大数据开发/数仓工程师技能树
数据工程常见分工: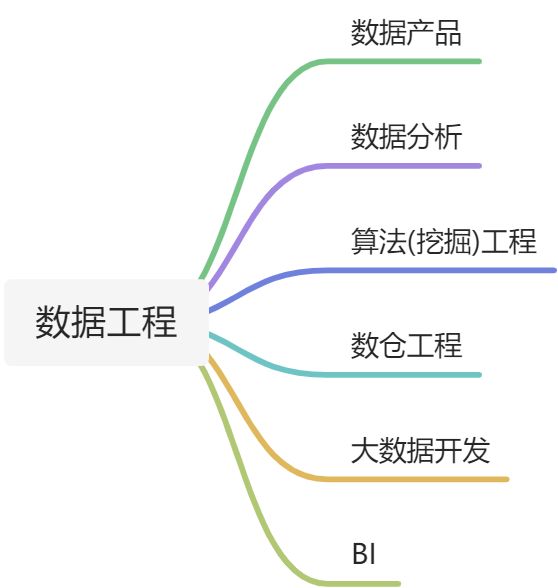
- 大数据分析
需要掌握技能有 SQL、EXCEL、PPT、Python\Spass\R, 简单指标获取,指标分析,产出报告等。
- 大数据开发
细分可分为 ETL 开发 和 平台开发。
ETL开发: 主要掌握 SQL 及简单 shell/Python 脚本,或 Kettle 等 ETL 的使用。 数据的清洗、转换、集成。
平台开发: 注重工具、平台等多种技能,如 Hadoop/Hive、Spark/Flink 与 主语言 Java 等。负责海量数据的存储与流转、工具与平台的搭建与维护、离线或实时指标代码的编写。
- 数据仓库工程
掌握 Hive、Hbase、ck 等数仓工具,对数据库模型有深刻了解,数据仓库的设计、搭建与维护。
与第 2 点联系较为紧密。
- 算法(挖掘)开发
掌握 Python、Spark等数据处理与训练库工具。对数据的训练与应用,发掘数据的深度价值。
技能树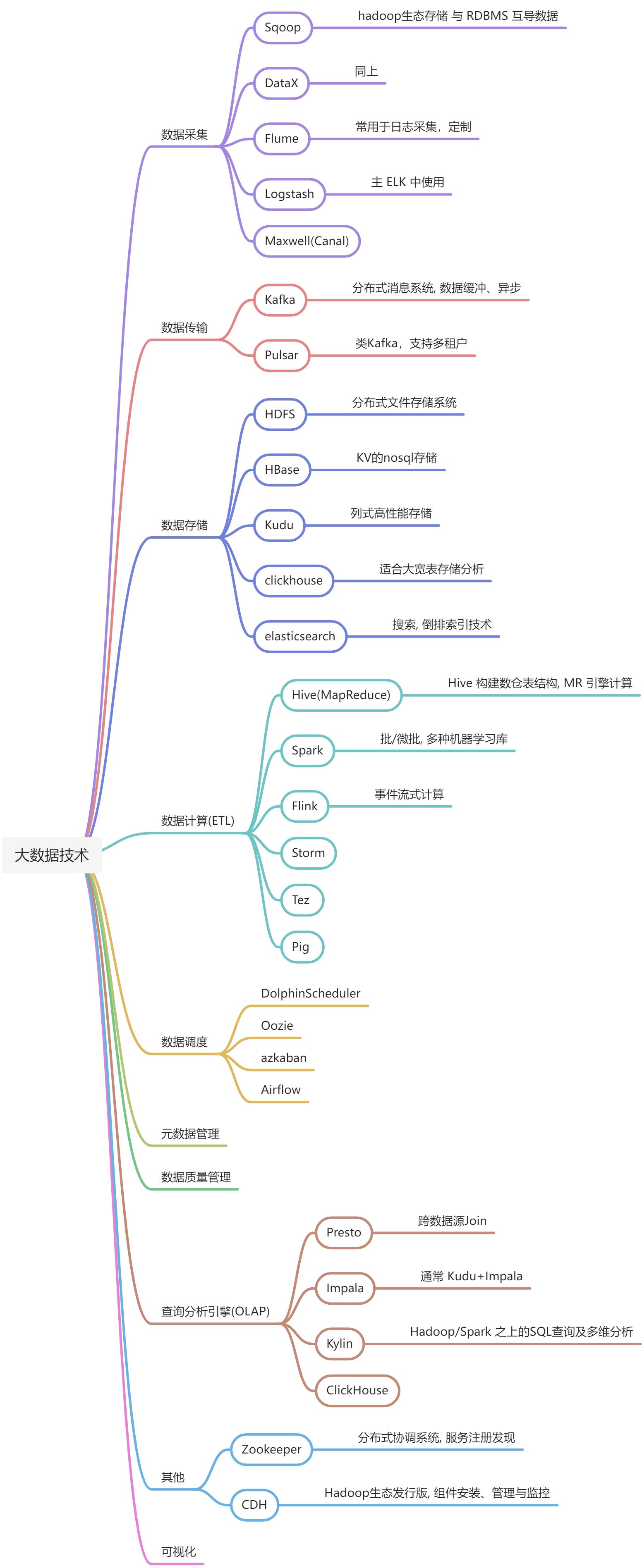
| 组件 | 常用知识 | 原理掌握 | 使用熟练 | |
|---|---|---|---|---|
数据采集 |
Sqoop | 增量,参数,Null,转义字符,数据一致性,并行度 | ☆☆☆☆☆ | ☆☆☆☆☆ |
| Flume | 传输定制,参数 | ☆☆☆☆☆ | ☆☆☆☆☆ | |
| DataX | ☆☆☆☆☆ | ☆☆☆☆☆ | ||
| Maxwell(Canal) | 参数,偏移量丢失 | ☆☆☆☆☆ | ☆☆☆☆☆ | |
数据传输 |
Kafka | 主题,订阅消费 | ☆☆☆☆☆ | ☆☆☆☆☆ |
| Pulsar | ☆☆☆☆☆ | ☆☆☆☆☆ | ||
数据存储 |
HDFS | 小文件 | ☆☆☆☆☆ | ☆☆☆☆☆ |
| HBase | RowKey设计 | ☆☆☆☆☆ | ☆☆☆☆☆ | |
| Kudu | 主键/分区 | ☆☆☆☆☆ | ☆☆☆☆☆ | |
| clickhouse | ☆☆☆☆☆ | ☆☆☆☆☆ | ||
| elasticsearch | ☆☆☆☆☆ | ☆☆☆☆☆ | ||
| ClickHouse | ☆☆☆☆☆ | ☆☆☆☆☆ | ||
数据计算 |
Hive | 数据倾斜、小文件合并 | ☆☆☆☆☆ | ☆☆☆☆☆ |
| Spark | 数据倾斜 | ☆☆☆☆☆ | ☆☆☆☆☆ | |
| Flink | checkpoint/savepoint | ☆☆☆☆☆ | ☆☆☆☆☆ | |
| Impala | 内存溢出/倾斜 | ☆☆☆☆☆ | ☆☆☆☆☆ | |
| Presto | ☆☆☆☆☆ | ☆☆☆☆☆ | ||
数据调度 |
DolphinScheduler | ☆☆☆☆☆ | ☆☆☆☆☆ | |
| azkaban | ☆☆☆☆☆ | ☆☆☆☆☆ |

若有收获,就点个赞吧
0 人点赞
