概述
LinkedHashMap是通过哈希表和链表实现的,它通过维护一个链表来保证对哈希表迭代时的有序性,而这个有序是指键值对插入的顺序。另外,当向哈希表中重复插入某个键的时候,不会影响到原来的有序性。
LinkedHashMap的实现主要分两部分,一部分是哈希表,另外一部分是链表。哈希表部分继承了HashMap,拥有了HashMap那一套高效的操作。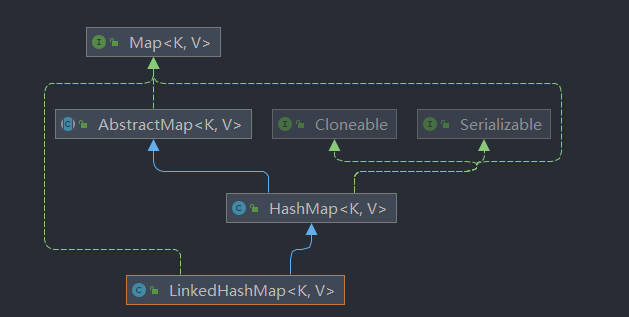
从图中可知,LinkedHashMap 是继承自 HashMap 的,所以它已经从 HashMap 那里继承了与哈希表相关的操作了
LinkedHashMap的属性
static class Entry<K,V> extends HashMap.Node<K,V> {Entry<K,V> before, after;Entry(int hash, K key, V value, Node<K,V> next) {super(hash, key, value, next);}}private static final long serialVersionUID = 3801124242820219131L;/*** 双链接列表中的头(最年长的)。*/transient LinkedHashMap.Entry<K,V> head;/*** 双链接列表的尾部(最年轻的)。*/transient LinkedHashMap.Entry<K,V> tail;/*** 此链接哈希映射的迭代排序方法:访问顺序为true,插入顺序为false。* @serial*/final boolean accessOrder;
可以发现:LinkedHashMap的链表节点继承了HashMap的节点,而且每个节点都包含了前指针和后指针,所以这里可以看出它是一个双向链表.
transient LinkedHashMap.Entry
transient LinkedHashMap.Entry
LinkedhashMap的一些方法
在HashMap源码中有这三个空的方法,其实这三个方法表示的是在访问、插入、删除某个节点之后,进行一些处理,它们在LinkedHashMap都有各自的实现。LinkedHashMap正是通过重写这三个方法来保证链表的插入、删除的有序性。
- _void _afterNodeAccess(Node
- _void _afterNodeInsertion(_boolean _evict)
- _void _afterNodeRemoval(Node
afterNodeAccess()
移动节点到尾部
就是把当前节点e移至链表的尾部。因为使用的是双向链表,所以在尾部插入可以以O(1)的时间复杂度来完成。并且只有当accessOrder设置为true时,才会执行这个操作。
void afterNodeAccess(Node<K,V> e) { // move node to lastLinkedHashMap.Entry<K,V> last;//当accessOrder的值为true,且e不是尾节点if (accessOrder && (last = tail) != e) {LinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;p.after = null;if (b == null)head = a;elseb.after = a;if (a != null)a.before = b;elselast = b;if (last == null)head = p;else {p.before = last;last.after = p;}tail = p;++modCount;}}
afterNodeInsertion()
afterNodeInsertion方法是在哈希表中插入了一个新节点时调用的,它会把链表的头节点删除掉,删除的方式是通过调用HashMap的removeNode方法。
void afterNodeInsertion(boolean evict) { // possibly remove eldestLinkedHashMap.Entry<K,V> first;if (evict && (first = head) != null && removeEldestEntry(first)) {K key = first.key;removeNode(hash(key), key, null, false, true);}}
afterNodeRemoval()
当HashMap删除一个键值对时调用的,它会把在HashMap中删除的那个键值对一并从链表中删除,保证了哈希表和链表的一致性。
void afterNodeRemoval(Node<K,V> e) { // unlinkLinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;p.before = p.after = null;if (b == null)head = a;elseb.after = a;if (a == null)tail = b;elsea.before = b;}
get()
get()方法,它调用的是HashMap的getNode方法来获取结果的
public V get(Object key) {Node<K,V> e;if ((e = getNode(hash(key), key)) == null)return null;if (accessOrder)afterNodeAccess(e);return e.value;}
结论
LinkedHashMap相对于HashMap,增加了双链表的结果(即节点中增加了前后指针),其他处理逻辑与HashMap一致,同样也没有锁保护,多线程使用存在风险。

若有收获,就点个赞吧
0 人点赞
