各种join,常用如 left join 等,OLAP 场景中使用相对较多的操作
JOIN 的使用种类
其中[]的为可省略词
- [INNER] JOIN
内连接,筛选只有当左右表条件都匹配上的结果 - LEFT [OUTER] JOIN
该join会将左表中的所有记录都输出,即使右边中没有与之匹配的结果(用NULL填充) - RIGHT [OUTER] JOIN
与 LEFT JOIN 相反 - FULL [OUTER] JOIN
相当于left join和right join的集合体,会将两边所有的数据都进行join,然后输出,包括左右表中没有匹配的记录。如左表记录没有匹配右表记录的,右边用null填充。右表亦然。 SEMI JOIN
这种join是相对使用比较少的join类型,需要与left/right结合使用。例如,如果我们使用left semi join的话,那就只会返回左表中匹配到的数据(注意这里与left outer join的区别)
left semi join其实就是只返回left outer join中,左表的数据,right semi join也是同样的道理。需要注意的是,我们在使用left semi join的时候,无法select右表的列select id,name from employee left semi join departmenton employee.dept_id = department.depart_id;
select depart_name from employee right semi join departmenton employee.dept_id = department.depart_id;
ANTI JOIN
这种join方式与semi-join一样,都是只返回一张表的结果,但是返回的是不匹配的结果,即取反的结果。例如,left anti join返回的是左表中,没有在右表匹配到的记录select id,name from employee left anti join departmenton employee.dept_id = department.depart_id;
select depart_name from employee right anti join departmenton employee.dept_id = department.depart_id;
JOIN 常见实现分类以及基本实现机制
数据库连接的三种方式
- NESTED LOOP JOIN
嵌套循环连接,外表驱动内表(外表返回的记录要匹配内表的行),一般小表作外表,内表连接字段要有索引。
支持所有谓词(相等谓词、不等谓词) - MERGE JOIN
至少要有一个连接谓词,连接键要进行排序,如T1.a=T2.b, a 要在 T1.a 上排序和 b 要在 T2.b 上排序。
连接方式是一次同时 读取并比较两个已经排好序的输入中的一行。如果行条件相等,输出连接并继续。否则取较大的一行并继续(小的一行在后面有序的行里不会有匹配)。 [归并的思想]
与嵌套循环连接不同的是,在嵌套循环连接里面总的成本可能会与输入表中的行数的乘积成正比,而合并连接中,每个表最多被read一次,所以总的成本与输入中的行数的总和成正比。因此,合并连接通常是在更大的输入时是更好的选择。但要求两边输入有序。 HASH JOIN
impala 连接方式主要是 hash join。
hash连接分两步执行:构建和探测(build and probe)。
在构建阶段,它会从第一个输入里面读取所有的行(Impala中为右表),然后计算equijoin 键的hash值,然后 创建一个在内存中的hash表。
在探测阶段,它会从第二个输入(左表)读取所有的行,在相同的equijoin键上计算hash值,然后根据hash表进行查找。因为hash函数会导致冲突(两个不同的键值在经过hash计算后会得出相同的hash值),Impala 还需要检查每个潜在的匹配来确保确实符合连接条件。
注意到,不同于嵌套循环连接及合并连接会立刻开始返回输出行,hash连接会在它的构建输入时,阻止输出。 也就是说,在返回任何输出之前它必须读取和处理它的整个构建输入。更进一步讲,不同于其他连接方法,hash连接要求一块内存来存放hash表。也就是说,对某个指定的时间点,能同时执行hash连接的数目就需要有一个限制。在hash连接开始执行之前,Impala会尝试估算它需要多少内存来构建它的hash表。然后,我们会尝试保存这么多的内存,确保hash连接可以成功执行。如果因为我们给了hash连接较少的内存,在这些情况下,hash连接的构建阶段就可能会出现运行内存不足。如果hash连接耗尽了内存,它会开始将总的hash表中的一小部分溢出(spill)到磁盘中。hash连接会跟踪 hash表中的哪些部分仍然在内存中,哪些部分已经溢出到磁盘中。当我们从构建表(build table)中读取每一新行时,我们会检查一下是否hash到了内存中或者磁盘上。如果是hash到内存中,则进行正常的hash处理。如果是hash到磁盘上的,我们会将该行写入磁盘。这一耗尽内存和溢出到磁盘的过程可能重复多次,直到构建阶段已经完成为止。我们在探测阶段会进行一个类似的过程。对探测表的每个新行,我们需要检查以查看是否hash到了内存中或 者磁盘上。如果是hash到内存部分,我们会对hash表进行探测,生成任何合适的连接的行,并丢弃该行。如 果hash到了磁盘部分,我们则将该行写入磁盘。一旦我们完成了对探测表的一次遍历,我们会逐个返回已经 溢出的部分,将构建表中的行读回内存,为每一部分重建hash表,接着读取对应的探测部分来完成连接。
impala 分布式 Join 实现机制
Broadcast Hash Join
Impala 默认的连接方式。Impala 将较小的表通过网络分发到所有需要执行该连接的Impala后台进程中。并建立 hash 表,然后与大表匹配。
这种方式不需要讲整个大表(一般在本地)的数据读入到内存,因此Impala使用1GB的缓存读取大表的数据,一部分一部分读入并进行连接。小数据集在每个节点中都占用内存。
缓存在内存中的数据并不是整个表的数据,而是连接列的哈希值以及查询需要用到的列。
小表会分发到所有Impala进程。
Impala 使用基于开销的优化估算表的大小并决定是否进行广播连接、哪个表比较小、哈希表需要多少内存等。
Shuffle Hash Join
也叫 partitioned hash join。分区哈希连接需要更多的网络开销,但可以允许大表的连接而不要求整个表的数据都能放到一个节点的内存中。当统计数据显示表太大而无法放到一个节点的内存中或者有查询提示时就会使用分区哈希连接(shuffle hash join)。
进行分区哈希连接时,每个Impala进程读取两个表的本地数据,使用一个哈希函数进行分区并把每个分区分发到不同的Impala进程。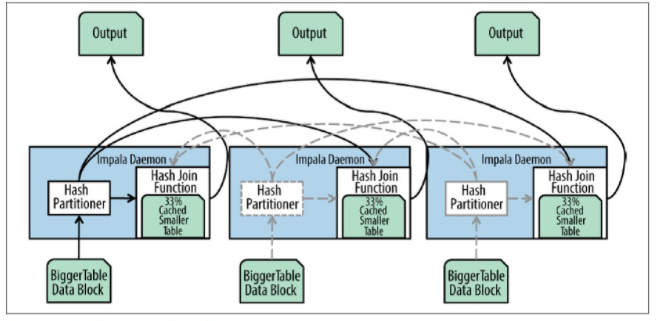
正如上图所示,大表的数据也通过相同的哈希函数就行分区并把分区发送能和小表相应数据进行连接的结点。注意,和广播连接不同的是,广播连接只有小表的数据需要通过网络分发,而分区哈希连接需要通过网络分发大表和小表的数据,因此需要更高的网络开销。
综述:
Impala有两种连接策略:
广播连接,需要更多的内存并只适用于大小表连接。将大表划分成多块,小表广播与这些块进行hash join;
分区连接,需要更多的网络资源,性能比较低,但是能进行大表之间的连接。将两个大表都划分成多块,然后分别进行hash join,有点类似于mapreduce中的shuffle。
Impala 保存 Join 顺序、连接方式
一般情况下,COMPUTE STATS会对JOIN的顺序进行自动优化。但是这个自动“优化”并不一定保证对所有的SQL都带来性能的提升 (需要测试)。对于那些性能下降的SQL,可以使用 STRAIGHT_JOIN 保证 Impala 在计算 Query Plan 保持原有的 JOIN 顺序。同时,SQL JOIN过程涉及数据的网络传输,Impala会根据表的大小选择合适的连接模式,也可以手动使用 Hint 指定特定的模式,select后面加上STRAIGHT_JOIN; join后面加上[shuffle]或者/* +shuffle */ 或 /* +BROADCAST */。
例:
SELECT STRAIGHT_JOIN select_list FROMjoin_left_hand_tableJOIN [{ /* +BROADCAST */ | /* +SHUFFLE */ }]join_right_hand_tableremainder_of_query;INSERT insert_clauses[{ /* +SHUFFLE */ | /* +NOSHUFFLE */ }][/* +CLUSTERED */]SELECT remainder_of_query;SELECT select_list FROMtable_ref/* +{SCHEDULE_CACHE_LOCAL | SCHEDULE_DISK_LOCAL | SCHEDULE_REMOTE}[,RANDOM_REPLICA] */remainder_of_query;
三种连接比较

- hash join: 对于等值 join, impala将采用hash的方式处理, 具体又分两种策略, broadcast 和 Shuffle.
broadcast join 非常适合右表是小表的情形, impala 先将右表复制到各个节点, 再和左表做 join.
shuffle join, 也叫做 partitioned join , 适合大表和大表关联. 注意 partitioned join 和右表的 partition 没有直接关系, impala 会将右表打散成 N 份, 发送到左表所在的节点, 然后作join.- nested loop join: 针对非等值 join, impala 将使用 nested loop join, 这时我们不能设置 SHUFFLE/BROADCAST hint, 也不能使用 spill disk 功能. impala 的非等值 join 的效率较低, Vertica的效率非常高, Hive直接不支持.
Impala 查询最佳实践
- 最大的表应该放在表清单的最左边.
- 多个join的查询语句, 应该将选择性最强的join放在最前面,且尽量少用非等值连接.
- 定期对表收集统计信息(COMPUTE INCREMENTAL STATS), 或者在大量DML操作后主动收集统计信息.
- 在一个单一的查询里面, 参加join的表个数尽量不要超过4个, 不然效率比较低下.
参考:

若有收获,就点个赞吧
0 人点赞
