一、复习
1、完全分布式的搭建(三台服务器),需要修改大约7个文件
2、脚本的使用(shell编程)— 帮助我们提高搭建环境的效率
3、本地hadoop环境的搭建
4、maven+idea+jdk
5、HSDF 理论、shell命令、java开发
二、MapReduce理论
Hadoop 由四大部分组成(Common、HDFS、Yarn、MapReduce)
整个大数据的技术发展 MapReduce —> MapReduce升级版 —> Spark — > Flink
理论部分:
MapReduce: 将运行的代码分发在不同的数据节点上,运行的结果进行合并,大大提高了运行的效率,减少了数据在电脑之间的传递。
MapReduce: 分为两个部分 Map阶段(对数据进行初步的处理)、Reduce阶段(进行合并)
MapReduce: 不适合做实时性很强的处理。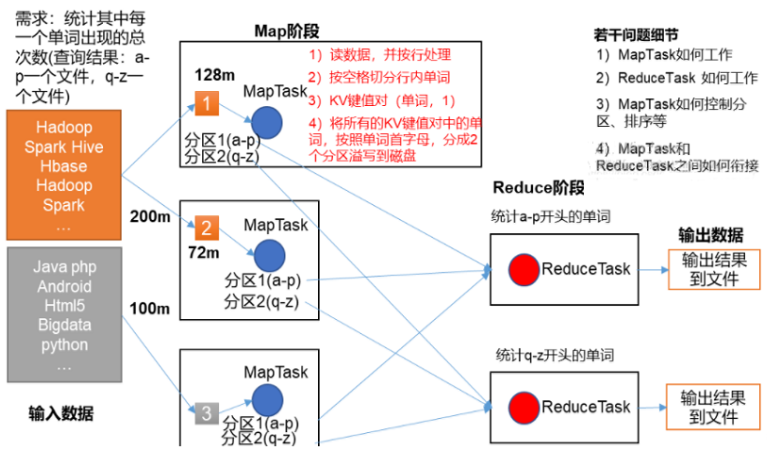

三、案例讲解
1、WordCount的案例:
1)创建maven项目
2)导入相应的坐标
<dependencies><!--每一个dependency 都是一个坐标,代表了一个或者多个jar包--><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.6</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.6</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.7.6</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope></dependency></dependencies>
3、拷贝log4j
4、代码编写
package com.hngc.mr01;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// <0,"hello java main hadoop">String line = value.toString();//拿到一行数据String[] arr = line.split("\\s+");// \s代表空格,+ 代表该空格出现一次或多次// 通过for循环,将切割出来的单词不断往外写入,写入到shuffle过程中for(String word:arr){context.write(new Text(word),new IntWritable(1));}}}
package com.hngc.mr01;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;import java.util.Iterator;public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {//(hadoop,<1,1,1,1...>)Iterator<IntWritable> iterator = values.iterator();int count = 0;while(iterator.hasNext()){IntWritable num = iterator.next();count += num.get();}context.write(key,new IntWritable(count));}}
package com.hngc.mr01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//设置环境
Configuration conf = new Configuration();
// 指定mapreduce任务是本地运行的
conf.set("mapreduce.framework.name","local");
// 我们的数据来源是本地文件系统,不是hdfs
conf.set("fs.defaultFS","file:///");
// 开启job任务
Job job = Job.getInstance(conf, "wordcount");
// 执行任务的入口类是哪一个
job.setJarByClass(WordCountDriver.class);
// map的类和reduce的类是哪一个,输入输出参数类型
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,new Path("file/mr/input"));
Path distPath = new Path("file/mr/output");
FileOutputFormat.setOutputPath(job,distPath);
/**
* 每次通过手动删除outPut文件夹很费劲,可以通过代码完成删除操作
*/
FileSystem fileSystem = FileSystem.get(conf);
boolean exists = fileSystem.exists(distPath);
if(exists){
fileSystem.delete(distPath,true);
}
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
5、再次运行,需要删除文件夹output
四、idea中的三种开发模式
1、local模式测试本地文件(同以上的wordCount)
2、local模式测试Hdfs文件
主要区别在于:数据均来自于hdfs,输出的结果也在hdfs上。

出现权限问题。
package com.hngc.mr02;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
System.setProperty("HADOOP_USER_NAME","root");
//设置环境
Configuration conf = new Configuration();
// 指定mapreduce任务是本地运行的
conf.set("mapreduce.framework.name","local");
// 我们的数据来源是hdfs
conf.set("fs.defaultFS","hdfs://192.168.32.137:8020");
// 开启job任务
Job job = Job.getInstance(conf, "wordcount2");
// 执行任务的入口类是哪一个
job.setJarByClass(WordCountDriver.class);
// map的类和reduce的类是哪一个,输入输出参数类型
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 此处的 path是hdfs中的路径,输出路径也是hdfs
FileInputFormat.setInputPaths(job,new Path("/input"));
Path distPath = new Path("/output");
FileOutputFormat.setOutputPath(job,distPath);
/**
* 每次通过手动删除outPut文件夹很费劲,可以通过代码完成删除操作
*/
FileSystem fileSystem = FileSystem.get(conf);
boolean exists = fileSystem.exists(distPath);
if(exists){
fileSystem.delete(distPath,true);
}
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
3、Yarn模式测试集群环境
本地代码,yarn平台、hdfs上的数据
1)去掉代码中的conf的代码:
// 指定mapreduce任务是本地运行的
_conf.set(“mapreduce.framework.name”,“local”);
// 我们的数据来源是hdfs
_conf.set(“fs.defaultFS”,“hdfs://192.168.32.137:8020”);
2)去集群环境上拷贝四个配置文件下来:core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml
下载之后,通过finalshell下载的,是在桌面的。
3) 将配置文件拷贝到 resources文件夹下
4)修改hosts文件,可以通过一些软件修改,比如 SwitchHosts
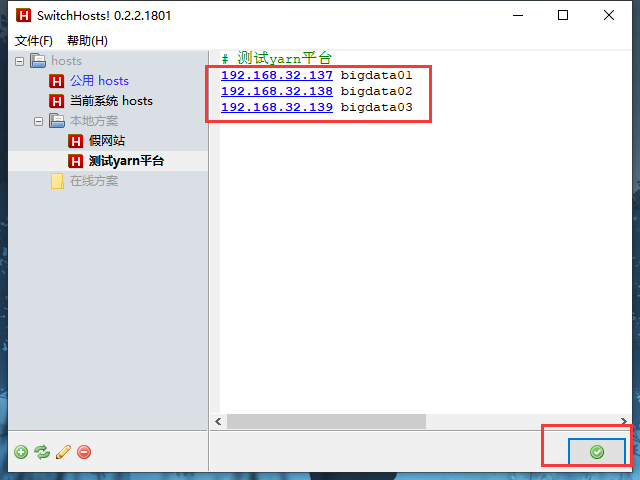
如果提示没有权限,使用管理员权限运行试一试。
5)打包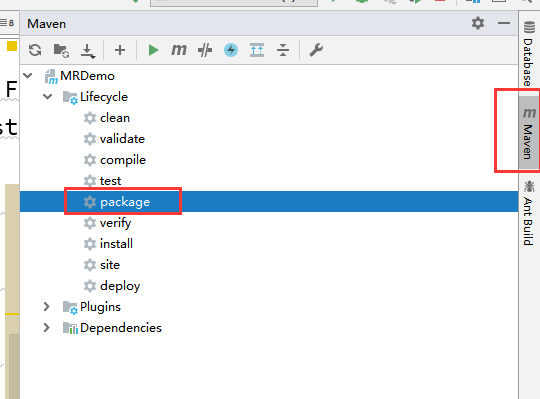
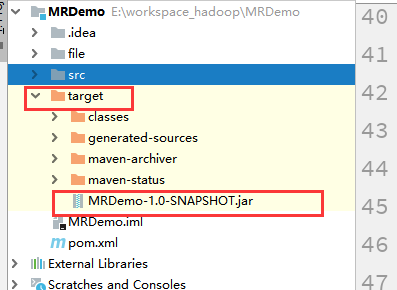
6)将jar包添加到本地环境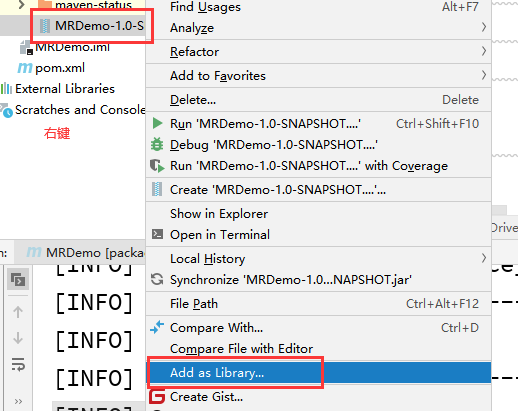
7)运行代码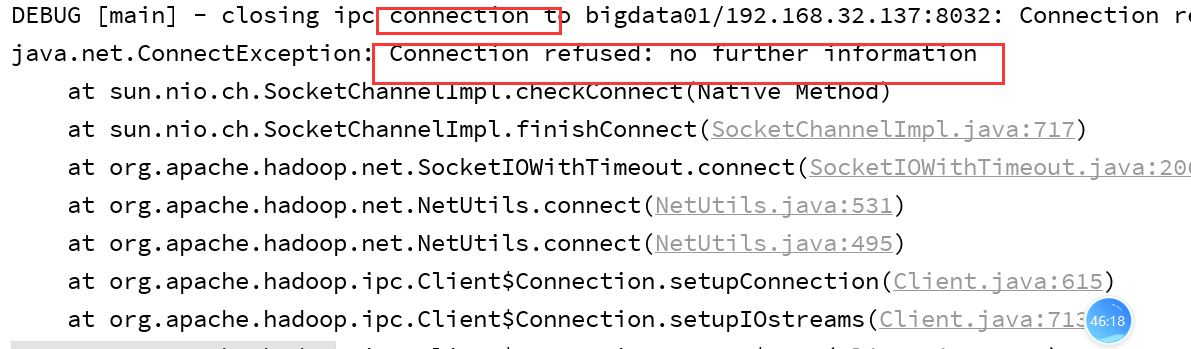
出现这个错误,说明我们的yarn平台没有运行。
start-yarn.sh 启动yarn平台。
运行过程中如果出现:
ExitCodeException exitCode=1: /bin/bash: 第 0 行:fg: 无任务控制
忘记粘贴一句话:
conf.set(“mapreduce.app-submission.cross-platform”, “true”);
package com.hngc.mr03;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
System.setProperty("HADOOP_USER_NAME","root");
//设置环境
Configuration conf = new Configuration();
conf.set("mapreduce.app-submission.cross-platform", "true");
// 开启job任务
Job job = Job.getInstance(conf, "wordcount3");
// 执行任务的入口类是哪一个
job.setJarByClass(WordCountDriver.class);
// map的类和reduce的类是哪一个,输入输出参数类型
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 此处的 path是hdfs中的路径,输出路径也是hdfs
FileInputFormat.setInputPaths(job,new Path("/input"));
Path distPath = new Path("/output");
FileOutputFormat.setOutputPath(job,distPath);
/**
* 每次通过手动删除outPut文件夹很费劲,可以通过代码完成删除操作
*/
FileSystem fileSystem = FileSystem.get(conf);
boolean exists = fileSystem.exists(distPath);
if(exists){
fileSystem.delete(distPath,true);
}
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
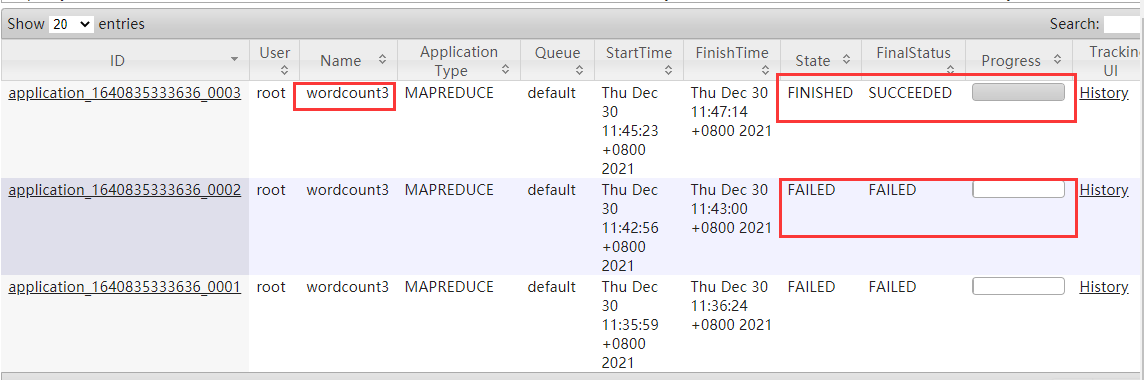
五、需要知道MapReduce中的数据类型有哪些?
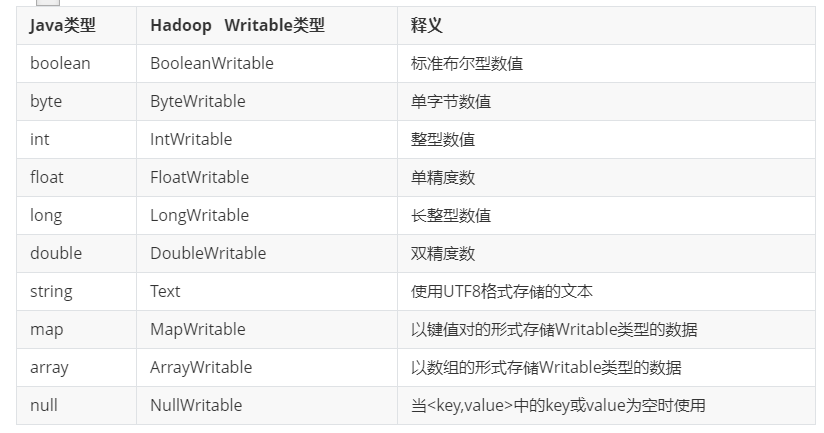
通过以上比较,发现每一个数据类型都是Writable,怎么回事儿?
Writable 是我们Hadoop的序列化形式。也就是说我们可以通过实现Writable接口自定义序列化类型。
如果我们自定义的数据类型,是在mapreduce中当做key值,需要实现WritableComparable。如果我们自定义的类型是当做Value值的,那么只需要实现Writable
六、关于流量统计的案例
拿到一个日志,先看数据格式,再看需求是什么?
需求:从日志文件中统计出每一个手机号的上下行流量以及总流量。
1363157995093 13922314466 00-FD-07-A2-EC-BA:CMCC 120.196.100.82 img.qfc.cn 12 12 3008 3720 200
通过分析:第二个字段是手机号,倒数第三个是上行流量,倒数第二个是下行流量。
编写代码:
Map : 格式化我们的数据,截取出需要的字段,分割成
手机号 <上行流量 下行流量>
Reduce: 每一个手机号进行上行流量和下行流量的合并,计算出总流量.
通过分析:我们需要自定义一个实体类型。
package com.hngc.flowcount;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class FlowPhoneWritable implements Writable {
private int up;// 上行流量
private int down; // 下行流量
//此处的无参构造方法一定要写,否则将来报错
public FlowPhoneWritable() {
}
public FlowPhoneWritable(int up, int down) {
this.up = up;
this.down = down;
}
public int getUp() {
return up;
}
public void setUp(int up) {
this.up = up;
}
public int getDown() {
return down;
}
public void setDown(int down) {
this.down = down;
}
// 序列化的方法
public void write(DataOutput dataOutput) throws IOException {
// 此处的序列化的书写格式,一定要记牢,不要使用write方法,是writeInt()
dataOutput.writeInt(up);
dataOutput.writeInt(down);
}
// 反序列化的方法
public void readFields(DataInput dataInput) throws IOException {
// 此处的发序列化,一定要和序列化的顺序照应,否则报错
this.up = dataInput.readInt();
this.down=dataInput.readInt();
}
}
编写Mapper、Reducer、Driver, 我们使用了内部类
package com.hngc.flowcount;
import com.hngc.mr01.WordCountDriver;
import com.hngc.mr01.WordCountMapper;
import com.hngc.mr01.WordCountReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Iterator;
/**
* 这个流量统计的案例,我讲Mapper、Reducer、Driver 编写在一个类中
*/
public class FlowCountDriver {
public static class FlowCountMapper extends Mapper<LongWritable, Text,Text,FlowPhoneWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//此处编写业务
String line = value.toString();
//1363157995093 13922314466 00-FD-07-A2-EC-BA:CMCC 120.196.100.82 img.qfc.cn 12 12 3008 3720 200
String[] arr = line.split("\t");// \t 代表的是tab键的空格 张三 李四 王五
String phone = arr[1];//获取手机号
// 此处如果不是手机号码,直接返回进入到下一个map方法。
if(phone.length()!=11){
return;
}
int up = Integer.parseInt(arr[arr.length-3]);//上行流量
int down = Integer.parseInt(arr[arr.length-2]);// 下行流量
context.write(new Text(phone),new FlowPhoneWritable(up,down));
}
}
public static class FlowCountReducer extends Reducer<Text,FlowPhoneWritable,Text,Text>{
@Override
protected void reduce(Text key, Iterable<FlowPhoneWritable> values, Context context) throws IOException, InterruptedException {
Iterator<FlowPhoneWritable> iterator = values.iterator();
int upCount=0,downCount=0;
// (1367333232,<flowphone01,flowphone02,flowphone03>)
while(iterator.hasNext()){
FlowPhoneWritable flowPhone = iterator.next();
upCount += flowPhone.getUp();
downCount += flowPhone.getDown();
}
Text message = new Text( "上行流量" + upCount + ",下行流量:" + downCount + ",总流量数:" + (upCount + downCount));
context.write(key,message);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//设置环境
Configuration conf = new Configuration();
// 指定mapreduce任务是本地运行的
conf.set("mapreduce.framework.name","local");
// 我们的数据来源是本地文件系统,不是hdfs
conf.set("fs.defaultFS","file:///");
// 开启job任务
Job job = Job.getInstance(conf, "phoneFlowCount");
// 执行任务的入口类是哪一个
job.setJarByClass(FlowCountDriver.class);
// map的类和reduce的类是哪一个,输入输出参数类型
job.setMapperClass(FlowCountMapper.class);
job.setReducerClass(FlowCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowPhoneWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job,new Path("E:\\河南工程学院大数据实训\\Day03-MapReduce实战\\The required Data\\HTTP_20130313143750.dat"));
Path distPath = new Path("file/mr/output2");
FileOutputFormat.setOutputPath(job,distPath);
/**
* 每次通过手动删除outPut文件夹很费劲,可以通过代码完成删除操作
*/
FileSystem fileSystem = FileSystem.get(conf);
boolean exists = fileSystem.exists(distPath);
if(exists){
fileSystem.delete(distPath,true);
}
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
MapTask 有多少个?ReducerTask有多少个?Map方法执行了几次?Reduce方法执行了几次?
MapTask有几个取决于数据的块儿(片儿)有几个,比如数据片儿的数量有10个,我们的MapTask就有多少个。
Map方法执行了几次?取决于数据有多少行,每一行就执行一次map方法。
ReduceTask有多少个,取决于我们的运行结果输出多少个?结果如果是一个文件,ReduceTask就只有一个。
Reduce方法执行多少次,取决于我们的数据,比如手机号,每一个手机号统计一次。
七、说一说分区器
比如我们的wordcount统计,a-p 统计结果放在一个结果文件中,另一个q-z放在另一个结果文件中。
自定义分区器:
package com.hngc.mr01;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class WordCountPartationer extends Partitioner<Text, IntWritable> {
public int getPartition(Text text, IntWritable intWritable, int i) {
// any quit
String word = text.toString();
char c = word.charAt(0);
// 返回值必须从0 开始,中间序号必须连续
if((c>='a'&&c<='p')||(c>='A'&&c<='P')){
return 0;
}else if((c>='q'&&c<='z')||(c>='Q'&&c<='Z')){
return 1;
}else{
return 2;
}
}
}
使用分区器: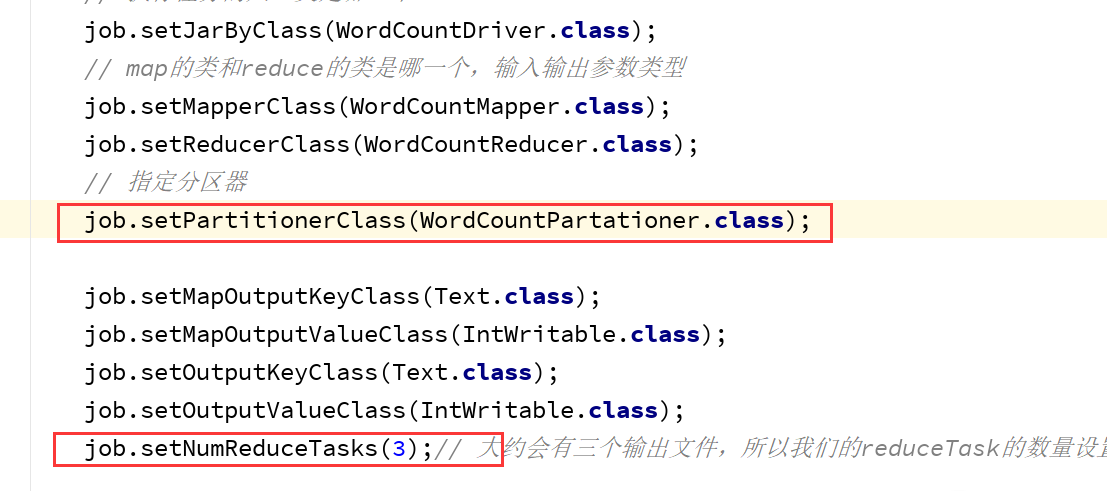
八、再来一个案例
从给定的数据中,计算每一年的最高温度是多少
温度数据的说明:
1. 每行数据的 [15,18] 位是年份
2. 每行的第87个字符,代表温度的符号(正负)
3. 每行的第 [88,91] 位代表温度的值,如果温度是9999代表无效温度
4. 每行的第92位是一个校验位,如果是0,1,4,5,9代表有效温度
数据来一行:
0188010010999992000010100004+70930-008670FM-12+0009ENJA V0202101N002110021019N0025001N1+00101+00031098181ADDAA106004191AY181061AY251061GF108991081061002501999999MA1999999098061MD1510071+9999MW1501REMSYN088AAXX 01004 01001 11325 82104 10010 20003 39806 49818 55007 60041 75085 886// 333 91119;
思路:
截取数据 年份当做Key 温度当做Value
Reduce阶段对这些温度进行比较,取出最大值
package com.hngc.temp;
import com.hngc.mr01.WordCountDriver;
import com.hngc.mr01.WordCountMapper;
import com.hngc.mr01.WordCountPartationer;
import com.hngc.mr01.WordCountReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Iterator;
/**
* 温度数据的说明:
* 1. 每行数据的 [15,18] 位是年份
* 2. 每行的第87个字符,代表温度的符号(正负)
* 3. 每行的第 [88,91] 位代表温度的值,如果温度是9999代表无效温度
* 4. 每行的第92位是一个校验位,如果是0,1,4,5,9代表有效温度
*/
public class MaxTempDriver {
public static class MaxTempMapper extends Mapper<LongWritable,Text,Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String year = line.substring(15,19);
int temp = Integer.parseInt(line.substring(87,92));
int validateCode = Integer.parseInt(line.substring(92,93));
// 此处需要对无效的数据进行过滤
if(Math.abs(temp)==9999){
return;
}
if(validateCode != 0 && validateCode!=1 && validateCode!=4 && validateCode!=5 && validateCode !=9){
return ;
}
context.write(new Text(year),new IntWritable(temp));
}
}
public static class MaxTempReducer extends Reducer<Text, IntWritable,Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int maxTemp = Integer.MIN_VALUE;//给定一个默认值,
Iterator<IntWritable> iterator = values.iterator();
while(iterator.hasNext()){
IntWritable tempWritable = iterator.next();
int temp = tempWritable.get();
maxTemp = Math.max(maxTemp,temp);
}
context.write(key,new IntWritable(maxTemp));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//设置环境
Configuration conf = new Configuration();
// 指定mapreduce任务是本地运行的
conf.set("mapreduce.framework.name","local");
// 我们的数据来源是本地文件系统,不是hdfs
conf.set("fs.defaultFS","file:///");
// 开启job任务
Job job = Job.getInstance(conf, "tempMax");
// 执行任务的入口类是哪一个
job.setJarByClass(MaxTempDriver.class);
// map的类和reduce的类是哪一个,输入输出参数类型
job.setMapperClass(MaxTempMapper.class);
job.setReducerClass(MaxTempReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,new Path("E:\\河南工程学院大数据实训\\Day03-MapReduce实战\\The required Data\\温度数据"));
Path distPath = new Path("file/mr/output3");
FileOutputFormat.setOutputPath(job,distPath);
/**
* 每次通过手动删除outPut文件夹很费劲,可以通过代码完成删除操作
*/
FileSystem fileSystem = FileSystem.get(conf);
boolean exists = fileSystem.exists(distPath);
if(exists){
fileSystem.delete(distPath,true);
}
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
九、关于Yarn
Yarn的启动 : start-yarn.sh
角色: 整个yarn你可以认为是大数据平台的一个操作系统,可以帮助我们运行一些任务。
ResourceManager:
龙头老大,可以管理NodeManager
NodeManager: 每一台电脑上的管家
Container: 一个个小的运行的容器,里面包含一部分内存,CPU,硬盘空间等。
AppMaster: 每一个任务运行,都需要有一个Master管理者。相当于公司里面的项目经理。

若有收获,就点个赞吧
0 人点赞
