千万级用户场景下的运营系统SQL调优
- 现在有场景,用户表存放基础用户信息,用户扩展表,存放用户扩展信息,背景是根据挑选筛选出特定的用户,push信息,用户日活百万计,注册用户千万级。
想查询最近登陆的用户sql语句:select id,name from users where id in (select user_id from users_extent_info where latest_login_time < xxxx). 一般这种sql会先跑聚合sql,比如sql,select count(id) from users where id in (select user_id from users_extent_info where latest_login_time < xxxx),如果小于1000,直接读取,过多的话就limit读取,这种sql对于千万级的表来说执行时间过长。
explain结果
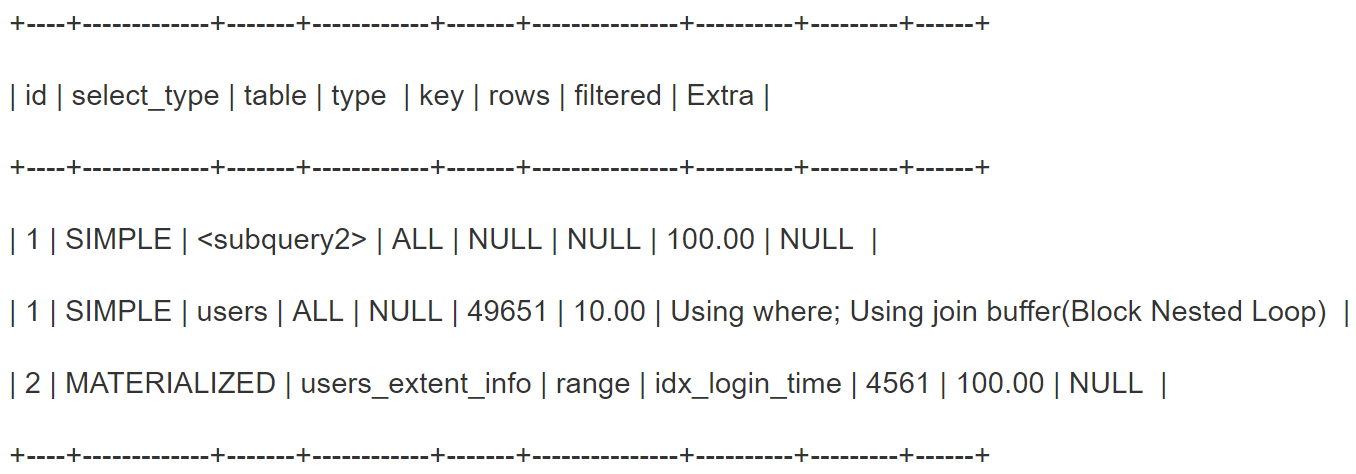
explain显示 users_extend_info的idx_login_time走了索引,MATERIALIZED成了物化表,落到磁盘上了,第二条显示扫描了users全表,并执行了join操作;第一条显示对子查询的物化表做了全表扫描,因为join操作让users的每一条数据都跟物化表做了匹配。
- 为什么会执行join操作,用show warnings命令看到sql内部将in优化成了semi join。semi join 对users表中的数据跟物化表做匹配。
优化查询条件上增加无效条件or。原因是mysql对什么样的子查询支持半连接优化,其中一条是子查询位于where/join-on子句中,且首层不存在or/not操作。
亿级数据量商品系统的SQL调优
背景,mysql数据库选择索引的时候,选择了一个不大合适的索引,导致性能很差引发慢查询。
- 假设sql语句select * from products where category = ‘xx’ and sub_category = ‘xx’ order by id desc limit xx,xx.在亿级数据中正常是很快的。出现了执行几十秒的情况。这种可能情况是没用到查询的索引。
执行计划中possible_key有index_category,但是用到的索引是PRIMARY。导致查询很慢的原因是在主键的聚簇索引上扫描,边扫描边用where字段筛选。为了解决这个问题,需要强制走index_category索引,sql语句要改成
select from products *force index(index_category) where category = ‘xx’ and sub_category = ‘xx’.
为什么会出现扫描不合适的索引的情况,mysql判断,亿级数据二级索引index_category的量也很大,先扫二级索引排序再回表和直接扫描主键索引差不多,可以按数据直接读取,这样是没问题的。 问题出在如果走主键索引的话,where category = ‘xx’ and sub_category = ‘xx’ 查询不到数据,就会导致全表扫描。
数十亿数量级评论系统调优
十亿级数据量,进行分库分表,一个商品的评论都是放在一个库的一张表里。针对一个商品几十万评论的深分页问题。
- 假设有sql语句select * from comments where product_id = ‘xx’ and is_good_comment = ‘1’ order by id desc limit 100000,20,意思是查某个商品的好评。这个核心索引是index_product_id,查询is_good_comment还需要回表,如果数据量有几十万次,可能需要做几十万次回表操作。
- 优化思路跟之前强制走二级索引反过来,上一个案例走二级索引不需要回表是因为查询的结果覆盖了索引,不需要回表。这次要减少回表操作,修改sql为
select * from comments a,(select id from comments where product_id = ‘xx’ and is_good_comment = ‘1’ order by id desc limit 100000,20 ) b where a.id = b.id.
先拿到符合数据的id,然后根据这个id去聚簇索引里查找完整的数据。

若有收获,就点个赞吧
0 人点赞
