buffer pool中的lru淘汰算法
- 缓存页不够的话,需要淘汰一些缓存页。淘汰缓存页就是把在缓存页中修改的数据刷回磁盘中,
变为一个空闲的缓存页。 - lru链表是来表示缓存页使用的频率。当数据从磁盘加载到缓存页时,就把这个缓存页的描述快放在lru链表的头部。一次类推。这种lru链表的尾部就是当前使用量最低的。需要释放缓存页的时候就从取lru链表尾部的节点释放。
free链表,flush链表,lru链表都是buffer pool中的结点,都是描述数据块。
lru算法的弊端预读机制带来的弊端。mysql的预读机制指的是当你在磁盘加载数据页的时候,可能会连带把这个数据页相邻的其他数据页也加载到缓存页里。
- 这样在执行lru算法的时候,头部可能有一个被预读进来的缓存页,这个缓存页还没有被使用。却把尾部可能经常使用的淘汰掉了。这样是不合理的。
mysql预读机制的触发条件
① innodb_read_ahead_threshold.默认56.顺序访问一个区的多个缓存页,超过这个阈值,就会触发预读机制,将下一相邻所以数据页加载到缓冲区内
② innodb_random_read_ahead. 默认off.如果buffer pool连续缓冲了一个区内的13个数据页。会把整个区都加载到缓冲区中。
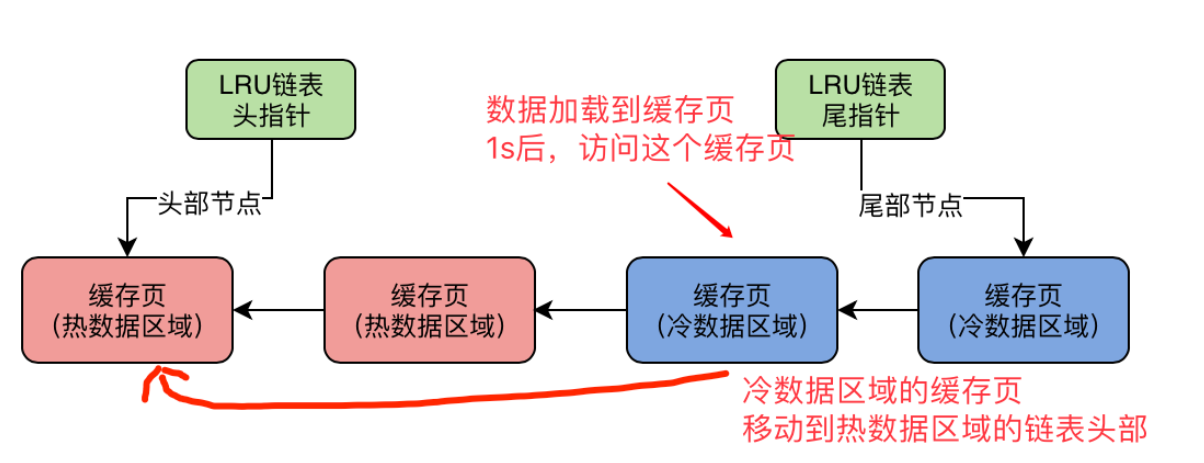
冷热数据分离结构优化lru算法为了减少预读机制带来的避短,采用冷热数据分离结构来设计lru链表。
- lru链表被设计成为存放冷数据和热数据两部分。比例通过innodb_old_blocks_pct控制,默认37%。冷数据占37%。
- 数据页第一次被加载到缓存的时候,缓存页放在冷数据的头部。在innodb_old_bloacks_time的时间后被访问,该缓存页就挪到热数据区域。innodb_old_bloacks_time 默认1000ms。
场景题
- 如果redis中存的有经常被访问的数据和不经常被访问的数据,怎么样基于冷热数据的结构优化。
常见场景是电商商品的缓存数据,经常被访问的数据就是热数据,不常被访问的数据是冷数据。
每天统计出来哪些商品被访问的次数最多,晚上启动一个定时任务,统计出热门商品预加载到redis中,第二天对热门商品的访问就会走redis缓存了。
lru冷热结构的热数据区域是怎么优化的

若有收获,就点个赞吧
0 人点赞
