dump:存储memory management:内存管理
https://www.cnblogs.com/qlqwjy/p/9763754.html
1. 下载安装
2. 常用数据类型
2.1 string
- 按
String元素插入顺序拍讯,数据后进先出,类似于栈(stock) - 构建一个
list- 从左边开始添加数据:
lpush userList 1,2,3,4 - 从右边开始添加数据:
rpush studentList mark,lihua,mary
- 从左边开始添加数据:
- 取数据
- 通过分数来对集合中的成员进行从小到大的排序
zset也叫sorted set,可以去重排序比如可以根据用户积分做排序,积分作为
set的值,set中的每一个nemeber都带一个分数3. 与SpringBoot整合
半仙老师指导:直接使用
RedisTemplate存储对象的时候,对象必须是可序列化的,- 风间老师指导:否则使用
StringRedisTemplate,通过Json序列化工具 直接使用
RedisTemplate会产生Jdk的序列化,在查看的时候会乱码,建议使用StringRedisTemplate4. 发布订阅模式
角色
- 发布者
(publish)发布消息到生产者 - 订阅者
(subscribe)订阅消息消费者
- 发布者
- 订阅的命令:
subscribe channel...(channel:频道 名称,可同时订阅多个,空格隔开) - 批量的订阅:
psubscribe imooc*(使用通配符订阅"imooc"开头的所有频道) 发布消息的命令:
publish channel message5. 键空间通知
5.1 概念与设置
它是基于发布订阅模式实现的,订阅某个频道之后,可以接受频道的事情
- redis收到某种事件的影响,比如”删除一个键”、”新增一个键”、”一个键过期”这些事件,这时候redis会发布一个通知,这时候我们就可以使用这个通知做事情
- 通知类型
- Key-speac: 通知事件的类型,比如删除一个键、过期一个键
- Key-event: 通知事件的内容,比如删除键的key
- https://class.imooc.com/lesson/1207#mid=30837
5.2 实战应用
解决延迟支付中,超期未支付的”库存归还”、”订单状态关闭”、”优惠券归还”问题
6.1 redis.conf文件解析
redis.conf:它是核心配置文件,在服务器启动的时候就会加载该文件,持久化都是在该文件内配置6. 持久化
不管是RDB、AOF在创建存储数据文件的时候,都是fork子进程。这里非常像进程的“master-worker”模式,这个模式在“ForkJoinPool”中也有应用。查看架构师大目老师讲解的优化章节
6.2 RDB方式
6.2.1 实际配置
- 快照持久化
(RDB redis database):保存某个时间点的全量数据快照,设置之后是每个一段时间进行这个时间点的全量数据备份 - 进入
redis.conf文件搜索"snapshotting",第一行就是相关配置 - 持久化时间策略的含义:表示在过去的给定时间内发生了多少次更改,进行一次备份,最开始的时间则从
redis服务启动开始save seconds changes:持久化时间策略配置save 900 1:在距离上一次变动的,15分钟内只发生1次更改save 300 10:在距离上一次变动的,5分钟内发生10次更改save 60 10000:在距离上一次变动的,1分钟内发生1万次更改
- 常用配置
stop-writes-on-bgsave-error yes:当备份进程出错误的时候,主进程就停止接收新的写入操作,这样就可以保护持久化的数据一致性问题rdbcompression yes:表示在被备份时将文件压缩后才做保存,建议设置为nosave "":禁用RDB配置
系统在设置RDB持久化之后会在一定时间内生成:
dump.rdb,该文件生成的目录是自行设置的例如:dir /usr/local/redis/working,每次备份都会把上一次的dump.rdb文件覆盖6.2.2 rdb文件的创建和载入
(1) 生成RDB文件的两个命令
save:会阻塞redis的进程,直到文件创建完成,很少使用bgsave:派生出fork出一个子进程来创建rdb文件不会阻塞服务进程,子进程进行备份的时候,主进程不会有任何的IO操作(增、删、改),但是可以提供查询操作,保证备份数据的完整性bgsave:创建RDB-
(2) Redis触发RDB持久化的方式
根据
redis.conf里面配置的save m n定时触发,使用的就是bgsave- 主从复制时,主节点自动触发
- 执行
debug reload -
(3) 服务器宕机,rdb文件如何载入redis
-
6.3 AOF方式
6.3.1 实际配置
文件追加持久化方式
(AOF append only file),保存写状态,根据英文名称可知,区别于RDB的全量保存方式,它是在后面追加的,它会记录下除了查询以外的所有变更数据库状态的指令,以append的形式追加保存到AOF文件中(增量保存) 进入
redis.conf文件搜索append only mode,第一行就是相关配置AOF持久化,默认是关闭的 ,默认是RDB方式appendonly no:默认是no,改成yes就表示启动了appendfilename "appendonly.aof":持久化产生的文件名称
- 持久化方式策略:
appendfsync always:一旦缓存区的内容发生变化,就将变化写入到AOF文件中appendfsync everysec:将缓存区的内容每隔一秒写入到AOF文件中appendfsync no:表示将写入操作交给OS管理,一般为提高效率OS会等缓存区填满,开始同步数据到磁盘中
-
6.3.2 日志重写解决AOF文件不断增大问题
原理是写实复制
copy-on-writer- 基本流程是
- 主进程
fork一个子进程 - 子进程把已经
AOF持久化的内容写入到一个临时文件里面,不依赖原来的AOF文件 - 主进程持续将新的变动持续写入到内存和老的
AOF文件中 - 主进程获取子进程重写
AOF的完成信号,往新AOF同步增量变动 - 使用新的
AOF文件替换掉原来的AOF文件
- 主进程
触发条件设置(和
hashmap的链表转换为树结构的扩容原理很像)优势:数据都是全量保存进内存中,大数据的容灾和恢复会比较容易和简单,并且进行的备份的时候会有一个子进程进行备份,此时主进程不会有写和删除的操作
- 劣势:数据完整性会有一定的缺失,系统宕机可能会丢失最后一次保存的数据
劣势:派生出
fork出一个子进程来创建rdb文件不会阻塞服务进程,该子进程对cpu的消耗会非常高,导致服务缓慢等(2) AOF的优劣势
优势:AOF是以日志的形式,来记录所有的写指令,当系统有新的写指令的时候,会以追加文件的形式记录信息,数据完整性比较好,因为数据是时实备份的
(3) 生产实战冷热备份
RDB是默认开启的,AOF是默认关闭的,在生产环境里面,两个都是要开启的
- AOF是为了解决数据持久化的实时性,作为数据热备份
-
6.3.4
bgsave原理7. redis的缓存过期处理与内存淘汰机制
7.1 redis的key过期的基本原则
虽然
key过期了,但是redis不会第一时间将key从内存中清理出去只要
redis不清理它,它依然在内存中被占用着,只是调用者感觉不到,认为它已经过期了7.2 主动定时删除
定时随机检查过期的
key,如果过期则删除-
7.3 被动惰性删除
当客户端请求一个
key的时候,redis会检测key是否过期,过期则删除key并返回一个nil这种策略对
cpu比较友好,不会有太多的损耗,但是内存占用会比较高7.4 按照内存使用率删除
max memory:到内存已使用率到达,则开始清理缓存,下面的每个配置都是到达设置的内存使用率才会生效noeviction:旧缓存永不过期,新缓存设置不了,返回错误allkeys-lru:清除最少用的旧缓存,然后保存新的缓存(推荐使用)allkeys-random:在所有的缓存中随机删除(不推荐)volatile-lru:在那些设置了expire过期时间的缓存中,清除最少用的旧缓存,然后保存新的缓存volatile-random:在那些设置了expire过期时间的缓存中,随机删除缓存volatile-ttl:在那些设置了expire过期时间的缓存中,删除即将过期的8. redis集群
8.1 主从复制
8.1.1 了解什么是主从模式
该模式也叫读写分离,是对redis的一个水平扩展,通过增加服务器来提升性能;常见设定(1主1从、1主2从)master:增删改操作,slave:读操作8.1.2 如何配置
准备三个节点的服务器,准备redis环境
配置要求:1个master、两个slave
在控制台输入:info replication,查看主从配置,在没有配置的情况下都是role:master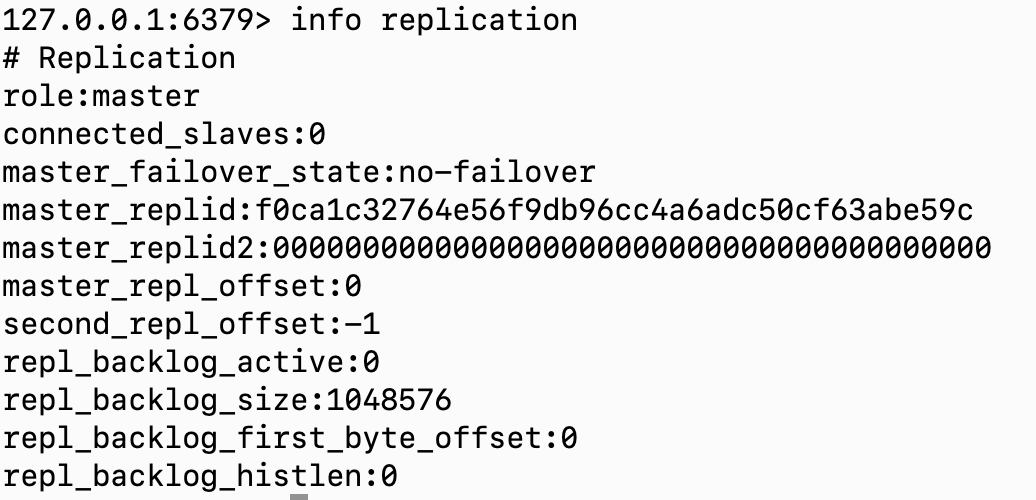
配置第一台节点,进入redis.conf文件,定义该节点为slave节点 ```makefile配置master节点的ip和端口(必须配置)replicaof
replicaof 192.168.1.191 6379
主节点的密码(能保证在内网,也可不配置)masterauth
masterauth 199702
当连接到 master 上时 slave 所用来认证的密码(必须配置)masteruser
Masteruser yihua
表示slave只能读,不能写
replica-serve-stale-data yes
配置完成之后输入`info replication`,查看节点信息<br />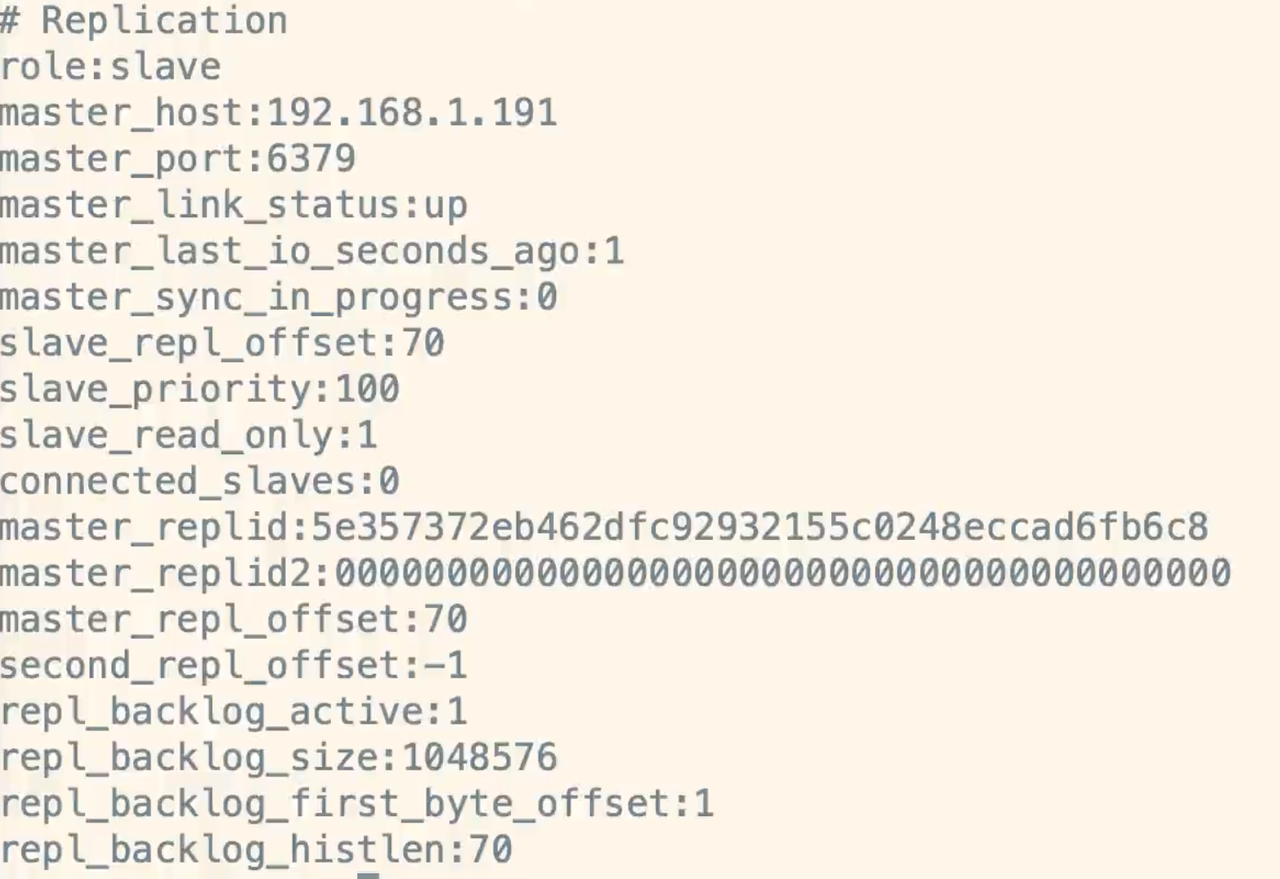<br />第二台`slave`节点配置和第一个节点的`slave`一样<br />配置master节点<br />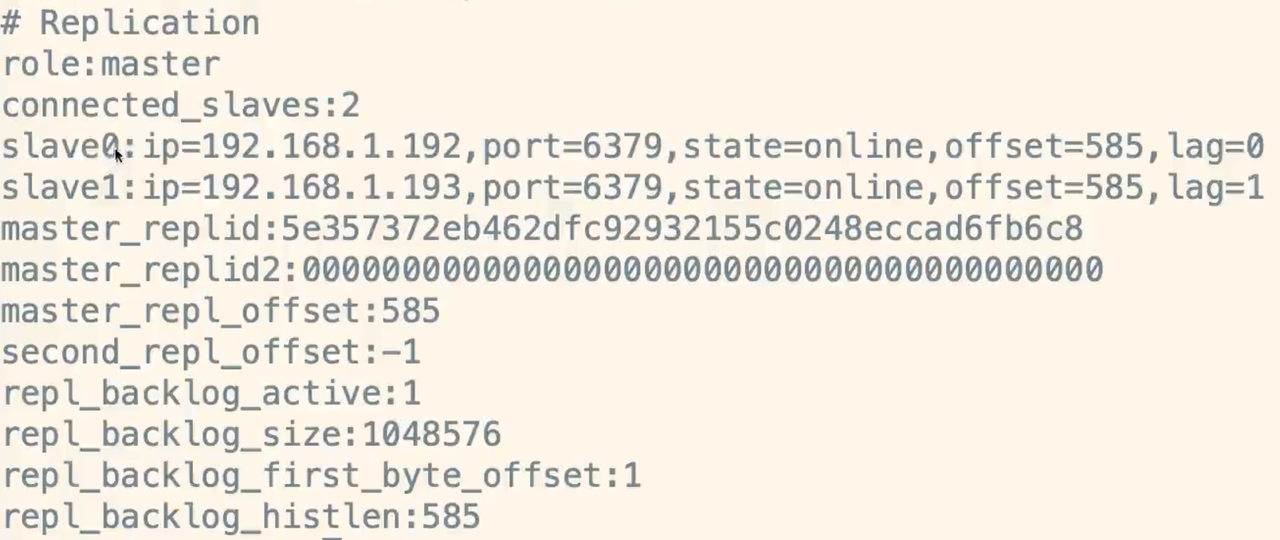<a name="a70cZ"></a>### 8.1.3 数据同步流程1. 第一步:全同步过程,也就是初始化的过程1. 先启动`master`节点,再启动`slave`节点1. `slave`发送`sync`命令到`master`,也就是异步的`ping master`1. `bgsave`操作:`master fork`一个后台进程,将`redis`数据快照保存到文件中(生成RDB文件)1. `master`将保存数据快照期间的写命令缓存起来1. 将生成的`RDB`文件发送给`slave`,`slave`使用新的`RDB`文件替换旧的`RDB`文件,`slave`接收到文件将文件保存到磁盘中,然后加载进内存,去恢复数据快照1. `master`将这期间收集到的增量写命令发送到`slave`端2. 第二部:增量同步过程1. `master`接收到用户的操作指令,判断是否需要传播到`slave`1. 将该操作记录到`AOF`文件中1. 将操作传播到其它的`slave`:1.对其主从库,2.往响应缓存写入指令1. 将缓存中的数据发送给`slave`<a name="RCigP"></a>## 8.2 哨兵模式<a name="r5qxj"></a>### 8.2.1 主从模式的缺点哨兵`sentinel`可以监控一个或者多个`redis master`服务,以及这些`master`服务的`salve`服务,当`master`服务宕机后,会把某一个`salve` 服务升级为 `master` 服务1. 弊端:不具备高可用性,`master`挂掉之后,`redis`将不能对外提供写入操作1. 解决:`Redis Sentinel`解决主从同步`master`宕机后主从切换问题1. 监控:`sentinel`不断的检查主从服务器是否运行正常1. 提醒:`sentinel`通过API向管理员或其它应用程序发送故障通知1. 自动故障迁移:主从切换;将一个`slave`升级为`master````makefileport 26379pidfile "/usr/local/redis/sentinel/redis-sentinel.pid"dir "/usr/local/redis/sentinel"daemonize yesprotected-mode nologfile "/usr/local/redis/sentinel/redis-sentinel.log"
## 配置哨兵sentinel monitor mymaster 127.0.0.1 6379 2## 密码sentinel auth-pass <master-name> <password>## master被sentinel认定为失效的间隔时间sentinel down-after-milliseconds mymaster 30000## 剩余的slaves重新和新的master做同步的并行个数sentinel parallel-syncs mymaster 1## 主备切换的超时时间,哨兵要去做故障转移,这个时候哨兵也是一个进程,如果他没有去执## 行,超过这个时间后,会由其他的哨兵来处理sentinel failover-timeout mymaster 180000
8.3 cluster模式
如何配置
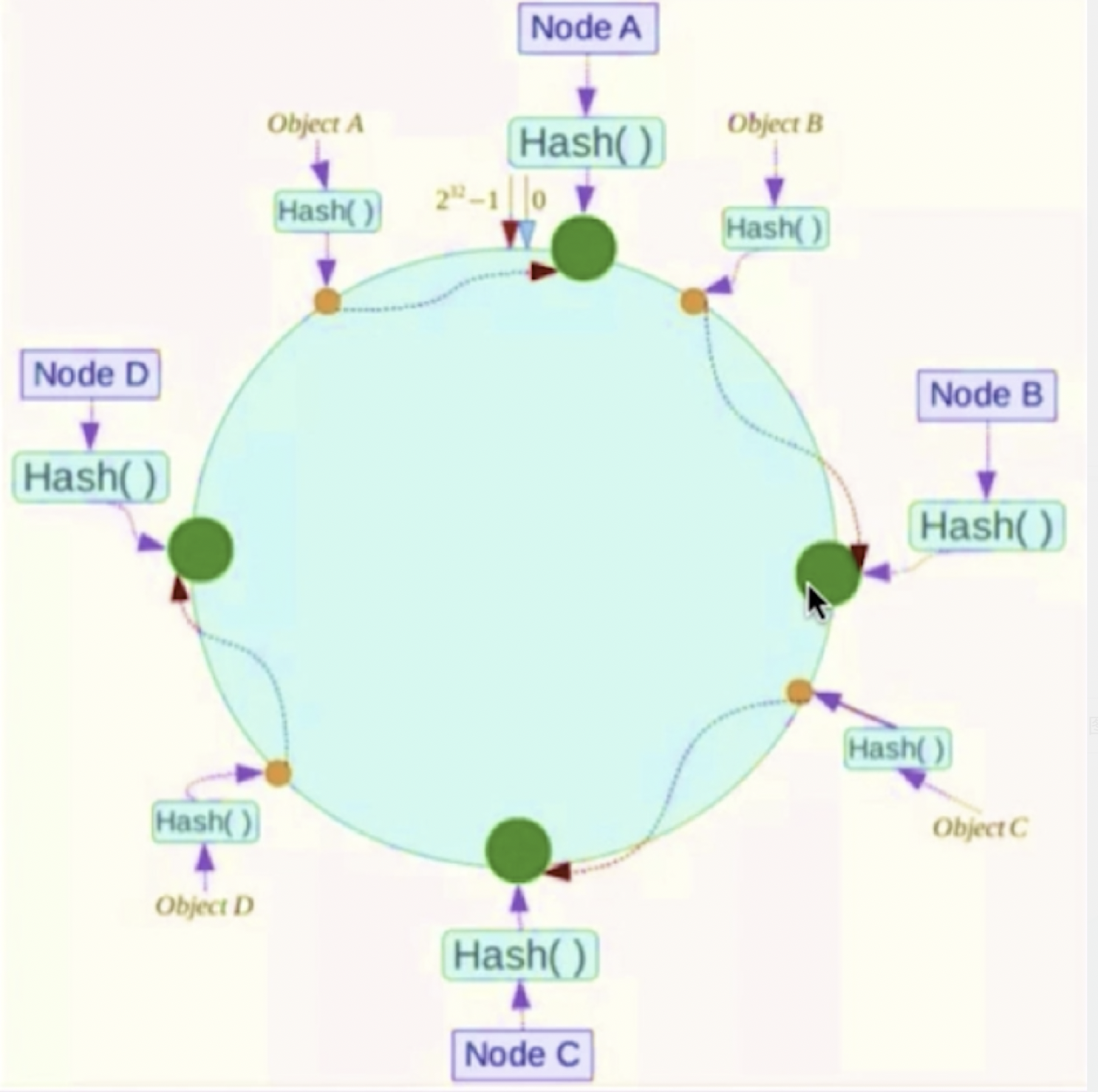
使用槽slots装数据,主节点有,从节点没有(16384个)这些槽会形成一个虚拟圆环;集群采用无中心结构,每个节点保存数据和整个集群的状态。每个节点都和其它节点连接,节点之间使用(流言协议GossIP)传播信息,以及发现新的节点
集群就是要让不同的key放置到redis不同节点中,通常计算key的hash值,来根据节点求模,常规的hash无法实现节点的动态增加,引入一致性hash算法:每个key对2^32进行hash取模hash(key)%16384,形成一个一个slot槽节点,将hash值空间组织成虚拟的圆环
| 将数据key使用相同的函数Hash计算出哈希值 | 集群中服务器宕机 | 集群中新增服务器 |
|---|---|---|
 |
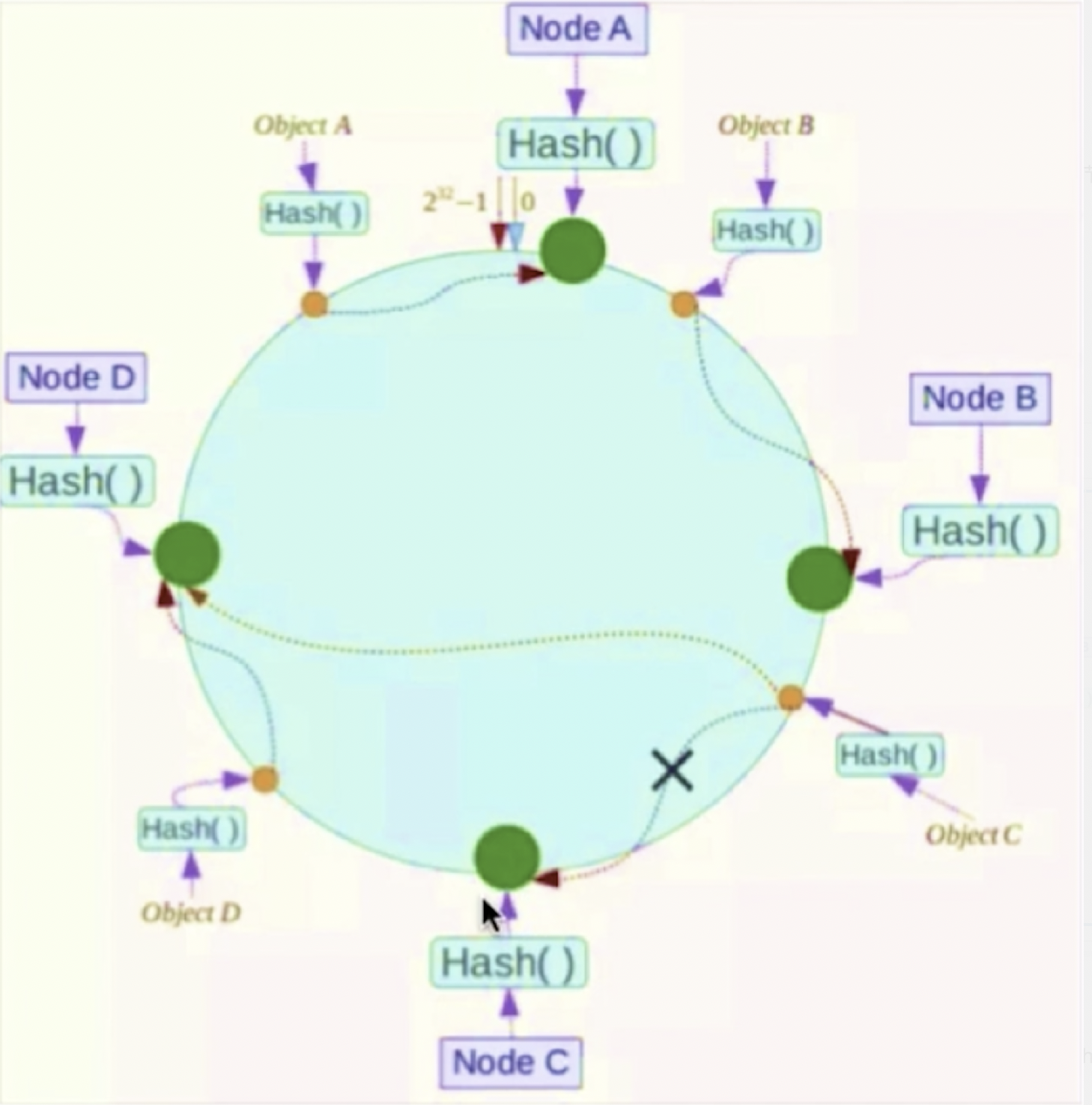 |
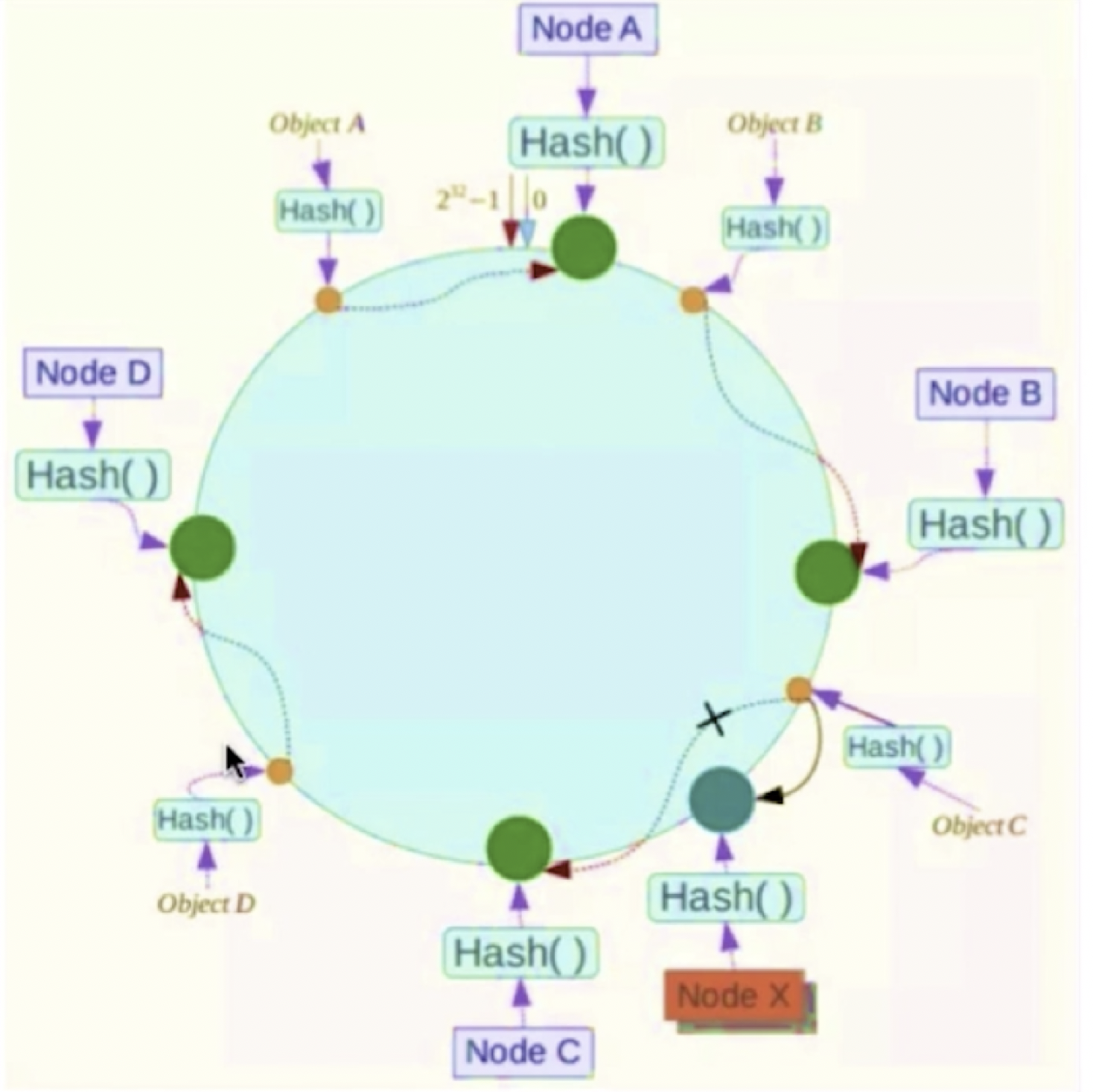 |
hash倾斜问题
- 问题原因:被缓存的数据大部分集中在一个服务器上
- 解决方式:引入虚拟数据节点来解决数据倾斜问题:为每个服务器节点计算多个
hash - 如何实现:例如可以增加编号来实现
| hash环数据倾斜示意图 | 引入虚拟节点的示意图 |
| —- | —- |
|
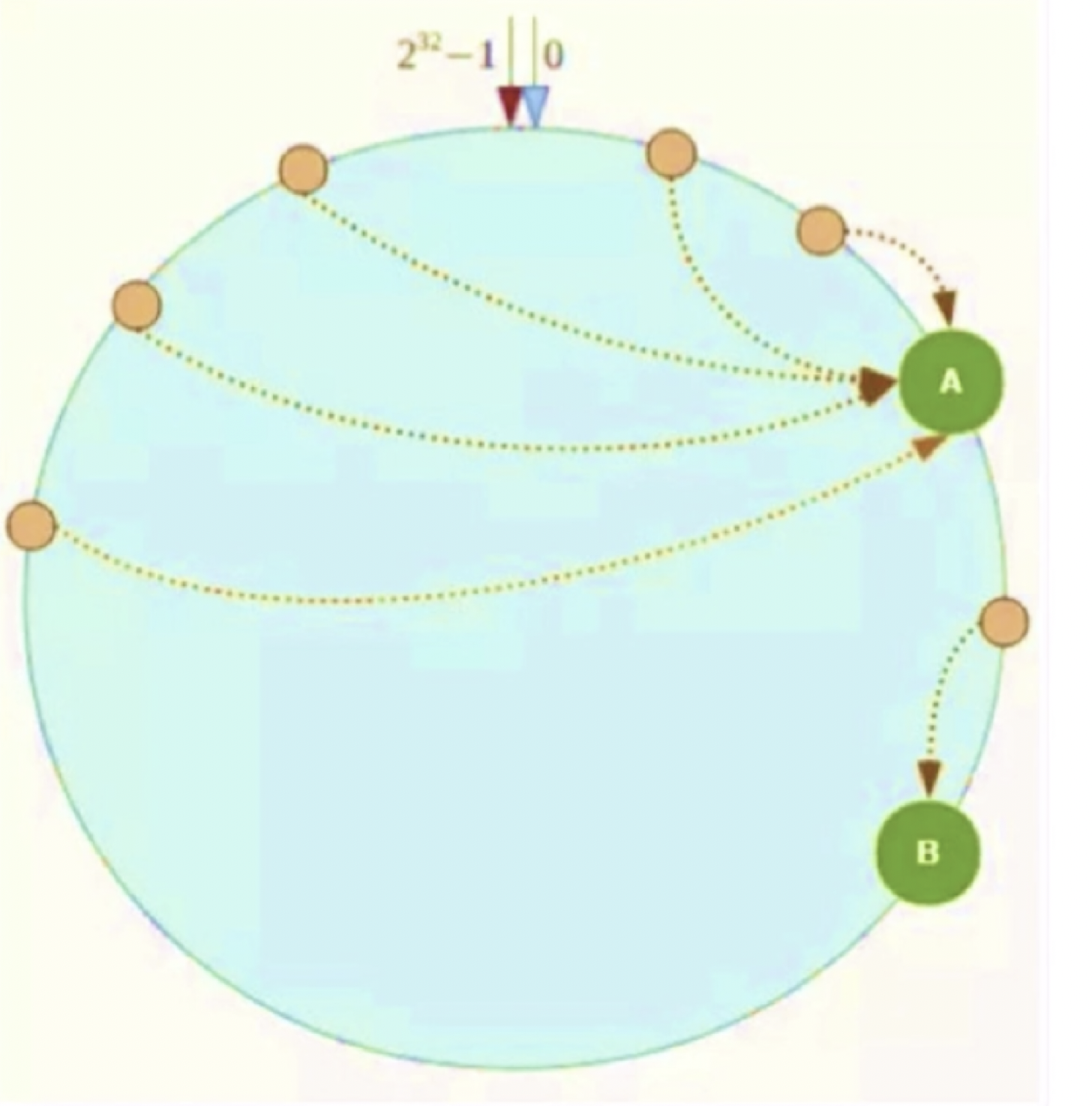 |
|  |
|
9. 缓存产生的问题
9.1 缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库
常见的解决方案
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生
- 设置热点数据永远不过期
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中
- 多级缓存结合
大量key同时过期,服务清除大量缓存,导致系统卡顿的解决方案:在设置key的过期的时候,给每个key设置一个随机字符
9.2 缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据(这里的读取数据通常指大量请求读取同一条数据),又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
常见解决方案
- 设置热点数据永远不过期
- 给相关业务代码加锁互斥
9.3 缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据,这时的用户很可能是攻击者,这时候可能发起百万级别的无效访问,会导致数据库压力过大
常见解决方案
- 业务解决:接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截
架构设计:
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null
- 缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)这样可以防止攻击用户反复用同一个id暴力攻击
布隆过滤器
- 就是一个长长的二进制数组,初始化的时候为0,如果有值就位1。
- 一个位置上面可能存在多个值
- 它存在百分之一的误判断率
- 它不支持数据的删除
通过多个hash运算,key才确定自己的位子,并且可以会散列在多个位子上,加起来才算一个完整的key
面试题
缓存更新的几种方案
前端信息的修改都是在后台管理系统完成的,一旦发生更改,需要删除缓存,然后重置
- 定时重置
- 比如每天凌晨三点,
- 注意:缓存中存在大量数据的时候,不能一次性删除,不然redis扛不住会崩掉
- 不同时间段重置:这个方案,在设置缓存的时候可以设置失效时间,注意散列设置时间
- 轮播图这种广告性质的比较特殊,在设置缓存的时候需要单独的设置时间
Redis 和 Memcache 的区别
redis为什么能那么快
从海量key里面查出固定前缀的key
redis做异步队列(消息队列)

若有收获,就点个赞吧
0 人点赞
