0 主要方向

目的:
- 存储大量历史数据与不断增长中的数据
- 分析挖掘数据、服务数据产品
1 自建流批一体(存算混合)
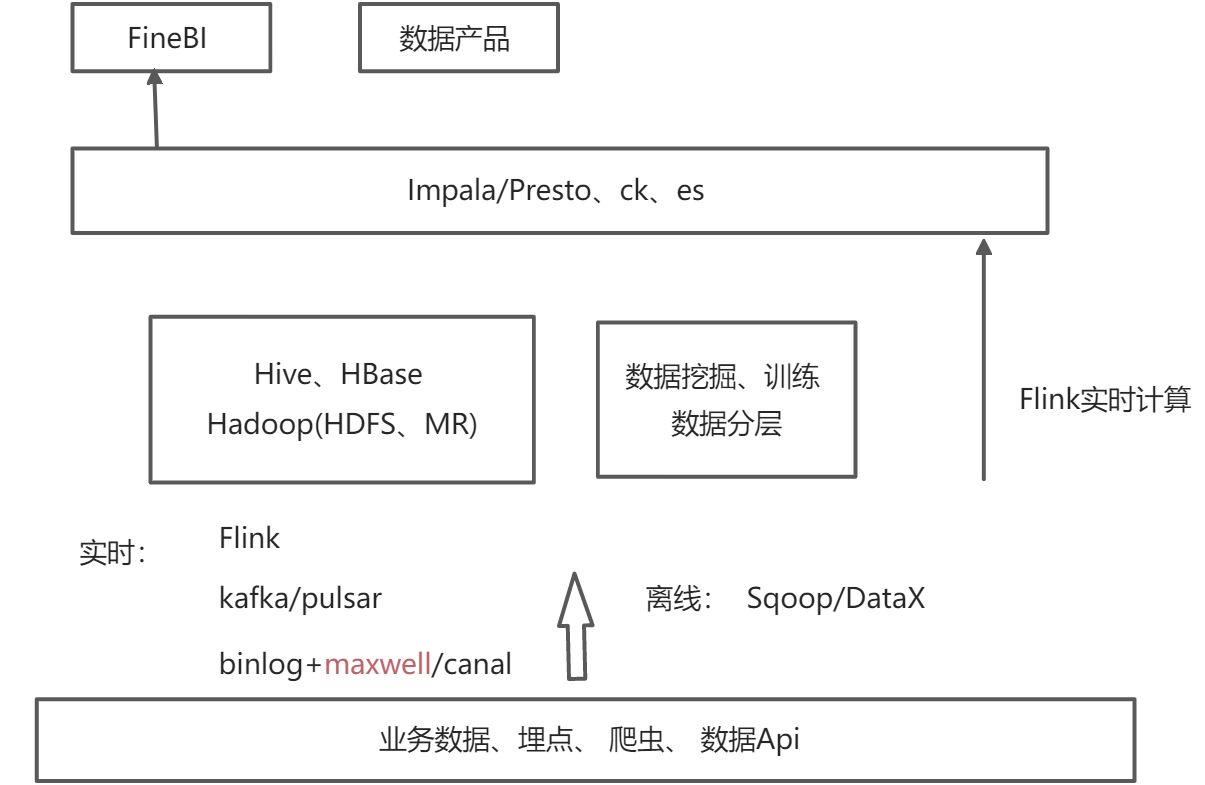

使用 CDH等平台自搭建服务
优点: 方案成熟、自主可控、组件灵活选择,易于探索
缺点:存算一体、增加存储的同时会增加计算资源、需要一定的运维
2 云服务-存算分离弹性伸缩架构
架构举例:
云原生服务,架构类似 CDH 平台,运维难度小。可以根据数据量弹性申请资源(计算+存储),避免空闲资源的浪费(当数据量大时效果好)
可以专注业务开发。
优点:对象存储(可选),节省空间;存储、计算分离,灵活按需增加
缺点:贵
产品
腾讯云:弹性 MapReduce
阿里云:大数据计算服务 MaxCompute
华为云:MapReduce服务 MRS
AWS:Amazon EMR
EMR 的两种模式:
- 集群模式:构建长期运行集群。
- 步骤执行模式: 根据任务,规划集群算力,创建集群(Spark、MR),运行任务,结束后,销毁集群。数据存储在 S3 等低成本系统中。
AWS Redshift:可以认为是一款分布式、高并发、大容量的 Postgresq 数据库。
每年每 TB<1000 USD ?
3 StarRocks
自主打造的新一代全面向量化的MPP引擎使查询性能大幅提高,是非原生向量化系统(Kylin/Druid/Elasticsearch/Impala-Kudu/Presto/Greenplum)的3~5倍以上。
ClickHouse向量化引擎并不支持全面的MPP,多表查询能力差,StarRocks的多表查询性能是其3~5倍以上。
其他系统都无法较好支持高并发查询,StarRocks可以支持每秒上万次的并发查询能力,在线查询场景。
由于 StarRocks 良好的多表 Join 性能,改变了过去大宽表的形式,采用星型关联表来建模,可以支持维度动态修改,降低回溯成本。
可以代替 Presto、Impala+kudu、ClickHouse
3.1 方式1:
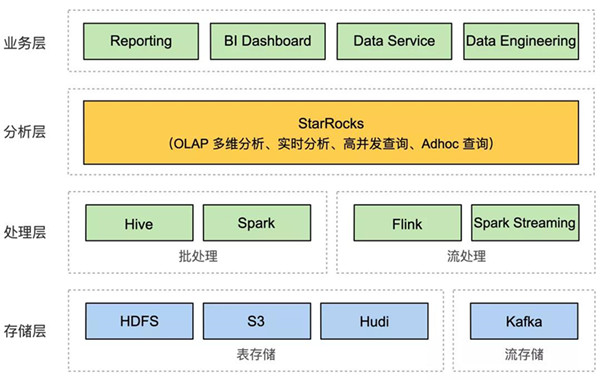
替换分析层的各种组件
实时计算 和 离线统计 流入 StarRocks,HDFS 主要存储历史数据和明细数据等。
即热数据 及 实时分析数据 流入 StarRocks,Hive 冷数据存储 。
3.2 方式2:
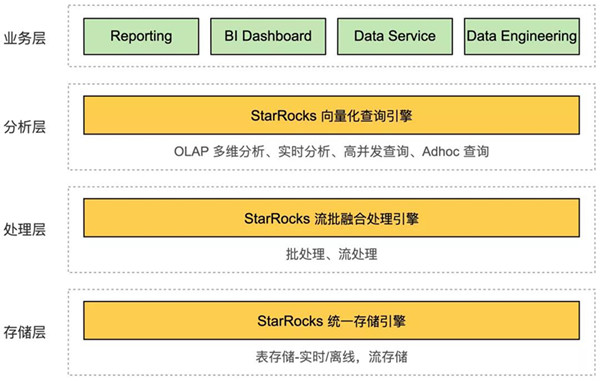
数据统一存储到 StarRocks, 管理方便。
4 TiDB
参考:TiDB 最佳实践
今日头条:http://t.cn/RnLfEMf
游族平台:https://mp.weixin.qq.com/s/_VAWuTO2KUlGB8B0ouLRTw
马蜂窝:https://www.slidestalk.com/TUG/MongoDBTiDB65928
同程旅游:https://segmentfault.com/a/1190000014361145
易果集团(实时数仓):http://t.cn/RTYVhzH
二维火餐饮(实时报表):https://mp.weixin.qq.com/s/Ui3i2xhvPB_gig3WU_2Jaw
缺点: 硬件要求高
5 总结
方案1:
方案成熟,数据量增大的同时,维护成本也增大。
方案2:
方案成熟,云服务支持,维护难度小,不用担心拓展,可专注业务开发。数据量不多时,优势不明显。
方案3:
组件少,较容易维护,数据处理方便,可专注业务开发。稳定未知
3.1 数据量较多时,分冷热数据存储,节省存储资源
3.2 数据量不多时,统一存储,节省开发,人力等资源。
业界 多使用1 and 2, 逐渐 3.1 化,
| 1 | 2 | 3 |
|---|---|---|

若有收获,就点个赞吧
0 人点赞
