概念
堆(Heap)的定义:
- 一颗完全二叉树。
- 堆中的每个节点的值都必须大于等于(或小于等于)其左右子节点的值。大于等于的叫做大顶堆,小于等于的叫做小顶堆。
堆的存储:由于堆是完全二叉树,所以用数组存储是最适合的,非常节约内存。
插入
先把插入的元素放到堆的最后,此时就不满足堆的定义了。我们就要进行调整,这个过程叫做堆化(heapify)。
插入后,我们需要做从下往上堆化。就是让插入节点与父节点对比,若不满足大小关系,则交换,一直重复这个过程。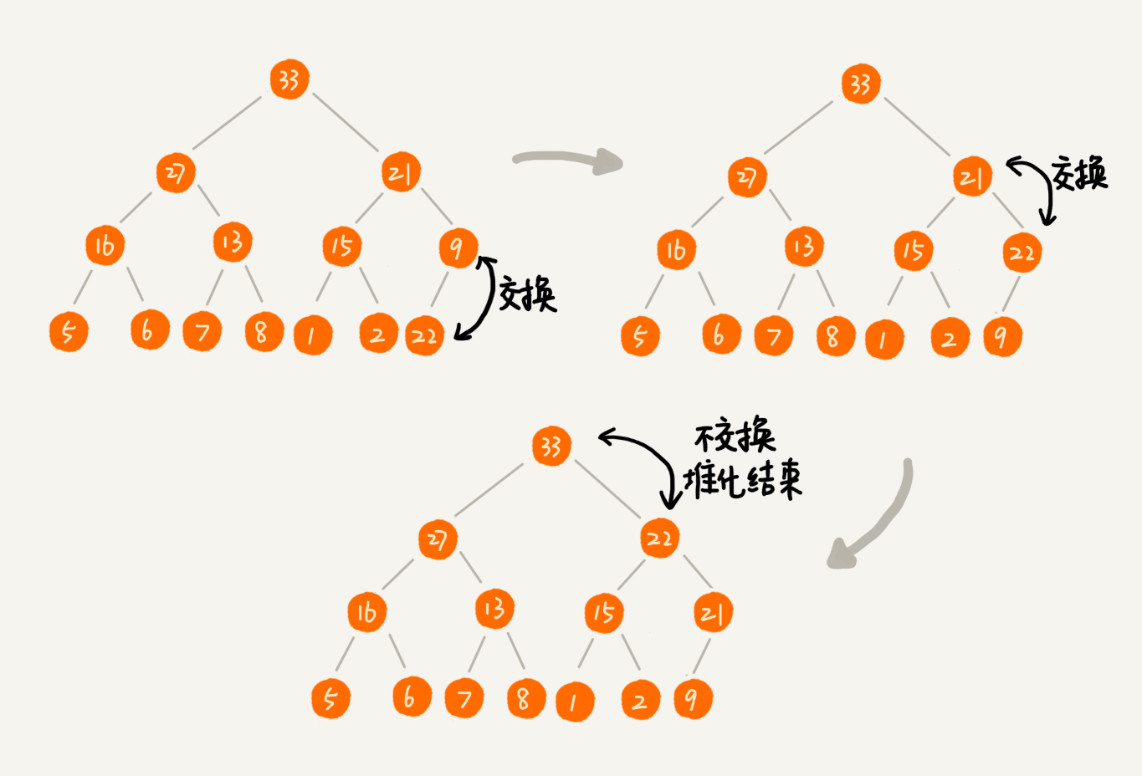
public class Heap {private int[] a; // 数组,从下标1开始存储数据private int n; // 堆可以存储的最大数据个数private int count; // 堆中已经存储的数据个数public Heap(int capacity) {a = new int[capacity + 1];n = capacity;count = 0;}public void insert(int data) {if (count >= n) return; // 堆满了a[++count] = data;int i = count;while (i/2 > 0 && a[i] > a[i/2]) { // 自下往上堆化swap(a, i, i/2); // swap()函数作用:交换下标为i和i/2的两个元素i = i/2;}}}
删除堆顶元素
删除堆顶元素后,把最后一个元素挪到堆顶,然后再进行从上往下堆化。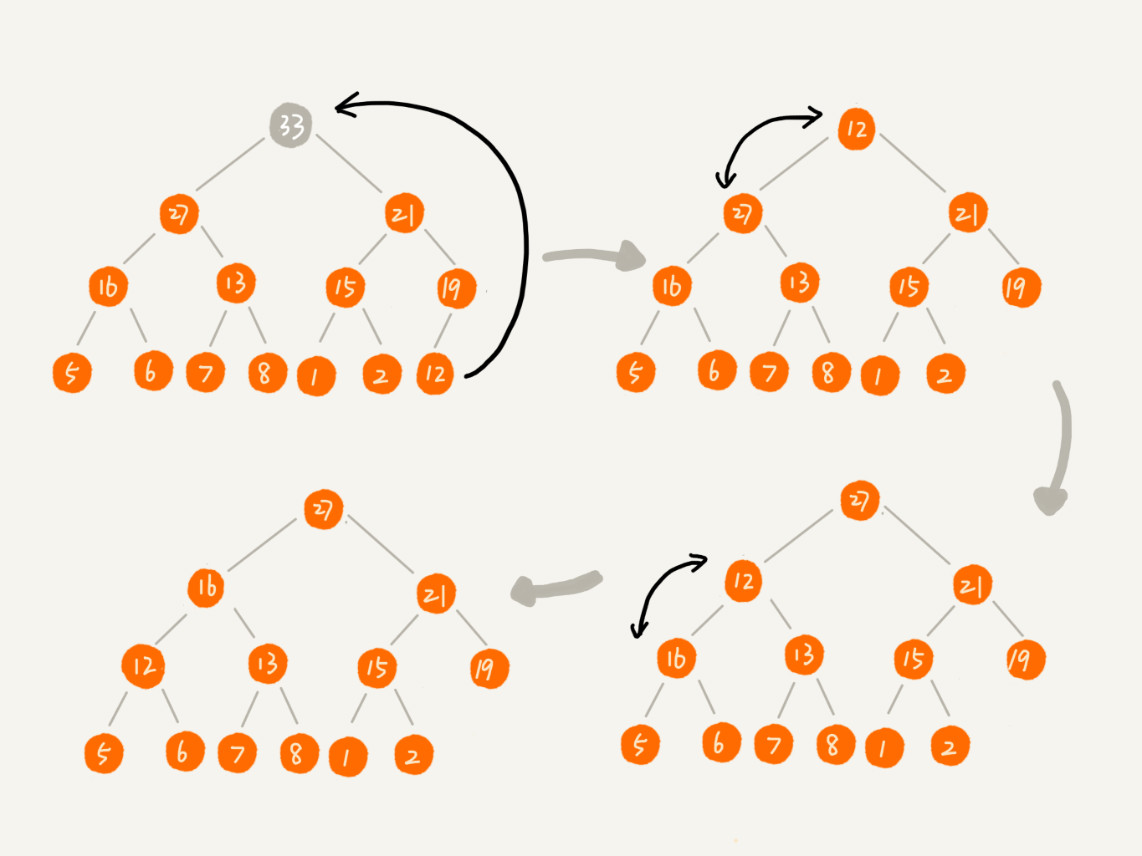
public void removeMax() {if (count == 0) return -1; // 堆中没有数据a[1] = a[count--];heapify(a, count, 1);}private void heapify(int[] a, int n, int i) { // 自上往下堆化while (true) {int maxPos = i;if (i*2 <= n && a[i] < a[i*2]) maxPos = i*2;if (i*2+1 <= n && a[maxPos] < a[i*2+1]) maxPos = i*2+1;if (maxPos == i) break;swap(a, i, maxPos);i = maxPos;}}
/
完全二叉树的高度不会超过 log2n,所以插入数据和删除堆顶元素的时间复杂度为 O(logn)。
堆排序
堆排序时间复杂度为 O(nlogn),原地排序。有建堆和排序两个步骤。
建堆
建堆就是将数组原地建成一个堆。有两种思路。
思路一:类似插入排序,将数组分成两个部分,前半部分已经组成堆,然后依次把后半部分的数据插入堆中。是从前往后处理数据,从下往上堆化的过程。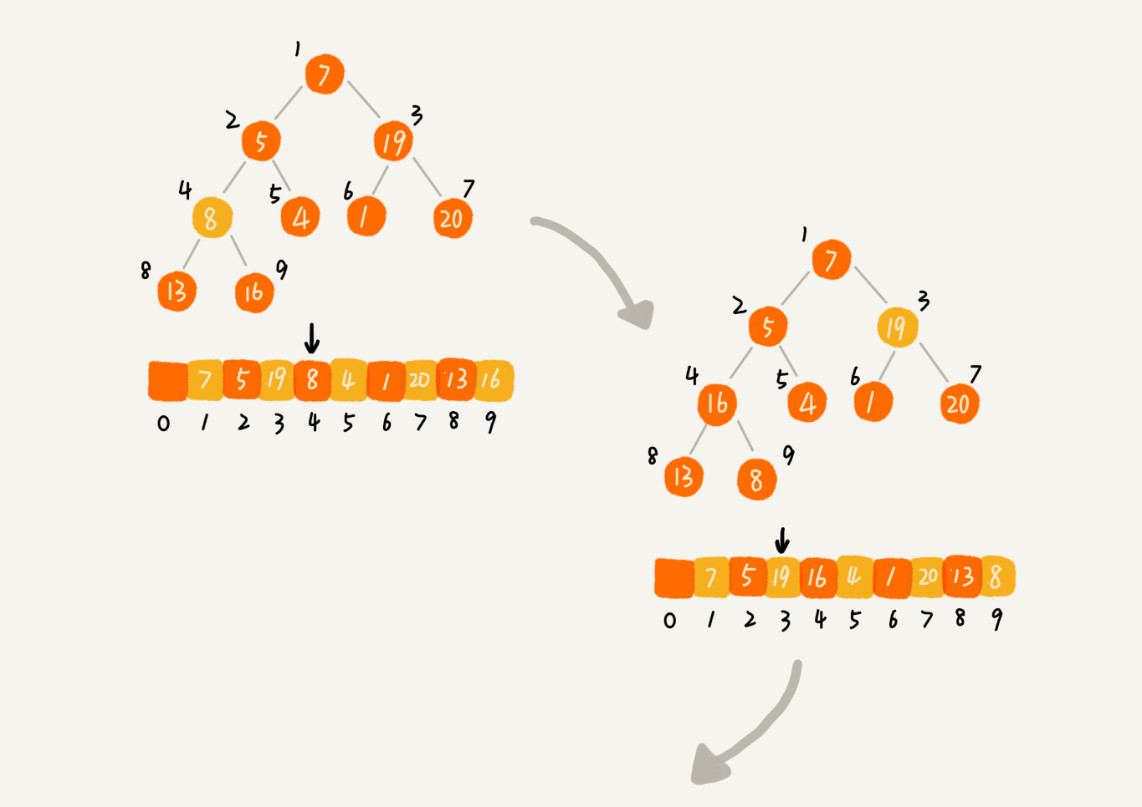
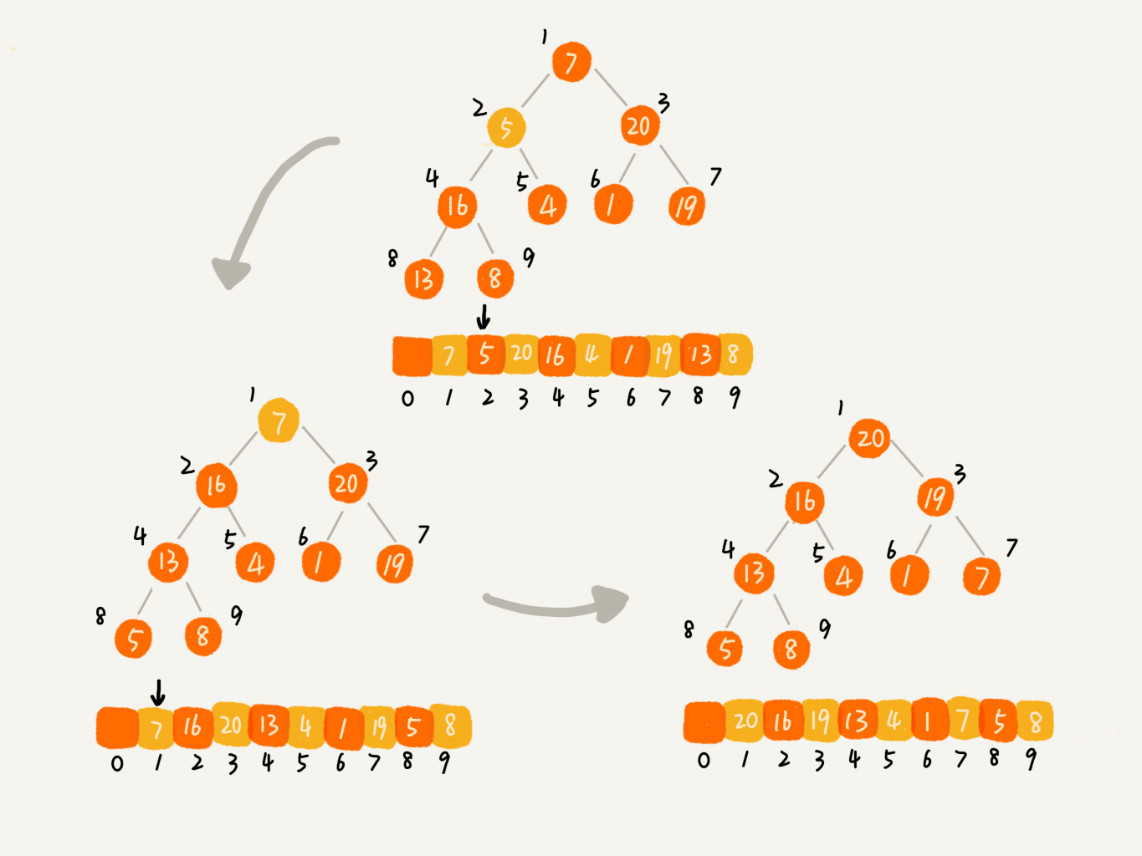
private static void buildHeap(int[] a, int n) {for (int i = n / 2; i >= 1; --i) {heapify(a, n, i);}}private static void heapify(int[] a, int n, int i) {while (true) {int maxPos = i;if (i * 2 <= n && a[i] < a[i * 2]) {maxPos = i * 2;}if (i * 2 + 1 <= n && a[maxPos] < a[i * 2 + 1]) {maxPos = i * 2 + 1;}if (maxPos == i) {break;}swap(a, i, maxPos);i = maxPos;}}
思路二:是从后往前处理数据,从上往下的堆化的过程。叶子节点往下没有数据,所以直接从非叶子节点开始处理。
思路二建堆的时间复杂度为 O(n)。如下图,右边的每一项求和即可。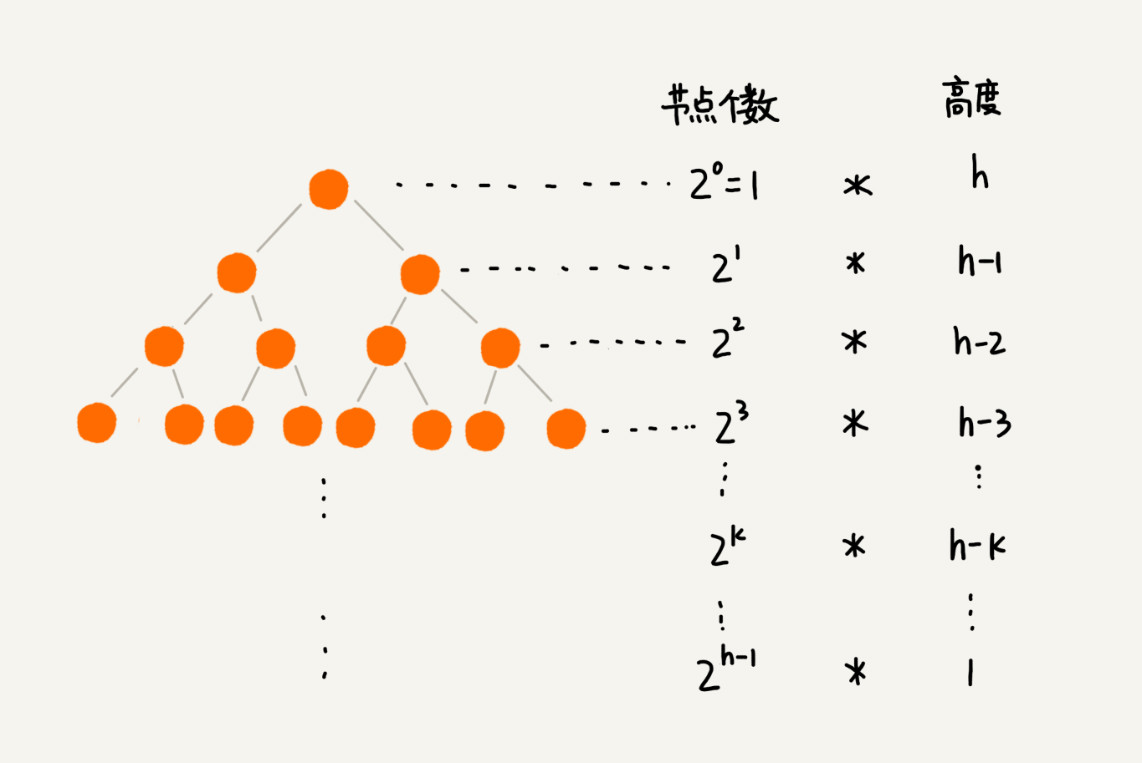
排序
以大顶堆为例,依次做上节的删除堆顶元素操作,得到的结果就是从小到大的排序数组。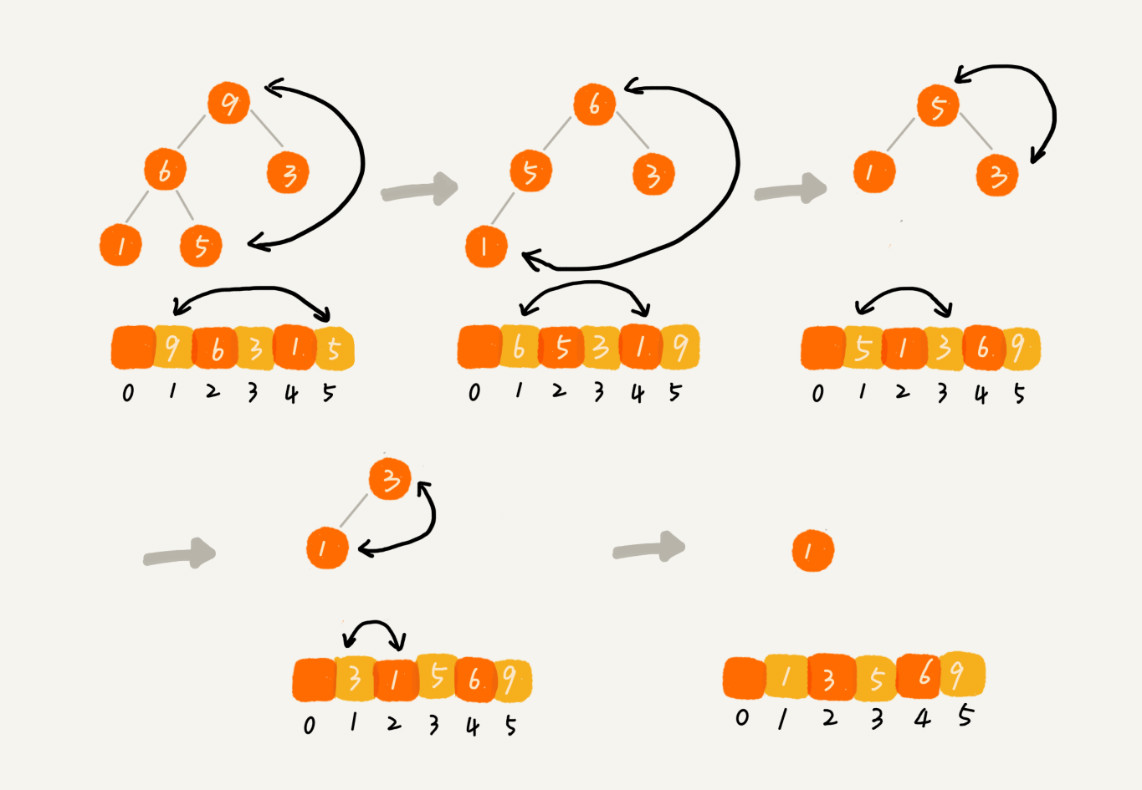
// n表示数据的个数,数组a中的数据从下标1到n的位置。
public static void sort(int[] a, int n) {
buildHeap(a, n);
int k = n;
while (k > 1) {
swap(a, 1, k);
—k;
heapify(a, k, 1);
}
}
建堆为 O(n),排序为 O(nlogn),所以堆排序时间复杂度为 O(nlogn)。是原地排序,不是稳定排序,因为将最后一个元素与堆顶元素互换。
为什么快排比堆排序性能好?
- 快排访问数组是连续的,堆排序是跳着访问的,所以快排堆 CPU 缓存更加友好。
堆排序的交换次数大于快排。快排交换次数不会大于逆序度,但是堆排序建堆过程会打乱原有顺序,增加逆序度。
堆的应用
优先级队列
优先级队列中,数据的出队顺序不是先进先出,而是按照优先级来,优先级最高的最先出队。
用堆实现优先级队列最直接,往优先级队列插入一个元素即往堆中插入一个元素。从队列中取出优先级最高的元素即从堆中取出堆顶元素。
优先级队列的应用非常广泛,这里举两个例子。
合并有序小文件
假设有 100 个小文件,每个 100MB,每个文件都是有序的,要求把这 100 个小文件合并成一个大文件。
思路类似归并排序的归并操作,从 100 个文件中都取出第一个元素组成大小为 100 的优先级队列,也就是堆。然后从堆中取出堆顶元素放入大文件中,再从堆顶元素对应的小文件中取出下一个元素插入堆中。循环这个过程,就合并成了一个大文件。
高性能定时器
假设有一个定时器,维护了很多定时任务,每个任务都有一个时间触发点。简单的实现:定时器每隔一段小时间就扫描一遍任务,如果有任务到达了时间就执行。此方法有两点低效:每次要扫描所有任务;如果下个任务还要很久,那么就要做很多次无用的扫描。
高效的实现:用优先级队列来解决,任务都放入优先级队列中,拿到堆顶的任务与当前时间比较,得到时间间隔 T,所以只需要直接 T 以后来执行堆顶任务就行;然后删除堆顶元素,与新的堆顶元素比较得到新的时间间隔。
求 Top K
求 Top K 有两种类型,静态数据(数据集合不会再变)和动态数据(有数据动态加入集合中)。
静态数据:维护一个大小为 K 的小顶堆,遍历数据,往堆中插入元素,若比堆顶元素大,则删除堆顶元素,把这个元素插入堆中,遍历完成后,堆中的元素就是 Top K。
- 动态数据:同样也是维护一个大小为 K 的小顶堆,当有数据添加进集合时,也对堆做比较操作。这样无论何时想要 Top K,只要返回堆中的数据即可。
求中位数
求动态数据中的中位数(处在中间位置的那个数)。
维护两个堆,一个大顶堆,一个小顶堆。大顶堆存储前半部分数据,小顶堆存储后半部分数据,两个堆的堆顶就是中位数。
关键是插入数据时怎么调整两个堆。如果小于大顶堆堆顶,则插入到大顶堆中;如果大于小顶堆堆顶,则插入小顶堆中。然后通过将一个堆的堆顶元素移至另一个堆来保持两个堆的大小均衡。
拓展一下,不仅可以求中位数,还能求任意百分位数据。比如接口 99% 响应时间。

若有收获,就点个赞吧
0 人点赞
