- 1. 海量数据的存储解决方案
- 2. 数据库访问瓶颈解决方案
- 3. MyCat
- 4. 天天吃货架构改造
- 5. Sharding-JDBC
- 6. 分布式全局id
注意:1、2两个项目分析的时候要不考虑其它一条带来的影响,例如
一个数据库之内的切分暂时不考虑,这个是数据库表设计的范畴
例如wiki项目,电子书内容单独拆分一个表,就是表设计问题
分库分表是同时拥有的
1. 海量数据的存储解决方案
分表:可以是本数据库分表这样就是单纯的为了解决海量数据存储问题
分库:分库一定是分表了,既能解决存储问题也能解决数据库访问瓶颈问题
1.1 分表(数据切分)
水平切分:
垂直切分
- 按照业务去切分,例如商品库、订单库、优惠券库,可以同时理解为微服务的领域划分问题
- 每种业务一个数据库
-
2. 数据库访问瓶颈解决方案
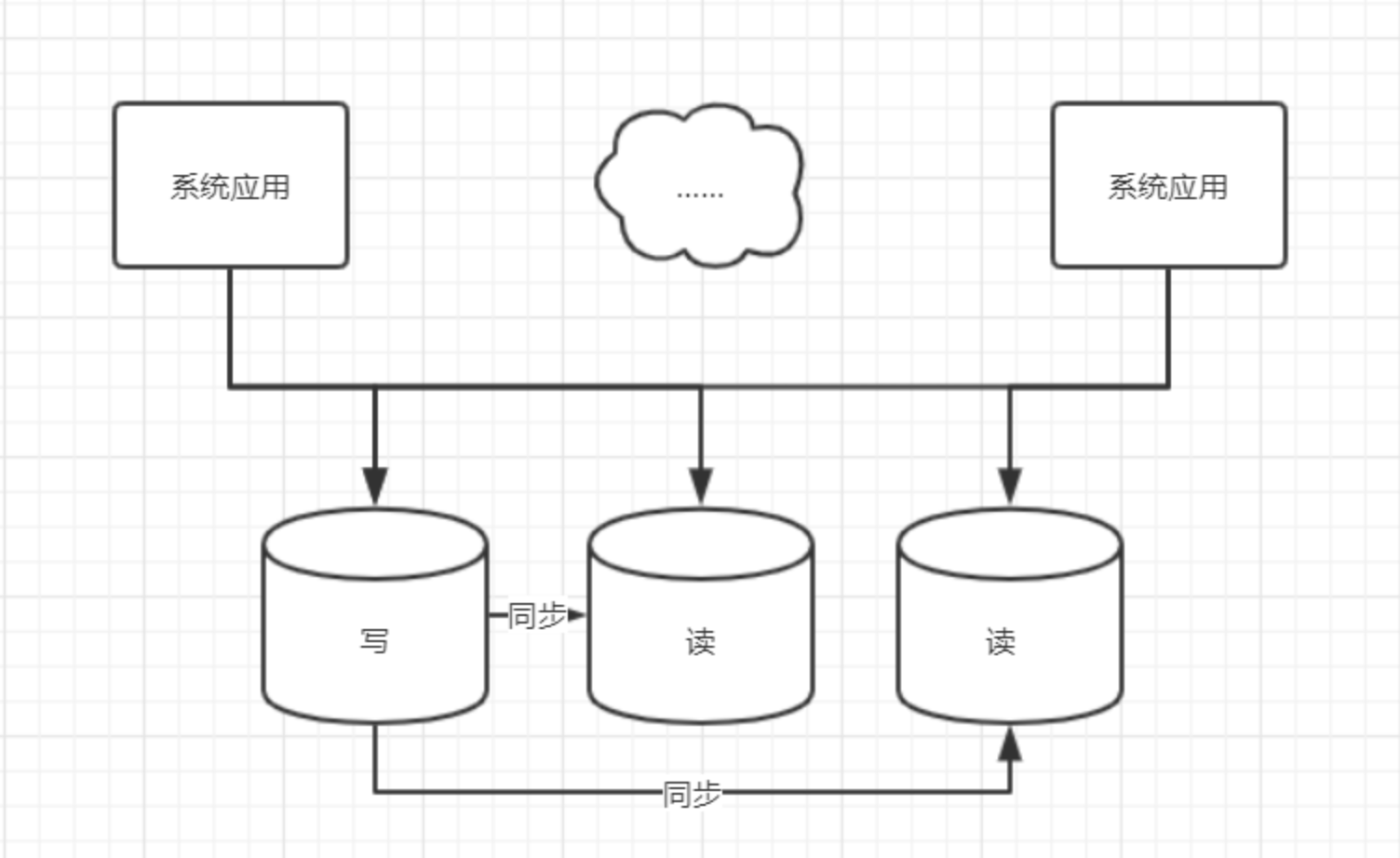
2.1 读写分离
2.2 使用场景
对数据实时性不高的业务场景,可以考虑读写分离
- 对于实时性要求高的场景,不建议使用读写分离,从写库写,还是从写库读取
分库分表如果你的网络延迟在
5ms之内是不错的,可以做到无感知3. MyCat
3.1 原理解析
3.1.1 应用场景
官方文档在:
study/mycat目录- 读写分离:此时配置最为简单,支持读写分离,主从切换
- 分库分表:对于超过
1000万的表进行分片,最大支持1000亿的数据 - 多租户应用:每个应用/服务对应一个数据库,应用只连接
MyCat,程序本身不许要改动 -
3.1.2 实现原理
它的背后是
Cobar,它是基于java开发- 实现了
MySQL的二进制传输协议,巧妙的将自己伪装成一个MySQL Server - MyCat对Cobar进行重构,并优化缓存内核,增强了聚合和join等特性
- MyCat就是一个数据库中间件产品,支持MySQL集群,提供高可用数据分片集群
3.2 下载与安装
```makefile官方网站
http://www.mycat.org.cn/
参考视频
https://class.imooc.com/lesson/1236#mid=29443
官网下载mycat
上传到虚拟机/云服务器
/home/software/mycat
解压软件
tar -zvxf Mycat-server-1.6.7.3-release-20190828135747-linux.tar.gz
移动到指定文件,/usr/mycat
mv mycat/ /usr/mycat
相关配置
….
在mycat的bin目录启动,consolg: 代表日志显示在控制台
./mycat consolg
后台启动方式
./mycat start
<a name="mhAP4"></a>## 3.3 MyCat的简单使用注意mysql8使用新的加密方式,连接客户端呢,暂不支持,要是有mysql native passpord<br />准备3个节点,一台安装MyCat,另外两台安装MySQL,实验MyCat的分库分表<br />[https://class.imooc.com/lesson/1236#mid=29443](https://class.imooc.com/lesson/1236#mid=29443)<a name="hL3kG"></a>## 3.4 配置解析<a name="V56Pt"></a>### 3.4.1 server.xml<a name="gfK5M"></a>#### 3.4.1.1 基础认知1. 是MyCat的基础配置,主要是用来配置用户名、密码、权限、schema(表)等1. 配置完成后如同给MySQL新建用户一样1. 客户端连接MyCat与连接MySQL没有任何差别<a name="p0XYK"></a>#### 3.4.1.2 系统配置模块略<a name="vOUly"></a>#### 3.4.1.3 防火墙配置模块略<a name="ngSlp"></a>#### 3.4.1.4 用户配置模块```makefile## 主要是分为三大模块配置系统配置、防火墙配置、用户配置,前面两者暂时不了解## 用户模块介绍<user name="root" defaultAccount="true"><property name="password">123456</property><property name="schemas">testdb</property><!-- 表级 DML 权限设置 --><privileges check="false"><schema name="TESTDB" dml="0110" ><table name="tb01" dml="0000"></table><table name="tb02" dml="1111"></table></schema></privileges></user><user name="user"><property name="password">user</property><property name="schemas">testdb</property><property name="readOnly">true</property></user>## 一个user标签就代表着一个用户权限## <user name="root" defaultAccount="true">## root: 连接MyCat的用户名## defaultAccount: 是否是默认用户## <property name="password">123456</property>## password: 连接MyCat的密码## <property name="schemas">testdb</property>## schemas: 就是指数据库,配置了那些内容就说明这个用户具有访问哪些数据库的权限## 例如: <property name="schemas">user,order,pay</property>## 上述配置就说明该用户拥有访问user、order、pay的权限## 这里的schemas和schemas.xml里面的配置对应## <property name="readOnly">true</property>## readOnly: 代表该用户拥有只读权限
3.4.2 schema.xml
3.4.2.1 基础认知
dataHost:数据主机,配置你实际连接的数据库的信息dataNode:数据节点,指定到具体的数据库-
3.4.2.2 dataHost
dataHost标签的属性介绍name:数据主机名称maxCon:最大连接数minCon:最小连接数balance:它是查询请求的负载均衡类型,0:不开启读写分离,所有的查询都落在writeHost上1:请求在,全部的读库和其它主库的从主库,随机分配2:所有读操作都随机的在 writeHost、 readhost 上分发3:开启查询的读写分离,所有的查询请求落在读库上,注意从1.4版本开始支持
writeType:当有多个writeHost,写请求的负载策略0:所有的写请求会落在第一个配置的writeHost,当你的第一个写库挂了,请求才会落在后续的writeHost1:表示在所有的writeHost上随机分配,在MyCat1.5之后就废弃
dbType:数据库类型,例如MySQL、MongoDB...dbDriver:数据库驱动
writeHost标签属性介绍dataNode标签属性介绍schema标签属性介绍name:相当于数据库的名称,这个名称相当于一个代理- 例如:命名为
user,那真实的数据库名称可能叫user_1、user_2... - 这里要和s
erver.xml中用户配置的schema对应起来
- 例如:命名为
checkSQLSchema:说实话老师没讲太懂,暂不了解sqlMaxLimit:指检索的时候加上一个limit语句- 例如:设置为
100,查询的时候只会查询100条 - 这个是性能优化做的,例如你的分片库有很多,你全表查询的时候,组装数据太多了,限制一下
- 如果你在写
sql的时候手动加上limit,那么配置的limit将不生效
- 例如:设置为
- dataNode:默认的数据库,不是所有的表都需要进行分片,那么哪些默认的表就会走这个配置
table标签属性介绍,它就是具体的分片表信息注意:
MyCat只是提供读写分离的作用,但是并不控制数据同步,数据同步是MySQL自己配置的事情- 首先
MySQL要完成主从配置,详细信息查看MySQL笔记 - 然后
dataHost标签的balance属性设置为33.5.2 数据库常见的读写模式
1主1从:主食写库,从是读库
1主多从:主是写库、从是读库
2主多从:主库之间互为主从3.6 端口管理
MyCat有两个端口:8066是数据连接、9066是管理端口
可以使用MyCat的9066端口管理MyCat信息,例如reload @@ config、reload @@ config_all在不重启MyCat的情况下重新加载配置文件3.7 常用分片规则
3.7.1 分片逻辑设置
3.7.1.1 分片规则的使用
## 整个流程的分析是"按照id自动分片"来解析的## schema.xml - schema标签 - table标签 - rule属性 - 配置已经存在的规则<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100"><table name="travelrecord" dataNode="dn1,dn2" rule="auto-sharding-long"/></schema>
3.7.1.2 分片规则的实现
```makefileAutoPartitionByLong: 按照id自动分片的实现类
autopartition-long.txt
id: 表示按照表中那个字段进行分片
rang-long: 分片的规则,对应上面的function标签
```makefile## 整个就是配置id如何分片的## range start-end ,data node index;范围开始-结束=数据节点索引## K=1000,M=10000.0-500M=0500M-1000M=11000M-1500M=2
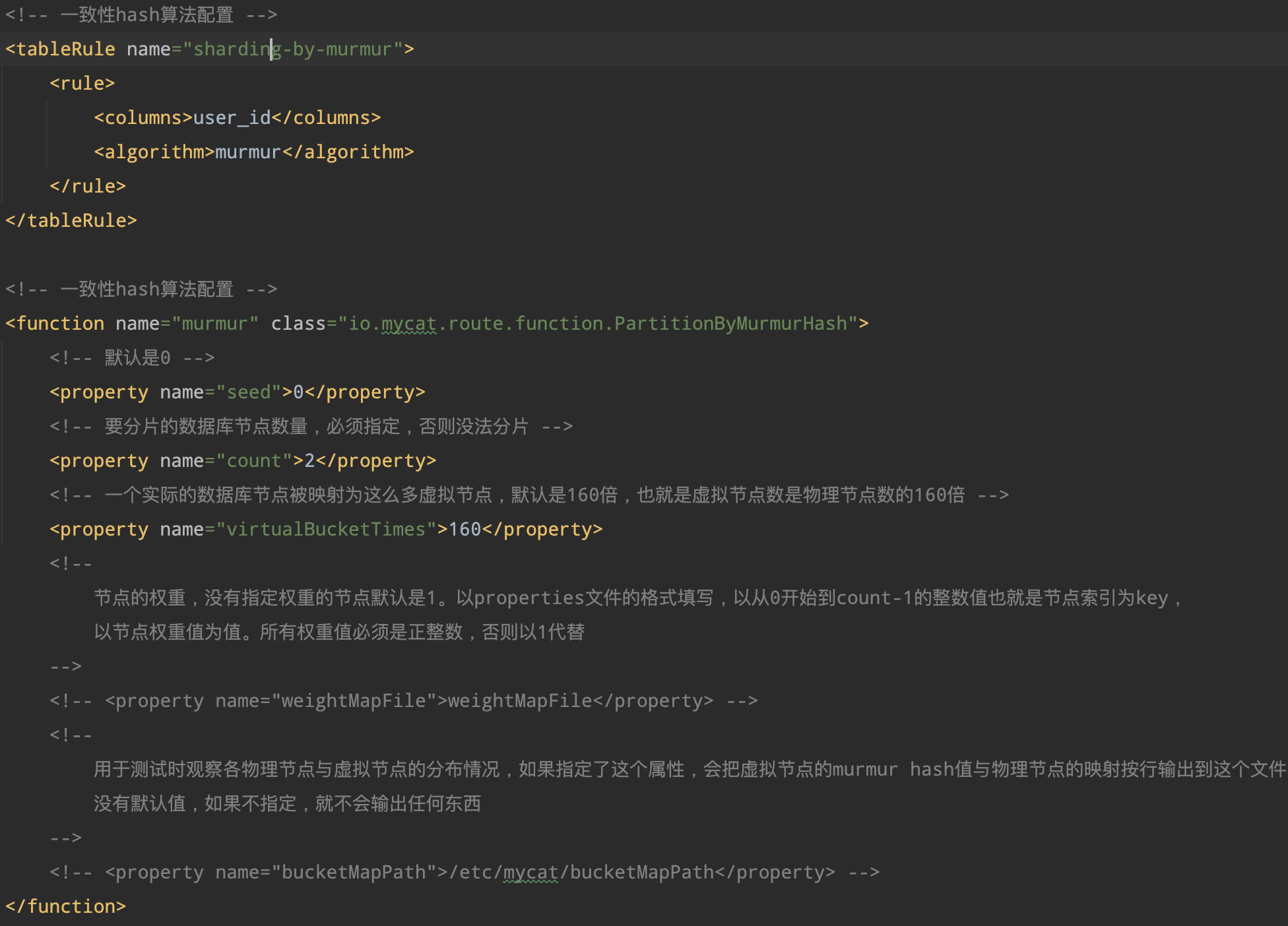
3.7.2 枚举分片
3.7.3 取模分片
3.7.4 其它分片
3.8 常用概念
3.8.1 全局表
- 定义:在没有个数据节点都保存一份相同的表
- 常见的全局表:字典表、可预估的数据量小的表…
- 为什么这么做:关联查询效率更高
如何设置,如果不设置则默认为分片表
定义:按照分片规则,字表数据和主表数据会落在同一个分片上
- 经典的主子表案例:
order、order_item - 为什么这么做:提高查询效率
- 如何设置
schema.xml - schema标签 - table标签 - childTable标签
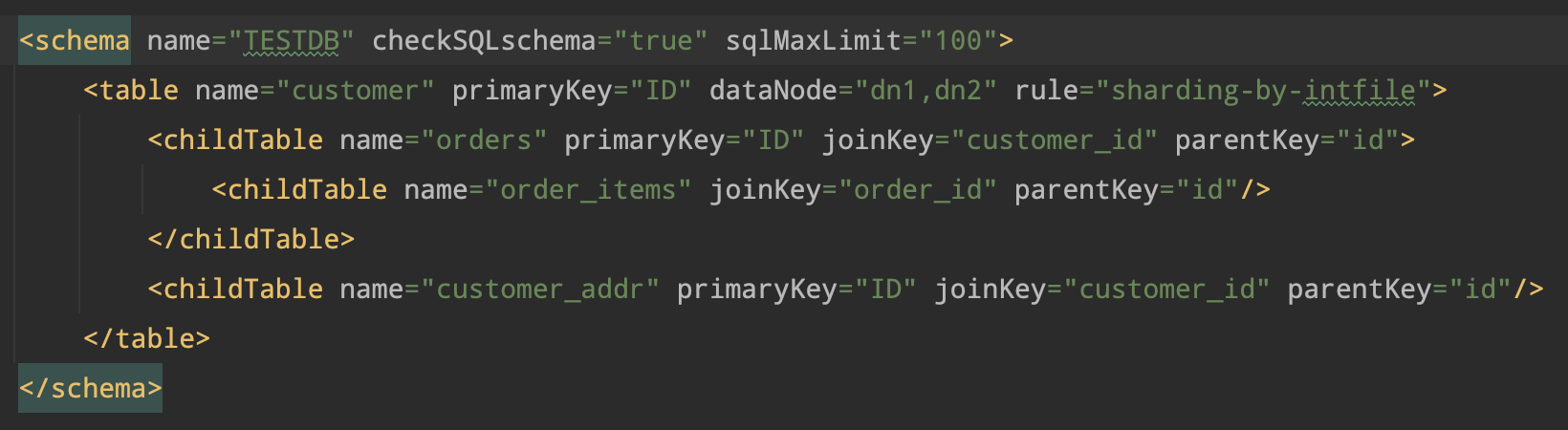
childTable标签随着业务的不断扩展,订单数据呈几何式增伤,需要对订单表进行分库分表
首先
order表做为主表,order_item、order_status作为字表4.1.2 分片逻辑思考☆☆☆
首先关于这个表的对象就三个用户、卖家、平台运营,分片逻辑必须满足至少一种一个对应的查询效能。平台运营作为官方人员,不用担心用户体验,作为次要考虑对象。
4.1.2.1 order_id分片
会导致一个用户的信息随机落到所有的分片节点,对上诉三个对象全都没有效能提升
4.1.2.2 merchant_id分片
选择
merchant_id来进行分片是方便了,卖家查询订单信息-
4.1.2.3 user_id分片
在实际操作中按照
user_id分片还是主流操作,其实上诉三个对象,用户才是平台最最有限考虑的对象- 那么按照这种分片,一个用户的订单会全部落在同一个分片,用户的查询效率将会最高

数据倾斜问题?
电商平台一个大的卖家,每天会产生很多的订单,如果按照merchant_id进行分库分表,那么同一个商家的所有订单会落在同一个分片库中,那么就会使有的表的数据量十分大,有些表的数据量很小
商户查询订单的解决方案?
可以基于bin-log或者flink等准实时的链路同步一张卖家的订单表,这个表只用来查询,不做增删改操作,后续订单新增还是需要根据user_id来进行分库。
这个商家表只需要提供高性能的查询服务,而且没有事务问题。而且可以不使用MySQL,更换为HBase、PolarDB、Lindorm...
用订单号查询怎么优化?
一般订单号查询,是查询固定的一个订单,这时候只需要确认订单所在的分片表,换一种说法只需要确认该订单的user_id即可,那么可以在生成订单的时候把user_id加进去,查询的时候解析出来,条件就变成了 where user_id = xxx and order_id = xxx;
4.2 环境背景


若有收获,就点个赞吧
0 人点赞
