一、什么是ElasticSearch
- 数据分类
结构化数据:值具有固定格式或有限长度的数据,如数据库,元数据等。
对于结构化数据,我们一般都是可以通过关系型数据库的table的方式存储和搜索,也可以建立索引。通过b-tree等数据结构快速搜索数据。
非结构化数据:全文数据,指定长或者无固定格式的数据。如邮件,word文档等。
对于非结构化数据,也即对全文数据的搜索主要又两种方法:顺序扫描法、全文扫描法。
- 顺序分类
我们可以了解他的大致搜索方式,就是按照顺序扫描的方式查找特定的关键词。比如让你在一篇篮球新闻中,找到科比这个名字在那些段落出现过,那你坑定需要从头到尾把文章阅读一边,然后标记出关键词子哪些地方出现过。
这种方法毋庸置疑效率最低,如果文章很长,等你阅读完这篇新闻找到科比这个关键词,那得化多少时间。
- 全文搜索
对非结构化的数据进行顺序扫描很慢,我们是否可以进行优化?把我们的非机构化数据想办法弄得有一定结构就可以了。将结构化数据中得一部分信息提取出来,重新组织,使其变得有一定结构,然后对这些有一定结构的数据进行搜索,从而达到所有相对较快得=得目的。这种方式就构成了全文检索得基本思路。这部分从非结构化数据中提取出来得然后重新组织得信息,我们称之为索引。
4.什么是全文搜索引擎
全文搜索引擎是目前广泛应用的主流搜索引擎。他的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指名该词出现位置和次数,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户。
现在常见的搜索引擎
Lucene,Solr,ElasticSearch
ElasticSearch介绍
ElasticSearch是一个开源的,基于Apache Lucene库构建的RESTFUL搜索引擎。
ElasticSearch实在solar几年后推出,他提供一个分布式,多租户能力的全文搜索引擎,具有HTTP,web界面(REST)和无架构josn文档,ElasticSearch的官方客户端库提供java,Groovy,PHP,Ruby,Perl,Python,.NET和js。
主要功能
- 分布式搜索
- 数据分析
- 分组和聚合
*应用场景
stack OverFlow、Github、日志数据分析
二、快速入门
核心概念
- 类型
- ⼀一种type就像⼀一类表,⽐比如user表,order表。
注意:
ES 5.x中⼀一个index可以有多种type。
ES 6.x中⼀一个index只能有⼀一种type。
ES 7.x以后已经移除type这个概念。
- ⼀一种type就像⼀一类表,⽐比如user表,order表。
- 索引(index)
- 一个索引可以理理解成⼀一个关系型数据库
- 映射
- mapping定义了每个字段的类型信息。相当于关系型数据库中的表结构。
- 文档
- 一个document相当于关系型数据库中的一行记录。
- 字段
- 相当于关系型数据库表的字段。
- 集群
- 集权由一个或者多个节点组成,一个集权有一个默认名称”elasticsearch”。
- 节点
- 集权的节点,一台机器或者一个进程。
- 分片和副本
- 副本是分片的副本。分片有主分片和副分片之分。
- 一个index数据再物理上被分布在多个主分区中,每个主分片只存放部分数据。
- 每个主分片可以有多个副本,叫做副本分片,是主分片的复制。
安装
1、es官网:https://www.elastic.co/guide/en/elastic-stack/7.2/index.html
安装时候环境调整和一些参数的修改:https://unicorn.blog.csdn.net/article/details/121747039?spm=1001.2014.3001.5502
2、可视化⼯工具kibana的安装和使⽤用
下载地址:https://www.elastic.co/cn/downloads/kiban三、Elasticsearch启动以及基本使用
进⼊入到bin⽬目录,执⾏行行sh elasticsearch.sh,守护进程的⽅式可以使⽤sh elasticsearch -d
一、Elasticsearch语句的一些增删改查操作
1、索引的操作PUT "localhost:9200/nba"{"acknowledged": true,"shards_acknowledged": true,"index": "nba"}
DELETE "localhost:9200/nba"
批量获取GET "localhost:9200/nba,cba"获取全部GET "localhost:9200/_all"
curl -I "localhost:9200/nba"
POST "localhost:9200/nba/_close"
2、映射的使用POST "localhost:9200/nba/_open"
PUT "localhost:9200/nba/_mapping" -H 'Content-Type:application/json' -d'{"properties": {"name": {"type": "text"},"team_name": {"type": "text"},"position": {"type": "keyword"},"play_year": {"type": "keyword"},"jerse_no": {"type": "keyword"}}}
单个获取GET "localhost:9200/xdclass/_mapping"批量获取GET "localhost:9200/nba,cba/mapping"获取所有GET "localhost:9200/_mapping"orGET "localhost:9200/_all/_mapping
PUT "localhost:9200/nba/_mapping" -H 'Content-Type:application/json' -d'{"properties": {"name": {"type": "text"},"team_name": {"type": "text"},"position": {"type": "keyword"},"play_year": {"type": "keyword"},"jerse_no": {"type": "keyword"},"country": {"type": "keyword"}}}
3、文档增删改查
PUT "localhost:9200/nba/_doc/1"(指定id) -H 'Content-Type:application/json' -d'{"name":"哈登","team_name":"⽕火箭","position":"得分后卫","play_year":"10","jerse_no":"13"}POST localhost:9200/nba/_doc (不指定id){"name":"库⾥里里","team_name":"勇⼠士","position":"组织后卫","play_year":"10","jerse_no":"30"}*自动创建索引1.查看auto_create_index开关状态,请求http://localhost:9200/_cluster/settings2.当索引不不存在并且auto_create_index为true的时候,新增⽂文档时会⾃自动创建索引3.修改auto_create_index状态PUT localhost:9200/_cluster/settings{"persistent": {"action.auto_create_index": "false"}}
DELETE "localhost:9200/xdclass/_doc/1"
查看一个文档GET localhost:9200/nba/_doc/1查看多个文档POST localhost:9200/_mget{"docs" : [{"_index" : "nba","_type" : "_doc","_id" : "1"},{"_index" : "nba","_type" : "_doc","_id" : "2"}]}POST localhost:9200/nba/_mget{"docs" : [{"_type" : "_doc","_id" : "1"},{"_type" : "_doc","_id" : "2"}]}POST localhost:9200/nba/_doc/_mget{"docs" : [{"_id" : "1"},{"_id" : "2"}]}
{"docs" : [{"_index" : "nba","_type" : "_doc","_id" : "1","_version" : 1,"_seq_no" : 0,"_primary_term" : 1,"found" : true,"_source" : {"name" : "哈登","team_name" : "⽕火箭","position" : "得分后卫","play_year" : "10","jerse_no" : "13"}}
POSTlocalhost:9200/nba/_update/1跟新字段{"doc": {"name": "哈登","team_name": "⽕火箭","position": "双能卫","play_year": "10","jerse_no": "13"}}向_source字段,增加⼀一个字段POST localhost:9200/nba/_update/1{"script": "ctx._source.age = 18"}从_source字段,删除⼀一个字段POST localhost:9200/nba/_update/1{"script": "ctx._source.remove(\"age\")"}根据参数值,更新指定文档的字段POST localhost:9200/nba/_update/1{"script": {"source": "ctx._source.age += params.age","params": {"age": 4}}}upsert 当指定的⽂档不存在时,upsert参数包含的内容将会被插入到索引中,作为⼀个新文档;如果指定的⽂文档存在,ElasticSearch引擎将会执行指定的更新逻辑。POST localhost:9200/nba/_update/3{"script": {"source": "ctx._source.allstar += params.allstar","params": {"allstar": 4}},"upsert": {"allstar": 1}}
DELETE localhost:9200/nba/_doc/1
二、IK分词器和Es数据类型
1、IK分词器
- 什么是分词器
- 将⽤用户输⼊入的⼀一段⽂文本,按照⼀一定逻辑,分析成多个词语的一种⼯具
- 常⽤用的内置分词器器
- standard analyzer
- simple analyzer
- whitespace analyzer
- stop analyzer
- language analyzer
- pattern analyze
安装IK分词器后测试:
curl -X POST "localhost:9200/_analyze"{"analyzer": "ik_max_word","text": "⽕火箭明年年总冠军"}
2、Es数据类型有哪些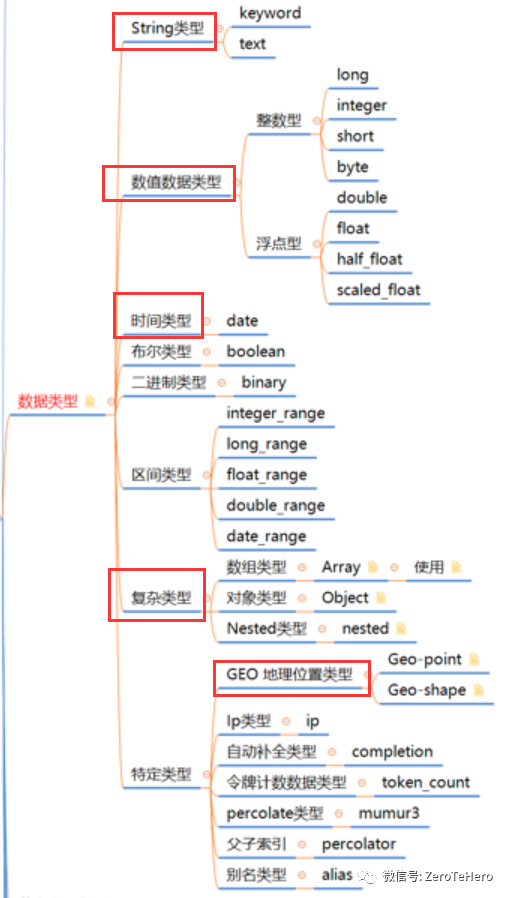
1、核心数据类型
字符串
text
⽤用于全⽂文索引,该类型的字段将通过分词器器进⾏行行分词
keyword
不不分词,只能搜索该字段的完整的值数值型
long, integer, short, byte, double,float, half_float, scaled_float
布尔- boolean
- ⼆二进制- binary
- 该类型的字段把值当做经过base64编码的字符串串,默认不不存储,且不不可搜索
- 范围类型
- 范围类型表示值是⼀一个范围,⽽而不不是⼀一个具体的值
- integer_range,float_range, long_range, double_range, date_range
- 譬如age的类型是integer_range,那么值可以是{“gte” : 20, “lte” : 40};搜索”term” :
{“age”: 21}可以搜索该值
- ⽇日期- date
- 由于Json没有date类型,所以es通过识别字符串串是否符合format定义的格式来判断是否为date类型
- format默认为:strict_date_optional_time||epoch_millis
- 格式
- “2022-01-01” “2022/01/01 12:10:30”这种字符串串格式
- 从开始纪元(1970年年1⽉月1⽇日0点)开始的毫秒数
- 从开始纪元开始的秒数
2、复杂数据类型
- 数组类型Array
- ES中没有专⻔门的数组类型,直接使⽤用[]定义即可,数组中所有的值必须是同⼀一种数据类
型,不不⽀支持混合数据类型的数组: - 字符串串数组[ “one”, “two” ]
- 整数数组[ 1, 2 ]
- Object对象数组[ { “name”: “Louis”, “age”: 18 }, { “name”: “Daniel”, “age”: 17 }]
- 同⼀一个数组只能存同类型的数据,不不能混存,譬如[ 10, “some string” ]是错误的
- ES中没有专⻔门的数组类型,直接使⽤用[]定义即可,数组中所有的值必须是同⼀一种数据类
- 对象类型Object
- 对象类型可能有内部对象
3、专用数据类型
- IP类型
- IP类型的字段⽤用于存储IPv4或IPv6的地址,本质上是⼀一个⻓长整型字段。
三、搜索的简单使用(最为重要的知识点)
- term(词条)查询和full text(全⽂文)查询
- 词条查询:词条查询不会分析查询条件,只有当词条和查询字符串完全匹配时,才匹配搜索。
- 全⽂文查询:ElasticSearch引擎会先分析查询字符串,将其拆分成多个分词,只要已分析的字段中包含词条的任意一个,或全部包含,就匹配查询条件,返回该⽂档;如果不不包含任意⼀个分词,表示没有任何⽂文档匹配查询条件。
单条POST localhost:9200/nba/_search{"query":{"term":{"jerse_no":"23"}}}
POST localhost:9200/nba/_search{"query": {"match_all": {}},"from": 0,"size": 10}
``` POST localhost:9200/nba/_update/ { “doc”: { “name”: “库里”, “team_name”: “勇⼠”, “position”: “控球后卫”, “play_year”: 10, “jerse_no”: “30”, “title”: “the best shooter” } }POST localhost:9200/nba/_search{"query": {"match": {"position": "后卫"}}}
POST localhost:9200/nba/_search { “query”: { “multi_match”: { “query”:”shooter”, “fields”:[“title”,”name”] } } }
<a name="zxuzI"></a>#### 四、搜索的进阶使用1、es之批量导入数据
POST “localhost:9200/_bulk” -H ‘Content-Type: application/json’ —data-binary @name
2、es之term的多种查询- 介绍- 单词级别查询- 这些查询通常用于结构化的数据,⽐比如:number, date, keyword等,⽽不是对text。- 也就是说,全⽂本查询之前要先对文本内容进行分词,⽽单词级别的查询直接在相应字段的反向索引中精确查找,单词级别的查询⼀般⽤用于数值、日期等类型的字段上。
POST nba/_search { “query”: { “term”: { “jerseyNo”: “23” } } }
```POST nba/_search{"query": {"exists": {"field": "teamNameEn"}}}
POST nba/_search{"query": {"prefix": {"teamNameEn": "Rock"}}}
*表示任意字符,?表示任意单个字符POST nba/_search{"query": {"wildcard": {"title": "*sh*"}}}
POST nba/_search{"query": {"regexp": {"title": ".*er"}}}
*查找id为1和2的球员POST nba/_search{"query": {"ids": {"values": [1,2]}}}
3、es的范围查询
#查找在nba打了了2年年到10年年以内的球员POST nba/_search{"query": {"range": {"playYear": {"gte": 2,"lte": 10}}}}#查找1980年年到1999年年出⽣生的球员POST nba/_search{"query": {"range": {"birthDay": {"gte": "01/01/1999","lte": "2022","format": "dd/MM/yyyy||yyyy"}}}}
4、布尔查询
四、Elasticsearch深入挖掘elastic search的原理
一、ElasticSearch分布式工作原理
简介:带你剖析ElasticSearch分布式工作原理
- Elasticsearch是分布式的,但是对于我们开发者来说并未过多的参与其中,我们只需启动对
应数量的节点,并给它们分配相同的cluster.name让它们归属于同⼀个集群,创建索引时候只需指定索引主分⽚片数和副分⽚片数即可,其他的都交给了了ES内部⾃⼰去实现。 - 这和数据库的分布式和同源的solr实现分布式都是有区别的,数据库要做集群分布式,⽐如分库分表需要我们指定路由规则和数据同步策略等,包括读写分离,主从同步等,solr的分布式也需依赖zookeeper,但是Elasticsearch完全屏蔽了这些。
- 虽然Elasticsearch天生就是分布式的,并且在设计时屏蔽了了分布式的复杂性,但是我们还得知道它内部的原理。
节点交互原理: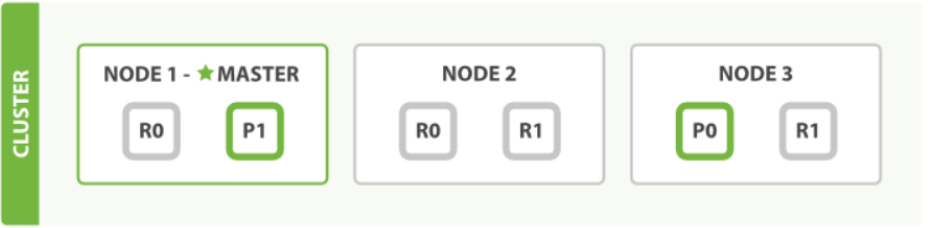
- es和其他中间件⼀一样,⽐比如mysql,redis有master-slave模式。es集群也会选举⼀个节点做为master节点。
- master节点它的职责是维护全局集群状态,在节点加入或离开集群的时候重新分配分⽚。
- 所有文档级别的写操作不会与master节点通信,master节点并不需要涉及到文档级别的变更和搜索等操作,es分布式不不太像mysql的master-slave模式,mysql是写在主库,然后再同步数据到从库。而es⽂档写操作是分片上而不是节点上,先写在主分片,主分片再同步给副分片,因为主分片可以分布在不同的节点上,所以当集群只有⼀个master节点的情况下,即使流量的增加它也不会成为瓶颈,就算它挂了,任何节点都有机会成为主节点。
- 读写可以请求任意节点,节点再通过转发请求到目的节点,⽐如⼀个文档的新增,文档通过路由算法分配到某个主分片,然后找到对应的节点,将数据写入到主分片上,然后再同步到副分片上。
写入文档: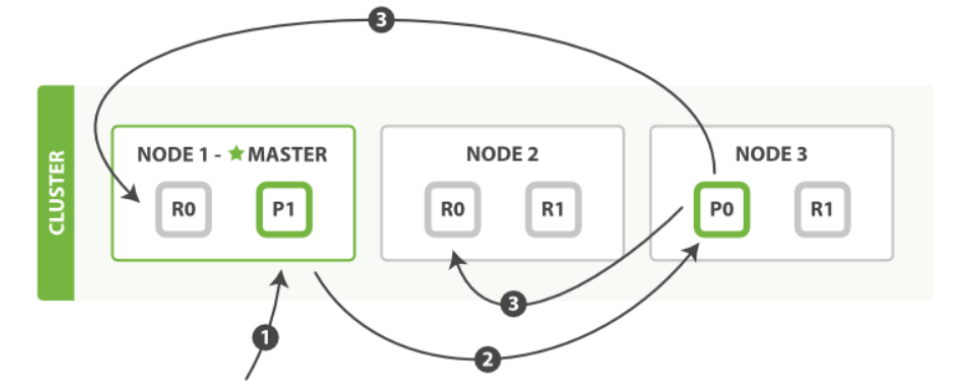
- 客户端向node-1发送新增文档请求。
- 节点通过文档的路由算法确定该文档属于主分片-P0。因为主分片P0在node-3节点,所以请求会转发到node-3。
- 文档在node-3的主分片-P0上新增,新增成功后,将请求转发到node-1和node-2对应的副分片-R0上,一旦所有副分片都报告成功,node-3向node-1报告成功,node-1向客户端报告成功。
读取文档:
- 客户端向node-1发送读取⽂档请求。
在处理理读取请求时,node-1在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。
二、elastic search⽂档的路由原理
简介:当新增一个文档时,这个文档会存放在那个分片中呢?
路由算法
- 首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了了。实际上,这个过程是根据下⾯这个公式决定的:
shard = hash(routing) % number_of_primary_shards
- 首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了了。实际上,这个过程是根据下⾯这个公式决定的:
routing是⼀个可变值,默认是⽂档的_id,也可以设置成⼀个自定义的值。routing通过hash函数⽣成一个数字,然后这个数字再除以number_of_primary_shards(主分片的数量)后得到余数。这个分布在0到number_of_primary_shards-1之间的余数,就是我们所寻求的⽂档所在分片的位置。
这就解释了为什什么我们要在创建索引的时候就确定好主分片的数量并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
新增一个文档(指定id)PUT /nba/_doc/1{"name": "哈登","team_name": "⽕火箭","position": "得分后卫","play_year": "10","jerse_no": "13"}
查看⽂档在哪个分⽚上:
GET /nba/_search_shards?routing=1{"nodes": {"V1JO7QXLSX-yeVI82WkgtA": {"name": "node-1","ephemeral_id": "_d96PgOSTnKo6nrJVqIYpw","transport_address": "192.168.1.101:9300","attributes": {"ml.machine_memory": "8589934592","xpack.installed": "true","ml.max_open_jobs": "20"}},"z65Hwe_RR_efA4yj3n8sHQ": {"name": "node-3","ephemeral_id": "MOE_Ne7ZRyaKRHFSWJZWpA","transport_address": "192.168.1.101:9500","attributes": {"ml.machine_memory": "8589934592","ml.max_open_jobs": "20","xpack.installed": "true"}}},"indices": {"nba": {}},"shards": [[{"state": "STARTED","primary": true,"node": "V1JO7QXLSX-yeVI82WkgtA","relocating_node": null,"shard": 2,"index": "nba","allocation_id": {"id": "leX_k6McShyMoM1eNQJXOA"}},{"state": "STARTED","primary": false,"node": "z65Hwe_RR_efA4yj3n8sHQ","relocating_node": null,"shard": 2,"index": "nba","allocation_id": {"id": "6sUSANMuSGKLgcIpBa4yYg"}}]]}
三、剖析elastic search的乐观锁
简介:剖析elastic search的乐观锁
锁的简单分类
- 悲观锁
顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞,直到它拿到锁。传统的关系型数据库⾥里边就⽤到了很多这种锁机制,⽐如行锁,表锁等,读锁,写锁等,都是在做操作之前先上。 - 乐观锁顾名思义,就是很乐观,每次去拿数据的时候都认为别⼈不会修改,所以不会上锁,但是在更新的时候会判断⼀下在此期间别人有没有去更新这个数据,⽐如可以使用版本号等机制。乐观锁适⽤用于多读的应用类型,这样可以提高吞吐量,因为我们elasticsearch⼀般业务场景都是写少读多,所以通过乐观锁可以在控制并发的情况下又能有效的提⾼系统吞吐量。
- 悲观锁
- 版本号乐观锁
- Elasticsearch中对⽂文档的index,GET和delete请求时,都会返回⼀一个_version,当⽂文档被修改时版本号递增。
- 所有⽂档的更新或删除API,都可以接受version参数,这允许你在代码中使用乐观的并发控制,这里要注意的是版本号要⼤于旧的版本号,并且加上version_type=external。
- 获取文档 ``` GET /nba/_doc/1 { “_index”: “nba”, “_type”: “_doc”, “_id”: “1”, “_version”: 1, “_seq_no”: 4, “_primary_term”: 7, “found”: true, “_source”: { “name”: “哈登”, “team_name”: “⽕火箭”, “position”: “得分后卫”, “play_year”: “10”, “jerse_no”: “13” } }
- 通过版本号新增文档(version要⼤于旧的version)
POST /nba/_doc/1?version=2&version_type=external { “name”: “哈登”, “team_name”: “⽕火箭”, “position”: “得分后卫”, “play_year”: “10”, “jerse_no”: “13” }
<a name="fVioY"></a>#### 四、什么是倒排索引**假设文档集合如下**:<br />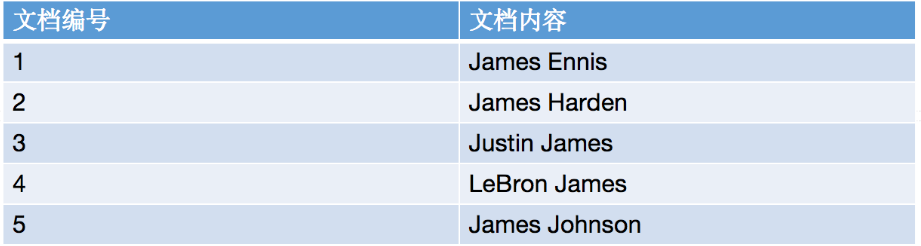- 我们是怎么通过james查找到名字带有james的球员呢?- 如果按照这个图,我们是不是得把这5个文档遍历⼀遍,把文档带有james的球员查找出来?- 如果按照这种顺序扫描,那每次输⼊不同的关键字,岂不不是要从头到尾遍历一遍?**假设⽂档集合如下图所示:**<br />- 我们把这个5个球员的名字进行分词,每个分词转成⼩写字⺟,并且以每个分词分组,统计它所在文档的位置。- 当有关键字请求过来的时候,将关键字转成小写,查找出关键字匹配到的文档位置,然后全部返回。<a name="V6jG4"></a>#### 完善倒排索引: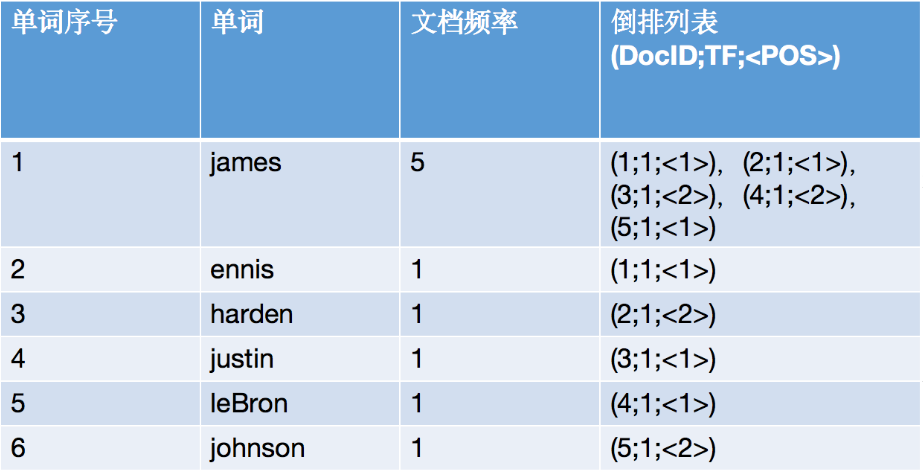- 参数解释- DocId:单词出现的文档id- TF:单词在某个文档中出现的次数- POS:单词在⽂档中出现的位置<a name="w2Lkq"></a>#### 五、浅谈elastic search的分词原理简介:谈谈elasticsearch的分词原理- es语句如下:**写时分词**
中文分词器文档写入的时候会根据字段设置的分词器类型进行分词,如果不指定就是默认的standard分词器。
写时分词器需要在mapping中指定,而且一旦指定就不能再修改,若要修改必须重建索引。
POST /test/_search { “query”: { “match”: { “msg_chinese”: “乔丹是篮球之神” } } } 分词:乔,丹,是,篮,球,之,神 POST /test/_analyze { “field”: “msg”, “text”:”乔丹是篮球之神” } 分词:乔丹, 是, 篮球, 之神 POST /test/_search { “query”: { “match”: { “msg”: “乔” } } }
- 文档写⼊的时候会根据字段设置的分词器类型进行分词,如果不指定就是默认的standard分词器。- 写时分词器需要在mapping中指定,⽽且一旦指定就不能再修改,若要修改必须重建索引。**读时分词器:**- 由于读时分词器默认与写时分词器默认保持一致,拿上面的例子,你搜索msg字段,那么读时分词器为Standard,搜索msg_chinese时分词器器则为ik_max_word。这种默认设定也是非常容易理解的,读写采用一致的分词器,才能尽最大可能保证分词的结果是可以匹配的。- 允许读时分词器单独设置。
POST test/_search { “query”: { “match”: { “msg_chinese”: { “query”: “乔丹丹”, “analyzer”: “standard” } } } }
⼀般来讲不需要特别指定读时分词器,如果读的时候不单独设置分词器,那么读时分词器的验证方法与写时⼀致。<br />**深入分析:**<br />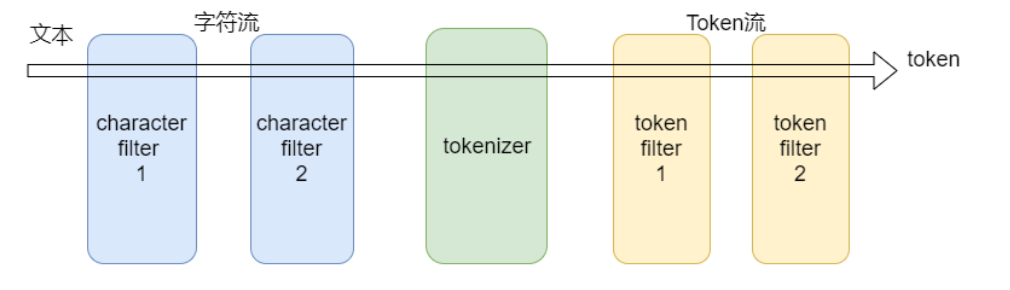- 分析器器(analyzer)有三部分组成- charfilter:字符过滤器- tokenizer:分词器- tokenfilter:token过滤器- charfilter(字符过滤器)- 字符过滤器器以字符流的形式接收原始⽂文本,并可以通过添加、删除或更更改字符来转换该流。⼀个分析器器可能有0个或多个字符过滤器器。- tokenizer(分词器)- ⼀个分词器接收⼀个字符流,并将其拆分成单个token(通常是单个单词),并输出一个token流。⽐如使用whitespace分词器当遇到空格的时候会将⽂本拆分成token。"eating an apple" >> [eating, and, apple]。一个分析器必须只能有⼀个分词器。
POST _analyze { “text”: “eating an apple”, “analyzer”: “whitespace” } ```
- tokenfilter(token过滤器)
- token过滤器器接收token流,并且可能会添加、删除或更更改tokens。⽐比如⼀一个lowercase token filter可以将所有的token转成⼩写。⼀个分析器可能有0个或多个token过滤器,它们按顺序应用。
- standard分析器器
- tokenizer
- Stanard tokenizer
- tokenfilters
- Standard Token Filter
- Lower Case Token Filter
- tokenizer

若有收获,就点个赞吧
0 人点赞
