SQL基本操作
数据库的作用:
1.永久保存数据
2.操作方便
SQL分类:
DDL(Data Definition Language) 数据定义语言,用来定义数据库对象:数据库,表,列等
DML(Data Manipulation Language) 数据操作语言,用来对数据库中表的数据进行增删改
DQL(Data Query Language) 数据查询语言,用来查询数据库中表的记录(数据)
DCL(Data Control Language) 数据控制语言,用来定义数据库的访问权限和安全级别,及创建用户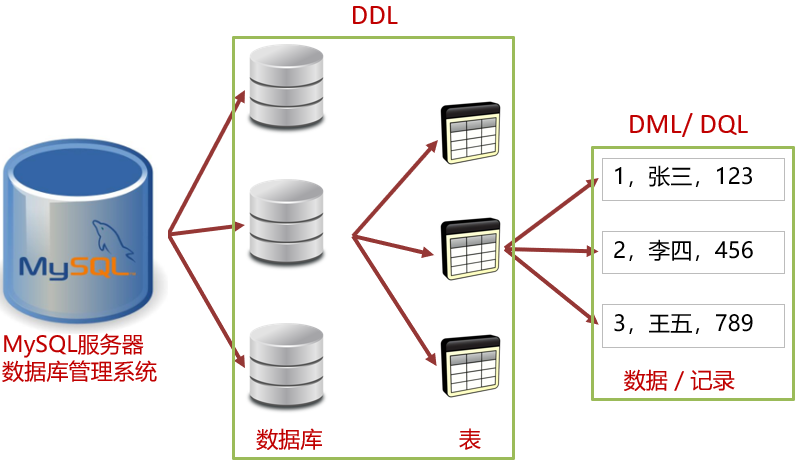
使用SQL创建、删除数据库:
创建数据库:CREATE DATABASE 数据库名;
删除数据库:DROP DATABASE 数据库名;
使用SQL对表进行增、删、改、查操作:
1.查看表:SHOW TABLES;
2.创建表:CREATE TABLE 表名(字段名 类型,字段名 类型);
3.删除表:DROP TABLE 表名;
4.查询表结构(了解)
DESC 表名;//description
5.DDL修改表(了解)

DOUBLE(5, 2): 总共5位, 小数占2位;
— 面试题: CHAR(5)和VARCHAR(5)的区别;
— CHAR(5): 固定长度的字符串,不管存几个内容,都要占用5个空间, 存’abc’ 占5个空间,效率高, 长度固定用char;
— VARCHAR(5): 数据有多长,就占用几个空间, 存’abc’ 占3个空间, 效率稍低, 长度不固定用varchar;
使用SQL对表中数据增、删、改操作:
添加数据:INSERT INTO 表名(字段名1,字段名2)VALUES (Z值1,值2);
修改数据:UPDATE 表名 SET 字段名=新的值;
删除数据:DELETE FROM 表名;
使用SQL对表中数据查询操作:
①SELECT *FROM 表名;
②去除重复查询: DISTINCT
③给列起别名
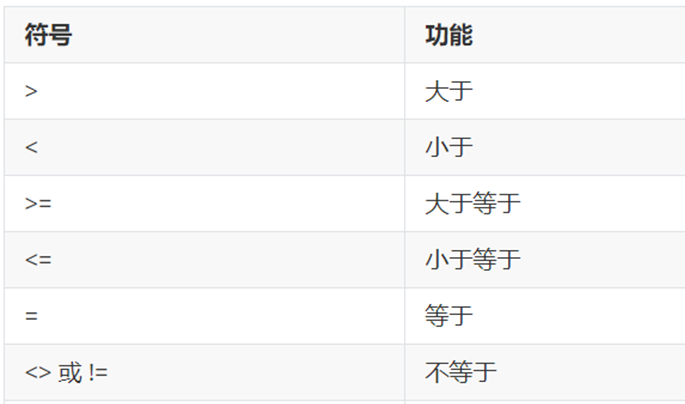
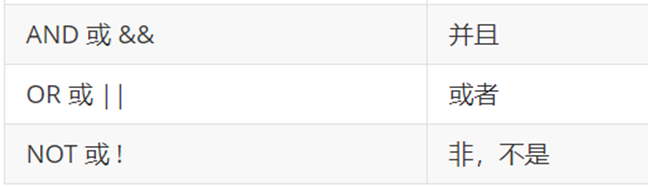
条件查询:





模糊查询like:
模糊查询语法
SELECT 字段名 FROM 表名 WHERE 字段名 LIKE ‘通配符字符串’;
MySQL通配符有两个
%: 表示任意多个字符
_: 表示一个字符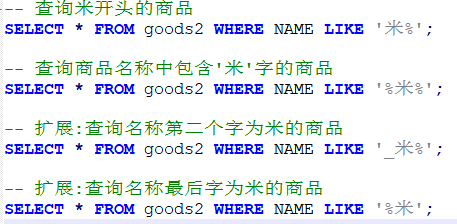
使用SQL对表中数据排序查询操作:
SELECT*FROM 表名 ORDER BY 字段名 排序方式;
ASC:升序
DESC:降序
聚合函数
SELECT 聚合函数(字段) FROM 表名;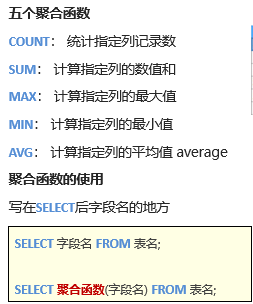
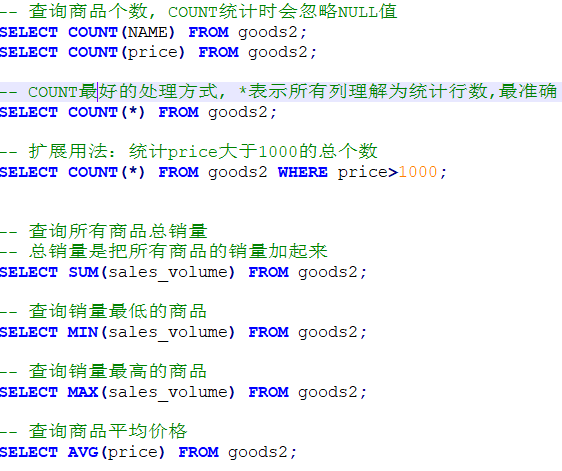

细节:如果不是数值类型(整数/小数),那么聚合函数计算结果为0。
分组查询(GROUP BY)

having与where的区别
where是在分组前对数据进行过滤,having是在分组后对数据进行过滤
where后面不可以使用聚合函数,having后面可以使用聚合函数
使用SQL对表中数据分页查询操作:
SELECT*FROM 表名 LIMIT 跳过的数量,显示的数量;
查询的七个关键字书写顺序:
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
LIMIT
— 先查询表里面所有的数据并进行过滤。(此时用where关键字过滤的是表里面的数据,把name为null的给过滤掉了)
— 然后进行分组,并统计每一组有多少条数据。
— 利用HAVING关键字对查询的结果再次过滤 把个数大于等于2的展示出来。
— 对having过滤之后的结果按照个数进行排序
— 最后再跳过第一个,展示两条数据
MySQL高级
约束
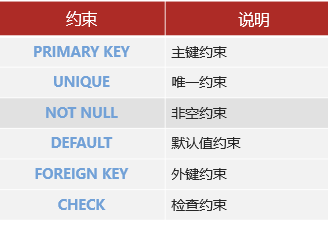
主键约束:
作用:用来区分表中的数据
特点:①主键必须是唯一不重复的值
②主键不能包含NULL值
数据库自动生成主键字段的值 
注意:AUTO_INCREMENT的字段类型必须是数值类型
例题:

其他约束:
唯一约束

默认值约束

非空约束

— 面试题: 主键是唯一和非空,普通的字段我们也可以添加唯一和非空,有区别吗?
答:
一张表只有一个主键;
一张表可以有多个唯一非空的字段。
外键约束
什么是外键:
一张表中的某个字段引用其他表的主键,这个字段称为外键。
主表: 将数据给别人用的表。
副表/从表: 使用别人数据的表。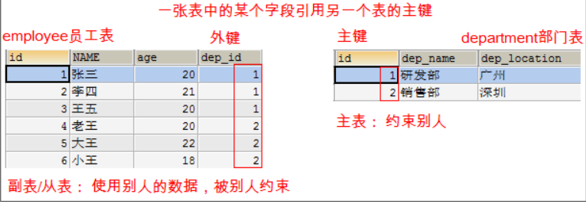

CONSTRAINT: 表示约束外键约束名: 给外键约束取个名字,将来通过约束名可以删除这个约束
FOREIGN KEY(外键字段名): 指定某个字段作为外键
REFERENCES主表(主键字段名) : 引用主表的主键的值references
在已有表添加外键约束, 外键约束可以省略: CONSTRAINT 外键约束名 (了解);
省略CONSTRAINT外键约束名 数据库会自动设置外键约束的名字,我们要到MySQL中显示框中的 3信息 中查找。
数据库设计
1.一对多实现方式:
在多的一方建立外键关联一的一方主键
2.多对多实现方式:
建立第三张中间表
中间表至少包含2个外键,分别关联双方主键
3.一对一实现方式:
在任意一方建立外键,关联对方主键,并设置外键唯一
多表查询
连接查询主要分为三种:内连接、外连接、交叉连接(交叉连接就是表连接的笛卡儿积)
多表查询的分类:
表连接查询—同时查询多张表
子查询—先查一张表, 后查另一张表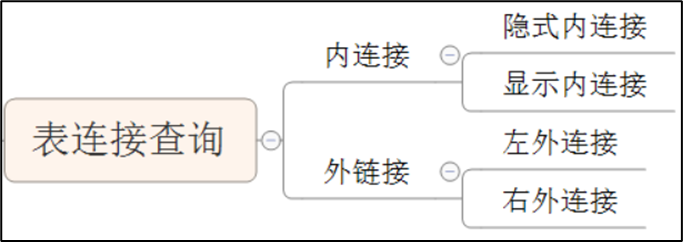
表连接查询-内连接

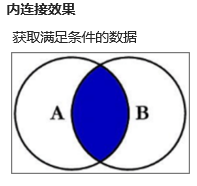
显示内连接格式:
SELECT * FROM 表1 INNER JOIN表2 ON表连接条件 WHERE查询条件;
不加条件会出现笛卡尔乘积,把所有表格乘积加到一起,所以应加上表连接条件。
表连接查询-左外连接
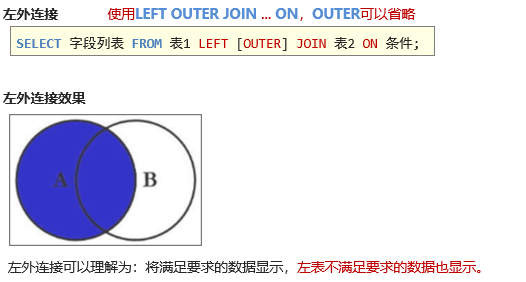
在使用显示内连接发现有缺陷时,再把起改成左外连接。
左外连接格式:
SELECT * FROM 表1 LEFT OUTER JOIN表2 ON表连接条件 WHERE查询条件;
也有右外连接:
右外连接格式
SELECT * FROM 表1 RIGHT OUTER JOIN表2 ON表连接条件 WHERE查询条件;
一般在工作中我们都使用左外, 右外可以转成左外, 我们中国人的书写顺序,从左到右。
子查询结果
子查询:一个查询语句的结果作为另一个查询语句的一部分。
子查询结果的三种情况:
1.单行单列(一个值)
2.多行单列(多个值)
3.多行多列 (虚拟的表)
子查询需要放在()中
先执行子查询,将子查询的结果作为父查询的一部分。
/* ===========子查询的结果是单行单列=========== */-- 查询工资最高的员工是谁?-- 1.查询最高工资SELECT MAX(salary) FROM tb_emp;-- 2.通过最高工资查询员工姓名SELECT NAME FROM tb_emp WHERE salary=(SELECT MAX(salary) FROM tb_emp);-- 子查询心得:建议先写好一条SQL,再复制到另一个SQL语句中/* ===========子查询的结果是多行单列的时候=========== */-- 查询工资大于5000的员工, 来自于哪些部门的名字-- 1.查询工资大于5000的员工所在部门idSELECT dept_id FROM tb_emp WHERE salary>5000;-- 2.根据部门id查找部门名称SELECT*FROM tb_dept WHERE id IN(SELECT dept_id FROM tb_emp WHERE salary>5000);/* ===========子查询的结果是多行多列=========== */-- 查询出2011年以后入职的员工信息, 包括部门名称-- 1.查询出2011年以后入职的员工信息SELECT*FROM tb_emp WHERE join_date>'2011-01-01';-- 2.找到对应的部门信息SELECT*FROM (SELECT*FROM tb_emp WHERE join_date>'2011-01-01')AS e LEFT OUTER JOIN tb_dept ON e.dept_id=tb_dept.`id`;
多表查询
-- 练习2
-- 查询所有员工信息。显示员工编号, 员工姓名, 工资, 职务名称, 职务描述, 部门名称, 部门位置
-- 1.根据需求明确查询哪些表: emp, job, dept
SELECT*FROM emp INNER JOIN job INNER JOIN dept;
-- 2.明确表连接条件去掉笛卡尔积
SELECT*FROM emp INNER JOIN job ON emp.job_id=job.id INNER JOIN dept ON emp.dept_id=dept.id;
-- 3.后续的查询
SELECT
emp.id 员工编号,
emp.ename 员工姓名,
emp.salary 工资,
job.jname 职务名称,
job.description 职务描述,
dept.dname 部门名称,
dept.loc 部门位置
FROM
emp INNER JOIN job ON emp.job_id=job.id
INNER JOIN dept ON emp.dept_id=dept.id;
-- 练习3
-- 查询经理的信息。显示员工姓名, 工资, 职务名称, 职务描述, 部门名称, 部门位置, 工资等级
-- 1.根据需求明确查询哪些表: emp, job, dept, salarygrade
SELECT *FROM emp INNER JOIN job INNER JOIN dept INNER JOIN salarygrade;
-- 2.明确表连接条件去掉笛卡尔积
SELECT *FROM emp INNER JOIN job ON emp.job_id=job.id
INNER JOIN dept ON emp.dept_id=dept.id
INNER JOIN salarygrade ON emp.salary BETWEEN salarygrade.losalary AND salarygrade.hisalary;
-- 3.后续的查询
SELECT
emp.ename 员工姓名,
emp.salary 工资,
job.jname 职务名称,
job.description 职务描述,
dept.dname 部门名称,
dept.loc 部门位置,
salarygrade.grade 工资等级
FROM
emp INNER JOIN job ON emp.job_id=job.id
INNER JOIN dept ON emp.dept_id=dept.id
INNER JOIN salarygrade ON emp.salary BETWEEN salarygrade.losalary AND salarygrade.hisalary
WHERE
job.jname='经理';
-- 练习4
-- 查询出部门编号、部门名称、部门位置、部门人数
-- 1.根据需求明确查询哪些表: emp, dept
SELECT*FROM dept INNER JOIN emp;
-- 2.明确表连接条件去掉笛卡尔积
SELECT*FROM dept LEFT OUTER JOIN emp ON emp.dept_id=dept.id;
-- 3.后续的查询
SELECT
dept.id 部门编号,
dept.dname 部门名称,
dept.loc 部门位置,
COUNT(emp.id) 部门人数
FROM
dept LEFT OUTER JOIN emp ON emp.dept_id=dept.id
GROUP BY dept.dname
ORDER BY 部门人数;
-- 练习5
-- 列出所有员工的姓名及其直接上级领导的姓名, 没有上级领导的员工也需要显示,显示自己的名字和领导的名字
-- 1.根据需求明确查询哪些表: emp pt, emp ld
SELECT*FROM emp pt INNER JOIN emp id;
-- 2.明确表连接条件去掉笛卡尔积
SELECT*FROM emp pt LEFT OUTER JOIN emp id ON pt.mgr=id.id;
-- 3.后续的查询
SELECT
pt.ename 员工姓名,
id.ename 领导姓名
FROM
emp pt LEFT OUTER JOIN emp id ON pt.mgr=id.id;
事务
事务隔离级别

read uncommitted
一个事务读取到了另一个事务中尚未提交的数据。性能最好,但是发送脏读。
(就是说第一个事务修改了数据,在没提交之前;第二个事务能读到第一个事务处理的修改)
read committed
解决了脏读,但是发生不可重复读问题,就是一个事务中两次读取的数据内容不一致。
(就是说第一个事务修改了数据,在第一个事务没提交前,第二个事务读取的数据不会变,这个解决了脏读问题;但是当第一个事务提交后,第二个事务读取的数据也发生了改变)
repeatable read
解决了不可重复读的问题,第一个事务修改数据提交,不会印象第二个事务读取的数据。
但会出现幻读:幻读就是一个事务多次读取到的数据一样,但是数据量有可能不一样。
serializeble
串行化,事务一个个处理,效率太慢了。
先开的事务,开启第二个事务执行不了,要等先开的事务先提交,第二个事务才能执行。
实践分享:企业实践工作中都不会修改数据库事务的隔离级别,推荐使用默认,为了保证并发事务的性能,如果查询数据的性能以后有缓存数据库、搜索引擎框架解决。
mysql数据库索引
首先计算机查找数据是逐个逐个查找,为了提高性能,用到数据库索引。
索引底层用的是B+Tree数据结构,简单来说这个数据结构就是通过判断大小来一层层确定数据的位置。
只要给字段名创建索引,mysql数据库会自动生成B+Tree数据结构。
主键默认是索引
1.创建索引,索引名的规范:idx表名字段名称
CREATE INDXE idx_stu_name ON stu(name);
2.创建复合索引(name,sex)
CREATE INDEX idx_stu_name_sex ON stu(name,sex);
索引失效的几种情况:

图中第二条是:%在前面不走索引,%在后面走索引。
EXPLAIN这是一个MySQL提供的查询有没有走索引的工具,在sql语句中SELECT的前面加EXPLAIN查询后,查询的结果会有一个key值,当key为null表示不走索引查询数据。
索引注意事项
索引的不足:
虽然索引大大提高了查询速度,同时却会较低更新表的速度,如对表进行INSERT、UPDATE、DELETE。因为更新表时,MySQL不仅要保存数据,还要保存更新索引文件。建立索引会占用磁盘空间的索引文件。
索引的使用原则:
1.在数据量大的表上建立索引才有意义(最起码十万级别数据才会考虑索引)
2.在经常查询的字段上使用索引
3表中数据修改频率高时,不建议建立索引(每插入、或者修改一条记录MySQL都要维护索引的顺序,这个过程不需要我们参与,但是非常消耗性能)
JDBC
JDBC:Java数据库连接。
作用:通过JDBC可以让Java程序操作数据库。
JDBC API
JDBC的使用步骤:
①注册驱动
②获取数据库连接
③获取执行SQL语句对象
④执行SQL语句并返回结果
⑤处理结果
⑥释放资源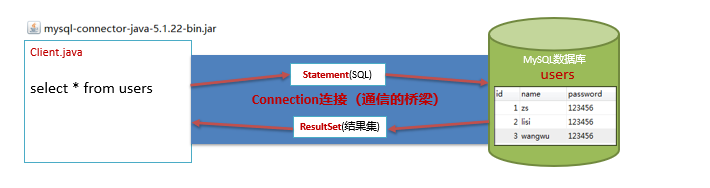
①注册驱动
DriverManager类的方法:DriverManager.registerDriver(new com.mysql.jdbc.Driver());
MySQL 5之后的驱动包,可以省略注册驱动的步骤
注册驱动,以后不用管驱动注册问题,会自动注册驱动
②获取数据库连接
1.获取Connection连接:
2.获取Statement对象: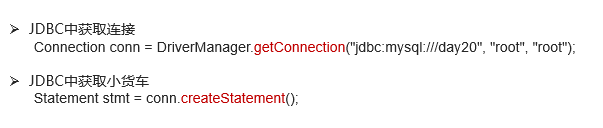
JDBC实现对单表数据增、删、改;查

增删改用:executeUpdate;查用:executeQuery
ResultSet获取数据
ResultSet的原理:
ResultSet用于保存执行查询SQL语句的结果。我们不能一次性取出所有的数据,需要一行一行的取出。
ResultSet内部有一个指针,记录获取到哪行数据。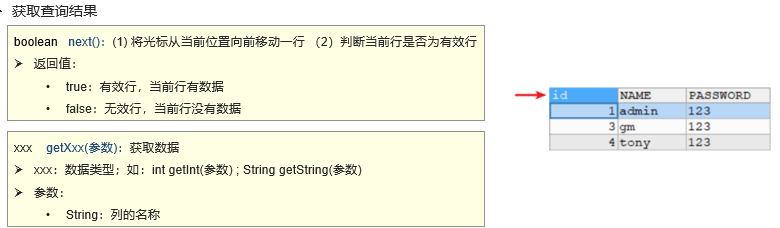

JDBC基本步骤如下代码:
?useSSL=false去除数据库警告
public class Demo02 {
public static void main(String[] args) throws SQLException {
// 1.注册驱动(自动注册)
// 2.获取Connection连接 ?useSSL=false去除数据库警告
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/day17?useSSL=false", "root", "root");
//如果连接的是本机的MySQL并且端口是3306那么可以省略localhost:3306
//Connection conn = DriverManager.getConnection("jdbc:mysql:///day17?useSSL=false", "root", "root");
// 3.获取Statement(小货车)
Statement stmt = conn.createStatement();
// 4.执行SQL语句
//stmt.executeQuery(sql):专门用于执行查询的SQL语句
String sql="DELETE FROM USER WHERE id=1";
int row = stmt.executeUpdate(sql);//执行增删改等语句
// 5.处理结果
System.out.println("影响的行数:" + row);
// 6.释放资源
stmt.close();
conn.close();
}
}
public class Demo03 {
public static void main(String[] args) throws SQLException {
// 1.注册驱动(自动注册)
// 2.获取连接
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/day17?useSSL=false", "root", "root");
// 3.获取Statement小货车
Statement stmt = conn.createStatement();
// 4.执行SQL语句
String sql = "SELECT*from user";
ResultSet rs = stmt.executeQuery(sql);
// 创建集合保存User对象
List<User> list = new ArrayList<>();
// 5.处理结果
while (rs.next()) {
int id = rs.getInt("id");
String name = rs.getString("name");
String password = rs.getString("password");
User user = new User(id, name, password);
list.add(user);
}
// 6.关闭资源
rs.close();
stmt.close();
conn.close();
}
}
用集合存放executeQuery查询出来的数据,以对象为一个单位存储。
JDBC事务
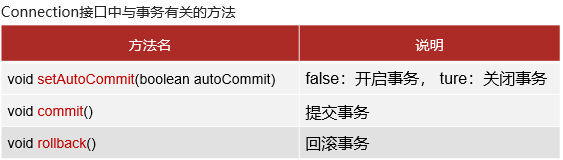
具体操作演示如下:(图为代码所需的MySQL数据)
public class Demo04 {
public static void main(String[] args) {
Connection conn=null;
Statement stat=null;
// 1.注册驱动(自动注册)
// 2.获取连接
try {
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/day17?useSSL=false", "root", "root");
// 3.开启事务, false表示开启事务
conn.setAutoCommit(false);
// 4.获取到Statement
stat = conn.createStatement();
// 5.Statement执行SQL
// 张三-500
stat.executeUpdate("UPDATE account SET balance=balance-500 where id=1;");
// 李四+500
stat.executeUpdate("UPDATE account SET balance=balance+500 where id=2;");
// 6.成功提交事务
conn.commit();
System.out.println("成功提交事务");
} catch (Exception throwables) {
// 6.失败回滚事务
try {
conn.rollback();
System.out.println("失败回滚事务");
} catch (SQLException e) {
e.printStackTrace();
}
}finally {
try {
stat.close();
conn.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
}
SQL 注入攻击
简单来说,当我们在SQL语句中输入命令时,Statement对象在执行SQL语句时,会将一部分内容当做查询条件来执行;所有我们用PreparedStatement预编译执行者对象来解决问题。
PreparedStatement作用:
1.预编译:SQL语句在执行前就已经编译好了,执行速度更快;
2.安全性更高:没有字符串拼接的SQL语句,所以避免SQL注入的问题;
3.代码的可读性更好,因为没有字符串拼接。
实例如下:
public class Demo06 {
public static void main(String[] args) throws SQLException {
// 1.获取连接
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/day17?useSSL=false", "root", "root");
// 2.编写参数化SQL(带?的SQL语句)
String sql="INSERT INTO user VALUES (NULL,?,?);";
PreparedStatement pstmt = conn.prepareStatement(sql);
// 3.给?赋值 pstmt.setXxx(第几个?, ?的具体值)
pstmt.setString(1,"gm");
pstmt.setString(2,"123");
// 4.执行
int row = pstmt.executeUpdate();//前面已经处理好了SQL语句,这里执行
System.out.println("影响的行数:"+row);
// 5.释放资源
pstmt.close();
conn.close();
}
}
JDBC实现登录案例

public class Demo7 {
public static void main(String[] args) throws SQLException {
// 1.使用数据库保存用户的账号和密码
// 2.让用户输入账号和密码
Scanner sc = new Scanner(System.in);
System.out.println("请输入账号:");
String name = sc.next();
System.out.println("请输入密码:");
String password = sc.next();
// 3.使用SQL根据用户的账号和密码去数据库查询数据
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/day17?useSSL=false", "root", "root");
String sql="SELECT * FROM user where name =? and password=?;";
PreparedStatement pstmt = conn.prepareStatement(sql);
//给?赋值
//pstmt.setString(第几个?,?的具体值);
pstmt.setString(1,name);
pstmt.setString(2,password);
//执行
ResultSet rs = pstmt.executeQuery();//这里不需要再给SQL语句
if (rs.next()){
// 4.如果查询到数据,说明登录成功
System.out.println("恭喜您,"+name+"登录成功!");
}else{
// 5.如果查询不到数据,说明登录失败
System.out.println("登录失败,账号或密码错误!");
}
// 6.关闭资源
rs.close();
pstmt.close();
conn.close();
}
}
数据库连接池
获取数据库连接需要消耗比较多的资源,数据库连接对象的使用率低;数据库连接池的连接可以重复使用,降低数据资源的消耗。像类似于线程池。
常用的连接池实现组件有以下这些:
1.阿里巴巴-德鲁伊Druid连接池:Druid是阿里巴巴开源平台上的一个项目
2.C3P0是一个开源的连接池,目前使用它的开源项目有Hibernate,Spring等。
3.DBCP(DataBase Connection Pool)数据库连接池,是Tomcat使用的连接池组件。
Druid 数据库连接池
Druid是阿里巴巴开发的号称为监控而生的数据库连接池,Druid是目前最好的数据库连接池。
Druid常用的配置参数:
Druid连接池使用步骤:
1.导入druid-1.0.0.jar的jar包
2.复制druid.properties文件到src下,并设置对应参数
3.加载properties文件的内容到Properties对象中
4.创建Druid连接池,使用配置文件中的参数
5.从Druid连接池中取出连接
6.执行SQL语句
7.关闭资源
能够使用Driud数据库连接池获取Connection对象
Properties pp = new Properties();
pp.load(new FileReader(“study_day17\src\druid.properties”));
// 创建Druid连接池,使用配置文件中的参数
DataSource ds = DruidDataSourceFactory.createDataSource(pp);
//从Druid连接池中取出连接
Connection conn = ds.getConnection();
将Druid连接池生成工具类,方便获取与数据库的连接:
生成工具类代码如下:
首先设置好properties文件: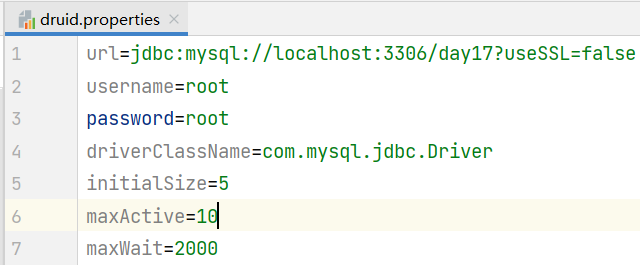
// 连接池的工具类, 抽取创建连接池的代码
public class DataSourceUtils {
// 保存一个连接池
private static DataSource ds;
// 静态代码块可以给静态成员变量赋值
static {
try {
Properties pp = new Properties();
pp.load(new FileReader("study_day17\\src\\druid.properties"));
// 4.创建Druid连接池,使用配置文件中的参数
ds = DruidDataSourceFactory.createDataSource(pp);
} catch (Exception e) {
e.printStackTrace();
}
}
// 提供一个方法返回连接池从的连接, 异常抛给调用者,让调用者去处理异常
public static Connection getConnection() throws SQLException {
// 从连接池中取一个连接并方法
return ds.getConnection();
}
}

若有收获,就点个赞吧
0 人点赞
