redis是一款非关系型数据库。
用于数据缓存,高访问,存储量不大。
MySQL磁盘数据库,安全性高;Redis内存数据库,访问速度快,提高访问性能。
在虚拟机启动redis服务:进入src目录中,./redis-server redis.conf
启动客户端的方式:在src目录中,./redis-cli
Redis数据类型
Redis中文网:https://www.redis.net.cn
http://doc.redisfans.com/
上面两个网站里面有所有的命令详解
Redis存储的是key-value结构的数据,其中key是字符串类型,value有5种常用的数据类型:
- 字符串 string:普通字符串,常用
- 哈希 hash:适合存储对象
- 列表 list:按照插入顺序排序,可以有重复元素
- 集合 set:无序集合,没有重复元素
- 有序集合 sorted set / zset:集合中每个元素关联一个分数(score),根据分数升序排序,没有重复元素

字符串string操作命令
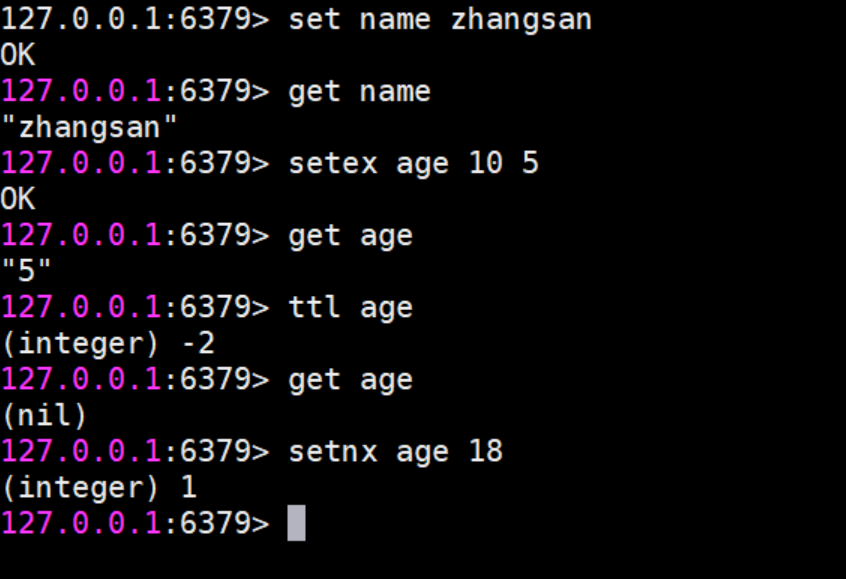
- SET key value 设置指定key的值
- GET key 获取指定key的值
- SETEX key seconds value 设置指定key的值,并将 key 的过期时间设为 seconds 秒
- SETNX key value 只有在 key 不存在时设置 key 的值
- del key1 key2 … 删除指定的key数据
哈希hash操作命令
Redis hash 是一个string类型的field和value的映射表,hash特别适用于存储对象
hash里面含有的键值对个数有限制,限制42亿以内
常用命令:
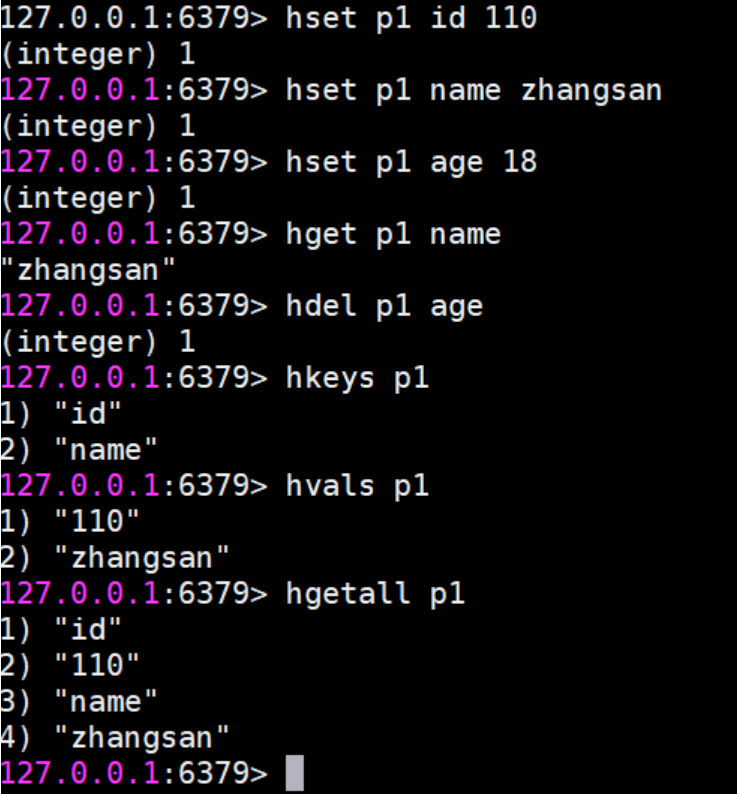
- HSET key field value 将哈希表 key 中的字段 field 的值设为 value
- HGET key field 获取存储在哈希表中指定字段的值
- HDEL key field 删除存储在哈希表中的指定字段
- HKEYS key 获取哈希表中所有字段
- HVALS key 获取哈希表中所有值
- HGETALL key 获取在哈希表中指定 key 的所有字段和值
列表list操作命令
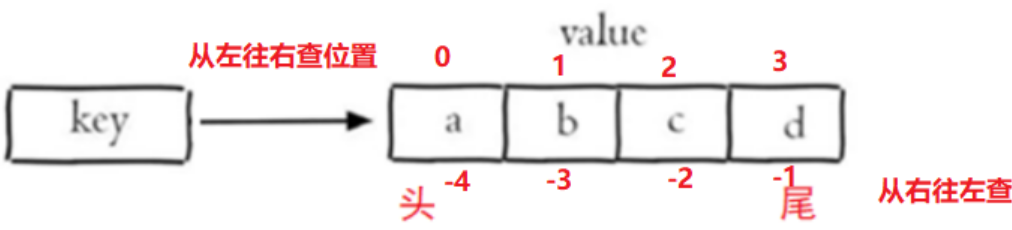
Redis列表是简单的字符串列表,按照插入顺序排序,类似于java中的linkedList(双向链表),value的个数限制42亿个以内。
常用命令:
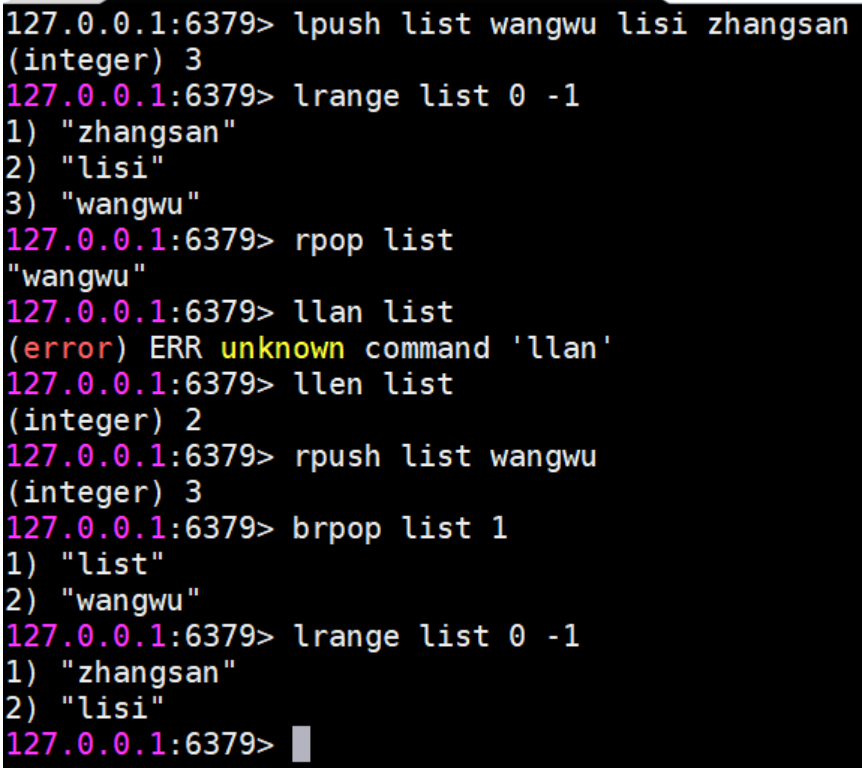
- LPUSH key value1 [value2] Left, 将一个或多个值插入到列表头部(左部), rpush是从尾部插入
- LRANGE key start stop 获取列表指定范围内的元素
- RPOP key 移除并获取列表最后一个元素 lpop从左侧头部删除一个元素
- LLEN key 获取列表长度
- BRPOP key1 [key2 ] timeout 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超 时或发现可弹出元素为止,超时时间单位秒
应用场景:数据已经固定的排行榜(这里排序不是实时的,而是插入后顺序就固定的)
集合set操作命令
Redis set是string类型的无序集合,集合成员是唯一的,不能出现重复的数据。
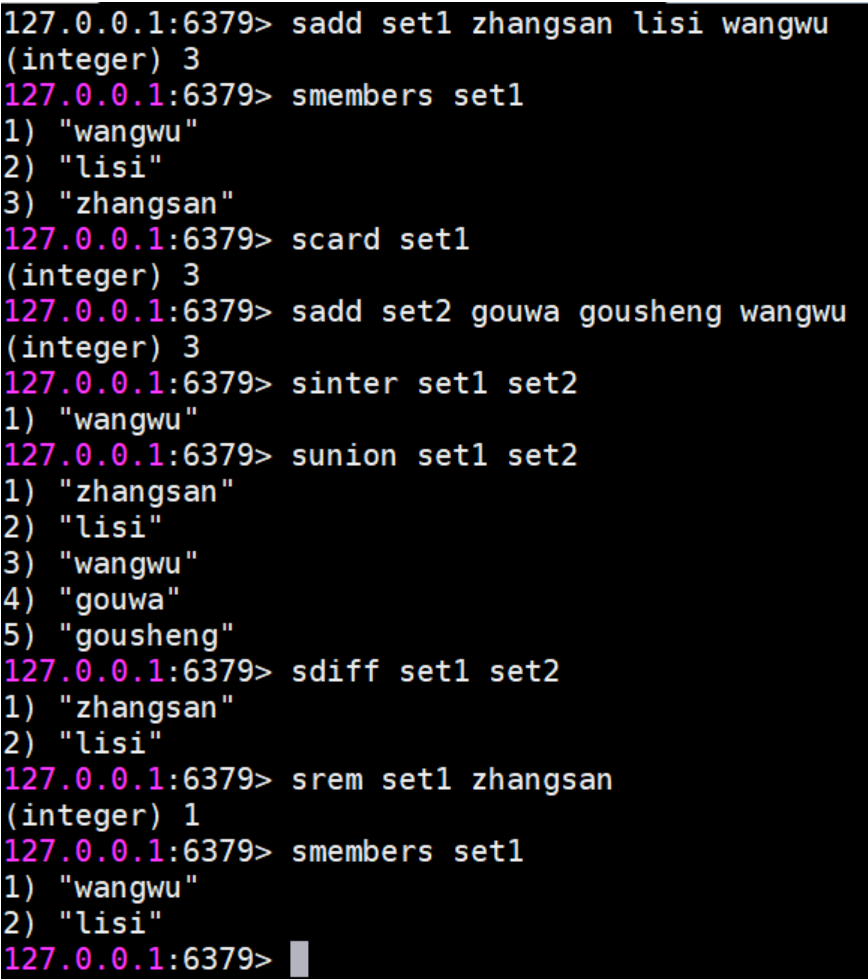
- SADD key member1 [member2] 向集合添加一个或多个成员
- SMEMBERS key 返回集合中的所有成员
- SCARD key 获取集合的成员数
- SINTER key1 [key2] 返回给定所有集合的交集
- SUNION key1 [key2] 返回所有给定集合的并集
- SDIFF key1 [key2] 返回给定所有集合的差集, 含义是key1有哪个元素在key2中不存在
- SREM key member1 [member2] 移除集合中一个或多个成员
有序集合sorted set操作命令
Redis sorted set 有序集合是string类型元素的集合,且不允许重复的成员。每个元素都会关联一个double类型的分数(score)。redis正是通过分数来为集合中的成员进行从小到大排序。有序集合的成员是唯一的,但分数却可以重复。
常用命令:
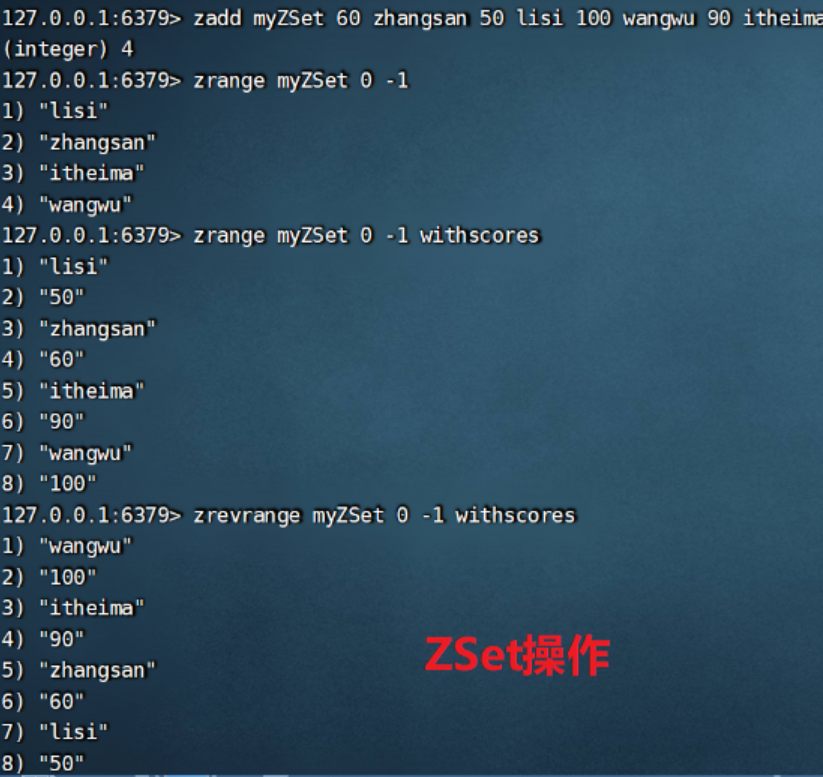
- ZADD key score1 member1 [score2 member2] 向有序集合添加一个或多个成员,或者更新已存在成员的 分数
- ZRANGE key start stop [WITHSCORES] 通过索引区间返回有序集合中指定区间内升序排序的成员 zrevrange降序查询
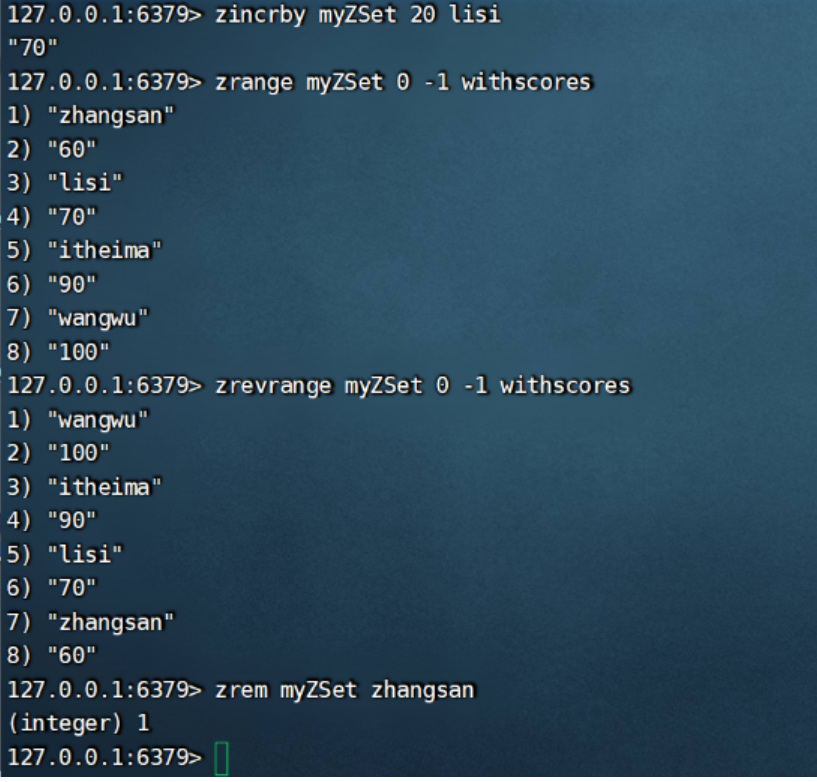
- ZINCRBY key increment member 有序集合中对指定成员的分数加上增量 increment
- ZREM key member [member …] 移除有序集合中的一个或多个成员
应用场景:实时排序, 加入的元素的数字就会比较进行重新排序。
通用命令
Redis中的通用命令,主要是针对key进行操作的相关命令:
- KEYS pattern 查找所有符合给定模式( pattern)的 key * 代表任意0~多个字符? 代表任意1个字符
- EXISTS key 检查给定 key 是否存在
- TYPE key 返回 key 所储存的值的类型
- TTL key 返回给定 key 的剩余生存时间(TTL, time to live),以秒为单位
- DEL key 该命令用于在 key 存在是删除 key
redis服务器上一共有16个数据库db0,db1,….db15, 如果不指定默认操作数据在db0的数据库上
切换数据库操作的命令 : select 数字
数字范围:0~15
在Java中操作Redis
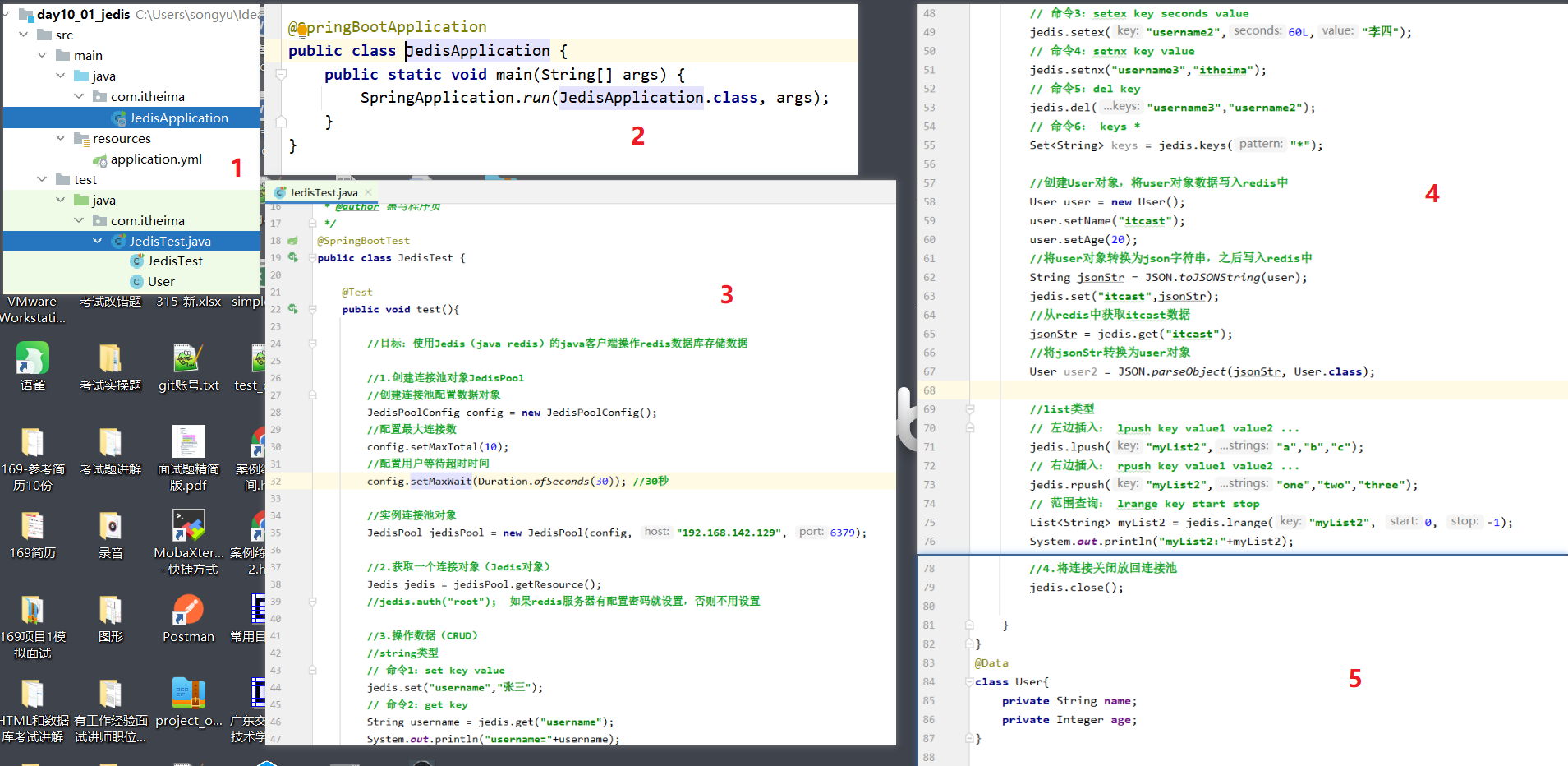
Jedis
Spring Data Redis
首先导入依赖
Spring Data Redis中提供了一个高度封装的类:RedisTemplate,针对 Jedis 客户端中大量api进行了归类封装,将同一类型操作封装为operation接口,具体分类如下:
- ValueOperations:简单K-V操作
- SetOperations:set类型数据操作
- ZSetOperations:zset类型数据操作
- HashOperations:针对hash类型的数据操作
- ListOperations:针对list类型的数据操作
ValueOperations是最常用的,占到百分之99,其他的用到查API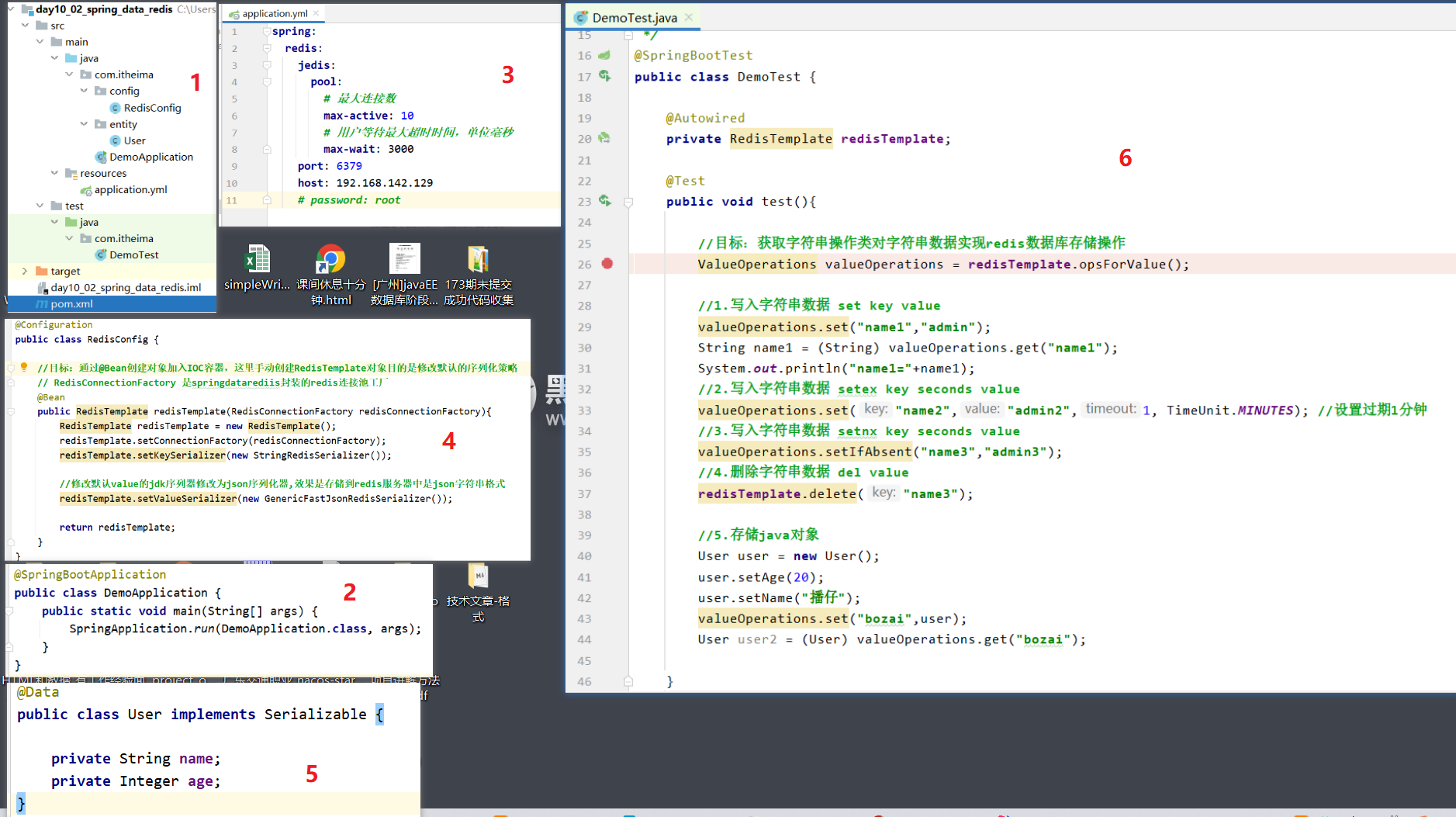
ValueOperations能大大简化存储java对象的步骤。
在RedisConfig类中:
在实体类中: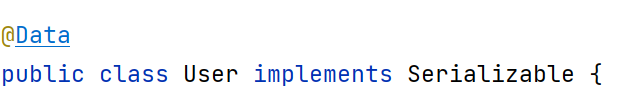
这里redis存储的是序列化后的数据,默认的是value的jdk序列器,上面两张图是把jdk序列器改为json序列化器,那么在redis数据库读到的就不是序列号了,而是java中传过去的数据。
Redis的持久化机制
如果不做持久化,redis服务器如果异常退出,会导致所有缓存数据丢失,当redis再次开启没有缓存数据,此时所有的都会去数据库查找数据,导致关系型数据库的压力瞬间变大,可能让数据库会崩溃。
原则:尽量不让redis的数据全部丢失,减少mysql的压力,所以redis有持久化机制
redis支持2种持久化机制:RDB和AOF, 默认开启的RDB,AOF默认没有开启
RDB
RDB策略也叫快照策略,持久化到一个dump.rdb文件中
有3个条件进行持久化操作,redis.conf 配置文件有设置:
save 900 1 : 如果有1个key进行了增删改操作,那么900秒(15分钟)持久化一次
save 300 10 : 如果有10个key进行了增删改操作,那么300秒(5分钟)持久化一次
save 60 10000 : 如果有10000个key进行了增删改操作,那么60秒(1分钟)持久化一次
RDB特点:
- 优点:几分钟持久化一次,持久化频率不高,不会影响redis运行性能
- 缺点:由于持久化频率低,会导致数据丢失较严重,比如服务器崩溃了,可能丢失几分钟的数据
AOF
第一步:开启AOF策略: 编辑redis.conf:
开启AOF策略: 编辑redis.conf
appendonly no 这是默认设置,需要修改为 appendonly yes 代表开启AOF持久化策略, 提供了3种AOF的方式:
appendfsync always :默认没有启用,这是 实时持久化,操作一个key的写入就持久化一次,
appendfsync everysec:这是默认启动的方式,每秒持久化一次,如果使用AOF推荐这个方式
appendfsync no:默认没有启用,是交给redis服务器自己去处理,忙的时候不持久化,空闲的时候再持久化。
第二步: 重启redis服务和应用最新修改的配置文件
AOF特点:
- 优点:每秒持久化一次,持久化频率高,数据不易丢失,可能会丢失1秒内的数据。这种方式数据安全较好。
- 缺点:持久化频率非常高,在企业实践应用中如果发现非常耗CPU,一般如果CPU的负载超过0.6建议不要使用这个策略,如果是0.6以下是可以开启的
当RDB和AOP同时开启的时候,服务器启动的时候是如何恢复数据?
答:redis4.0以前是如果开启了AOF,只会恢复AOF的数据
这种方式被开发者社区投诉,说不够智能,建议AOF开始备份时间起应该恢复AOF的数据,时间以前应该恢复RDB的数据
redis4.0以后RDB和AOF数据都恢复了,以AOF开始时间点为基准,时间点前面恢复RDB数据,时间点后使用AOF恢复数据

若有收获,就点个赞吧
0 人点赞
