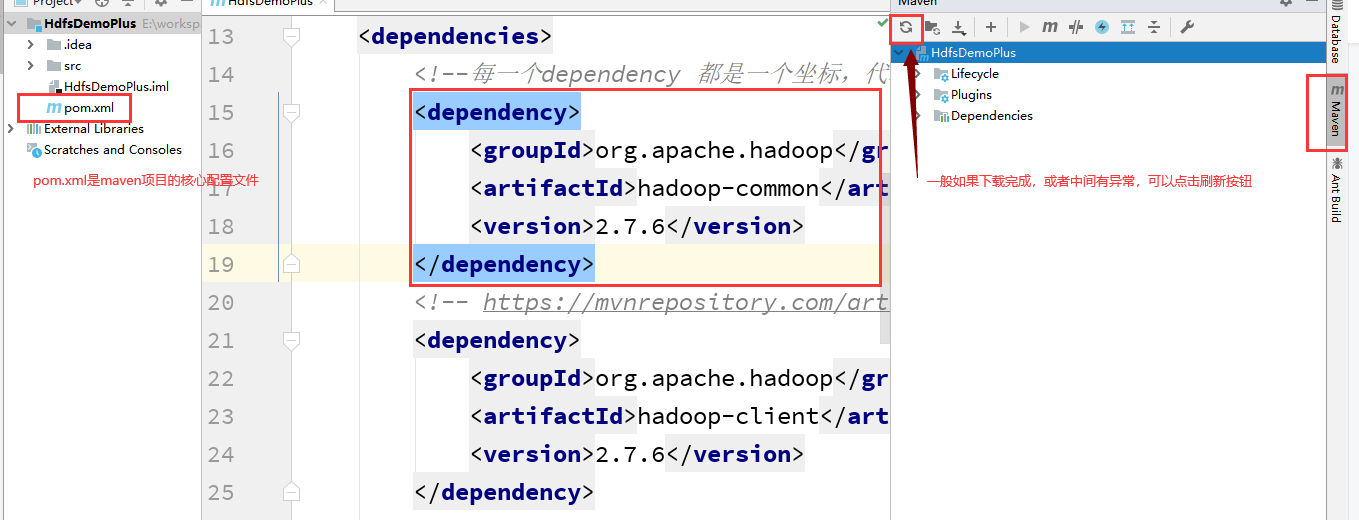
导入坐标:
<dependencies>
<!--每一个dependency 都是一个坐标,代表了一个或者多个jar包-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.6</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.6</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.6</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
编写代码:
使用到了单元测试。
说明缺失log4j的配置文件,复制过来一个即可,存放位置如下: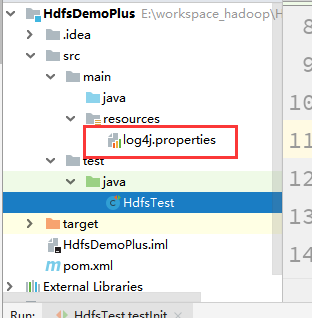
第一个代码,获取文件系统的对象
@Test
public void testInit() throws IOException {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.32.137:8020");
FileSystem fileSystem = FileSystem.get(configuration);
System.out.println(fileSystem);
System.out.println("文件系统的类型名称:"+fileSystem.getClass().getName());
}
第二个代码:文件的上传 将windows上的文件上传至hdfs平台
System.setProperty("HADOOP_USER_NAME","root");
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.32.137:8020");
FileSystem fileSystem = FileSystem.get(configuration);
Path localPath = new Path("D:/file1.txt");
Path hdfsPath = new Path("/input");
fileSystem.copyFromLocalFile(localPath,hdfsPath);
fileSystem.close();
System.out.println("上传成功");

要么修改hdfs的文件夹的权限,要么修改java代码
只需要在开始部分添加一句话即可:
System.setProperty("HADOOP_USER_NAME","root");
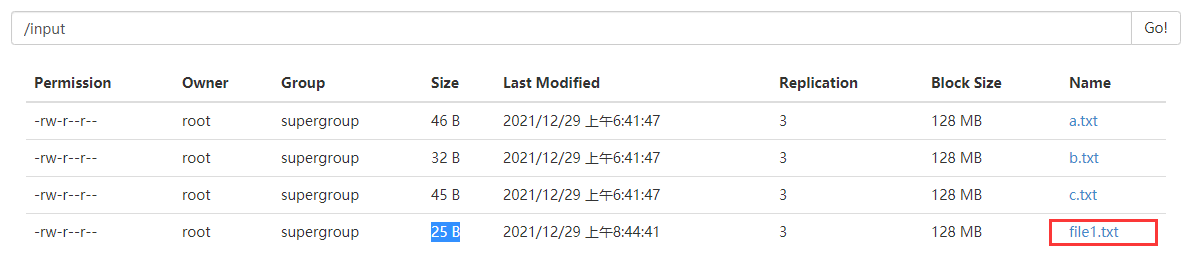
通过以上的java代码操作,我们了解到,如何通过java代码操作hdfs.
通过shell命令可以进行的操作,我们通过java代码都可以完成。
4、关于hdfs的理论部分
1)HDFS 会将大的文件切割成一个个块进行存储,每个块大小是固定的, hadoop1.x —> 64M hadoop2.x—>128M
Hadoop3.x—>256M ,块的大小可以通过配置文件进行配置。
2)HDFS不适用于存储大量的小文件。每一个块不管大小,都会占用150个字节的内存,大量小文件,会占用大量的内存。
3)HDFS不适用于低延时的数据访问。
4)HDFS 由三个组件组成 namenode datanode secondaryNamenode
namenode 和 secondaryNameNode 各有一个,datanode 可以有多个。
namenode 负责 整个hdfs的元数据的一些管理,数据存储在内存中。
datanode管理一些基本的数据块儿,块存储在磁盘上。
secondaryNameNode —> 不是namenode 的一个双胞胎,而只是一个小秘。帮助namenode 进行数据的本地化存储的。
5)namenode 的一个持久化机制
namenode 中的数据都是存储在内存的,为了防止数据丢失,提供了两个帮手fsimage , edit 这两个文件,可以陆续的将namenode中的数据存储在磁盘上。
每隔一个小时,或者不达到一个小时的时候hdfs被操作了100万次,会触发,数据备份操作,SecondaryNameNode 通知 namenode 开始备份了,namenode 就会产生一个新的fsimage和edit,secondarynamenode 将 fsimage和edit的文件进行拉取到另一个电脑上 ,进行合并,合并出来的新的fsimage传递回去,存放在namenode 电脑上。
namenode 电脑上只会存放最近的两次备份的 fsimage 文件,删除掉之前产生的fsimage文件。
6) 当你的namenode 电脑重新开机的时候,hdfs平台重新运行的时候,会加载最新的fsimage和edit文件,到内存中。
7) datanode 会每隔3秒跟namenode进行通信,告知namenode 我还活着。如果超过10分30秒还没有通知namenode,就认为该节点挂了。
常见问题: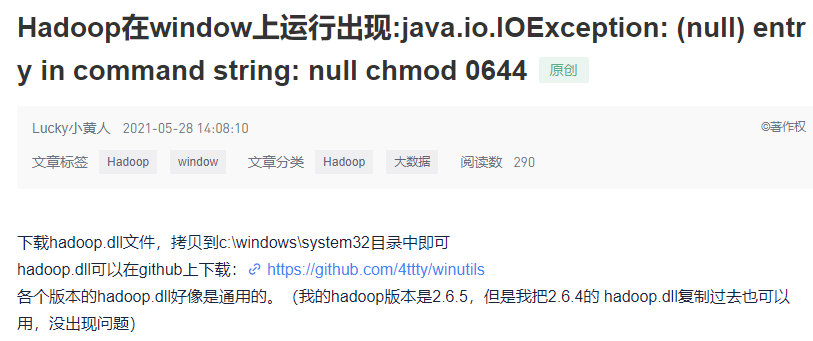

若有收获,就点个赞吧
0 人点赞
