DOM 操作
浏览器环境 , 规格
JavaScript 语言最初是为 Web 浏览器创建的。此后,它已经发展成为一种具有多种用途和平台的语言。
平台可以是一个浏览器,一个 Web 服务器,或其他 主机(host),甚至可以是一个“智能”咖啡机,如果它能运行 JavaScript 的话。它们每个都提供了特定于平台的功能。JavaScript 规范将其称为 主机环境。
主机环境提供了自己的对象和语言核心以外的函数。Web 浏览器提供了一种控制网页的方法。Node.JS 提供了服务器端功能,等等。
下面是 JavaScript 在浏览器中运行时的鸟瞰示意图:
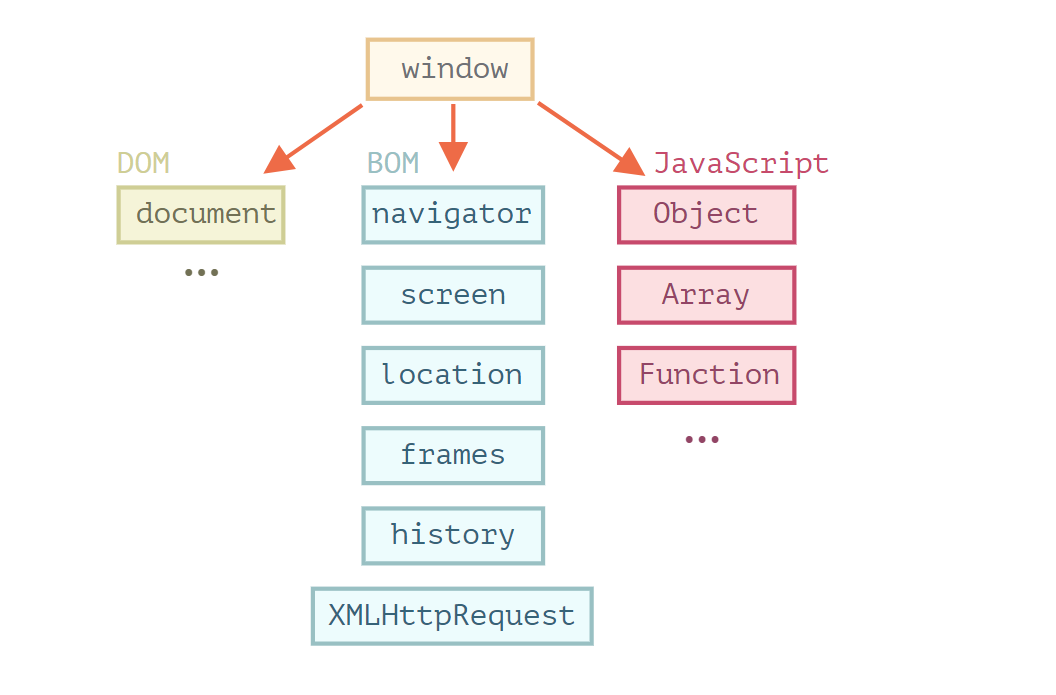
有一个叫做 window 的“根”对象。它有两个角色:
- 首先,它是 JavaScript 代码的全局对象,如 全局对象 一章所述。
- 其次,它代表“浏览器窗口”,并提供了控制它的方法。
例如,在这里我们将它用作全局对象:
function sayHi() {alert("Hello");}// 全局函数是全局对象的方法:window.sayHi();
在这里,我们将它用作浏览器窗口,以查看窗口高度:
在这里,我们将它用作浏览器窗口,以查看窗口高度:
alert(window.innerHeight); // 内部窗口高度
还有更多窗口特定的方法和属性,我们稍后会介绍它们。
文档对象模型 DOM
DOM: Document Object Mode 文档对像模型
是HTML和XML文档的编程接口, 定义了访问和操作HTML和XML文档的标准方法 。
DOM 以树形目录结构表达HTML和XML文档 的 , 每一个节点就是一个DOM元素
例如:
// 将背景颜色修改为红色document.body.style.background = "red";// 在 1 秒后将其修改回来setTimeout(() => document.body.style.background = "", 1000); // 1000ms = 1s
DOM 不仅仅用于浏览器
DOM 规范解释了文档的结构,并提供了操作文档的对象。有的非浏览器设备也使用 DOM。
例如,下载 HTML 文件并对其进行处理的服务器端脚本也可以使用 DOM。但它们可能仅支持部分规范中的内容。
用于样式的 CSSOM
另外也有一份针对 CSS 规则和样式表的、单独的规范 CSS Object Model (CSSOM),这份规范解释了如何将 CSS 表示为对象,以及如何读写这些对象。
当我们修改文档的样式规则时,CSSOM 与 DOM 是一起使用的。但实际上,很少需要 CSSOM,因为我们很少需要从 JavaScript 中修改 CSS 规则(我们通常只是添加/移除一些 CSS 类,而不是直接修改其中的 CSS 规则),但这也是可行的。
浏览器对象模型 BOM
浏览器对象模型(Browser Object Model),简称 BOM,表示由浏览器(主机环境)提供的用于处理文档(document)之外的所有内容的其他对象。
例如:
- navigator 对象提供了有关浏览器和操作系统的背景信息。navigator 有许多属性,但是最广为人知的两个属性是:
navigator.userAgent— 关于当前浏览器,navigator.platform— 关于平台(可以帮助区分 Windows/Linux/Mac 等)。 - location 对象允许我们读取当前 URL,并且可以将浏览器重定向到新的 URL。
这是我们可以如何使用 location 对象的方法:
alert(location.href); // 显示当前 URLif (confirm("Go to Wikipedia?")) {location.href = "https://wikipedia.org"; // 将浏览器重定向到另一个 URL}
函数 alert/confirm/prompt 也是 BOM 的一部分:它们与文档(document)没有直接关系,但它代表了与用户通信的纯浏览器方法。
规范
BOM 是通用 HTML 规范 的一部分。
是的,你没听错。在 https://html.spec.whatwg.org 中的 HTML 规范不仅是关于“HTML 语言”(标签,特性)的,还涵盖了一堆对象、方法和浏览器特定的 DOM 扩展。这就是“广义的 HTML”。此外,某些部分也有其他的规范,它们被列在 https://spec.whatwg.org 中。
DOM树
HTML 文档的主干是标签(tag)。
根据文档对象模型(DOM),每个 HTML 标签都是一个对象。嵌套的标签是闭合标签的“子标签(children)”。标签内的文本也是一个对象。
所有这些对象都可以通过 JavaScript 来访问,我们可以使用它们来修改页面。
例如,document.body 是表示 <body> 标签的对象。
运行这段代码会使 <body> 保持 3 秒红色状态:
document.body.style.background = 'red'; // 将背景设置为红色setTimeout(() => document.body.style.background = '', 3000); // 恢复回去
在这,我们使用了 style.background 来修改 document.body 的背景颜色,但是还有很多其他的属性,例如:
innerHTML— 节点的 HTML 内容。offsetWidth— 节点宽度(以像素度量)- ……等。
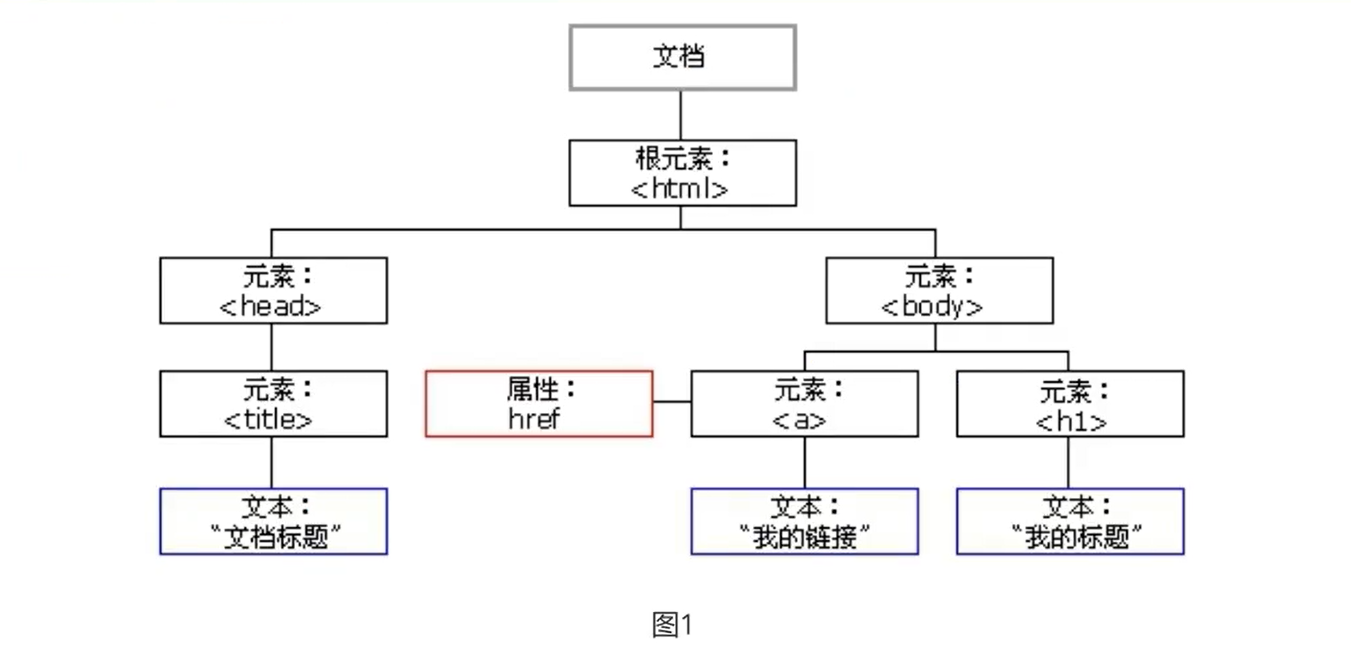
document -> html/xml -> head/body -> ….
搜索: getElement querySelector
当元素彼此靠得近时,DOM 导航属性(navigation property)非常有用。如果不是,那该怎么办?如何去获取页面上的任意元素?
还有其他搜索方法。
教程 : https://zh.javascript.info/searching-elements-dom
document.getElementById 【 或者只使用 id】
如果一个元素有 id 特性(attribute),那我们就可以使用 document.getElementById(id) 方法获取该元素,无论它在哪里。
例如:
<div id="elem"><div id="elem-content">Element</div></div><script>// 获取该元素let elem = document.getElementById('elem'); // 查找id// 将该元素背景改为红色elem.style.background = 'red'; // 设置样式</script>
此外,还有一个通过 id 命名的全局变量,它引用了元素: (建议不要使用)
<div id="elem"><div id="elem-content">Element</div></div><script>// elem 是对带有 id="elem" 的 DOM 元素的引用elem.style.background = 'red'; // 也就是 window.elem.style.background = "red";// id="elem-content" 内有连字符,所以它不能成为一个变量// ...但是我们可以通过使用方括号 window['elem-content'] 来访问它</script>
请不要使用以 id 命名的全局变量来访问元素
在规范中 对此行为进行了描述,所以它是一种标准。但这是注意考虑到兼容性才支持的。
浏览器尝试通过混合 JavaScript 和 DOM 的命名空间来帮助我们。对于内联到 HTML 中的简单脚本来说,这还行,但是通常来说,这不是一件好事。因为这可能会造成命名冲突。另外,当人们阅读 JavaScript 代码且看不到对应的 HTML 时,变量的来源就会不明显。
在本教程中,我们只会在元素来源非常明显时,为了简洁起见,才会使用 id 直接引用对应的元素。
在实际开发中,document.getElementById 是首选方法。
**id** 必须是唯一的
id 必须是唯一的。在文档中,只能有一个元素带有给定的 id。
如果有多个元素都带有同一个 id,那么使用它的方法的行为是不可预测的,例如 document.getElementById 可能会随机返回其中一个元素。因此,请遵守规则,保持 id 的唯一性。
querySelectorAll 【获取所有选择器的内容】
到目前为止,最通用的方法是 elem.querySelectorAll(css),它返回 elem 中与给定 CSS 选择器匹配的所有元素。
在这里,我们查找所有为最后一个子元素的 <li> 元素:
<body><ul><li>The</li><li>test</li></ul><ul><li>has</li><li>passed</li></ul></body><script>let elements = document.querySelectorAll("ul > li:last-child"); // ul 下面的 最后的li 元素for (let elem of elements) console.log(elem.innerHTML); // test , passed ;</script>
也可以使用伪类
CSS 选择器的伪类,例如 :hover 和 :active 也都是被支持的。例如,document.querySelectorAll(':hover') 将会返回鼠标指针现在已经结束的元素的集合(按嵌套顺序:从最外层 <html> 到嵌套最多的元素)。
querySelector 【获取第一个选择器】
elem.querySelector(css) 调用会返回给定 CSS 选择器的第一个元素。
换句话说,结果与 elem.querySelectorAll(css)[0] 相同,但是后者会查找 所有 元素,并从中选取一个,而 elem.querySelector 只会查找一个。因此它在速度上更快,并且写起来更短。
matches 【判断获取到匹配的选择器】
之前的方法是搜索 DOM。
elem.matches(css) 不会查找任何内容,它只会检查 elem 是否与给定的 CSS 选择器匹配。它返回 true 或 false。
<body><a href="http://example.com/file.zip">...</a><a href="http://ya.ru">...</a></body><script>for (let elem of document.querySelectorAll("a")) {if (elem.matches("a[href$='zip']")) console.log("The archive reference: " + elem.href);}</script>
closest 【查找标签的父级】
元素的祖先(ancestor)是:父级,父级的父级,它的父级等。祖先们一起组成了从元素到顶端的父级链。
elem.closest(css) 方法会查找与 CSS 选择器匹配的最近的祖先。elem 自己也会被搜索。
换句话说,方法 closest 在元素中得到了提升,并检查每个父级。如果它与选择器匹配,则停止搜索并返回该祖先。
<body><h1>Contents</h1><div class="contents"><ul class="book"><li class="chapter">Chapter 1</li><li class="chapter">Chapter 1</li></ul></div></body><script>let chapter = document.querySelector('.chapter'); // 选择 li// 使用 closest 方法 elem.closest(css) 方法会查找与 CSS 选择器匹配的最近的祖先 ,// 如果它与选择器匹配,则停止搜索并返回该祖先。console.log(chapter.closest(".book")); // ulconsole.log(chapter.closest(".contents")); // divconsole.log(chapter.closest("h1")); // null 因为 h1 不是它的父级或者祖级</script>
getElementsBy* 【匹配其他标签】
还有其他通过标签,类等查找节点的方法。
如今,它们大多已经成为了历史,因为 querySelector 功能更强大,写起来更短。
因此,这里我们介绍它们只是为了完整起见,而你仍然可以在旧脚本中找到这些方法。
elem.getElementsByTagName(tag)查找具有给定标签的元素,并返回它们的集合。tag参数也可以是对于“任何标签”的星号"*"。elem.getElementsByClassName(className)返回具有给定CSS类的元素。document.getElementsByName(name)返回在文档范围内具有给定name特性的元素。很少使用。
例如:
// 获取文档中的所有 divlet divs = document.getElementsByTagName('div');
让我们查找 table 中的所有 input 标签:
<body><table class="table"><tr><td><label for=""><input type="radio" name="age" value="young" checked="checked"></label> less than 18<label for=""><input type="radio" name="age" value="mature" ></label> from 18 to 50<label for=""><input type="radio" name="age" value="senior" ></label> more than 60</td><td></td></tr></table></body><script>let inputs = document.getElementsByTagName("input");for (let elem of inputs) {console.log(elem.value + ":" + elem.checked); // young : true}</script>
不要忘记字母
**"s"**!新手开发者有时会忘记字符
"s"。也就是说,他们会调用getElementByTagName而不是getElement**s**ByTagName。
getElementById中没有字母"s",是因为它只返回单个元素。但是getElementsByTagName返回的是元素的集合,所以里面有"s"。它返回的是一个集合,不是一个元素!
新手的另一个普遍的错误是写:
这是行不通的,因为它需要的是一个 input 的 集合,并将值赋(assign)给它,而不是赋值给其中的一个元素。
我们应该遍历集合或通过对应的索引来获取元素,然后赋值,如下所示:
// 行不通document.getElementsByTagName('input').value = 5;
// 应该可以运行(如果有 input)document.getElementsByTagName('input')[0].value = 5;
查找 .article 元素:
<form name="my-form"><div class="article">Article</div><div class="long article">Long article</div></form><script>// 按 name 特性查找let form = document.getElementsByName('my-form')[0];// 在 form 中按 class 查找let articles = form.getElementsByClassName('article'); // 返回的是数组alert(articles.length); // 2, found two elements with class "article"</script>
实时的集合
所有的 "getElementsBy*" 方法都会返回一个 实时的(live) 集合。这样的集合始终反映的是文档的当前状态,并且在文档发生更改时会“自动更新”。
在下面的例子中,有两个脚本。
- 第一个创建了对
<div>的集合的引用。截至目前,它的长度是1。 - 第二个脚本在浏览器再遇到一个
<div>时运行,所以它的长度是2。
<div>First div</div><script>let divs = document.getElementsByTagName('div');alert(divs.length); // 1</script><div>Second div</div><script>alert(divs.length); // 2</script>
相反,querySelectorAll 返回的是一个 静态的 集合。就像元素的固定数组 。
如果我们使用它,那么两个脚本都会输出 1:
<div>First div</div><script>let divs = document.querySelectorAll('div');alert(divs.length); // 1</script><div>Second div</div><script>alert(divs.length); // 1</script>
现在我们可以很容易地看到不同之处。在文档中出现新的 div 后,静态集合并没有增加。
小结
有 6 种主要的方法,可以在 DOM 中搜索元素节点:
| 方法名 | 搜索方式 | 可以在元素上调用? | 实时的? |
|---|---|---|---|
querySelector |
CSS-selector | ✔ | - |
querySelectorAll |
CSS-selector | ✔ | - |
getElementById |
id |
- | - |
getElementsByName |
name |
- | ✔ |
getElementsByTagName |
tag or '*' |
✔ | ✔ |
getElementsByClassName |
class | ✔ | ✔ |
目前为止,最常用的是 querySelector 和 querySelectorAll,但是 getElement(s)By* 可能会偶尔有用,或者可以在旧脚本中找到。
此外:
elem.matches(css)用于检查elem与给定的 CSS 选择器是否匹配。elem.closest(css)用于查找与给定 CSS 选择器相匹配的最近的祖先。elem本身也会被检查。
让我们在这里提一下另一种用来检查子级与父级之间关系的方法,因为它有时很有用:
- 如果
elemB在elemA内(elemA的后代)或者elemA==elemB,elemA.contains(elemB)将返回 true。
节点属性 : type tag 和 content
不同的 DOM 节点可能有不同的属性。例如,标签 <a> 相对应的元素节点具有链接相关的(link-related)属性,标签 <input> 相对应的元素节点具有与输入相关的属性,等。文本节点与元素节点不同。但是所有这些标签对应的 DOM 节点之间也存在共有的属性和方法,因为所有类型的 DOM 节点都形成了一个单一层次的结构(single hierarchy)。
每个 DOM 节点都属于相应的内建类。
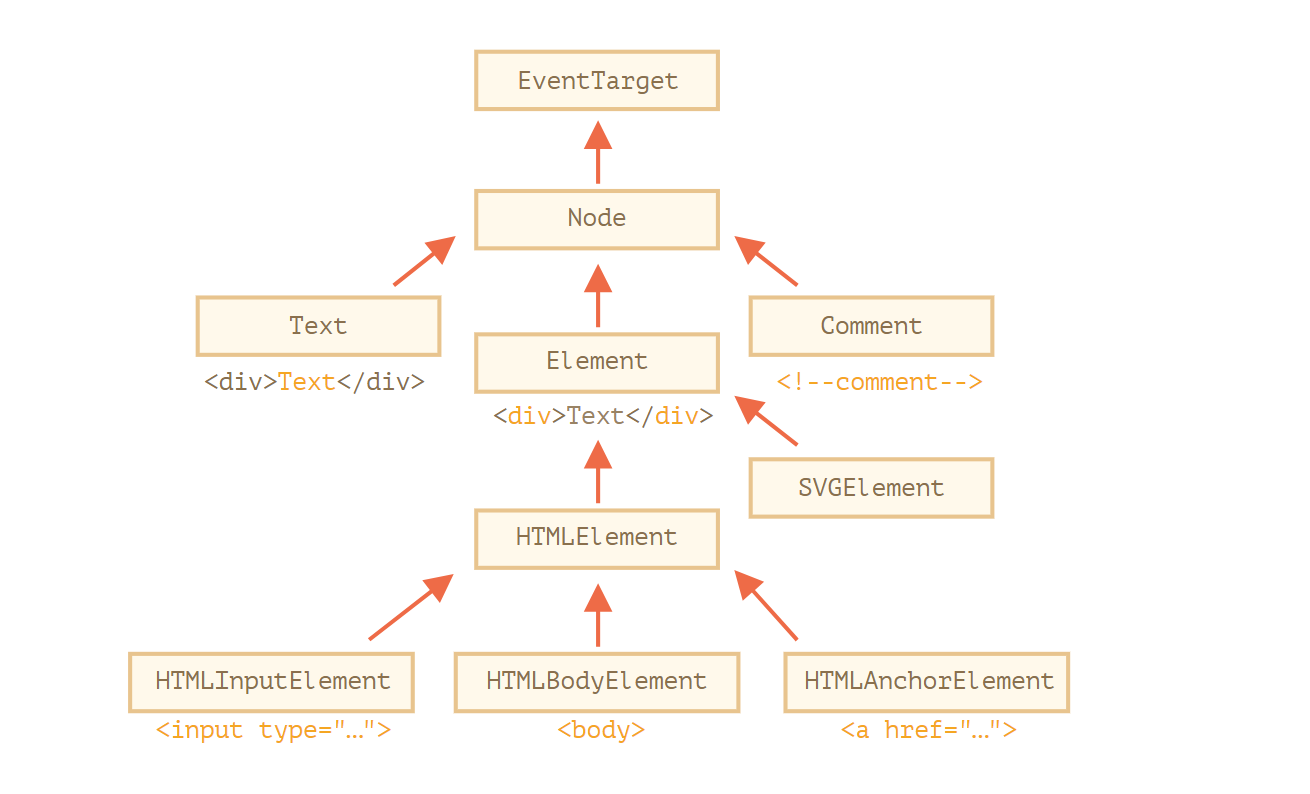
类如下所示:
- EventTarget — 是根的“抽象(abstract)”类。该类的对象从未被创建。它作为一个基础,以便让所有 DOM 节点都支持所谓的“事件(event)”,我们会在之后学习它。
- Node — 也是一个“抽象”类,充当 DOM 节点的基础。它提供了树的核心功能:
parentNode,nextSibling,childNodes等(它们都是 getter)。Node类的对象从未被创建。但是有一些继承自它的具体的节点类,例如:文本节点的Text,元素节点的Element,以及更多异域(exotic)类,例如注释节点的Comment。 - Element — 是 DOM 元素的基本类。它提供了元素级的导航(navigation),例如
nextElementSibling,children,以及像getElementsByTagName和querySelector这样的搜索方法。浏览器中不仅有 HTML,还会有 XML 和 SVG。Element类充当更多特定类的基本类:SVGElement,XMLElement和HTMLElement。 - HTMLElement
— 最终是所有 HTML 元素的基本类。各种 HTML 元素均继承自它:- HTMLInputElement —
<input>元素的类, - HTMLBodyElement —
<body>元素的类, - HTMLAnchorElement —
<a>元素的类, - ……等,每个标签都有自己的类,这些类可以提供特定的属性和方法。
- HTMLInputElement —
例如,我们考虑一下 <input> 元素的 DOM 对象。它属于 HTMLInputElement 类。
它获取属性和方法,并将其作为下列类(按继承顺序列出)的叠加:
HTMLInputElement— 该类提供特定于输入的属性,HTMLElement— 它提供了通用(common)的 HTML 元素方法(以及 getter 和 setter)Element— 提供通用(generic)元素方法,Node— 提供通用 DOM 节点属性,EventTarget— 为事件(包括事件本身)提供支持,- ……最后,它继承自
Object,因为像hasOwnProperty这样的“普通对象”方法也是可用的。
我们可以通过回调来查看 DOM 节点类名,因为对象通常都具有 constructor 属性。它引用类的 constructor,constructor.name 就是它的名称:
console.log(document.body.constructor.name); // HTMLBodyElemnet
……或者我们可以对其使用 toString 方法:
console.log(document.body); // [object HTMLBodyElement]
nodeType 属性
nodeType 属性提供了另一种“过时的”用来获取 DOM 节点类型的方法。
它有一个数值型值(numeric value):
- 对于元素节点
elem.nodeType == 1, - 对于文本节点
elem.nodeType == 3, - 对于 document 对象
elem.nodeType == 9, - 在 规范 中还有一些其他值。
例如:
<body><script>let elem = document.body;// 让我们检查一下它是什么?alert(elem.nodeType); // 1 => element// 第一个子节点是alert(elem.firstChild.nodeType); // 3 => text// 对于 document 对象,类型是 9alert( document.nodeType ); // 9</script></body>
在现代脚本中,我们可以使用 instanceof 和其他基于类的检查方法来查看节点类型,但有时 nodeType 可能更简单。我们只能读取 nodeType 而不能修改它。
标签: nodeName 和 tagName
给定一个 DOM 节点,我们可以从 nodeName 或者 tagName 属性中读取它的标签名:
例如:
alert( document.body.nodeName ); // BODYalert( document.body.tagName ); // BODY
tagName 和 nodeName 之间有什么不同吗?
当然,差异就体现在它们的名字上,但确实有些微妙。
tagName属性仅适用于Element节点。nodeName
是为任意
定义的:- 对于元素,它的意义与
tagName相同。 - 对于其他节点类型(text,comment 等),它拥有一个对应节点类型的字符串。
换句话说,tagName 仅受元素节点支持(因为它起源于 Element 类),而 nodeName 则可以说明其他节点类型。
例如,我们比较一下 document 的 tagName 和 nodeName,以及一个注释节点:
<body><!-- comment --><script>// for commentalert( document.body.firstChild.tagName ); // undefined(不是一个元素)alert( document.body.firstChild.nodeName ); // #comment// for documentalert( document.tagName ); // undefined(不是一个元素)alert( document.nodeName ); // #document</script></body>
如果我们只处理元素,那么 tagName 和 nodeName 这两种方法,我们都可以使用,没有区别。
innerHTML 内容
innerHTML 属性允许将元素中的 HTML 获取为字符串形式。
我们也可以修改它。因此,它是更改页面最有效的方法之一。
下面这个示例显示了 document.body 中的内容,然后将其完全替换:
<body><p>A paragraph</p><div>A div</div><script>alert( document.body.innerHTML ); // 读取当前内容document.body.innerHTML = 'The new BODY!'; // 替换它</script></body>
我们可以尝试插入无效的 HTML,浏览器会修复我们的错误:
<body><script>document.body.innerHTML = '<b>test'; // 忘记闭合标签alert( document.body.innerHTML ); // <b>test</b>(被修复了)</script></body>
脚本不会执行
如果 innerHTML 将一个 <script> 标签插入到 document 中 — 它会成为 HTML 的一部分,但是不会执行。
innerHTML+=” 会进行完全重写
我们可以使用 elem.innerHTML+="more html" 将 HTML 附加到元素上。
就像这样:
chatDiv.innerHTML += "<div>Hello<img src='smile.gif'/> !</div>";chatDiv.innerHTML += "How goes?";
但我们必须非常谨慎地使用它,因为我们所做的 不是 附加内容,而且完全地重写。
从技术上来说,下面这两行代码的作用相同:
elem.innerHTML += "...";// 进行写入的一种更简短的方式:elem.innerHTML = elem.innerHTML + "..."
换句话说,innerHTML+= 做了以下工作:
- 移除旧的内容。
- 然后写入新的
innerHTML(新旧结合)。
总结
每个 DOM 节点都属于一个特定的类。这些类形成层次结构(hierarchy)。完整的属性和方法集是继承的结果。
主要的 DOM 节点属性有:
nodeType
我们可以使用它来查看节点是文本节点还是元素节点。它具有一个数值型值(numeric value):1表示元素,3表示文本节点,其他一些则代表其他节点类型。只读。nodeName/tagName
用于元素名,标签名(除了 XML 模式,都要大写)。对于非元素节点,nodeName描述了它是什么。只读。innerHTML
元素的 HTML 内容。可以被修改。outerHTML
元素的完整 HTML。对elem.outerHTML的写入操作不会触及elem本身。而是在外部上下文中将其替换为新的 HTML。nodeValue/data
非元素节点(文本、注释)的内容。两者几乎一样,我们通常使用data。可以被修改。textContent
元素内的文本:HTML 减去所有<tags>。写入文本会将文本放入元素内,所有特殊字符和标签均被视为文本。可以安全地插入用户生成的文本,并防止不必要的 HTML 插入。hidden
当被设置为true时,执行与 CSSdisplay:none相同的事。
DOM 节点还具有其他属性,具体有哪些属性则取决于它们的类。例如,<input> 元素(HTMLInputElement)支持 value,type,而 <a> 元素(HTMLAnchorElement)则支持 href 等。大多数标准 HTML 特性(attribute)都具有相应的 DOM 属性。
然而,但是 HTML 特性(attribute)和 DOM 属性(property)并不总是相同的,我们将在下一章中看到。
DOM 属性
当浏览器加载页面时,它会“读取”(或者称之为:“解析”)HTML 并从中生成 DOM 对象。对于元素节点,大多数标准的 HTML 特性(attributes)会自动变成 DOM 对象的属性(properties)。(译注:attribute 和 property 两词意思相近,为作区分,全文将 attribute 译为“特性”,property 译为“属性”,请读者注意区分。)
例如,如果标签是 <body id="page">,那么 DOM 对象就会有 body.id="page"。
但特性—属性映射并不是一一对应的!在本章,我们将带领你一起分清楚这两个概念,了解如何使用它们,了解它们何时相同何时不同。
属性
我们已经见过了内建 DOM 属性。它们数量庞大。但是从技术上讲,没有人会限制我们,如果我们觉得这些 DOM 还不够,我们可以添加我们自己的。
例如,让我们在 document.body 中创建一个新的属性:
document.body.myData = {name: 'Caesar',title: 'Imperator'};alert(document.body.myData.title); // Imperator
我们也可以像下面这样添加一个方法:
document.body.sayTagName = function() {alert(this.tagName);};document.body.sayTagName(); // BODY(这个方法中的 "this" 的值是 document.body)
我们还可以修改内建属性的原型,例如修改 Element.prototype 为所有元素添加一个新方法:
Element.prototype.sayHi = function() {alert(`Hello, I'm ${this.tagName}`);};document.documentElement.sayHi(); // Hello, I'm HTMLdocument.body.sayHi(); // Hello, I'm BODY
所以,DOM 属性和方法的行为就像常规的 Javascript 对象一样:
- 它们可以有很多值。
- 它们是大小写敏感的(要写成
elem.nodeType,而不是elem.NoDeTyPe)。
HTML 特性
在 HTML 中,标签可能拥有特性(attributes)。当浏览器解析 HTML 文本,并根据标签创建 DOM 对象时,浏览器会辨别 标准的 特性并以此创建 DOM 属性。
所以,当一个元素有 id 或其他 标准的 特性,那么就会生成对应的 DOM 属性。但是非 标准的 特性则不会。
例如:
<body id="test" something="non-standard"><script>alert(document.body.id); // test// 非标准的特性没有获得对应的属性alert(document.body.something); // undefined</script></body>
所以,如果一个特性不是标准的,那么就没有相对应的 DOM 属性。那我们有什么方法来访问这些特性吗?
当然。所有特性都可以通过使用以下方法进行访问:
elem.hasAttribute(name)— 检查特性是否存在。elem.getAttribute(name)— 获取这个特性值。elem.setAttribute(name, value)— 设置这个特性值。elem.removeAttribute(name)— 移除这个特性。
这些方法操作的实际上是 HTML 中的内容。
我们也可以使用 elem.attributes 读取所有特性:属于内建 Attr 类的对象的集合,具有 name 和 value 属性。
下面是一个读取非标准的特性的示例:
<body something="non-standard"><script>alert(document.body.getAttribute('something')); // 非标准的</script></body>
HTML 特性有以下几个特征:
- 它们的名字是大小写不敏感的(
id与ID相同)。 - 它们的值总是字符串类型的。
下面是一个使用特性的扩展示例:
<body><div id="elem" about="Elephant"></div><script>alert( elem.getAttribute('About') ); // (1) 'Elephant',读取elem.setAttribute('Test', 123); // (2) 写入alert( elem.outerHTML ); // (3) 查看特性是否在 HTML 中(在)for (let attr of elem.attributes) { // (4) 列出所有alert( `${attr.name} = ${attr.value}` );}</script></body>
请注意:
getAttribute('About')— 这里的第一个字母是大写的,但是在 HTML 中,它们都是小写的。但这没有影响:特性的名称是大小写不敏感的。- 我们可以将任何东西赋值给特性,但是这些东西会变成字符串类型的。所以这里我们的值为
"123"。 - 所有特性,包括我们设置的那个特性,在
outerHTML中都是可见的。 attributes集合是可迭代对象,该对象将所有元素的特性(标准和非标准的)作为name和value属性存储在对象中。
属性特性同步
当一个标准的特性被改变,对应的属性也会自动更新,(除了几个特例)反之亦然。
在下面这个示例中,id 被修改为特性,我们可以看到对应的属性也发生了变化。然后反过来也是同样的效果:
<input><script>let input = document.querySelector('input');// 特性 => 属性input.setAttribute('id', 'id'); // 改变了id内容alert(input.id); // id(被更新了)// 属性 => 特性input.id = 'newId'; // 改变了id内容alert(input.getAttribute('id')); // newId(被更新了)</script>
但这里也有些例外,例如 input.value 只能从特性同步到属性,反过来则不行:
<input><script>let input = document.querySelector('input');// 特性 => 属性input.setAttribute('value', 'text'); // 更改value的值alert(input.value); // text// 这个操作无效,属性 => 特性input.value = 'newValue'; // 因为没有 input.value 这个特性,不能改变alert(input.getAttribute('value')); // text(没有被更新!)</script>
在上面这个例子中:
- 改变特性值
value会更新属性。 - 但是属性的更改不会影响特性。
这个“功能”在实际中会派上用场,因为用户行为可能会导致 value 的更改,然后在这些操作之后,如果我们想从 HTML 中恢复“原始”值,那么该值就在特性中。
DOM 属性是多类的
DOM 属性不总是字符串类型的。例如,input.checked 属性(对于 checkbox 的)是布尔型的。
<input id="input" type="checkbox" checked /><script>alert(input.getAttribute('checked')); // 特性值是:空字符串alert(input.checked); // 属性值是:true</script>
还有其他的例子。style 特性是字符串类型的,但 style 属性是一个对象:
<div id="div" style="color:red;font-size:120%">Hello</div><script>// 字符串alert(div.getAttribute('style')); // color:red;font-size:120%// 对象alert(div.style); // [object CSSStyleDeclaration]alert(div.style.color); // red</script>
尽管大多数 DOM 属性都是字符串类型的。
非标准的特性, dataset
当编写 HTML 时,我们会用到很多标准的特性。但是非标准的,自定义的呢?首先,让我们看看它们是否有用?用来做什么?
有时,非标准的特性常常用于将自定义的数据从 HTML 传递到 JavaScript,或者用于为 JavaScript “标记” HTML 元素。
像这样:
<!-- 标记这个 div 以在这显示 "name" --><div show-info="name"></div><!-- 标记这个 div 以在这显示 "age" --><div show-info="age"></div><script>// 这段代码找到带有标记的元素,并显示需要的内容let user = {name: "Pete",age: 25};for(let div of document.querySelectorAll('[show-info]')) {// 在字段中插入相应的信息let field = div.getAttribute('show-info');div.innerHTML = user[field]; // 首先 "name" 变为 Pete,然后 "age" 变为 25}</script>
总结
- 特性(attribute)— 写在 HTML 中的内容。
- 属性(property)— DOM 对象中的内容。
简略的对比:
| 属性 | 特性 | |
|---|---|---|
| 类型 | 任何值,标准的属性具有规范中描述的类型 | 字符串 |
| 名字 | 名字(name)是大小写敏感的 | 名字(name)是大小写不敏感的 |
操作特性的方法:
elem.hasAttribute(name)— 检查是否存在这个特性。elem.getAttribute(name)— 获取这个特性值。elem.setAttribute(name, value)— 设置这个特性值。elem.removeAttribute(name)— 移除这个特性。elem.attributes— 所有特性的集合。
在大多数情况下,最好使用 DOM 属性。仅当 DOM 属性无法满足开发需求,并且我们真的需要特性时,才使用特性,例如:
- 我们需要一个非标准的特性。但是如果它以
data-开头,那么我们应该使用dataset。 - 我们想要读取 HTML 中“所写的”值。对应的 DOM 属性可能不同,例如
href属性一直是一个 完整的 URL,但是我们想要的是“原始的”值。
DOM修改文档
DOM 修改是创建“实时”页面的关键。
在这里,我们将会看到如何“即时”创建新元素并修改现有页面内容。
例子:展示一条消息
让我们使用一个示例进行演示。我们将在页面上添加一条比 alert 更好看的消息。
它的外观如下:
<style>.alert {padding: 15px;border: 1px solid #d6e9c6;border-radius: 4px;color: #3c763d;background-color: #dff0d8;}</style><div class="alert"><strong>Hi there!</strong> You've read an important message.</div>
这是一个 HTML 示例。现在,让我们使用 JavaScript 创建一个相同的 div(假设样式已经在 HTML/CSS 文件中)。
创建一个元素
要创建 DOM 节点,这里有两种方法:
document.createElement(tag)
用给定的标签创建一个新 元素节点(element node):let div = document.createElement('div');document.createTextNode(text)
用给定的文本创建一个 文本节点:let textNode = document.createTextNode('Here I am');
大多数情况下,我们需要为此消息创建像 div 这样的元素节点。
创建一条消息
创建一个消息 div 分为 3 个步骤:
// 1. 创建 <div> 元素let div = document.createElement('div');// 2. 将元素的类设置为 "alert"div.className = "alert";// 3. 填充消息内容div.innerHTML = "<strong>Hi there!</strong> You've read an important message.";
我们已经创建了该元素。但到目前为止,它还只是在一个名为 div 的变量中,尚未在页面中。所以我们无法在页面上看到它。
插入方法
为了让 div 显示出来,我们需要将其插入到 document 中的某处。例如,into <body> element, referenced by document.body.
对此有一个特殊的方法 append:document.body.append(div)。
这是完整代码:
<style>.alert {padding: 15px;border: 1px solid #d6e9c6;border-radius: 4px;color: #3c763d;background-color: #dff0d8;}</style><script>let div = document.createElement('div');div.className = "alert";div.innerHTML = "<strong>Hi there!</strong> You've read an important message.";document.body.append(div);</script>
在这个例子中,我们对 document.body 调用了 append 方法。不过我们可以在其他任何元素上调用 append 方法,以将另外一个元素放入到里面。例如,通过调用 div.append(anotherElement),我们便可以在 <div> 末尾添加一些内容。
这里是更多的元素插入方法,指明了不同的插入位置:
node.append(...nodes or strings)—— 在node末尾 插入节点或字符串,node.prepend(...nodes or strings)—— 在node开头 插入节点或字符串,node.before(...nodes or strings)—— 在node前面 插入节点或字符串,node.after(...nodes or strings)—— 在node后面 插入节点或字符串,node.replaceWith(...nodes or strings)—— 将node替换为给定的节点或字符串。
这些方法的参数可以是一个要插入的任意的 DOM 节点列表,或者文本字符串(会被自动转换成文本节点)。
让我们在实际应用中看一看。
下面是使用这些方法将列表项添加到列表中,以及将文本添加到列表前面和后面的示例:
<ol id="ol"><li>0</li><li>1</li><li>2</li></ol><script>ol.before('before'); // 将字符串 "before" 插入到 <ol> 前面ol.after('after'); // 将字符串 "after" 插入到 <ol> 后面let liFirst = document.createElement('li');liFirst.innerHTML = 'prepend';ol.prepend(liFirst); // 将 liFirst 插入到 <ol> 的最开始let liLast = document.createElement('li');liLast.innerHTML = 'append';ol.append(liLast); // 将 liLast 插入到 <ol> 的最末尾</script>

节点移除
想要移除一个节点,可以使用 node.remove()。
让我们的消息在一秒后消失:
<style>.alert {padding: 15px;border: 1px solid #d6e9c6;border-radius: 4px;color: #3c763d;background-color: #dff0d8;}</style><script>let div = document.createElement('div');div.className = "alert";div.innerHTML = "<strong>Hi there!</strong> You've read an important message.";document.body.append(div);setTimeout(() => div.remove(), 1000);</script>
请注意:如果我们要将一个元素 移动 到另一个地方,则无需将其从原来的位置中删除。
所有插入方法都会自动从旧位置删除该节点。
例如,让我们进行元素交换:
<div id="first">First</div><div id="second">Second</div><script>// 无需调用 removesecond.after(first); // 获取 #second,并在其后面插入 #first</script>
克隆节点
如何再插入一条类似的消息?
我们可以创建一个函数,并将代码放在其中。但是另一种方法是 克隆 现有的 div,并修改其中的文本(如果需要)。
当我们有一个很大的元素时,克隆的方式可能更快更简单。
调用 elem.cloneNode(true) 来创建元素的一个“深”克隆 — 具有所有特性(attribute)和子元素。如果我们调用 elem.cloneNode(false),那克隆就不包括子元素。
一个拷贝消息的示例:
<style>.alert {padding: 15px;border: 1px solid #d6e9c6;border-radius: 4px;color: #3c763d;background-color: #dff0d8;}</style><div class="alert" id="div"><strong>Hi there!</strong> You've read an important message.</div><script>let div2 = div.cloneNode(true); // 克隆消息div2.querySelector('strong').innerHTML = 'Bye there!'; // 修改克隆div.after(div2); // 在已有的 div 后显示克隆</script>
DocumentFragment
DocumentFragment 是一个特殊的 DOM 节点,用作来传递节点列表的包装器(wrapper)。
我们可以向其附加其他节点,但是当我们将其插入某个位置时,则会插入其内容。
例如,下面这段代码中的 getListContent 会生成带有 <li> 列表项的片段,然后将其插入到 <ul> 中:
<ul id="ul"></ul><script>function getListContent() {let fragment = new DocumentFragment(); // `DocumentFragment` 是一个特殊的 DOM 节点,用作来传递节点列表的包装器(wrapper)for(let i=1; i<=3; i++) {let li = document.createElement('li');li.append(i);fragment.append(li);}return fragment;}ul.append(getListContent()); // (*)</script>
请注意,在最后一行 (*) 我们附加了 DocumentFragment,但是它和 ul “融为一体(blends in)”了,所以最终的文档结构应该是:
<ul><li>1</li><li>2</li><li>3</li></ul>
DocumentFragment 很少被显式使用。如果可以改为返回一个节点数组,那为什么还要附加到特殊类型的节点上呢?重写示例:
<ul id="ul"></ul><script>function getListContent() {let result = [];for(let i=1; i<=3; i++) {let li = document.createElement('li');li.append(i);result.push(li);}return result;}ul.append(...getListContent()); // append + "..." operator = friends!</script>
我们之所以提到 DocumentFragment,主要是因为它上面有一些概念,例如 template 元素,我们将在以后讨论。
总结
- 创建新节点的方法:
document.createElement(tag)— 用给定的标签创建一个元素节点,document.createTextNode(value)— 创建一个文本节点(很少使用),elem.cloneNode(deep)— 克隆元素,如果deep==true则与其后代一起克隆。
- 插入和移除节点的方法:
node.append(...nodes or strings)— 在node末尾插入,node.prepend(...nodes or strings)— 在node开头插入,node.before(...nodes or strings)— 在node之前插入,node.after(...nodes or strings)— 在node之后插入,node.replaceWith(...nodes or strings)— 替换node。node.remove()— 移除node。
文本字符串被“作为文本”插入。
- 这里还有“旧式”的方法:
parent.appendChild(node)parent.insertBefore(node, nextSibling)parent.removeChild(node)parent.replaceChild(newElem, node)
这些方法都返回 node。
- 在
html中给定一些 HTML,elem.insertAdjacentHTML(where, html)会根据where的值来插入它:"beforebegin"— 将html插入到elem前面,"afterbegin"— 将html插入到elem的开头,"beforeend"— 将html插入到elem的末尾,"afterend"— 将html插入到elem后面。
另外,还有类似的方法,elem.insertAdjacentText 和 elem.insertAdjacentElement,它们会插入文本字符串和元素,但很少使用。
- 要在页面加载完成之前将 HTML 附加到页面:
document.write(html)
页面加载完成后,这样的调用将会擦除文档。多见于旧脚本。
样式和类
在我们讨论 JavaScript 处理样式和类的方法之前 — 有一个重要的规则。希望它足够明显,但是我们仍然必须提到它。
通常有两种设置元素样式的方式:
- 在 CSS 中创建一个类,并添加它:
<div class="..."> - 将属性直接写入
style:<div style="...">。
JavaScript 既可以修改类,也可以修改 style 属性。
相较于将样式写入 style 属性,我们应该首选通过 CSS 类的方式来添加样式。仅当类“无法处理”时,才应选择使用 style 属性的方式。
例如,如果我们动态地计算元素的坐标,并希望通过 JavaScript 来设置它们,那么使用 style 是可以接受的,如下所示:
let top = /* 复杂的计算 */;let left = /* 复杂的计算 */;elem.style.left = left; // 例如 '123px',在运行时计算出的elem.style.top = top; // 例如 '456px'
className 和 classList
更改类是脚本中最常见的操作之一。
在很久以前,JavaScript 中有一个限制:像 "class" 这样的保留字不能用作对象的属性。这一限制现在已经不存在了,但当时就不能存在像 elem.class 这样的 "class" 属性。
因此,对于类,引入了看起来类似的属性 "className":elem.className 对应于 "class" 特性(attribute)。
例如:
<body class="main page"><script>alert(document.body.className); // main page</script></body>
如果我们对 elem.className 进行赋值,它将替换类中的整个字符串。有时,这正是我们所需要的,但通常我们希望添加/删除单个类。
这里还有另一个属性:elem.classList。
elem.classList 是一个特殊的对象,它具有 add/remove/toggle 单个类的方法。
- add() 添加类名
- remove() 删除类名
- toggle() 有类名就删除,没有类名就添加
- contains() 检查是否存在类名,有就返回 true , 没有就返回false
例如:
<body class="main page"><script>// 添加一个 classdocument.body.classList.add('article');alert(document.body.className); // main page article</script></body>
因此,我们既可以使用 className 对完整的类字符串进行操作,也可以使用使用 classList 对单个类进行操作。我们选择什么取决于我们的需求。
classList 的方法:
elem.classList.add/remove(class)— 添加/移除类。elem.classList.toggle(class)— 如果类不存在就添加类,存在就移除它。elem.classList.contains(class)— 检查给定类,返回true/false。
此外,classList 是可迭代的,因此,我们可以像下面这样列出所有类:
<body class="main page"><script>for (let name of document.body.classList) {alert(name); // main,然后是 page}</script></body>
元素样式
elem.style 属性是一个对象,它对应于 "style" 特性(attribute)中所写的内容。elem.style.width="100px" 的效果等价于我们在 style 特性中有一个 width:100px 字符串。
对于多词(multi-word)属性,使用驼峰式 camelCase:
background-color => elem.style.backgroundColorz-index => elem.style.zIndexborder-left-width => elem.style.borderLeftWidth
document.body.style.backgroundColor = prompt('background color?', 'green');
前缀属性
像 -moz-border-radius 和 -webkit-border-radius 这样的浏览器前缀属性,也遵循同样的规则:连字符 - 表示大写。
例如:
button.style.MozBorderRadius = '5px';button.style.WebkitBorderRadius = '5px';
重置样式属性
有时我们想要分配一个样式属性,稍后移除它。
例如,为了隐藏一个元素,我们可以设置 elem.style.display = "none"。
然后,稍后我们可能想要移除 style.display,就像它没有被设置一样。这里不应该使用 delete elem.style.display,而应该使用 elem.style.display = "" 将其赋值为空。
// 如果我们运行这段代码,<body> 将会闪烁document.body.style.display = "none"; // 隐藏setTimeout(() => document.body.style.display = "", 1000); // 恢复正常
如果我们将 display 设置为空字符串,那么浏览器通常会应用 CSS 类以及内置样式,就好像根本没有这样的 style 属性一样。
用 **style.cssText** 进行完全的重写, 完全重写,也就是连之前存在的样式会被覆盖
通常,我们使用 style.* 来对各个样式属性进行赋值。我们不能像这样的 div.style="color: red; width: 100px" 设置完整的属性,因为 div.style 是一个对象,并且它是只读的。
想要以字符串的形式设置完整的样式,可以使用特殊属性 style.cssText:
<div id="div">Button</div><script>// 我们可以在这里设置特殊的样式标记,例如 "important"div.style.cssText=`color: red !important;background-color: yellow;width: 100px;text-align: center;`;alert(div.style.cssText);</script>
我们很少使用这个属性,因为这样的赋值会删除所有现有样式:它不是进行添加,而是替换它们。有时可能会删除所需的内容。但是,当我们知道我们不会删除现有样式时,可以安全地将其用于新元素。
可以通过设置一个特性(attribute)来实现同样的效果:div.setAttribute('style', 'color: red...')。
注意单位
不要忘记将 CSS 单位添加到值上。
例如,我们不应该将 elem.style.top 设置为 10,而应将其设置为 10px。否则设置会无效:
<body><script>// 无效!document.body.style.margin = 20;alert(document.body.style.margin); // ''(空字符串,赋值被忽略了)// 现在添加了 CSS 单位(px)— 生效了document.body.style.margin = '20px';alert(document.body.style.margin); // 20pxalert(document.body.style.marginTop); // 20pxalert(document.body.style.marginLeft); // 20px</script></body>
请注意:浏览器在最后几行代码中对属性 style.margin 进行了“解包”,并从中推断出 style.marginLeft 和 style.marginTop。
总结
要管理 class,有两个 DOM 属性:
className— 字符串值,可以很好地管理整个类的集合。classList— 具有add/remove/toggle/contains方法的对象,可以很好地支持单个类。
要改变样式:
style属性是具有驼峰(camelCased)样式的对象。对其进行读取和修改与修改"style"特性(attribute)中的各个属性具有相同的效果。要了解如何应用important和其他特殊内容 — 在 MDN 中有一个方法列表。style.cssText属性对应于整个"style"特性(attribute),即完整的样式字符串。
要读取已解析的(resolved)样式(对于所有类,在应用所有 CSS 并计算最终值之后):
getComputedStyle(elem, [pseudo])返回与style对象类似的,且包含了所有类的对象。只读。
元素大小的滚动
示例
作为演示属性的示例元素,我们将使用下面给出的元素:
<div id="example">...Text...</div><style>#example {width: 300px;height: 200px;border: 25px solid #E8C48F;padding: 20px;overflow: auto;}</style>
它有边框(border),内边距(padding)和滚动(scrolling)等全套功能。但没有外边距(margin),因为它们不是元素本身的一部分,并且它们没什么特殊的属性。
这个元素看起来就像这样:
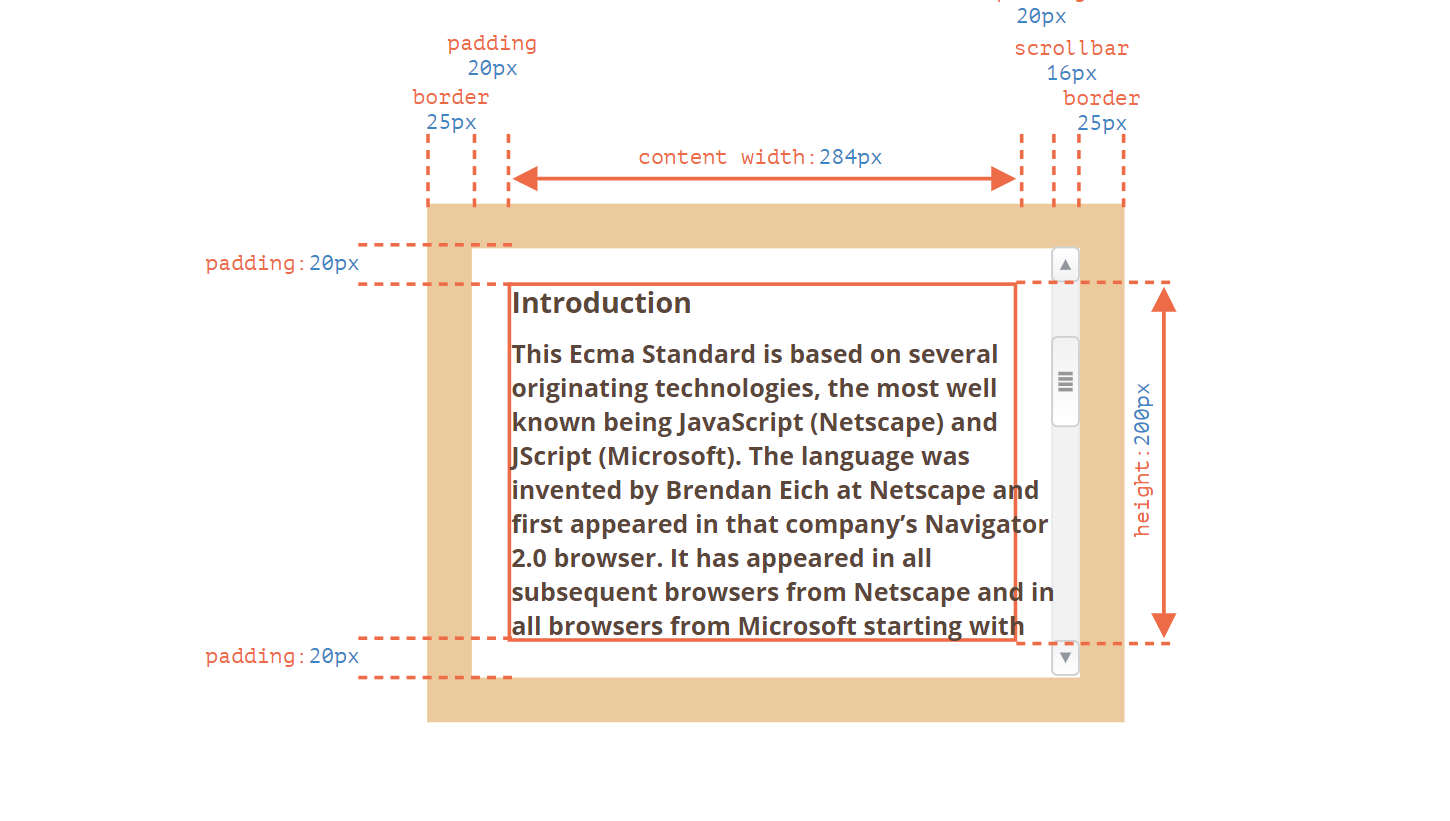
Window 大小和移动
我们如何找到浏览器窗口(window)的宽度和高度呢?我们如何获得文档(document)的包括滚动部分在内的完整宽度和高度呢?我们如何使用 JavaScript 滚动页面?
对于此类信息,我们可以使用与 <html> 标签相对应的根文档元素 document.documentElement。但是还有其他方法和特性需要考虑。
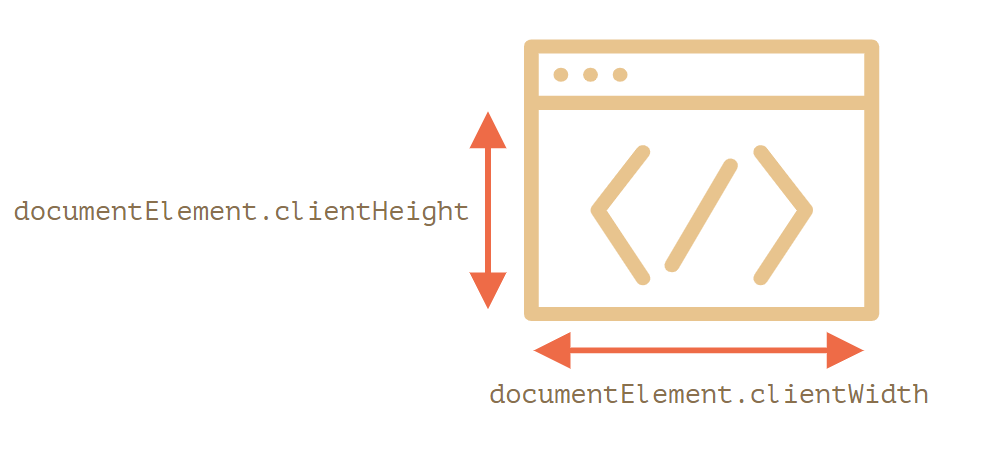
窗口的 width / heigth
为了获取窗口(window)的宽度和高度,我们可以使用 document.documentElement 的 clientWidth/clientHeight:
不是
**window.innerWidth/innerHeight**浏览器也支持像
window.innerWidth/innerHeight这样的属性。它们看起来像我们想要的,那为什么不使用它们呢?如果这里存在一个滚动条,并且滚动条占用了一些空间,那么
clientWidth/clientHeight会提供没有滚动条(减去它)的 width/height。换句话说,它们返回的是可用于内容的文档的可见部分的 width/height。
window.innerWidth/innerHeight包括了滚动条。如果这里有一个滚动条,它占用了一些空间,那么这两行代码会显示不同的值:
在大多数情况下,我们需要 可用 的窗口宽度以绘制或放置某些东西。也就是说,在滚动条内(如果有)。所以,我们应该使用
documentElement.clientHeight/clientWidth。也就是说区别: clienHeight/clienWidth 不会将滚动条算在内, 而innerWidth/innerHeight 会将滚动条计算在内
alert( window.innerWidth ); // 整个窗口的宽度alert( document.documentElement.clientWidth ); // 减去滚动条宽度后的窗口宽度
**DOCTYPE**很重要请注意:当 HTML 中没有
<!DOCTYPE HTML>时,顶层级(top-level)几何属性的工作方式可能就会有所不同。可能会出现一些稀奇古怪的情况。在现代 HTML 中,我们始终都应该写
DOCTYPE。
文档的 width / heigth
从理论上讲,由于根文档元素是 document.documentElement,并且它包围了所有内容,因此我们可以通过使用 documentElement.scrollWidth/scrollHeight 来测量文档的完整大小。
但是在该元素上,对于整个文档,这些属性均无法正常工作。在 Chrome/Safari/Opera 中,如果没有滚动条,documentElement.scrollHeight 甚至可能小于 documentElement.clientHeight!很奇怪,对吧?
为了可靠地获得完整的文档高度,我们应该采用以下这些属性的最大值:
let scrollHeight = Math.max(document.body.scrollHeight, document.documentElement.scrollHeight,document.body.offsetHeight, document.documentElement.offsetHeight,document.body.clientHeight, document.documentElement.clientHeight);alert('Full document height, with scrolled out part: ' + scrollHeight);
获得当前滚动
DOM 元素的当前滚动状态在其 scrollLeft/scrollTop 属性中。
对于文档滚动,在大多数浏览器中,我们可以使用 document.documentElement.scrollLeft/scrollTop,但在较旧的基于 WebKit 的浏览器中则不行,例如在 Safari(bug 5991)中,我们应该使用 document.body 而不是 document.documentElement。
幸运的是,我们根本不必记住这些特性,因为滚动在 window.pageXOffset/pageYOffset 中可用:
alert('Current scroll from the top: ' + window.pageYOffset);alert('Current scroll from the left: ' + window.pageXOffset);
这些属性是只读的。
滚动: scrollTo , scrollBy , scrollintoView
重要:
必须在 DOM 完全构建好之后才能通过 JavaScript 滚动页面。
例如,如果我们尝试通过
<head>中的脚本滚动页面,它将无法正常工作。
可以通过更改 scrollTop/scrollLeft 来滚动常规元素。
我们可以使用 document.documentElement.scrollTop/scrollLeft 对页面进行相同的操作(Safari 除外,而应该使用 document.body.scrollTop/Left 代替)。
或者,有一个更简单的通用解决方案:使用特殊方法 window.scrollBy(x,y) 和 window.scrollTo(pageX,pageY)。
- 方法
scrollBy(x,y)将页面滚动至 相对于当前位置的**(x, y)**位置。例如,scrollBy(0,10)会将页面向下滚动10px。 - 方法
scrollTo(pageX,pageY)将页面滚动至 绝对坐标,使得可见部分的左上角具有相对于文档左上角的坐标(pageX, pageY)。就像设置了scrollLeft/scrollTop一样。
scrollintoView
为了完整起见,让我们再介绍一种方法:elem.scrollIntoView(top)。
对 elem.scrollIntoView(top) 的调用将滚动页面以使 elem 可见。它有一个参数:
- 如果
top=true(默认值),页面滚动,使elem出现在窗口顶部。元素的上边缘将与窗口顶部对齐。 - 如果
top=false,页面滚动,使elem出现在窗口底部。元素的底部边缘将与窗口底部对齐。 - 类似于翻半页
进制滚动
有时候我们需要使文档“不可滚动”。例如,当我们需要用一条需要立即引起注意的大消息来覆盖文档时,我们希望访问者与该消息而不是与文档进行交互。
要使文档不可滚动,只需要设置 document.body.style.overflow = "hidden"。该页面将“冻结”在其当前滚动位置上。
总结
几何:
- 文档可见部分的 width/height(内容区域的 width/height):
document.documentElement.clientWidth/clientHeight - 整个文档的 width/height,其中包括滚动出去的部分:
let scrollHeight = Math.max(document.body.scrollHeight, document.documentElement.scrollHeight,document.body.offsetHeight, document.documentElement.offsetHeight,document.body.clientHeight, document.documentElement.clientHeight);
滚动:
- 读取当前的滚动:
window.pageYOffset/pageXOffset。 - 更改当前的滚动:
window.scrollTo(pageX,pageY)— 绝对坐标,window.scrollBy(x,y)— 相对当前位置进行滚动,elem.scrollIntoView(top)— 滚动以使elem可见(elem与窗口的顶部/底部对齐)。
浏览器事件简介
事件 是某事发生的信号。所有的 DOM 节点都生成这样的信号(但事件不仅限于 DOM)。
这是最有用的 DOM 事件的列表,你可以浏览一下:
鼠标事件:
click—— 当鼠标点击一个元素时(触摸屏设备会在点击时生成)。contextmenu—— 当鼠标右键点击一个元素时。mouseover/mouseout—— 当鼠标指针移入/离开一个元素时。mousedown/mouseup—— 当在元素上按下/释放鼠标按钮时。mousemove—— 当鼠标移动时。
键盘事件:
keydown和keyup—— 当按下和松开一个按键时。
表单(form)元素事件:
submit—— 当访问者提交了一个<form>时。focus—— 当访问者聚焦于一个元素时,例如聚焦于一个<input>。
Document 事件:
DOMContentLoaded—— 当 HTML 的加载和处理均完成,DOM 被完全构建完成时。
CSS 事件:
transitionend—— 当一个 CSS 动画完成时。
还有很多其他事件。我们将在下一章中详细介绍具体事件。
HTML 特性
处理程序可以设置在 HTML 中名为 on<event> 的特性(attribute)中。
例如,要为一个 input 分配一个 click 处理程序,我们可以使用 onclick,像这样;
<input value="Click me" onclick="alert('Click!')" type="button">
在鼠标点击时,onclick 中的代码就会运行。
请注意,在 onclick 中,我们使用单引号,因为特性本身使用的是双引号。如果我们忘记了代码是在特性中的,而使用了双引号,像这样:onclick="alert("Click!")",那么它就无法正确运行。
HTML 特性不是编写大量代码的好位置,因此我们最好创建一个 JavaScript 函数,然后在 HTML 特性中调用这个函数。
在这里点击会运行 countRabbits():
<script>function countRabbits() {for (let i = 1; i <= 3; i++) {alert("Rabbits number: " + i);}}</script><!-- 点击表单执行函数 --><input type="button" value="Click me" onclick="countRabbits()">
DOM属性
我们可以使用 DOM 属性(property)on<event> 来分配处理程序。
例如 elem.onclick:
<input id="elem" type="button" value="Click me"><script>elem.onclick = function() {alert('Thank you');};</script>
如果一个处理程序是通过 HTML 特性(attribute)分配的,那么随后浏览器读取它,并从特性的内容创建一个新函数,并将这个函数写入 DOM 属性(property)。
因此,这种方法实际上与前一种方法相同。
这两段代码工作相同:
- 只有 HTML:
<input type="button" onclick="alert('Click!')" value="Button">
- HTML + JS:
<input type="button" id="button" value="Button"><script>button.onclick = function() {alert('Click!');};</script>
在第一个例子中,button.onclick 是通过 HTML 特性(attribute)初始化的,而在第二个例子中是通过脚本初始化的。这是它们唯一的不同之处。
因为这里只有一个 **onclick** 属性,所以我们无法分配更多事件处理程序。
在下面这个示例中,我们使用 JavaScript 添加了一个处理程序,覆盖了现有的处理程序:
<input type="button" id="elem" onclick="alert('Before')" value="Click me"><script>elem.onclick = function() { // 覆盖了现有的处理程序alert('After'); // 只会显示此内容};</script>
要移除一个处理程序 —— 赋值 elem.onclick = null。
访问元素: this
处理程序中的 this 的值是对应的元素。就是处理程序所在的那个元素。
下面这行代码中的 button 使用 this.innerHTML 来显示它的内容:
<button onclick="alert(this.innerHTML)">Click me</button>
可能出现的错误
如果你刚开始写事件 —— 请注意一些细微之处。
我们可以将一个现存的函数用作处理程序:
function sayThanks() {alert('Thanks!');}elem.onclick = sayThanks;
但要注意:函数应该是以 sayThanks 的形式进行赋值,而不是 sayThanks()。
// 正确button.onclick = sayThanks;// 错误button.onclick = sayThanks();
如果我们添加了括号,那么 sayThanks() 就变成了一个函数调用。所以,最后一行代码实际上获得的是函数执行的 结果,即 undefined(因为这个函数没有返回值)。此代码不会工作。
……但在标记(markup)中,我们确实需要括号:
<input type="button" id="button" onclick="sayThanks()">
这个区别很容易解释。当浏览器读取 HTML 特性(attribute)时,浏览器将会使用 特性中的内容 创建一个处理程序。
addEventListener
上述分配处理程序的方式的根本问题是 —— 我们不能为一个事件分配多个处理程序。
假设,在我们点击了一个按钮时,我们代码中的一部分想要高亮显示这个按钮,另一部分则想要显示一条消息。
我们想为此事件分配两个处理程序。但是,新的 DOM 属性将覆盖现有的 DOM 属性:
input.onclick = function() { alert(1); }// ...input.onclick = function() { alert(2); } // 替换了前一个处理程序
Web 标准的开发者很早就了解到了这一点,并提出了一种使用特殊方法 addEventListener 和 removeEventListener 来管理处理程序的替代方法。它们没有这样的问题。
添加处理程序的语法:
element.addEventListener(event, handler[, options]);
event
事件名,例如:"click"。handler
处理程序。options
具有以下属性的附加可选对象:once:如果为true,那么会在被触发后自动删除监听器。capture:事件处理的阶段,我们稍后将在 冒泡和捕获 一章中介绍。由于历史原因,options也可以是false/true,它与{capture: false/true}相同。passive:如果为true,那么处理程序将不会调用preventDefault(),我们稍后将在 浏览器默认行为 一章中介绍。
要移除处理程序,可以使用 removeEventListener:
element.removeEventListener(event, handler[, options]);
移除需要相同的函数
要移除处理程序,我们需要传入与分配的函数完全相同的函数。
这不起作用:
处理程序不会被移除,因为
removeEventListener获取了另一个函数 —— 使用相同的代码,但这并不起作用,因为它是一个不同的函数对象。下面是正确方法:
请注意 —— 如果我们不将函数存储在一个变量中,那么我们就无法移除它。由
addEventListener分配的处理程序将无法被“读回”。
elem.addEventListener( "click" , () => alert('Thanks!'));// ....elem.removeEventListener( "click", () => alert('Thanks!'));
function handler() {alert( 'Thanks!' );}input.addEventListener("click", handler);// ....input.removeEventListener("click", handler);
对象处理程序 : handleEvent
我们不仅可以分配函数,还可以使用 addEventListener 将一个对象分配为事件处理程序。当事件发生时,就会调用该对象的 handleEvent 方法。
例如:
<button id="elem">Click me</button><script>let obj = {handleEvent(event) {alert(event.type + " at " + event.currentTarget);}};elem.addEventListener('click', obj);</script>
正如我们所看到的,当 addEventListener 接收一个对象作为处理程序时,在事件发生时,它就会调用 obj.handleEvent(event) 来处理事件。
我们也可以对此使用一个类:
<button id="elem">Click me</button><script>class Menu {handleEvent(event) {switch(event.type) {case 'mousedown':elem.innerHTML = "Mouse button pressed";break;case 'mouseup':elem.innerHTML += "...and released.";break;}}}let menu = new Menu();elem.addEventListener('mousedown', menu);elem.addEventListener('mouseup', menu);</script>
这里,同一个对象处理两个事件。请注意,我们需要使用 addEventListener 来显式设置事件,以指明要监听的事件。这里的 menu 对象只监听 mousedown 和 mouseup,而没有任何其他类型的事件。
handleEvent 方法不必通过自身完成所有的工作。它可以调用其他特定于事件的方法,例如:
<button id="elem">Click me</button><script>class Menu {handleEvent(event) {// mousedown -> onMousedownlet method = 'on' + event.type[0].toUpperCase() + event.type.slice(1);this[method](event);}onMousedown() {elem.innerHTML = "Mouse button pressed";}onMouseup() {elem.innerHTML += "...and released.";}}let menu = new Menu();elem.addEventListener('mousedown', menu);elem.addEventListener('mouseup', menu);</script>
现在事件处理程序已经明确地分离了出来,这样更容易进行代码编写和后续维护。
总结
这里有 3 种分配事件处理程序的方式:
- HTML 特性(attribute):
onclick="..."。 - DOM 属性(property):
elem.onclick = function。 - 方法(method):
elem.addEventListener(event, handler[, phase])用于添加,removeEventListener用于移除。
HTML 特性很少使用,因为 HTML 标签中的 JavaScript 看起来有些奇怪且陌生。而且也不能在里面写太多代码。
DOM 属性用起来还可以,但我们无法为特定事件分配多个处理程序。在许多场景中,这种限制并不严重。
最后一种方式是最灵活的,但也是写起来最长的。有少数事件只能使用这种方式。例如 transtionend 和 DOMContentLoaded(上文中讲到了)。addEventListener 也支持对象作为事件处理程序。在这种情况下,如果发生事件,则会调用 handleEvent 方法。
无论你如何分类处理程序 —— 它都会将获得一个事件对象作为第一个参数。该对象包含有关所发生事件的详细信息。
冒泡和捕获
冒泡
冒泡(bubbling)原理很简单。
当一个事件发生在一个元素上,它会首先运行在该元素上的处理程序,然后运行其父元素上的处理程序,然后一直向上到其他祖先上的处理程序。 也就是从小到大执行内容
假设我们有 3 层嵌套 FORM > DIV > P,它们各自拥有一个处理程序:、
<!-- 当一个事件发生在一个元素上,它会首先运行在该元素上的处理程序,然后运行其父元素上的处理程序,然后一直向上到其他祖先上的处理程序。 --><form onclick="alert('form')">form<div onclick="alert('div')">div<p onclick="alert('p')">p</p></div></form>
点击内部的 <p> 会首先运行 onclick:
- 在该
<p>上的。 - 然后是外部
<div>上的。 - 然后是外部
<form>上的。 - 以此类推,直到最后的
document对象。
因此,如果我们点击 <p>,那么我们将看到 3 个 alert:p → div → form。
这个过程被称为“冒泡(bubbling)”,因为事件从内部元素“冒泡”到所有父级,就像在水里的气泡一样。
几乎 所有事件都会冒泡
这句话中的关键词是“几乎”。
例如,
focus事件不会冒泡。同样,我们以后还会遇到其他例子。但这仍然是例外,而不是规则,大多数事件的确都是冒泡的。
event.target
父元素上的处理程序始终可以获取事件实际发生位置的详细信息。
引发事件的那个嵌套层级最深的元素被称为目标元素,可以通过 **event.target** 访问。
注意与 this(=event.currentTarget)之间的区别:
event.target—— 是引发事件的“目标”元素,它在冒泡过程中不会发生变化。this—— 是“当前”元素,其中有一个当前正在运行的处理程序。
例如,如果我们有一个处理程序 form.onclick,那么它可以“捕获”表单内的所有点击。无论点击发生在哪里,它都会冒泡到 <form> 并运行处理程序。
在 form.onclick 处理程序中:
this(=event.currentTarget)是<form>元素,因为处理程序在它上面运行。event.target是表单中实际被点击的元素。
event.target 可能会等于 this —— 当点击事件发生在 <form> 元素上时,就会发生这种情况。
停止冒泡
冒泡事件从目标元素开始向上冒泡。通常,它会一直上升到 <html>,然后再到 document 对象,有些事件甚至会到达 window,它们会调用路径上所有的处理程序。
但是任意处理程序都可以决定事件已经被完全处理,并停止冒泡。
用于停止冒泡的方法是 event.stopPropagation()。
例如,如果你点击 <button>,这里的 body.onclick 不会工作:
<body onclick="alert(`the bubbling doesn't reach here`)"><!--event.stopPropagation() 停止冒泡 --><button onclick="event.stopPropagation()">Click me</button></body>
event.stopImmediatePropagation()
如果一个元素在一个事件上有多个处理程序,即使其中一个停止冒泡,其他处理程序仍会执行。
换句话说,
event.stopPropagation()停止向上移动,但是当前元素上的其他处理程序都会继续运行。有一个
event.stopImmediatePropagation()方法,可以用于停止冒泡,并阻止当前元素上的处理程序运行。使用该方法之后,其他处理程序就不会被执行。不要在没有需要的情况下停止冒泡!
冒泡很方便。不要在没有真实需求时阻止它:除非是显而易见的,并且在架构上经过深思熟虑的。
有时
event.stopPropagation()会产生隐藏的陷阱,以后可能会成为问题。例如:
- 我们创建了一个嵌套菜单,每个子菜单各自处理对自己的元素的点击事件,并调用
stopPropagation,以便不会触发外部菜单。- 之后,我们决定捕获在整个窗口上的点击,以追踪用户的行为(用户点击的位置)。有些分析系统会这样做。通常,代码会使用
document.addEventListener('click'…)来捕获所有的点击。- 我们的分析不适用于被
stopPropagation所阻止点击的区域。太伤心了,我们有一个“死区”。通常,没有真正的必要去阻止冒泡。一项看似需要阻止冒泡的任务,可以通过其他方法解决。其中之一就是使用自定义事件,稍后我们会介绍它们此外,我们还可以将我们的数据写入一个处理程序中的
event对象,并在另一个处理程序中读取该数据,这样我们就可以向父处理程序传递有关下层处理程序的信息。
捕获
事件处理的另一个阶段被称为“捕获(capturing)”。它很少被用在实际开发中,但有时是有用的。
DOM 事件标准描述了事件传播的 3 个阶段:
- 捕获阶段(Capturing phase)—— 事件(从 Window)向下走近元素。
- 目标阶段(Target phase)—— 事件到达目标元素。
- 冒泡阶段(Bubbling phase)—— 事件从元素上开始冒泡。

若有收获,就点个赞吧
0 人点赞
