- 1. 主流的应用场景(其它MQ同理)
- 2. 环境搭建
- 2.1 服务端配置说明
- 2.2 搭建
zookeeper集群 - 2.3 搭建
kafka集群 - 可以直接在zk集群的三台服务器上搭建kafka集群
- 下载kafka安装包
- 上传文件到服务器,或者上传一个之后使用copy命令
- 解压到指定目录
- 修改解压后的文件名称
- 进入配置文件目录
- 修改server.properties文件,指定kafka集群中broker的唯一标志,默认值是-1,如果没有指定会默认生成一个
- 修改server.properties文件,需要连接的zk集群地址,包含ip:port
- 修改server.properties文件,修改端口
- 修改server.properties文件,指明kafka需要监听的客户端
- 修改server.properties文件,一般写本机地址
- 修改server.properties文件,所有的消息都是需要保存到磁盘上的,这两个就是指定存储文件目录,配置的时候配置一个就行了,dirs如果有多个磁盘可以写多个文件分开存储
- 修改server.properties文件,broker所能接收的最大消息值,默认是1m
- 修改server.properties文件,新建一个topic默认的分区数,默认是1
- 创建kafka存储消息(log日志数据)的目录
- 到此为止,kafka已经配置成功,进入到kafka的bin目录,执行启动命令,启动kafka
- 2.4 搭建kafka manager可视化控制台
- 3. 核心概念讲解
- 4. 生产者/消费者快速入门
- 5. 与
SpringBoot整合使用 - 6. 海量日志搜集
ELK
acquire:获得、取到 Concurrent:并发
1. 主流的应用场景(其它MQ同理)
1.1 数据异步化
1.1.1 什么是异步化
- 异步化的原理同理为多线程中的异步,例如下面的例子
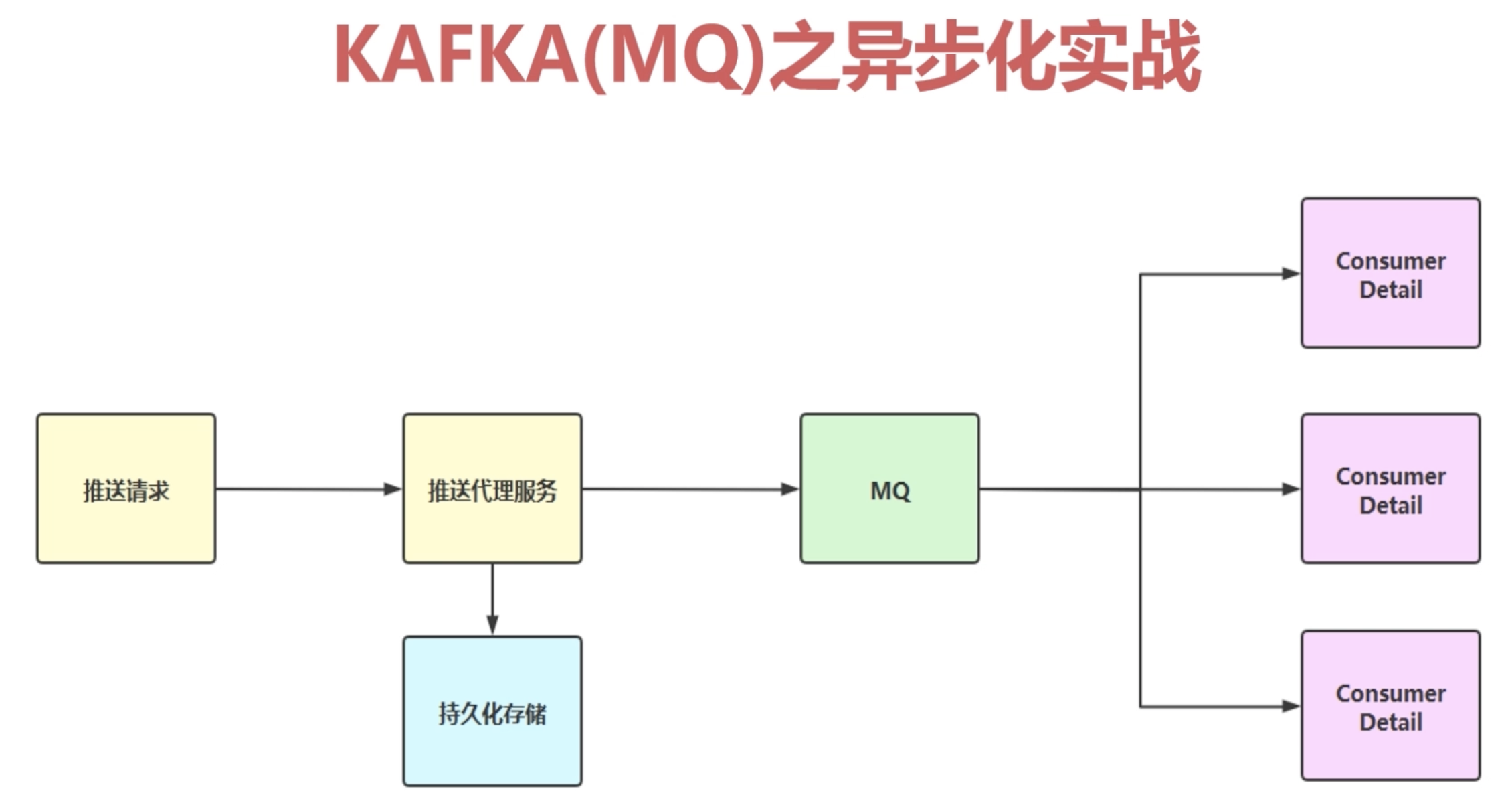
- 消息持久化:可以防止我们的消息发送失败,我们可以重推送,保证我们的消息触达率(这个一般是重要消息,具体参考
Rabbit MQ的学习过程,因为Rabbit适合中小型公司做数据异步化消息中间件)1.2 服务解耦、削峰填谷
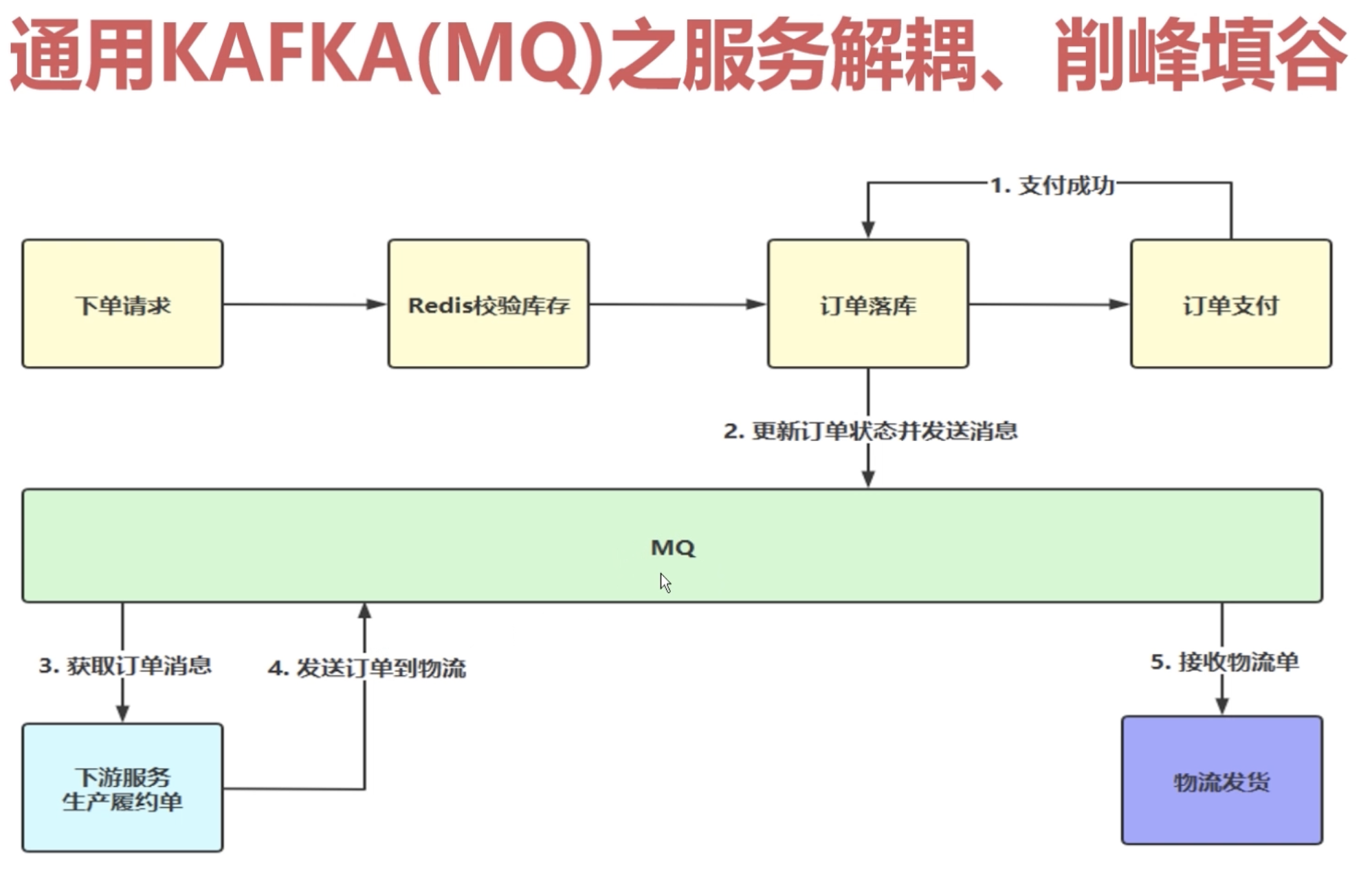
1.2.1 概念理解
- 服务解耦:异步化了之后,就是不用再担心别的服务的问题
削峰填谷:
MQ天然的就有这种缓存的机制,把消息缓存到MQ borker里面,然后我们去慢速的消费,高峰期的时候可以去做一个削峰,低谷期的时候做一个填谷,使我们的处理能力,相对来说更均匀一些1.2.2 架构分析
1.3 海量日志收集(
kafka特有)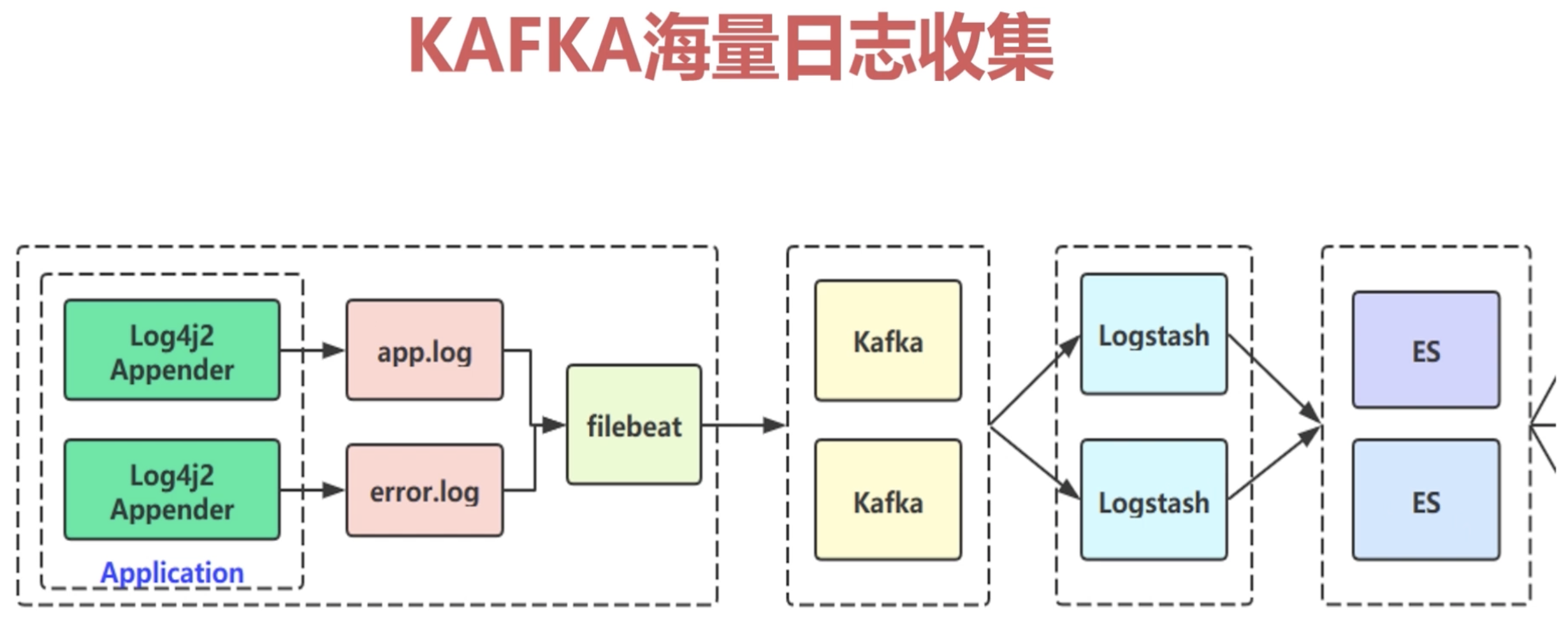
海量日志收集:注意第阶段的日志收集实战,自己总结
- 上图的架构解析:
- 下载kafka安装包:https://archive.apache.org/dist/kafka/2.1.0/kafka_2.12-2.1.0.tgz
2.1 服务端配置说明
参数文件:$KAFKA_HOME/config/server.propertieszookeeper.connect:需要连接的zk集群地址,包含ip:portlisteners:指明kafka需要监听的客户端broker.id:指定kafka集群中broker的唯一标志,默认值是-1,如果没有指定会默认生成一个log.dir、log.dirs:kafka所有的消息都是需要保存到磁盘上的,这两个就是指定存储文件目录message.max.bytes:broker所能接收的最大消息值,默认是1m2.2 搭建
zookeeperzookeeper集群2.3 搭建
```makefilekafka集群可以直接在zk集群的三台服务器上搭建kafka集群
下载kafka安装包
https://archive.apache.org/dist/kafka/2.1.0/kafka_2.12-2.1.0.tgz
上传文件到服务器,或者上传一个之后使用copy命令
/home/software/kafka scp kafka_2.12-2.1.0.tgz 192.168.231.132:/home/software/kafka
解压到指定目录
tar -zxvf kafka_2.12-2.1.0.tgz.gz -C /usr/local/
修改解压后的文件名称
cd /usr/local mv kafka_2.12-2.1.0 kafka_2.12
进入配置文件目录
vim /usr/local/kafka_2.12/config/server.properties
修改server.properties文件,指定kafka集群中broker的唯一标志,默认值是-1,如果没有指定会默认生成一个
broker.id=0
修改server.properties文件,需要连接的zk集群地址,包含ip:port
zookeeper.connect=192.168.11.221:2181,192.168.11.222:2181,192.168.11.223:2181
修改server.properties文件,修改端口
port=9092
修改server.properties文件,指明kafka需要监听的客户端
listeners:
修改server.properties文件,一般写本机地址
host.name=192.168.11.221
修改server.properties文件,所有的消息都是需要保存到磁盘上的,这两个就是指定存储文件目录,配置的时候配置一个就行了,dirs如果有多个磁盘可以写多个文件分开存储
log.dir=/usr/local/kafka_2.12/kafka-logs log.dirs=/usr/local/kafka_2.12/kafka-logs
修改server.properties文件,broker所能接收的最大消息值,默认是1m
message.max.bytes=10302430
修改server.properties文件,新建一个topic默认的分区数,默认是1
num.partitions=5
创建kafka存储消息(log日志数据)的目录
mkdir /usr/local/kafka_2.12/kafka-log
到此为止,kafka已经配置成功,进入到kafka的bin目录,执行启动命令,启动kafka
/usr/local/kafka_2.12/bin/kafka-server-start.sh /usr/local/kafka_2.12/config/server.properties &
```makefile
2.4 搭建kafka manager可视化控制台
## 这个在一台服务器上安装就行,因为集群信息已经互通,假设192.168.11.222## 把jar包(kafka manager)上传到 服务器/home/software/kafka/kafka-manager-2.0.0.2.zip## 解压到指定目录unzip kafka-manager-2.0.0.2.zip -d /usr/local/## 修改配置文件vim /usr/local/kafka-manager-2.0.0.2/conf/application.conf## 配置zk的地址kafka-manager.zkhosts="192.168.11.221:2181,192.168.11.222:2181,192.168.11.223:2181"## 启动/usr/local/kafka-manager-2.0.0.2/bin/kafka-manager &
## 6.4 浏览器访问控制台:默认端口号是9000http://192.168.11.222:9000/## 6.5 添加Cluster集群## 7 集群验证:## 7.1 通过控制台创建了一个topic为"test" 2个分区 1个副本## 7.2 消费发送与接收验证cd /usr/local/kafka_2.12/bin## 启动发送消息的脚本## --broker-list 192.168.11.221 指的是kafka broker的地址列表## --topic test 指的是把消息发送到test主题kafka-console-producer.sh --broker-list 192.168.11.221:2181 --topic test## 启动接收消息的脚本kafka-console-consumer.sh --bootstrap-server 192.168.11.221:9092 --topic test
3. 核心概念讲解
3.1 集群架构解析
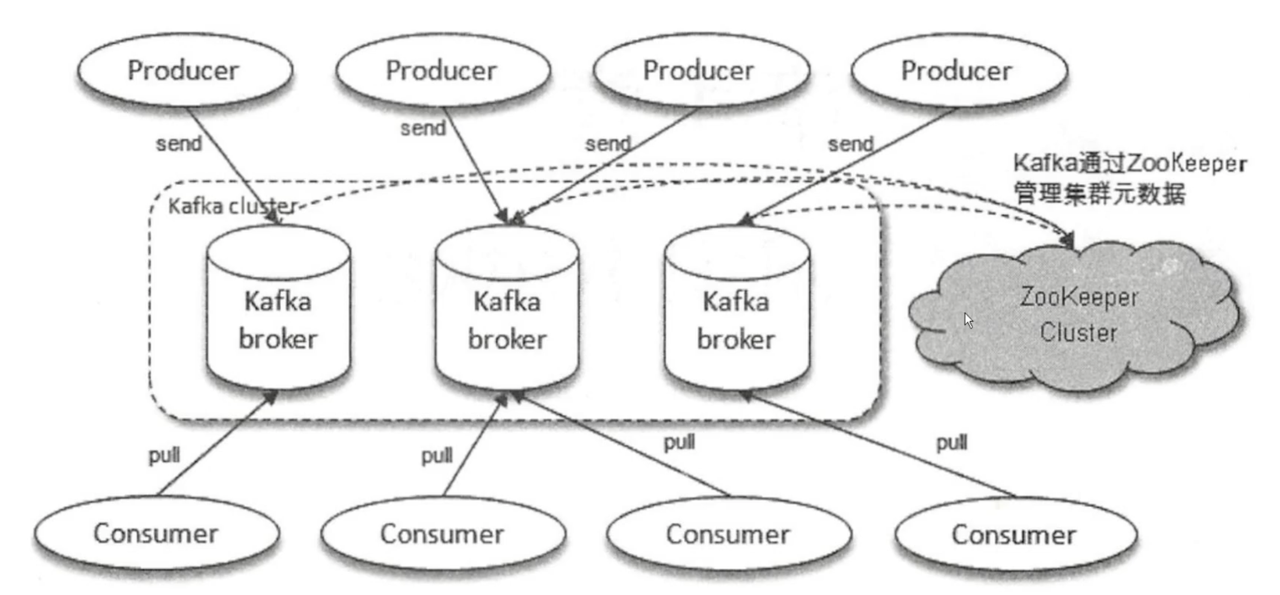
上图是
kafka最基本的全局上的一个架构模型上图是一个
kafka broker的详情图- 对比
Rabbit MQ的个人理解topic就是exchange,partition就是queue- 生产者把消息发送到
topicA中某个partition,消费者订阅topicA从而拉取其中的消息进行消费
- 主题
topic- 是一个逻辑上的概念不是一个物理存储的概念,这样一解释更像exchange
- 分区
partition- 起始位置的
offset为0 - 暂时定位一个物理存储概念
- 一个
topic对应多个partition,每个分区里面包含不同的消息 - 在存储的结构上可以理解为一个可以追加日志的log文件
topic如何将消息投递到对应的partitionpartition策略,例如hash策略
- 起始位置的
- 偏移量(
offset)- 偏移量,就是上图的
0,1,2,3....... - 在消息的
partition中是一个唯一的标识 kafka通过offset保证消息在partition内是顺序的
- 偏移量,就是上图的
- 消息的填充过程(发送消息)
- 消息都会被一个一个填充到我们的
partition里面,也可以理解为追加到一个一个日志文件里面 - 这时候都会分配一个偏移量
offset,对于这个offset它是一个顺序写入的过程0,1,2...
- 消息都会被一个一个填充到我们的
- 消息的找到过程(拉取消息)
- 订阅
topic,在确定是哪个partition - 在消息的
partition中offset是一个唯一的标识,通过offset找到对应的消息
- 订阅
- 如何保证消息的有序
- 我们消费的时候,一个消费者、一个线程、一个进程只连接一个分区
其它的相关逻辑
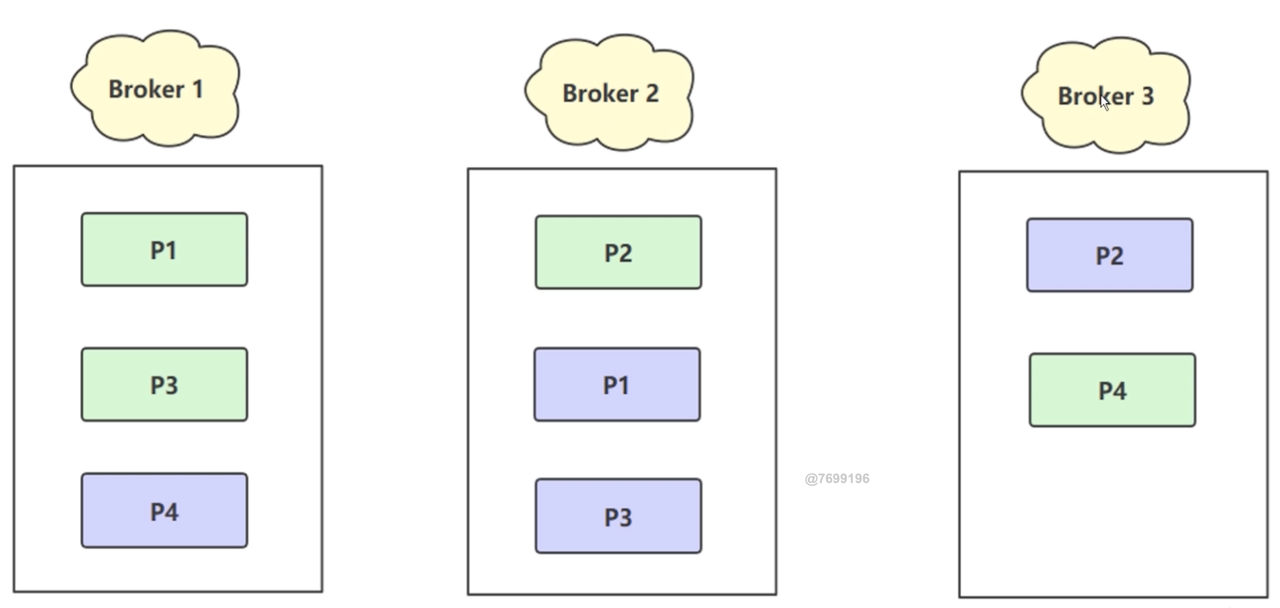
broker1、broker2:指的是一个一个物理机器集群borker1-p1和broker2-p1:相互的数据是完全一样的,防止某台机器挂掉了,数据仍然保证完整性(类似于es的副本分片)- 同一时刻分片数据不一致,因为数据同步需要时间(虽然很短)
- 绿色的是
leader分片会对外提供读写功能,紫色的follower分区,会不断的向leader拉取数据,只有当leader故障了,follower才会对外提供服务 总结:空间(存储空间)换取数据的高可靠性:不管是
kafka还是es,只要是分布式的架构,都会使用这种方式来保证数据高可靠性,是一个常规的解决方式3.4
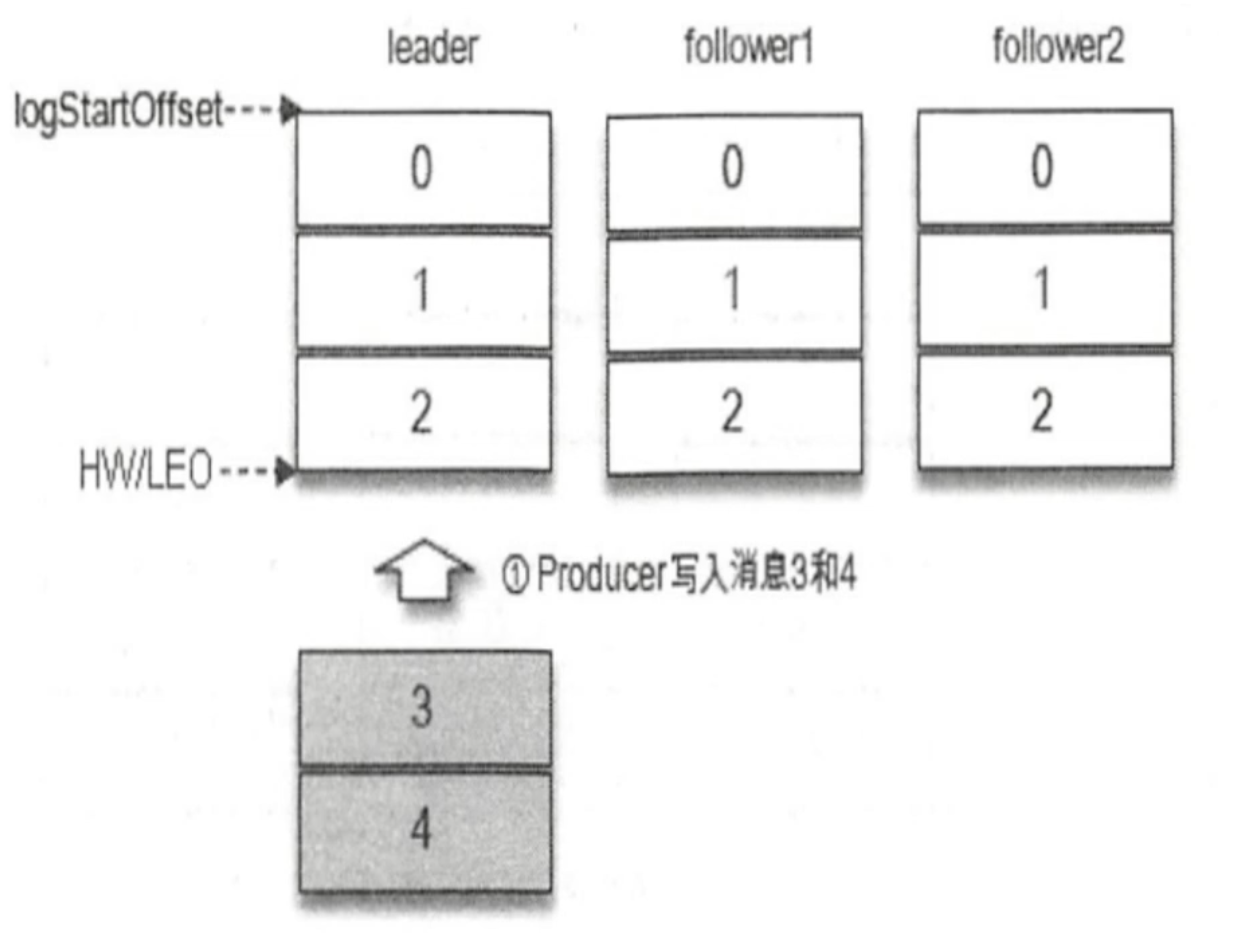
Hw、LEO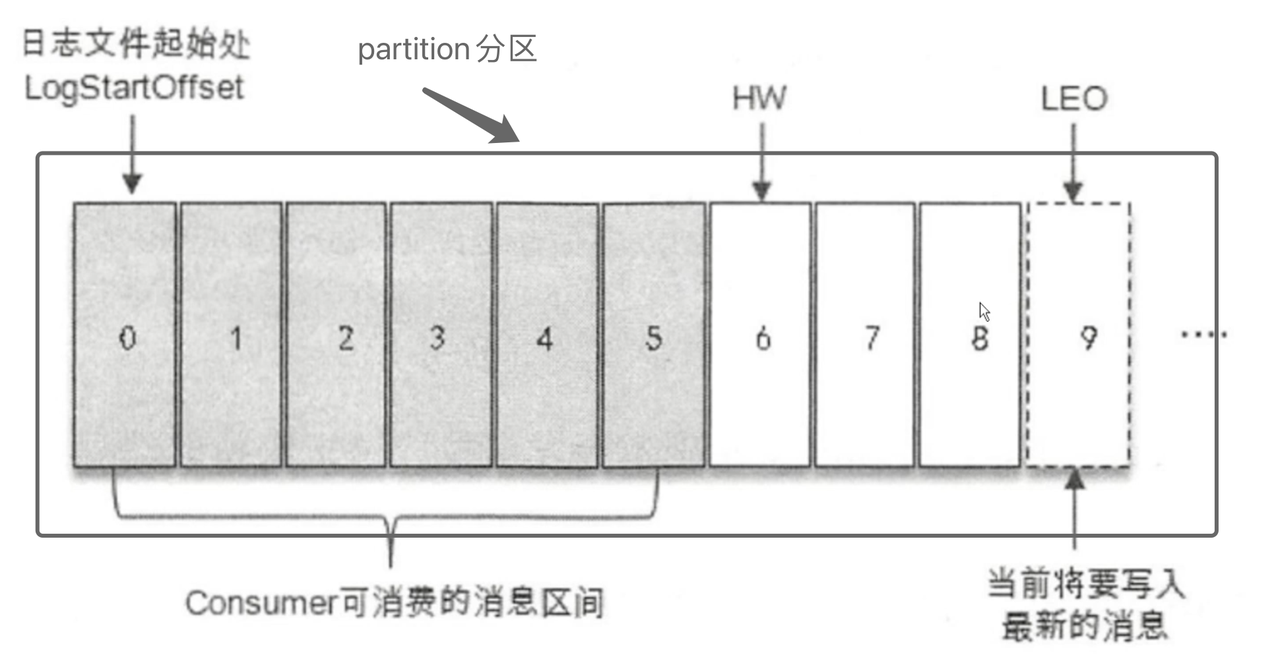
High Watermark:消费者最多拉取到高水位线的消息(拉取 <hw,注意不能等于)Log End Offset:日志文件最后一条记录的offset,例如:一个partition有100条数据,最后一条的偏移量就是99,这个99就是LEO,也就是说leo = offset3.5 同步副本机制
ISR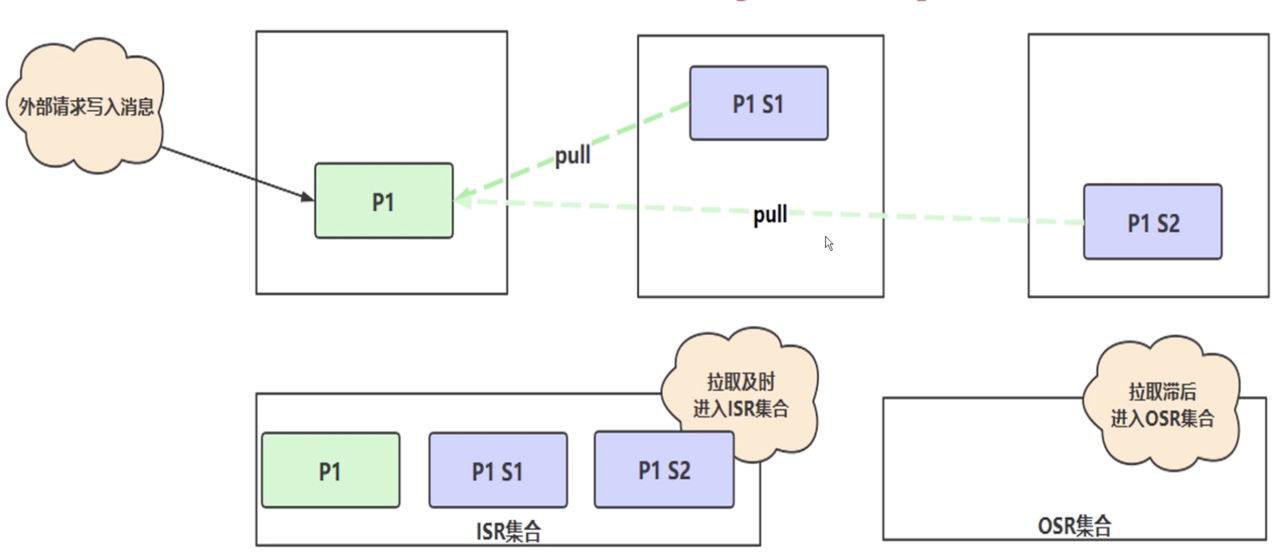
ISR机制保证主从分区的数据一致性- 两个时间概念
- 拉取时间:
follower从leader拉取数据花费的时间 - 容忍时间:
follower从leader拉取数据需要一定的时间,kafka可以设置一个容忍时间
- 拉取时间:
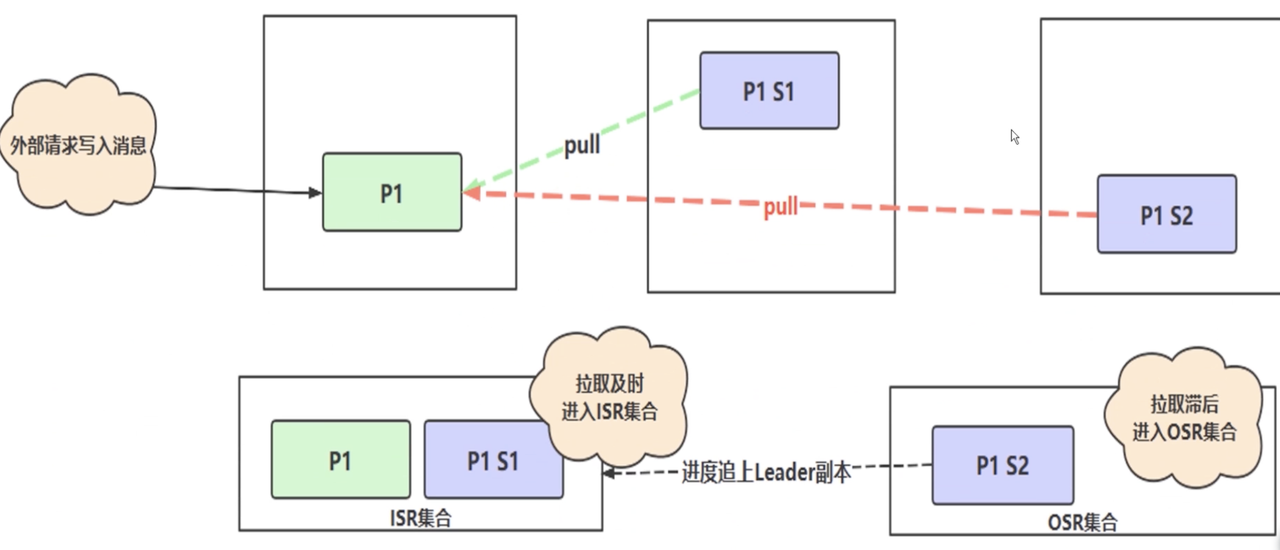
- 上图的流程机制
p1收到写入请求 -s1 s2会从p1拉取数据- 如果拉取时间 < 容忍时间,则副本会进入到
ISR集合 - 否则会进入
out sync replicas OSR集合,这时候leader已经放弃s2这个副本 - 后续看图二,如果
s2追上进度,就会被从新拉进ISR集合
leader挂掉的后续拉取策略(注意是默认策略)
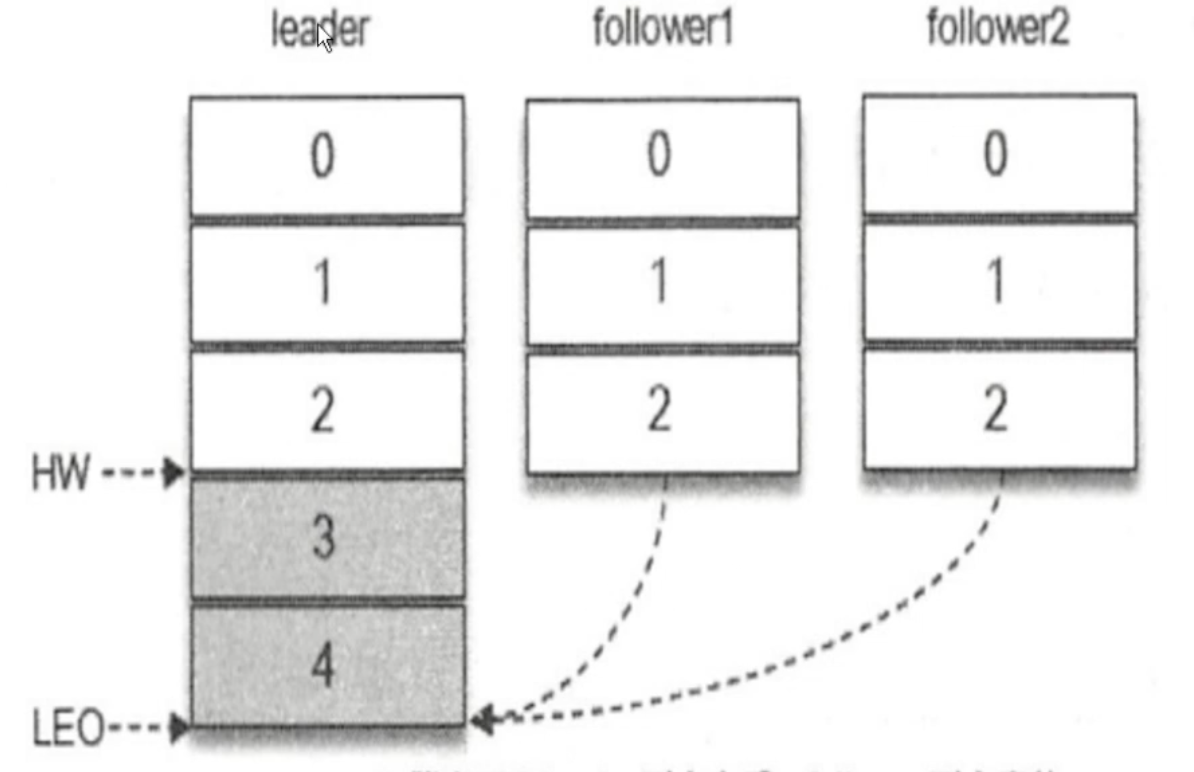
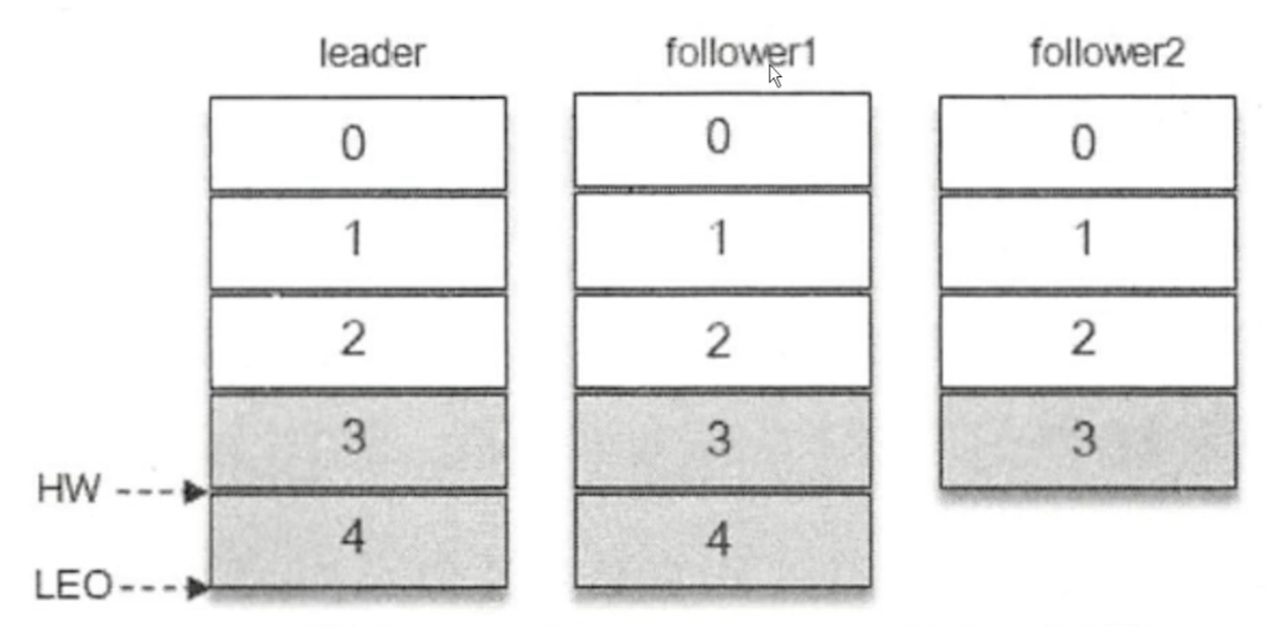
- 图一:当前一段时间没有数据写入
hw = leo - 图二:
maste写入消息后,slave正在拉取数据,这时候可以看出因为其它副本没有同步完成数据,那么Hw就只能等于原来的最大数据量 - 图三:只有当所有的数据在每个分片上同步完成,
hw才会增加
- 图一:当前一段时间没有数据写入
拉取策略是可以设置的(默认是全部副本)
kafka的所有Broker都会注册到kafka集群中去,kafka集群会选举一个Broker作为leader作为kafka七群的总控制器controller,负责管理整个集群所有分区partition和副本follower的状态leader和follower数据同步
如果
leader写入成功follwer还没写入时,leader就挂掉了,此时重新选举leader,新的leader自然没有这条信息。这种情况下,如果原有leader恢复正常,成为follwer节点,会把之前写入的那条信息同步给新leader4. 生产者/消费者快速入门
Tips:结合代码 + 笔记 + 源码学习生产者和消费者的内容
 |
|  |
|  |
| —- | —- | —- |
|
| —- | —- | —- |4.1 生产者
4.1.1 简单流程
KafkaProducer是线程安全的,KafkaConsumer不是线程安全的-
(2)
ProducerRecord<K, V>public class ProducerRecord<K, V> {private final String topic; // 对应的主题private final Integer partition; // 分区的数量private final Headers headers; // 自定义的一些属性private final K k; // 在关键参数中设置的,可以用来判断进入哪个分区private final V v; // 具体的消息内容private final Long timestamp; // 消息具体发送的时间}
5.1.3 消息重试机制
(1) acks
- 含义:发送消息后,
broker端至少多少个副本接受到消息(这里的副本包含leader``follower)才给生产端回应消息 acks = 1:默认情况,leader副本收到消息,就给生产端回应成功acks = 0:生产者发送完成消息后,不需要收到任何消息(不需要任何可靠性消息投递保证)acks = -1、acks = a:生产者在消息发送之后,需要ISR中所有副本都成功写入消息之后,才能收到来之broker端的相应()。
-
(3)
retries、retry.backoff.msretries -
(4)
compression.type 指定消息的压缩方式,默认值为
none,可选择gizp``snappy``lz4(5)
connections.max.idle.ms-
(6)
linger.ms、batch.size、buffer.memory
- 这三个是调优相关的
linger.ms:例如设置100毫秒(100是经验设置,要记住),这100毫秒之内的消息都是在内存中的,等到100毫秒的时候一起发送;也可以成为延迟发送、批量发送batch.size:累计多少条消息,则进行一次批量发送buffer.memory:缓存提升性能参数,默认32M- 三个参数的配合情况
- 前两条的存储的信息都是
buffer.memory中 - 背景:
linger.ms = 100ms,batch.size = 100条100ms到了,累计了30条消息,也是要发送一次- 刚到
50ms,累计了100条,也要发送一次 - 结论:只要满足一条就发送
- 前两条的存储的信息都是

4.1.4 拦截器
Tips:生产者和消费者都有拦截器
- 看生产者源码就知道在发送消息
(doSend)之前有一个拦截器,我们就是需要实现这个拦截器
- 实现这个
org.apache.kafka.clients.producer.ProducerInterceptor接口,具体看项目代码 配置实现的拦截器
properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, CustomProducerInterceptor.class.getName())4.1.5 序列化问题
broker只会接收二进制数据,所以消息的发送和接收需要做序列化和反序列化一些基本的、简单的数据类型
kafka已经提供了序列化和反序列化机制,所以前面所有的demo演示中,我们将对象转换为JSON数据其实也就是字符串,kafka自带的序列化工具序列化字符串- 特殊对象,例如自定义的对象,需要我们自己实现序列化/反序列化机制
- 具体实现查看代码即可(
注意:直接参考已经实现的StringSerializer) 理解之后其实通过转
JSON然后使用默认String序列化工具也是ok的4.1.6 分区器
作用:就是对消息进行分区的,消息到底是落到那个分区他来决定
- 如果消息的
partition属性带有值,则按照指定的分区,没有的话需要通过分区器来进行分区 - 有一个默认的分区器
DefaultPartitioner - 自定义分区器,只需要实现
Partitioner接口即可,其中的partition方法的参数介绍- @param topic 主题名称
- @param key 要分区的键(如果没有键,则为 null)
- @param keyBytes 序列化的要分区的键(如果没有键,则为 null)
- @param value 要分区的值或 null
- @param valueBytes 序列化要分区的值或 null
- @param cluster 当前集群元数据
- 实际工作中分区器如何使用
- 例如想要不同的消息进入不同的分区
- 例如商品topic,有4个分区(鞋子、裤子、上衣、内衣),根据@param value或者其他任意参数,让他们进入属于自己的分区
- 例如我们理算接收不同的调用方,核心进入a分区,中台进入b分区….
- 顺序消费问题
- 按照a例子属于自己的进入自己的分区,一个消费者只能消费一个分区,实现顺序消费
- 问题:消费者如何只接受某一个分区的消息?可以在拦截器进行拦截
- 例如想要不同的消息进入不同的分区
4.1.7 生产者发消息到broker的流程
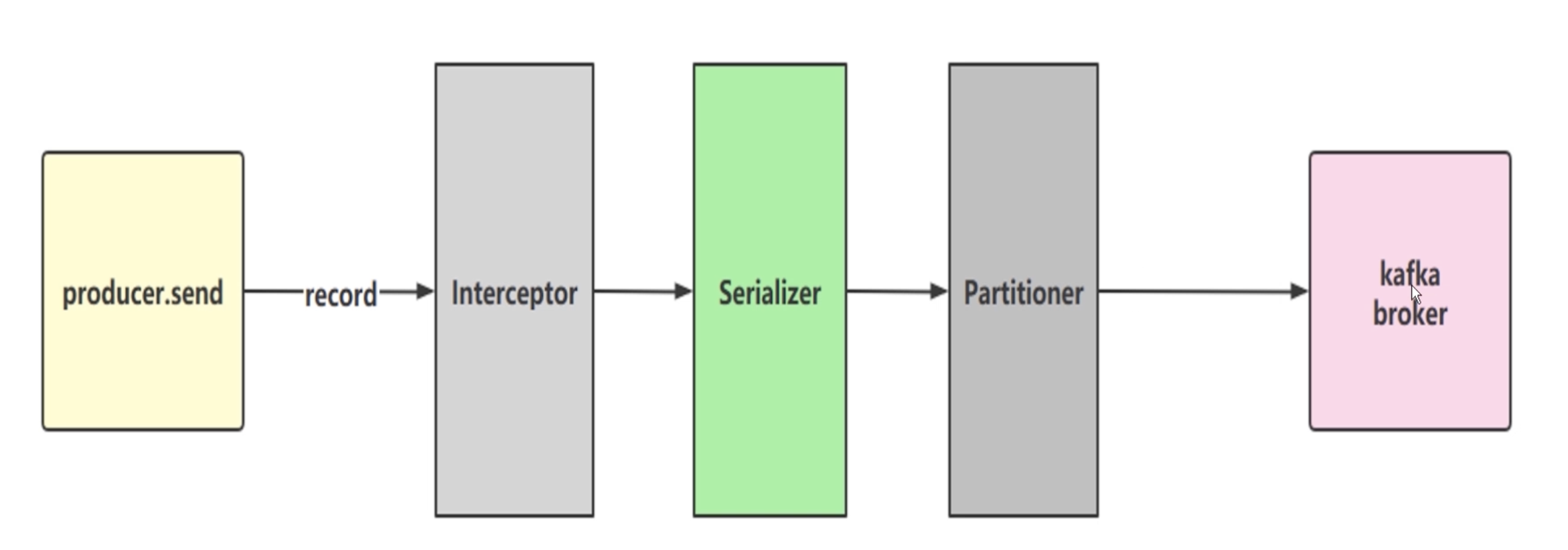
- ProducerRecord把信息包装成消息,由KafkaProducer.send()发送出去
- 经过拦截器也就是
onSend()方法,拦截器可能自由的做一些业务 - serializer、partition
- 经过序列化,key、value都需要序列化
- 有key通过key进行hash计算出一个分区,没有指定key也会通过算法计算出分区
- 如果带有partition的属性值,就需要走分区器进行分区
- 如果指定的partition的值,则按照指定的来
4.2 消费者流程
4.2.1 简单流程
- 配置消费者启动关键参数
- 创建
kafka消费者对象 - 订阅相关主题
- 拉取消息,并进行消费处理
-
4.2.2 消费者、消费者组的概念
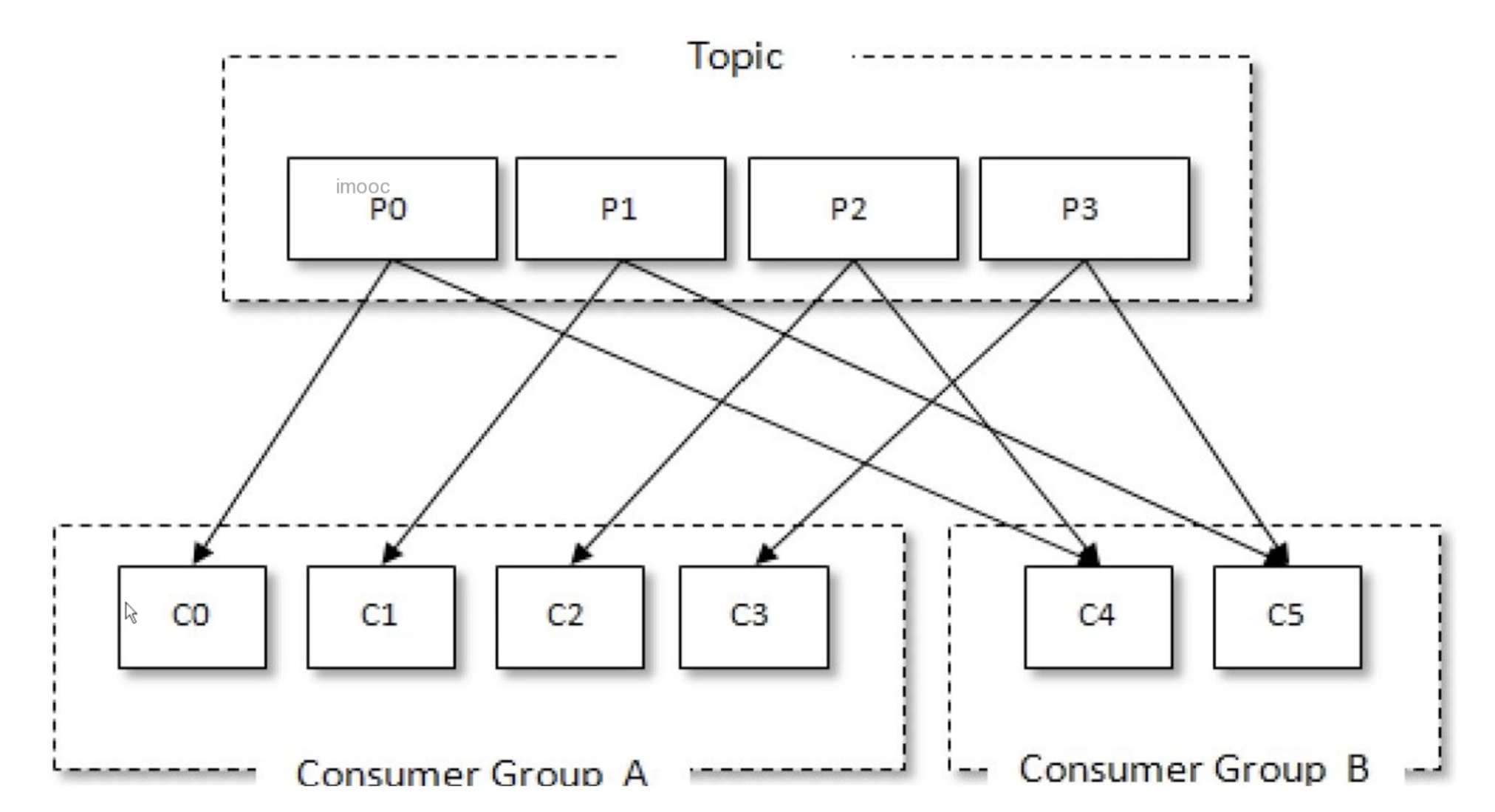
几个消费者联合起来就是消费者组
- 一个消费者组内的消费者同时订阅一个
topic- 消费者的数量 = 分区的数量
- 一个分区只能被一个消费组中的一个消费者消费,例如:不能说
co、c1同时消费p0(这时kafka的规定)
- 一个分区只能被一个消费组中的一个消费者消费,例如:不能说
- 消费者的数量 > 分区的数量
- 例如有
4个分区,但是一个消费者组有5个消费者,那么安装规定其中一个消费者什么都不敢,因为如果干了就违反一对一的消费
- 例如有
- 消费者的数量 < 分区的数量
- 比如
2个消费者,4个分区,那么可能1个消费者分到3个分区,一个分到1个分区,总之是把分区分配完毕,不能违反规定
- 比如
- 消费者的数量 = 分区的数量
- 不同消费组的消费者订阅同一
topic,相当于广播模式 - 一个消费者最内的消费者都是点对点的意思
- 一个消费者组看成一个整体,然后不同的消费者组就是发布订阅模型
4.2.3 消费者重要参数
Tips:其它参数,查看项目代码
(1) assign、subscribe
assign:只订阅主题下的一个、多个分区subscribe:订阅主题,支持支持集合、正则表达式 ```java // 对于consume消息的订阅 subscribe方法 :可以订阅一个 或者 多个 topic consumer.subscribe(Collections.singletonList(Const.TOPIC_CORE)); // 也可以支持正则表达式方式的订阅 consumer.subscribe(Pattern.compile(“topic-.*”));
// 可以指定订阅某个主题下的某一个、多个 partition TopicPartition tp1 = new TopicPartition(Const.TOPIC_CORE, 0); TopicPartition tp2 = new TopicPartition(Const.TOPIC_CORE, 2); consumer.assign(Arrays.asList(tp1, tp2);
// 如何拉取主题下的所有partition,然后订阅相关的partition
List
(2) auto_offset_reset_conifg
- �
AUTO_OFFSET_RESET_CONFIG有三种方式:"latest", "earliest", "none" none:不设置,存储在kafka的本地文件的信息latest:默认,从一个分区的最后提交的offset开始拉取消息earliest:从最开始的起始位置拉取消息 0properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "");(3)
fetch.min.bytes
-
(4)
fetch.max.bytes -
(5)
max.partition.fetch.bytes 一次
fetch请求,从分区中取取得的record最大值,默认1M(6)
fetch.max.wait.msfetch请求发送给broker之后,在broker中可能被阻塞的时长,默认500ms(7)
max.pull.recordsconsumer每次调用pull时候,最大拉取的records数量,默认500条4.2.4 消费者的手工提交
- 设置这个参数:
ConsumerConfig.enable.auto.commit.config = false - 提交方式:
- 消息级别:同步提交、异步提交
- 分区级别:同步提交、异步提交
- 整体(代表一次拉取的所有消息):整体提交、分区提交
offset不提交会有什么现象?KafkaProducer是线程安全的,KafkaConsumer不是线程安全的KafkaConsumer中定义了一个acquire()方法用来检测是否只有一个线程在操作,如果有其它线程操作则会抛出ConcurrentModificationException(并发修改异常)KafkaConsumer在执行所有的动作的时候都会先执行acquire()方法检测是否线程安全思考:消费者线程不安全,那么单线程如何解决消息堆积问题呢? 解析:实现消费者的多线程,这个也是解决消息堆积的一种方式:生产者消息发送太快了,消费者又是单线程 的可能会造成消息堆积�
既然消费者是单线程的,那么消费者如何实现多线程呢?
借用消费者组内的规则:一个partition只能被一个Consumer消费,那我就把partition和consumer的数量对其
5. 与SpringBoot整合使用
6. 海量日志搜集ELK

若有收获,就点个赞吧
0 人点赞
