扣减库存分为两种:
1、下单减库存;
2、付款减库存;
update语句自带行锁,for update属于被关锁,会阻塞查询的。
1. 超卖现象
锁问题主要是解决,并发场景下共享资源的处理问题,超卖现象作为经典的共享资源问题,特别适合各种锁来解决该问题,下面是各种解决场景
2. 数据库行锁解决
2.1 解决思路
- 上述的流程是一般的设计思路,可以将扣减库存的动作下沉至数据库
- 向数据库传递库存增量,扣减库存即增量为
-1 - 在数据库
update语句计算库存,通过update行锁解决并发问题 - 常见的修改语句sql:
update product set stock = stock-buy_count_num update_time = xxx where id = xx2.2 如何避免库存为负值
是否适合分布式的决定要素
2.1.1 多次校验
在修改之后,还需要校验库存值,如果为负值,则抛出异常该事务回滚
2.1.2 字段约束
在数据库里将stock字段加个约束,不能为负数,这样第一个线程更新库存后为0,后面第二个线程过来执行更新时,报数据库约束错误,使程序内部抛出运行时异常,最后事务回滚
2.1.3 sql语句约束
在where里加stock>=#{需要购买的数量}应该也一样能解决库存超卖问题吧
2.1.2 统一加锁
扣减库存的两个动作“校验库存”、“扣减库存”,给这两个动作加锁,使之称为原子性的操作,只有获取到锁的线程才能执行
2.1.2.1 Synchronized
https://class.imooc.com/lesson/1235#mid=29407
在方法或者代码块上加锁即可
事务和锁的问题
加锁只是锁住了这一块的代码,但是在并发场景下,代码的执行速度是非常块的,当A线程执行完毕代码,数据库开始执行但是A线程的事务还没有提交,在这个时候B线程也执行完成代码,事务进入到数据库,这个时候库存读取会依然是原始数
2.1.2.2 ReentrantLock
https://class.imooc.com/lesson/1235#mid=29409:视频主要介绍ReentrantLock的使用,学习即可
3. 分布式锁解决
分布式锁的核心就是找到,多个进程、线程共同访问的第三方组件例如mysql、redis、zookeeper…
3.1 基于数据库实现
- 给数据库加上行级锁,也就是悲观锁
- 加锁语句:
select * from 表名 where 条件 for update - 这个语句会在你检索数据的时候,会将你检索出的数据加上锁,这样其它的线程在执行同样的语句的时候只能等待,其它线程只能查询数据,不能修改数据(更加具体的知识点查看mysql数据库章节)
- 基于数据库的实现方式,如果使用了分库分表能否还是正确的,看具体的业务场景吧
- 总结
- 优点:简单方便、易于理解、不需要引入不必要的第三方组件
- 缺点:并发量大的时候,数据库的压力大
- 建议:作为锁的数据库和业务数据库分开 ```sql — 演示案例数据信息 key:value {“id”:1,”business_code”:”demo”,”businss_name”:”doem演示”}
— 查看事务的提交方式: 0-手动 1-自动,默认为自动提交,也就是说查出来是1 select @@autocommit;
— 关闭事务的自动提交,这样才能看见行级锁的问题 set @@autocommit = 0;
— 加锁sql语句 select * from demo_lock where business_code = “demo” for update
— 事务手动提交sql commit;
— 操作流程 1.打开两个执行窗口 2.第一个窗口执行加锁语句,可以成功 3.第二个窗口执行加锁语句,系统阻塞,检索失败,必须等待窗口一的事务提交释放锁才可以
— 注意行级锁是不影响查询的,如果在加锁的过程中,执行查询语句依然是ok的,例如下面的sql select * from demo_lock where business_code = “demo”
<a name="zt7t2"></a>## 3.2 基于redis实现<a name="M0DHZ"></a>### 3.2.1 整体的原理1. 官网文档:[https://redis.io/topics/distlock](https://redis.io/topics/distlock)1. 使用`setnx`命令,利用`redis`的单线程特性,在高并发场景下只有一个线程会成功1. 设置成功即等于获取了锁,可以执行后续的业务处理1. 如果出现异常,过了锁的有效期,锁自动释放1. 命令解析:`set key value [nx|px] [ex seconds] [px milliseconds]`1. `key`:资源名称`recource_name`,可根据不同的业务区分不同的锁1. `value`:随机值`random_value`,每个线程的随机值不同,用于释放锁时的校验1. `nx`:`key`不存在时候设置成功,`key`存在则什么都不做1. `xx`:只在键已经存在时,才对键进行操作设置1. `ex seconds`:设置多少秒(过期时间)1. `px milliseconds`:设置多少毫秒(过期时间)1. `set`操作完成时返回`OK`,失败返回`nil`6. 必须保证`redis`是单机版本的吗?1. 不需要的,集群,哨兵,主从模式下都是可以使用的1. 不过要是数据同步时,如果节点挂掉,会对分布式锁产生影响7. 缺点1. 不支持阻塞,就是当上一个锁没有被释放,下一个线程不会等待,直接`fasle`也就是获取锁失败,但是可以使用`redisson`解决<a name="igSkz"></a>### 3.2.2 锁的释放1. 释放锁采用`redis`的`delete`命令1. 释放时候校验之前设置的随机数,相同才能释放,因为要确保是这个线程对应的`key`1. 释放锁采用`lua`脚本,因为`delete`命令并没有提供校验功能1. 为什么不是直接按照`key`删除锁?1. 个人理解,其实是可以按照key`来`删除的,只是老师没有讲解1. 例如`key`是固定的,例如`OrderLock`、`ProductLock`,在`finally`中直接删除即可1. 例如可以是随意的字符,也可以在业务执行的时候记录`key`,最后在`finally`中删除5. 按照值删除,为什么不取出来比较一下删除,而是采用脚本1. 使用脚本可以利用Redis的原子性操作,取值、比较、删除是一个不可分割的操作1. 如果不使用脚本,3个步骤就分开了,会有并发的影响。6. 为什么不是直接比较```lua-- 校验的脚本命令if redis.call("get",KEYS[1]) == ARGV[1] thenreturn redis.call("del",KEYS[1])elsereturn 0end
- 为什么要校验这个锁释放的就是自己产生的?
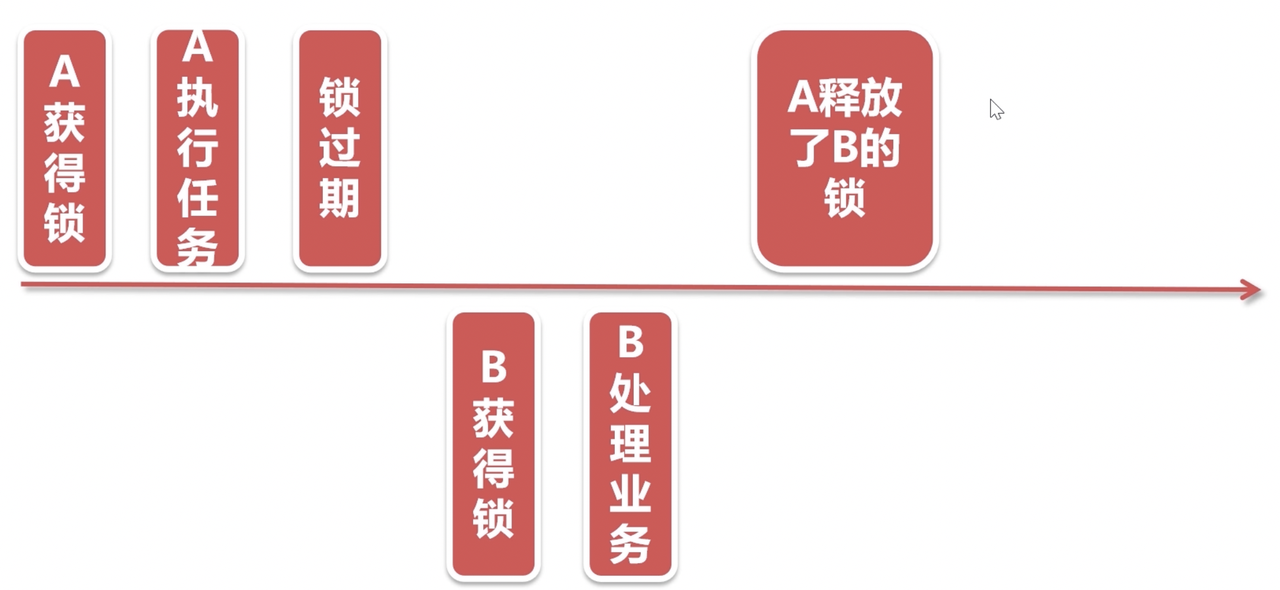
- 当我们的系统出现异常问题,导致任务执行过长,超出了我们预期的过期时间,如下图
- 锁过期的时候,B线程创建了自己的锁,并且执行业务
- 然后A线程执行完毕,开始释放锁,这时候redis中只有B线程的锁,A线程就把B线程的锁释放了
- 所以这个redis过期时间要调试精确,校验作为兜底,至少不能影响下一个业务
-
3.2.3 代码实现流程
查看分布式锁项目之
distributed-redis,注意controller中单独的写法和封装的工具类3.2.4 实现分布式定时任务
单个项目使用spring-task作为定时任务,每个项目获取redis分布式锁,谁能获取锁,谁就执行任务
3.2.5 基于redisson的分布式锁
内部已经实现,注意它实现的方式支持阻塞,直接使用即可,查看分布式锁项目的
distributed-redisson项目,注意测试包下面写的是基本的用法,然后代码包写的是SpringBoot的用法
https://class.imooc.com/lesson/1235#mid=29421 ```makefile这个配置文件写在resources下面
启动类导入配置文件
@ImportResource(“classpath*:redisson.xml”)
使用的时候直接注入
@Autowired private RedissonClient redisson;
<a name="sexyS"></a>## 3.2 基于zookeeper实现1. 利用有序瞬时节点与`watch`机制,让请求的线程顺序执行,并且利用`wait()`让`zk`分布式锁支持阻塞1. 每个业务锁占用一个持久节点例如`/order`1. 当需要获取锁时在持久节点目录下创建一个临时节点例如`/order/order_0000001`1. 创建成功判断当前节点的序号是否为最小值,如果是则表示获取锁成功1. 不是最小节点,即通过watch机制监听比它小的节点的删除事件1. 在此期间通过wait()方法休眠当前线程,直到监听的节点删除,并且通过notify唤醒该线程1. 临时节点好处在于当进程挂掉后能自动上锁的节点自动删除即取消锁,因为设置了超时时间<a name="qJ1WA"></a># 4. 天天吃货改造改造完成数据库的sql是不变的,数据库的查询依然是加行锁,但是为什么还需要分布式锁呢<br />只要是update都会有锁,使用分布式锁是将压力前移到应用层```makefile1.@Transactional(rollbackFor = Exception.class):spring默认的回滚异常是RunTimeException,想要回滚exception的异常,需要进行如上所示的配置

若有收获,就点个赞吧
0 人点赞
