0 概况

kafka 或 kinesis 做数据收集 S3+redshift 做数仓 EMR 做计算 RDS 做数据市场 AWS Glue / AWS Data Pipeline 做数据集成
Google cloud vs AWS 对比及成本计算:传送门
1 Redshift

双副本
2021-11-30 Amazon Redshift 无服务器版(预览版)部分欧美地区
2 特点
2.1 快速
对于大小在 100GB 到 1PB 或更高的数据集,可以实现很高的查询性能,并使用了列式存储。Amazon Redshift 采用了大规模并行处理 (MPP) 数据仓库架构,可以对 SQL 操作进行并行分布处理,以便利用所有可用资源。底层硬件支持高性能数据处理,使用本地连接的存储以便尽可能增大 CPU 与驱动器之间的吞吐量,同时使用 10GigE 网状网络以便尽可能增大节点之间的吞吐量。 支持物化视图。
2.2 扩展
调整大小时,Amazon Redshift 可将您现有的集群置于只读模式,并预置一个您选定大小的新集群,然后将数据从您的旧集群并行复制到您的新集群。在预置新集群的同时,可继续对您的旧集群运行查询。一旦您的数据被复制到新集群,Amazon Redshift 会自动将查询重新定向至新集群,并移除旧集群。整个调整大概需10-15分钟。
Redshift可以选择集群模式,也就是可以选择Redshift底层,基于多少台硬件服务器提供算力和存储。
节点类型:
- RA3 : 托管存储 RMS
- DC2 密集计算:SSD、高速 CPU、大量 RAM
- DS2 密集存储:HDD
2.3 完全托管
Amazon Redshift 处理数据仓库的管理、监控及扩展所需的所有工作,从监控集群运行状况、备份到进行修补和升级。非完全的server less,可以选择集群数量和性能,基本无需管理。
2.4 自动备份
自动快照到 S3。
2.4 快速恢复
2.5 容错
会持续监控集群的运行状况,并自动从出故障的驱动器重新复制数据,同时根据需要替换节点以实现容错。集群还可以重新定位到备选可用区 (AZ),而不会有任何数据丢失或应用程序变更。
2.6 网络隔离
vpc
2.7 并发
500 个并发连接, 一次最多可以同时运行50个查询。包括INSERT / UPDATE / DELETE等所有内容。
3 案例
2014-2018 70节点
2018 每天超过 4TB
2018 S3(数据湖、存算分离),结合 Amazon S3 Glacier 低成本存档。依靠 S3 Object Lock 功能进一步实现合规性。
2019 Redshift 计算层, Amazon Redshift Spectrum 查询 S3 数据,就地查询,而无需加载数据。
2020 每天可接收 700 亿条记录 — 峰值为 1130 亿条记录。
- VOO — 比利时领先的电信运营商
2017-2020 600TB, 该数据湖建立在 S3 之上, 一些数据文件在 Amazon EMR 上进行预处理.
Redshift 查询 S3 数据湖的 PB 级结构化和半结构化数据。
使用 Amazon Redshift 的数据湖导出功能将结果以 Apache Parquet 等开放数据格式保存回 Amazon S3
以便使用 Amazon EMR 进行进一步分析并使用Amazon SageMaker 进行机器学习.
将数据存放在其 Amazon Redshift 仓库中。Magellan Rx 可以保留、检索和恢复存储在其 Amazon S3 存储桶中的每个对象的每个版本,满足其灾难恢复要求。
Amazon Redshift ML,使数据分析师和数据库开发人员可以在 Amazon Redshift 数据仓库中使用熟悉的 SQL 命令轻松创建、训练和应用机器学习模型。
集成了一个基于 S3 的 8 节点数据湖或原始数据存储库 Redshift。
该公司将其低延迟数据保存在 Amazon Redshift 中,将中等延迟数据保存在 Amazon S3 中,使用Amazon Redshift Spectrum功能每天直接从 Amazon S3 查询超过 60 TB 的客户和产品数据,无需加载数据。该公司还为机器学习算法挖掘数据。
与第三方营销数据合并,并在 created schemas in the AWS Glue Data Catalog (元数据管理),使用商业智能 (BI) 工具(如 Tableau)来获取用于构建报告的整合数据视图。用户还可以利用 Amazon Redshift 湖库,因为他们可以使用自己的 BI 工具访问数据,而不管数据存储在哪里。
通过将 Amazon S3 与 Amazon Redshift 结合使用,通过将计算与存储分离并将其数据分析集群从 12 个节点减少到 8 个节点来优化其成本。
正在通过 Amazon Redshift 湖屋获取我们访问和分析的数据,并支持个性化产品推荐、网站优化和新功能。
- MYTONA — 移动游戏发行商
该公司是 Redshift RA3 节点的早期采用者,可在不增加存储成本的情况下增加计算容量。
MYTONA 还对热数据使用高性能固态驱动器,对冷数据使用更便宜的Amazon Simple Storage Service (Amazon S3)。这可以控制成本,尤其是在数据量可能快速变化的情况下。
4 架构
综上,得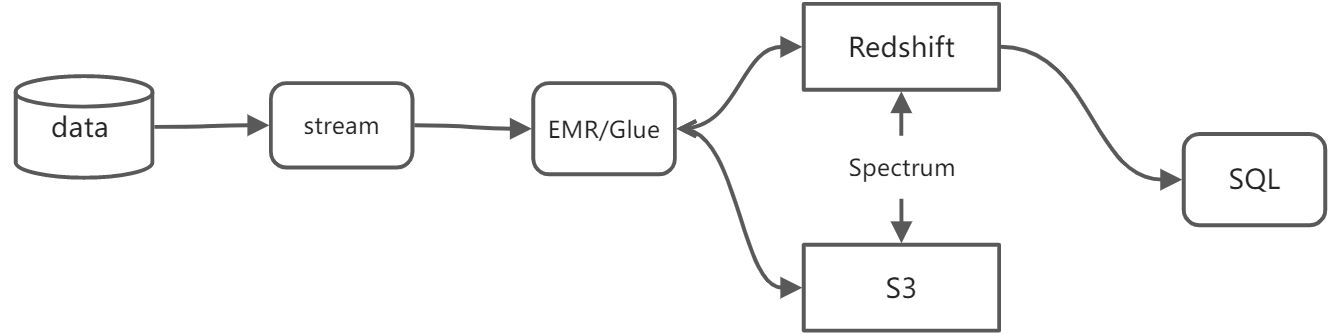
数据流:
AWS Data Pipeline
Amazon Kinesis Firehose
- MySQL -> S3 -> Redshift (staging) -> SQL -> Redshift
存储: Redshift RA3 + S3
计算(ETL)/查询: Glue/EMR + Redshift SQL + Spectrum
5 迁移
~~从 Netezza、Oracle、Teradata、SQL Server 到 Redshift ~~
BigQuery 到 Redshift:
参考1:https://stackoverflow.com/questions/57045670/moving-bigquery-data-to-redshift
将数据从 Big Query 移动到 Cloud Storage Bucket, 与 S3 桶同步
BigQuery -> Google cloud storage -> S3 -> Redshift
gsutil rsync -d -r gs://your-gs-bucket s3://your-s3-bucket
参考2:https://hevodata.com/blog/google-analytics-to-redshift/
https://www.softcrylic.com/blogs/moving-google-analytics-data-through-bigquery-to-amazon-redshift-for-reporting/
参考3:https://dzone.com/articles/step-by-step-how-to-load-your-google-analytics-dat
6 成本
详细对比:
| Redshift | Spectrum | S3 | MSK(kafka) | Kinesis Data Firehose/streams/Pipeline/Lambda | Glue | EMR | |||
|---|---|---|---|---|---|---|---|---|---|
| 规格 | dc2 算优化 | ds2 存优化 | RA3 托管存 | 按量 | 按量 | 基础设施与量 | 按量 | 按量 | 基础设施与量 |
| 收费 | dc2.large dc2.8xlarge |
ds2.xlarge ds2.8xlarge |
全预付(1节点) ra3.4xlarge: 1年:18834 usd ra3.16xlarge: 1年:75424 usd 存储RMS: 0.024 usd/G/月 |
扫描 1 TB = 5 USD | 每月 标准: 50TB内: 0.025 usd/G 500TB内: 0.024usd/G 500TB外:0.023usd/G 智能: 低访问 0.0138usd/G 归档: 0.005usd/G 请求/传输: |
托管式: 2800 usd/月 |
按数据量付费 一天1e, 1157条/s 567.62 usd/月 格式转换(可选) 352.32 usd/月 动态分区(可选) 435usd 左右/月 |
按秒/时, 元数据对象 ETL Job(Spark) 一个月 几十 美金 |
m5.2xlarge(8+32)/ m5.4xlarge master3 core2 node*3 1121.28usd/月 |
| 备注 | 适合 1T 以下 未压缩数据 |
不划算 | ra3.4xlarge | 直接读取 S3 数据,无需加载进 Redshift | Parquet 按4:1 压缩 成本低 |
serverLess 版未上线。 | to Redshift 仅支持 Gzip 压缩, 本质上 ->s3->redshift copy 近实时 60s批 一条流一个表 |
serverLess 服务 |

数据量: 按 1e/天, 1k/条,平均 1157 条/秒
数据流:1500 USD/月
存储:15705 USD/月(5RedShift) + 800 USD/月(S3 30T/年)
计算/查询:200 USD/月(st) + 1000 USD/月(ETL)
月总:11350 USD = 72438 rmb
年总:136200 USD = 869256 rmb
暂停和恢复:按需模式 当集群暂停时,数据仓库的存储会产生费用。按需计算计费按秒暂停和恢复。
Amazon Redshift 无服务器版(预览版)对 Amazon S3 中外部数据的查询不单独计费,而是包含在 Amazon Redshift 无服务器版的费用中(以 RPU 小时为单位)。
7 综合
Redshift 列限制:单个表中定义最多 1,600 列。
物化视图:支持
访问控制:可以通过标准GRANT 语法强制执行列级安全性,该语法允许每个用户/组访问特定列,而不是依赖于视图。行级授权仍由授权视图处理。
调度:UI 中 AWS EventBridge 工作的 API
查询少,BigQuery 更具性价比,如 Redshift 托管存(或s3),按需查询,则成本相差不大。
AWS 生态更强大。
按功能、性能、生态等方面,aws win
8 实践
7.1 写入
- insert
- upsert
Redshift 可以执行 upsert,但只能通过一个复杂的过程。Redshift 不提供 UPSERT 命令来更新表。用户必须将数据加载到暂存表中,然后将暂存表与目标表连接起来以执行 UPDATE 语句和 INSERT 语句。
- copy
COPY 命令可以从Amazon S3/Amazon EMR/Amazon DynamoDB/Remote Hosts等多个数据源将数据加载到Redshift中。能够同时从多个数据文件或多个数据流读取。Amazon Redshift 将工作负载分配到集群节点并且并行执行加载操作,包括对行进行排序和跨节点切片分配数据。
先将数据传输到 S3 存储桶,然后发出 Amazon Redshift COPY 命令将数据加载 Redshift 集群中。
配置命令,自动执行。
- AWS Glue

通过 Aurora for Postgresql/MySQL 作为实时数据摄入缓存表接收数据,然后异步合并到Redshift中,从而实现数据的实时可用。只支持云商数据库?
对比
| 吞吐量 | CDC支持 | 是否需要编写脚本 | 调度方式 | 摄入时延 | |
|---|---|---|---|---|---|
| INSERT(DML) | 低 | 是 | 是 | 借助第三方 | 秒级别 |
| COPY | 高 | 否 | 是 | 借助第三方 | 分钟级别 |
| Kinesis Data Firehose | 高,COPY实现 | 否 | 否 | 自动 | 分钟级别 |
| DMS | 高,COPY实现 | 是 | 否 | 自动 | 分钟级别 |
| Glue | 高,COPY实现 | 否 | 可自动生成 | 内置调度 | 分钟级别 |
| Federated Query | 中 | 否 | 是 | 借助第三方 | 毫秒级别 |
综合对比几种数据摄入方式:
- 在数据量较大的离线数据加载场景下,推荐使用COPY,COPY可以使用整个集群的资源实现数据的并行加载,并根据集群资源和数据量控制加载频率。
- 对于数据源为流式数据的场景下,可以使用 Kinesis Data Firehose 内置机制自动的实现数据加载至Redshift。
- 对于 CDC 场景可以通过 DMS 读取 RDS 等数据库的 binlog 变更日志,通过DMS解析后转换成加载语句加载至Redshift中。
- 对于想实现数据实时摄入、秒级延迟的场景,可以借助Amazon Redshift Federated Query,通过Aurora for Postgresql/MySQL 作为实时数据摄入缓存表接收数据,然后异步合并到Redshift中,从而实现数据的实时可用。
秒级 CDC, 只能通过 自定义脚本 insert
相关链接
- 数据组件基准测试对比
- BigQuery 与 RedShift 对比
- 对比参考
- Amazon Redshift 架构
- Amazon Redshift深入解析.pdf
- 基于个性化查询场景的 Amazon Redshift 压力测试方案
- 高性能云数据仓库性能测试v1.0-2020-10
产品评测:Actian Avalanche、Amazon Redshift、Microsoft Azure Synapse、Google BigQuery、Snowflake

若有收获,就点个赞吧
0 人点赞
