一
- const:例如select * from table where id = X.这样通过聚簇索引或者通过二级索引+聚簇索引回表查到数据的,这种效率很高。有个条件,二级索引必须是唯一索引才属于const方式。
- ref:如果是普通二级索引,查询叫做ref。如果包含很多个列的普通索引,必须从最左侧开始连续多个列都是等值比较才能叫ref。如果查询语句中有name is null,即使name是主键或者唯一索引,也只能是ref,在name允许为null的情况下。
ref_or_null:如果一个二级索引同时比较了一个值还有限定了is null,执行计划叫ref_or_null.
二
range:范围查询。例如select * from table where age >=x and age <=x.
- index:index并不是直接走索引,假设表内有索引字段KEY(x1,x2,x3),sql语句为select x1,x2,x3 from table where x2=xxx.这样查询因为x2不是联合索引最左侧的字段,所以无法直接走索引,但是要查询的字段就是联合索引字段,索引树的聚簇索引节点存放的是完整的数据页,联合索引的节点存放的是x1,x2,x3和主键的值。针对这种查询,会直接遍历key(x1,x2,x3),不需要回源到聚簇所声音,这种方式叫index。
- intersection,union交集:查完多个索引后进行合并。
-
不同的SQL语句,会执行什么样的执行计划
sql语句select * from table where x1=xx and x2 >=xx.如果索引不是(x1,x2),此时只能选择一个索引去用,会选择哪一个,根据mysql负责生成执行计划的查询优化器,一般会选择索引在扫描行数比较少的条件,比如x1=xx,查的比较少,根据x1查出数据加载到内存,再根据x2筛选。
如果用到多个二级索引,例如sql select * from table where x1=xx and x2=xx.x1和x2分别有一个索引,有一种情况是先对x1字段的索引树进行查找,接着对x2的索引树查出一波数据,再对两波数据根据主键值做一个交集。另一种情况就是先根据x1查出数据,再回表查询,查询出的结果用另一个字段过滤。
多表关联的sql语句的执行计划
如果sql为select * from t1,t2 where t1.x1=xxx and t1.x2 = t2.x2 and t2.x3=xx.sql的执行计划可能是先根据 t1.x1= xxx 查出一波数据,再根据这波数据去另一个表筛选出符合条件的数据。 先从一个表里查一波数据,这个表叫做”驱动表”。
- 内连接:两个表里的数据必须是完全能关联上的,才能返回回来。
- 左连接:返回左表的全部数据和右表符合条件的数据。
- 右连接:返回右表的全部数据和左表符合条件的数据。
嵌套循环关联:先去驱动表里根据where筛选条件找出一部分数据,再循环这部分数据,去另一个驱动表里根据on连接和where条件查找数据,如果没有加索引得话非常耗时。尽量将表都加上索引。
mysql如何根据成本优化执行计划
mysql中的成本一般分为两块,一块是将数据从磁盘中读到内存中,叫IO成本,一个数据页的成本约定为1.0.一块是拿到数据后对数据做运算,叫CPU成本,一条数据是0.2.
- 全表扫描的成本如何计算:命令 show table status like ‘表名’。可以拿到统计信息rows和data_length。rows是表中记录数,data_length是表的聚簇索引的字节数大小。用data_length/1024/16kb就是有多少页。
- 索引扫描的成本计算:分两种,直接根据主键查和先根据二级索引再回表查询。如果是先根据二级索引,就是先在二级索引里根据条件查一波数据的IO成本,然后再加上回表到聚簇索引里查询完整数据的成本。
多表关联查询的成本计算和执行计划,先选择驱动表,如果有多个索引会根据不同的索引计算成本,选择一个成本最低的方法。
mysql如何基于各种规则去优化执行计划
mysql在执行sql语句的时候,可能会对一些较为复杂的sql语句做优化,比如删掉一些无关紧要的括号,或者做常量值替换。
- 子查询如何执行,如何优化。select from t1 where x1 =(select x1 from t2 where id = xxx).先执行子查询,根据主键定位出x1的值,再执行select from t1 where x1 =xxx.
sql语句select * from t1 where x1 in (select x2 from t2 where x3 = xxx).一般会认为先执行子查询,再对t1表进行全表扫描,再判断每条数据是否在这个子查询的结果集里。这种查询会被优化为先执行子查询,将子查询查出来的数据写入临时表里,临时表也会建立索引,此时要么是全表扫描t1表,看判断是否在临时表中,如果t1表数据很多,会很耗时,可以反过来扫描临时表,将临时表数据值到t1表里根据x1字段的索引进行查找,查找物化表的值是否在t1的索引树中。
explain命令得到的SQL执行计划
执行explain select * from table语句可以得到

id:每个select对应一条id;
select_type:这一条执行计划对应的查询时什么类型
table:表名
type:针对这个表的访问方法,比如const,ref,range,index,all
possible_keys:type确定访问方式,possible_keys是可选择的索引
ref:某个字段的索引进行等值匹配搜索的时候,跟索引列进行等值匹配的目标值的信息
refs:读取多少条数据
filtered:经过搜索条件过滤后的剩余数据百分比
extra:额外的信息
- 例如explain select * from t1
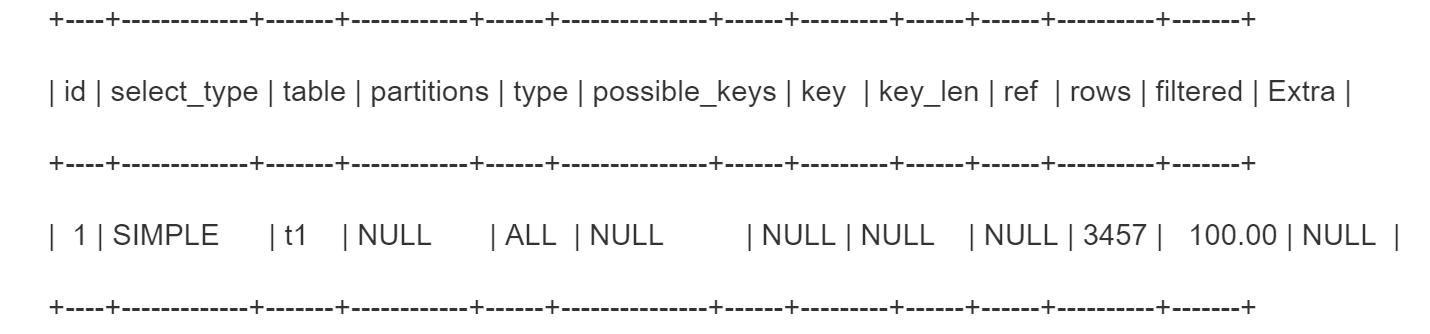
全表扫描t1,共3457条数据
explain select * from t1 join t2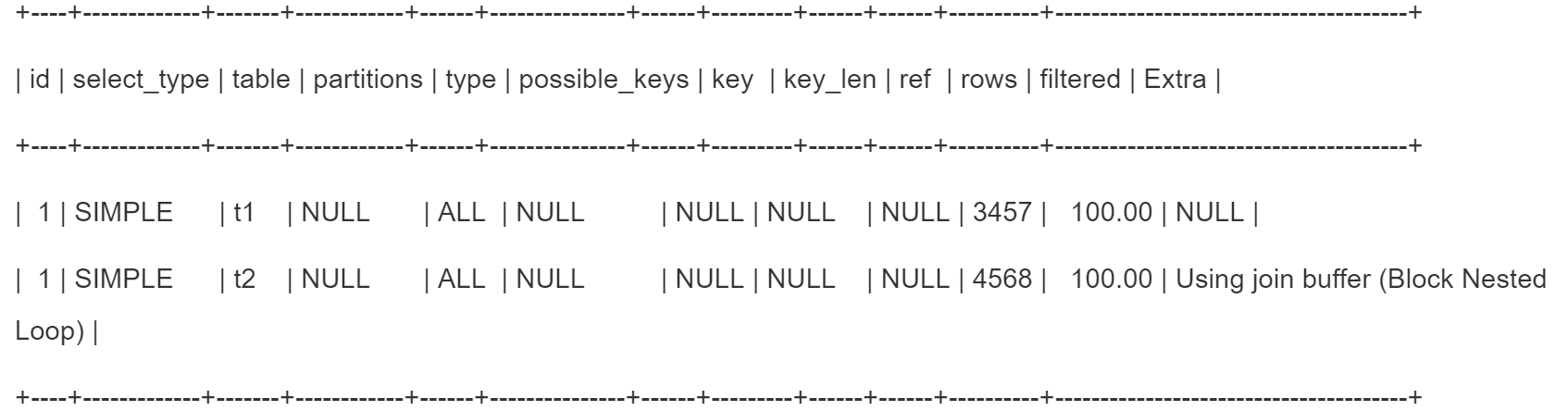
先全表扫描t1,共3456条数据,再全表扫描t2,采用笛卡尔积的方式,t1表中的每一条数据都去匹配t2表里的每一条数据。id=1,因为只有一个select查询
- explain select * from t1 where x1 in(select x1 from t2) or x3 = ‘xxx’
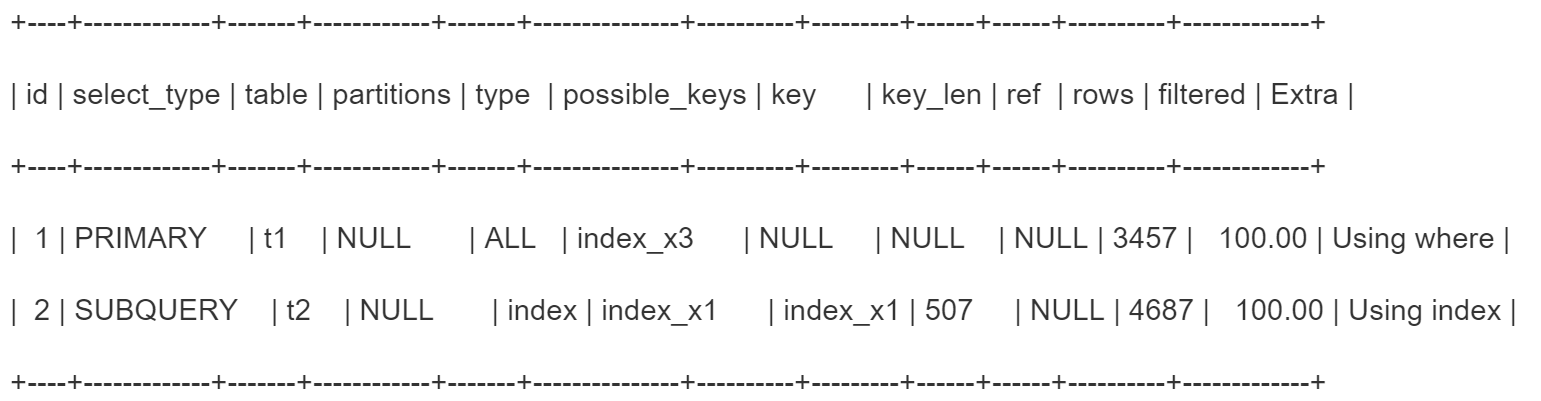
主查询的selectId=1,子查询的selectId=2。主查询中因为x3 = ‘xxx’,可能用到的索引是index_x3,但是type=all,说明放弃了索引,走全表扫描。
子查询本来就是全表扫描,但是对主查询而言,会使用x1 in这个筛选条件,用到了索引,用index_x1的索引树跟子查询结果集做对比。
- explain select from t1 union select from t2
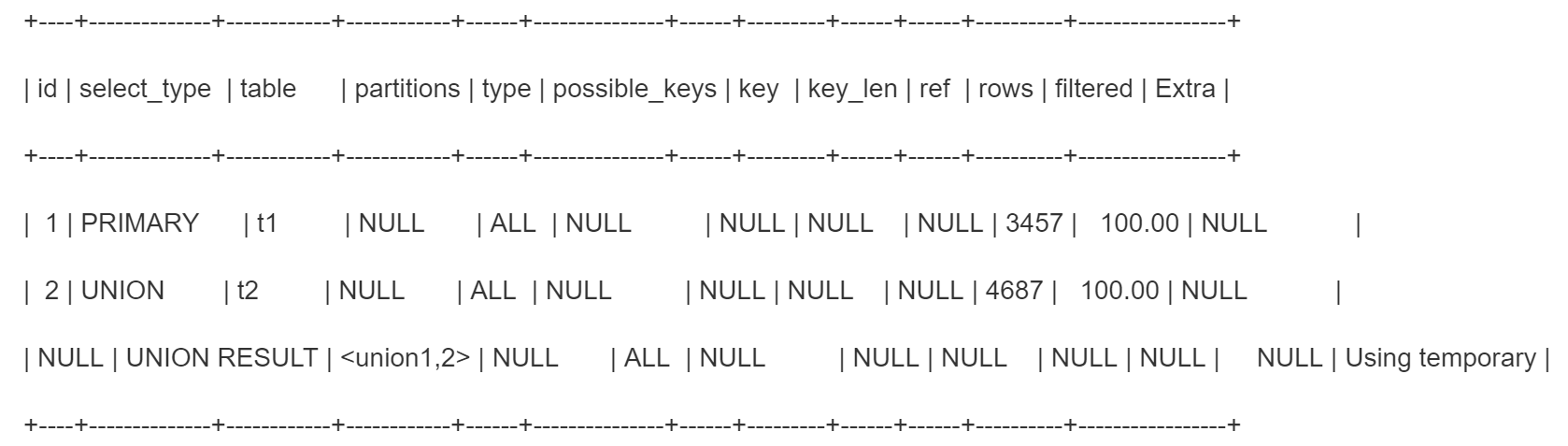
第三天union是个临时的表名,把结果放到临时表去重
- explain select * from t1 inner join t2 on t1.id = t2.id
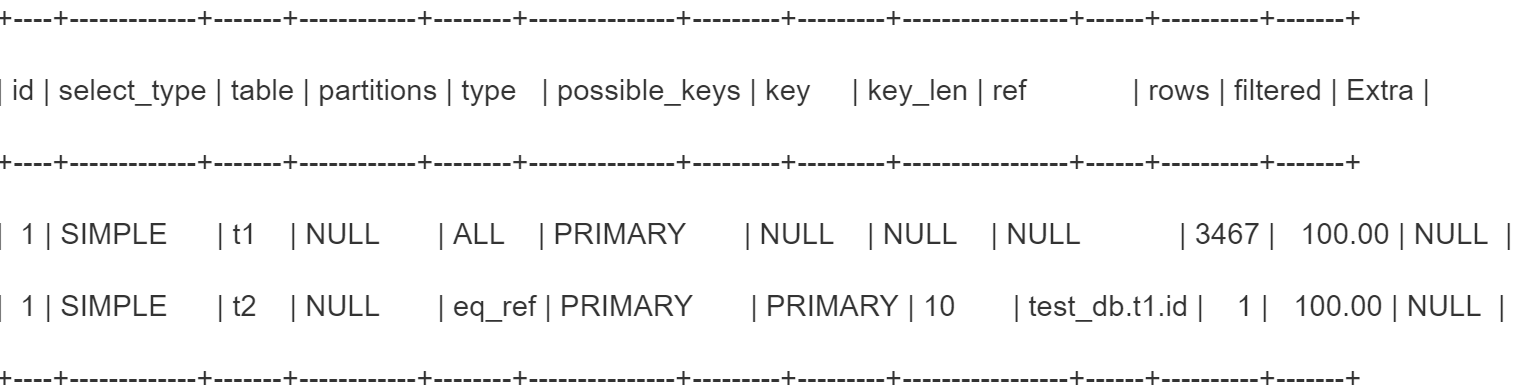
t1是驱动表,进行全表扫描。t2查询type是eq_ref,意思是针对t1表里查出的数据,在t2表基于主键进行等值匹配。
如果是正常二级索引就是ref,允许为null就是ref_or_null
- possible_key 就是可能使用上的索引,根据成本计算到底使用哪一个。
explain select from t1 where x1=’xxx’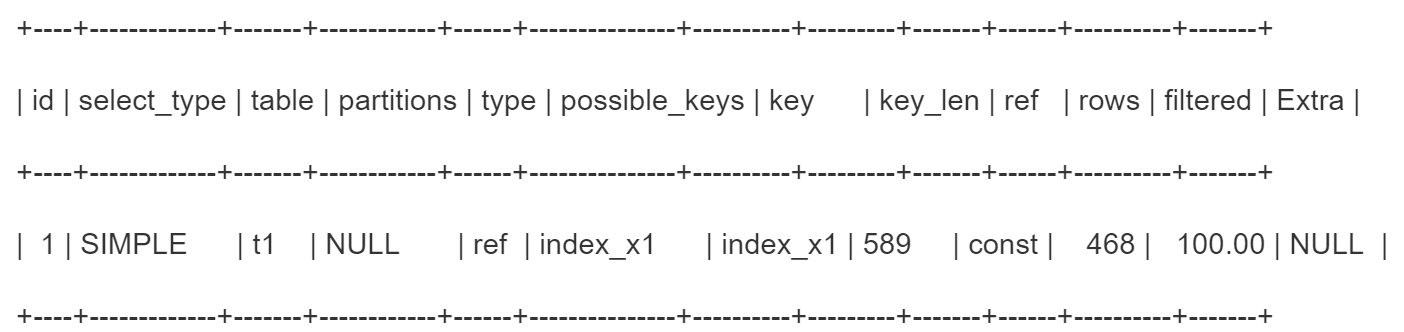
type = ref,说明走了索引,为index_x1,索引最大值的长度为589.ref=const因为做的是等值匹配
explain select from t1 innner join t2 on t1.id = t2.id
ref = t1.id,意思是t1表的id跟t2表的主键做等值匹配。
rows:是查询出多少条数据
filtered:查询方式查出来的数据再加上其他不在索引范围条件又会过滤出百分之多少的数据。
- extra额外的信息
explain select x1 from t1 where x1= ‘xxx’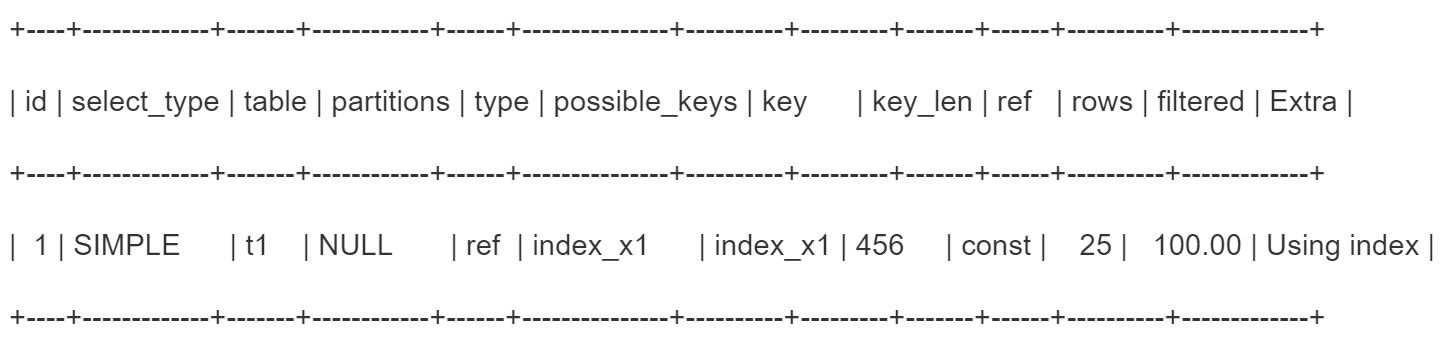
执行计划跟之前一样,extra=using index意思是仅仅涉及到二级索引不需要回表。
- extra = using where.一般是扫描表, 没用到索引,但是有where。或者除了用到索引之外还需要其他的字段进行筛选。
explain select * from t1 where x2 = ‘xxx’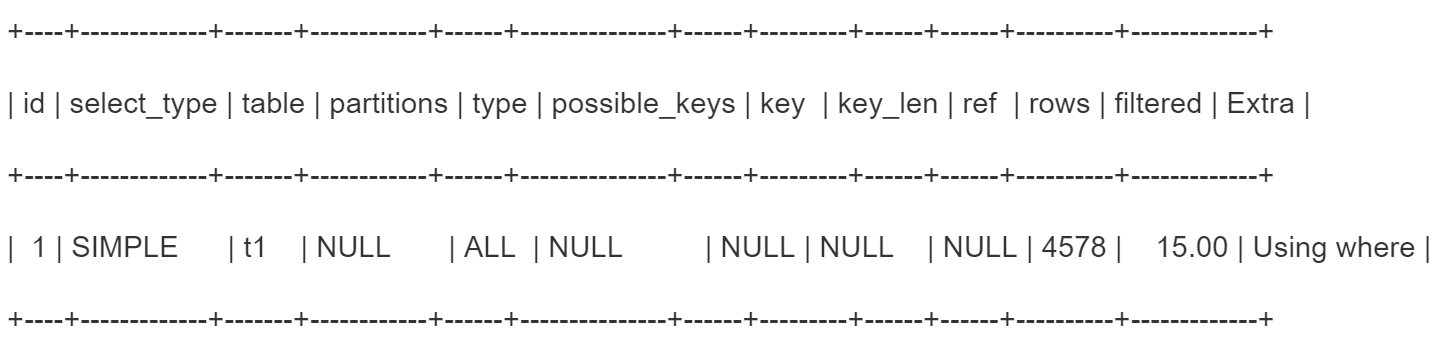
x2不是索引,用全表扫描出4578条数据,使用where x2 =’xxx’ 过滤出15%的数据。
ref是否有值跟是否用到索引有关
- 多表关联时,如果关联条件不是索引,会用到join_buffer提升性能
- extra= using filesort :需要排序
explain select * from t1 order by x2 limit 10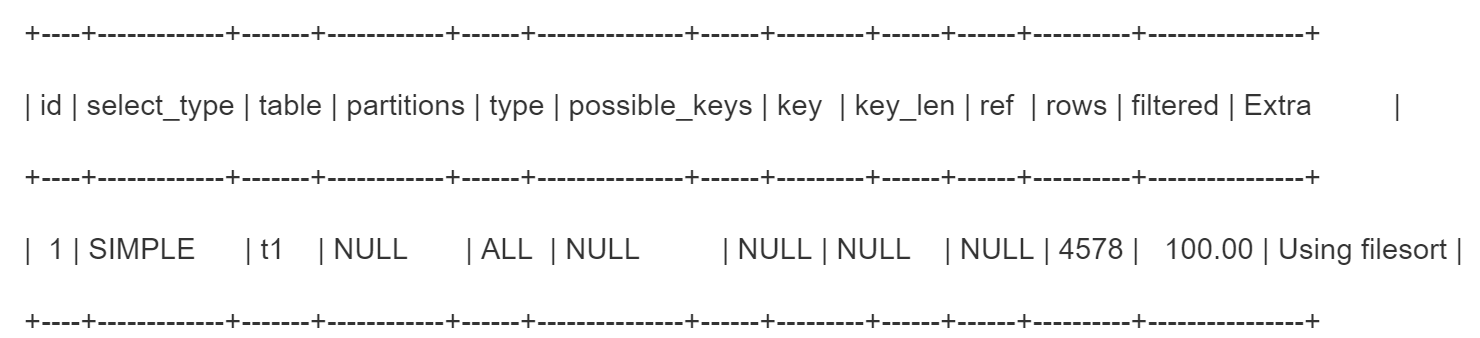
x2不是索引,基于x2字段排序没法走索引,只能基于排序算法在磁盘文件中排序。
或者extra = using temprory,基于临时表的方法,在做group by,union,distinct之类的语法时。
这两种性能都很低,mysql的优化核心就是找到需要全表扫描或者扫描的数据量多大的地方进行优化,尽可能的走索引。

若有收获,就点个赞吧
0 人点赞
